SMILEtrack:基于相似度学习的多目标跟踪
摘要
多目标跟踪(MOT)在计算机视觉领域有着广泛的应用。基于检测的跟踪(TBD)是一种流行的多目标跟踪范式。TBD由第一步的目标检测、随后的数据关联、轨迹生成和更新组成。本文提出一种基于孪生网络的相似性学习模块(SLM)来提取重要的目标外观特征,并提出一种将目标运动和外观特征有效结合的方法。该设计加强了对物体运动和外观特征的建模,用于数据关联。设计了一种相似性匹配级联(SMC)用于SMILEtrack跟踪器的数据关联。SMILEtrack在MOTChallenge和MOT17测试集上分别取得了81.06 MOTA和80.5 IDF1的成绩。
1、简介
MOT是计算机视觉领域的一个研究热点,在视频理解中起着至关重要的作用。MOT的目标是估计每个目标的轨迹,并尝试将它们与视频序列中的每一帧关联起来。随着MOT的成功,它可以在社会上普遍使用,如车辆计算、计算机交互[25][12]、智能视频分析、自动驾驶等。基于TBD (Tracking-By-Detection)范式的多目标跟踪策略[1]、[27]、[26]是近年来主流且高效的多目标跟踪策略。根据检测结果进行跟踪,将问题分解为检测和关联两个步骤。在检测步骤中,我们需要在单个视频帧中定位感兴趣的目标,将每个目标链接到现有的轨迹,或在关联步骤中创建新的轨迹。然而,由于目标模糊、遮挡、场景复杂等问题,该方法仍然面临挑战。
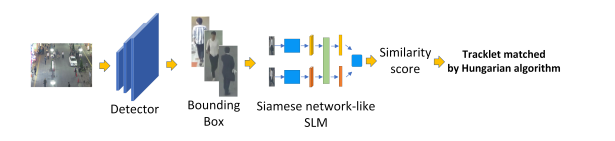
图1 SMILEtrack的流程图。SMILEtrack是一种类似孪生网络的架构,用于学习对象特征。
为实现跟踪系统,求解模型可分为独立检测与嵌入模型(SDE)和联合检测与嵌入模型(JDE)。该方法属于SDE;架构如图1所示。SDE至少需要两个功能组件:一个检测器和一个再识别模型。首先,检测器通过边界框在单帧中定位所有物体。然后,再识别模型将从每个边界框中提取物体的特征以生成嵌入。最后,将每个边界框关联到一个现有轨迹或创建一个新的轨迹。然而,SDE方法在使用两个独立的模型进行物体检测和嵌入提取时需要多次计算,因此无法达到实时推理速度。由于检测器和重识别模型之间的特征不能共享,SDE方法在推理时需要将重识别模型应用于每个包围盒以提取嵌入。面对这一问题,一种可行的解决方案是将检测器与重识别模型相结合。JDE类别[26][32]在单次深度网络中结合了检测器和嵌入模型。只需对模型进行一次推理,即可同时输出检测结果和被检测框对应的外观嵌入。
尽管JDE的成功使得MOT任务取得了很好的精度结果,但我们认为JDE仍然存在一些问题。例如,不同组件之间的功能冲突。我们认为目标检测任务和目标再识别任务所需要的特征是完全不同的。用于目标检测任务的特征需要高层特征来识别目标属于哪个类别,而用于再识别任务的特征则需要更多的低层特征来区分同一类别的不同实例。因此,JDE中的共享特征模型会降低任务的性能。然而,正如我们前面提到的JDE的缺点,SDE可以克服这些缺点,在MOT方面仍然有很好的潜力。
近年来,基于注意力机制[24]的Transformer[24]被引入计算机视觉领域,并取得了优异的效果。在MOT问题中,大多数基于transformer的方法使用CNN + transformer框架。这意味着该模型首先通过CNN架构提取输入的图像特征,然后将这些特征映射塑造为transformer的输入。与基于检测的跟踪方法不同,基于transformer的跟踪方法通过将检测和数据关联部分结合起来实现跟踪结果。该方法不需要额外的轨迹匹配技术,只需一个模型即可直接输出轨迹的身份和位置。尽管基于transformer的方法在特征注意力方面取得了突出的结果,但在将整个图像输入到transformer架构时,其推理速度仍有一定的限制。
