论文速读《UniVLA:让机器人学会通用技能的新方法》
代码:https://github.com/OpenDriveLab/UniVLA
相关论文:https://arxiv.org/pdf/2505.06111
0. 简介
如何让机器人在各种环境中高效工作是当前AI领域的重大挑战。传统方法往往依赖大量带标注的动作数据,这使得机器人很难从一个场景迁移到另一个场景,更难以适应不同的物理形态。
UniVLA(通用视觉-语言-动作框架)通过一个巧妙的方法解决了这个问题。它引入了\"任务中心的潜在动作\"概念,让机器人能够从互联网视频中学习,并将知识迁移到不同环境和不同机器人平台。最令人印象深刻的是,UniVLA在计算资源只有OpenVLA(之前最先进方法)的1/20、训练数据仅有其1/10的情况下,性能表现却大幅领先。
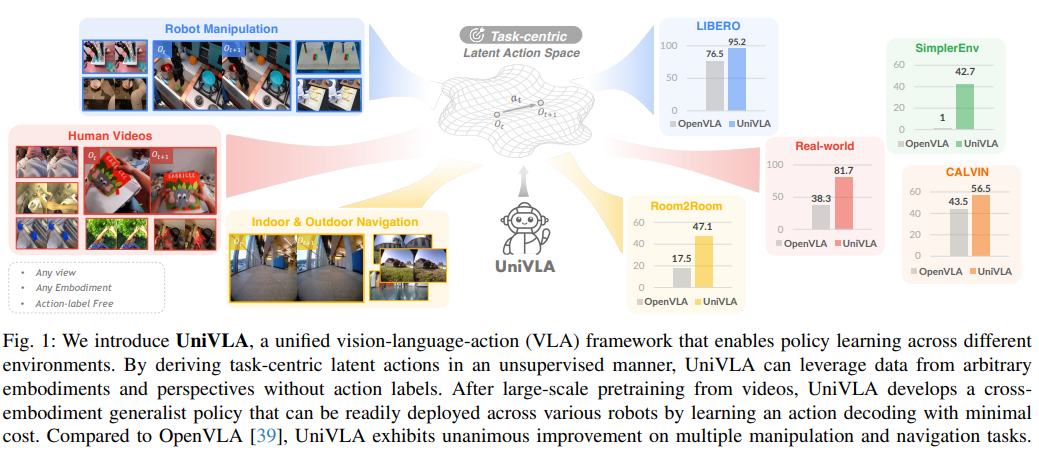
图1:UniVLA框架能够通过无监督方式从视频中学习动作,实现跨平台知识迁移,并在各类机器人上便捷部署。
1. 主要贡献
UniVLA的创新主要体现在三个方面:
-
统一动作空间:创造了一个与机器人形态无关的统一潜在动作空间,让机器人能够从互联网视频中学习通用技能,实现高效决策。
-
智能动作提取:开发了从多种视频中提取与任务相关的潜在动作的新方法,成功分离出核心动作与无关视觉变化,大幅提升学习效率。
-
跨平台卓越表现:在多项测试和实机部署中表现优异,比之前最好的系统OpenVLA在各项任务中提升显著(LIBERO基准+18.5%,导航任务+29.6%,实际部署+36.7%)。
2. 核心思路解析
2.1 视觉-语言-动作模型的演进
近年来,视觉-语言-动作(VLA)模型取得了长足进步。RT系列和OpenVLA等模型通过大量数据训练,让机器人能够执行语言指令。但这些方法存在两个主要问题:①直接在底层动作空间规划效率低;②需要大量带标签的数据。
UniVLA的创新之处在于,它不需要直接学习具体的机器人动作,而是从视频变化中学习通用的\"动作表征\",这使得它能够利用海量无标注的互联网视频进行学习。
2.2 跨平台知识迁移
传统的机器人学习面临相机视角、关节构造、动作空间等差异带来的挑战,导致在一个平台上学到的知识很难迁移到另一个平台。
