Python调用D435i使用教程_realsense d435i python
1.D435i相机在Windows上使用
1.1安装Intel RealSense Viewer
打开IntelRealSense/librealsense: Intel® RealSense™ SDK下载安装包
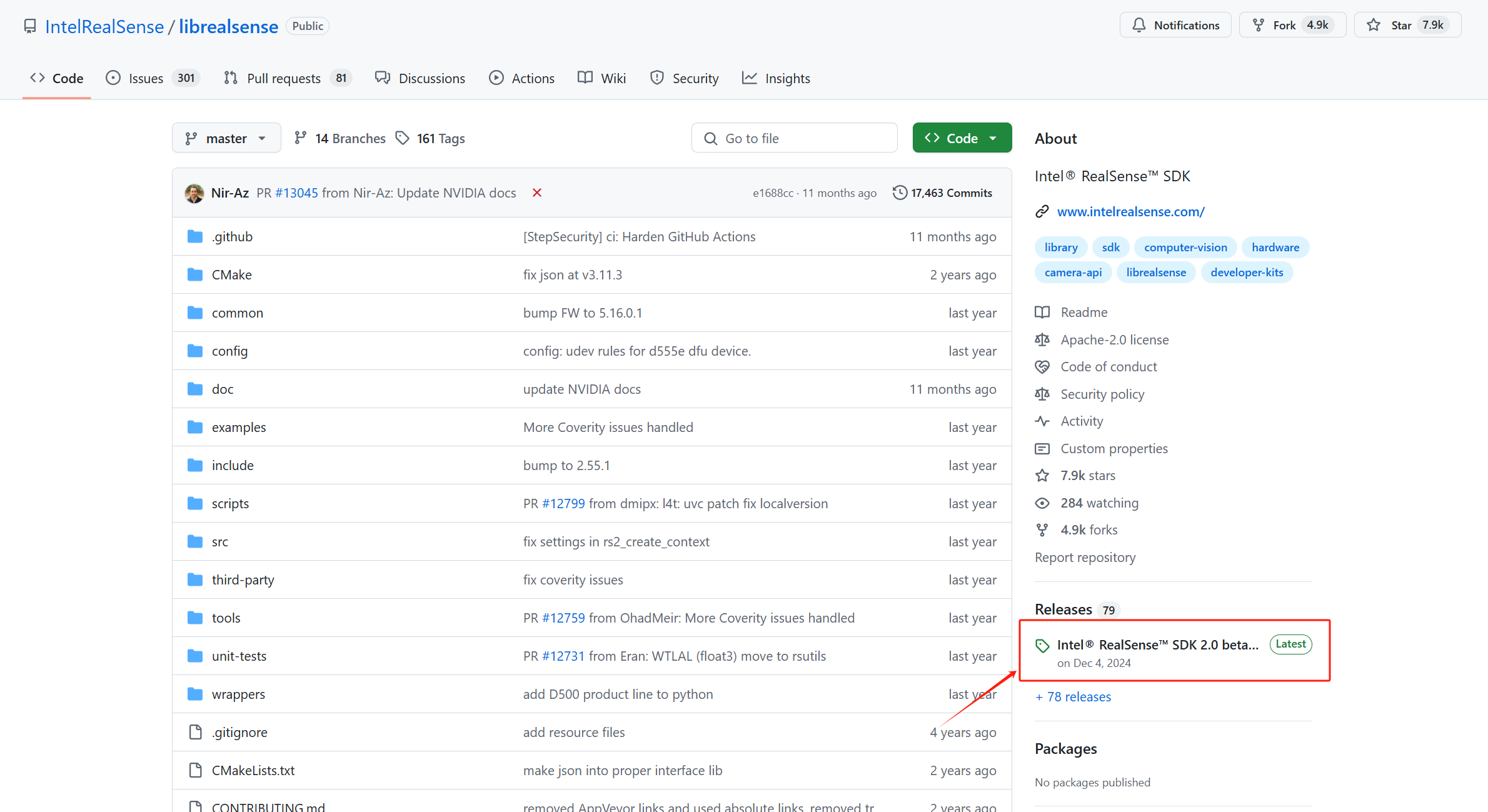
下载这个win10的,win11也可以用
打开安装包,下一步

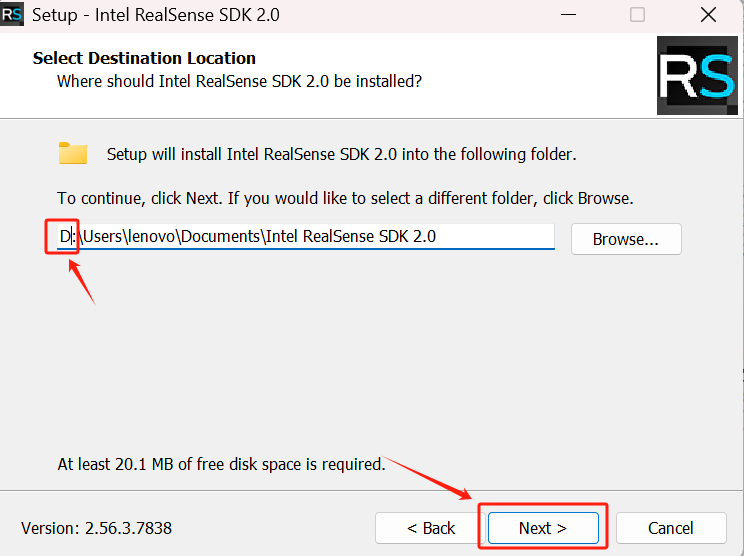
选择安装路径,如果要安装在D盘的话只把前面的C改成D就可以,下一步
这里默认就可以,下一步
下一步
安装
完成
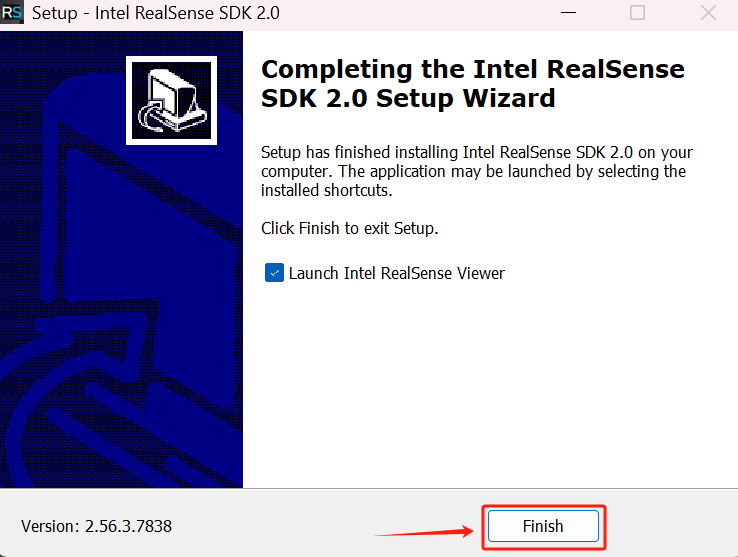
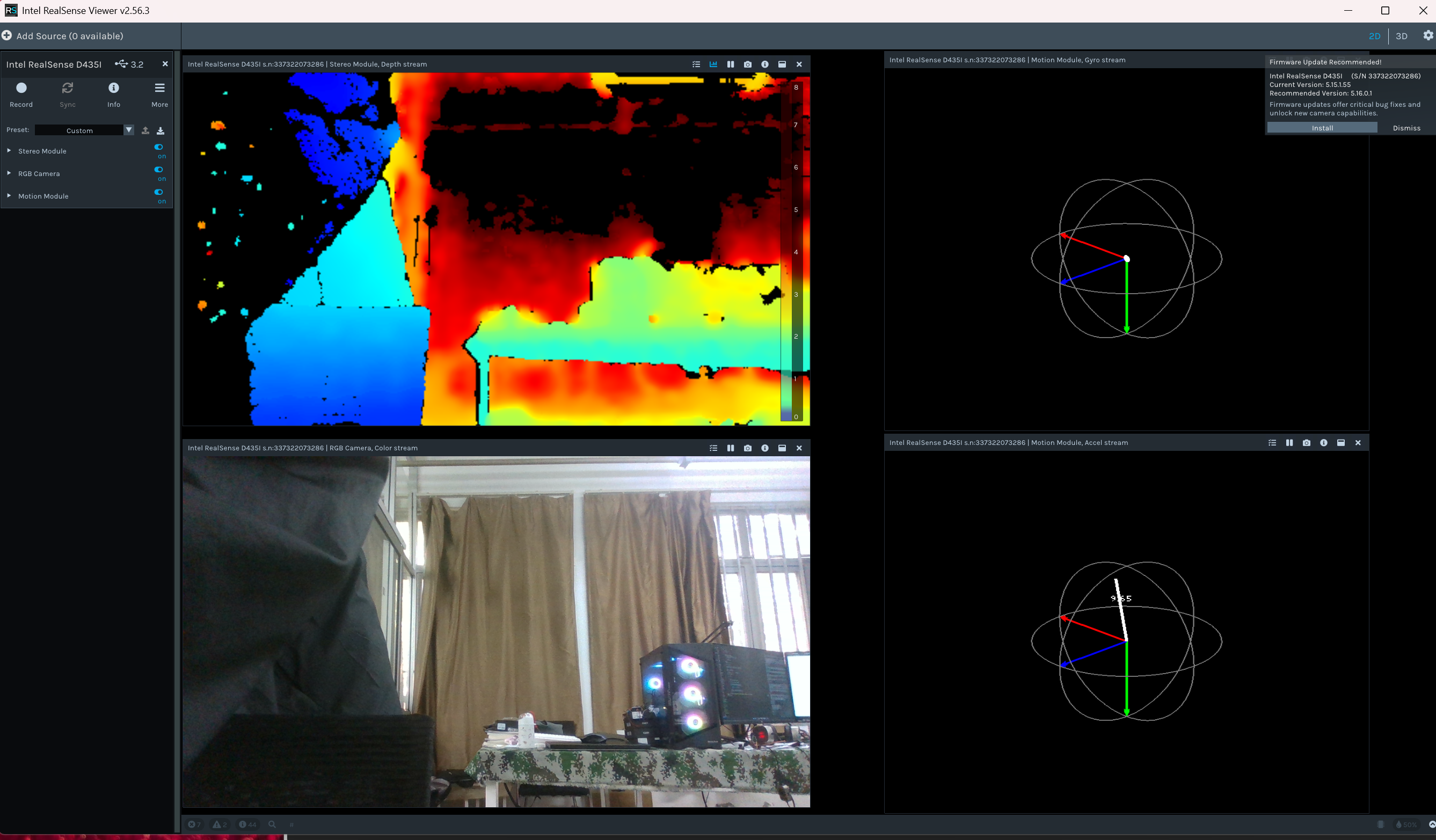
打开软件,右上角选择2D,左边的rgb,深度和坐标都打开
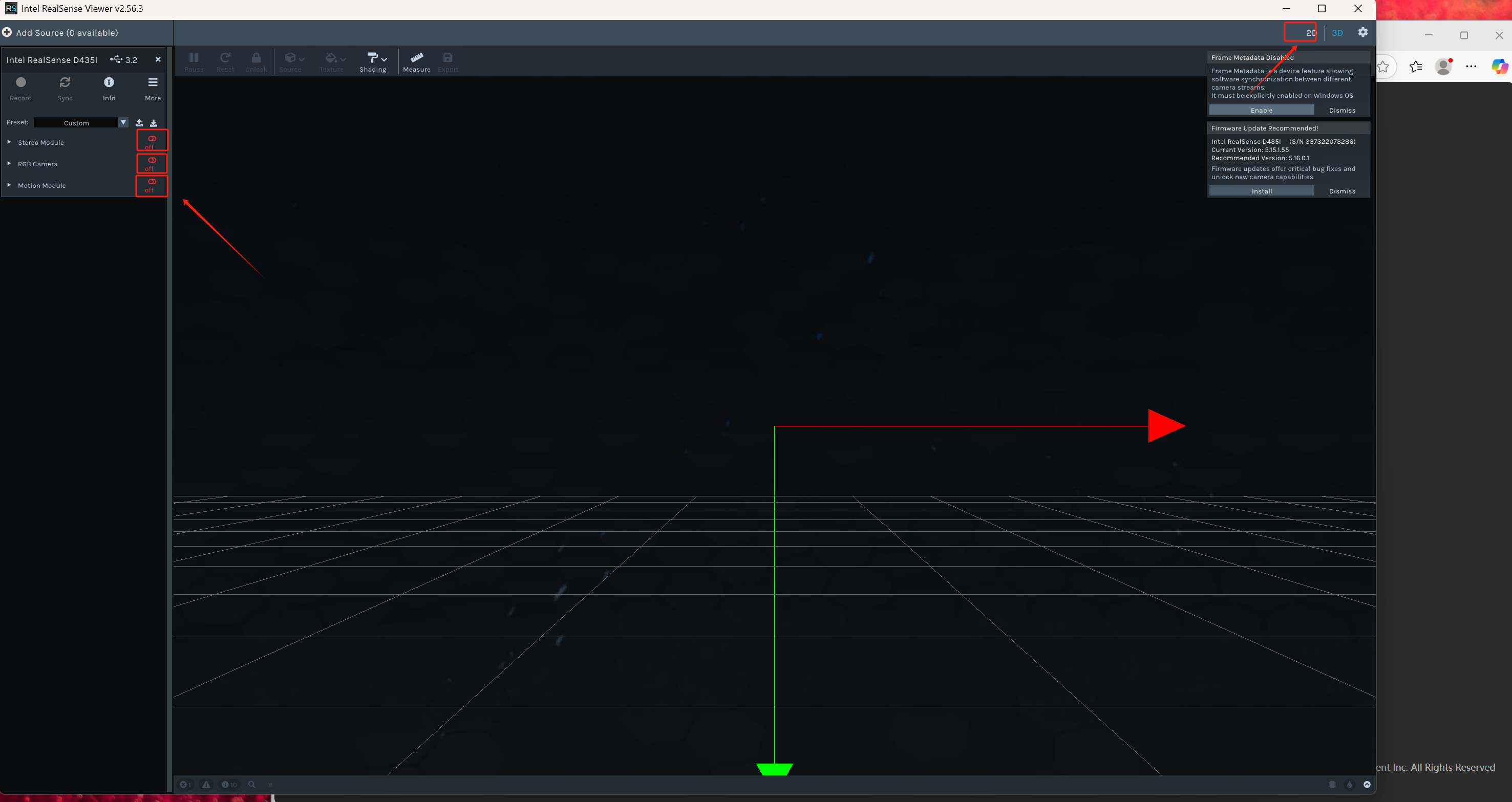
然后就可以显示画面了
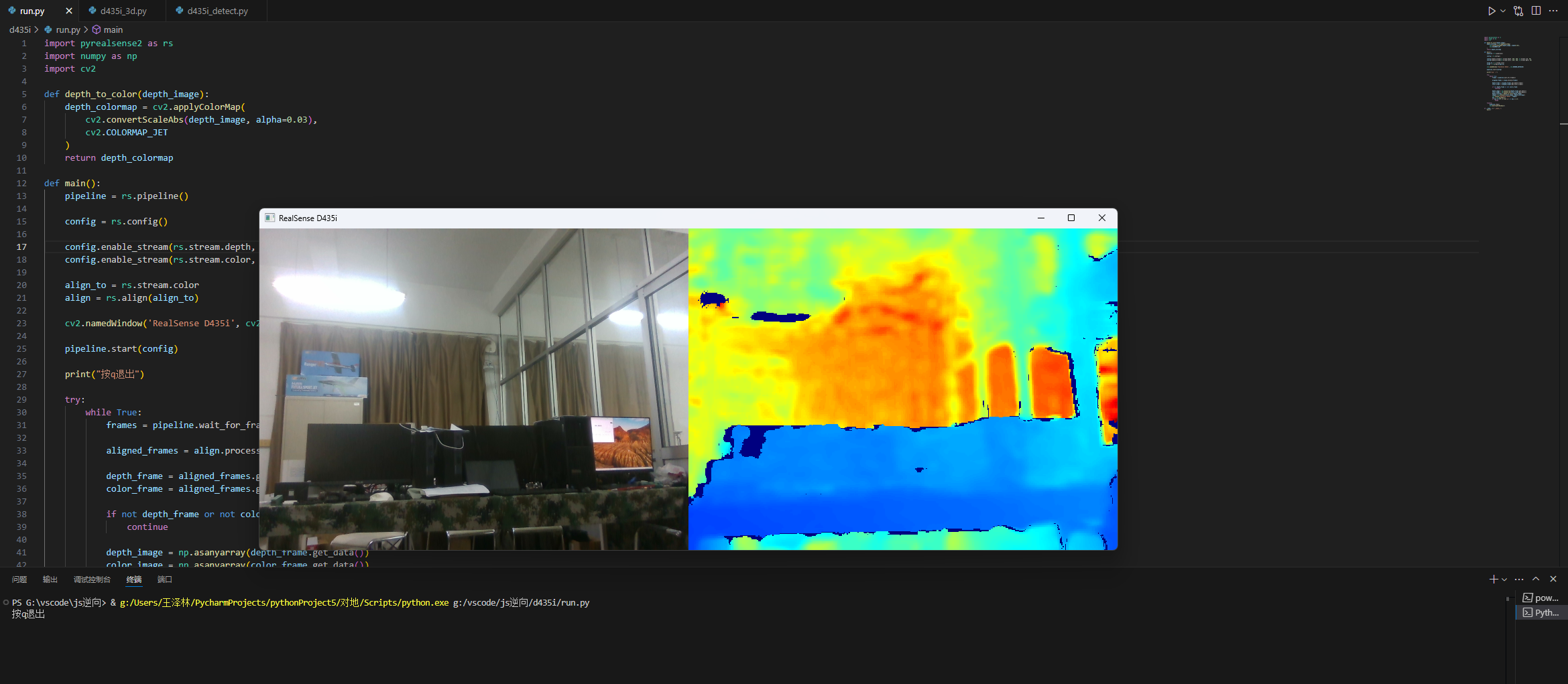
1.2用Python代码显示
新建一个run.py文件,把以下代码复制进去
import pyrealsense2 as rsimport numpy as npimport cv2def depth_to_color(depth_image): depth_colormap = cv2.applyColorMap( cv2.convertScaleAbs(depth_image, alpha=0.03), cv2.COLORMAP_JET ) return depth_colormapdef main(): pipeline = rs.pipeline() config = rs.config() config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30) align_to = rs.stream.color align = rs.align(align_to) cv2.namedWindow(\'RealSense D435i\', cv2.WINDOW_AUTOSIZE) pipeline.start(config) print(\"按q退出\") try: