(ECCV-2020)超越部分模型。用细粒度的部分池化进行行人检索(和一个强大的卷积基线)
文章目录
- 超越部分模型。用细粒度的部分池化进行行人检索(和一个强大的卷积基线)
- Abstract.
- 1 Introduction
- 2 Related works
-
- 用于行人检索的手工制作的部分特征。
- 深度学习的部分特征。
- 具有注意力机制的深度学习部分。
- 3 Proposed Method
-
- 3.1 PCB: A Part-based Convolutional Baseline
-
- Backbone network.
- From backbone to PCB.
- Important Parameters.
- 3.2 Within-Part Inconsistency
- 3.3 Refined Part Pooling
- 3.4 Induced Training for Part Classifier
- 参考文献
超越部分模型。用细粒度的部分池化进行行人检索(和一个强大的卷积基线)
paper题目:Beyond Part Models: Person Retrieval with Refined Part Pooling (and A Strong Convolutional Baseline)
paper是清华大学发表在ECCV 2018的工作
paper地址:链接
Abstract.
使用部分级特征为行人图像描述提供了细粒度的信息。部分信息挖掘的先决条件是每个部分都应该很好地定位。本文不使用姿势估计器等外部资源,而是考虑每个部分内的内容一致性,以定位精确的部分位置。具体来说,本文的目标是学习用于人检索的有判别性的部分特征,并做出了两个贡献。 (i)提出一个名为 Part-based Convolutional Baseline (PCB) 的网络。给定一个图像输入,它输出一个由几个部分级特征组成的卷积描述符。凭借均匀的分块策略,PCB 使用取得了最先进的结果,证明其为用于人物检索的强大卷积基线。 (ii) 细化部分池化 (RPP) 方法。均匀分区不可避免地会在每个部分中产生异常值,这些异常值实际上与其他部分更相似。 RPP 将这些异常值重新分配给它们最接近的部分,从而产生具有增强的部分内一致性的细粒度部分。实验证实,RPP 让 PCB 获得了又一轮的性能提升。例如,在 Market-1501 数据集上,作者实现了 (77.4+4.2)% 的 mAP 和 (92.3+1.5)% 的 rank-1 准确度,大大超过了现有技术水平。代码地址:链接
关键词:人物检索,部分级特征,部分细化
1 Introduction
行人检索,也称为行人重识别(re-ID),旨在在给定查询行人感兴趣的情况下,在大型数据库中检索指定行人的图像。目前,深度学习方法在这个社区中占主导地位,与手工制作的竞争对手相比具有令人信服的优势。深度学习的表示提供了很高的判别能力,尤其是在从深度学习的部分特征中聚合时。重识别基准的最新技术是通过部分的深度特征实现的。
学习有判别的部分特征的一个基本前提是部分应该被准确定位。最近最先进的方法在其分区策略上有所不同,可以相应地分为两组。第一组利用外部线索,例如来自人体姿势估计的帮助。它们依赖于外部人体姿态估计数据集和复杂的姿态估计器。姿势估计和人物检索之间的基础数据集偏差仍然是对人物图像进行理想语义划分的障碍。另一组 [39,41,25] 放弃了语义部分的线索。它们不需要部分标记,但与第一组相比具有竞争力的准确性。一些分区策略在图 1 中进行了比较。在学习部分级深度特征的这种进步背景下,作者重新思考什么是对齐良好的部分的问题。语义分区可以为良好的对齐提供稳定的线索,但容易出现嘈杂的姿势检测。本文从另一个角度强调了每个部分的一致性,作者推测这对空间对齐至关重要。然后作者给出动机,即给定粗划分的部分,作者的目标是细化它们以加强部分内的一致性。具体来说,本文做出以下两个贡献:
首先,提出了一个名为 Part-based Convolutional Baseline (PCB) 的网络,它在 conv 层上进行统一分区以学习部分级特征。它没有明确划分图像。 PCB 将整个图像作为输入并输出卷积特征。 PCB作为分类网络,架构简洁,对backbone网络稍作修改。训练程序是标准的。实验表明卷积描述符比常用的全连接(FC)描述符具有更高的判别能力。例如,在 Market-1501 数据集上,性能从 85.3% rank-1 准确率和 68.5% mAP 提高到 92.3% (+7.0%) rank-1 准确率和 77.4% (+8.9%) mAP,超过了许多最先进的方法。