现有方法如BC-Z和Octo尝试通过构建统一动作表示来处理这个问题,但往往需要手动对齐不同系统的动作空间。UniVLA则通过学习统一的潜在动作表征,自然地实现了跨平台知识迁移,无需额外的对齐步骤。
2.3 潜在动作学习的突破
之前的潜在动作学习方法(如LAPA、Genie等)存在一个关键问题:它们往往会捕获大量与任务无关的视觉变化,如相机抖动或背景物体移动,这些\"噪声\"会干扰模型学习真正重要的动作。
UniVLA通过巧妙的两阶段设计,成功将任务相关的动作与无关的视觉变化分离开来,构建了更加有效的动作表示空间。
3. UniVLA工作原理
UniVLA通过三个关键步骤实现智能机器人控制:
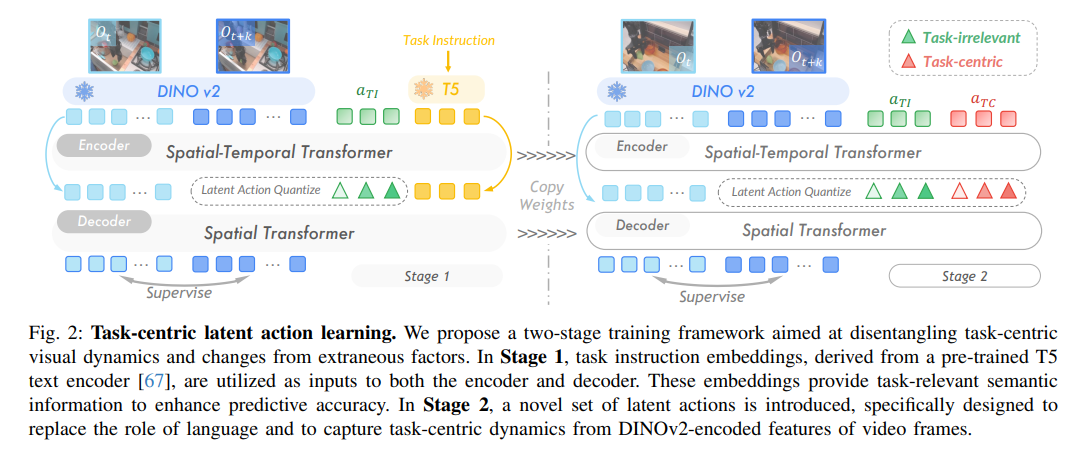
图2:UniVLA的两阶段潜在动作学习框架,有效分离任务相关动态与外部视觉变化。
3.1 智能动作提取
第一步是从视频中提取\"伪动作标签\"(潜在动作),为后续的策略学习打下基础。
动作量化:系统分析连续视频帧之间的变化,使用编码器和解码器架构来捕获动作信息。与传统方法不同,UniVLA不直接处理原始像素,而是利用DINOv2特征作为语义丰富的表征,这种表征更关注物体和空间关系,而非纹理和光照等无关细节。
动作解耦:为解决网络视频中动作与无关视觉变化混杂的问题,UniVLA设计了两阶段训练流程:
- 首先融入语言指令,建立包含环境变化、物体出现等信息的表征
- 在此基础上,专注学习与任务相关的动态表征
这种明确的解耦大大增强了模型在不同环境和任务中的泛化能力。
3.2 通用策略训练
有了潜在动作后,UniVLA基于Prismatic-7B视觉-语言模型构建通用策略。它通过添加特殊标记扩展词汇表,让模型能够预测下一个潜在动作。
最令人惊讶的是,这种压缩后的动作空间(仅164维,远低于OpenVLA的2567维)大大加速了模型收敛。UniVLA仅用960个GPU小时就取得了与OpenVLA(需要21500小时)相当甚至更好的结果。
3.3 实际部署优化

图3:UniVLA的策略架构,利用轻量级解码器将潜在动作转化为实际机器人控制信号。
动作解码:为将抽象的潜在动作转变为实际机器人可执行的指令,UniVLA设计了轻量级动作解码器。通过注意力机制,系统能够根据视觉信息提取相关动作特征,并将其映射到特定机器人的控制信号。