while True: frames = pipeline.wait_for_frames() aligned_frames = align.process(frames) depth_frame = aligned_frames.get_depth_frame() color_frame = aligned_frames.get_color_frame() if not depth_frame or not color_frame: continue depth_image = np.asanyarray(depth_frame.get_data()) color_image = np.asanyarray(color_frame.get_data()) depth_colormap = depth_to_color(depth_image) images = np.hstack((color_image, depth_colormap)) cv2.imshow(\'RealSense D435i\', images) key = cv2.waitKey(1) if key & 0xFF == ord(\'q\') or key == 27: break finally: pipeline.stop() cv2.destroyAllWindows()if __name__ == \"__main__\": main()装一下库
pip install pyrealsense2 -i https://pypi.tuna.tsinghua.edu.cn/simple运行代码
2.D435i在Ubantu上使用
2.1安装Intel RealSense Viewer
打开IntelRealSense/librealsense: Intel® RealSense™ SDK下载安装包
我是Ubantu24.04,所以我下载的是这个
如果是22.04,20.04下载这个
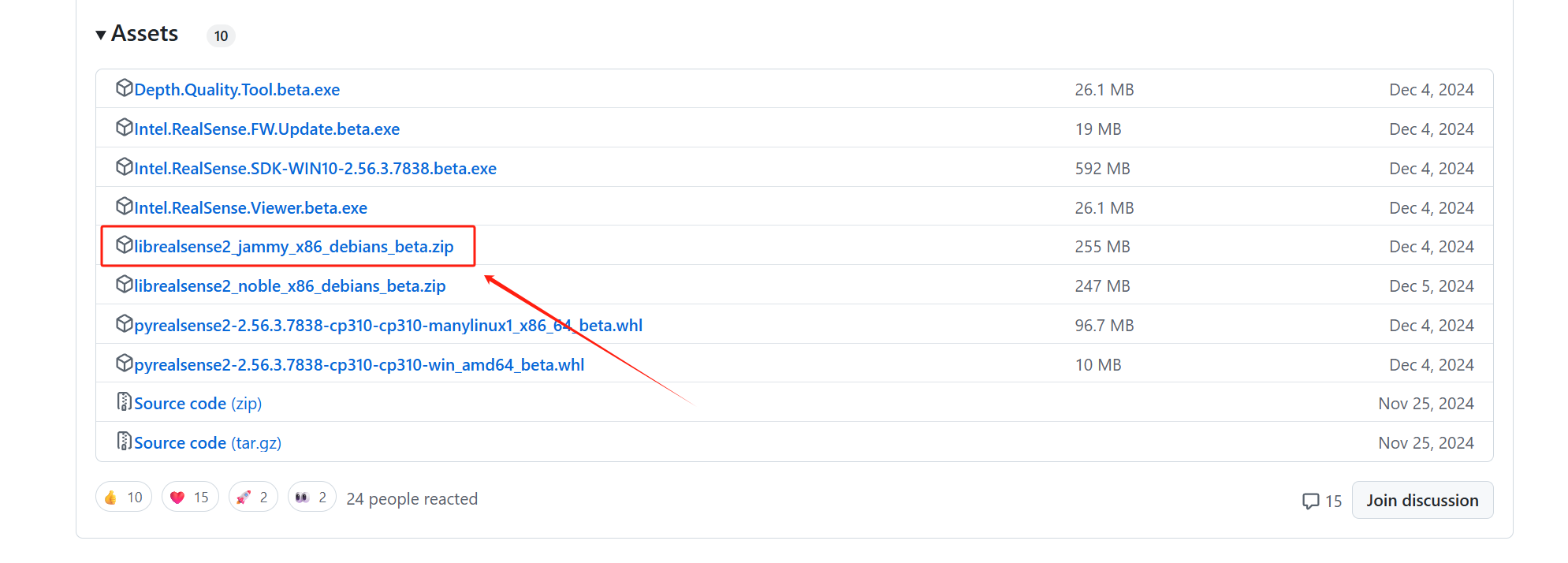
下载完之后打开文件夹,右键选择在终端打开
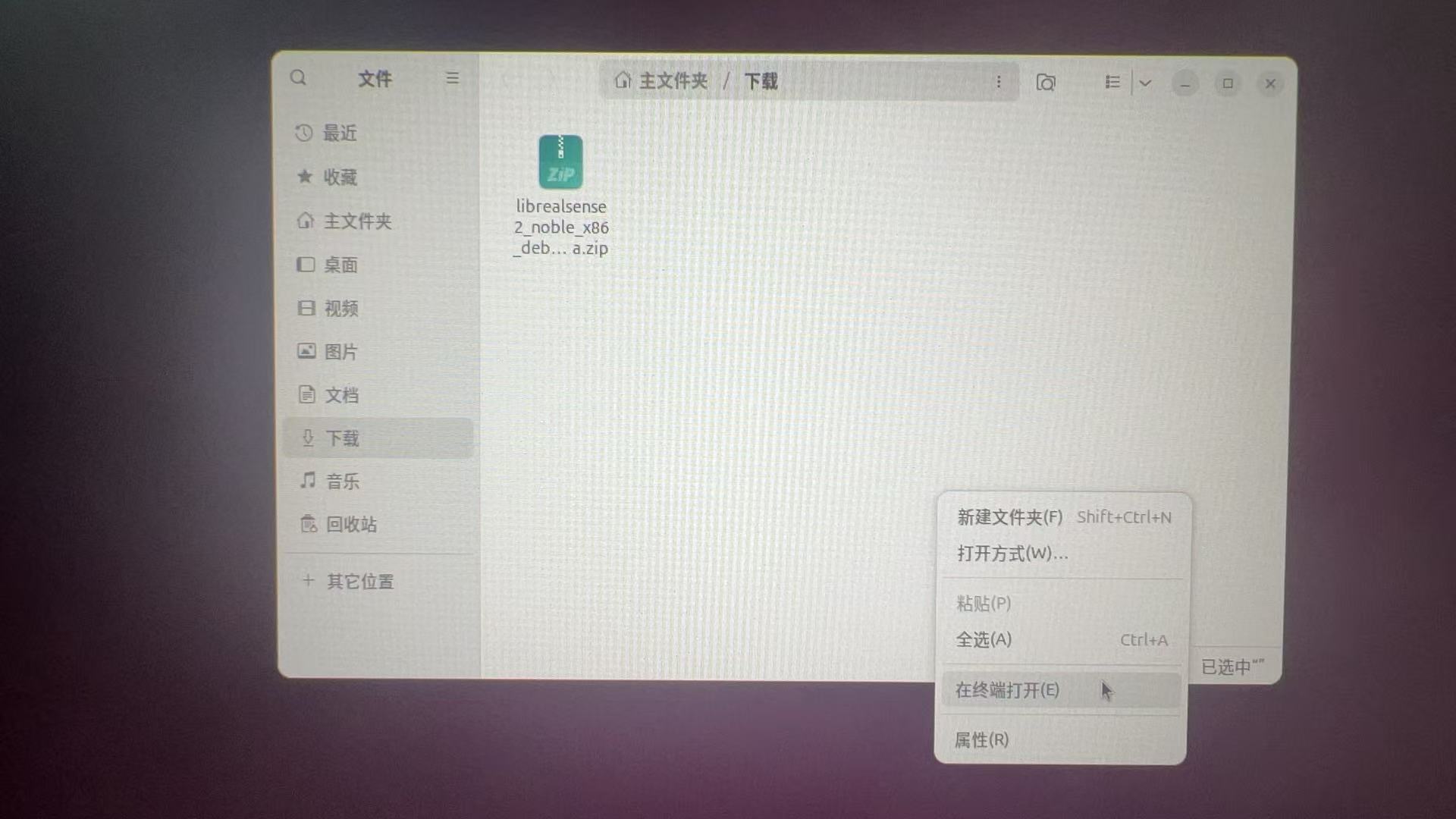
解压
unzip librealsense2_noble_x86_debians_beta.zip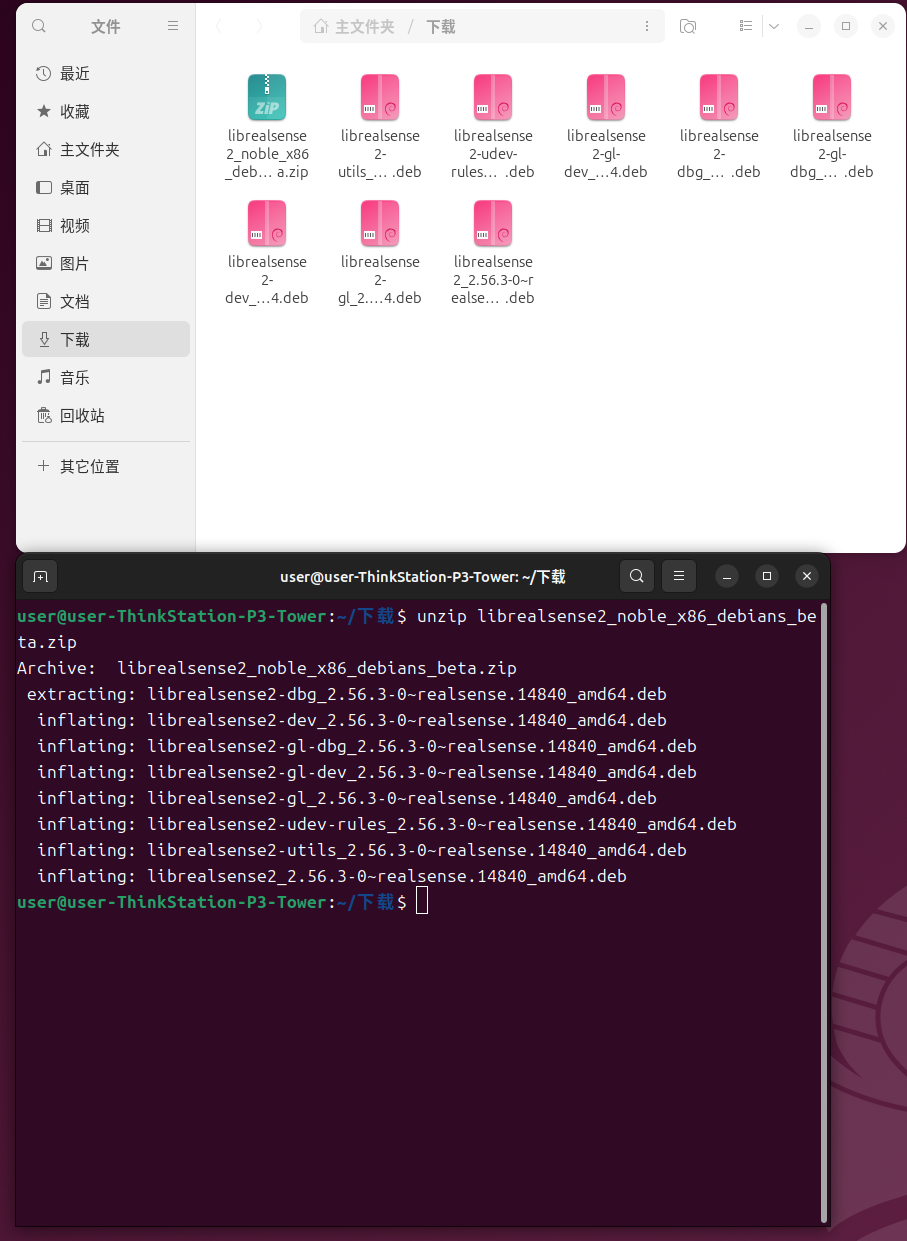
安装