为了生成高质量的检测结果和目标外观,采用TBD模型SDE来解决JDE中存在的特征冲突问题。然而,大多数特征描述子不能很好地区分不同物体之间的外观特征。为了解决这个问题,我们提出了SMILEtrack,它结合了一个检测器和一个类似孪生网络的相似性学习模块(SLM)。受视觉transformer[6]的启发,利用SLM中的注意力机制和图像切片机制,创建了一个图像切片注意力块(ISA)。此外,我们创建了一个相似性匹配级联SMC,用于匹配视频中每个帧之间的对象。该系统的大致过程如下:首先,利用PRB[4]检测器预测目标边界框位置;在获得对象边界框后,我们通过SMC将边界框与轨迹关联。
我们的工作贡献总结如下:
-
提出了一个单独的检测和嵌入模型,名为SMILEtrack,以及相似性学习模块(SLM),该模块使用类似孪生网络的架构来学习每个对象之间的相似性。
-
针对SLM中的特征提取部分,构建了图像切片注意力块(Image Slicing Attention Block, ISA),利用图像切片方法和transformer的注意力机制来学习物体特征。
-
为了完成轨迹匹配部分,我们建立了相似匹配级联(SMC)来关联每帧中的每个边界框。
2 相关工作
2.1 Tracking-by-Detection
基于tbd的算法已经在MOT问题中取得了相当大的成功,是MOT框架中最流行的算法。TBD方法的主要任务是将视频中各帧之间的检测结果关联起来,完成多目标检测系统。整个工作大致可以分为两部分。
2.1.1 检测方法
Faster R-CNN[18]是一个两级检测器;它使用VGG-16作为骨干,即区域建议网络(RPN)来检测边界框。SSD[11]使用锚机制代替RPN;在每个特征图上设置不同大小的锚点以提高检测质量。YOLO系列[15][16][17][2]是一种利用特征金字塔网络(feature pyramid network, FPN)解决目标检测中的多尺度问题的单阶段方法,在速度和精度上都具有突出的性能。虽然基于锚点的检测器可以取得很好的性能,但仍然存在一些由锚点引起的问题。例如,基于锚点的检测器难以按情况调整锚点的某些超参数,并且在训练部分计算锚点的交并比(IOU)需要大量的时间和内存。为了克服这些问题,无锚点检测器是另一种选择。角网络[9]是一种无锚点的方法;它利用热图和角池化而不是锚点来预测目标的左上角和右下角,然后匹配这两个点来生成对象的边界框。与CornerNet相比,CenterNet[34]通过中心池化和级联角点池化直接预测目标的中心点。YOLOX将YOLO系列从基于锚点的检测器转变为无锚点检测器。同时,采用解耦头来提高检测的准确性。
2.1.2 数据关联方法
在MOT系统中,需要解决物体遮挡、场景拥挤、运动模糊等问题。因此,需要仔细对待数据关联的方法。SORT[1]算法首先根据目标在当前帧的位置利用卡尔曼滤波器预测目标的未来位置,然后通过计算现有目标检测框与预测边界框之间的IOU距离生成分配代价矩阵。最后利用匈牙利算法匹配赋值代价矩阵。SORT算法虽然具有较快的推理速度,但由于它不关心目标的外观信息,因此无法处理长期遮挡问题或快速运动的目标。
为了解决遮挡问题,Deep SORT[27]应用预训练的CNN模型提取目标的边界框外观特征,然后利用外观特征计算目标轨迹与待检测目标之间的相似度。最后采用匈牙利算法完成分配。这种方法可以有效地减少ID开关的数量,但在深度排序中检测模型和特征提取模型是分离的,导致推理速度远不能达到实时性。针对这一问题,JDE[26]将检测器和嵌入模型结合在一个one-shot网络中,可以实时运行,且与两阶段方法的精度相当。FairMOT[32]展示了锚点带来的不公平性,采用基于CenterNet的无锚点方法,在MOT17[14]等多个数据集上取得了较大的性能提升。然而,JDE模型存在构件间特性冲突等问题。
而[21]和[22]算法则摒弃了目标外观特征,仅利用高性能的检测器和运动信息完成跟踪。尽管这些方法可以在MOTChallenge基准中达到最先进的性能和高推理速度,但我们认为,这部分是由于MOTChallenge基准数据集中运动模式的简单性。此外,在较拥挤的场景中,未参考目标外观特征会导致目标跟踪精度较差。
2.2 Tracking-by-Attention
