一文通透GR00T N1和N1.5——英伟达开源的通用人形VLA:VLM Eagle-2慢思考、DiT快反应,且可类似LAPA利用海量的无标注视频做训练_智元 英伟达 比较
前言
就在昨天3.19日的凌晨,英伟达发布的GR00T N1还是很有含金量的(上午已有好几个朋友私我了),由此可以看到很多相关工作的影子,比如helix π0 LAPA,具体而言,其具有双系统架构
- VLM模块(系统2)通过视觉和语言指令解释环境,在NVIDIA L40 GPU上以10Hz运行
- 随后的扩散transformer「类似CogACT的VLM + DiT的构成」,即DiT模块(系统1)实时生成流畅的运动动作(120Hz)
总之,如我在我司具身实战营回答一学员朋友的,N1把近期的这三个工作:
- 无监督视频数据的利用
类似Google Genie、LAPA/moto、ViLLA) - 慢推理、快反应的双系统
类似Helix,Helix详见《Helix——Figure 02发布的通用人形机器人控制VLA:不用微调即可做多个任务的快与慢双系统,让两个机器人协作干活(含清华HiRT详解)》 - 以及VLA
详见此系列《通用机械臂之路: π0等VLA sota模型》
再次向前迈进了一步『至于3.18日晚上计划的fourier-lerobot对idp3的封装解读,则作为这两天的第二篇』
再之后,25年6.11,英伟达再次推出了GR00T N1的升级版GR00T N1.5,故本文第二部分介绍这个N1.5
PS,我司「七月在线」也准备在一个人形项目中 试下这个GR00T N1,欢迎私我一两句自我简介(比如在哪个公司做什么,或在哪个高校研几什么业),邀请进:『七月具身:VR摇操与GROOT群』
顺便说个事,随着我司「七月在线」接的B端大客户具身订单越来越多了,非常缺人
- 除了现有长沙、南京的具身团队之外,我司将在25年Q2之内,在上海也建立一支全职具身团队
需要做过至少1年的具身算法开发(比如模仿学习、RL、VLA之类的),且有真机部署经验,有意私我- 整个团队完成一个个项目的过程中,对个人的挑战、锻炼、提高都将极大,当然 硕士实习生也需要
第一部分 GR00T N1的原理详解
1.1 GR00T N1的提出背景与相关工作
1.1.1 GR00T N1
通过本博客之前的文章可知,目前机器人可用的训练数据大概有三类,且如果类似英伟达把这三类数据汇总成一个金字塔的话,则从上至下是

- 真实机器人的轨迹数据,下文2.2.4节详述
真实世界中通过物理机器人硬件收集的数据则是顶层 - 合成生成的数据集,含视频生成数据、仿真数据,下文2.2.2、2.2.3节详述
通过物理模拟生成的合成数据——即synthetic data generated with physics simulations,比如仿真数据
对于后者,他们使用预训练的视频生成模型生成合成的神经轨迹——就是模型预测的行为。通过这种方式,将内部收集的遥操作轨迹从88小时增加到827小时,即数据金字塔的“峰值”,使用了带有新语言指令的多样化反事实机器人轨迹(diverse counterfactual robot trajectories)
- 网络数据,与(带标注或无标注的)人类视频数据集,下文2.2.1节详述
大量的网络数据和人类视频构成金字塔的底层基础
当然,其中有相当一部分的图像-文本数据可以是作为VLM的预训练数据的,而当VLM赋能机器人时,VLM这部分的预训练数据便成为了机器人的知识之一
金字塔的底层提供广泛的视觉和行为先验,而顶层则确保了在具身的真实机器人执行中的落地性
英伟达在GR00T N1的训练中,为了全部利用上这三类数据,特别是为了使用无动作标签的数据源(例如人类视频和视频生成模型生成的视频)训练的模型,他们
- 类似LAPA「LAPA的介绍详见此文《ViLLA——继AgiBot World之后,智元发布GO1及其背后基于潜在动作的VLA架构ViLLA:利用海量的无标注视频做训练(含LAPA、Moto的详解)》的第二部分」,也学习了一个latent-action codebook

- 并且使用了一个经过训练的逆向动力学模型「IDM,特指Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos」来推断伪动作
“ 使用少量标记数据,训练一个足够准确的逆动力学模型,以标记大量未标记的在线数据源(这里是人们玩 Minecraft 的在线视频),然后从中训练一般的行为先验 ”
如此,使得能够为无动作的视频注释动作,从而有效地将它们视为模型训练的额外机器人embodiments
- 总之,他们通过统一数据金字塔中的所有数据源,构建了一个一致的数据集,其中输入包括机器人状态、视觉观察和语言指令,而输出是相应的电机动作
然后,他们在三个数据层上端到端地预训练他们的模型——通过在这种异构数据混合中采样训练批次来实现 - 毕竟,即便是OpenX这样的机器人数据集,汇集来自许多不同机器人的训练数据。但机器人在体型结构、传感器、执行器自由度等方面的巨大差异,使得这部分数据在用来训练时,也得先做一定的处理的,比如类似RDT做的「1.2.1 解决数据异构性问题,且兼容多个模态的输入」
1.1.2 相关工作:具身模型、训练数据来源
近年来,对于具身模型的开发,一般有两种方法
- 一种常见的方法是将现有的预训练基础模型作为高层黑箱推理模块,与低层机器人特定策略相结合
Brohan 等,2023,RT-2
Driess 等,2023, Palm-e
Huang 等,2023, Inner monologue: Embodied reasoning through
planning with language models,Grounded decoding: Guiding text generation with grounded models for embodied agents
Liang 等,2023,Code as policies: Language model programs for embodied control
Lin 等,2023,Text2motion: from natural language instructions to feasible plans
Singh 等,2023,Progprompt: Generating situated robot task plans using large language models
这种方法使机器人能够使用预训练的基础模型规划低层技能或动作的序列。然而,这种方法假设了低层策略的可用性以及一个足够的接口来将它们连接到黑箱基础模型 - 另一种方法是对预训练的基础模型进行针对机器人数据的微调,以构建VLA模型
Black 等,2024,π0
Brohan 等,2022,2023,RT-1,RT-2
