PyTorch 08 —预训练模型(迁移学习)
一、什么是预训练网络
预训练网络是一个保存好的之前已在大型数据集(大规模图像分类任务)上训练好的卷积神经网络。如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征的空间层次结构可以作为有效的提取视觉世界特征的模型。
即使新问题和新任务与原始任务完全不同,学习到的特征在不同问题之间是可移植的,这也是深度学习与浅层学习方法的一个重要优势。它使得深度学习对于小数据问题非常的有效。即便是咱门这些数据集非常小,比如上一章的四分类任务,仅仅不到1000张图片,这个时候就可以去移植预训练模型,使得它使用已经训练好的模型来对这个四种图片提取它的特征,从而训练一个分类模型出来。
ImageNet是一个手动标注好类别的图片数据库(为了机器视觉研究),目前已有22,000个类别。当我们在深度学习和卷积神经网络的背景下听到“ImageNet”一词时,我们可能会提到ImageNet视觉识别比赛,称为ILSVRC。这个图片分类比赛是训练一个模型,能够将输入图片正确分类到1000个类别中的某个类别。训练集120万,验证集5万,测试集10万。这1,000个图片类别是我们在日常生活中遇到的,例如狗,猫,各种家居物品,车辆类型等等。
在图像分类方面,ImageNet比赛准确率已经作为计算机视觉分类算法的基准。自2012年以来,卷积神经网络和深度学习技术主导了这一比赛的排行榜。
PyTorch内置预训练网络
Pytorch库中包含 VGG16、VGG19、densenet ResNet、mobilenet、Inception v3等经典的模型架构。
二、预训练网络VGG16
VGG介绍
VGG全称是Visual Geometry Group,属于牛津大学科学工程系,其发布了一些列以VGG开头的卷积网络模型,可以应用在人脸识别、图像分类等方面,分别从VGG16~VGG19。
在2014年,VGG模型架构由Simonyan和Zisserman提出,在“极深的大规模图像识别卷积网络”(Very Deep Convolutional Networks for Large Scale Image Recognition)这篇论文中有介绍。
VGG研究卷积网络深度的初衷是想搞清楚卷积网络深度是如何影响大规模图像分类与识别的精度和准确率的,最初是VGG-16, 号称非常深的卷积网络全称为(GG-Very-Deep-16 CNN) 。
VGG模型结构简单有效,前几层仅使用3×3卷积核来增加网络深度,通过max pooling(最大池化)依次减少每层的神经元数量,最后三层分别是2个有4096个神经元的全连接层和一个softmax层。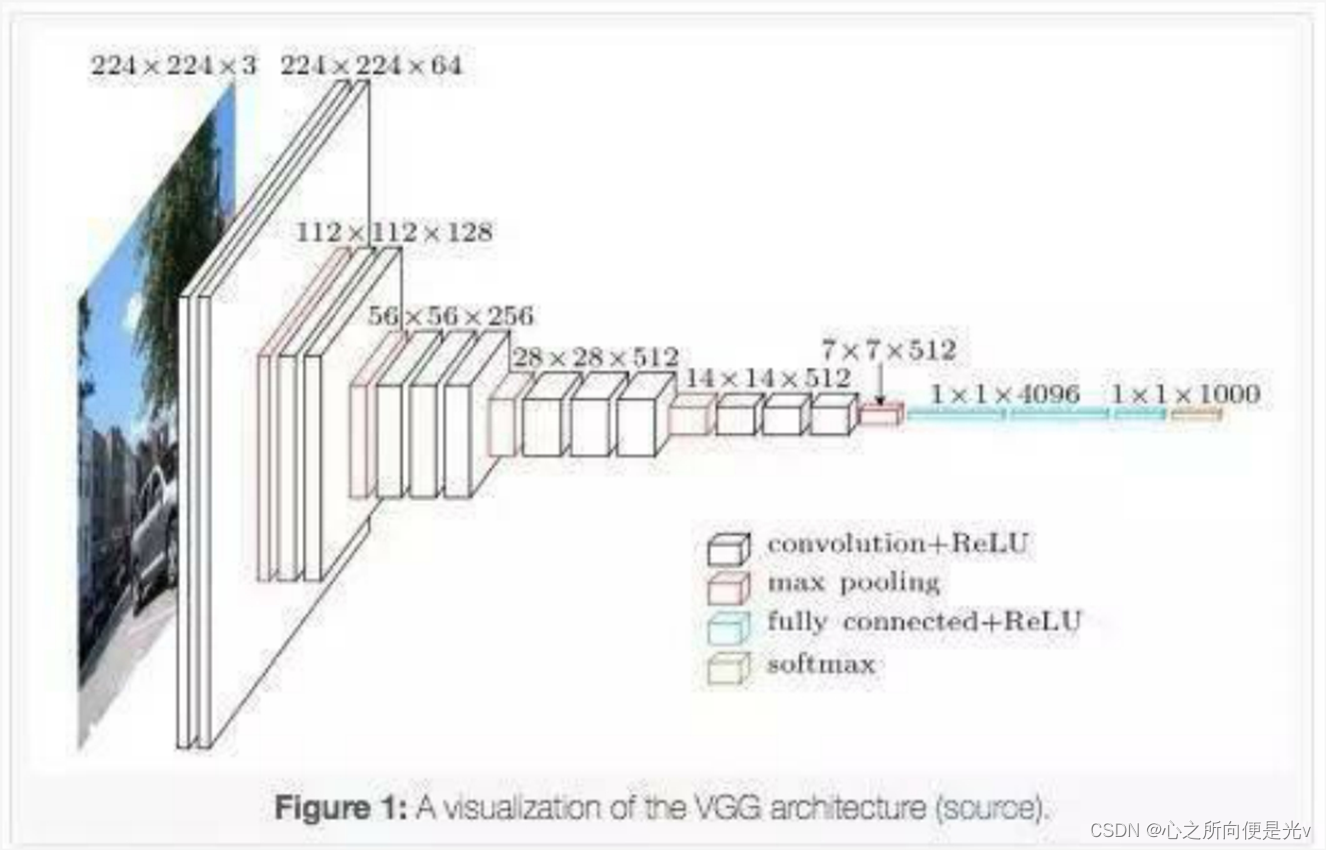
VGG在加深网络层数同时为了避免参数过多,在所有层都采用3x3的小卷积核,卷积层步长被设置为1。VGG的输入被设置为224x244大小的RGB图像,在训练集图像上对所有图像计算RGB均值,然后把图像作为输入传入VGG卷积网络,使用3x3或者1x1的filter,卷积步长被固定1。
VGG全连接层有3层,根据卷积层+全连接层总数目的不同可以从VGG11 ~ VGG19,最少的VGG11有8个卷积层与3个全连接层,最多的VGG19有16个卷积层+3个全连接层,此外VGG网络并不是在每个卷积层后面跟上一个池化层,还是总数5个池化层,分布在不同的卷积层之下.
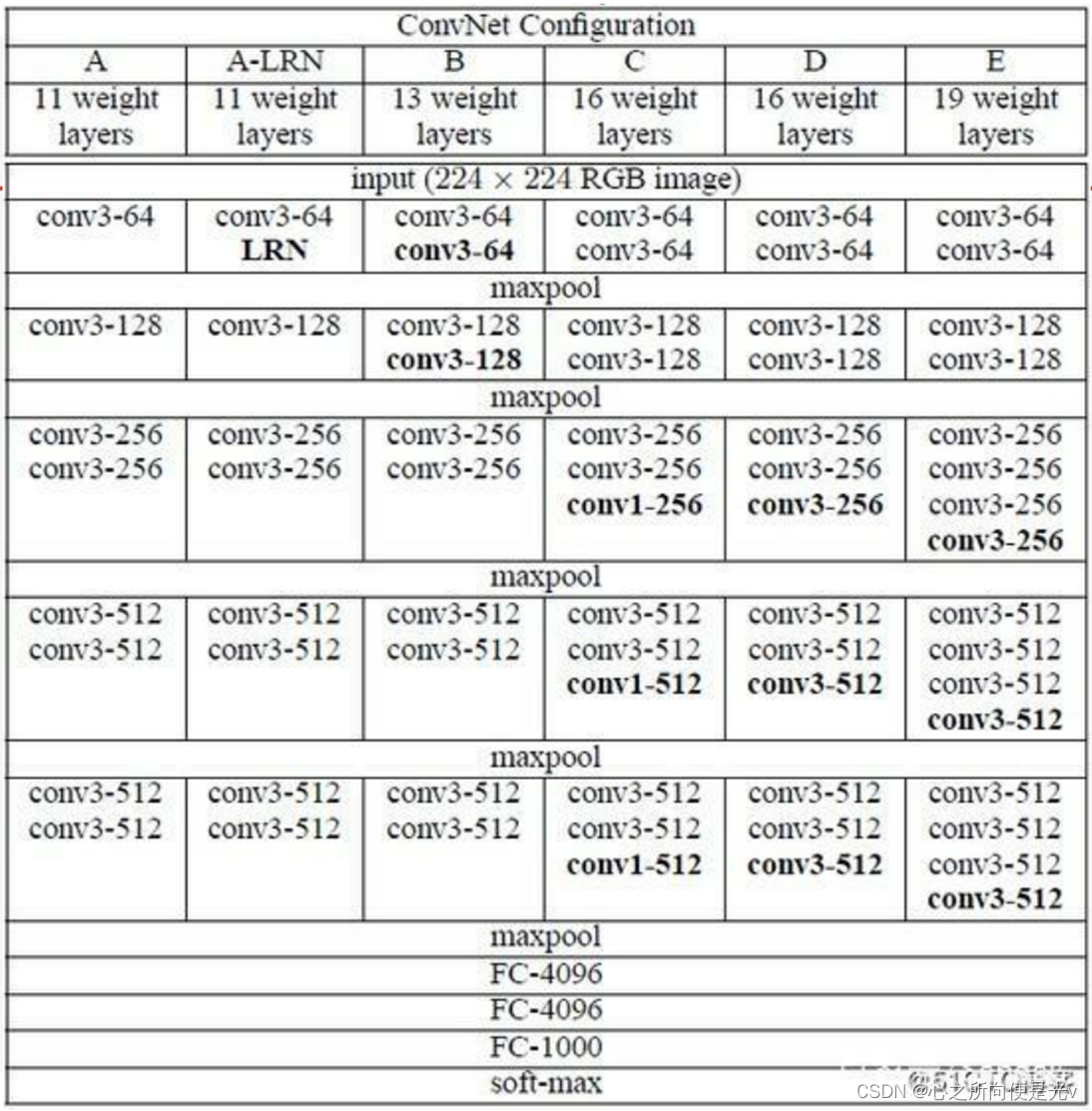
conv表示卷积层;FC表示全连接层(dense);Conv3 表示卷积层使用3x3 filters ;conv3-64表示 深度64 ;maxpool表示最大池化。
在实际处理中还可以对第一个全连接层改为7x7的卷积网络,后面两个全连接层改为1x1的卷积网络,这个整个VGG就变成一个全卷积网络FCN。
代码实战
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport numpy as npimport matplotlib.pyplot as plt%matplotlib inlineimport torchvisionfrom torchvision import transformsimport os"""(1)加载VGG模型"""print('(1)加载VGG模型')base_dir = r'../dataset2/4weather'train_dir = os.path.join(base_dir , 'train')test_dir = os.path.join(base_dir , 'test')transform = transforms.Compose([ transforms.Resize((192, 192)), # 如果图片太小,经过几次池化后,图片也许还不如卷积核大,就会报错 transforms.ToTensor(), transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) ])train_ds = torchvision.datasets.ImageFolder(train_dir,transform=transform)test_ds = torchvision.datasets.ImageFolder(test_dir,transform=transform)BTACH_SIZE = 16train_dl = torch.utils.data.DataLoader(train_ds,batch_size=BTACH_SIZE,shuffle=True )test_dl = torch.utils.data.DataLoader(test_ds,batch_size=BTACH_SIZE, )# torchvision里的datasets里面有预训练数据;models里面有预训练模型。pretrained参数表示是否是预训练的;pretrained默认不是预训练的# 即表示只是引入模型的架构,这些参数、权重并不是经过imageNet数据集上经过训练的。pretrained=True,现在加载这个模型的话,不仅# 是加载它的框架,它的权重也被设置为在imageNet上经过训练好的权重。# pth是PyTorch的简写,pytorch在保存模型的时候都喜欢将这个模型保存为 .pth 结尾。model = torchvision.models.vgg16(pretrained=True) # C:\Users\admin/.torch\modelsprint(model)显示模型结果:


预训练模型的使用
我们实际上使用了预训练模型当中的卷积基部分来提取特征,因为预训练模型已经在imageNet上预训练好了,所以它的卷及部分可以有效的去提取图片当中的特性。然后重新训练它的分类器(全连接层)。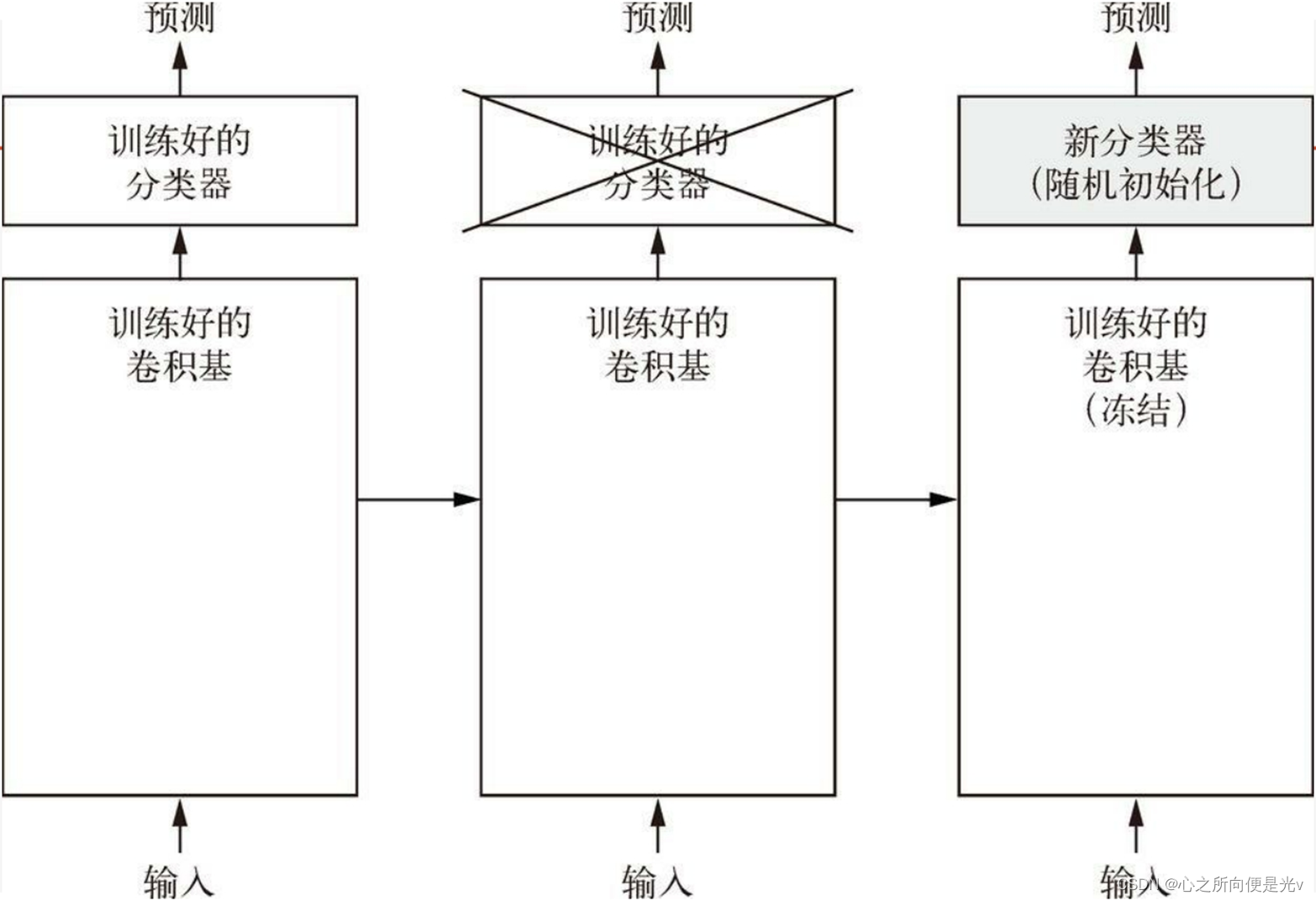
"""(2)更改模型"""print('\n(2)更改模型')# 2-1、将卷积部分冻结(卷积部分就是features部分)for p in model.features.parameters(): # 提取模型的卷积部分的参数,让它冻结,不再进行梯度的更新 p.requires_grad = False# 2-2、更改分类器,原分类器是输出到1000个分类上,我们需要输出到4分类model.classifier[-1].out_features = 4# 下面就可以对这个模型进行训练了if torch.cuda.is_available(): model.to('cuda')optimizer = torch.optim.Adam(model.classifier.parameters(),lr=0.001) # 优化器loss_fn = nn.CrossEntropyLoss() # softmax交叉熵 损失函数def fit(epoch, model, trainloader, testloader): # 训练函数 correct = 0 total = 0 running_loss = 0 model.train() for x, y in trainloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): y_pred = torch.argmax(y_pred, dim=1) correct += (y_pred == y).sum().item() total += y.size(0) running_loss += loss.item() # exp_lr_scheduler.step() epoch_loss = running_loss / len(trainloader.dataset) epoch_acc = correct / total test_correct = 0 test_total = 0 test_running_loss = 0 with torch.no_grad(): model.eval() for x, y in testloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) y_pred = torch.argmax(y_pred, dim=1) test_correct += (y_pred == y).sum().item() test_total += y.size(0) test_running_loss += loss.item() epoch_test_loss = test_running_loss / len(testloader.dataset) epoch_test_acc = test_correct / test_total print( 'epoch: ', epoch, 'loss: ', round(epoch_loss, 3), 'accuracy:', round(epoch_acc, 3), 'test_loss: ', round(epoch_test_loss, 3), 'test_accuracy:', round(epoch_test_acc, 3) ) return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_accepochs = 10train_loss = []train_acc = []test_loss = []test_acc = []for epoch in range(epochs): epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,model,train_dl,test_dl) train_loss.append(epoch_loss) train_acc.append(epoch_acc) test_loss.append(epoch_test_loss) test_acc.append(epoch_test_acc)plt.figure(0)plt.plot(range(1, epochs+1), train_loss, label='train_loss')plt.plot(range(1, epochs+1), test_loss, label='test_loss')plt.legend()plt.show()plt.figure(1)plt.plot(range(1, epochs+1), train_acc, label='train_acc')plt.plot(range(1, epochs+1), test_acc, label='test_acc')plt.legend()plt.show()三、数据增强和学习速率衰减
数据增强
为了解决过拟合,还可以使用数据增强,什么是数据增强呢?就是人为的去扩充这个数据,比如说训练的图片全是白天的图片,可以人为的将白天图片减低它的亮度,模拟黑夜的情况。再比如说,训练集中有张人脸照片只有左边耳朵,可以将这张图片进行翻转变成右边耳朵。
