【2019斯坦福CS224N笔记】(4)Linguistic Structure Dependency Parsing
Dependency Parsing: 依存关系语法分析,简称 依存分析。
1、句法结构(syntactic structure)分析的主要有两种方式
与编译器中的解析树类似,NLP中的解析树用于分析句子的句法结构。使用的结构主要有两种类型——constituency和dependency。
Constituency Grammar:使用短语结构语法将单词放入嵌套的组件中。
Constituency = phrase structure grammar = context-free grammars (CFGs)
context-free grammars (CFGs) 上下文无关语法
句子是使用逐步嵌套的单元构建的
- 短语结构将单词组织成嵌套的成分
- 起步单元:单词被赋予一个类别 (part of speech=pos 词性)
- 单词组合成不同类别的短语
- 短语可以递归地组合成更大的短语
Dependency Parsing:句子的从属结构显示哪些词依赖于(修饰或是)哪些词。这些单词之间的二元非对称关系称为依赖关系,并被描述为从head到dependent。通常这些依赖关系形成一个树结构。经常用语法关系的名称进行分类(主语,介词宾语,同位语等)。有时会将假根节点作为head添加到树中,所以每个单词都依赖于一个节点。
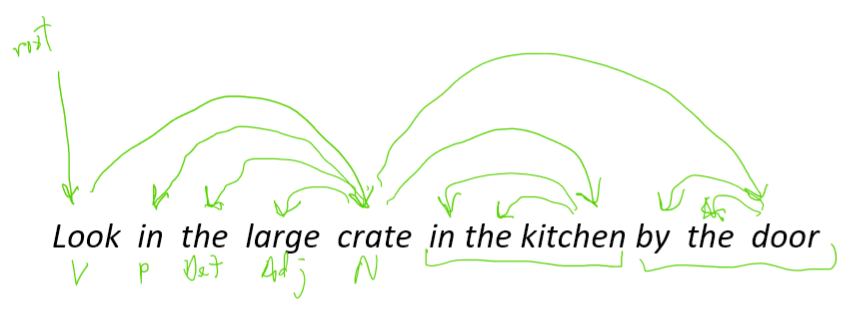
- \text{look} 是整个句子的根源, \text{look} 依赖于 \text{crate} (或者说 \text{crate} 是 \text{look} 的依赖)
- \text{in, the, large} 都是 \text{crate} 的依赖
- \text{in the kitchen} 是 \text{crate} 的修饰
- \text{in, the} 都是 \text{kitchen} 的依赖
- \text{by the door} 是 \text{crate} 的依赖
为什么我们需要句子结构?
- 为了能够正确地解释语言,我们需要理解句子结构
- 人类通过将单词组合成更大的单元来传达复杂的意思,从而交流复杂的思想
- 我们需要知道什么与什么相关联
- 除非我们知道哪些词是其他词的参数或修饰词,否则我们无法弄清楚句子是什么意思
2. Dependency Grammar and Dependency Structure(依赖语法和依赖结构)
关联语法假设句法结构包括词汇项之间的关系,通常是二元不对称关系(“箭头”),称为依赖关系
Dependency Structure有两种表现形式:
- 一种是直接在句子上标出依存关系箭头及语法关系

- 另一种是将其做成树状机构(Dependency Tree Graph)