Cheang 等,2024, Gr-2
Huang 等,2024,An embodied generalist agent in 3d world
Kim 等,2024,Openvla
Li等,2023,Vision-language foundation models as effective robot imitators
Wen 等,2024,Tinyvla: Towards fast, data-efficient vision-language-action models for
robotic manipulation
Yang 等,2025, Magma: A foundation model for multimodal AI agents
Ye 等,2025, Latent action pretraining from videos,即LAPA
Zhen 等,2024, 3d-vla: 3d vision-language-action generative world model
Zheng等,2025, TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies与在高层视觉语言模型(VLM)规划和低层控制之间强制实施严格的层级结构不同,这些 VLA 模型允许针对下游部署任务进行端到端优化
英伟达采用类似上面第二种 微调的方法来训练 GR00T N1,并使用 Eagle-2 模型「Li 等2025-Eagle 2: Building post-training data strategies from scratch for frontier vision-language models」作为视觉语言模型VLM
且他们将 VLM 与基于流匹配的
- Hu 等2024-LoRA: Low-rank adaptation of large language models
- Lipman 等- Flow matching for generative modeling
- Liu 等2022-Flow straight and fast: Learning to generate and transfer data with rectified flow
动作生成模型,和动作分块模型「Zhao 等2023-ALOHA ACT」一起进行微调,且
- 与之前使用专家混合架构(将基础 VLM 模型与动作生成模型Gemma连接)的VLA 模型π0 相比,GR00T N1使用了简单的交叉注意力机制
这种方法在可以使用的 VLM 模型和动作生成模型的具体架构方面提供了灵活性 - 此外,他们使用了针对特定机器人实现的状态和动作投影模块——这些模块支持不同的机器人实现,包括潜在的LAPA(Ye 等,2025)和基于IDM (Baker 等2022-Video pretraining (vpt): Learning to act by watching unlabeled online videos) 的动作
这些投影器的使用类似于 Octo Model Team 等(2024,即Octo: An open-source generalist robot policy)中的那些,尽管该工作并未对 VLM 模型进行微调
而对用于机器人学习的数据集上,分为遥操采集、手持夹爪采集、视频数据集
- 一种常见的方法是使用机器人远程操作『Al-daco 等,2024;Dass 等,2024;Fu 等,2024;Iyer 等;Mandlekar 等,2018,2019,2020;Wu 等,2023;Zhang 等,2018;Zhao 等,2023』,即人类使用智能手机,或虚拟现实VR控制器等设备来控制机器人执行感兴趣的任务
机器人在运行期间的传感器数据流和机器人控制指令(The robot sensor streams and robot controls)会被记录到一个数据集中,从而能够收集到高质量的任务演示最近,通过利用大型人类操作团队和机器人队列在较长时间内(例如数月)进行操作,这种方法得到了扩展,生成了包含数千小时演示的大规模机器人操作数据集
AgiBot-World-Contributors 等,2025
Black 等,2024
Brohan 等,2022,2023
Ebert 等,2022
Lynch 等,2023
O’Neill 等,2024然而,以这种方式收集数据需要大量的成本和人力投入
- 另一个方向是使用特殊设备进行的人类演示硬件用于捕获与机器人相关的观察和动作数据,而无需明确地远程操作目标机器人
例如
这些方法通常能更快地收集数据,但与直接远程操作机器人相比,它们与下游机器人存在一定的不匹配
- 另一种研究方向利用人类视频数据集『Damen等人,2018;Goyal等人,2017;Grauman等人,2022,2024;Miech等人,2019』,作为机器人训练数据的来源,这些数据集丰富且比在机器人上收集数据容易得多
一些研究「Karamcheti等人,2023;Nair等人,2022;Wu等人,2023」使用人类视频数据集来预训练表示,然后将这些表示用作下游机器人数据集上训练策略的特征空间
其他研究「Bharadhwaj等人,2024;Ren等人,2025」尝试通过视频中动作的中间表示联合使用人类视频数据和机器人数据
Ye等人(2025)的LAPA表明,仅在人类视频上预训练潜在动作的VLAs对下游机器人任务具有正向迁移作用
最终,英伟达的本项工作,能够有效地从多种真实世界的机器人数据、人类视频数据和合成数据中学习,而不是依赖于单一类型的训练数据
对于机器人领域的合成数据生成
- 现实世界中的机器人数据收集需要大量时间和相当高的人力成本。相比之下,在模拟环境中收集数据可以更加高效且轻松,这使其成为一种引人注目的替代方案
最近,一些研究『Dalal 等,2023;Garrett 等,2024;Gu 等,2023;Ha等,2023;James 等,2020;Jiang 等,2024;Mandlekar 等,2023;Nasiriany 等,2024;Wang 等,2024;Yang 等,2025』提出了自动化的数据生成管道,可以利用模拟生成数千个任务演示,几乎不需要人力。这使得生成大规模数据集变得容易;
然而,由于模拟到现实的差距,利用这些数据集可能会面临挑战
- 另一个有前途的方向是使用神经生成模型来扩充现有的机器人示范集(Chen等人,2023;Mandi等人,2022;Yu等人,2023)
然而,以往的工作局限于利用图像补全或文本到图像扩散模型来扩充训练数据在英伟达的工作中,他们利用了视频生成模型的最新进展
Agarwal等人 2025——Cosmos world foundation model platform for physical ai
