Java工作流Activity开发_activity工作流开发步骤
在 Java 项目中,使用 Activiti 或 Camunda 等工作流引擎可以实现业务流程的自动化管理(如审批流、订单处理等)。以下是基于 Activiti 的工作流开发全流程指南,涵盖设计、集成和实战示例。
一、Activiti 核心概念
-
BPMN 2.0
-
标准化的业务流程建模符号(通过 XML 定义流程,如
.bpmn文件)。
-
-
关键组件
-
ProcessEngine:工作流引擎核心,管理所有服务。
-
RepositoryService:部署流程定义(BPMN文件)。
-
RuntimeService:启动流程实例。
-
TaskService:处理用户任务(如审批)。
-
HistoryService:查询历史记录。
-
二、开发环境搭建
1. 依赖引入(Maven)
org.activiti activiti-engine 7.1.0.M6 org.activiti activiti-spring-boot-starter 7.1.0.M62. 数据库配置
Activiti 默认使用 H2 内存数据库,生产环境需切换为 MySQL/PostgreSQL:
# application.properties (Spring Boot)spring.datasource.url=jdbc:mysql://localhost:3306/activiti?useSSL=falsespring.datasource.username=rootspring.datasource.password=123456spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driveractiviti.database-schema-update=true # 自动建表三、工作流开发步骤
1. 设计 BPMN 流程
使用工具(如 Activiti Modeler、Camunda Modeler)绘制流程图:
-
定义用户任务(User Task)、网关(Gateway)、服务任务(Service Task)等。
-
示例:请假审批流程
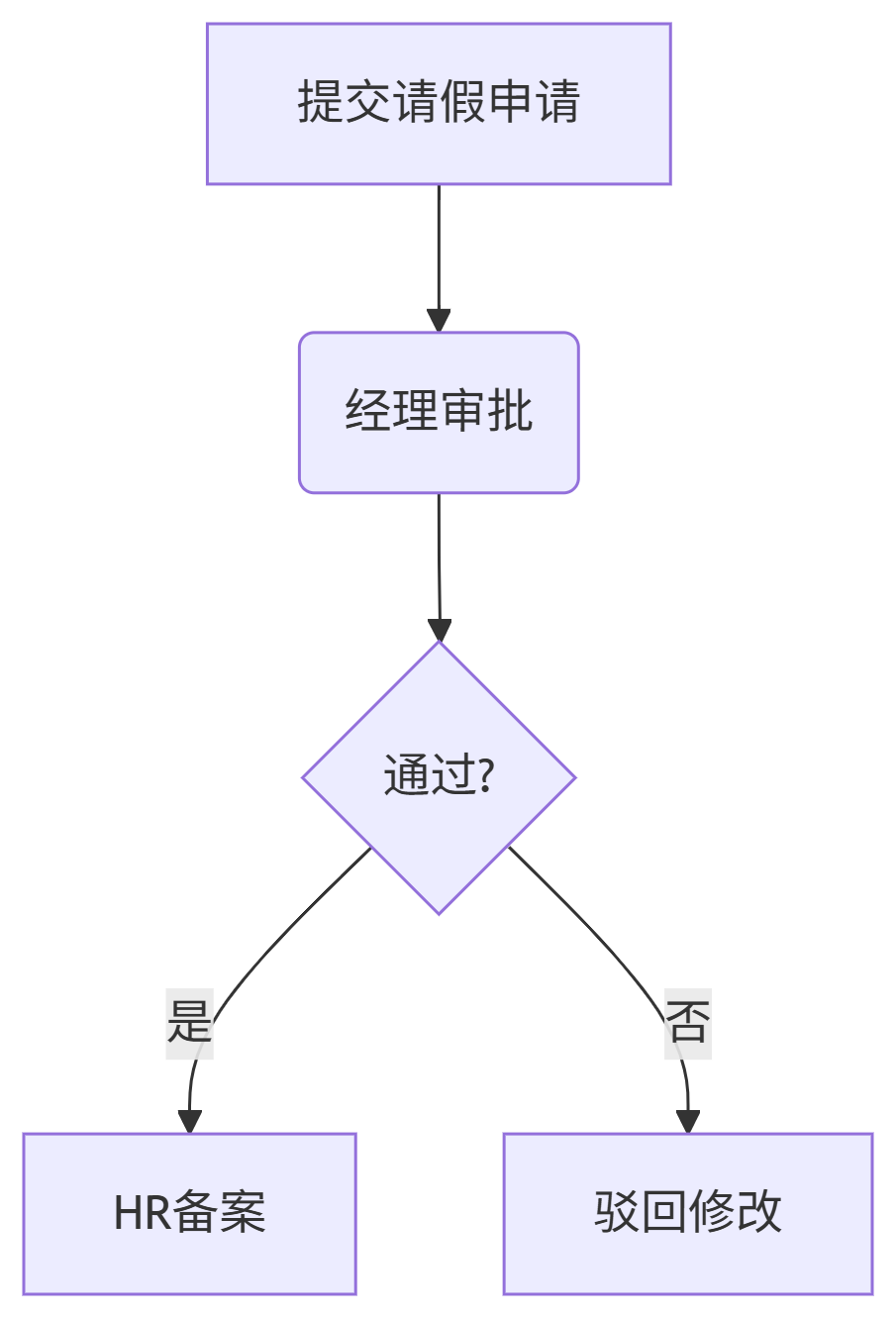
2. 部署流程定义
ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();RepositoryService repositoryService = processEngine.getRepositoryService();// 部署 BPMN 文件Deployment deployment = repositoryService.createDeployment() .addClasspathResource(\"processes/leave-request.bpmn20.xml\") .deploy();System.out.println(\"流程部署ID: \" + deployment.getId());3. 启动流程实例
RuntimeService runtimeService = processEngine.getRuntimeService();// 设置流程变量(如申请人、请假天数)Map variables = new HashMap();variables.put(\"employee\", \"张三\");variables.put(\"days\", 3);// 启动流程ProcessInstance instance = runtimeService.startProcessInstanceByKey(\"leaveRequest\", variables);4. 处理用户任务
