字符函数和字符串函数详解(2)
文章目录
- 前言
- 一、字符串查找
- 1.1 strstr
- 1.2 strtok
- 二、错误信息报告
- 2.1 strerror
- 三、字符操作
- 四、内存操作函数
- 4.1 memcpy
- 4.2 memmove
- 4.3 memcmp
- 4.4 memset
- 总结
前言
大家好,我是耶鲁,上篇文章我们讲解到了字符函数和字符串函数(1)。如果还没有看过的同学,建议先阅读第一部分之后再来看本篇内容,确保知识的连贯性,![]() 点我。本篇我将把余下的内容逐一呈现。依旧是干货满满,希望兄弟们多多支持!有任何问题都可以随时反馈给我,废话不多说开干!
点我。本篇我将把余下的内容逐一呈现。依旧是干货满满,希望兄弟们多多支持!有任何问题都可以随时反馈给我,废话不多说开干!
一、字符串查找
1.1 strstr
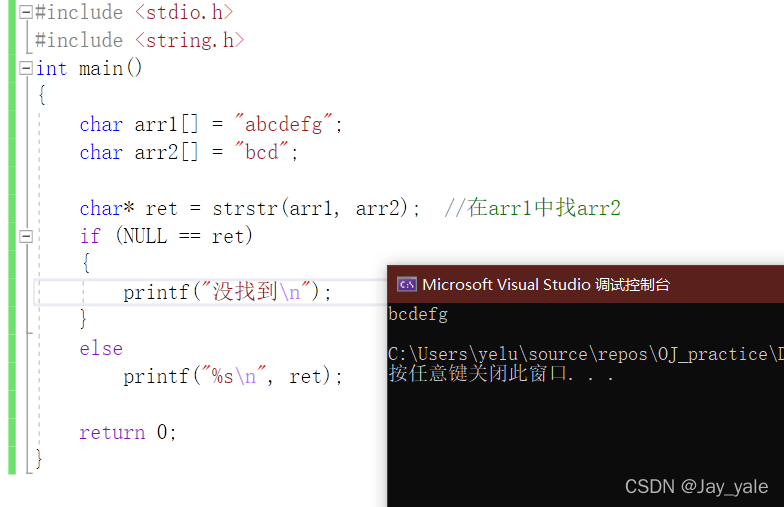
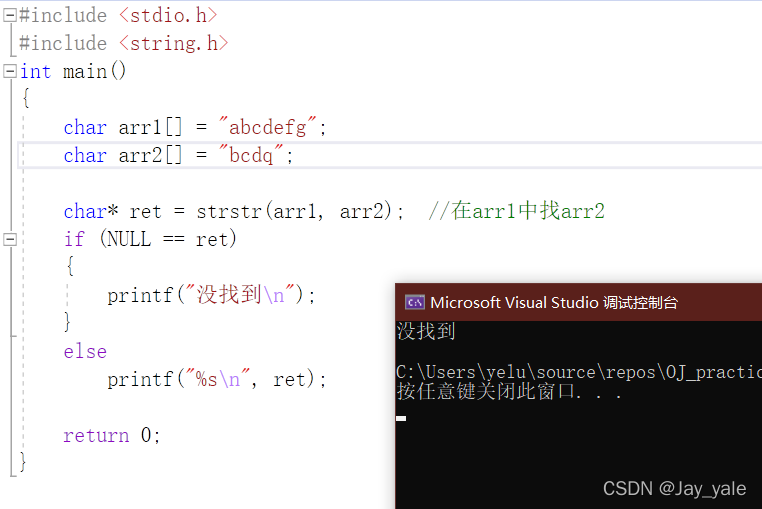
strstr(str1,str2)函数用于判断字符串str2是否是str1的子串,如果是,则函数返回str1字符串从str2第一次出现的位置开始到str1结尾的字符串;否则,则返回NULL。
函数原型:char* strstr(const char* str1, const char* str2);strstr返回的是一个指针,指向str2在str1中首次出现的位置。
示例代码:
strstr的模拟实现:
#include #include char* my_strstr(const char* str1, const char* str2){const char* s1 = str1;//替代str1进行查找const char* s2 = str2; //替代str2进行查找const char* cur = str1; //记录每一次查找的位置if (*str2 == '\0') {return (char*)str1; //如果刚开始*str2就为'\0',则返回str1}while (*cur){s1 = cur; //使s1每一次查找都能从cur记录的位置开始s2 = str2;//每一次从头开始while (*s1 && *s2 && *s1 == *s2){s1++;s2++;}if (*s2 == '\0') //当*s2为'\0',说明已经查找出来了return (char*)cur;cur++; //此时没找到,就换下一个位置,直至找到}return NULL;//如果最终没有找到,则返回NULL}int main(){char arr1[] = "abbcdefg";char arr2[] = "bbc";char* ret = my_strstr(arr1, arr2); //在arr1中找arr2if (NULL == ret){printf("没找到\n");}elseprintf("%s\n", ret);return 0;}代码运行结果如下:
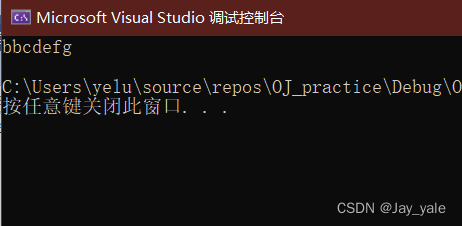
分析:str1和str2总是记录两个字符串的起始位置,s1得到了str1的起始位置s2,s2得到了str2的起始位置,cur得到了str1的起始位置。经过分析,发现只用str1和str2是完成不了太过于复杂的操作。接着当str2不等于’\0’时,跳出if语句。当前*cur是a,为真,进入while循环。再把cur和str2分别赋给s1和s2。*s1此时为a,*s2此时为b,进入while循环不满足第三个条件,为假。执行if语句,*s2不等于’\0’,为假,跳出循环。执行cur++。cur现在指向b。再往下执行两条赋值语句,得到*s1为b,*s2为b。满足条件进入第二个while循环,执行两条自增语句,使s1指向第二个b,s2指向第二个b。满足条件,再执行一次while循环。s1指向了c的位置,s2也指向了c的位置,条件还是满足,又一次执行循环。现在s1指向了d的位置,而s2指向了'\0’,不满足while循环条件,跳出循环。紧接着执行if语句,*s2目前为'\0’,条件成立,返回cur。至此才完成我们想要的结果!