其次,提出了一种名为 Refined Part Pooling (RPP) 的自适应池化方法来改进均匀分区。作者认为每个部分的内容应该一致的动机。作者观察到在均匀划分下,每个部分都存在异常值。事实上,这些异常值更接近其他部分的内容,这意味着部分内不一致。因此,通过将这些异常值重新定位到它们最接近的部分来细化统一分区,从而加强部分内的一致性。图 1(f) 显示了细化部分的一个例子。 RPP 不需要部分标签进行训练,并且在 PCB 实现的高基线上提高了检索精度。例如在 Market-1501 上,RPP 进一步将性能提高到 93.8% (+1.5%) rank-1 准确度和 81.6% (+4.2%) mAP。

图 1 行人检索中几种深度模型的划分策略。 (a) 到 (e):分别由 GLAD [35]、PDC [31]、DPL [39]、Hydra-plus [25] 和 PAR [41] 划分的部分。(f):部位的方法采用均匀划分然后细化每个条纹。 PAR [41] 和本文的方法都进行“软”分区,但本文的方法与 [41] 有很大不同,详见第 2 节。
2 Related works
用于行人检索的手工制作的部分特征。
在深度学习方法主导 re-ID 研究社区之前,手工算法已经开发出学习部分或局部特征的方法。 Gray 和 Tao [13] 将行人划分为水平条纹以提取颜色和纹理特征。类似的分块策略随后被许多工作采用。其他一些工作采用更复杂的策略。Gheissari等人[12]将行人分成几个三角形进行部分特征提取。Cheng等人[4] 采用图形结构将行人解析为语义部分。Das等人[6] 在头部、躯干和腿部应用 HSV 直方图来捕捉空间信息。
深度学习的部分特征。
大多数行人检索数据集的最先进技术目前由深度学习方法报告。在为 re-ID 学习部分特征时,深度学习相对于手工算法的优势有两个。首先,深度特征通常会获得更强的判别能力。其次,深度学习为解析行人提供了更好的工具,这进一步有利于部分特征。特别是,人体姿态估计和地标检测取得了令人瞩目的进展。最近的几项 re-ID 工作将这些工具用于行人分块,并报告了令人鼓舞的改进。然而,当以现成的方式直接使用这些姿势估计方法时,用于姿势估计和人物检索的数据集之间的潜在差距仍然是一个问题。其他人则放弃划分的语义线索。Yao等人[39] 对特征图上的最大激活坐标进行聚类,以定位几个感兴趣的区域。Liu等人[25]和Zhao等人[41] 将注意力机制 [38] 嵌入网络中,允许模型自行决定将注意力集中在哪里。
具有注意力机制的深度学习部分。
本文的一个主要贡献是细化的部分池化。作者将其与 Zhao 等人最近的一项工作 PAR [39] 进行了比较。详细说明。两项工作都使用部分分类器对行人图像进行“软”划分,如图 1 所示。两项工作的优点是不需要部分标记来学习判别部分。但是,这两种方法的动机、训练方法、机制和最终表现都有很大的不同,下面将详细介绍。
动机:PAR旨在直接学习对齐的部分,而RPP旨在细化预分区的部分。工作机制:PAR采用注意力方法,以无监督的方式训练部分分类器,而RPP的训练可以看作是一个弱监督的过程。训练过程:RPP首先训练一个均匀划分的身份分类模型,然后利用学习到的知识诱导部分分类器的训练。性能:稍微复杂的训练程序使RPP获得了更好的解释和明显更高的性能。例如在 Market-1501 上,PAR 实现的 mAP、PCB 协同注意力机制和提出的 RPP 分别为 63.4%、74.6% 和 81.6%。此外,RPP 具有与各种分区策略配合的潜力。
3 Proposed Method
第3.1节首先提出了一个基于部分的卷积基线(PCB)。PCB采用了卷积特征均匀划分的简单策略。第3.2节描述了部分内不一致的现象,这揭示了均匀分区的问题。第3.3节提出了细化部分池化(RPP)方法。RPP通过对卷积特征进行像素级的细化来减少分区误差。RPP也是在没有部分标签信息的情况下学习的特点,这在第3.4节中详细介绍。
3.1 PCB: A Part-based Convolutional Baseline
Backbone network.