TaskService taskService = processEngine.getTaskService();// 查询某用户的任务列表List tasks = taskService.createTaskQuery() .taskAssignee(\"经理李四\") .list();// 完成任务for (Task task : tasks) { taskService.complete(task.getId(), Collections.singletonMap(\"approved\", true));}5. 监听与自动化
通过 Java Delegate 实现服务任务自动化:
public class NotifyHRDelegate implements JavaDelegate { @Override public void execute(DelegateExecution execution) { String employee = (String) execution.getVariable(\"employee\"); System.out.println(\"通知HR处理员工: \" + employee); }}在 BPMN 中配置:
四、高级功能
1. 与 Spring Boot 集成
-
自动注入
ProcessEngine和各类 Service。 -
使用
@ActivitiListener注解监听事件。
2. REST API 暴露
通过 activiti-rest 模块提供 HTTP 接口,供前端调用:
@RestController@RequestMapping(\"/api/process\")public class ProcessController { @Autowired private RuntimeService runtimeService; @PostMapping(\"/start\") public String startProcess(@RequestBody Map variables) { ProcessInstance instance = runtimeService.startProcessInstanceByKey(\"leaveRequest\", variables); return \"流程启动: \" + instance.getId(); }}3. 动态流程控制
-
动态调整流程节点:通过
RuntimeService.suspendProcessInstanceById暂停流程。 -
条件路由:在 BPMN 中使用
${days > 3}表达式控制分支。
五、实战注意事项
-
事务管理
-
Activiti 默认集成 Spring 事务,确保业务操作与流程状态同步提交/回滚。
-
-
性能优化
-
避免频繁查询历史表,使用
HistoryService时添加分页条件。
-
-
日志监控
-
启用
activiti.eventlogging记录关键事件,便于审计。
-
六、可视化与调试
-
Activiti Admin
-
监控运行中的流程实例、任务分布。
-
-
日志整合
-
结合 ELK 收集流程引擎日志,分析瓶颈。
-
示例项目结构
src/main/resources/processes/ ├── leave-request.bpmn20.xml # 流程定义文件src/main/java/com/example/ ├── delegate/NotifyHRDelegate.java # 服务任务逻辑 ├── controller/ProcessController.java # REST接口 └── Application.java # Spring Boot 入口总结
通过 Activiti 实现 Java 工作流开发的核心步骤:
-
设计 BPMN 流程图 → 2. 部署流程定义 → 3. 启动和处理实例 → 4. 集成业务逻辑。
适合需要严格流程控制的场景(如金融审批、供应链管理)。对于轻量级需求,也可考虑 Flowable 或 Camunda。