Wan团队 2025——Wan: Open and advanced large-scale video generative models
来创建完整的神经轨迹,其规模前所未有:大约30万条神经轨迹,相当于827小时的机器人轨迹在他们的模型中,他们利用了由MimicGen(Mandlekar等,2023)和DexMimicGen(Jiang等,2024)生成的大型合成模拟数据集,以及通过最先进的视频生成模型生成的神经生成视频数据集
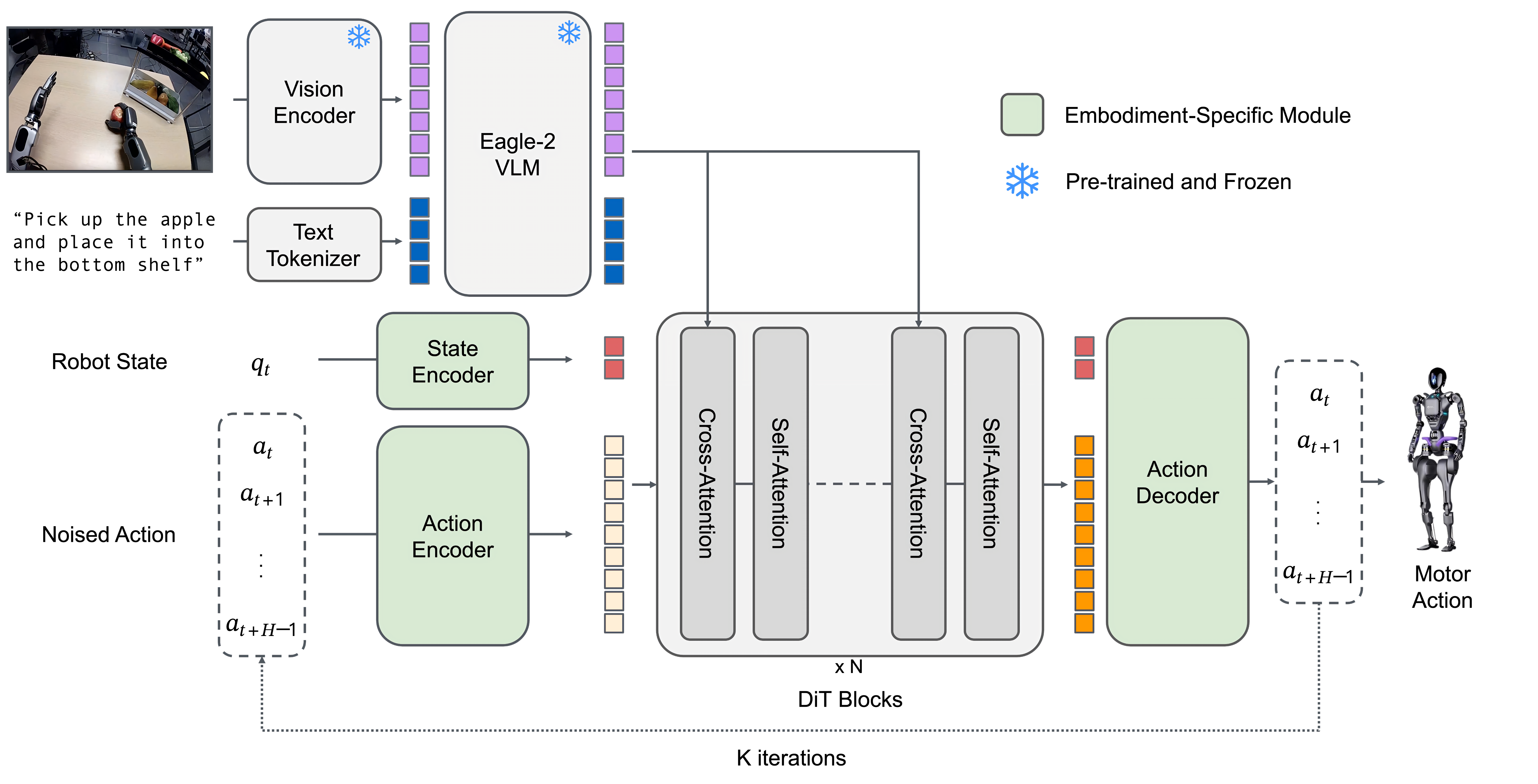
1.2 GR00T N1 基础模型:推理模块VLM + 动作模块DiT
GR00T N1 模型包含

- 一个视觉-语言骨干网络作为推理模块system 2,用于编码语言和图像输入
对于VLM的选择上,他们使用 NVIDIA Eagle-2 VLM作为视觉-语言骨干网络,且在N1-2B模型总计2.2B参数中,VLM的部分占1.34B - 以及一个基于DiT 的流匹配策略作为动作模块system 1,用于输出高频动作
他们在 L40 GPU 上使用 bf16 进行推理时,采样 16 个动作片段的推理时间为 63.9 毫秒,且作为一个大规模多任务的语言条件策略,该策略支持各种机器人结构,并通过高效的后训练之后,可以实现对新任务的快速适应
1.2.1 状态编码器与动作编码器:分别对机器人的本体感知状态和噪声化动作进行编码
进一步而言,如下图图3所示,对于动作模块DiT而言,其处理机器人的本体感知状态和(噪声化的)动作,然后与来自Eagle-2 VLM主干网络的图像和文本token进行交叉注意力计算,以输出去噪后的电机动作

- 为了处理不同机器人结构中状态和动作维度的差异,他们为每种结构分别采用一个多层感知机MLP,将其投影到一个共享的嵌入维度,以作为 DiT 的输入
且如π0所述,动作编码器MLP还会将扩散时间步与噪声动作向量一起编码 - 最终使用动作流匹配方法,通过迭代去噪采样动作。模型以噪声化的动作Noised Action作为输入,此外还包括机器人的本体感知状态编码Robot State、图像token和文本token
且类似ALOHA ACT,动作按块处理,这意味着在任意时刻,模型使用
,其中包含从时刻
的动作向量。在他们的实现中,设置的
1.2.2 视觉-语言模块(系统2):对视觉和语言输入进行编码
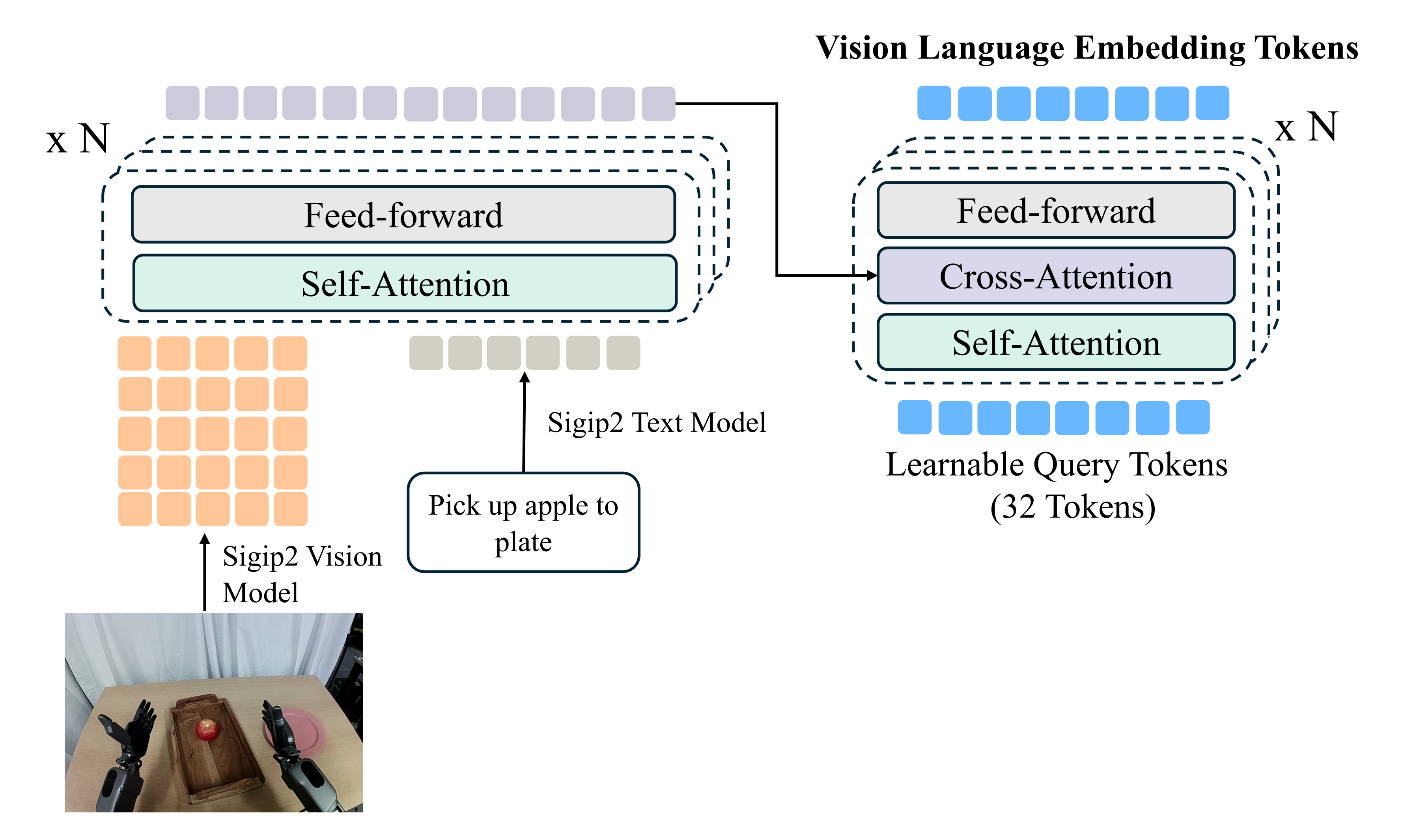
为了对视觉和语言输入进行编码,GR00T N1 使用了 Eagle-2 VLM,该模型在互联网规模的数据上进行了预训练,Eagle-2 是从 SmolLM2和 SigLIP-2图像编码器 微调而来的
- 图像以 224×224 的分辨率进行编码,然后进行像素重排,每帧生成 64 个图像token嵌入
这些嵌入随后与文本一起由 Eagle-2 VLM 的 LLM 组件进一步编码
LLM 和图像编码器在一组广泛的视觉-语言任务上进行了对齐,遵循了Eagle 2提出的一般方法 - 在策略训练期间,任务的文本描述以及(可能是多张)图像以视觉-语言训练中使用的聊天格式输入到VLM中
然后,从LLM 中提取形状为(批量大小× 序列长度× 隐藏维度,batch size × sequence length × hidden dimension)的视觉-语言特征
他们发现,使用中间层而不是最终层的LLM 嵌入,不仅推理速度更快,而且下游策略的成功率更高。对于GR00T-N1-2B,他们使用第12 层的表示
1.2.3 扩散transformer-DiT模块(系统1):综合上面的4个输入,对动作进行建模、预测
为了对动作进行建模,GR00T N1 使用了 DiT 的一种变体,这是一种通过自适应层归一化进行去噪步骤调节的transformer「For modeling actions, GR00T N1 uses a variant of DiT (Peebles and Xie, 2023), which is a transformer with denoising step conditioning via adaptive layer normalization」,表示为
DiT及其变体的介绍,详见此文《Diffusion Transformer(DiT)——将扩散过程中的U-Net换成ViT:近频繁用于视频生成与机器人动作预测(含清华PAD详解)》
如图3所示,由以下部分组成
- 交替使用交叉注意力和自注意力模块,类似于Flamingo(Alayrac et al., 2022)和VIMA(Jiang et al., 2023)
和状态嵌入
上进行操作
作为条件
- 在最后一个DiT 模块之后,对最终的H 个token应用一个特定于体现的动作解码器(即另一个MLP),以预测动作
给定一个真实值动作块,一个流匹配时间步
,以及采样噪声
,加噪后的动作片段
通过以下公式计算:
模型预测——相当于是预测的噪声,旨在通过最小化以下损失函数以逼近去噪向量场
——相当于是所添加的噪声「毕竟本质就是让预测逼近真实」
如同π0中所述,作者使用,
在推断过程中,通过
步去噪生成动作块
- 首先,随机采样
,然后使用前向欧拉积分迭代生成动作块,更新如下
- 且在实践中,他们发现K = 4 推理步骤在所有实现中都能很好地运行
1.3 预训练数据:真实数据、人类视频、视频生成数据、仿真数据
1.3.1 对于无标注的人类视频:通过潜在操作获取潜在动作token
对于人类第一视角的视频和模型预测的神经轨迹neural trajectories,没有任何可以直接用于训练GR00T N1 的动作
这些数据集不包含明确的动作标签,但包含了人类与物体交互的大量序列,捕捉了可供性、任务语义和自然的运动模式。这些数据集涵盖了广泛的真实世界人类行为,包括抓取、工具使用、烹饪、组装以及在自然环境中执行的其他任务导向的活动,并提供了详细的内容
第一人称视角的手物交互(示例如下图图11所示),整个视频数据集包括以下内容:
- Ego4D 是一个大规模的第一人称视频数据集,涵盖了日常活动的多样化录制
- Ego-Exo4D 在第一人称录制的基础上,补充了外部(第三人称)视角(Grauman 等,2024)
- Assembly-101 通过提供详细的逐步物体组装视频,专注于复杂的组装任务(Sener 等,2022)
- EPIC-KITCHENS 包含第一人称视角的烹饪活动视频(Damen 等, 2018)
- HOI4D 捕捉了人-物体交互,并为分割、手部与物体姿态以及动作提供逐帧标注(Liu 等, 2022)
- HoloAssist在增强现实环境中捕捉协作与辅助任务(Wang等,2023)
- RH20T-Human包含了对细粒度操作任务的录制,重点关注在各种真实场景下的自然手-物交互(Fang等,2023)