sudo dpkg -i librealsense2-udev-rules_2.56.3-0~realsense.14840_amd64.debsudo dpkg -i librealsense2_2.56.3-0~realsense.14840_amd64.debsudo dpkg -i librealsense2-dev_2.56.3-0~realsense.14840_amd64.debsudo dpkg -i librealsense2-utils_2.56.3-0~realsense.14840_amd64.debsudo dpkg -i librealsense2-gl_2.56.3-0~realsense.14840_amd64.debsudo dpkg -i librealsense2-gl-dev_2.56.3-0~realsense.14840_amd64.debsudo apt-get install -f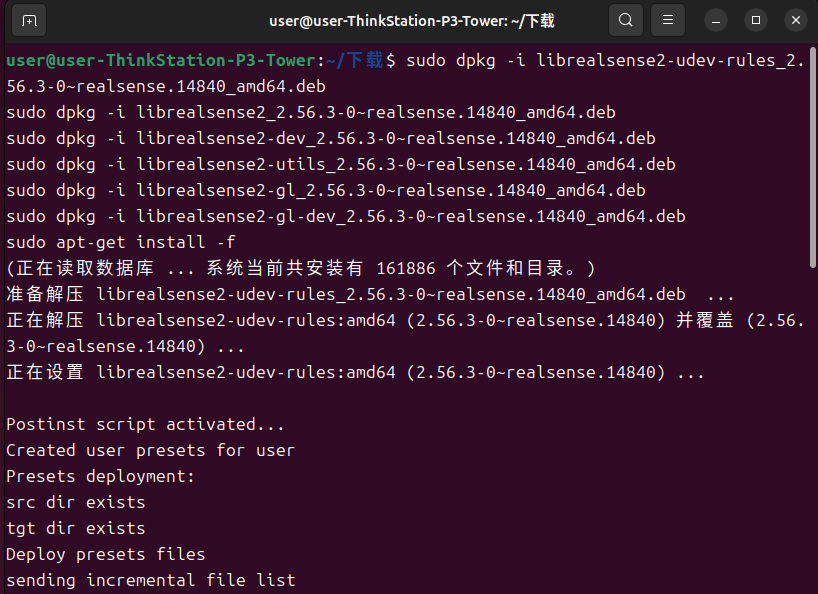
运行,右上角选择2D,左边的rgb,深度和坐标都打开
realsense-viewer
显示画面
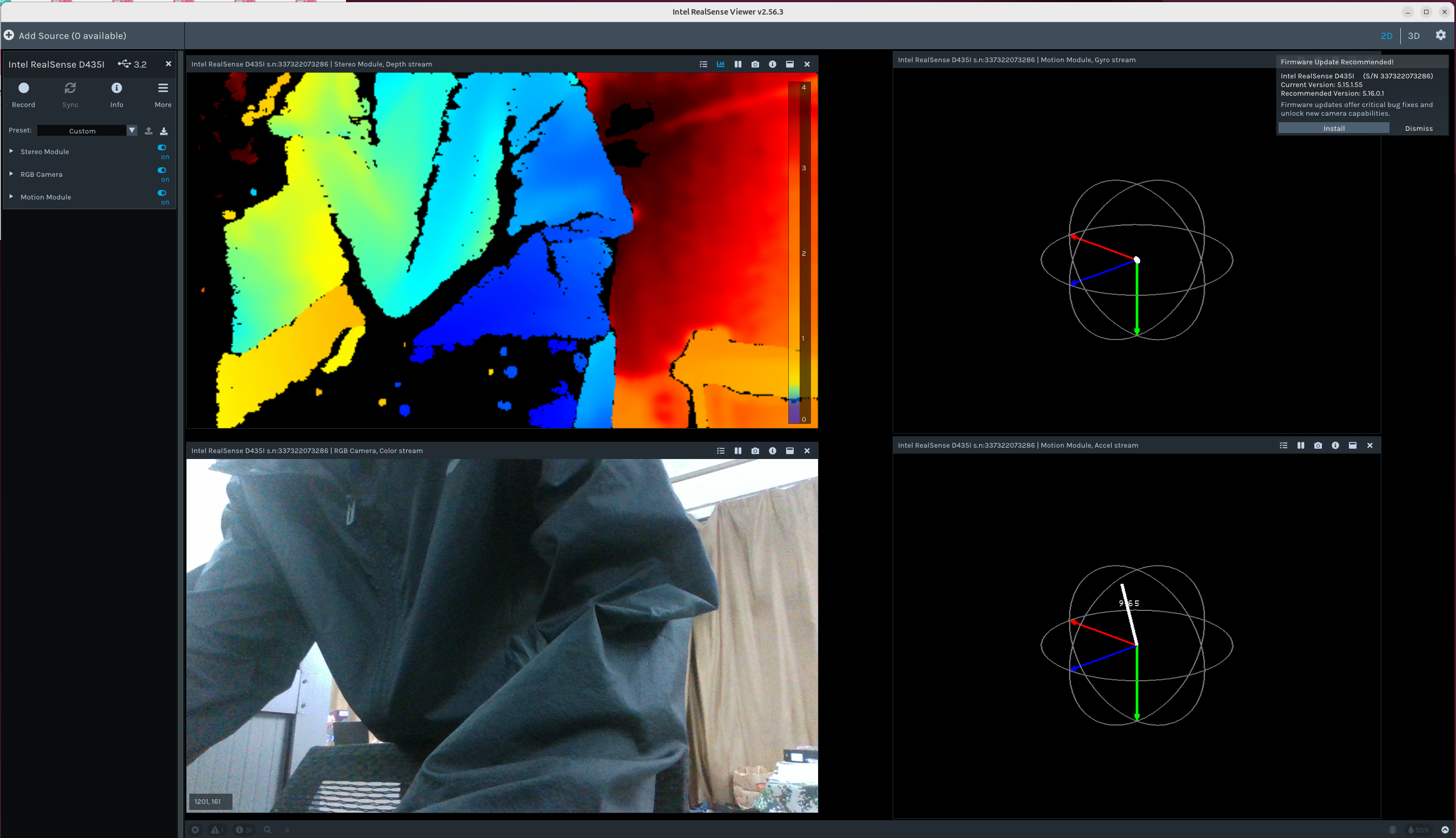
2.2用Python代码显示
Ubantu与Windows一样,只是大部分情况都用命令行。打开终端,新建一个run.py文件
nano run.py
把以下代码复制进去,按Ctrl+O写入,Ctrl+X退出
import pyrealsense2 as rsimport numpy as npimport cv2def depth_to_color(depth_image): depth_colormap = cv2.applyColorMap( cv2.convertScaleAbs(depth_image, alpha=0.03), cv2.COLORMAP_JET ) return depth_colormapdef main(): pipeline = rs.pipeline() config = rs.config() config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30) align_to = rs.stream.color align = rs.align(align_to) cv2.namedWindow(\'RealSense