随着transformer在目标检测方面的成功应用,Trackformer[13]在DETR的基础上,将MOT问题转换为集合预测问题,并增加了目标查询和自回归轨迹查询用于目标跟踪。TransTrack[23]基于可变形DETR构建,具有两个解码器,一个用于当前帧检测,另一个用于前一帧检测。通过匹配两个解码器之间的检测框来完成跟踪问题。TransCenter[29]是一种基于点的跟踪,为利用transformer的MOT提出了一个具有多尺度输入图像的密集查询特征图。
3 方法
在本节中,我们将介绍SMILEtrack模型的细节,包括相似性学习模块(SLM)和用于每帧框关联的相似性匹配级联(SMC)。
3.1 体系结构概述
图2描述了SMILEtrack的整体架构。我们的框架可以分为以下步骤。(1)检测物体位置:为了定位目标物体的位置,我们采用PRB作为检测器。(2)数据关联:MOT问题是通过关联相邻帧中的每个对象来实现的。在得到PRB[4]生成的检测结果后,计算每一帧之间的运动相似度矩阵和外观相似度矩阵,并将这两个矩阵的代价矩阵结合到匈牙利算法中求解线性分配问题。
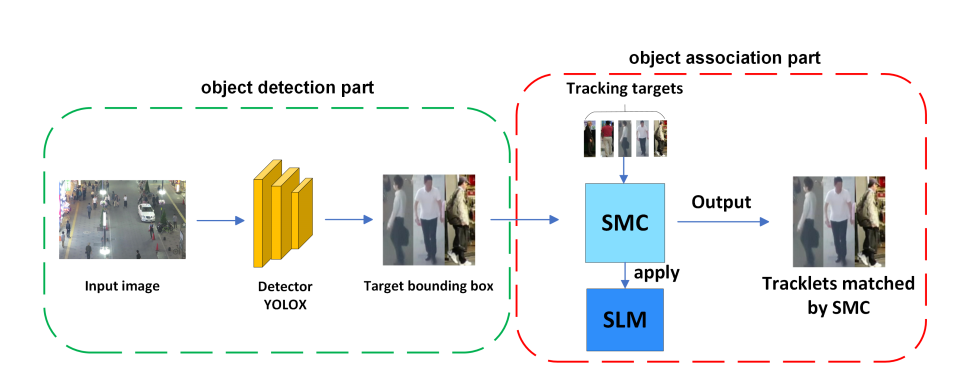
图2 SMILEtrack架构由两部分组成:(1)目标检测和(2)目标关联。
## 3.2. 相似度学习模块(SLM)用于Re-ID
为了达到鲁棒的跟踪质量,目标的外观信息是必不可少的。许多跟踪方法都考虑了目标的外观信息。例如,DeepSORT应用由简单CNN构建的深度外观描述符来提取目标外观特征。虽然外观描述子可以提取有用的外观特征,但我们抱怨外观描述子不能很好地区分不同物体之间的外观特征。为了提取更具判别力的外观特征,提出了一种类似孪生网络架构的相似性学习模块SLM。SLM的细节如图3所示。
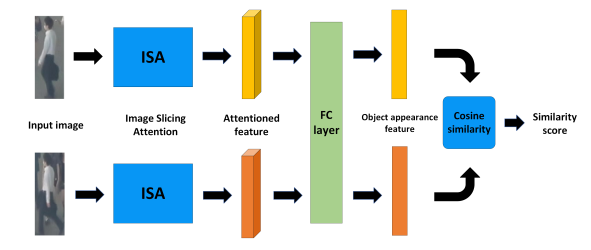
图3 相似度学习模块SLM的完整架构。
对于SLM的输入,我们将两幅不同的图像同时放入SLM中。它们都将通过 3.2.1节中的ISA特征提取器,该特征提取器在两个图像之间共享参数。稍后将更详细地介绍ISA的体系结构。在提取输入图像的特征后,使用全连接层对特征进行集成。为了学习一种鲁棒的能够区分不同目标的外观特征,采用余弦相似度距离计算两幅图像之间的相似度。相同对象之间的相似度分数应该尽可能高;否则,不同对象之间的相似度分数应该接近于零。
3.2.1图像切片注意(ISA)块
为了产生可靠的外观特征,一个优秀的特征提取器是必不可少的。虽然变压器在特征增强方面表现突出,但我们认为在跟踪系统中加入完整的编码器-解码器架构对于模型计算和参数大小来说过于繁重。受VIT的启发,我们构建了一个ISA,该ISA应用了图像切片技术和特征提取的注意机制。ISA的详细体系结构如图4所示。
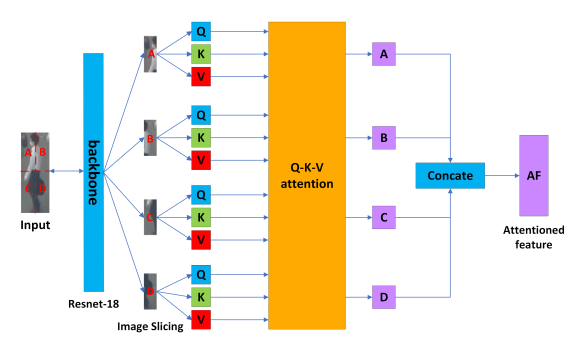
图4 完整的图像切片注意力块架构—ISA。对输入图像应用图像切片,我们将其划分为左上角部分,右上角部分,左下角部分,右下角部分。
3.2.2图像切片 基本的transformer接收一个一维向量作为编码器的输入。对于二维图像,直接将整个图像作为输入将增加计算复杂度。一种实用的方法是对图像进行切片。为了准备Q-K-V注意力块[24]的输入,我们首先通过检测器生成物体的边界框。由于每个边界框具有不同的尺度,我们将它们调整为固定大小 $B \in R^{w \times n}$ ,其中(w;H)为区域提案的宽度和高度。注意,在训练MOT数据集时,我们设置$w = 80, h = 224$。为了生成缩放边界框的特征图,我们应用骨干Resnet-18[8]来提取特征。在获得边界框的特征映射后,我们将其划分为大小为$s \times t$的切片 $S_{i} \in R^{n \times s \times t}$ ,其中n = 4是切片的数量。此外,我们向每个切片添加一个一维位置嵌入$E_{P}$。每个切片可以表示为以下等式: $$ S_{i}=S_{i}+E_{P}, \quad i=A, B, C, D, \quad E_{P}=1,2,3,4 \tag{1} $$