transforms.RandomCrop # 随机位置裁剪 。transforms.CenterCrop叫从中间裁剪transforms.RandomHorizontalFlip(p=1) # 随机水平翻转。p代表比例,以一定的比例翻转过来transforms.RandomVerticalFlip(p=1) # 随机上下翻转transforms.RandomRotation # 随机旋转transforms.ColorJitter(brightness=1) # 进行颜色的随机变换。brightness明暗度,contrast对比度,saturation饱和度transforms.ColorJitter(contrast=1)transforms.ColorJitter(saturation=0.5)transforms.ColorJitter(hue=0.5) # 随机调整颜色transforms.RandomGrayscale(p=0.5) # 随机灰度化
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport numpy as npimport matplotlib.pyplot as pltimport torchvisionfrom torchvision import transformsimport osbase_dir = r'./datasets/4weather'train_dir = os.path.join(base_dir , 'train')test_dir = os.path.join(base_dir , 'test')"""(1)数据增强的方法"""transforms.RandomCrop # 随机位置裁剪。 transforms.CenterCrop(从中间裁剪)transforms.RandomHorizontalFlip(p=1) # 随机水平翻转(p是翻转比例)transforms.RandomVerticalFlip(p=1) # 随机上下翻转transforms.RandomRotation # 随机旋转transforms.ColorJitter(brightness=1) # 颜色随机。brightness明暗度transforms.ColorJitter(contrast=1) # 随机调整对比度transforms.ColorJitter(saturation=0.5) # 饱和度transforms.ColorJitter(hue=0.5) # 随机调整颜色transforms.RandomGrayscale(p=0.5) # 随机灰度化# 对于训练数据要进行数据增强,测试的时候没有必要数据增强train_transform = transforms.Compose([ transforms.Resize(224), transforms.RandomCrop(192), # 随机的从224的图片裁剪出192的图片出来;让这个模型每一次看到图片当中的不同位置 transforms.RandomHorizontalFlip(), # 随机的水平(左右)翻转。 transforms.RandomRotation(0.2), # 随机的旋转一个角度,角度是0.2(20度) transforms.ColorJitter(brightness=0.5), # 将图像的亮度随机变化为原图亮度的50%(1−0.5)∼150%(1+0.5) transforms.ColorJitter(contrast=0.5), # 随机的改变对比度 transforms.ToTensor(), transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5])])test_transform = transforms.Compose([ transforms.Resize((192, 192)), transforms.ToTensor(), transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5])])train_ds = torchvision.datasets.ImageFolder(train_dir,transform=train_transform)test_ds = torchvision.datasets.ImageFolder(test_dir,transform=test_transform)BTACH_SIZE = 16train_dl = torch.utils.data.DataLoader(train_ds,batch_size=BTACH_SIZE,shuffle=True)test_dl = torch.utils.data.DataLoader(test_ds,batch_size=BTACH_SIZE)model = torchvision.models.vgg16(pretrained=True)for param in model.features.parameters(): param.requires_grad = Falsemodel.classifier[-1].out_features = 4if torch.cuda.is_available(): model.to('cuda')loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.classifier.parameters(), lr=0.0001)学习速率衰减