D435i\', cv2.WINDOW_AUTOSIZE) pipeline.start(config) print(\"按q退出\") try: while True: frames = pipeline.wait_for_frames() aligned_frames = align.process(frames) depth_frame = aligned_frames.get_depth_frame() color_frame = aligned_frames.get_color_frame() if not depth_frame or not color_frame: continue depth_image = np.asanyarray(depth_frame.get_data()) color_image = np.asanyarray(color_frame.get_data()) depth_colormap = depth_to_color(depth_image) images = np.hstack((color_image, depth_colormap)) cv2.imshow(\'RealSense D435i\', images) key = cv2.waitKey(1) if key & 0xFF == ord(\'q\') or key == 27: break finally: pipeline.stop() cv2.destroyAllWindows()if __name__ == \"__main__\": main()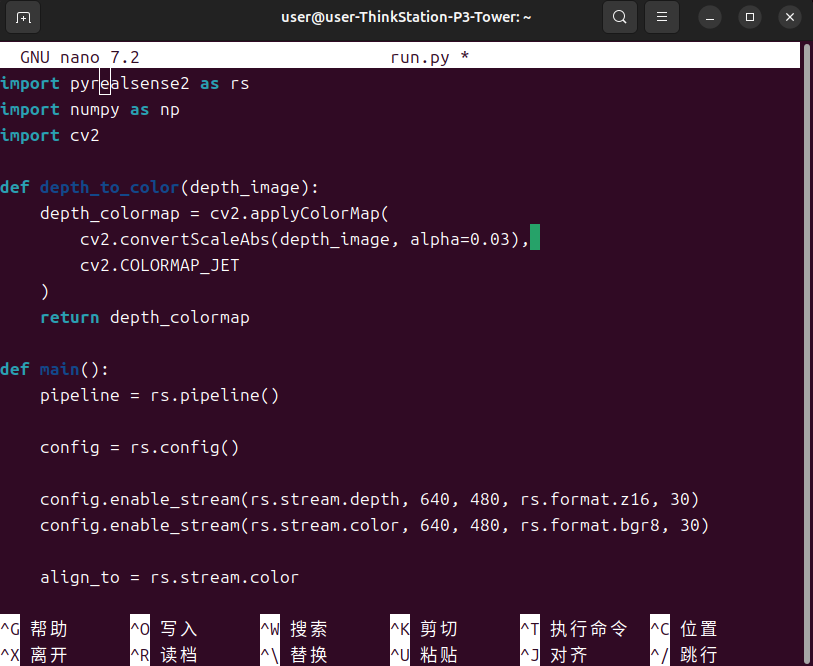
装库
pip install pyrealsense2 -i https://pypi.tuna.tsinghua.edu.cn/simple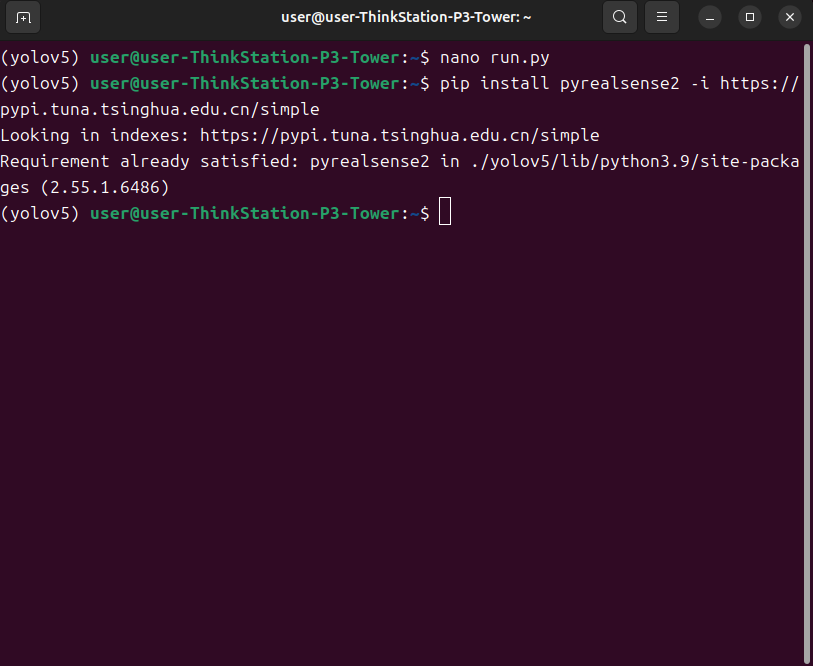
直接运行
python run.py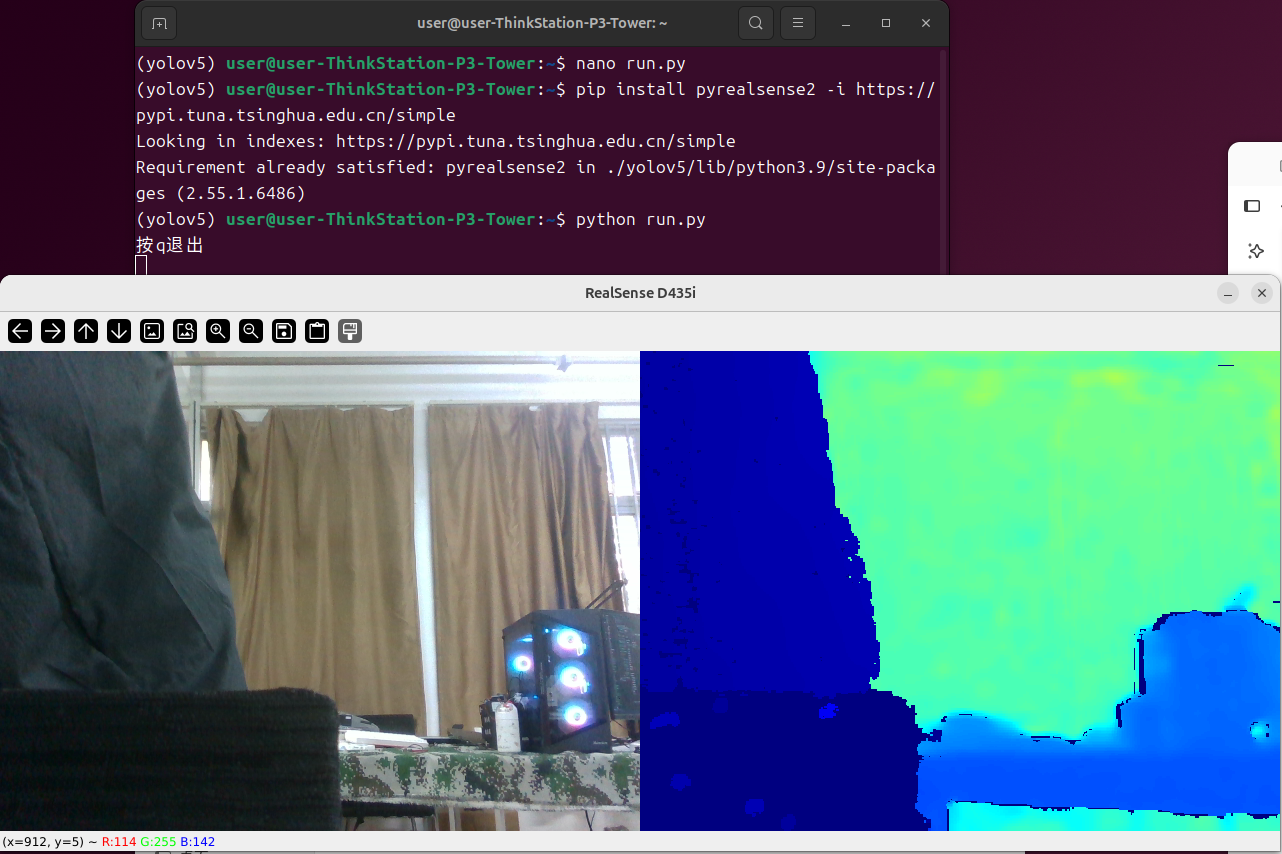
3.Ubantu部署yolov5并调用D435i进行检测
3.1创建yolov5环境
Ctrl+Alt+T打开终端,输入以下命令获取更多Python版本,注意输入密码的时候不显示,输入完按回车就可以。