最后,将特征切片序列 S = {SA ∼SD } S= \left\{S_{A} \sim S_{D}\right\} S={SA∼SD}作为注意力块的输入。
3.2.3 Q-K-V注意力块
标准transformer擅长处理序列之间的长期复杂依赖关系,如自然语言处理。transformer中最重要的部分是注意力块。transformer通过将查询打包到矩阵Q中来计算注意力函数,也将键和值打包到矩阵K和v中。注意力块的计算表示为
Attention ( Q , K , V ) = softmax ( Q K T d k ) V (2) \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V \tag{2} Attention(Q,K,V)=softmax(dkQKT)V(2)
其中 d k d_k dk为关键向量的维数。为了为注意力块生成查询、键和值,我们为图像切片产生的每个切片应用一个接一个的全连接层。每个切片在通过Q-K-V注意力块后都有一个输出 S i S_i Si。我们通过Q-K-V注意力块将每个切片 S = {SA ∼SD } S= \left\{S_{A} \sim S_{D}\right\} S={SA∼SD}的输出表示为以下等式:
S A = S A( Q S 1, K S 1, V S 1) + C A( Q S 1, K S 2, V S 2) + C A( Q S 1, K S 3, V S 3) + C A( Q S 1, K S 4, V S 4) S B = S A( Q S 2, K S 2, V S 2) + C A( Q S 2, K S 1, V S 1) + C A( Q S 2, K S 3, V S 3) + C A( Q S 2, K S 4, V S 4) S C = S A( Q S 3, K S 3, V S 3) + C A( Q S 3, K S 1, V S 1) + C A( Q S 3, K S 2, V S 2) + C A( Q S 3, K S 4, V S 4) S D = S A( Q S 4, K S 4, V S 4) + C A( Q S 4, K S 1, V S 1) + C A( Q S 4, K S 2, V S 2) + C A( Q S 4, K S 3, V S 3) (3) \begin{aligned} S_{A} & =S A\left(Q_{S 1}, K_{S 1}, V_{S 1}\right)+C A\left(Q_{S 1}, K_{S 2}, V_{S 2}\right) \\ & +C A\left(Q_{S 1}, K_{S 3}, V_{S 3}\right)+C A\left(Q_{S 1}, K_{S 4}, V_{S 4}\right) \\ S_{B} & =S A\left(Q_{S 2}, K_{S 2}, V_{S 2}\right)+C A\left(Q_{S 2}, K_{S 1}, V_{S 1}\right) \\ & +C A\left(Q_{S 2}, K_{S 3}, V_{S 3}\right)+C A\left(Q_{S 2}, K_{S 4}, V_{S 4}\right) \\ S_{C} & =S A\left(Q_{S 3}, K_{S 3}, V_{S 3}\right)+C A\left(Q_{S 3}, K_{S 1}, V_{S 1}\right) \\ & +C A\left(Q_{S 3}, K_{S 2}, V_{S 2}\right)+C A\left(Q_{S 3}, K_{S 4}, V_{S 4}\right) \\ S_{D} & =S A\left(Q_{S 4}, K_{S 4}, V_{S 