# 学习速率衰减。取出optimizer的参数。人为# for p in optimizer.param_groups:# p['lr'] *= 0.9 # 以0.9的衰减系数衰减# pytorch为我们内置了学习速率衰减的方法from torch.optim import lr_scheduleroptimizer = torch.optim.Adam(model.classifier.parameters(), lr=0.001)exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.9) # StepLR根据步数进行学习速率的衰减。每隔7步,乘以gamma衰减系数。# .MultiStepLR(),根据一个milestones进行衰减,milestone是一个列表,比如[10,20]就是在10、20个epoch上进行衰减lr_scheduler.MultiStepLR(optimizer,[10,15,18,25],gamma=0.9)# .Exponentia1LR(optimizer,gamma=0.9)。在每一个epoch上进行衰减def fit(epoch, model, trainloader, testloader): correct = 0 total = 0 running_loss = 0 model('train') for x, y in trainloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): y_pred = torch.argmax(y_pred, dim=1) correct += (y_pred == y).sum().item() total += y.size(0) running_loss += loss.item() exp_lr_scheduler.step() # 记录经过了多少个epoch(运行了多少次fit函数),只要到达7步,就会衰减。 epoch_loss = running_loss / len(trainloader.dataset) epoch_acc = correct / total test_correct = 0 test_total = 0 test_running_loss = 0 model('eval') with torch.no_grad(): for x, y in testloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) y_pred = torch.argmax(y_pred, dim=1) test_correct += (y_pred == y).sum().item() test_total += y.size(0) test_running_loss += loss.item() epoch_test_loss = test_running_loss / len(testloader.dataset) epoch_test_acc = test_correct / test_total print('epoch: ', epoch, 'loss: ', round(epoch_loss, 3), 'accuracy:', round(epoch_acc, 3), 'test_loss: ', round(epoch_test_loss, 3), 'test_accuracy:', round(epoch_test_acc, 3) ) return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_accepochs = 10train_loss = []train_acc = []test_loss = []test_acc = []for epoch in range(epochs): epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model, train_dl, test_dl) # 人为的进行学习速率衰减 # if(epoch%5 == 0): # for p in optimizer.param_groups: # p['lr'] *= 0.9 train_loss.append(epoch_loss) train_acc.append(epoch_acc) test_loss.append(epoch_test_loss) test_acc.append(epoch_test_acc)plt.plot(range(1, epochs+1), train_loss, label='train_loss')plt.plot(range(1, epochs+1), test_loss, label='test_loss')plt.legend()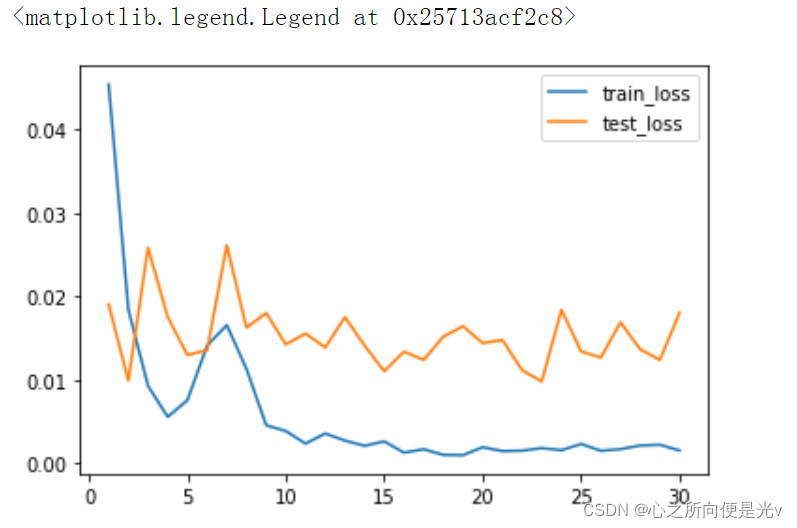
plt.plot(range(1, epochs+1), train_acc, label='train_acc')plt.plot(range(1, epochs+1), test_acc, label='test_acc')plt.legend()
四、预训练网络ResNet以及模型微调
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport numpy as npimport matplotlib.pyplot as pltimport torchvisionfrom torchvision import transformsimport osprint("一、RESNET预训练模型:")base_dir = r'./datasets/4weather'train_dir = os.path.join(base_dir , 'train')test_dir = os.path.join(base_dir , 'test')transform = transforms.Compose([ transforms.Resize((192, 192)), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])train_ds = torchvision.datasets.ImageFolder( train_dir, transform=transform )test_ds = torchvision.datasets.ImageFolder( test_dir, transform=transform )BTACH_SIZE = 32train_dl = torch.utils.data.DataLoader(train_ds,batch_size=BTACH_SIZE,shuffle=True)test_dl = torch.utils.data.DataLoader(test_ds,batch_size=BTACH_SIZE,)model = torchvision.models.resnet18(pretrained=True)print(model)for p in model.parameters(): p.requires_grad = False # 里面所有参数都是不可训练的# 我们只需将最后的线性层的out_features置换成我们分类的类别即可。