PCB可以将任何为图像分类设计的没有隐藏全连接层的网络作为backbone,例如Google Inception和ResNet。本文主要采用ResNet50,考虑到其具有竞争力的性能以及相对简洁的结构。
From backbone to PCB.
作者将骨干网络重塑为PCB,并稍作修改,如图2所示。原有的全局平均池化(GAP)层之前的结构与backbone网模型保持完全相同。不同的是,删除GAP层和后面的层。当一个图像经过了从backbone网络继承的所有层,它就变成了一个激活的三维张量 T \boldsymbol{T} T。本文将沿通道轴查看的激活向量定义为列向量。然后,通过传统的平均池化,PCB 将 T \boldsymbol{T} T划分为 p p p个水平条带,并将同一条带中的所有列向量平均为单个部分级列向量 g i ( i = 1 , 2 , ⋯ , p \boldsymbol{g}_{i}(i=1,2, \cdots, p gi(i=1,2,⋯,p, 下标除非必要,否则省略 ) ) )。之后,PCB 采用卷积层来降低 g \boldsymbol{g} g的维数。根据作者的初步实验,降维的列向量 h \boldsymbol{h} h设置为 256-dim。最后,将每个 h \boldsymbol{h} h输入到一个分类器中,该分类器由一个全连接 (FC) 层和一个 Softmax 函数实现,以预测输入的标识 (ID)。
在训练期间,通过最小化 p p p个 ID 预测的交叉熵损失之和来优化 PCB。在测试过程中,将 p p p块 g \boldsymbol{g} g或 h \boldsymbol{h} h连接起来形成最终的描述符 G \mathcal{G} G或 H \mathcal{H} H,即 G = [g1 ,g2 , ⋯ ,gp ] \mathcal{G}=\left[\boldsymbol{g}_{1}, \boldsymbol{g}_{2}, \cdots, \boldsymbol{g}_{p}\right] G=[g1,g2,⋯,gp]或 H = [h1 ,h2 , ⋯ ,hp ] \mathcal{H}=\left[\boldsymbol{h}_{1}, \boldsymbol{h}_{2}, \cdots, \boldsymbol{h}_{p}\right] H=[h1,h2,⋯,hp].正如在实验中观察到的,使用 G G G可以实现稍高的准确度,但计算成本更高,这与 [32] 中的观察结果一致。
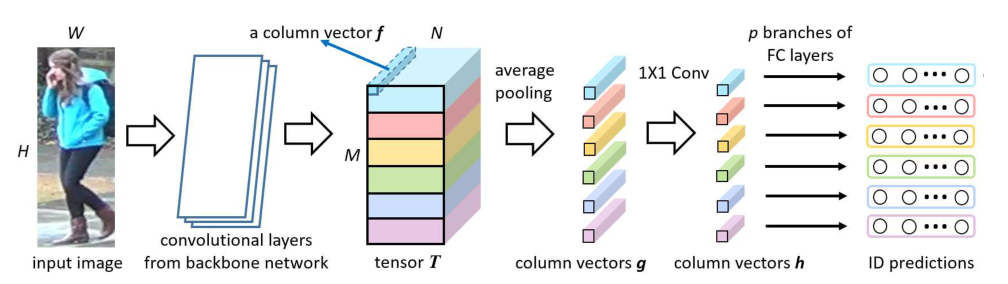
图 2. PCB 的结构。输入图像通过来自backbone网络的堆叠卷积层向前形成 3D 张量T \boldsymbol{T} T。 PCB 用传统的池化层替换了原来的全局池化层,将T \boldsymbol{T} T空间下采样为p p p个列向量g \boldsymbol{g} g。随后的1 × 1 1 \times 1 1×1内核大小的卷积层降低了g \boldsymbol{g} g的维数。最后,将每个降维的列向量h \boldsymbol{h} h分别输入到分类器中。每个分类器都用一个全连接(FC)层和一个顺序 Softmax 层来实现。p p p块g \boldsymbol{g} g或h \boldsymbol{h} h被连接起来形成输入图像的最终描述符。
Important Parameters.