sudo apt updatesudo apt install software-properties-commonsudo add-apt-repository ppa:deadsnakes/ppasudo apt update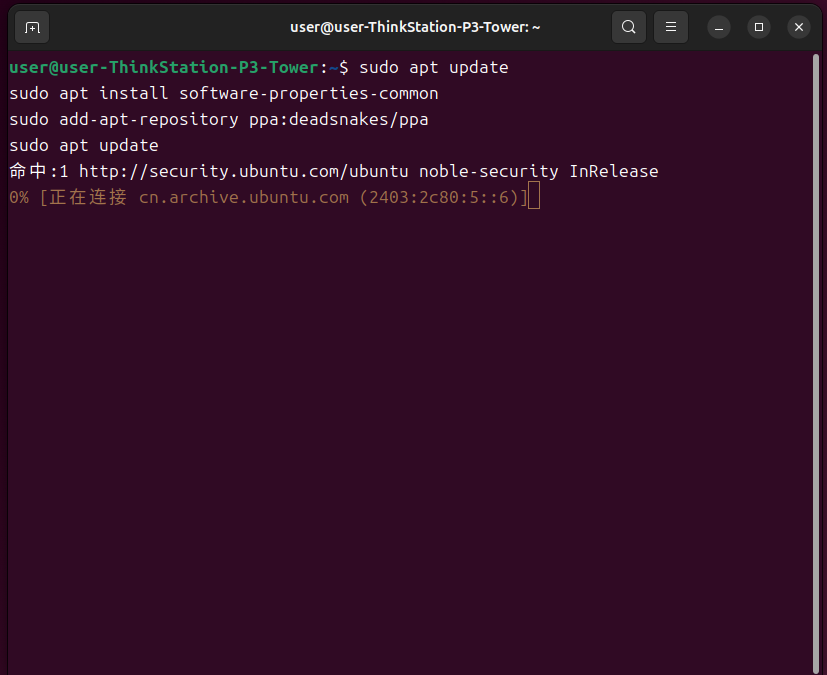
安装Python3.9,输入y确认安装
sudo apt install python3.9 python3.9-venv python3.9-dev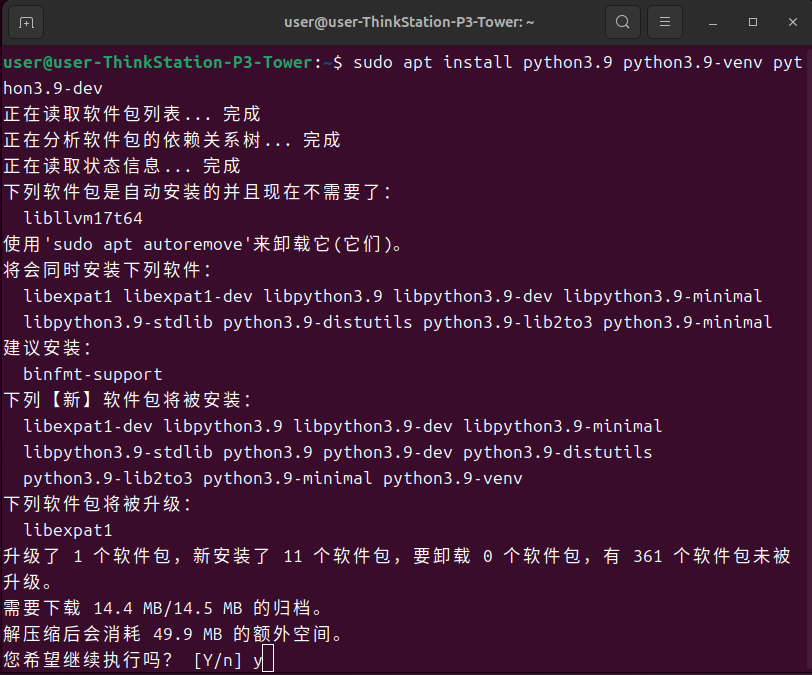
新建虚拟环境
python3.9 -m venv yolov5
激活环境,出现yolov5就算是激活成功了
source yolov5/bin/activate
3.2安装gpu版本Pytorch
打开终端,在终端输入
nvidia-smi查看显卡驱动版本
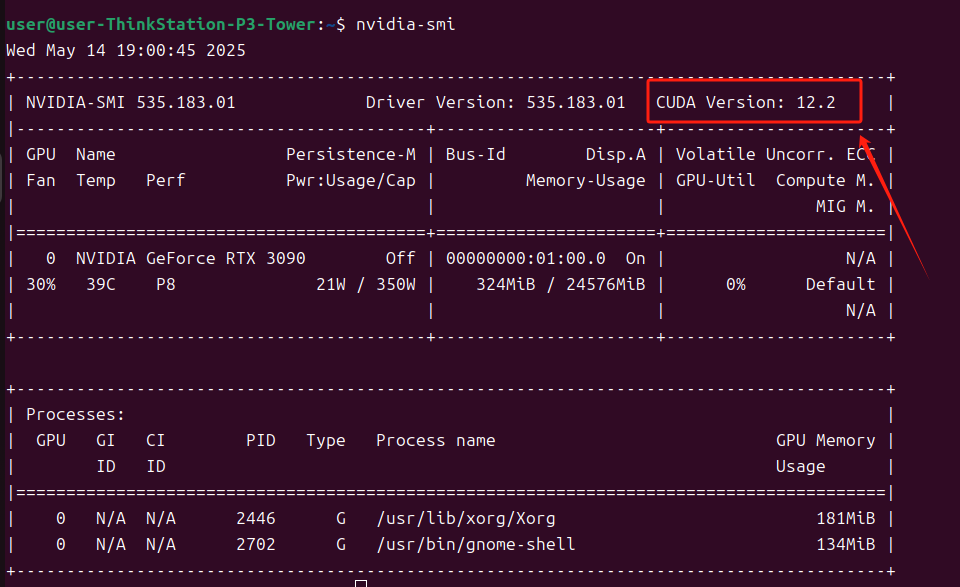
记住这个版本打开CUDA Toolkit Archive | NVIDIA Developer,点击对应的版本
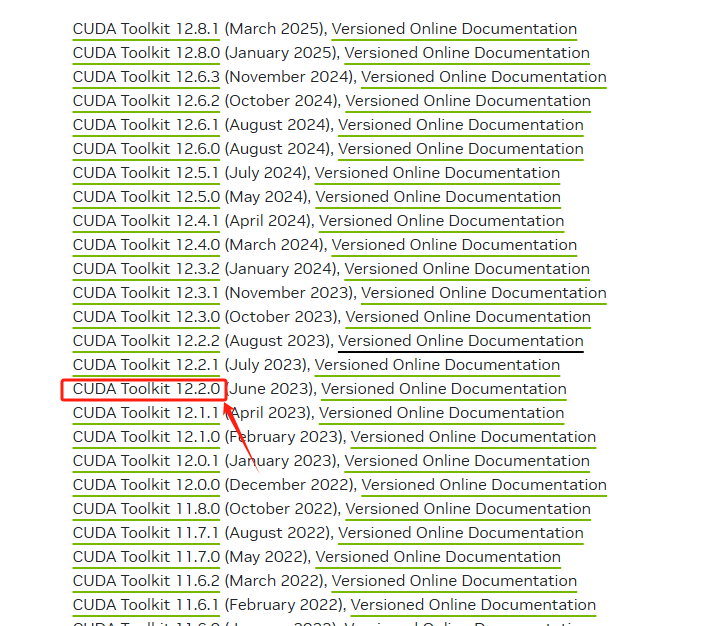
选择对应的系统,一般都是X86
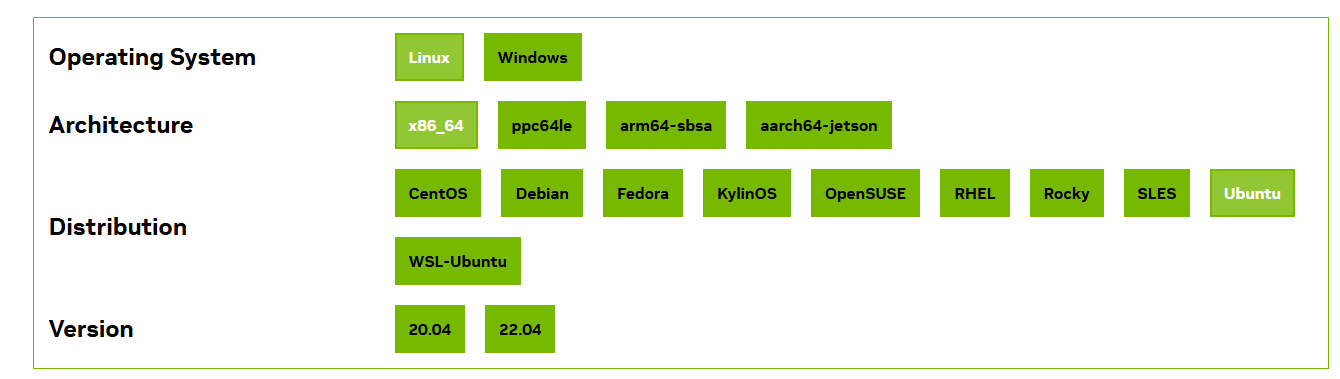
这里因为我的乌班图版本是24.04,但是cuda没有24.04的,所以需要升级一下显卡驱动。
打开终端输入以下命令查看可以安装的驱动版本
ubuntu-drivers devices
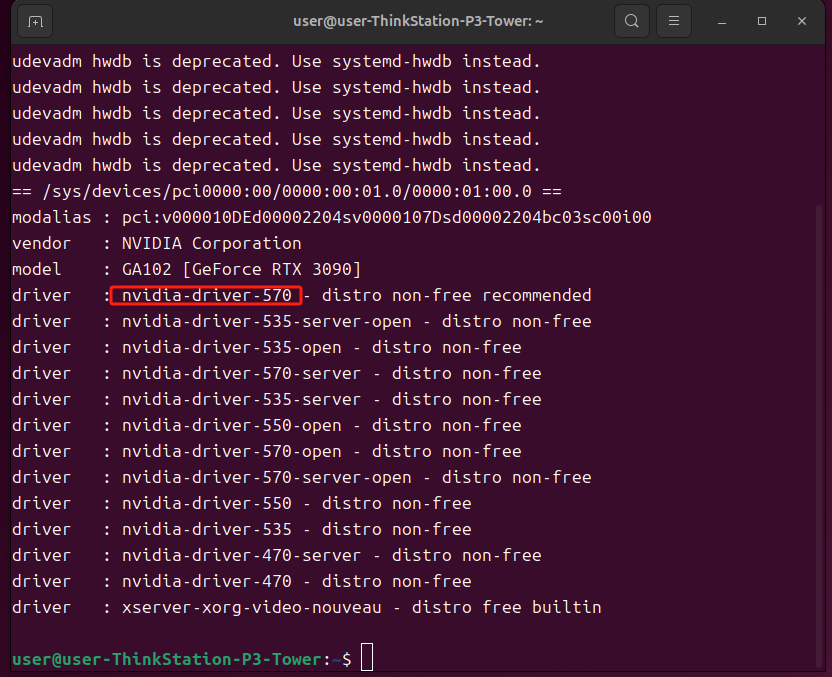
这里选择安装推荐的版本
sudo apt install nvidia-driver-570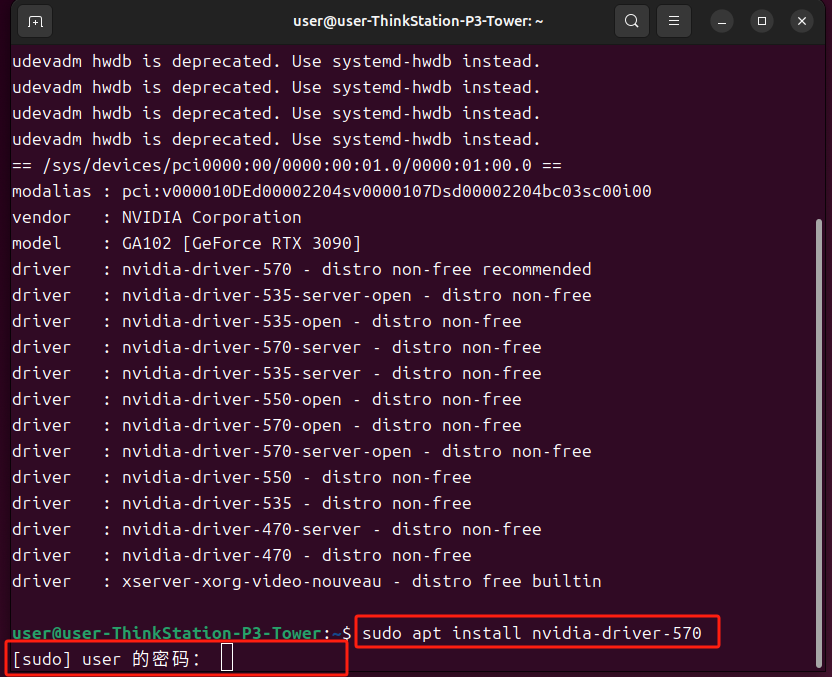
确认安装
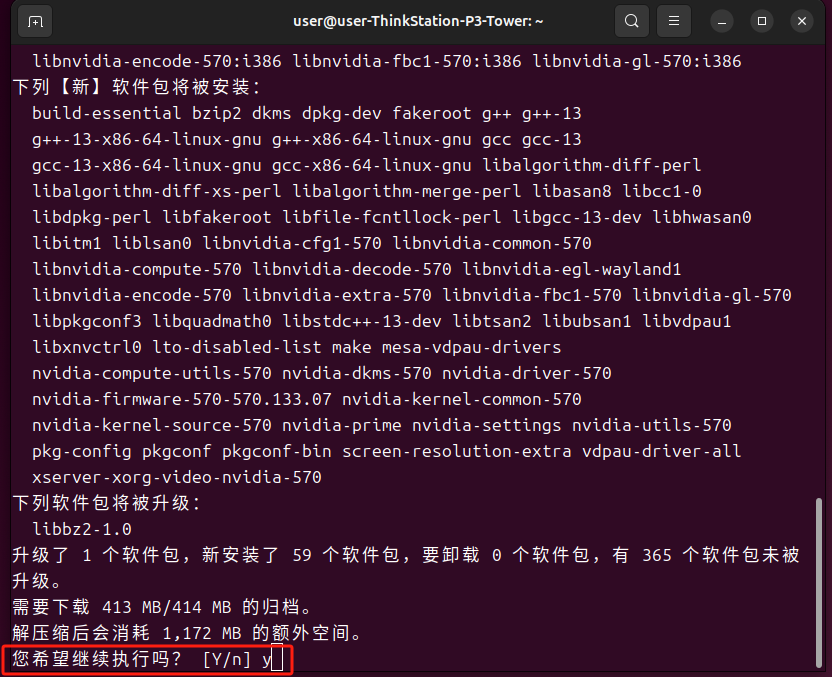
没有报错就是安装成功了,安装完成后重启一下电脑。
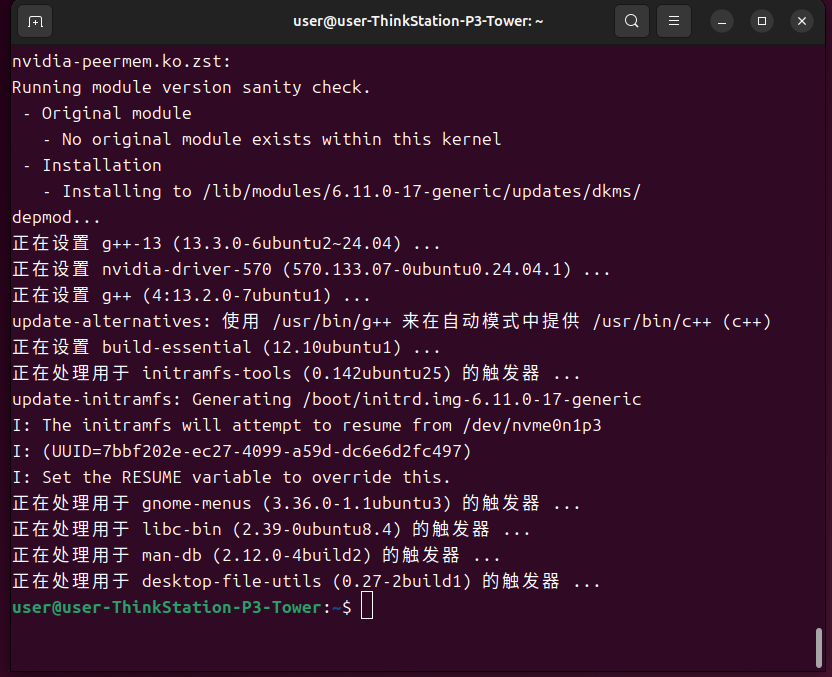
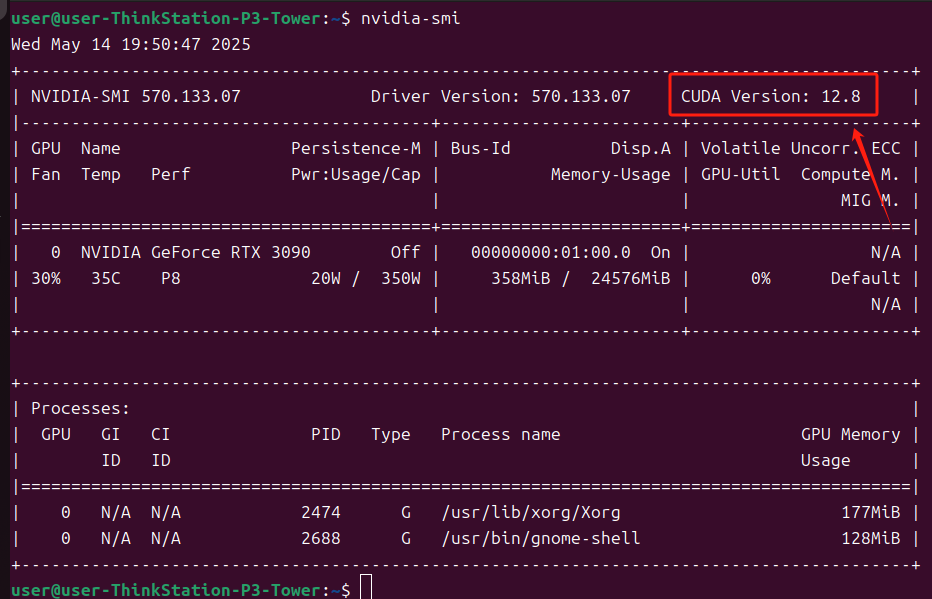
再次打开终端输入
nvidia-smi可以看到版本已经更新了
CUDA Toolkit Archive | NVIDIA Developer打开这个网站,找到与自己版本对应的cuda