可将最后的linear层替换成我们自己的linear层,我们自己的# linear层的requires_grad默认是True。in_f = model.fc.in_featuresmodel.fc = nn.Linear(in_f,4)# print("\nafter changed model:\n",model)# 将模型转移到GPU上if torch.cuda.is_available(): model.to('cuda')# 创建优化器optimizer = torch.optim.Adam(model.fc.parameters(),lr = 0.001)# 定义损失函数loss_fn = nn.CrossEntropyLoss()def fit(epoch, model, trainloader, testloader): correct = 0 total = 0 running_loss = 0 model.train() # 模型里面有Bn层,表现在训练时和预测时不一样。 for x, y in trainloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): y_pred = torch.argmax(y_pred, dim=1) correct += (y_pred == y).sum().item() total += y.size(0) running_loss += loss.item() # exp_lr_scheduler.step() epoch_loss = running_loss / len(trainloader.dataset) epoch_acc = correct / total test_correct = 0 test_total = 0 test_running_loss = 0 model.eval() with torch.no_grad(): for x, y in testloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) y_pred = torch.argmax(y_pred, dim=1) test_correct += (y_pred == y).sum().item() test_total += y.size(0) test_running_loss += loss.item() epoch_test_loss = test_running_loss / len(testloader.dataset) epoch_test_acc = test_correct / test_total print('epoch: ', epoch, 'loss: ', round(epoch_loss, 3), 'accuracy:', round(epoch_acc, 3), 'test_loss: ', round(epoch_test_loss, 3), 'test_accuracy:', round(epoch_test_acc, 3) ) return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_accepochs = 50train_loss = []train_acc = []test_loss = []test_acc = []for epoch in range(epochs): epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model, train_dl, test_dl) train_loss.append(epoch_loss) train_acc.append(epoch_acc) test_loss.append(epoch_test_loss) test_acc.append(epoch_test_acc)模型微调
所谓微调:就是共同训练新添加的分类器层和部分或者全部卷积层。这允许我们“微调”基础模型中的高阶特征表示,以使它们与特定任务更相关。
只有分类器已经训练好了,才能微调卷积基的卷积层。如果有没有这样的话,刚开始的训练误差很大,微调之前这些卷积层学到的表示会被破坏掉。
微调步骤:
- 1、在预训练卷积基上添加自定义层
- 2、冻结卷积基所有层
- 3、训练添加的分类层
- 4、解冻卷积基的一部分层
- 5、联合训练解冻的卷积层和添加的自定义层
-