4}\right)+C A\left(Q_{S 4}, K_{S 1}, V_{S 1}\right) \\ & +C A\left(Q_{S 4}, K_{S 2}, V_{S 2}\right)+C A\left(Q_{S 4}, K_{S 3}, V_{S 3}\right) \end{aligned} \tag{3} SASBSCSD=SA(QS1,KS1,VS1)+CA(QS1,KS2,VS2)+CA(QS1,KS3,VS3)+CA(QS1,KS4,VS4)=SA(QS2,KS2,VS2)+CA(QS2,KS1,VS1)+CA(QS2,KS3,VS3)+CA(QS2,KS4,VS4)=SA(QS3,KS3,VS3)+CA(QS3,KS1,VS1)+CA(QS3,KS2,VS2)+CA(QS3,KS4,VS4)=SA(QS4,KS4,VS4)+CA(QS4,KS1,VS1)+CA(QS4,KS2,VS2)+CA(QS4,KS3,VS3)(3)
其中 QSi Q_{S i} QSi是由 S i S_{i} Si得到的查询矩阵, KSi K_{S i} KSi是由 S i S_{i} Si得到的关键矩阵, VSi V_{S i} VSi是由 S i S_{i} Si得到的值矩阵。SA是自我注意力。CA是交叉注意力(Cross-Attention)。自注意力和交叉注意力的计算均如公式2所示。在得到特征 S = {S1 ∼S4 } S=\left\{S_{1} \sim S_{4}\right\} S={S1∼S4}后,我们使用concatenate机制将它们融合,以保留输入图像的特征。
3.3 基于相似匹配级联(SMC)的目标跟踪算法
目标关联是基于检测的跟踪范式方法的关键部分。对于匹配部分,选择不同的策略会得到完全不同的结果。ByteTrack是一种简单有效的关联方法。它保留每个检测框并将其分为高置信度和低置信度,然后将它们与IOU距离相关联。尽管ByteTrack在MOT中达到了最先进的性能,但我们认为,这在一定程度上是因为MOTChallenge基准数据集中运动模式的简单性。在关联部分仅使用IOU距离信息仍存在一些问题,如当目标越来越接近时,会出现id切换问题。为了解决这个问题,我们结合ByteTrack和SLM的优势,设计了一种变体关联方法。我们方法的匹配流水线如图5所示,关联方法的伪代码在补充中显示。
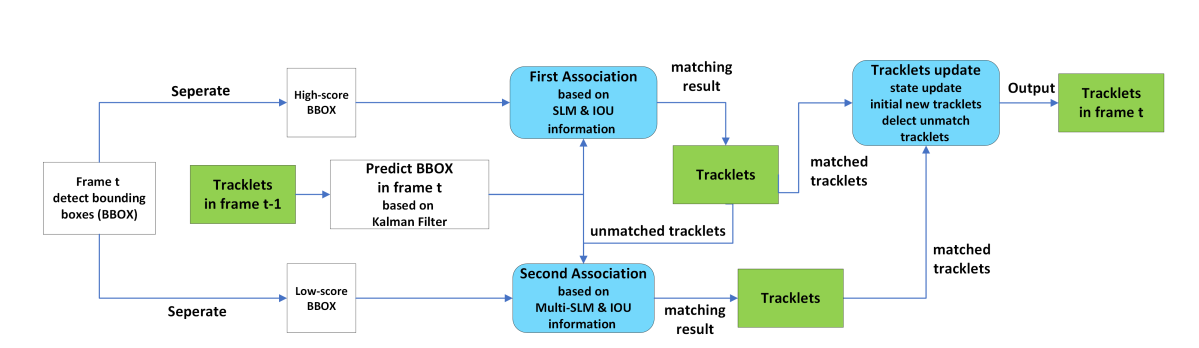
图5 相似匹配级联(SMC)的流程图
首先确定当前帧中所有的检测框,并根据阈值将其划分为$D_{high}$集和$D_{low}$集;对于thres值的设置,我们将deti中的检测d按照得分由低到高重新排列,然后计算deti中前半部分d的得分均值,并将得分均值设置为thres。得到阈值thres后,将得分高于thres的检测框放入$D_{high}$,将得分在thres到0.1之间的检测框放入$D_{low}$。将得分低于0.1的检测框视为背景或噪声。在分离检测框后,将丢失的目标列表LL融合到跟踪列表TL中,并在TL中使用卡尔曼滤波器预测每个目标在当前帧的位置。
(第一阶段)在第一关联阶段,我们首先关注 Dhigh D_{high} Dhigh集。计算 Dhigh D_{high} Dhigh和TL的运动矩阵 M m M_m Mm和外观相似度矩阵 M a M_a Ma。对于运动矩阵 M m M_m Mm,计算TL和 Dhigh D_{high} Dhigh之间的IOU距离。对于外观相似度矩阵 M a M_a Ma,采用SLM算法进行计算。然后,我们通过门函数将矩阵 M m M_m Mm和 M a M_a Ma融合为代价矩阵 Chigh C_{high} Chigh:
C high = M m ( i , j ) − ( 1 − M a ( i , j ) ) (4) C_{\text {high }}=M_{m}(i, j)-\left(1-M_{a}(i, j)\right) \tag{4} Chigh =Mm(i,j)−(1−Ma(i,j))(4)
