计算机视觉---YOLOv8_yolo v8
一、YOLOv8 核心架构与技术特点
YOLOv8 是 Ultralytics 于 2023 年推出的新一代目标检测框架,继承了 YOLO 系列「快速、高效」的传统,同时在精度、速度、扩展性上实现突破。
1. 模型架构革新
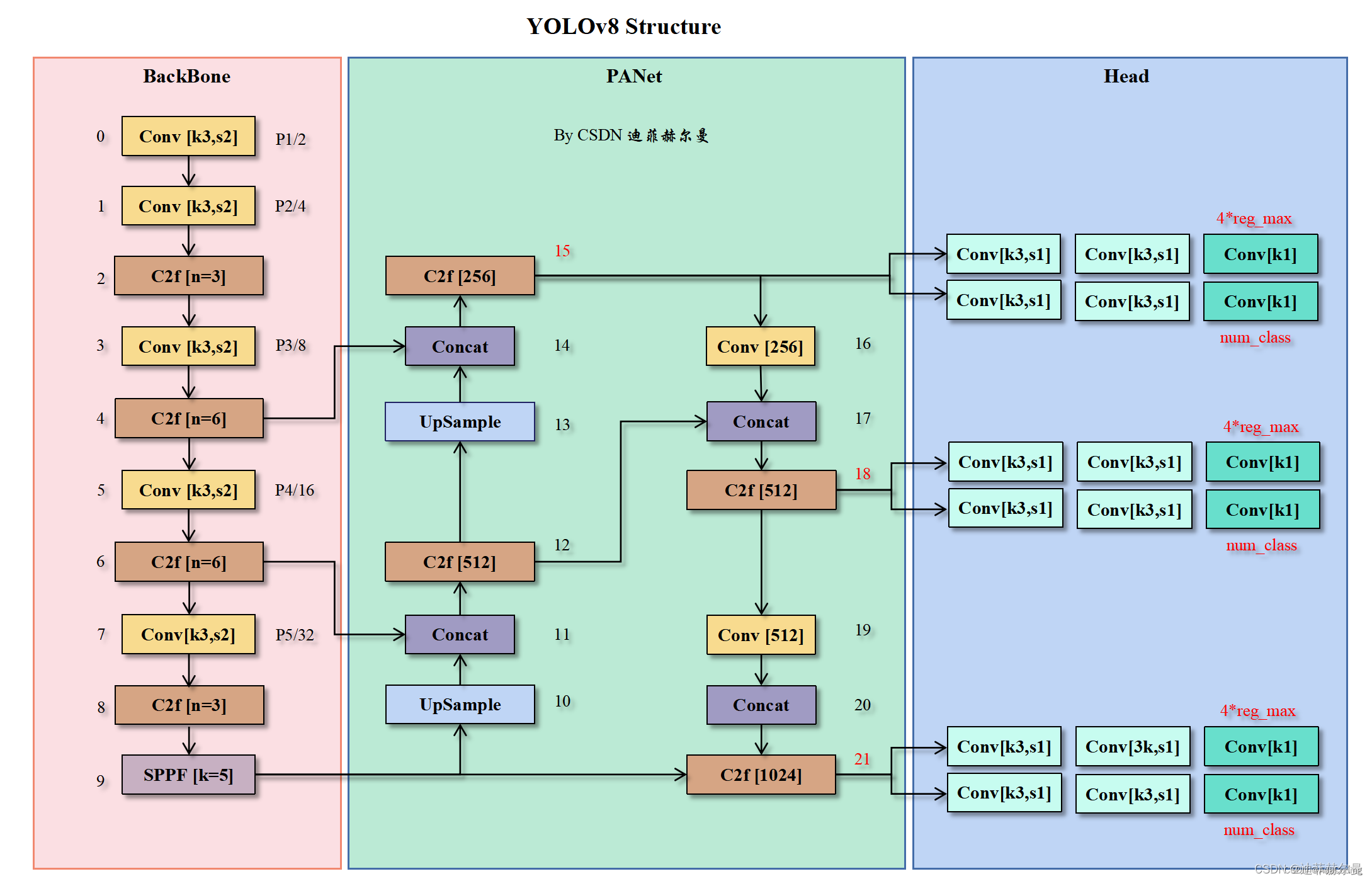
YOLOv8 采用 全卷积架构,取消了 YOLOv5 的锚点机制(Anchor-Free),转向基于关键点的检测方式,大幅简化训练流程。整体结构分为四部分:
- Backbone(骨干网络)
- 基于 CSPDarknet 改进,引入 C2f 模块(Cross Stage Partial Fusion),替代 YOLOv5 的 C3 模块。C2f 通过减少跨阶段连接的通道数,降低计算量的同时保持特征融合效率,轻量化效果显著。
CF2模块讲解请参阅这篇优秀博客
-
采用 动态深度与宽度缩放,支持 N/S/M/L/X 五种尺度模型,适配不同硬件需求(如移动端到 GPU 端)。
-
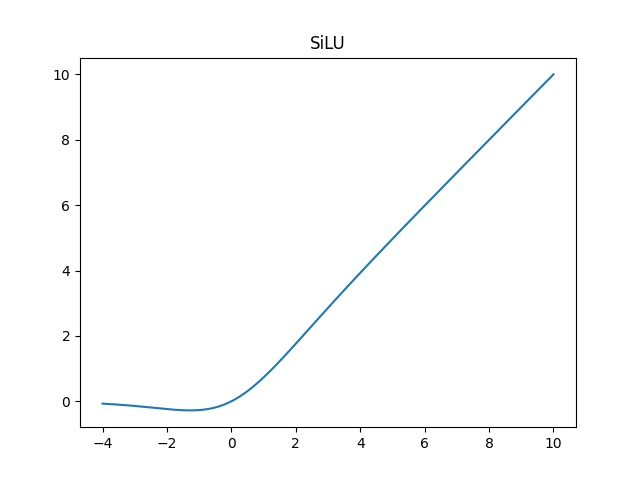
激活函数从 LeakyReLU 改为 SiLU(Swish),提升非线性表达能力,尤其在深层网络中效果更优。
-
Neck(特征融合颈部)
- 升级为 PAFPN(Path Aggregation Feature Pyramid Network),相比 YOLOv5 的 FPN,增加了自底向上的路径聚合结构,强化不同层级特征的交互,提升小目标检测性能。
- 特征图输出尺寸为输入的 1/8、1/16、1/32,保留多尺度检测能力。
-
Head(检测头)
- 采用 Anchor-Free 机制,每个位置直接预测 4 个坐标偏移量(xywh)、类别概率和 置信度,无需预设锚点,减少超参数调优成本。
- 检测头为 解耦头(Decoupled Head),将分类和回归分支分离,提升训练稳定性,避免任务冲突。
- 支持 多任务输出:通过切换 Head,可扩展至实例分割(Segmentation)和姿态估计(Pose Estimation),共享骨干网络,实现端到端多任务学习。
-
损失函数
- 回归损失采用 CIoU Loss(Complete IoU Loss),同时优化边界框的位置、尺度和旋转一致性,收敛速度更快。
- 分类损失使用 BCEWithLogitsLoss(二元交叉熵),配合焦点损失(Focal Loss)缓解正负样本不均衡问题。
2. 训练策略优化
-
数据增强
- 继承 YOLOv5 的 Mosaic、MixUp 增强,新增 Copy-Paste(将目标从一张图复制到另一张图)和 RandomAffine(随机仿射变换),提升数据多样性。
- 采用 自动锚点生成(但因 Anchor-Free 机制,实际仅用于辅助初始化)。
-
优化器与学习率策略