1.2 strtok
函数原型:char* strtok(char* str, const char* sep);
以下面这句代码为例,我逐一地来用通俗的语言解释下面的这几段话。
char arr[] = "yelu@year#jay";
1. sep参数是个字符串,定义了用作分隔符的字符集合。
分隔符就是'@', '.'
2. 第一个参数指定了一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
第一个参数指向了"yelu@year#jay"这样的一个字符串。像yelu,year,jay这些是标记(我们也可以理解为这是一个字段),它可以是一个或者是多个,也可能是0个(比如空字符串)。若是多个标记的话,这多个标记会被一个或者多个分隔符分割就如上面那行代码所示,它的三个标记就是被两个分隔符分割的得到的。
3. strtok函数找到str中的下一个标记,并将其用'\0'结尾,返回一个指向这个标记的指针(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容,并且可修改)。
当strtok找到第一个标记后它会怎么做呢?实际上它会把这个分隔符'@'改成'\0',并且它会返回y的地址。你本身是想从这个arr数组中提取这三个字段,但是我们不会拿这个字符数组本身直接操作,我们可以用strcpy把arr拷贝到一个临时的字符数组中,再进行如上操作,并且这个临时数组可以修改其内容,对arr无影响。
4. strtok函数的第一个参数不为NULL,函数将找到str中的第一个标记,strtok函数将保存它在字符串中的位置。