M m ( i , j ) M_{m}(i, j) Mm(i,j)为第 i i i个轨迹波与第 j j j个检测之间的IOU距离, M a ( i , j ) M_{a}(i, j) Ma(i,j)为第i个轨迹波与SLM生成的第j个检测之间的特征相似度。最后,在第一阶段匹配中利用代价矩阵 Chigh C_{high} Chigh的匈牙利算法完成线性赋值。将 Dhigh D_{high} Dhigh的不匹配检测和TL的不匹配航迹放入 DRemain D_{Remain} DRemain和 T LRemain TL_{Remain} TLRemain中。
(第二阶段)在第二个匹配阶段,我们匹配 Dlow D_{low} Dlow和 T LRemain TL_{Remain} TLRemain。计算 Dlow D_{low} Dlow和 T LRemain TL_{Remain} TLRemain的运动矩阵 M m M_m Mm与第一个匹配阶段相同。对于外观相似度矩阵 M a M_a Ma,构建了一个多模板SLM,用于学习低分检测与轨迹之间的相似性。在进行低分检测时,由于低分检测对象特征不同于因遮挡而产生的轨迹特征,直接利用上一帧的轨迹特征进行相似度计算可能会得到不可靠的分数。为了解决这个问题,本文采用了一种特征库机制来保存曲目在不同帧中的各种特征。第i个轨迹的特征库 F i F_i Fi与得分较低的第j个检测的相似度得分计算为:
M a ( i , j ) = max { S L M ( f i , d j ) ∣ for all f i ∈ F i } (5) M_{a}(i, j)=\max \left\{S L M(f i, d j) \mid \text { for all } f_{i} \in F_{i}\right\} \tag{5} Ma(i,j)=max{SLM(fi,dj)∣ for all fi∈Fi}(5)
在得到矩阵 M m M_m Mm和 M a M_a Ma后,通过融合与第1阶段相同的矩阵 M m M_m Mm和 M a M_a Ma生成代价矩阵 Clow C_{low} Clow,并利用代价矩阵 Clow C_{low} Clow利用匈牙利算法完成线性赋值。将#D_{low} 的不匹配检测和 的不匹配检测和 的不匹配检测和TL_{Remain的不匹配航迹放入 DRRemain D_{RRemain} DRRemain和 T LRRemain TL_{RRemain} TLRRemain中。
在对象关联阶段结束后,我们设置阈值H来初始化新轨迹。 DRemain D_{Remain} DRemain中分数高于H的未匹配航迹可以初始化一个新航迹,并将 T LRRemain TL_{RRemain} TLRRemain中未匹配的航迹移动到丢失对象列表LL中。将未匹配的检测片段作为背景。注意,只有当LL中的音轨存在超过30帧时,我们才删除LL中的音轨。
4、实验结果
4.1 数据集
在MOTChallenge[14]基准上进行了实验。具体地,在MOT17[14]测试集上按照“私有检测”协议进行评估。MOT17是MOTChallenge中最受欢迎的数据集。它包含14个视频序列(7个序列用于训练,另外7个序列用于测试),包括移动和静态摄像机。
其他常见的MOT数据集包括ETH [19], CalTech [5], MOT16 [14], CityPerson [31], CrowdHuman [20], ETHZ [7], CUHK-SYSU[28]和PRW[33]。ETH、MOT16和CityPerson数据集仅为训练检测模型提供边界框注释;因此,训练re-ID和MOT模型需要额外的数据集。CalTech、PRW和CUHKSYSU数据集为训练re-ID模型提供了边界框位置和身份注释。
在MOT17训练集、CrowdHuman、ETHZ和Cityperson的组合上训练SMILEtrack。对于消融研究,我们使用训练集的前半部分进行模型训练,另一半用于验证。从MOT17视频序列中裁剪行人图像用于训练SLM re-ID模型。