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport numpy as npimport matplotlib.pyplot as pltimport torchvisionfrom torchvision import transformsimport osbase_dir = r'./datasets/4weather'train_dir = os.path.join(base_dir , 'train')test_dir = os.path.join(base_dir , 'test')train_transform = transforms.Compose([ transforms.Resize(224), transforms.RandomResizedCrop(192, scale=(0.6,1.0), ratio=(0.8,1.0)), transforms.RandomHorizontalFlip(), transforms.RandomRotation(0.2), torchvision.transforms.ColorJitter(brightness=0.5, contrast=0, saturation=0, hue=0), torchvision.transforms.ColorJitter(brightness=0, contrast=0.5, saturation=0, hue=0), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])test_transform = transforms.Compose([ transforms.Resize((192, 192)), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])train_ds = torchvision.datasets.ImageFolder( train_dir, transform=train_transform )test_ds = torchvision.datasets.ImageFolder( test_dir, transform=test_transform )BTACH_SIZE = 32train_dl = torch.utils.data.DataLoader(train_ds,batch_size=BTACH_SIZE,shuffle=True)test_dl = torch.utils.data.DataLoader(test_ds,batch_size=BTACH_SIZE,)model = torchvision.models.resnet101(pretrained=True)for param in model.parameters(): param.requires_grad = Falsein_f = model.fc.in_featuresmodel.fc = nn.Linear(in_f, 4)if torch.cuda.is_available(): model.to('cuda')loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)from torch.optim import lr_schedulerexp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.5)def fit(epoch, model, trainloader, testloader): correct = 0 total = 0 running_loss = 0 model.train() for x, y in trainloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): y_pred = torch.argmax(y_pred, dim=1) correct += (y_pred == y).sum().item() total += y.size(0) running_loss += loss.item() exp_lr_scheduler.step() epoch_loss = running_loss / len(trainloader.dataset) epoch_acc = correct / total test_correct = 0 test_total = 0 test_running_loss = 0 model.eval() with torch.no_grad(): for x, y in testloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) y_pred = torch.argmax(y_pred, dim=1) test_correct += (y_pred == y).sum().item() test_total += y.size(0) test_running_loss += loss.item() epoch_test_loss = test_running_loss / len(testloader.dataset) epoch_test_acc = test_correct / test_total print('epoch:', epoch, ',loss:', round(epoch_loss, 3), ',accuracy:', round(epoch_acc, 3), ',test_loss:', round(epoch_test_loss, 3), ',test_accuracy:', round(epoch_test_acc, 3) ) return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_accepochs = 30train_loss = []train_acc = []test_loss = []test_acc = []for epoch in range(epochs): epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model, train_dl, test_dl) train_loss.append(epoch_loss) train_acc.append(epoch_acc) test_loss.append(epoch_test_loss) test_acc.append(epoch_test_acc)"""微调。先将Linear层训练好之后才训练卷积层,这才是微调。"""