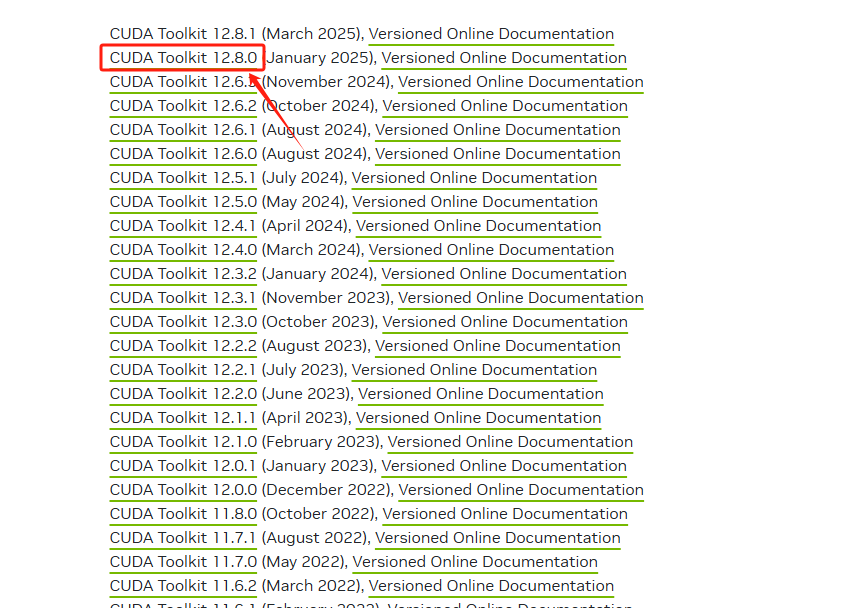
选择对应的版本,注意这里选择runfile
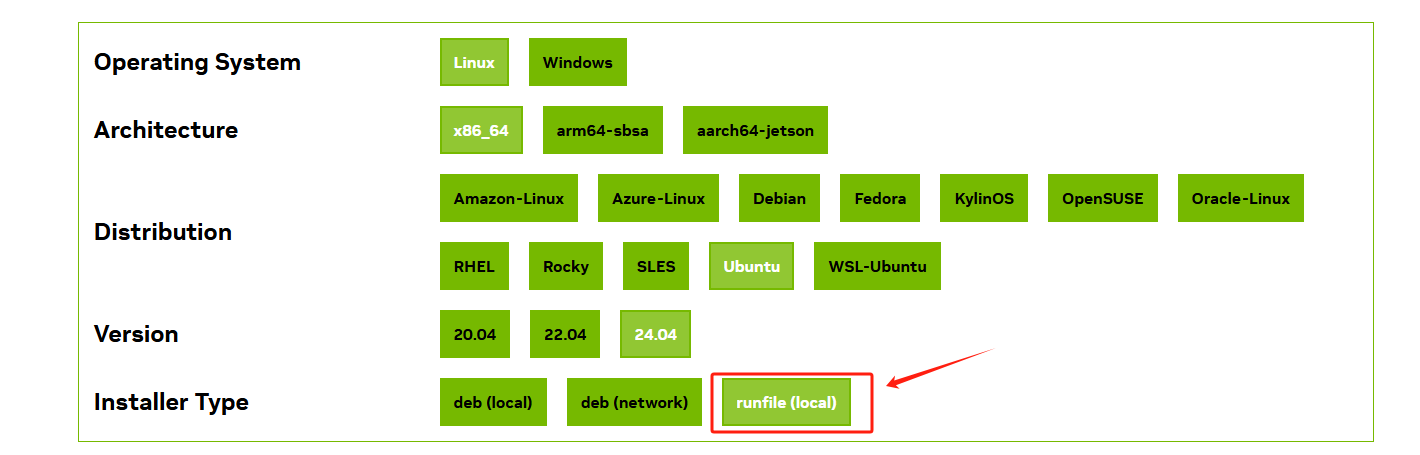
复制以下命令在终端输入
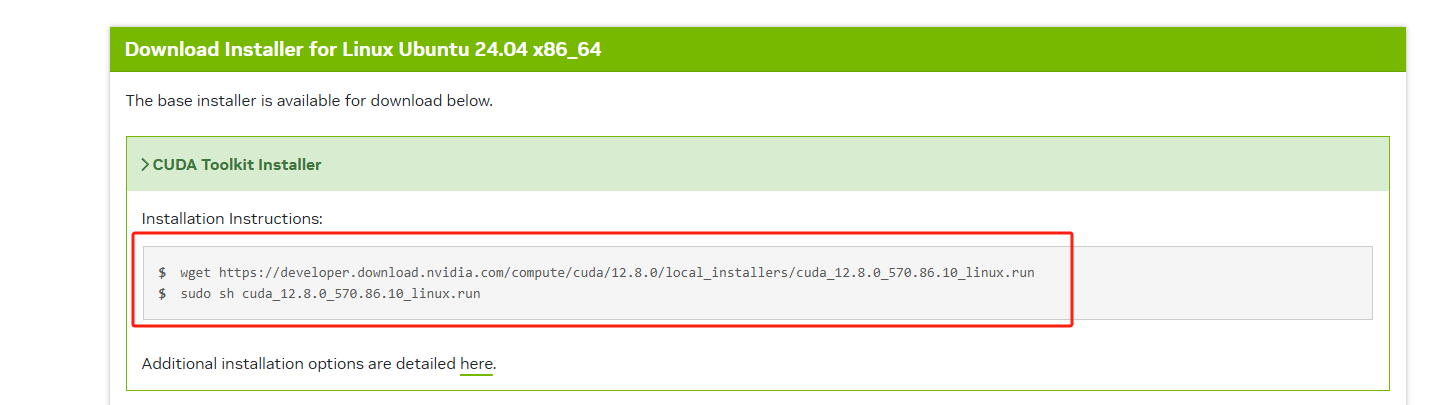
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.86.10_linux.run等待下载
下载完成后输入以下命令安装
sudo sh cuda_12.8.0_570.86.10_linux.run
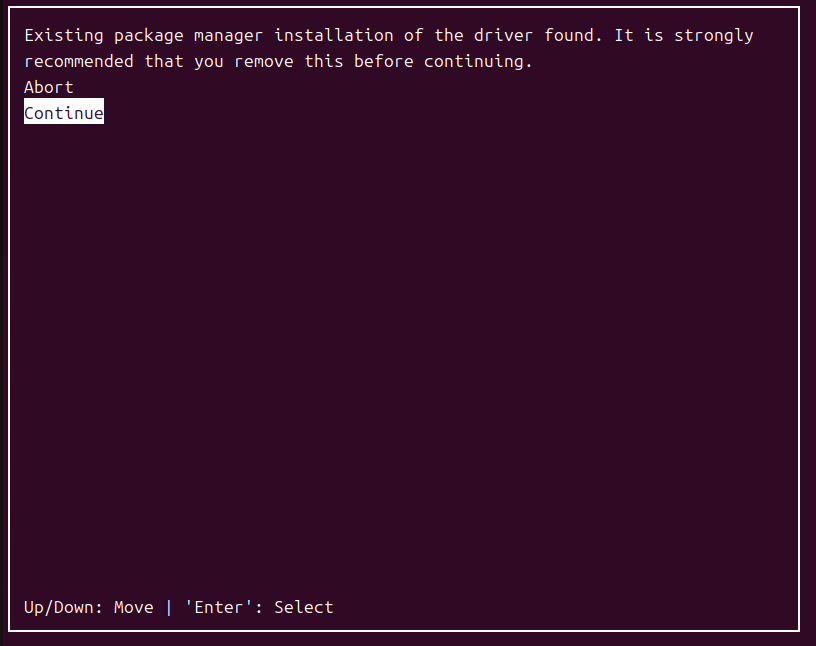
选择继续
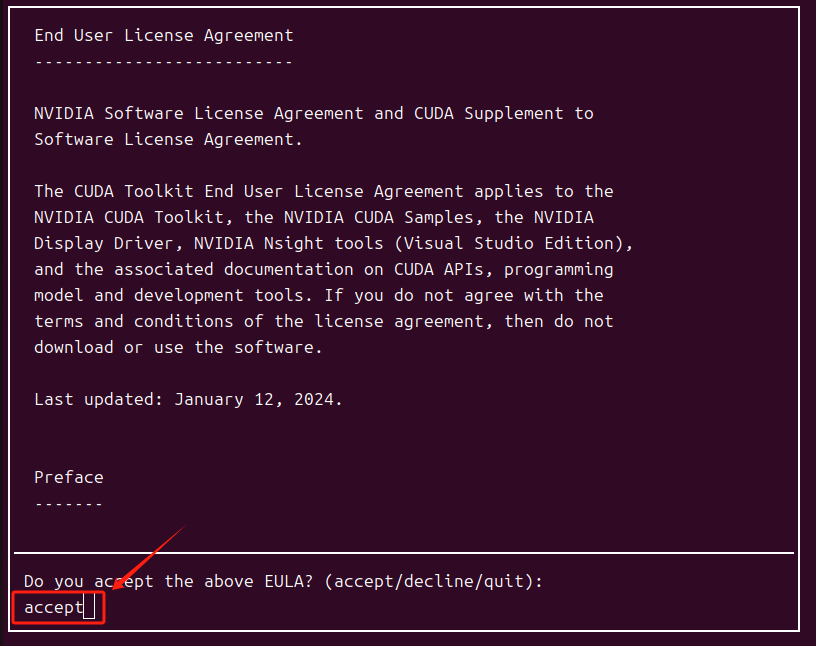
输入一下接收
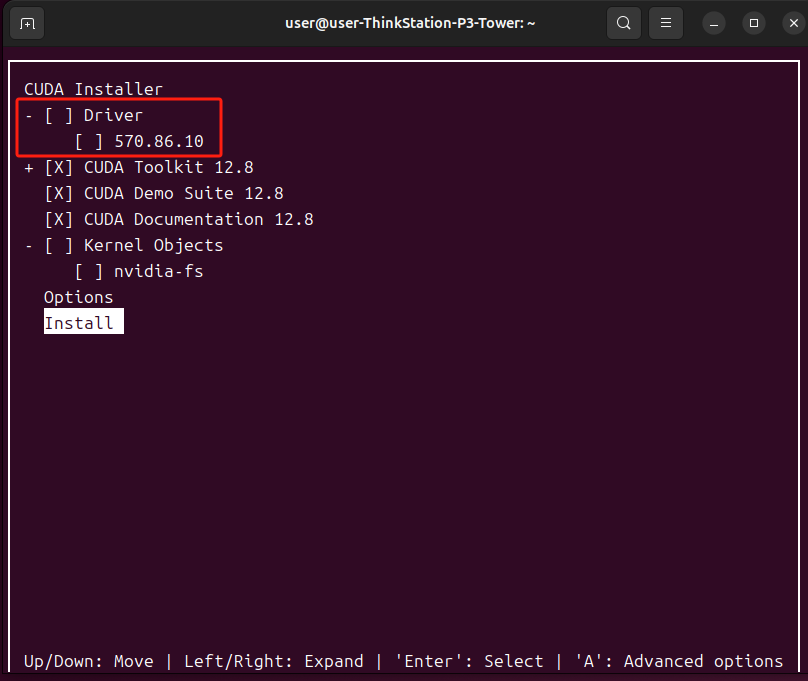
把光标移动到Driver按下空格,取消安装显卡驱动,因为之前的步骤已经安装过了这里重复安装会报错。然后光标移动到Install回车进行安装。
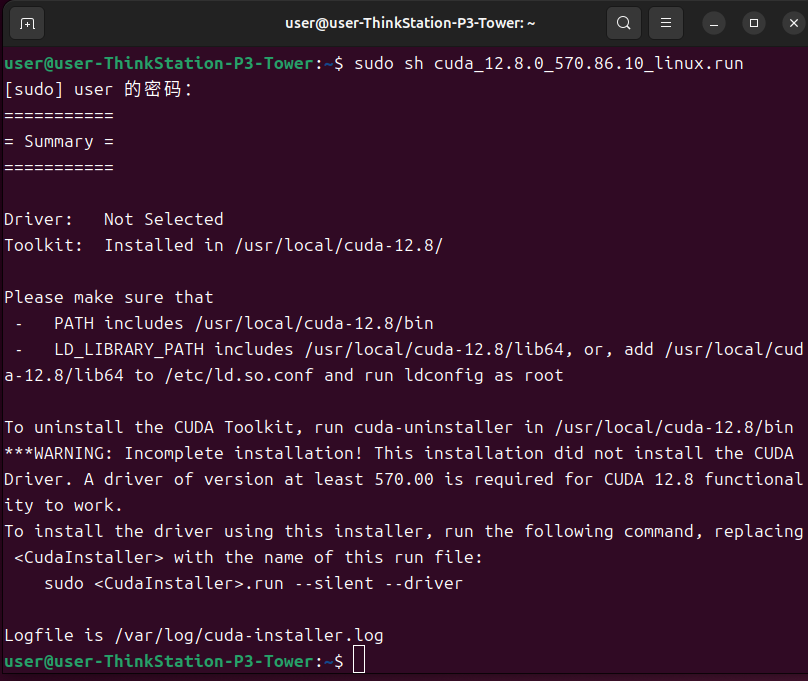
出现以下内容即为安装成功。
使用文本编辑器打开环境变量文件
nano ~/.bashrc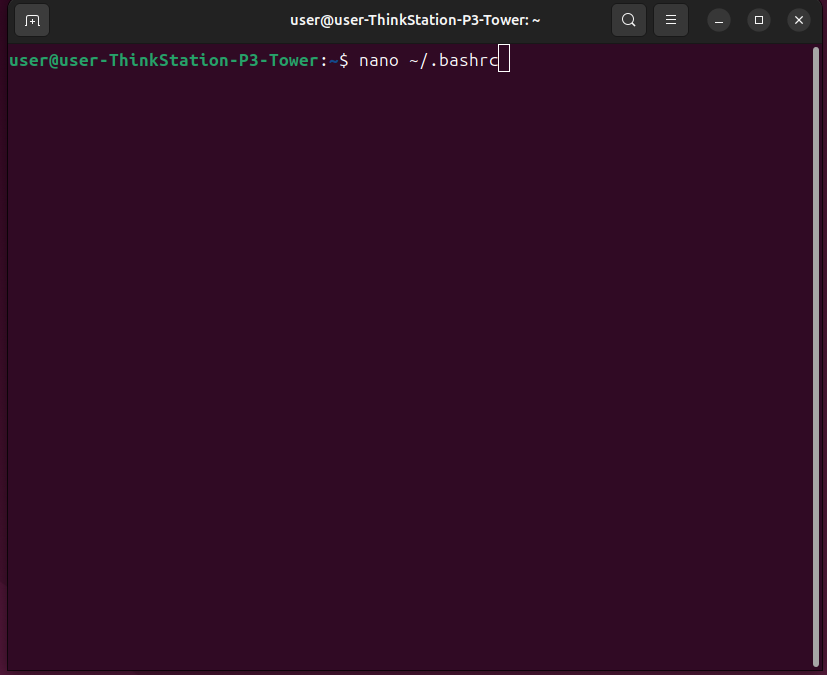
在文件最后添加以下内容
export PATH=/usr/local/cuda-12.8/bin${PATH:+:${PATH}}export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}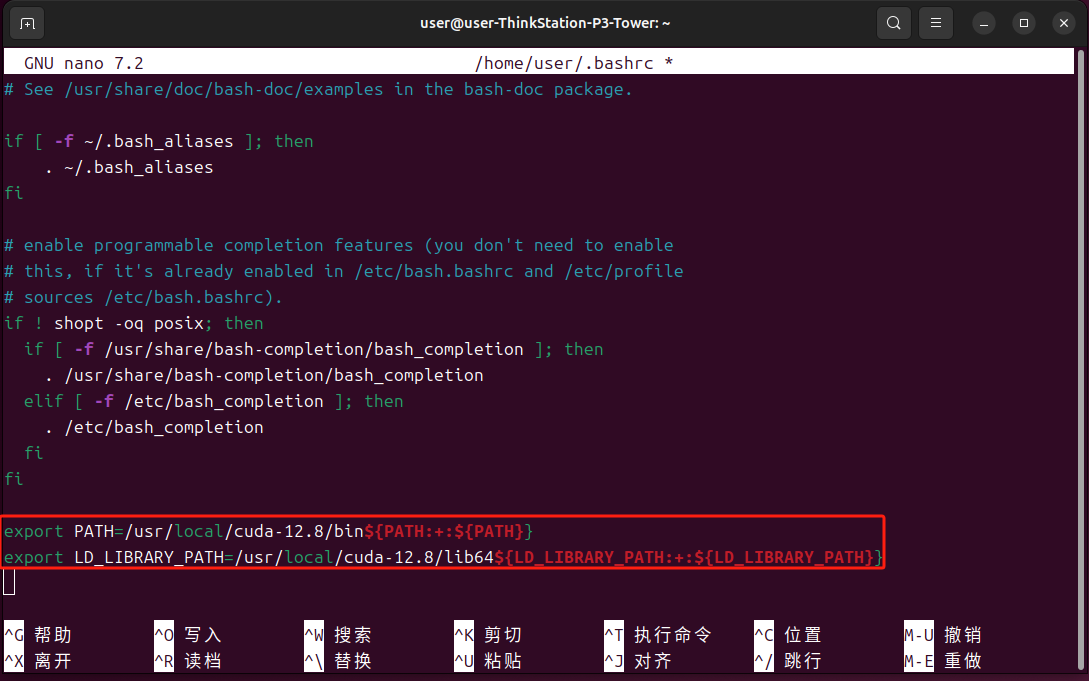
按下Ctrl+O写入,Ctrl+X离开,然后更新一下环境变量
source ~/.bashrc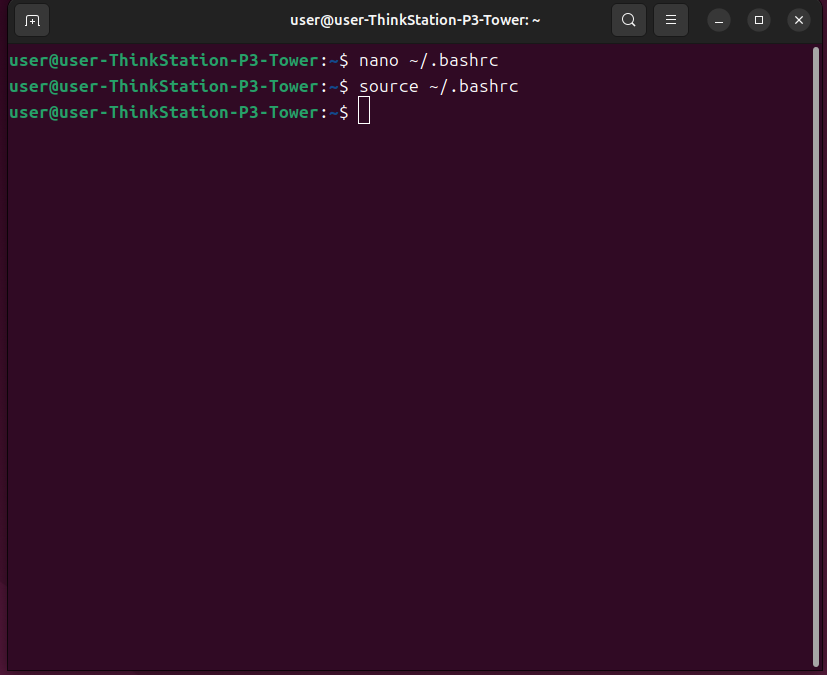
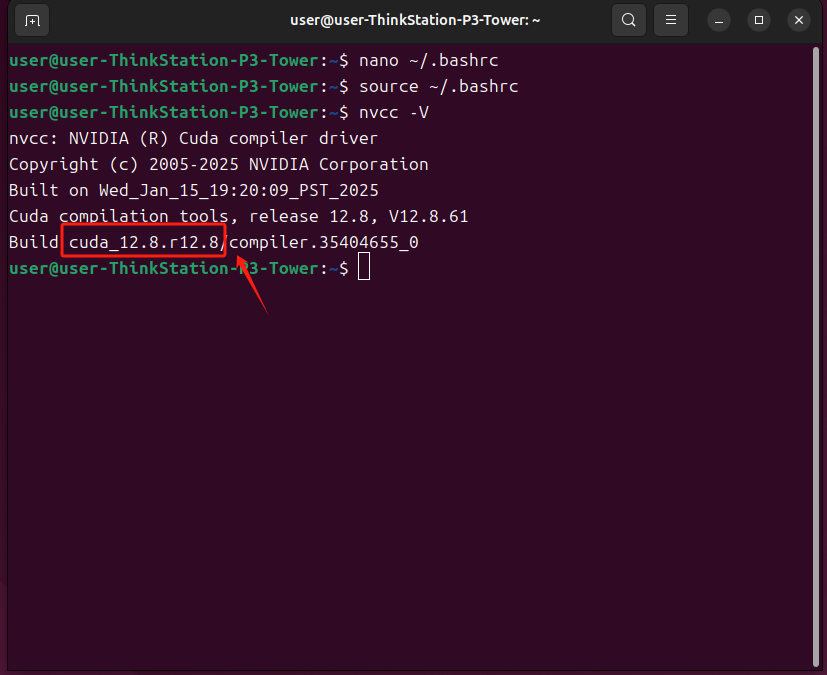
输入以下命令查看cuda是否安装成功
nvcc -V出现以下内容即为安装成功,重启一下电脑,记住这个版本。
打开PyTorch官网,找到与自己对应的Pytorch版本,因为我这里是12.8所以我选择12.8。如果是12.7这里没有12.7那就选择12.6,高版本cuda兼容低版本Pytorch!