4.2、MOT评价指标
标准的多目标跟踪评价指标包括多目标跟踪精度(MOTA)、多目标跟踪精度(MOTP)、身份F1分数(IDF1)、大部分被跟踪(MT)、大部分丢失(ML)、假正率(FP)、假负率(FN)、ID精确率(IDP)和ID切换(IDs)。其中,MOTA和IDF1是两个最常用的指标。MOTA与IDF1的计算公式如式6和式7所示
M O T A = 1 − ∑ t ( F N t + F P t + I D S W t ) ∑ t G T t (6) M O T A=1-\frac{\sum_{t}\left(F N_{t}+F P_{t}+I D S W_{t}\right)}{\sum_{t} G T_{t}} \tag{6} MOTA=1−∑tGTt∑t(FNt+FPt+IDSWt)(6)
I D F 1 = 2 I D T P 2 I D T P + I D F P + I D F N (7) I D F_{1}=\frac{2 I D T P}{2 I D T P+I D F P+I D F N} \tag{7} IDF1=2IDTP+IDFP+IDFN2IDTP(7)
MOTA是FP、FN和IDs的结合,体现了检测性能。相比之下,IDF1算法更关注身份匹配能力和数据关联性能。
4.3、实现细节
我们在COCO[10]数据集上训练PRB[4]检测器用于权重的初始化;该模型在MOT16和MOT17数据集上进行了微调,以提高行人检测性能。在训练过程中应用了多种数据增强方法,包括Mosaic[2]和Mixup[30]。
为了对MOT17进行评估,在MOT17训练集、CrowdHuman、ETHZ和Cityperson的组合上对PRB进行了100个epoch的训练。输入图像的大小为1440 × 800。我们选择SGD优化器,并将初始学习率设置为10−3,使用余弦退火调度。
为了训练SLM,我们在自己的数据集上训练,这些数据集是从MOT17训练集中裁剪出来的。由于从MOT17裁剪出来的每个行人都有不同的尺寸,我们将行人的尺寸调整为固定的224 × 80。我们选择优化器SGD,学习率初始为6.5 × 10−3的余弦退火计划。我们使用MSE[3]损失进行150次训练。
对于SMC中提出的门函数,我们将阈值 ε \varepsilon ε设置为0.7来过滤代价矩阵。在线性分配阶段,剔除代价矩阵大于0.2的航迹匹配;对于初始的新对象,阈值H设置为0.7以过滤检测。对于multi-template-SLM中使用的每个目标的特征库,我们将特征库的大小设置为能够存储50帧外观。此外,将特征库分为高分模板和低分模板两类。对于置信度较高的检测结果,将检测结果的外观特征存储到高分模板中;否则,将低置信度检测的外观特征放入低评分模板中。
4.4. 评价结果
表1展示了基于MOTChallenge的“私有检测器”协议,SMILEtrack在MOT17测试集上与当前最先进的跟踪器的评估结果。所有结果都是使用MOTChallenge官方评估网站生成的。SMILEtrack取得了80.3 MOTA和77.3 IDF1的优异成绩。使用消融研究的最佳结果作为MOT17评估的模型设置。将被跟踪目标的SLM相似特征维数设置为256。利用IOU和外观信息计算两个SMC匹配阶段的相似度矩阵。采用门函数融合IOU和外观信息,采用多模板slm解决检测得分低的问题。
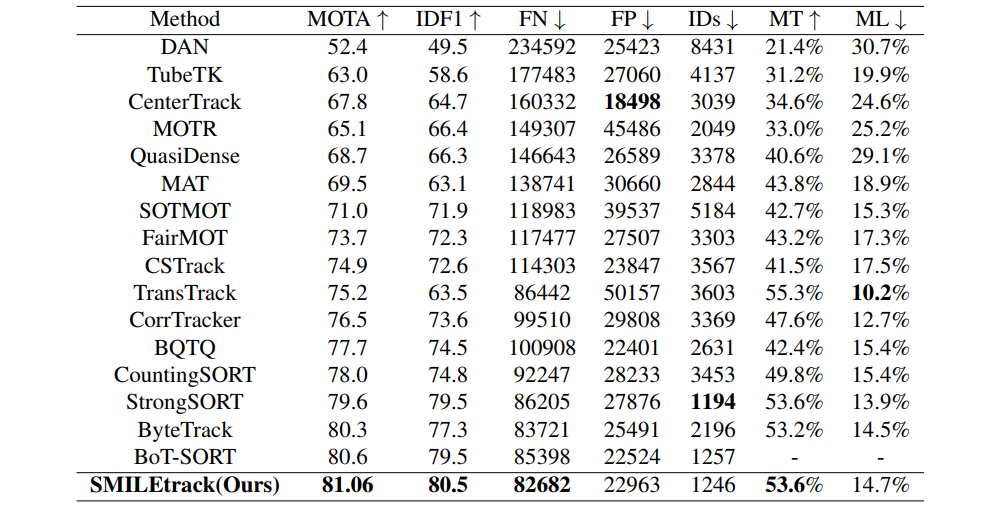
表1 在MOT17[14]测试集上与“私有检测器”协议下的最新方法进行对比。
## 4.5. 消融实验
使用来自MOT17验证集和CrowdHuman数据集组合训练的相同权重进行消融研究。这确保了公平性,并防止了检测器方差的影响。
4.5.1、相似特征维度