PCB 受益于细粒度的空间聚合。几个关键参数,即输入图像大小(即 [ H , W ] ) [\boldsymbol{H}, \boldsymbol{W}]) [H,W]))、张量 T \boldsymbol{T} T的空间大小(即 [ M , N ] [\boldsymbol{M}, \boldsymbol{N}] [M,N])和池化列向量的个数(即 p \boldsymbol{p} p)对PCB的性能很重要。请注意,在给定固定大小输入的情况下, [ M , N ] [\boldsymbol{M}, \boldsymbol{N}] [M,N]由backbone模型的空间下采样率决定。一些深度目标检测方法,例如SSD和R-FCN,表明降低backbone网络的下采样率可以有效地丰富特征的粒度。PCB通过删除backbone网络中的最后一个空间下采样操作来增加 T \boldsymbol{T} T的大小从而获得的成功。这种操作大大提高了检索准确性,同时增加了非常小的计算成本。详细信息可在第 4.4 节中访问。
通过作者的实验,PCB的优化参数设置为:
输入图像的大小调整为 384 × 128 384 \times 128 384×128,高宽比为 3 : 1 3: 1 3:1。
T \boldsymbol{T} T的空间大小设置为 24 × 8 24 \times 8 24×8。
T \boldsymbol{T} T被等分为6条水平条带。
3.2 Within-Part Inconsistency
PCB的均匀分割是简单、有效的,还有待改进。它不可避免地会给每个部分引入分割错误,从而损害学习特征的识别能力。本文从一个新的角度分析分区错误:内部不一致。
在关注要在空间上划分的张量 T \boldsymbol{T} T时,作者对内部不一致性的直觉是: T \boldsymbol{T} T的同一部分中的列向量 f f f应该彼此相似,并且与其他部分中的列向量不同;否则会出现部分内部不一致的现象,这意味着部分被不适当地分割。
在将 P C B \mathrm{PCB} PCB训练为收敛后,通过测量余弦距离来比较每个 f f f和 g i ( i = 1 , 2 , ⋯ , p ) \boldsymbol{g}_{i}(i=1,2, \cdots, p) gi(i=1,2,⋯,p)之间的相似性,即每个部分的平均合并列向量。这样做可以找到最接近每个 f f f的部分,如图3所示。每个列向量由一个小矩形表示,并以其最近部分的颜色绘制。作者观察到,在训练过程中,当指定到一个指定的水平条纹(部分)时,存在许多异常值,这些异常值与另一部分更相似。这些异常值的存在表明,它们本质上与另一部分的列向量更一致。
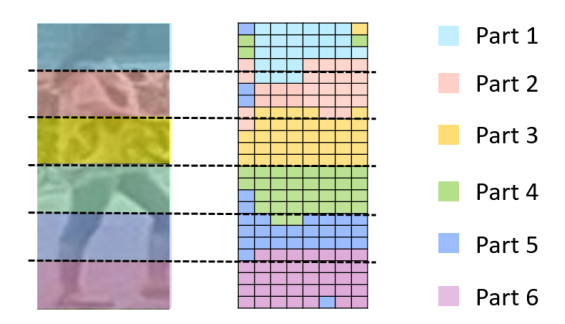
图3。部分内部不一致性的可视化。T \boldsymbol{T} T左:T \boldsymbol{T} T在训练期间被等分为p=6个水平条纹(部分)。右图:T \boldsymbol{T} T中的每个列向量都用一个小矩形表示,并以其最近部分的颜色绘制。
3.3 Refined Part Pooling
本文提出了改进的部分池化(RPP)来纠正部分内的不一致。本文的目标是根据它们与每个部分的相似性分配所有列向量,以便重新定位异常值。更具体地说,定量测量列向量 f f f和每个部分 P i P_i Pi之间的相似度值 S ( f ↔Pi ) S\left(f \leftrightarrow P_{i}\right) S(f↔Pi)。然后根据相似度值 S ( f ↔Pi ) S\left(f \leftrightarrow P_{i}\right) S(f↔Pi)将列向量 f f f采样到部分 P i P_i Pi中,公式为:
Pi ={S ( f ↔ P i) f,∀f∈F} , P_{i}=\left\{S\left(f \leftrightarrow P_{i}\right) f, \forall f \in F\right\}, Pi={S(f↔Pi)f,∀f∈F},
其中 F F F是张量 T \boldsymbol{T} T中的完整列向量集, { ∙ } \{\bullet\} {∙}表示形成聚合的采样操作。
直接测量给定 f f f和每个部分之间的相似度值并非易事。假设已经执行了上式中定义的采样操作来更新每个部分,那么“已经测量”的相似性不再存在。必须迭代地执行“相似性测量”→“采样”过程,直到收敛,这会演化出嵌入深度学习的非平凡聚类。
因此,RPP 不是测量每个 f f f和每个 P i P_{i} Pi之间的相似性,而是使用部分分类器来预测 S ( f ↔Pi ) S\left(f \leftrightarrow P_{i}\right) S(f↔Pi)的值(也可以解释为 f f f属于 P i P_{i} Pi的概率),如下所示:
S(f↔ P i ) = softmax ( W i T f) = exp ( W i T f ) ∑ j = 1 pexp ( W j T f ) S\left(f \leftrightarrow P_{i}\right)=\operatorname{softmax}\left(W_{i}^{T} f\right)=\frac{\exp \left(W_{i}^{T} f\right)}{\sum_{j=1}^{p} \exp \left(W_{j}^{T} f\right)} S(f↔Pi)=softmax(WiTf)=∑j=1pexp(WjTf)exp(WiTf)
其中 p p p是预定义部分的数量(即 P C B \mathrm{PCB} PCB中 p = 6 p=6 p=6), W W W是部分分类器的可训练权重矩阵。
提出的细化部分池化进行“软”和自适应分区以细化原始“硬”和均匀分区,并且源自均匀分区的异常值将被重新定位。结合上述细化部分池化,PCB 被进一步重塑为图 4。细化部分池化,即部分分类器以及随后的采样操作,取代了原始的平均池化。所有其他层的结构与图 2 完全相同。
W W W必须在没有部分标签信息的情况下学习。为此,作者设计了一个诱导训练程序,详见下文第 3.4 节。
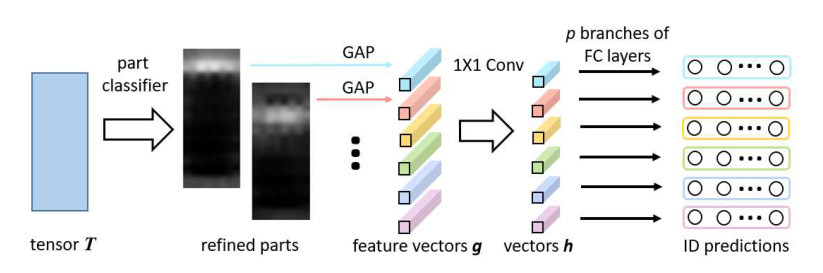
图 4. PCB 与细化部分池相结合。当关注空间分区时,3D 张量T \boldsymbol{T} T简单地用矩形而不是立方体表示。与图 2 相比,T \boldsymbol{T} T之前的层被省略,因为它们保持不变。部分分类器预测每个列向量属于p p p个部分的概率。然后从所有的列向量中对每个部分进行采样,并以相应的概率作为采样权重。 GAP 表示全局平均池化。
3.4 Induced Training for Part Classifier
所提出的诱导训练的关键思想是:在没有部分标签信息的情况下,可以使用预训练的 PCB 中已经学习的知识来诱导新附加的部分分类器的训练。算法如下。
首先,训练一个标准的 PCB 模型以收敛于 T \boldsymbol{T} T等分。
其次,删除了 T \boldsymbol{T} T之后的原始平均池化层,并在 T \boldsymbol{T} T上附加了一个 p p p类部分分类器。根据部分分类器的预测,从 T \boldsymbol{T} T中采样新部分,详见 3.3 节。
第三,将 PCB 中所有已经学习的层设置为固定,只留下部分分类器可训练。然后在训练集上重新训练模型。在这种情况下,模型仍然期望张量 T \boldsymbol{T} T被平均划分,否则它将预测错误的训练图像的身份。所以步骤 3 惩罚部分分类器,直到它进行接近原始统一分区的分区,而部分分类器倾向于将本质上相似的列向量分类到同一部分。步骤 3 的结果将达到平衡状态。