对于这些数据,他们通过训练一个VQ-VAE 模型来从视频的连续图像帧中提取特征,从而类似LAPA或Google的Genie 生成潜在动作

- 编码器接受一个视频的当前帧
和未来帧
(具有固定窗口大小H,如上图所示,H可以等于1),并输出潜在动作
——上图用
表示
- 解码器被训练为接受潜在动作
相当于
- 首先,训练一个潜在动作模型:从视频中提取背后的潜在动作信息
该模型使用VQ-VAE 目标进行训练,其中编码器输出的连续嵌入 映射到最近的codebook嵌入
where the continuous embedding from the encoder is mapped to the nearest embedding from the codebook- 然后后续便可以再预训练一个潜在规划器:预测潜在动作token序列
即在训练(一个潜在动作模型)之后,作者再提取编码器并将其用作逆动力学模型
给定一个
相当于潜在规划器Latent Planner预测潜在动作token的ground truth便是基于头部视角的LAM 编码器生成的
——
,即可让他两之间通过流匹配建loss
After training, we take the encoder and use it as an inverse dynamics model; given an𝑥𝑡 and 𝑥𝑡+𝐻 pair, we extract the continuous pre-quantized embedding and use this as the latent action label during pre-training从而使用相同的流匹配损失,但将其视为一个独特的”LAPA” 形态,也类似此文ViLLA中介绍的「1.2.2 潜在规划器:预测潜在动作token序列」

在所有异构数据上共同训练VQ-VAE 模型,使得能够统一所有数据,使用相同的学习潜在动作空间,从而有可能提升跨体现泛化能力
下图图4 展示了来自8 种不同体现(包括机器人和人类形态)的 和
对,这些对都是通过相似的潜在动作检索得到的

- 第一个潜在动作展示了所有形态将右臂从右移动到左
- 第二个潜在动作展示了将右臂从左移动到右
1.3.2 视频生成:为增强Neural Trajectories——通过真实的远程操作数据微调视频生成模型
机器人数据的规模与人力劳动呈线性关系,因为通常需要人类操作员远程操控机器人以生成每一条轨迹
- 近年来,视频生成模型在高质量可控视频生成方面展示了显著潜力,为在机器人领域构建世界模型铺平了道路
- 为了利用这些模型,英伟达对图像到视频生成模型(Agarwal 等,2025;Wan Team,2025;Yang 等,2024)进行了微调——并以现有初始帧和新颖的语言提示为条件,生成了827小时的视频数据,实现了约10倍的数据扩充
具体而言,他们对WAN2.1-I2V-14B(Wan团队,2025)使用LoRA(Hu等人,2022)在收集的远程操作轨迹上进行微调。这些轨迹被均匀下采样到480P分辨率的81帧用于微调
为了生成这约827 小时的视频;他们在一张L40 GPU 上生成一秒视频需要2 分钟,并且在3,600 张L40 GPU 上大约花费了105k L40 GPU 小时(约1.5 天)
这使得能够生成包含更多现实世界反事实场景(counter factual scenarios)的训练数据,而无需为每种情况实际采集远程操控数据,示例如下图图5所示

- 且为了增加神经轨迹的多样性,首先使用商用级多模态大型语言模型(LLM)——比如我个人猜测可以是GPT4o,在初始帧中检测物体,并生成更多可能的“将{object}从{location A}拾取到{location B}”的组合,同时指示模型仅考虑物理上可行的组合
相当于让GPT4o为视频生成模型 规划出可行的模拟轨迹 - 此外,还对生成的视频应用后处理机制,包括筛选和重新生成描述
即从每个视频中采样8帧,并提示一个商用级多模态LLM评估其是否符合指令。不符合该标准的视频将重新生成字幕,在此过程中视频被下采样到256P分辨率的16帧
在包含3,000 个带有语言注释的现实世界机器人数据样本的数据集上训练了模型100 个epoch,每个样本以480P 分辨率记录,由81 帧组成
- 如上图图5 所示,他们的模型可以根据新的语言提示生成高质量的反事实轨迹
- 此外,该模型在互联网规模的视频数据上训练,展现出在处理未见过的初始帧、新颖物体和新的运动模式方面的强泛化能力
- 这些视频进一步被标注为潜在动作和基于IDM 的伪动作,用于模型训练
1.3.3 仿真轨迹:仿真中基于DexMimicGen自动生成训练数据——挺6的
原论文表示,由于同时控制双臂和灵巧手的难度,扩大人形机器人在现实世界中的数据采集规模成本极高
- 但最近的研究(Jiang 等,2024;Mandlekar 等,2023;Wang 等,2024)表明,在仿真环境中生成训练数据是一种可行的替代方案
- 故他们使用 DexMimicGen合成大规模的机器人操作轨迹
每个任务被分解为一系列以物体为中心的子任务。最初的人类演示被分割成更小的操作序列,每个序列对应于涉及单一物体的一个子任务
- 通过使用DexMimicGen,他们将有限的人类演示集扩展为大规模的人形操作数据集。考虑到训练前和训练后的数据集,总计生成了78万条模拟轨迹——相当于6,500小时,或连续九个月的人类演示数据——仅用了11小时
这些仿真数据极大地补充了真实机器人数据,同时几乎不需要额外的人力成本
任务包含大量逼真的3D 资产
- 他们在RoboCasa 模拟框架(Nasiriany 等,2024)下构建了这些任务
总体而言,任务遵循” 将A 从B 重新排列到C” 的行为,其中A 对应一个物体,B 和C 分别代表环境中的起始位置和目标位置
起始位置和目标位置是诸如盘子、篮子、餐垫和架子之类的容器,机器人必须在起始容器和目标容器的不同组合之间重新放置物体- 总体而言,他们的预训练仿真数据集包含54 种独特的起始和目标容器类别组合
他们将物体和容器随机放置在桌子的不同位置,并在场景中加入干扰物体和容器。这些干扰项要求模型关注任务语言,以执行期望的行为此外,他们使用DexMimicGen以大规模生成多样化、高质量的训练数据集
- 首先通过使用Leap Motion设备的远程操作,收集数十个源演示
Leap Motion设备 可跟踪手腕的6自由度姿态和手指姿态- 将这些数据重定向并发送给基于 mink (Zakka,2024) 的全身逆向运动学(IK)控制器
- 在获得人类演示后,DexMimicGen 将演示处理为以物体为中心的片段,并对这些片段进行变换和组合,从而生成新的演示
借助该系统,他们为预训练任务中的每一对(源、目标)容器生成 10,000 个新演示,总共获得 54 万个演示