在表示行人时特征维度的选择(即SLM中目标外观尺寸)会极大地影响MOT的精度,并且检测特征和重识别特征的设置是不一样的。在检测时,由于目标检测需要丰富的高层特征,因此通常希望特征维数较大。相比之下,re-ID特征需要更多的低层外观特征来区分候选者。
我们在SLM中测试了不同的物体外观尺寸,结果如表2所示。观察发现,特征维度为64时,MOTA和IDs表现最佳,而特征维度为128时,IDF1表现最佳。我们发现,随着特征维度的降低,MOTA和IDs的性能会提高。我们在SLM中选择128维作为目标外观尺寸,以最大化MOTChallenge的整体性能。

表2 关于特征尺寸的性能。
4.5.2、相似度矩阵
在数据关联中,目标与轨迹的相似度矩阵是目标匹配的关键因素。大多数方法选择IOU信息或外观信息作为相似度矩阵。在我们的SMC中,主要的关联包括两个阶段。在阶段I和阶段II中,我们评估了IOU信息或外观信息的组合来构建相似度矩阵。结果如表4所示。注意,SLM表示对象的外观信息。IOU信息和appearance信息的组合如下式:
S i m i l a r i t y m a t r i x = α ⋅ I O U + ( 1 − α ) ⋅ S L M (8) Similarity matrix =\alpha \cdot I O U+(1-\alpha) \cdot S L M \tag{8} Similaritymatrix=α⋅IOU+(1−α)⋅SLM(8)
其中权重参数 α \alpha α被设置为0.5。
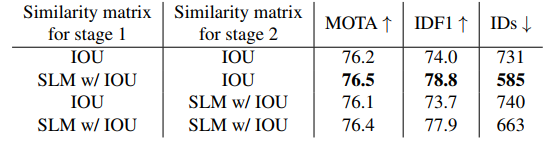
表4 第一阶段和第二阶段不同策略的比较 MOT17验证集。
相比于表4中第1行和第2行,阶段1中结合IOU信息和外观信息的相似度矩阵在仅使用IOU信息的情况下获得了更高的MOTA和IDF1。注意,在第1行和第3行中,使用低分数检测框上的外观信息会导致较低的MOTA和IDF1。原因是低分数检测框通常包含一些遮挡或运动模糊,使外观信息不可靠。在表4中,第一阶段同时使用IOU和appearance,而第二阶段仅使用IOU可以得到最好的结果。

表3 针对不同策略在MOT17验证集上的消融研究。
4.5.3、 使用gate函数和多模板slm进行外观匹配
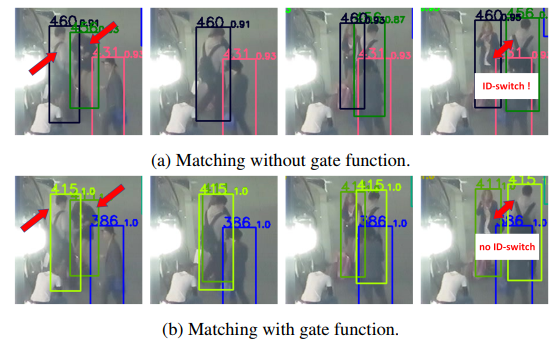
图6 不同IOU和外观信息融合策略的比较。每个边界框左上角的数字表示目标ID。当两个目标越接近且IOU分数高于外观分数时,使用IOU和外观信息的共同加权和可能会导致id切换问题。我们提出的门函数可以防止id切换问题的发生。
我们对门函数和多模板- slm进行了消融研究。表3显示了结果。IOU和外观是进行匹配的有效信息。大多数方法通过公式(8)将IOU和外观信息结合起来。当行人的IOU评分远远高于行人之间的外观相似度评分时,这种方法可能会产生问题。针对这一问题,提出门函数来拒绝外观相似度低于 = 0:7的目标匹配,即使它们具有较高的IOU分数。针对低分数检测框中特征不可靠的问题,采用多模板lm机制,利用特征库来存储目标的不同外观。在匹配部分采用了Gate函数和多模板slm算法。对于相似度矩阵,我们同时使用阶段1和阶段2的IOU信息和外观信息。最佳性能是将Gate函数应用于阶段I和II,将Multi-template-SLM应用于阶段2。我们在图6中展示了MOT17-04-FRCNN视频的一些可视化结果。我们发现使用IOU和外观信息的共同加权和会导致我们在图6中提到的情况出现问题。然而,应用Gate函数融合IOU和外观信息可以克服这个问题。
5、结论
本文提出SMILEtrack,一种类似孪生网络的架构,可以有效地学习目标外观,用于单摄像头多目标跟踪。本文提出了一种相似性匹配级联(SMC)方法,用于每帧中的边界框关联。实验表明,SMILEtrack在MOT17上取得了较高的MOTA、IDF1和IDs性能分数。
未来的工作。由于SMILEtrack是一个独立的检测和嵌入(SDE)方法,因此它的运行速度比联合检测和嵌入(JDE)方法慢。未来,我们将研究可以改善MOT时间与精度权衡的方法。