当我们把arr的地址传给它的时候,也就是y的地址,它不为空指针。函数将找到字符串中的第一个标记,也就是“year”,strtok会记住它在字符串中的位置。
5. strtok函数的第一个参数为NULL,函数将在同一个字符。中被保存的位置开始,查找下一个标记。
假如临时拷贝数组传过去的第一个参数为空指针,它会在相同的字符串中被保存的位置开始找下一个标记,也就是它会紧接着向后面找year这个标记。
6. 如果字符串中不存在更多的标记,则返回NULL指针。
如果没有再找到标记了,它就会返回一个空指针。
小总结:
1. strtok函数找到第一个标记的时候,函数的第一个参数不为NULL。
2. strtok函数找非第一个标记的时候,函数的第一个参数是 NULL。
代码示例:
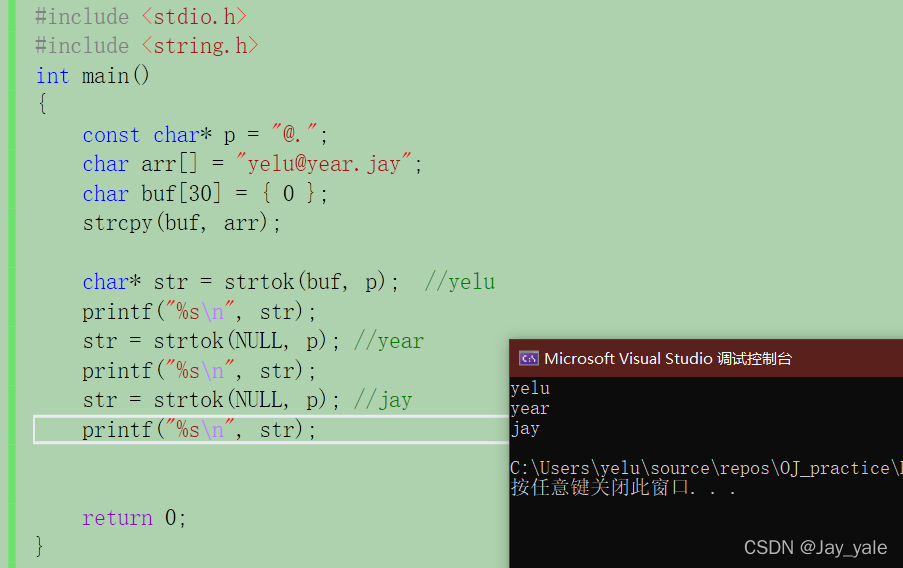
通过代码的调试截图可以验证我上面所说的一些结论是完全符合的。
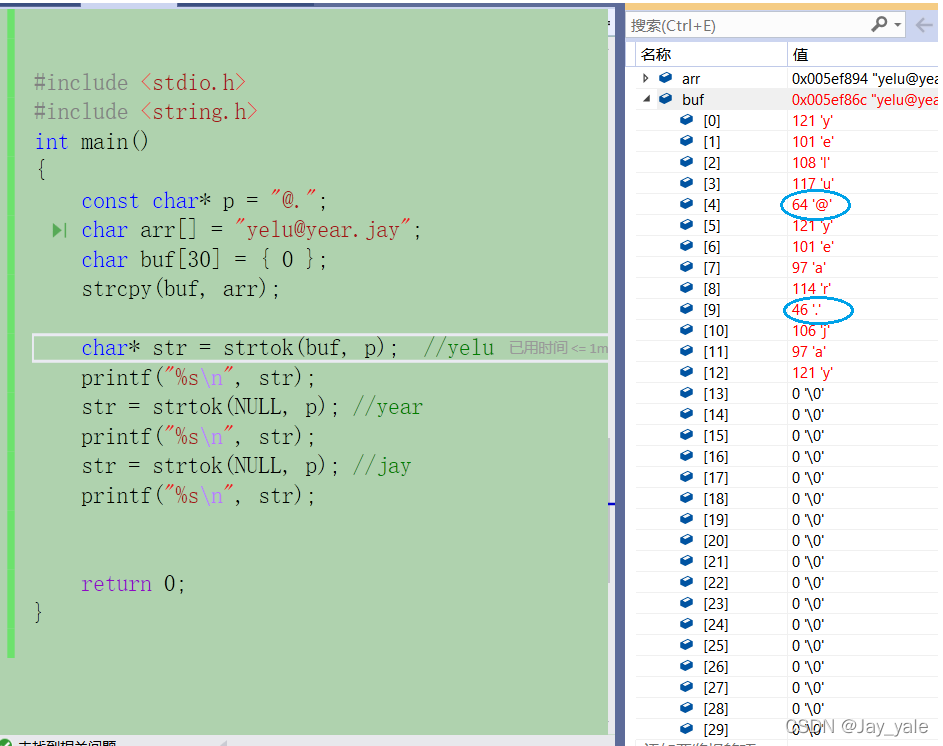
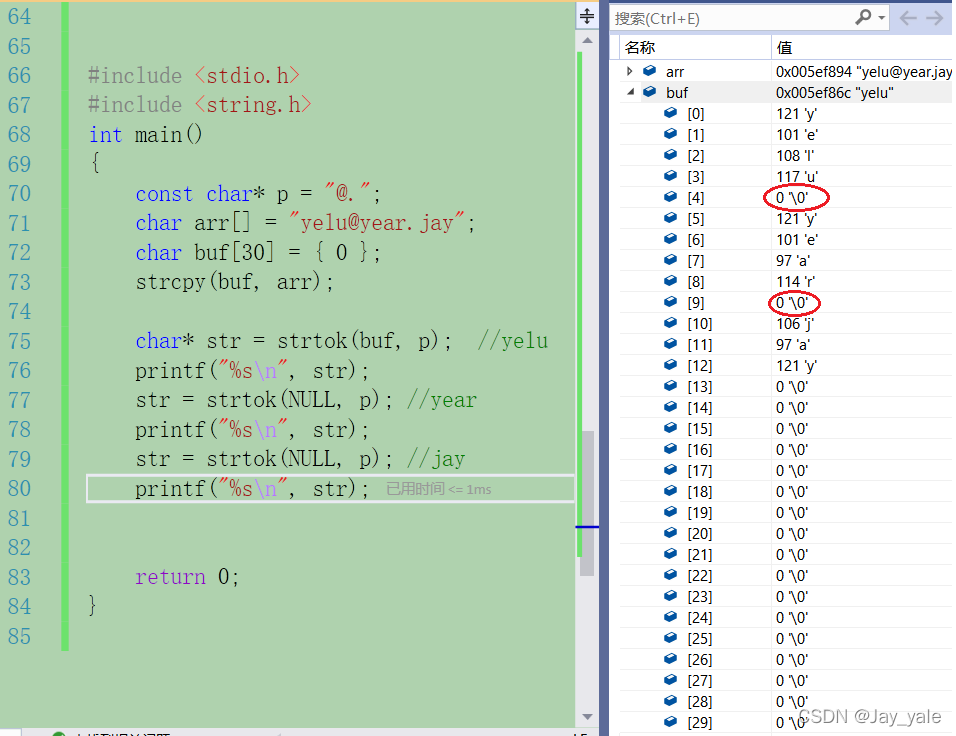
上图的代码是在我们明知道有几个字段的情况下,那如果我们不知道有几个标记,那这种写法就不一定是对的,并且代码较为冗余,所以需要对代码进行优化。
通过上面的我们分析strtok函数实现的过程和特点,我们可以使用for循环,利用for循环语句的特点我们最开始第一步str先初始化,初始化在整个程序中只执行一次,接下来,第二步判断str是否为空指针。第三步,假设str不为空指针,执行打印语句。第四步,重新给str赋值下一个标记地址。此后就在2,3,4这几步循环往复,直至str为空指针,跳出循环,程序结束。
修改代码如下图所示,是不是更加的简洁,巧妙!!
