Python实战——用 Web Unlocker 构建企业级电商竞品监控系统的终极手册
Python实战——用 Web Unlocker 构建企业级电商竞品监控系统的终极手册
-
-
- 导言:你与顶尖操盘手之间,只差一个自动化情报系统的距离
- 第一部分:地基与武器——为什么必须是 Web Unlocker?
- 第二部分:终极实操项目——从零构建一个多商品监控应用
- 第三部分:自动化部署——让你的机器人7x24小时为你工作
- 结论:你已掌握开启数据之门的钥匙
- 🔥 最终行动号召:立即将蓝图变为现实!🔥
-
导言:你与顶尖操盘手之间,只差一个自动化情报系统的距离
想象两个场景:
场景A (也许是你现在的日常):
早上9点,你打开电脑,收藏夹里有20个竞争对手的商品链接。你一个个点开,眯着眼在页面上寻找价格和库存信息,然后手动复制粘贴到你的Excel表格里。突然,你发现一个主要对手昨晚降价了15%,而你已经错过了8个小时的黄金应对时间。下午,老板问你最近市场有什么动态,你只能拿出那份滞后且不完整的Excel表。
场景B (你读完本文后可以实现的未来):
早上9点,你打开电脑。一个程序已经在你睡觉时自动运行了100多次,它检查了所有竞品的价格和库存。你打开一个自动生成的log.txt文件,上面清晰地记录着:“[03:15:32] 商品B08P2H5LW7 价格从 $199.99 变更为 $169.99”。同时,一个data.csv文件里,已经整齐地躺着所有竞品最新的、带有时间戳的数据。你从容地根据精准情报,调整今天的运营策略。
从场景A到场景B的跨越,就是本文将带你完成的旅程。我们将使用的核心武器,是 Bright Data Web Unlocker——它不是一个简单的工具,而是赋予你获取数据“超能力”的钥匙。忘掉那些让你浅尝辄止的短文吧,准备好,我们的深度实战,现在开始。

第一部分:地基与武器——为什么必须是 Web Unlocker?
在动手之前,我们必须理解我们的武器和战场。
1.1 战场的残酷真相:网站的“铜墙铁壁”