for param in model.parameters(): # 解冻卷积部分 param.requires_grad = Trueextend_epochs = 30from torch.optim import lr_scheduleroptimizer = torch.optim.Adam(model.parameters(), lr=0.0001) # 优化模型的全部参数。微调时,训练的速率要小一些exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.5)for epoch in range(extend_epochs): epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model, train_dl, test_dl) train_loss.append(epoch_loss) train_acc.append(epoch_acc) test_loss.append(epoch_test_loss) test_acc.append(epoch_test_acc)plt.figure(0)plt.plot(range(1, len(train_loss)+1), train_loss, label='train_loss')plt.plot(range(1, len(train_loss)+1), test_loss, label='test_loss')plt.legend()plt.show()plt.figure(1)plt.plot(range(1, len(train_loss)+1), train_acc, label='train_acc')plt.plot(range(1, len(train_loss)+1), test_acc, label='test_acc')plt.legend()plt.show()五、模型权重保存
-
模型当作的权重(可训练参数)保存下来,训练前后,model的可训练参数发生变化。state_dict就是一个简单的Python字典,它将模型中的可训练参数(比如weights和biases,batchnorm的running_mean、torch.optim参数等)通过将模型每层与层的参数张量之间一一映射, 实现保存、更新、变化和再存储。
-
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport numpy as npimport matplotlib.pyplot as pltimport torchvisionimport osimport copyfrom torchvision import transformsbase_dir = r'./datasets/4weather'train_dir = os.path.join(base_dir , 'train')test_dir = os.path.join(base_dir , 'test')transform = transforms.Compose([ transforms.Resize((96, 96)), transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])train_ds = torchvision.datasets.ImageFolder( train_dir, transform=transform)test_ds = torchvision.datasets.ImageFolder( test_dir, transform=transform)BATCHSIZE = 16train_dl = torch.utils.data.DataLoader( train_ds, batch_size=BATCHSIZE, shuffle=True)test_dl = torch.utils.data.DataLoader( test_ds, batch_size=BATCHSIZE,)class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 16, 3) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(16, 32, 3) self.conv3 = nn.Conv2d(32, 64, 3) self.fc1 = nn.Linear(64*10*10, 1024) self.fc2 = nn.Linear(1024, 256) self.fc3 = nn.Linear(256, 4) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = self.pool(F.relu(self.conv3(x))) x = x.view(-1, 64 * 10 * 10) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xmodel = Net()if torch.cuda.is_available(): model.to('cuda')optim = torch.optim.Adam(model.parameters(), lr=0.001)loss_fn = nn.CrossEntropyLoss()def fit(epoch, model, trainloader, testloader): correct = 0 total = 0 running_loss = 0 model.train() for x, y in trainloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) optim.zero_grad() loss.backward() optim.step() with torch.no_grad(): y_pred = torch.argmax(y_pred, dim=1) correct += (y_pred == y).sum().item() total += y.size(0) running_loss += loss.item() epoch_loss = running_loss / len(trainloader.dataset) epoch_acc = correct / total test_correct = 0 test_total = 0 test_running_loss = 0 model.eval() with torch.no_grad(): for x, y in testloader: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = model(x) loss = loss_fn(y_pred, y) y_pred = torch.argmax(y_pred, dim=1) test_correct += (y_pred == y).sum().item() test_total += y.size(0) test_running_loss += loss.item() epoch_test_loss = test_running_loss / len(testloader.dataset) epoch_test_acc = test_correct / test_total print('epoch:', epoch, ',loss:', round(epoch_loss, 3), ',accuracy:', round(epoch_acc, 3), ',test_loss:', round(epoch_test_loss, 3), ',test_accuracy:', round(epoch_test_acc, 3) ) return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_accepochs = 10train_loss = []train_acc = []test_loss = []test_acc = []for epoch in range(epochs): epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model, train_dl, test_dl) train_loss.append(epoch_loss) train_acc.append(epoch_acc) test_loss.append(epoch_test_loss) test_acc.append(epoch_test_acc)"""保存模型"""# 模型当作的权重(可训练参数)保存下来,训练前后,model的可训练参数发生变化。# state_dict就是一个简单的Python字典,它将模型中的可训练参数# (比如weights和biases,batchnorm的running_mean、torch.optim参数等)通过将模型每层与层的参数张量之间一一映射,# 实现保存、更新、变化和再存储。model.state_dict() # 这个方法会返回模型可训练参数的当前状态,返回的是python字典PATH = './my_net.pth' # 将模型的参数保存的位置torch.save(model.state_dict(), PATH) # 当前模型权重参数# 如何去加载刚刚保存好的模型呢?现在保存的只是模型的参数,我们需要定义模型本身(重新初始化模型)# 我们现在的保存模型参数的方法,需要将模型代码,类,保存起来。# 重新初始化类,得到一个新的模型new_model = Net() # 新的模型的参数是随机初始化的参数new_model.load_state_dict(torch.load(PATH)) # 将参数加载进模型new_model.to('cuda')test_correct = 0test_total = 0new_model.eval()with torch.no_grad(): for x, y in test_dl: if torch.cuda.is_available(): x, y = x.to('cuda'), y.to('cuda') y_pred = new_model(x) y_pred = torch.argmax(y_pred, dim=1) test_correct += (y_pred == y).sum().item() test_total += y.size(0)epoch_test_acc = test_correct / test_totalprint(epoch_test_acc)"""训练函数保存最优参数。在训练的epoch上,保存最优参数的那一次epoch"""best_model_wts = copy.deepcopy(model.state_dict()) # 深拷贝best_acc = 0.0train_loss = []train_acc = []test_loss = []test_acc = []for epoch in range(epochs): epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model, train_dl, test_dl) train_loss.append(epoch_loss) train_acc.append(epoch_acc) test_loss.append(epoch_test_loss) test_acc.append(epoch_test_acc) if epoch_test_acc > best_acc: best_acc = epoch_acc best_model_wts = copy.deepcopy(model.state_dict())model.load_state_dict(best_model_wts)model.eval()完整模型的保存和加载
- torch.save(model.state_dict(), PATH) 只保存模型参数。
-
PATH = './my_whole_model.pth'torch.save(model, PATH)new_model2 = torch.load(PATH)new_model2.eval()