顺带说一句,这个做法,其实我司「七月在线」也在用:即在仿真中通过仿真数据基于RL训练一个base model,然后再在真实环境中基于模仿学习采集真实数据做微调
1.3.4 真实世界数据集:含遥操采集(VIVE和动捕手套、VR、Leap Motion),和OpenX
他们使用以下真实世界的机器人数据集:
- GR00T N1 人形机器人预训练数据集。他们内部收集的数据集涵盖了广泛的通用操作任务,重点是通过远程操作进行的傅里叶GR1
对于如何遥操,有三种方式
1 利用VIVE Ultimate Tracker捕捉远程操作员的手腕姿态
同时使用Xsens Metagloves跟踪手指运动另,他们还探索了其他远程操作硬件选项,即包括
2 Apple Vision Pro
3 Leap Motion详见下图图6

记录下的人体动作随后通过逆向运动学重定向为仿人动作
实时远程操作的控制频率为20Hz除了机器人的动作外,还在每个步骤捕获来自头戴相机的图像,以及人类的低维本体感知和动作。该数据集包括精细的注释,详细描述了诸如抓取、移动和放置等原子动作,以及粗粒度的注释,将精细动作序列聚合为高级任务表示。这种分层结构支持精确运动控制和高级任务推理的学习
除了机器人的动作外,还在每一步采集头戴相机的图像,以及人的低维本体感觉和动作。该数据集包含细粒度注释,详述了如抓取、移动和放置等原子动作,以及粗粒度注释,将一系列细粒度动作聚合为更高层次的任务表示
这种分层结构支持精确运动控制和高层次任务推理的学习 - Open X-Embodiment
Open X-Embodiment Collaboration 等人是一个广泛使用的跨实体机器人操作数据集
包括了 RT-1(Brohan 等人,2022)、Bridge-v2(Walke 等人,2023)、Language Table(Lynch 等人,2022)、DROID(Khazatsky 等人,2024)、MUTEX(Shah 等人,2023)、RoboSet(Bharadhwaj 等人,2024)和 Plex(Thomas 等人,2023),提供了涵盖各种操作任务、语言条件控制和机器人-环境交互的多样化数据集 - AgiBot-Alpha.AgiBot-World-Contributors 等人是一个由 100 个机器人生成的大规模轨迹数据集
他们在训练运行启动时使用了当时可用的 140,000 条轨迹。该数据集涵盖了精细操作、工具使用以及多机器人协作
1.4 训练的更多细节
1.4.1 预训练
在预训练阶段,GR00T N1通过上面提到的流匹配损失函数
在多样化的实体和数据源上进行训练,这些数据源涵盖了各种真实与合成的机器人数据集以及人体运动数据
- 对于人类视频,在没有真实动作标签的情况下,他们提取学习得到的潜在动作,并将其用作流匹配目标
对于机器人数据集,例如GR-1人形数据或Open X-Embodiment数据,同时使用真实机器人动作和学习到的潜在动作作为流匹配目标 - 在用于增强机器人数据集的神经轨迹(原论文对应2.2.2节)的情况下,同时使用潜在动作以及从基于真实机器人数据训练的逆动力学模型预测的动作
预训练超参数列于附录中的表6

1.4.2 后训练
在后训练阶段,他们在与每个单一具身环境相对应的数据集上微调他们预训练的模型
- 与预训练阶段类似,他们保持VLM主干网络的语言部分参数冻结,仅微调模型的其余部分
As in pretraining, we keep the language component of the VL backbone frozen and fine-tune therest of the model后训练的超参数在附录的表6中给出
使用神经轨迹进行后训练为了克服后训练过程中数据稀缺的挑战,他们探讨通过生成神经轨迹来扩充每个下游任务的数据,方法类似于上文1.3节(原论文第2.2节)所述的流程
- 对于依赖多视角的下游任务,他们对视频模型进行微调,使其能够生成网格中的多个子图像,如下图图14所示

- 对于仿真任务,从随机初始化的环境中收集多样化的初始观测
- 对于真实机器人任务,他们手动随机初始化物体的姿态,并记录机器人的初始观测。新的初始帧也可以通过img2img扩散自动生成,但他们将进一步探索留待未来工作中进行
且他们还展示了
1) 多轮视频生成,用于生成由原子任务组成的长时域轨迹
比如,下图展示了两个连续的序列,其中后一序列的初始帧来自前一序列的结束帧,突出了生成需要原子任务组合的任务轨迹的可能性

以及
2) 液体和关节物体的神经轨迹,这类轨迹已知在仿真中极具挑战性。不过,下游任务的定量评估他们同样留待未来工作 - 在他们的基于神经轨迹的后训练流程中,仅在仿真任务中使用人工收集的轨迹对视频生成模型进行微调,并且仅使用真实世界基准中收集的10%数据用于后训练,以符合现实场景下他们只能获得有限遥操作数据的情况
- 由于生成的视频没有动作标签,故他们采用潜在或逆动力学模型(IDM)标注的动作(Baker等,2022),并训练策略模型将这些伪动作视为不同体现下的动作标签
- 在低数据量情景下,仅在少量数据上训练IDM模型,以贴合真实应用场景
至于如何训练IDM模型的详细信息在附录E中提供。在原论文第4.4节中对潜在和IDM标记的动作进行了某些经验比较。在后训练过程中,以1:1的采样比例,将真实世界轨迹与神经轨迹共同用于策略训练
1.4.3 训练基础设施
他们在通过NVIDIA OSMO(NVIDIA,2025)管理的集群上训练GR00T N1,这是一个用于扩展复杂机器人工作负载的编排平台
- 训练集群配备了通过NVIDIA Quantum-2 InfiniBand连接的H100 NVIDIA GPU,采用胖树拓扑结构
通过一个基于Ray分布式计算库(Moritz等,2018)构建的自定义库,促进容错的多节点训练和数据摄取 - 为单个模型使用多达1024个GPU。GR00T-N1-2B大约使用了50,000个H100 GPU小时进行预训练
在单个A6000 GPU的环境下测试了计算受限的微调
如果仅调整adapter层(动作和状态编码器 + 动作解码器)和DiT,可以使用最多200的批量大小
当调整视觉编码器时,可以使用最多16的批量大小
// 待更
第二部分 GR00T N1.5
2.1 整体概览:GR00T N1.5相比N1的改进
25年6.11日,英伟达推出了GR00T N1.5(这是其技术blog、其GitHub地址),与 N1 一样
- GR00T N1.5 使用 NVIDIA Eagle VLM 对文本和视觉观察进行编码
- 然后,视觉语言嵌入通过 VLM 生成,再由 DiT 进行交叉注意力处理,DiT 处理状态和加噪的动作
总之,与 N1 相比,主要的不同之处在于以下几点:
- 在预训练和微调期间,视觉语言模型(VLM)都是固定的