- 默认使用 SGD 优化器,搭配 余弦退火学习率衰减(Cosine Annealing),相比 YOLOv5 的线性衰减,能更充分探索参数空间,避免过早收敛。
- 引入 **EMA(指数移动平均)**更新模型参数,提升训练稳定性,尤其在后期收敛阶段效果显著。
-
标签分配策略
- 采用 Task-Aligned Assigner(任务对齐分配器),根据预测框与真实框的 IoU 和分类置信度动态分配正负样本,使训练更聚焦高质量候选框。
3. 推理与部署改进
-
后处理优化
- 弃用传统 NMS(非极大值抑制),改用 Soft-NMS 或 DIoU-NMS,通过惩罚重叠框的置信度而非直接删除,减少漏检问题,尤其在密集目标场景中表现更佳。
- 支持 自适应推理尺寸,可通过参数动态调整输入分辨率,平衡速度与精度。
-
多平台部署支持
- 原生支持导出为 ONNX、TensorRT、OpenVINO、CoreML 等格式,适配 CPU、GPU、边缘设备(如 NVIDIA Jetson、树莓派)和移动端(iOS/Android)。
- 集成 DeepSORT 等跟踪算法,支持实时目标跟踪(需额外配置)。
4. 多任务扩展能力
-
实例分割(YOLOv8-Seg)
- 在检测头基础上增加 掩码分支,输出每个目标的二进制掩码,采用 YOLACT++ 类似的掩码生成机制,支持实时分割(如 30 FPS 在 COCO 数据集)。
-
姿态估计(YOLOv8-Pose)
- 通过关键点检测头预测人体关节点坐标,结合轻量级姿态解码算法,可同时输出目标框与 17 个人体关键点,适用于动作识别等场景。
二、YOLOv8 与先前版本对比(重点 vs. YOLOv5)
三、YOLOv8 性能表现(COCO 2017 数据集)
注:YOLOv8 的 FPS 基于 640x640 输入尺寸,使用 TensorRT FP16 加速,相比 YOLOv5 同尺度模型,速度提升约 10-30%,AP 提升 1-3%。
四、YOLOv8 的应用场景与局限
- 优势场景:实时目标检测(如安防、自动驾驶)、多任务视觉系统(检测+分割+姿态估计)、边缘设备部署(轻量化模型)。
- 局限性:对极度复杂背景或非常规目标的泛化能力仍弱于 Transformer 类模型(如 DETR);多任务模式下显存占用较高,需高端 GPU 支持。
五、总结:YOLOv8 的技术突破
YOLOv8 通过 Anchor-Free 架构、PAFPN 特征融合、多任务统一框架和 部署优化,实现了 YOLO 系列从「快速检测」到「全能视觉工具」的跨越。相比前代,其核心提升在于:
- 效率优先:轻量化设计与硬件优化使其在移动端和边缘端更具竞争力;
- 全能扩展:一套模型支持多任务,降低开发门槛;
- 工业级部署:原生支持多种推理引擎,适配生产环境需求。
对于开发者而言,YOLOv8 是平衡科研创新与工程落地的优选方案,尤其适合需要快速迭代的视觉应用场景。
如何使用YOLOv8,请参阅这篇优秀博客YOLOv8调参超详细教程
你内在的某种力量,比任何障碍都更强大。 —克里斯蒂安·达·拉森