最后,允许更新所有层。整个网络,即 PCB 以及部分分类器都经过微调以进行整体优化。
在上述训练过程中,Step1 中训练的 PCB 模型诱导了部分分类器的训练。第 3 步和第 4 步收敛速度非常快,总共需要 10 多个 epoch。

参考文献
-
Cheng, D.S., Cristani, M., Stoppa, M., Bazzani, L., Murino, V.: Custom pictorial structures for re-identification. In: BMVC (2011)
-
Das, A., Chakraborty, A., Roy-Chowdhury, A.K.: Consistent Re-identification in a Camera Network. Springer International Publishing (2014)
-
Gheissari, N., Sebastian, T.B., Hartley, R.: Person reidentification using spatiotemporal appearance. In: CVPR (2006)
-
Gray, D., Tao, H.: Viewpoint invariant pedestrian recognition with an ensemble of localized features. In: ECCV (2008)
-
Liu, X., Zhao, H., Tian, M., Sheng, L., Shao, J., Yi, S., Yan, J., Wang, X.: Hydraplus-net: Attentive deep features for pedestrian analysis. In: ICCV (2017)
-
Su, C., Li, J., Zhang, S., Xing, J., Gao, W., Tian, Q.: Pose-driven deep convolutional model for person re-identification. In: ICCV (2017)
-
Sun, Y., Zheng, L., Deng, W., Wang, S.: SVDNet for pedestrian retrieval. In: ICCV (2017)
-
Wei, L., Zhang, S., Yao, H., Gao, W., Tian, Q.: GLAD: Global-local-alignment descriptor for pedestrian retrieval. ACM Multimedia (2017)
-
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, R., Bengio, Y.: Show, attend and tell: Neural image caption generation with visual attention. In: ICML (2015)
-
Yao, H., Zhang, S., Zhang, Y., Li, J., Tian, Q.: Deep representation learning with part loss for person re-identification. arXiv preprint arXiv:1707.00798 (2017)
-
Zhao, L., Li, X., Wang, J., Zhuang, Y.: Deeply-learned part-aligned representations for person re-identification. In: ICCV (2017)