- 连接视觉编码器与语言模型(LLM)的适配器多层感知机(MLP)被简化,并在输入到 LLM 的视觉和文本token嵌入中都添加了层归一化
2.1.1 模型和数据改进:预训练和微调期间VLM被冻结,且VLM升级为Eagle 2.5
- 冻结的视觉语言模型(Frozen VLM)
在预训练和微调过程中,视觉语言模型保持不变,从而保留了语言理解能力并提高了泛化能力 - 增强的视觉语言模型定位(Enhanced VLM Grounding)
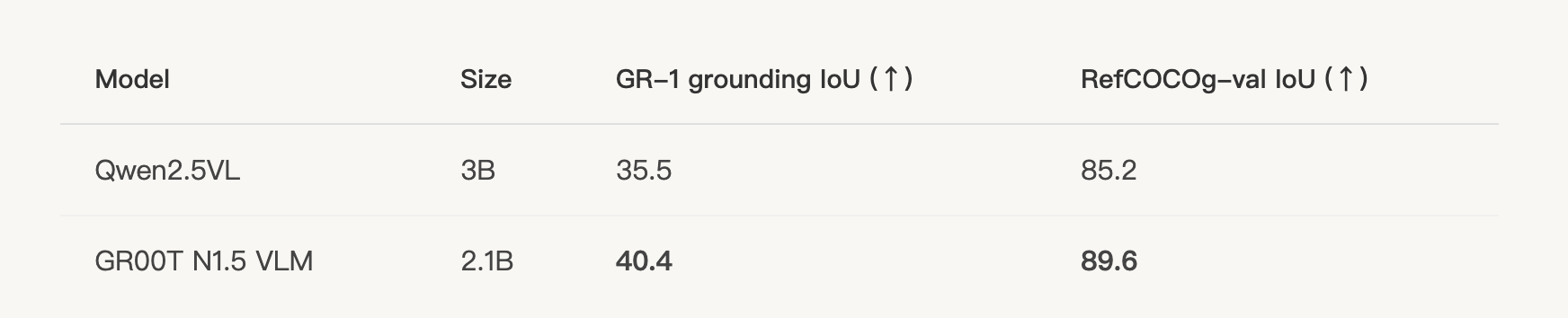
更新至 Eagle 2.5 版本,具备更出色的定位能力和物理理解能力,在 GR-1 定位任务中实现了 40.4 的交并比(IoU)——相比之下,Qwen2.5VL 为 35.5具体而言,在 RefCOCOg 和他们内部的 GEAR GR-1 grounding dataset(带有referring expressions)上,观察到 N1.5 视觉语言模型的表现优于 Qwen2.5-VL-3B
- 简化的适配器(Simplified Adapter)
在视觉编码器和语言模型之间简化了多层感知机(MLP)连接,并增加了层归一化 - FLARE 集成(FLARE Integration),下文2.3节会详解
除了 N1 所使用的流匹配损失外,对于 N1.5,作者还添加了未来潜在表示对齐(参见 FLARE 项目)
FLARE 并非生成性地对未来的帧进行建模,而是将模型与目标未来的嵌入进行对齐
作者发现添加 FLARE 不仅提高了策略性能,还解锁了从人类视频中学习的能力
- DreamGen 集成(DreamGen Integration),下文2.3节会详解
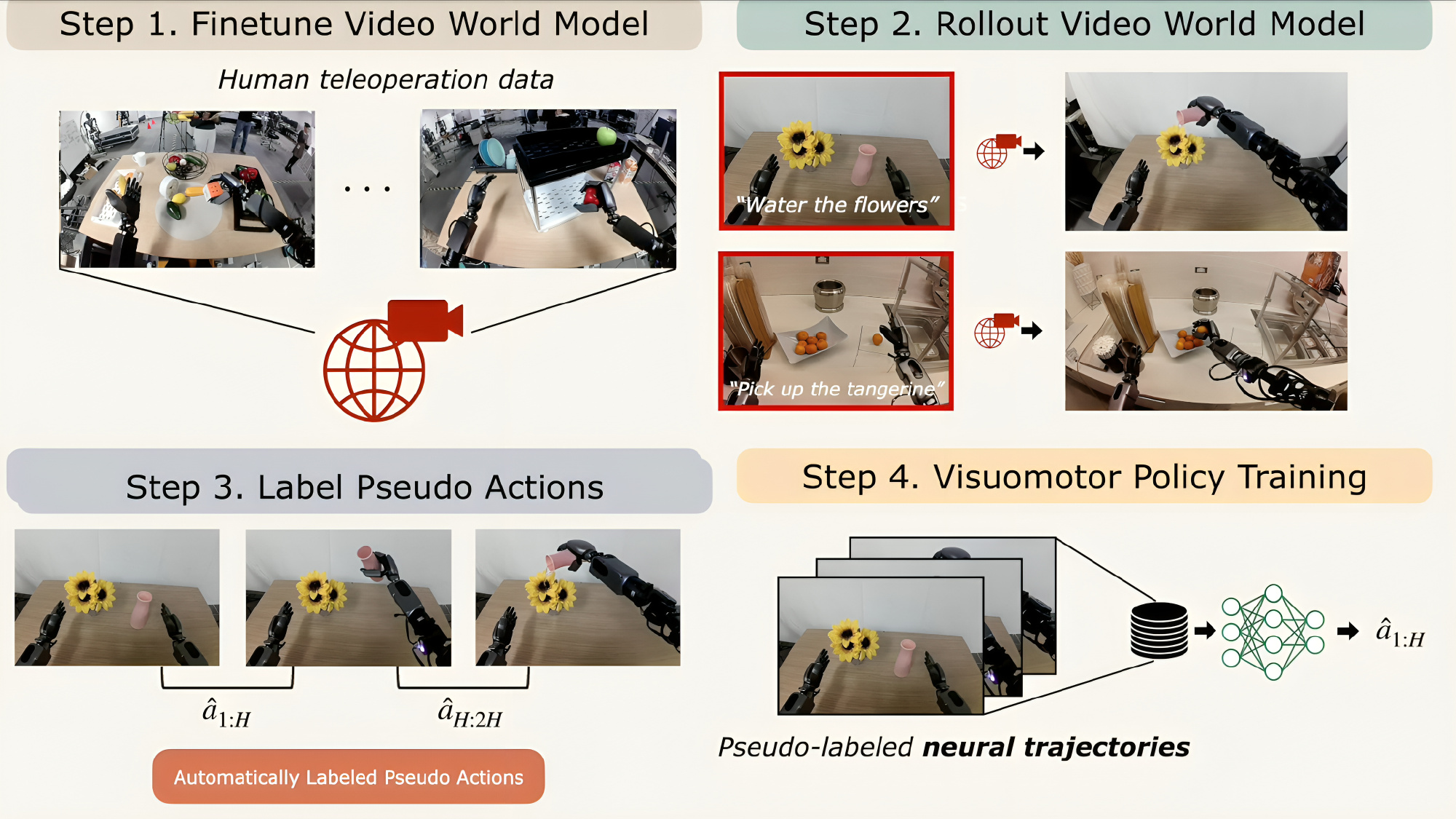
引入通过 DreamGen 生成的合成神经轨迹,从而能够泛化到超出遥操作数据的新行为和任务如下图所示,1 首先在遥操作机器人轨迹上对视频世界模型进行微调。2 给定初始帧和语言指令后,模型会生成展现预期行为的视频序列。3 由于这些视频缺少动作标注,作者通过潜在动作模型或逆向动力学模型推断伪动作,形成称之为神经轨迹的序列。4 最后,在这些神经轨迹上训练视觉运动机器人策略
2.1.2 性能改进
- 语言指令遵循:在 GR-1 操作任务中,语言指令遵循能力显著提升,从 N1 版本的 46.6% 提升至 93.3%
- 数据效率:在低数据量场景(零样本和少样本情况)下表现更优
- 更好的新物体泛化能力
- 新增的具身化头部:
通过 EmbodimentTag.OXE_DROID 头部支持单臂机器人末端执行器(EEF)控制空间
通过 EmbodimentTag.AGIBOT_GENIE1 头部支持配备夹爪的人形机器人,从关节空间控制扩展到更广泛的机器人兼容性
这些改进使得 GR00T N1.5 在需要强大语言理解能力、少样本适应性和对新物体及环境泛化能力的应用中表现尤为出色
2.2(选读) FLARE:基于隐式世界建模的机器人学习
FLARE 的核心是从动作去噪网络的隐藏状态中预测机器人未来观测的紧凑表示。FLARE 主要包括两个关键阶段
- 首先,预训练一个紧凑且具备动作感知能力的观测嵌入模型。虽然通用嵌入模型也可用于目标未来嵌入,但作者发现,针对下游控制任务显式优化的动作感知嵌入,因其紧凑性和任务对齐性,能带来更优的性能和效率
- 接下来,通过引入极少量的附加 token,与diffusion transformer协同训练,这些 token 被优化用于预测未来观测嵌入
该方法对现有 VLA 架构 [7,8] 只需极小的修改,因此具有广泛适用性且易于部署
最后,FLARE还支持从无动作标签的数据源中学习,例如人类视频
- 通过利用GoPro采集的人类第一视角演示视频——使用头戴式GoPro摄像机采集的以自我视角为主的人体视频数据集
- 并且每个物体仅需一条真实机器人演示,FLARE成功学习了新的抓取策略,凸显了其在利用非结构化数据源进行大规模机器人学习方面的潜力
2.2.1 研究背景:包含流匹配损失函数
在本研究中,继π0 和GR00T N1 [7,8] 之后,作者采用flow-matching [9] 作为从人类示范中拟合动作的学习目标
- 令
表示机器人的观测,其包括图像输入(可能来自多个视角)和语言指令
- 令
- 令
为从专家示范中提取的动作片段
- 且定义
为观测的视觉-语言嵌入
给定VL嵌入、一个动作片段
、流匹配时间步
,以及采样噪声
,可将构造加噪的动作片段如下
然后,模型预测被训练以逼近去噪方向
「纯噪声
减掉纯净动作
便是所添加的噪声
![]() 」,通过最小化以下流匹配损失
」,通过最小化以下流匹配损失
当然,也可以写成是:![]()
且作者从分布中采样时间步长
,其中
,方法同Black 等人[7]
在推理阶段,通过K 步去噪生成动作片段。可首先采样一个初始片段,然后应用前向欧拉积分对其进行迭代细化
遵循GR00T N1 [8],作者在所有实验中都设置K = 4,并且对于,使用相同的Diffusion Transformer (DiT) 架构[10],通过交替的交叉注意力和自注意力层,以机器人视觉语言嵌入
进行条件处理
2.2.2 通过「未来潜在表示对齐」进行潜在世界建模
为了使DiT模块中的潜在表示能够预测未来的潜在状态,作者在输入序列中添加了M个可学习的未来token嵌入,使得该序列包含三个组成部分:
- 通过状态编码器编码的当前本体感受状态
- 加噪的动作片段
——由动作编码器编码
- 以及一组 M 个可学习的未来token
接下来,作者从内部层 截取与
个未来 token 对应的中间 DiT 表示,利用 MLP 对这些特征进行投影,最后将其与未来观测
的冻结视觉-语言嵌入对齐
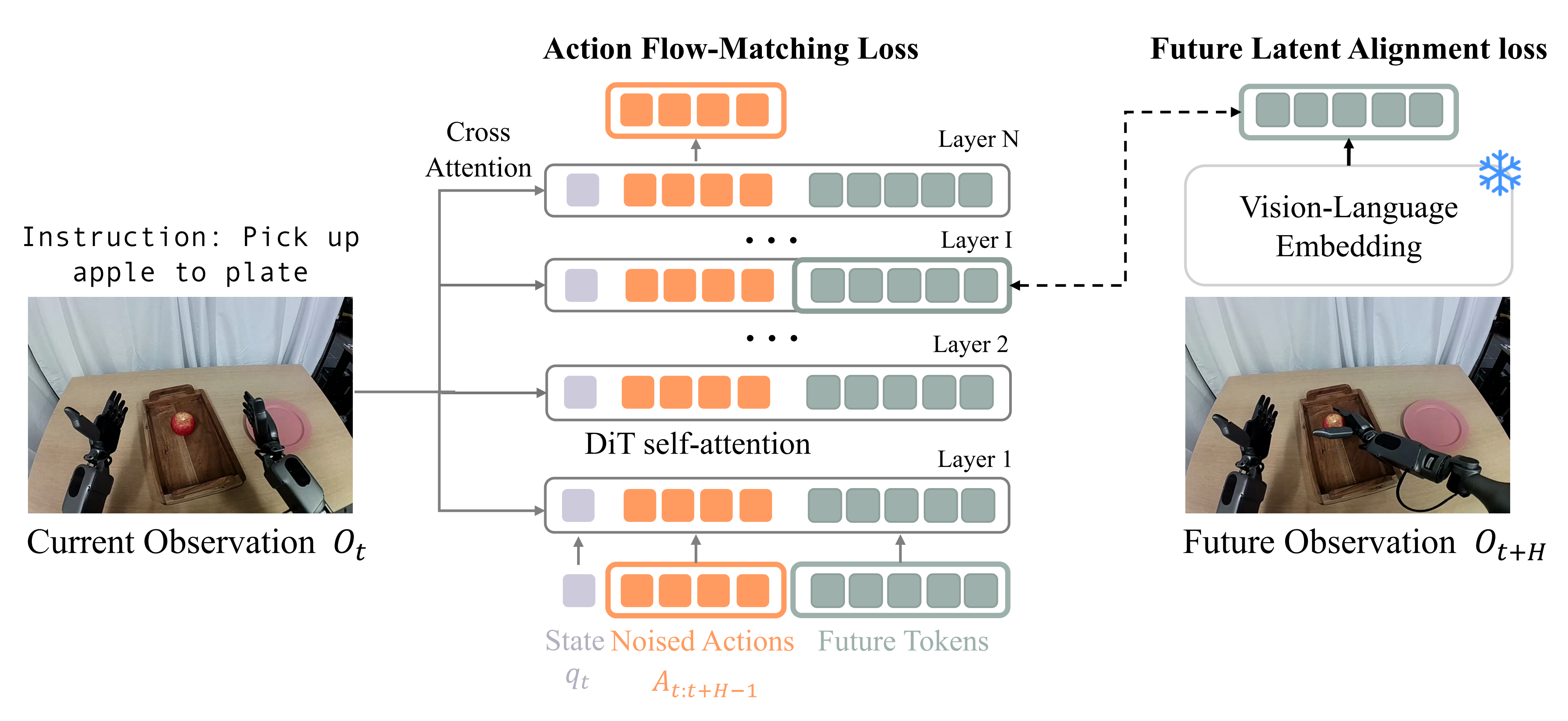
FLARE的方法类似于表示对齐(REPA)[11]在提升文本到图像扩散模型中的应用,但由于潜在世界建模的设定,存在几个重要的不同之处
- 首先,将DiT策略与未来嵌入对齐,而不是当前观测的嵌入
- 其次,FLARE的架构引入了可学习的未来token,使得流匹配和对齐在DiT中沿着各自独立的路径进行,并通过自注意力机制相互作用
通过这种方式,鼓励DiT模块在保持其通过动作流匹配进行动作预测能力的同时,能够在内部推理未来的潜在状态
令B表示批量维度,D表示嵌入维度,可以将潜在对齐目标写为
其中,输出第L 层对M 个未来token 的DiT 激活,
是对未来观测
的编码器
总体损失函数为
通过实证研究,作者发现λ = 0.2 在他们的实验中表现最佳
2.2.3 动作感知的未来嵌入模型
虽然FLARE的未来潜在对齐框架能够广泛兼容多种嵌入模型,但作者发现引入动作感知的未来嵌入能够在性能和效率上带来进一步提升