历史学习:受大语言模型\"思维链\"启发,UniVLA将历史动作作为上下文反馈给模型,形成闭环学习。这种设计显著提高了长期任务的执行效果,同时避免了传统方法需要处理大量历史视觉数据带来的计算负担。
4. 实验效果展示
4.1 操作任务表现
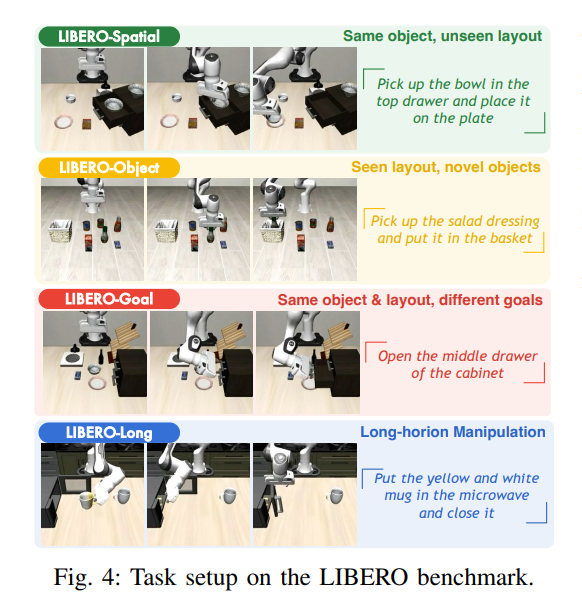
图4:LIBERO基准测试中的各类任务设置
在LIBERO操作基准测试中,UniVLA平均成功率达95.4%,远超其他方法。即使仅在有限数据上训练,其平均成功率也能达到93.0%,展现出强大的学习效率。
4.2 导航能力测试
在Room2Room导航测试中,UniVLA将成功率从基线的8.10%提升到了47.1%,超越了需要处理全部历史观察的复杂模型,展现出其轻量高效的优势。
4.3 实机测试效果
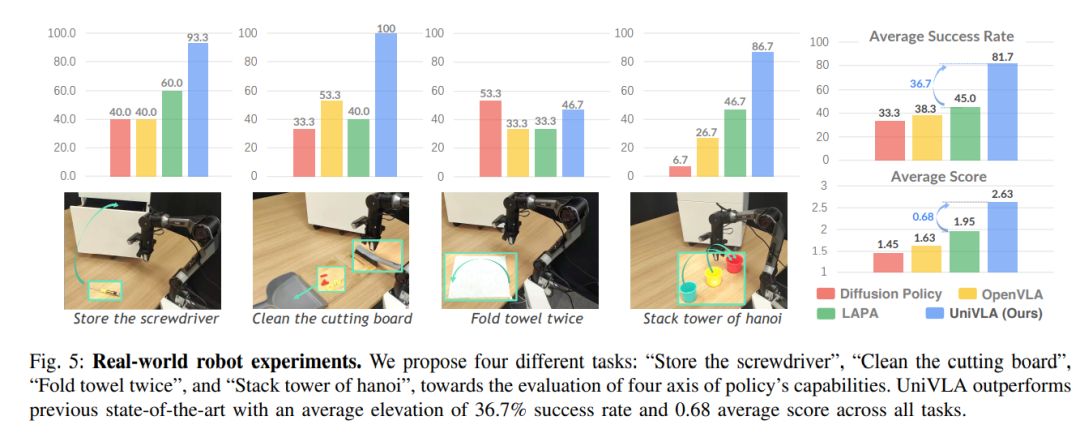
图5:真实机器人上的四种测试任务,全面检验系统的空间感知、工具使用、物体操作和语义理解能力。
在真实机器人测试中,UniVLA在四项复杂任务上表现出色:存放工具、清洁案板、折叠毛巾和汉诺塔堆叠。尤其在需要语义理解的任务中,如汉诺塔堆叠,成功率高达86.7%。
比最近的技术高出36.7%的成功率,同时在RTX 4090上实现10Hz的实时控制,展示了其在实际应用中的卓越表现。
4.4 数据扩展性
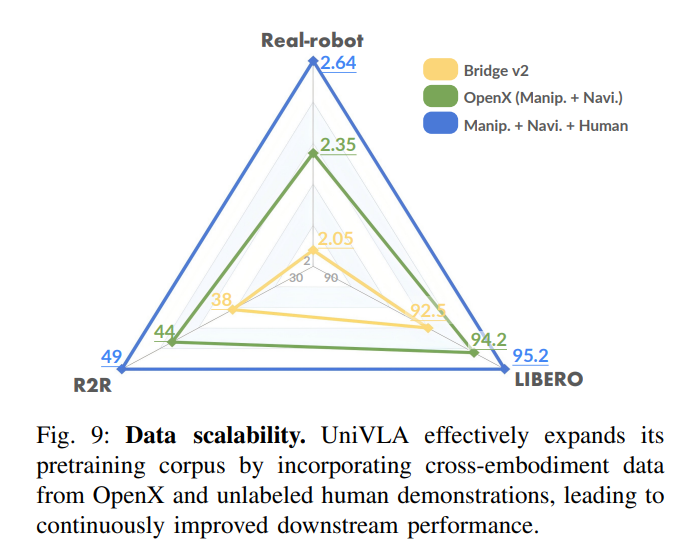
图9:UniVLA能够有效利用更多数据持续提升性能,展现出优秀的可扩展性。
与许多模型在数据增加后性能提升有限不同,UniVLA展示出优秀的数据可扩展性:随着训练数据增加,模型性能持续提升。即使在少量数据条件下,它也表现出色,仅用10%的训练数据就超过了其他方法使用全部数据的效果。
5. 总结与展望
UniVLA开创了一种新型机器人学习范式,通过任务中心的潜在动作表征,实现了跨平台、高效的知识迁移。它的核心创新在于:
- 从视频中智能提取与任务相关的动作表征,有效分离核心动作和无关视觉变化
- 在统一的潜在空间中进行高层规划,提升了模型在多种场景中的适应性
- 大幅降低了计算和数据需求,以极低的成本取得了领先性能
随着这类技术的发展,我们有望看到更加智能、通用的机器人系统,它们能够自然地适应各种复杂环境,执行多样化任务,为机器人技术的广泛应用铺平道路。