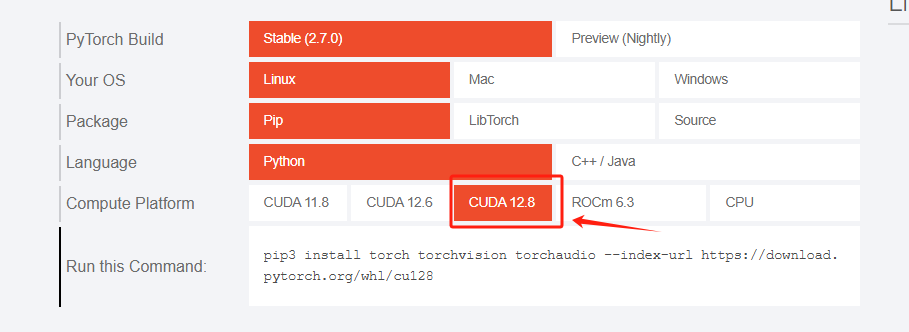
打开终端,激活环境
source yolov5/bin/activate
更新一下pip
pip install --upgrade pip
复制Pytorch官网上的命令安装
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128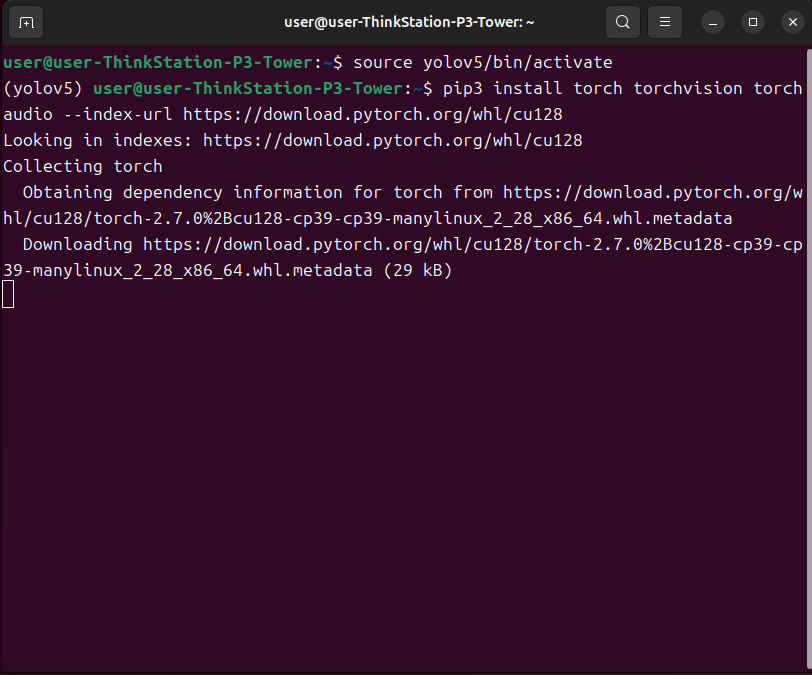
没有报错就是安装成功了,安装不成功大多数情况是网络问题。
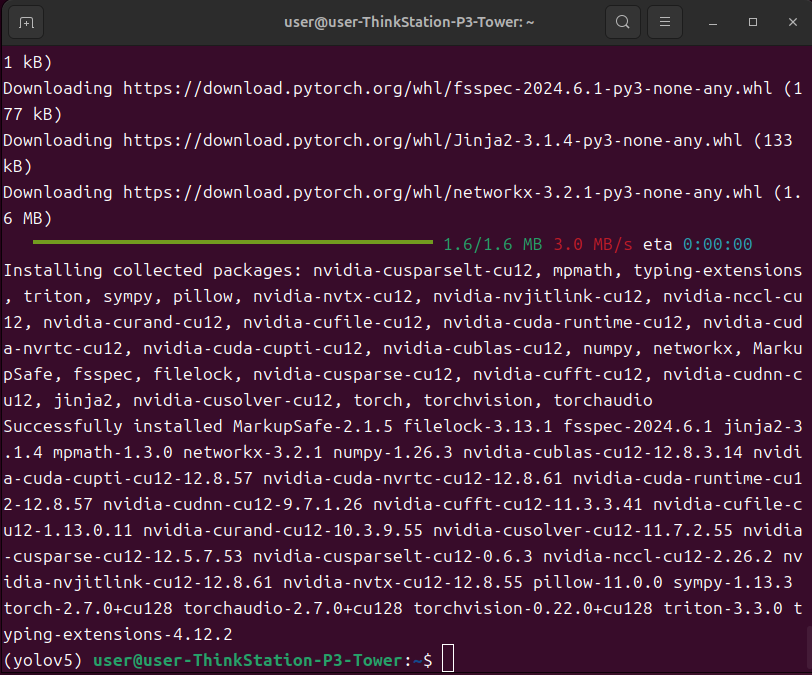
安装ultralytics
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
3.3安装cup版本Pytorch
打开终端,激活环境
source yolov5/bin/activate
更新一下pip
pip install --upgrade pip
安装ultralytics,安装这个库的时候会顺带安装cpu版本的Pytorch
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
3.4克隆yolov5源码
安装git命令
sudo apt install git -y
克隆yolov5源码,因为新建的环境名叫yolov5,这里克隆yolov5源码的时候需要改一下主文件夹名称,不然就会有两个yolov5,这里指定名字叫yolov5-repo
git clone https://github.com/ultralytics/yolov5.git yolov5-repo
3.5验证安装
切换到yolov5-repo文件夹下
cd yolov5-repo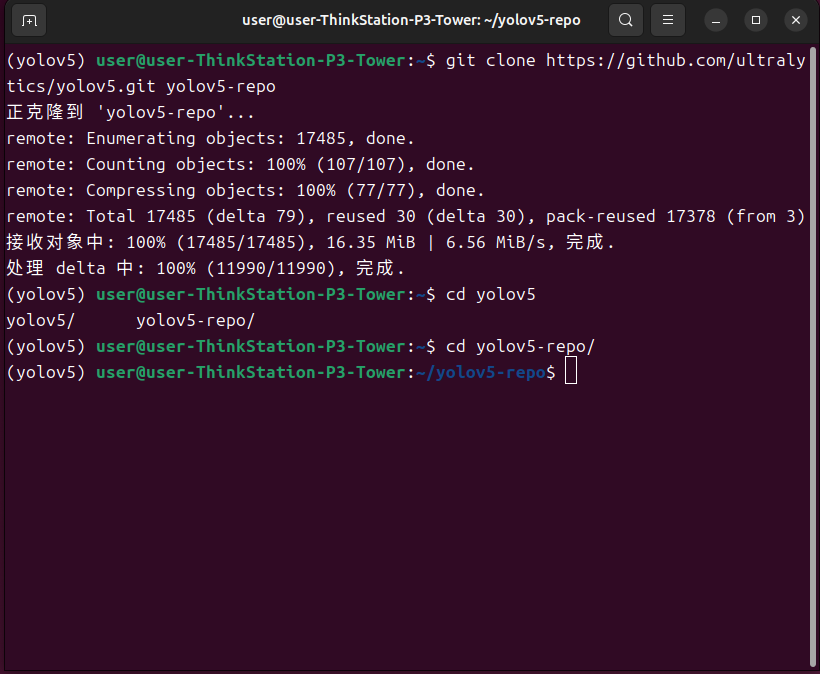
下载预训练模型
python -c \"import torch; torch.hub.download_url_to_file(\'https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt\', \'yolov5s.pt\')\"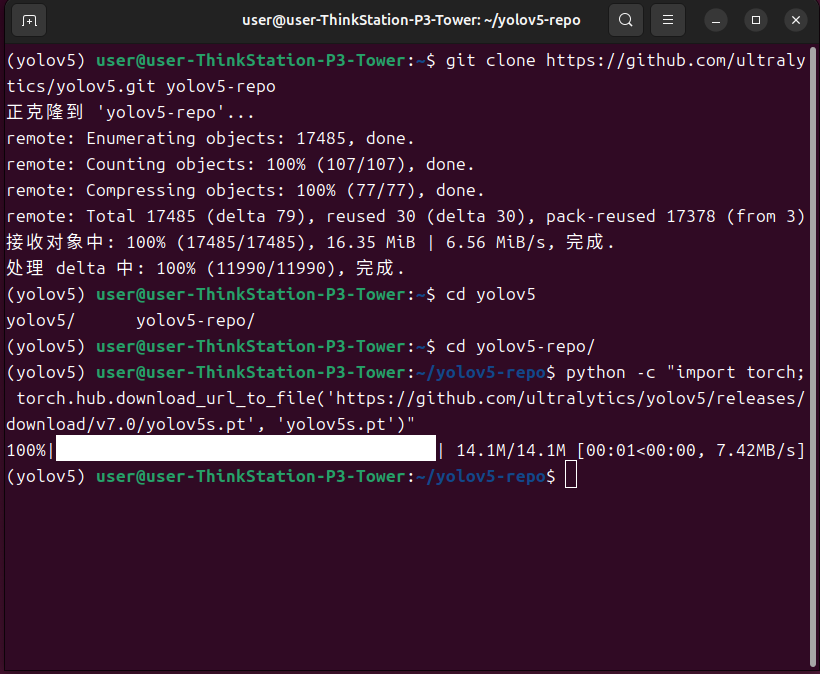
预测一下验证是否安装成功
python detect.py --source data/images/bus.jpg --weights yolov5s.pt这个路径是预测结果,可以打开查看一下
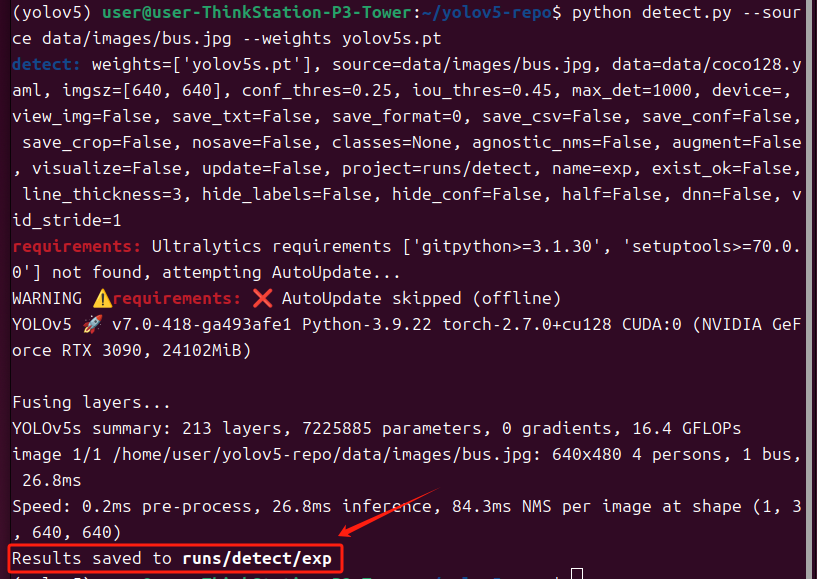
到这里yolov5就安装完了。

3.6调用D435i实时检测
安装D435i库pyrealsense2
pip install pyrealsense2 -i https://pypi.tuna.tsinghua.edu.cn/simple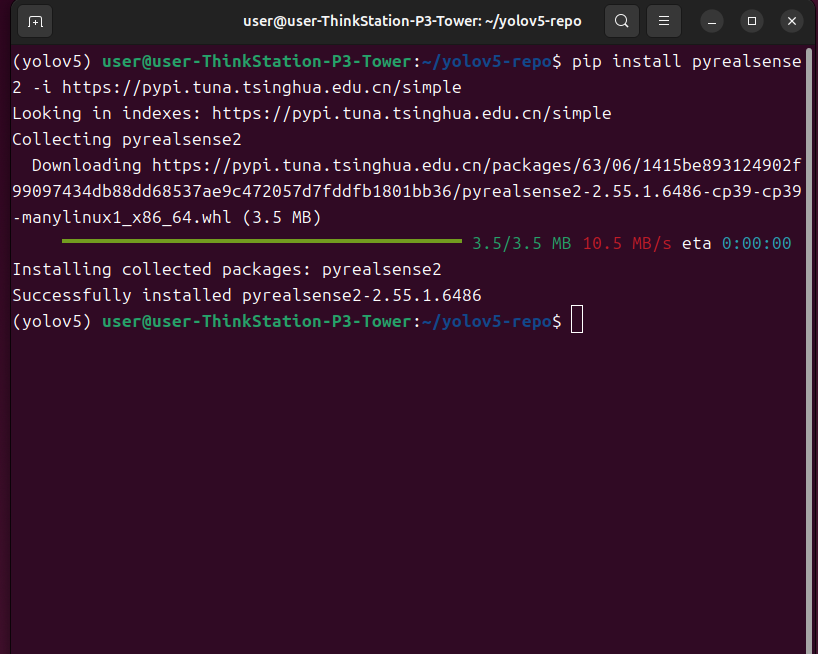
在yolov5-repo文件夹下新建一个d435i_detect.py文件
nano d435i_detect.py
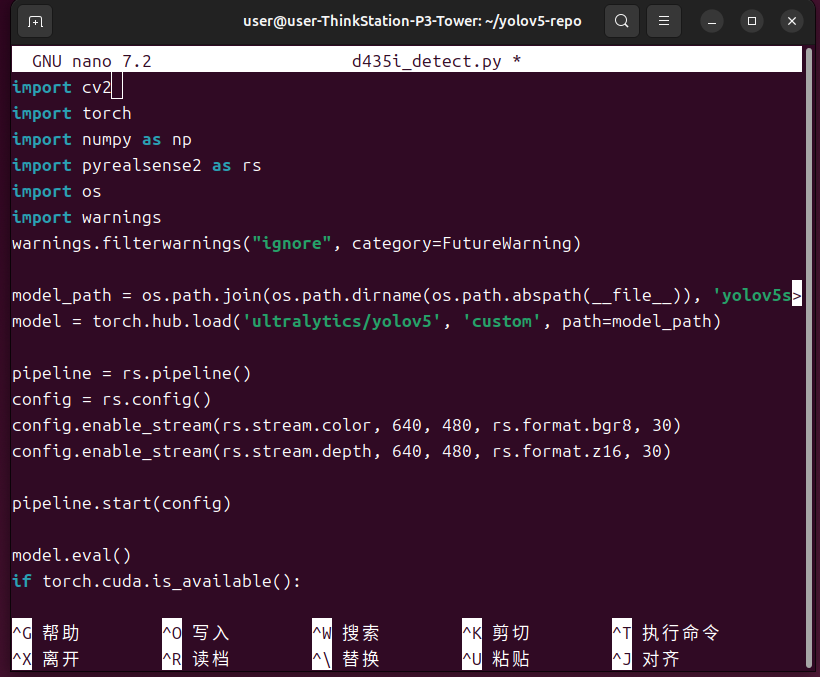
复制以下代码
import cv2import torchimport numpy as npimport pyrealsense2 as rsimport osimport warningswarnings.filterwarnings(\"ignore\", category=FutureWarning)model_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \'yolov5s.pt\')model = torch.hub.load(\'ultralytics/yolov5\', \'custom\', path=model_path)pipeline = rs.pipeline()config = rs.config()config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)pipeline.start(config)model.eval()if torch.cuda.is_available(): model.cuda()align = rs.align(rs.stream.color)try: while True: frames = pipeline.wait_for_frames() aligned_frames = align.process(frames) color_frame = aligned_frames.get_color_frame() depth_frame = aligned_frames.get_depth_frame() if not color_frame or not depth_frame: continue color_image = np.asanyarray(color_frame.get_data()) depth_image = np.asanyarray(depth_frame.get_data()) depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.03), cv2.COLORMAP_JET) results = model(color_image) detections = results.pandas().xyxy[0].to_dict(\'records\') for detection in detections: xmin, ymin, xmax, ymax = int(detection[\'xmin\']), int(detection[\'ymin\']), int(detection[\'xmax\']), int(detection[\'ymax\']) cv2.rectangle(color_image, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2) label = f\"{detection[\'name\']} {detection[\'confidence\']:.2f}\" cv2.putText(color_image, label, (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2) cv2.rectangle(depth_colormap, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2) cv2.putText(depth_colormap, label, (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2) images = np.hstack((color_image, depth_colormap)) cv2.namedWindow(\'RealSense D435i YOLOv5 Detection\', cv2.WINDOW_AUTOSIZE) cv2.imshow(\'RealSense D435i YOLOv5 Detection\', images) key = cv2.waitKey(1) if key == 27: break finally: pipeline.stop() cv2.destroyAllWindows()Ctrl+O写入,Ctrl+X离开