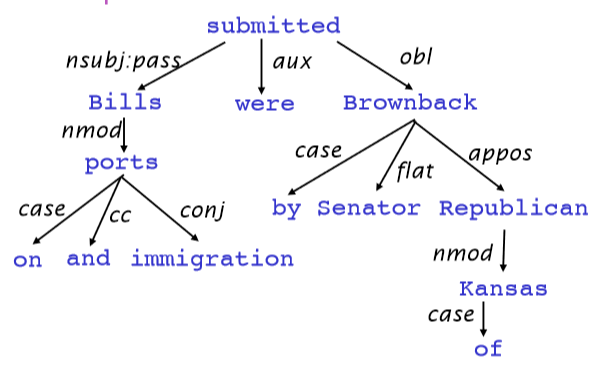
箭头通常标记(type)为语法关系的名称(主题、介词对象、apposition等)。
依赖关系标签的系统,例如 universal dependency 通用依赖
箭头连接头部(head)(调速器,上级,regent)和一个依赖(修饰词,下级,下属):A \to 依赖于 A 的事情
通常,依赖关系形成一棵树(单头 无环 连接图)
Dependency Parsing

- 通过为每个单词选择它所依赖的其他单词(包括根)来解析一个句子
- 通常有一些限制
- 只有一个单词是依赖于根的
- 不存在循环 A \to B, B \to A
- 这使得依赖项成为树
- 最后一个问题是箭头是否可以交叉(非投影的 non-projective)
- 没有交叉的就是non-projectice
Projectivity

- 定义:当单词按线性顺序排列时,没有交叉的依赖弧,所有的弧都在单词的上方
- 与CFG树并行的依赖关系必须是投影的
- 通过将每个类别的一个子类别作为头来形成依赖关系
- 但是依赖理论通常允许非投射结构来解释移位的成分
- 如果没有这些非投射依赖关系,就不可能很容易获得某些结构的语义
3、基于贪婪的转换的解析【nivre 2003】
- 贪婪判别依赖解析器 greedy discriminative dependency parser 的一种简单形式
- 解析器执行一系列自底向上的操作
- 大致类似于shift-reduce解析器中的“shift”或“reduce”,但“reduce”操作专门用于创建头在左或右的依赖项
- 解析器如下:
- 栈 \sigma 以 ROOT 符号开始,由若干 w_i 组成
- 缓存 \beta 以输入序列开始,由若干 w_i 组成
- 一个依存弧的集合 A ,一开始为空。每条边的形式是 (w_i,r,w_j) ,其中 r 描述了节点的依存关系
- 一组操作
- 最终目标是 \sigma = [\text{ROOT}], \beta = \phi ,A 包含了所有的依存弧
Basic transition-based dependency parser
Transition-based Dependency Parsing可以看做是state machine,对于 ,state由三部分构成
。
是
中若干
构成的stack。
是
中若干
构成的buffer。
是dependency arc 构成的集合,每一条边的形式是
,其中r描述了节点的依存关系如动宾关系等。
初始状态时, 仅包含ROOT
,
包含了所有的单词
,而
是空集
。最终的目标是
包含ROOT
,
清空,而
包含了所有的dependency arc,
就是我们想要的描述Dependency的结果。
state之间的transition有三类:
- SHIFT:将buffer中的第一个词移出并放到stack上。
- LEFT-ARC:将