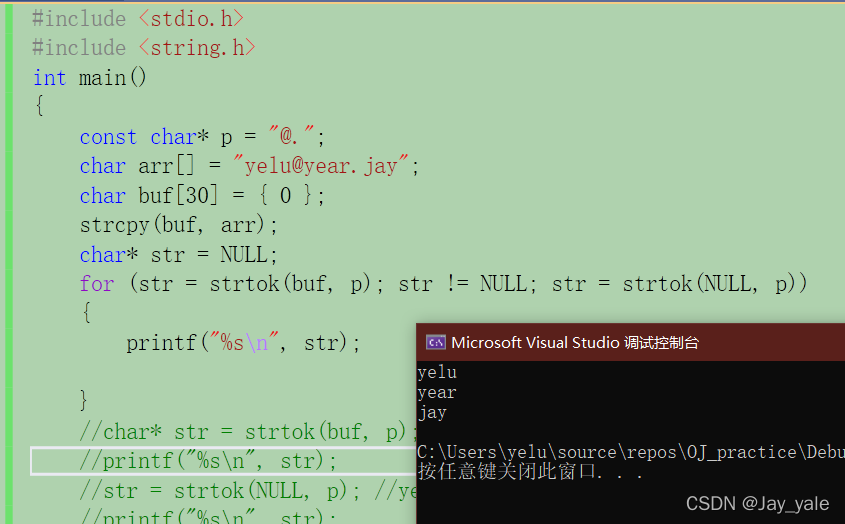
大胆推测一下,我们知道该strtok函数在运行过程中会有记忆功能,但是,对于局部变量来说的话,他出了自己的作用域就会被销毁,不存在记忆功能。而现在出现的记忆功能也就说明,在该函数的实现过程中,应该是在局部变量前面加static变成静态变量或者是全局变量得到的记忆功能,当静态变量和全局变量都可以满足要求的时候,我们应该优先选取静态变量,不选取全局变量。
此函数的模拟实现我就不在此展示了,如果有兴趣的话,根据我上面的分析,相信你也可以尝试着模拟实现一下!
二、错误信息报告
2.1 strerror
C 库函数strerror从内部数组中搜索错误号 errnum,并返回一个指向错误消息字符串的指针。strerror生成的错误字符串取决于开发平台和编译器。
函数原型:char* strerror(int errornum);
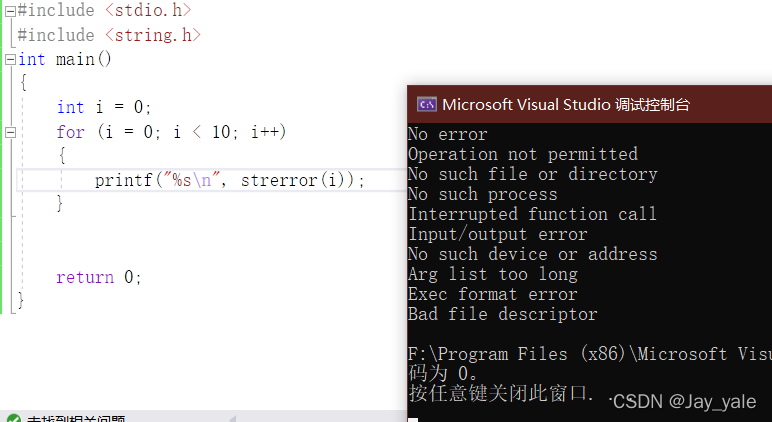
返回错误码所对应的错误信息(注:错误信息是一个常量字符串)。函数返回的是char*,那它返回的char*是什么呢?其实在C语言中规定了一些错误信息,这个错误信息一般有两个部分组成,一部是错误码,错误码会对应着一些错误信息比如:0的错误码对应的错误信息是 No Error(没有错误),2,3,4等一些错误码又代表一种错误信息。如果程序那个地方有问题,编译器返回一个错误码,但是你又没有提前了解出现的错误码所对应的是什么错误信息,这时我们就需要借助strerror这个函数来把出现的错误码进行翻译。char*其实返回的是错误码所对应错误信息的起始地址。
示例代码:
这就是我们利用strerror所翻译出来各个错误码所对应的错误信息。
C语言可以操作文件,打开文件我们会用fopen这个函数。下图是fopen函数的原型。


我去用fopen这个函数去打开我的一个文件,假如我想打开一个test.txt这样一个文件,那以什么样的形式打开呢?