运行代码进行检测
python d435i_detect.py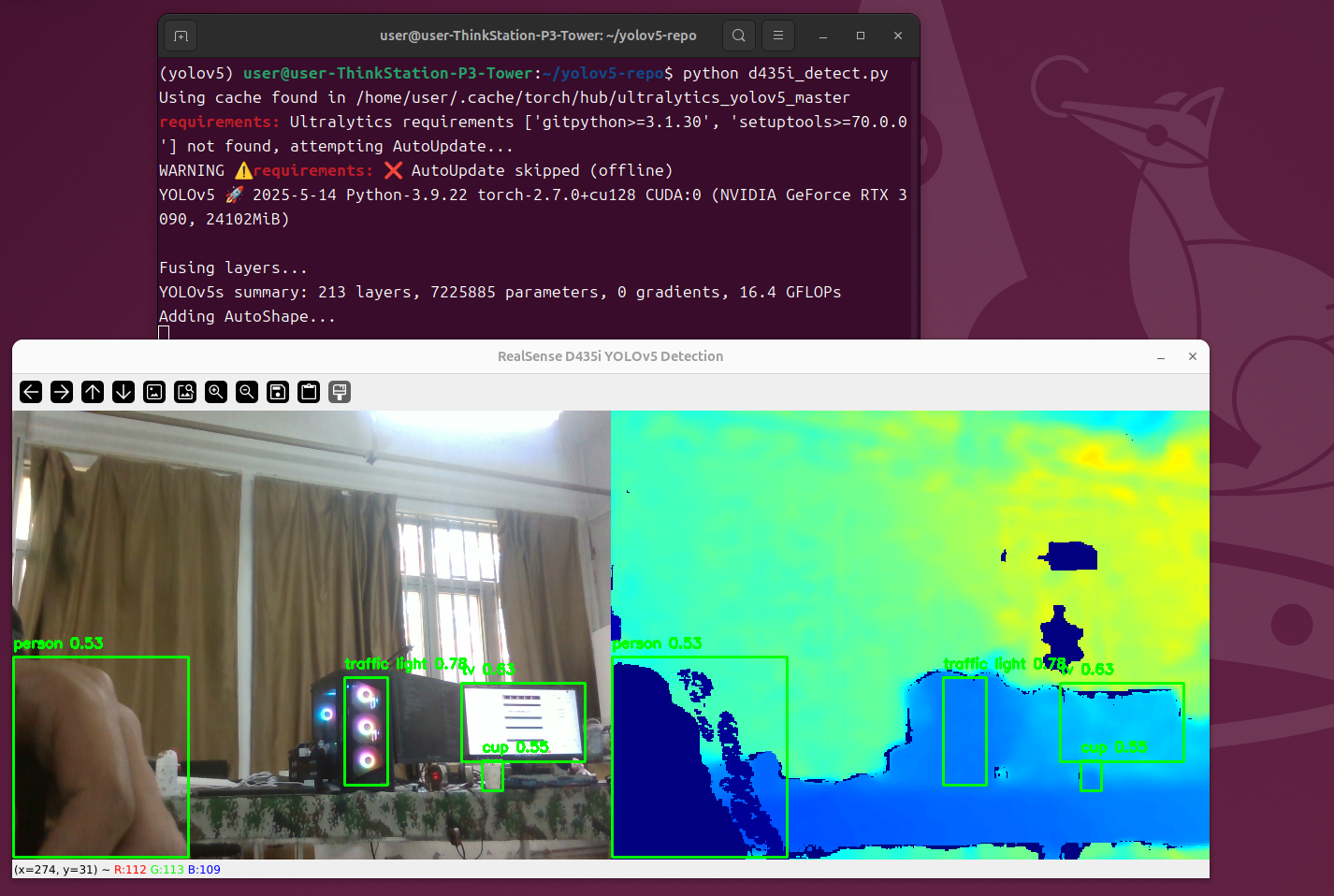
4.Ubantu使用D435i显示被检测物体三位坐标
在yolov5-repo文件夹下新建一个d435i_3d.py文件
nano d435i_3d.py
复制以下代码
import cv2import torchimport numpy as npimport pyrealsense2 as rsimport osimport warningswarnings.filterwarnings(\"ignore\", category=FutureWarning)model_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), \'yolov5s.pt\')model = torch.hub.load(\'ultralytics/yolov5\', \'custom\', path=model_path)pipeline = rs.pipeline()config = rs.config()config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)profile = pipeline.start(config)depth_sensor = profile.get_device().first_depth_sensor()depth_scale = depth_sensor.get_depth_scale()color_intrinsics = profile.get_stream(rs.stream.color).as_video_stream_profile().get_intrinsics()model.eval()if torch.cuda.is_available(): model.cuda()align = rs.align(rs.stream.color)try: while True: frames = pipeline.wait_for_frames() aligned_frames = align.process(frames) color_frame = aligned_frames.get_color_frame() depth_frame = aligned_frames.get_depth_frame() if not color_frame or not depth_frame: continue color_image = np.asanyarray(color_frame.get_data()) depth_image = np.asanyarray(depth_frame.get_data()) depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.03), cv2.COLORMAP_JET) results = model(color_image) detections = results.pandas().xyxy[0].to_dict(\'records\') for detection in detections: xmin, ymin, xmax, ymax = int(detection[\'xmin\']), int(detection[\'ymin\']), int(detection[\'xmax\']), int(detection[\'ymax\']) center_x = (xmin + xmax) // 2 center_y = (ymin + ymax) // 2 depth_value = depth_frame.get_distance(center_x, center_y) point_3d = rs.rs2_deproject_pixel_to_point(color_intrinsics, [center_x, center_y], depth_value) x, y, z = point_3d cv2.rectangle(color_image, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2) label = f\"{detection[\'name\']} {detection[\'confidence\']:.2f}\" cv2.putText(color_image, label, (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2) coord_text = f\"X:{x:.3f} Y:{y:.3f} Z:{z:.3f}\" cv2.putText(color_image, coord_text, (center_x - 70, center_y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2) cv2.rectangle(depth_colormap, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2) cv2.putText(depth_colormap, label, (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2) cv2.putText(depth_colormap, coord_text, (center_x - 70, center_y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2) images = np.hstack((color_image, depth_colormap)) cv2.namedWindow(\'RealSense D435i YOLOv5 Detection\', cv2.WINDOW_AUTOSIZE) cv2.imshow(\'RealSense D435i YOLOv5 Detection\', images) key = cv2.waitKey(1) if key == 27: break finally: pipeline.stop() cv2.destroyAllWindows()Ctrl+O写入,Ctrl+X离开
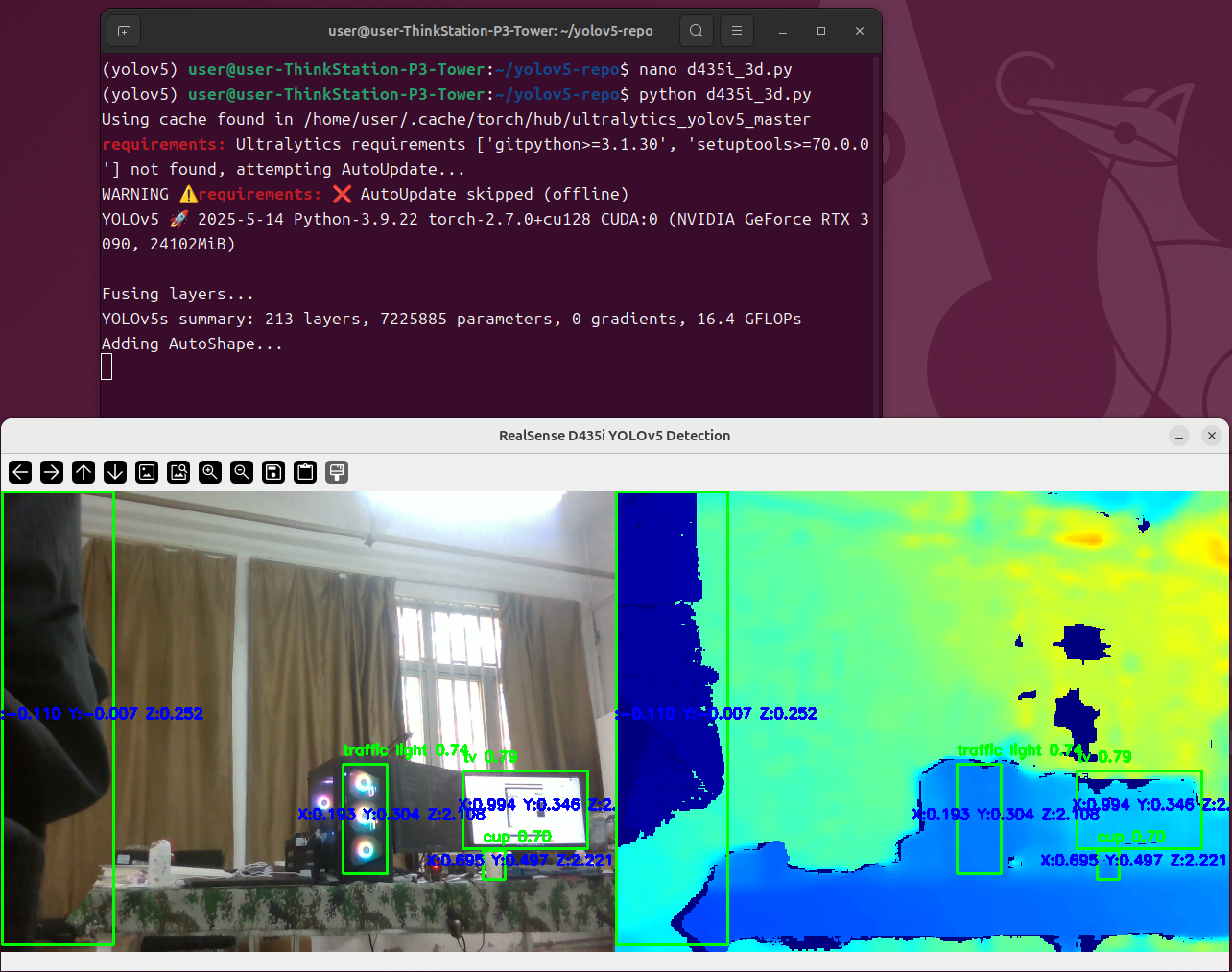
运行代码
python d435i_3d.py