加入边的集合
,其中
是stack上的次顶层的词,
是stack上的最顶层的词。
- RIGHT-ARC:将
加入边的集合
我们不断的进行上述三类操作,直到从初始态达到最终态。在每个状态下如何选择哪种操作呢?当我们考虑到LEFT-ARC与RIGHT-ARC各有|R|(|R|为r的类的个数)种class,我们可以将其看做是class数为2|R|+1的分类问题,可以用SVM等传统机器学习方法解决。
Evaluation of Dependency Parsing: (labeled) dependency accuracy(依赖解析的评估)
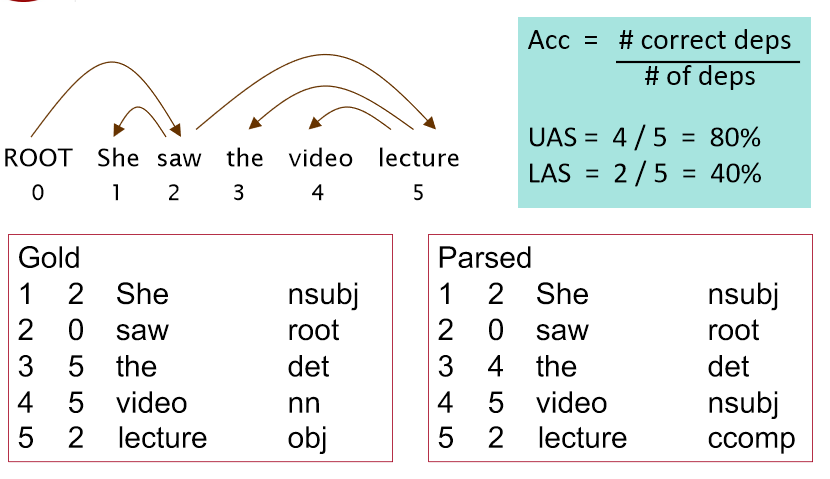
我们有两个metric,一个是LAS(labeled attachment score)即只有arc的箭头方向以及语法关系均正确时才算正确,以及UAS(unlabeled attachment score)即只要arc的箭头方向正确即可。
4. 为什么要训练神经依赖解析器?重新审视指标功能
Indicator Features的问题
- 稀疏
- 不完整
- 计算复杂
- 超过95%的解析时间都用于特征计算
4.1 A neural dependency parser [Chen and Manning 2014]
斯坦福依赖关系的英语解析
- Unlabeled attachment score (UAS) = head
- Labeled attachment score (LAS) = head and label
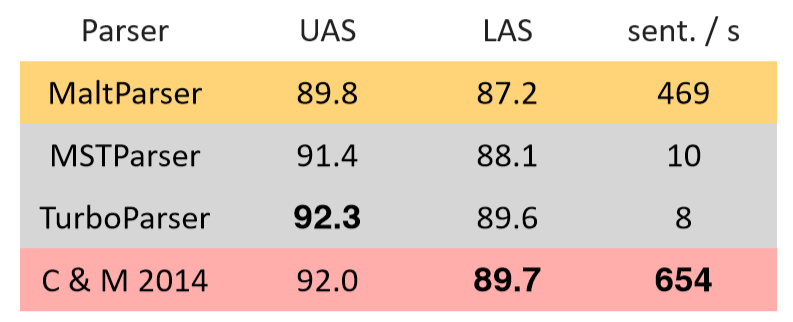
- 效果好,速度快
4.2 Distributed Representations(
- 我们将每个单词表示为一个d维稠密向量(如词向量)
- 相似的单词应该有相近的向量
- 同时,part-of-speech tags 词性标签(POS)和 dependency labels 依赖标签也表示为d维向量
- 较小的离散集也表现出许多语义上的相似性。
- NNS(复数名词)应该接近NN(单数名词)
- num(数值修饰语)应该接近amod(形容词修饰语)。
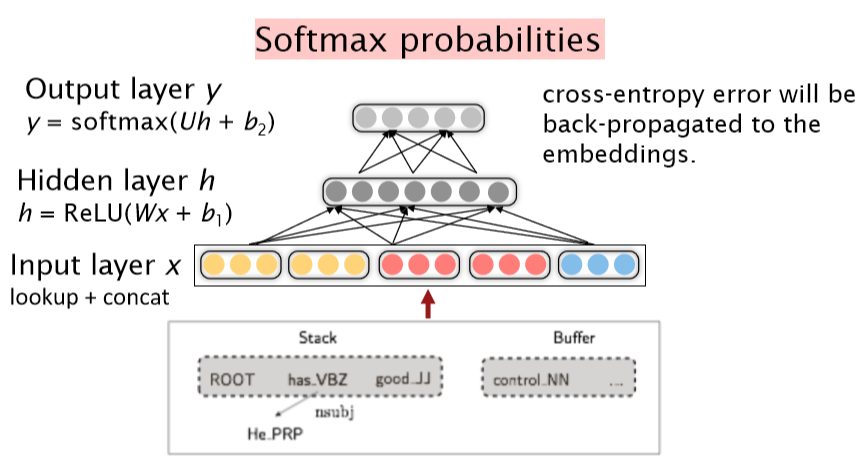
对于Neural Dependency Parser,其输入特征通常包含三种
- stack和buffer中的单词及其dependent word
- 单词的part-of-speech tag
- 描述语法关系的arc label
我们根据堆栈/缓冲区位置提取一组令牌:
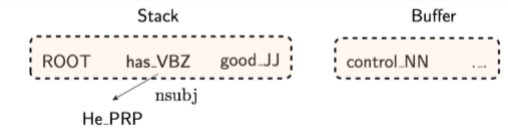

我们将其转换为词向量并将它们联结起来作为输入层,再经过若干非线性的隐藏层,最后加入softmax layer得到shift-reduce解析器的动作
Model Architecture 模型结构