为此,作者提出了一种紧凑的视觉-语言嵌入方法,用于描述机器人当前的观测,并针对策略学习进行了显式优化。该设计目标有两个方面:一是实现嵌入的紧凑性,二是确保对动作的感知能力
- 具体来说,作者利用SigLIP-2 [12] 中的视觉和文本编码器,对机器人的图像观测和文本指令进行编码。编码后的tokens 通过四层自注意力transformer 模块进行融合,以捕捉跨模态依赖关系
- 随后,应用Q-former [13] 模块,将融合后的序列压缩为M = 32 个可学习查询token,从而生成一种紧凑、固定大小的表征,自然地泛化到多摄像头输入
为了确保动作感知性,作者将视觉语言嵌入端到端地与常规动作流匹配目标一起训练,通过附加8DiT 模块来预测机器人的动作
通过这种方式,所有与任务相关的信息都能被保证被捕获在潜在token 嵌入中 - 为了对嵌入模型进行预训练,作者利用了多样化的跨形态机器人数据集,包括来自GR00T N1 [8]的模拟和现实世界人形桌面操作数据,以及OpenX-Embodiment [14]的另外七个数据集,总计约2,000小时的机器人数据
在预训练完成后,作者在下游领域和任务中,将下游策略与潜在世界模型及动作预测目标联合进行后训练
- 具体而言,在后训练阶段,使用预训练的嵌入模型对下游策略的编码器进行初始化,同时也采用了预训练的嵌入模型用于定义未来潜在表示的预测目标
- 为缓解预训练与下游视觉观测之间的分布偏移,作者并未将嵌入模型完全冻结,而是采用了相对于策略编码器的指数滑动平均(EMA)更新策略。该方法使嵌入模型能够在策略微调过程中,随着视觉和语言编码器的演化逐步适应。实验证明,EMA的更新率为0.995时效果最佳
介绍一下基于Q-former的紧凑型视觉-语言嵌入模块的架构细节
- 具体来说,作者采用siglip2-large-patch16-256作为视觉和语言编码器的主干网络
这256个视觉token与32个语言token拼接后,通过四层自注意力Transformer,生成288个融合的视觉-语言token- 为了获得紧凑的表示,采用Q-former架构[13],其中32个可学习的查询token(随机初始化)通过交替的自注意力和交叉注意力层与288个融合token进行交互
where 32 learnable query tokens—randomly initialized—interact with the 288 fused tokens through interleaved self-attention and cross-attentionlayers最终输出32个压缩的视觉-语言token
2.3(选读) DreamGen:通过视频世界模型解锁机器人学习中的泛化能力
如下图所示
DREAMGEN遵循一个简单的四步流程(见图2),用于应用最先进的视频生成模型[7,8,9,10,11,12](也被称为视频世界模型)来生成合成训练数据。该流程被设计为可在不同机器人、环境和任务中通用
- 在目标机器人上对视频世界模型进行微调,以捕捉特定实体的动力学和运动学特征
- 以初始帧和语言指令对的方式为模型提供提示,从而生成大量机器人视频,这些视频既包含微调过程中学到的熟悉行为,也涵盖在未见场景下的新颖行为
- 随后,利用潜在动作模型[13]或逆动力学模型(IDM)[14]提取伪动作
- 最后,将得到的视频-动作序列对(称为神经轨迹)用于下游视觉运动策略的训练
此前的研究主要关注将视频世界模型用作实时规划器[15,16,17,18,19],而DREAMGEN则将其视为合成数据生成器,充分发挥其在物理推理、自然运动和语言基础等方面的强先验能力
在接下来的小节中,将详细介绍DREAMGEN的4个不同步骤(如图2所示),即如何创建和利用神经轨迹来训练视觉-运动机器人策略
2.3.1 步骤1:视频世界模型微调
在初始阶段,对人类远程操作机器人轨迹上的视频世界模型进行微调。这一适应过程使模型能够学习机器人的物理约束和运动能力
- 为了减缓模型对先前互联网视频知识的遗忘,作者在不同的视频世界模型微调中默认采用低秩适应(LoRA)[21]
在微调这些模型时,主要关注两个指标:指令跟随性和物理规律跟随性,以判断视频世界模型是否已最佳适应目标机器人领域(详细内容见原论文的第4节) - 在大多数后续机器人实验中,作者采用WAN2.1 [9]作为基础视频世界模型
当训练数据集中包含多个视角(如RoboCasa [20]和DROID [22])时,作者将这些视角拼接为一个2×2的网格(其中一个网格为黑色像素),并对视频世界模型进行微调
且还观察到,每个视频世界模型与微调数据对之间所需的最佳微调量是不同的
2.3.2 步骤2:视频世界模型推演
在对视频世界模型在目标机器人实体上进行微调后,作者利用不同的初始帧和语言指令生成合成机器人视频
- 对于仿真实验,从模拟器中收集新的初始帧,并针对每个任务随机化目标物体或环境的位置
- 对于现实世界实验,手动拍摄新的初始帧,同时随机化目标物体的位置
- 对于环境泛化实验,我们还会拍摄新环境的初始帧,但仅使用在单一环境中收集的数据来训练视频世界模型(相关图片见附录B)
- 最后,在行为泛化实验中,作者手动设计新的行为提示,并在原论文的第4.3节视频基准中包含所有候选项
2.3.3 步骤3:伪动作标注
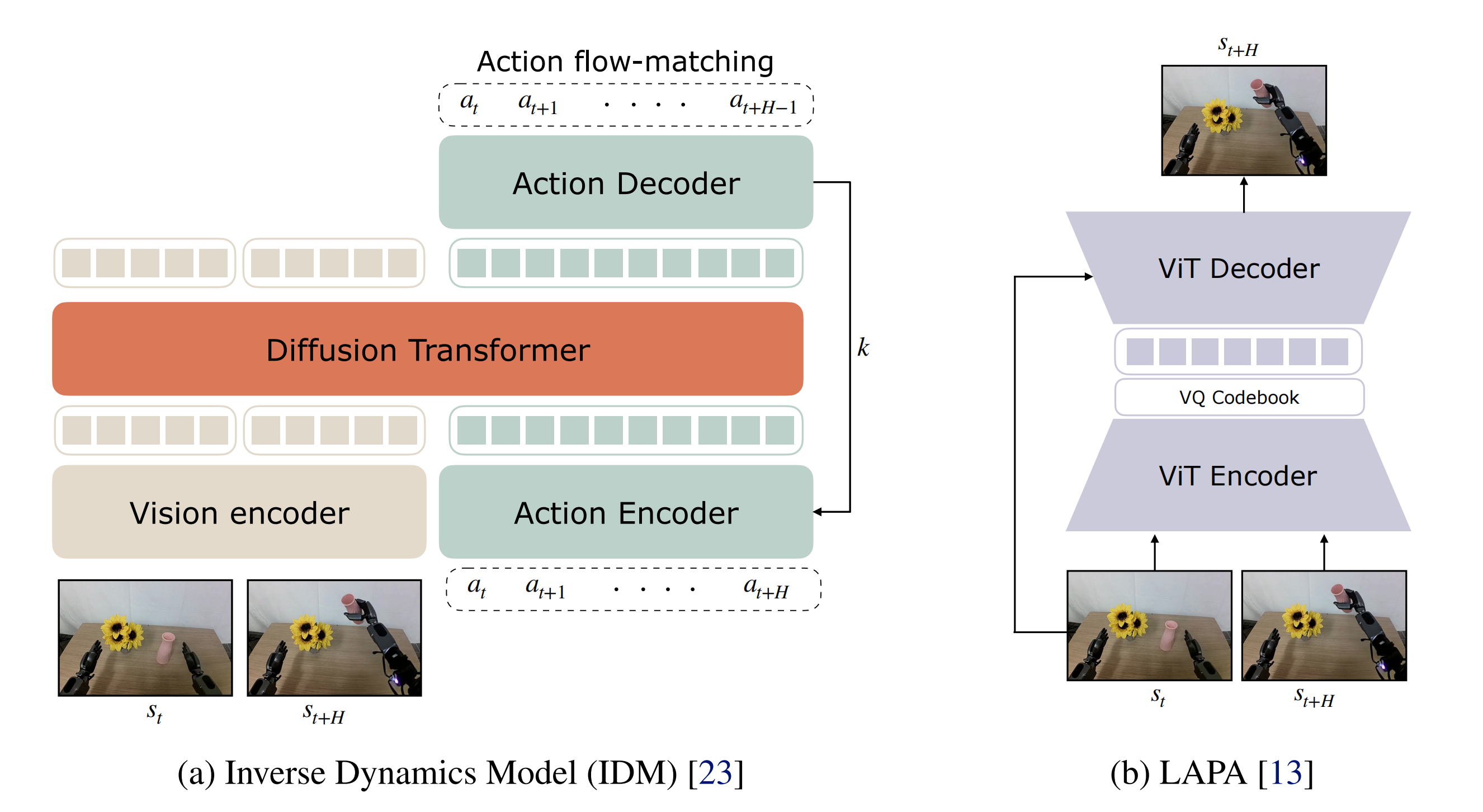
下图图3展示了用于训练IDM模型的(a)架构,以及用于训练潜在动作模型(LAPA)的(b)架构,这两种架构都用于为生成的视频提取伪动作标签
- IDM 动作
对于逆动力学模型(IDM)架构,作者采用带有SigLIP-2 视觉编码器的diffusion transformer,并使用流匹配目标进行训练
IDM 以两帧图像为条件,训练以预测图像帧之间的动作片段(见图3)
没有显式地使用任何语言或本体感受作为输入,因为作者希望IDM 模型只捕捉机器人的动力学特性
对于IDM 训练数据,使用与各自设置下训练视频世界模型相同的数据集,除非另有说明。训练完成后,采用滑动窗口方法进行伪标签生成:IDM 预测H 个动作,从到
接下来,它滑动一个窗口并预测另外H个动作,从到
,以此类推。更多细节见原论文的附录A
- 潜在动作
对于潜在动作,作者采用了LAPA潜在动作模型[13],该模型具有transformer编码器-解码器架构,并在多样化的机器人和人类视频上进行训练。潜在动作模型通过VQ-VAE目标进行训练,使得潜在动作能够捕捉视频中两个帧之间的视觉变化信息为了从生成的视频中获取潜在动作,作者将潜在动作模型以轨迹的当前帧和未来帧(向前1秒)为条件进行推理
且采用与GR00T N1 [5]相同的预量化连续嵌入作为潜在动作。用于训练潜在动作模型的具体数据混合如表3所示。潜在动作的一个优势在于,训练潜在动作模型时不需要目标机器人具身的真实动作标签