我们通过下图可以看出,它的打开方式大概有以下几种。我们看第一个"r",意思是:read。他下面对应的英文解释大概的意思是:如果这个文件不存在或者没有被找到的话,这个fopen函数会调用失败。

如果遇到错误的话,它会返回一个空指针。

假如我们要找查test.txt这样一个文件,这个文件具体有没有,是看在你的工程路径里面是否存在。当然我们目前里面是没有这个文件的,但是我们还是想读取这个文件,这样程序就会发生错误。其实当库函数使用的时候,发生错误会把errno这个全局的错误变量设置为本次执行库函数产生的错误码。(注:errno是C语言提供的一个全局变量,可以直接使用,放在errno.h头文件中的)。这时我们就可以利用strerror这个函数来翻译错误码所对应的错误信息。
示例代码:
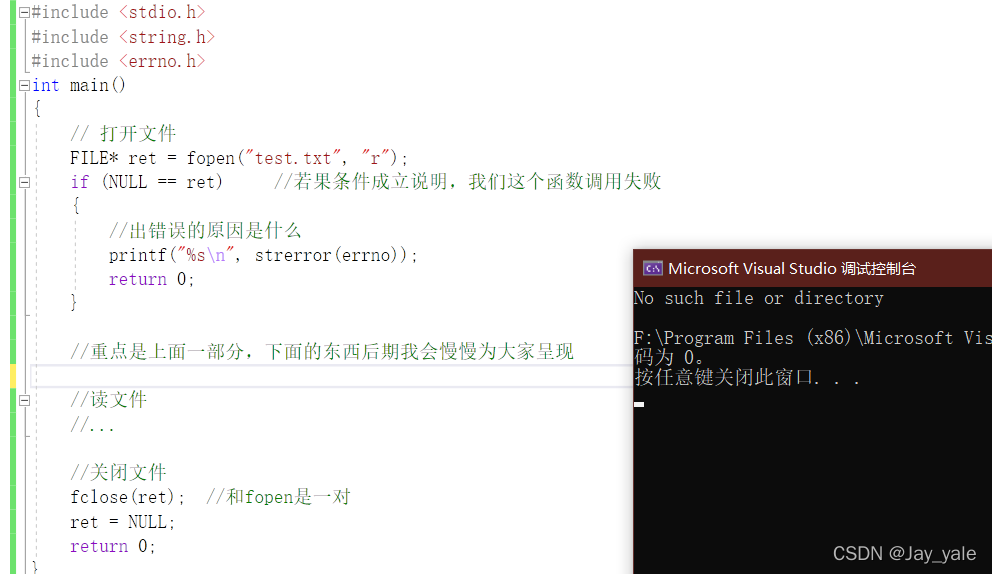
类似的如果以后我们在使用一个函数的时候,如果出现错误,我们就可以用这种方式得知错误的具体原因。
三、字符操作
前面我们学习的都是和字符串相关的函数,现在我们认识一组比较常用的字符分类函数。
字符分类函数:
| 函数 | 如果他的参数符合下列条件就返回真(判断) |
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行'\n',回车‘\r’,制表符'\t'或者垂直制表符'\v' |
| isdigit | 十进制数字 0~9 |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母a~f,大写字母A~F |
| islower | 小写字母a~z |
| isupper | 大写字母A~Z |
| isalpha | 字母a~z或A~Z |
| isalnum | 字母或者数字,a~z,A~Z,0~9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
还有两个字符转换函数 tolower(将大写字母转换为小写字母)和 toupper(将小写字母转化为大写字母)
字符转换:int tolower ( int c );
int toupper ( int c );
示例代码:
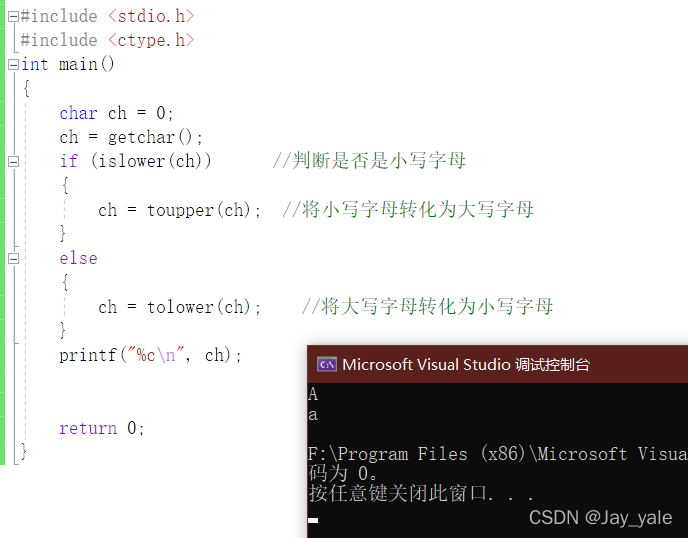
大家如果感兴趣可以下去自行学习,在这里我就不一一赘叙了。
四、内存操作函数
4.1 memcpy
函数原型:void* memcpy(void* dest, const void* src, size_t num);
从源src所指的内存地址的起始位置开始拷贝num个字节到目标dest所指的内存地址的起始位置中。
这个函数在遇到 '\0' 的时候并不会停下来。
如果src和dest有任何的重叠,赋值的结果都是未定义的。
我们一般拷贝字符串到另一个数组,都是用strcpy,但是如果我们想拷贝整型数组或者其它类型的数组呢?