2.3.4 步骤4:基于神经轨迹的策略训练
最后,作者在由DREAMGEN 生成的神经轨迹上,通过语言指令和图像观测进行条件设定,训练视觉运动机器人策略
由于神经轨迹不包含状态信息,作者将状态信息设为零值
- 更具体地说,给定图像观测
,训练策略生成
,该输出可以是潜在动作,也可以是上一小节中的IDM 标注动作
- 由于神经轨迹与底层机器人策略架构无关,展示了DREAMGEN 在为三种不同视觉运动策略模型生成合成训练数据方面的有效性,分别是Diffusion Policy [24]、π0 [2] 和GR00T N1 [5]
且作者提出了两种基于神经轨迹的训练方案:
- 一种是与真实世界轨迹联合训练
- 另一种是仅使用带有IDM动作标签的神经轨迹进行训练
- 在神经轨迹与真实轨迹联合训练时,采用1:1的采样比例
- 对于GR00T N1,通过使用独立的动作编码器和解码器,将这两类轨迹视为不同的体现
- 在行为和环境泛化实验中,仅使用神经轨迹进行策略训练
2.4 训练细节
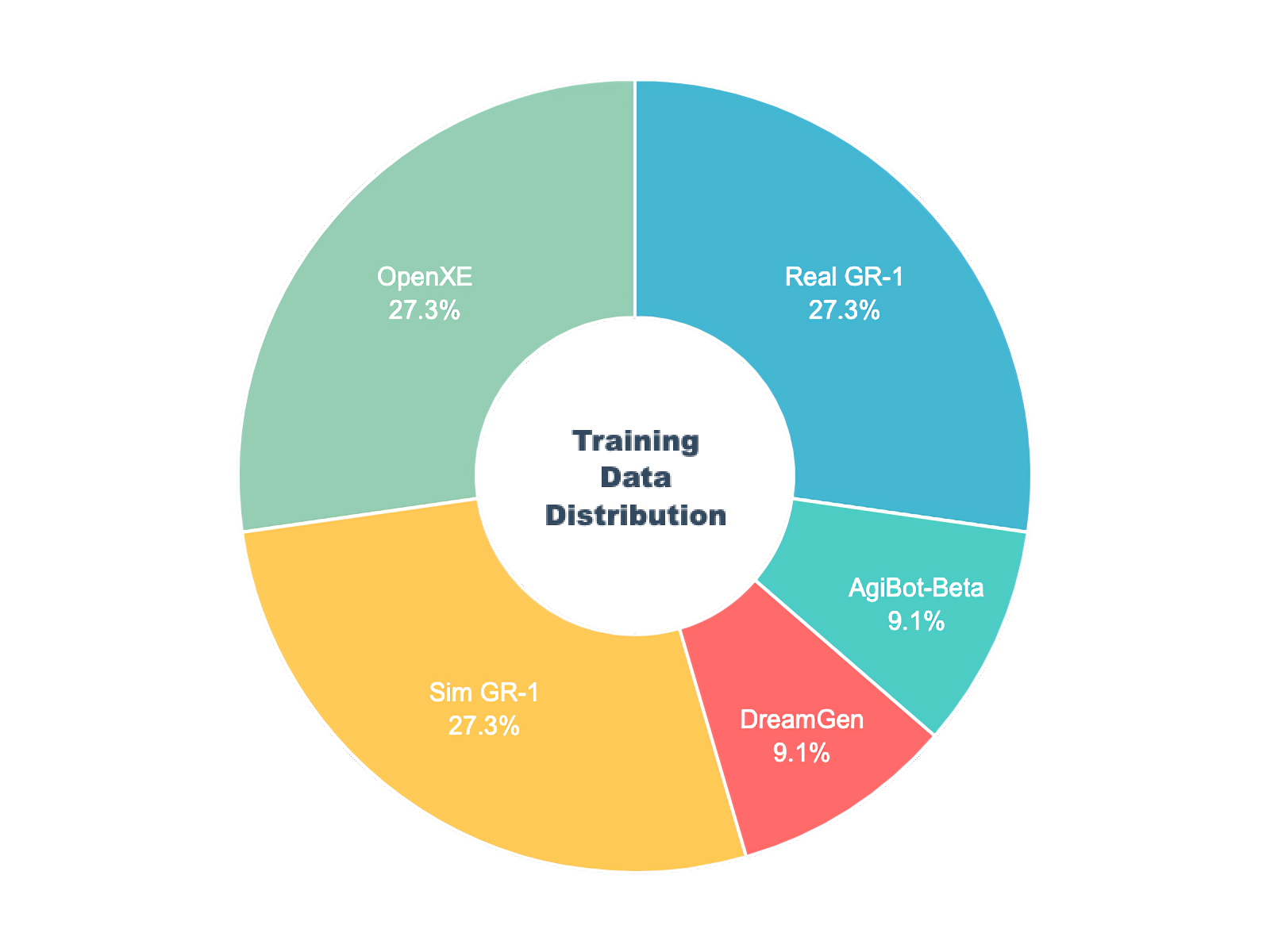
作者在 1000 个 H100 GPU 上对 GR00T N1.5 进行了 25 万步的训练,全局批处理大小为 16384。与 N1 一样,且使用了带有余弦学习率计划和 0.05 预热比例的 AdamW 优化器
- 在预训练和后训练阶段,都使用了 0.2 的 FLARE 损失系数
- 预训练混合数据集包括内部的 GR-1 数据、OpenXE、模拟的 GR-1(又名 DexMG)、来自 DreamGen 的神经轨迹以及 AgiBot-Beta
// 待更
第三部分 使用GR00TN1.5的一般流程
3.1 使用流程、先决条件、安装、数据格式与加载
3.1.1 使用GR00TN1.5的一般流程
以下是使用GR00TN1.5的一般流程
- 假设用户已经收集了一组以(视频、状态、动作)三元组形式的机器人演示数据三元组
- 用户首先需要将演示数据转换为LeRobot兼容的数据模式『详细信息见getting_started/LeRobot_compatible_data_schema.md』,该模式与上游Huggingface兼容LeRobot
- 代码库提供了不同配置的示例,用于在不同机器人形态下进行训练
- 代码库提供了便捷的脚本,用于在用户数据上微调预训练的GR00TN1.5模型,且支持推理运行
- 用户将把Gr00t策略连接到机器人控制器,以便在目标硬件上执行动作
3.1.2 使用上的先决条件
以下是使用上的先决条件
- 已在 Ubuntu 20.04 和 22.04 系统上,以及 H100、L40、RTX4090 和 A6000 GPU 上对微调代码进行了测试。以及Python==3.10,CUDA版本12.4
- 在推理测试中,已在Ubuntu 20.04和22.04,GPU: RTX3090、RTX4090和A6000上进行了测试
- 如果尚未安装CUDA 12.4,请按照此处的说明进行安装
- 如果尚未安装tensorrt,请按照此处的说明进行安装
- 请确保系统已安装以下依赖项:ffmpeg、libsm6、libxext6
3.1.3 安装指南
克隆该仓库:
git clone https://github.com/NVIDIA/Isaac-GR00Tcd Isaac-GR00T创建一个新的conda环境并安装依赖项。推荐使用Python 3.10『请注意,请确保您的CUDA版本为12.4。否则,可能会在正确配置flash-attn模块时遇到困难』:
conda create -n gr00t python=3.10conda activate gr00tpip install --upgrade setuptoolspip install -e .[base]pip install --no-build-isolation flash-attn==2.7.1.post4 3.1.4 数据格式与加载
- 为了加载和处理数据,该库使用了 Huggingface LeRobot 数据,但采用了更为详细的模态和注释方案——称之为“LeRobot 兼容数据模式”
- 一旦数据按照此格式组织好,就可以使用LeRobotSingleDataset类加载数据
from gr00t.data.dataset import LeRobotSingleDatasetfrom gr00t.data.embodiment_tags import EmbodimentTagfrom gr00t.data.dataset import ModalityConfigfrom gr00t.experiment.data_config import DATA_CONFIG_MAP# get the data configdata_config = DATA_CONFIG_MAP[\"fourier_gr1_arms_only\"]# get the modality configs and transformsmodality_config = data_config.modality_config()transforms = data_config.transform()# This is a LeRobotSingleDataset object that loads the data from the given dataset path.dataset = LeRobotSingleDataset( dataset_path=\"demo_data/robot_sim.PickNPlace\", modality_configs=modality_config, transforms=None, # we can choose to not apply any transforms embodiment_tag=EmbodimentTag.GR1, # the embodiment to use)# This is an example of how to access the data.dataset[5] - getting_started/0_load_dataset.ipynb是一个关于如何加载数据并对其进行处理的交互式教程。与GR00TN1.5模型进行接口对接
- scripts/load_dataset.py 是一个可执行脚本,内容与笔记本相同
可尝试运行该脚本以加载数据集
python scripts/load_dataset.py --dataset-path ./demo_data/robot_sim.PickNPlace3.2 推理
- GR00TN1.5模型托管在Huggingface上
- 示例跨体数据集可在 demo_data/robot_sim.PickNPlace 获取
// 待更