这里我们就要用到memcpy这个函数。只要是在内存里存放的它都可以拷贝,它不在乎是什么类型的数据。
我们通过memcpy函数的原型知道它的返回值是void*,那么这里为什么是void*的指针? 其实还是和它的特点相关,void*可以接收任意数据类型的地址。
示例代码: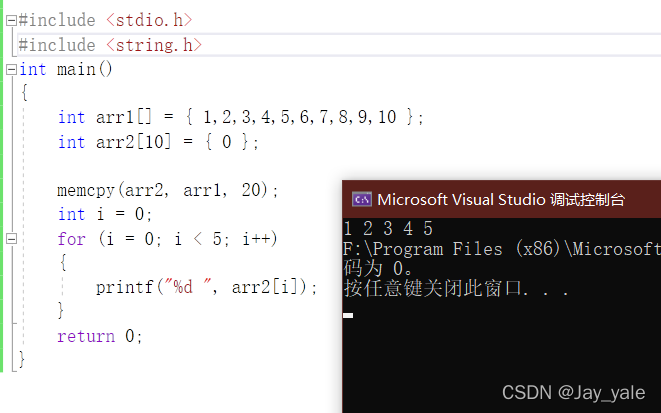
memcpy的模拟实现:
#include #include #include void* my_memcpy(void* dest, const void* src, size_t num){void* ret = dest;assert(dest && src);while (num--){*(char*)dest = *(char*)src; dest = (char*)dest + 1; //强制类型转换都是临时的src = (char*)src + 1;}return ret;}int main(){int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };int arr2[10] = { 0 };my_memcpy(arr2, arr1, 20);int i = 0;for (i = 0; i < 5; i++){printf("%d ", arr2[i]);}return 0;}代码的运行结果如下:
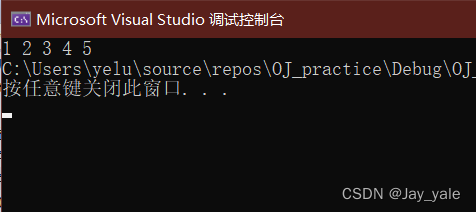
void*的指针不能解引用,也不能加加,减减。所以我们这里只能对dest进行强制类型转换,并且强制类型转换为char*最为合适。
有人就会问那为什么不强制类型转换为int*呢?举个反例:比如说这里让我们拷贝7个字节,如果强制类型转换成整型指针,加一次拷贝4个字节,在加一次又拷贝4个字节。一共拷贝了8个字节,而我们只需要拷贝7个字节。但是如果用char*的话只需拷贝7次就可以了。
这种强制类型转换都是临时的,所以每次用的时候都要强制类型转换一次。
我们再来讨论另外一种情况:
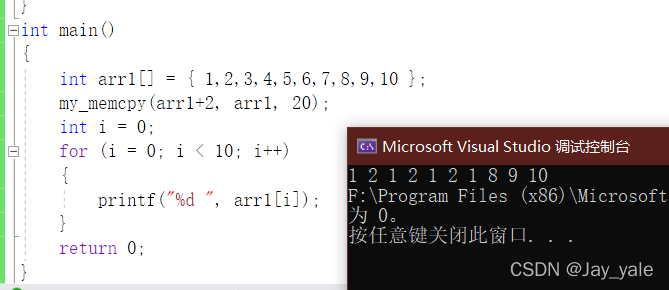
我们预想的结果是1 2 1 2 3 4 5 8 9 10。但是上图代码运行的结果和我们预想的不太一样嘞。其实按照我们模拟实现的代码是实现把源数据直接一个一个往目标空间里面填,过程大概如下图所示:
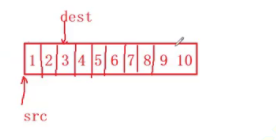
按照我们刚刚模拟memcpy函数的代码这个逻辑进行拷贝的话,我们是逐个字节进行拷贝。这里放大来看,一般情况下整型的大小都是四个字节,所以1就要占四个字节,这时我们就把1的四个字节挨个往3里面放。紧接着2的四个字节往4里面放。此时3的四个字节已经被覆盖变成1了,同样的4也被2覆盖变成了2。当你接下来准备拷贝3的到5的位置上去的时候,3已经变成1了,所以就把1拷贝给5。同理可得后面出现的结果。
其实这里我们本不应该用my_memcpy。实际上,在内存里面,如果内存重叠了还要进行拷贝,这个时候可以用我们memmove函数。它支持在拷贝内存数据的时候是可以重叠的。
我们可以验证一下:
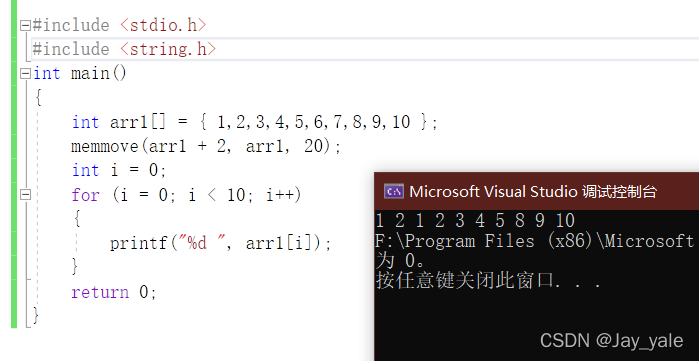
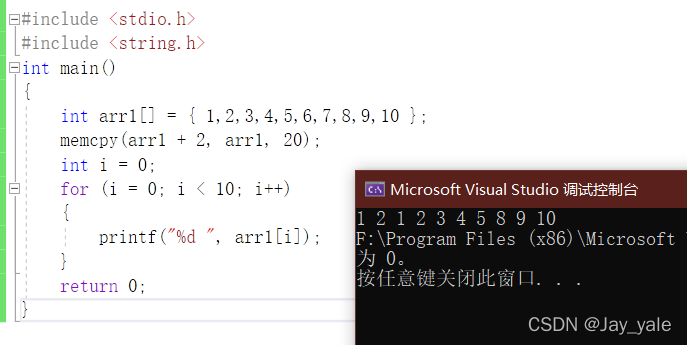
but,当我们用memcpy来写,也是可以实现的!其实,C语言只要求memcpy能拷贝不重叠的内存空间就可以了。
memmove去处理那些重叠内存拷贝,但是我们发现在VS中memcpy函数也能实现重叠拷贝,远远完成了规定的功能。通俗的解释就是:假设期末考试规定60分及格,但是你考了90分,那分数肯定是越高越好呀!
4.3 memmove
函数原型:void * memmove ( void * destination, const void * source, size_t num );
- 和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
- 如果源空间和目标空间出现重叠,就得使用memmove函数处理。
memmove的模拟实现:
如果关于内存重叠拷贝还有点似懂非懂的话,接下来我就借讲解memmove函数的模拟实现再生动形象地为家人们进行深度剖析!
分析:如果我们这里想把1 2 3 4 5,拷贝到3 4 5 6 7中去,通过上面的分析我们知道,这样直接放是不行滴。
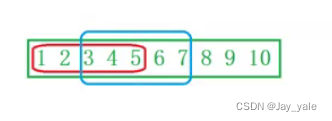
但是我们可以倒着放,从后向前拷贝,先把5放到7里面去,再把4放到6里面去….这样就可以避免覆盖。
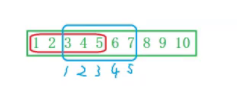
如果我们的需求改变了,想把3 4 5 6 7拷贝到1 2 3 4 5中去,倒着放的方法在这个场景就不适用了,but这里从前向后拷贝又是可以滴。
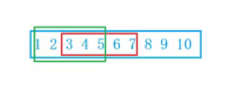
通过上面的一系列分析,我们必须找到一个万全之策。既然有两种不同的拷贝方法(1.前 --> 后 2. 后 --> 前),那我们就具体情况具体分析呗。首先对我们的内存进行明确的划分,什么情况从前向后拷贝,什么情况从后向前拷贝。经过观察,我们可以得出当src(源地址)大于dest(目标地址)的时候,采取从前向后进行拷贝;当dest(目标地址)在src(源地址)到(char*)src+num(这里的num是字节数)之间的时候,采取从后向前进行拷贝,如果dest大于(char*)src + num的时候,两种方法都可。下面是具体的示意图。

具体实现有以下两种方法,我认为当然是第一种比较简单。
经过我![]() 的一段胡乱分析(
的一段胡乱分析(![]() ),我们就可以顺理成章地完成memmove函数的模拟实现!
),我们就可以顺理成章地完成memmove函数的模拟实现!
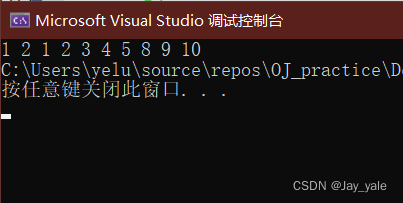
#include #include void* my_memmove(void* dest, const void* src, size_t num){void* ret = dest;assert(dest && src);// 前 -> 后if (dest 前else{while (num--){*((char*)dest + num) = *((char*)src + num); //先找到末尾的字节,然后从后向前逐个字节的进行拷贝}}return ret;}int main(){int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };my_memmove(arr1 + 2, arr1, 20);int i = 0;for (i = 0; i < 10; i++){printf("%d ", arr1[i]);}return 0;}代码运行结果如下:
4.3、memcmp
memcmp函数的原型为 int memcmp(const void *ptr1, const void *ptr2, size_t num);
其功能是把存储区 ptr1 和存储区 ptr2 的前 num 个字节进行比较。
返回值方式和strcmp函数相似,但是memcmp该函数是按字节比较的。
返回值如下:
示例代码: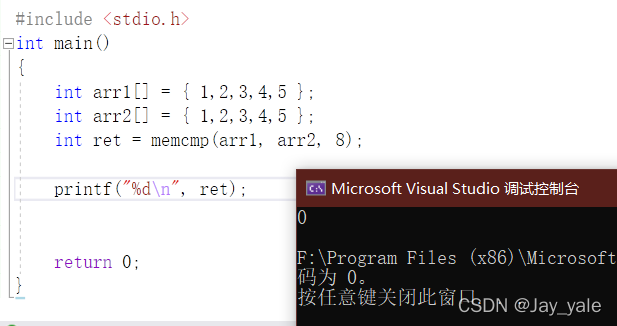
4.4、memset
memset是计算机中C/C++语言初始化函数。作用是将某一块内存中的内容全部设置为指定的值, 这个函数通常为新申请的内存做初始化工作。
函数原型:void *memset(void *dest, int c, size_t num);
函数解释:将dest中当前位置后面的num个字节用c替换并返回 dest 。
示例代码:
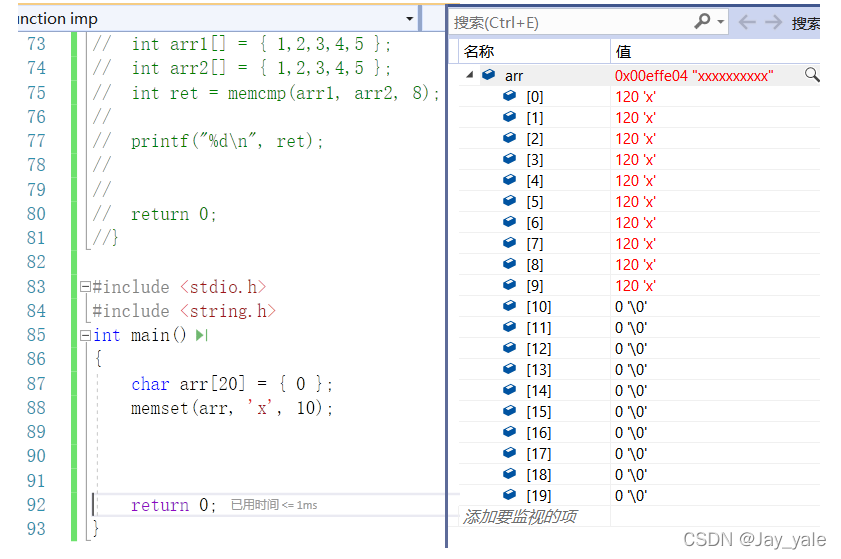
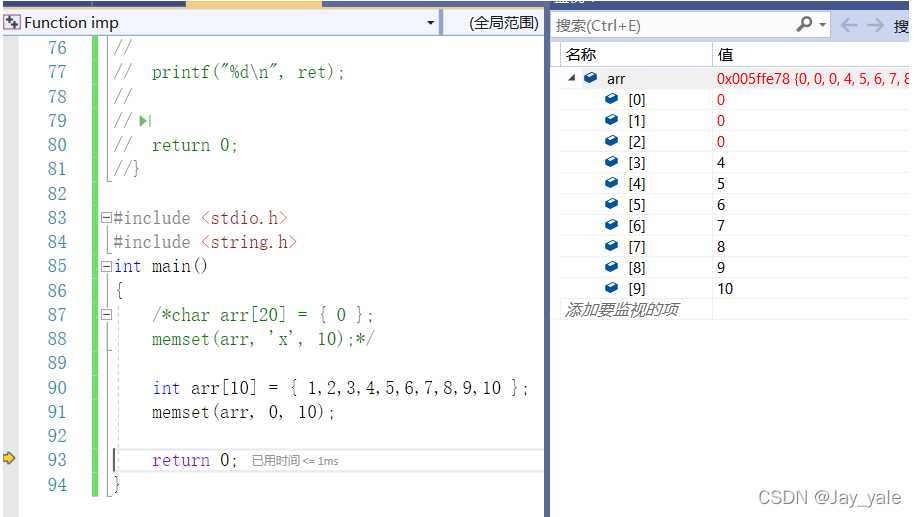
memset不仅针对字符数组,针对整型也是可以的。
如下图所示:
整型数组里面每个数字都是四个字节,在内存中是这样存放的:1是 01 00 00 00,2是 02 00 00 00,3是 03 00 00 00 ,4是 04 00 00 00….函数作用的是十个字节,所以前十个字节都被改成0。
01 00 00 00 02 00 00 00 03 00 00 00,虽然3只被改了两个字节,但是它后面两个字节都为0,所以3也为0。
总结
以上就是今天要讲的内容,至此《字符函数和字符串函数》就全部讲解完毕了。如果你认为讲的还阔以的话,希望能得到家人们的三连鼓励!你们的支持就是我写文最大的动力,哈哈。最后还是送大家一句话:读书欲精不欲博,用心欲专不欲杂。咱们下次再见,拜拜![]()