为什么你不能简单地用一个程序直接访问电商网站?因为它们筑起了坚固的防线:
- IP 识别与封锁: 来自同一个IP的频繁访问,会被立刻识别为机器人并拉黑。
- CAPTCHA (验证码): “我不是机器人”的勾选框、图片点选,是程序的噩梦。
- 浏览器指纹: 网站会检测你的浏览器、操作系统、分辨率、字体等上百个参数,形成独一无二的“指纹”。普通程序没有指纹,一秒识破。
- 动态加载: 你看到的价格,很多是页面打开后通过JavaScript动态加载的,直接访问HTML源码根本不存在。
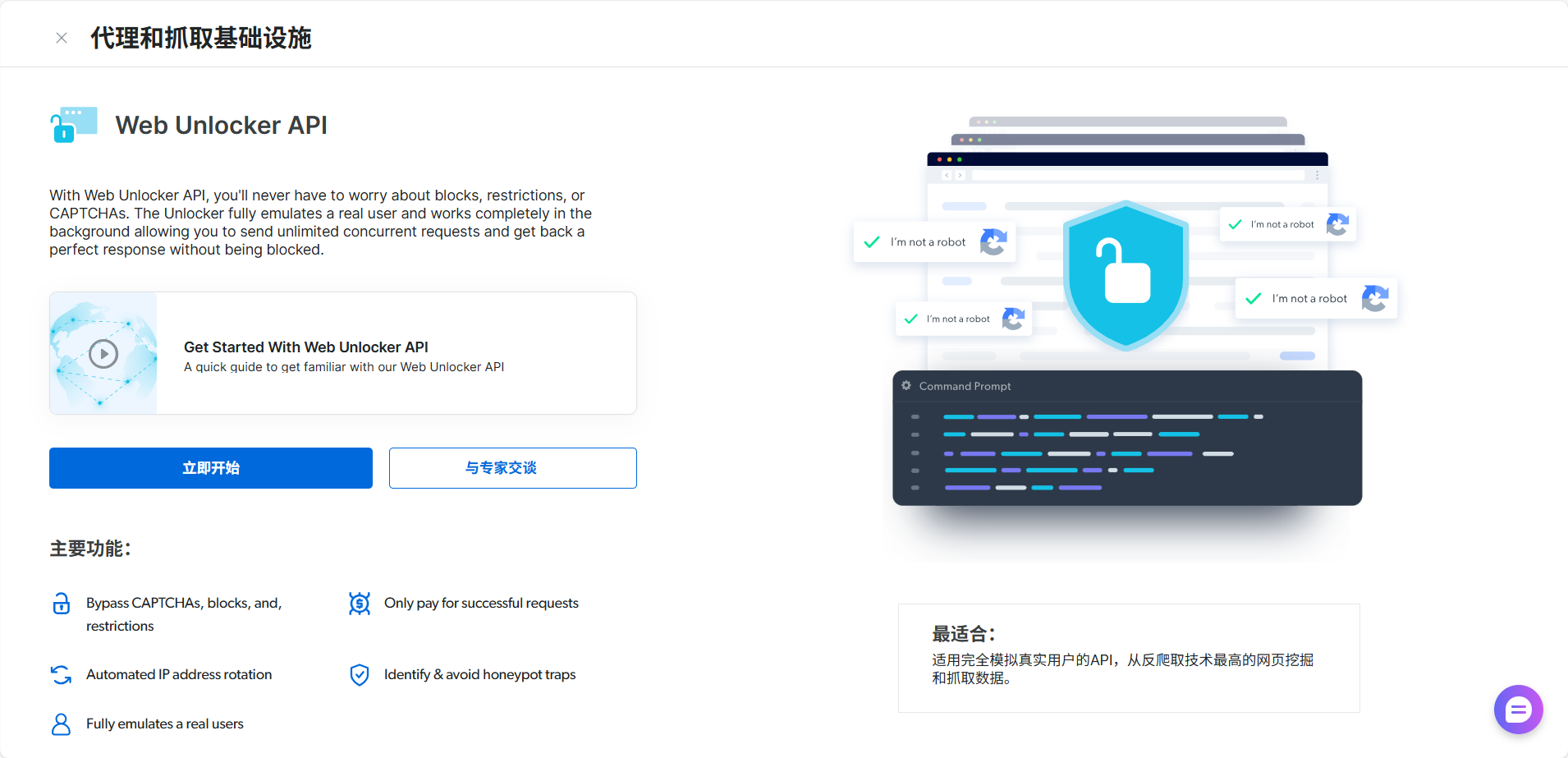
1.2 Web Unlocker:你的“特种部队”
Web Unlocker 就是为了摧毁上述所有防线而生的。你可以把它想象成一支精英特种部队:
- 它拥有庞大的住宅IP库(千军万马),让你的每一次请求都像一个来自不同家庭的真实用户。
- 它能自动处理和破解验证码(拆弹专家)。
- 它能模拟生成完美的浏览器指份(伪装大师)。
- 它能完整渲染JavaScript,确保你拿到的是最终显示给用户的完整页面(全景侦察兵)。
最关键的是: 它将这一切复杂的对抗过程完全封装。你只需要把你的请求“委托”给它,它就能保证你的请求畅通无阻地到达目标服务器,并带回干净的、完整的HTML页面。它负责“破门”,你负责“取宝”。 这种模式赋予了我们接下来所有实操的绝对控制力和灵活性。
第二部分:终极实操项目——从零构建一个多商品监控应用
这是本文的核心,我们将一步步构建一个真实、可用的Python应用。
项目目标:
创建一个Python程序,该程序能够:
- 读取一个包含多个商品URL的列表。
- 使用 Web Unlocker 逐一抓取这些页面的价格和库存。
- 将抓取到的最新数据,以追加模式写入一个CSV文件,并附上时间戳。
- 如果发现价格或库存发生变化,将变更信息记录到一个独立的日志文件中。
2.1 环境搭建:磨刀不误砍柴工
1. 安装 Python:
如果你的电脑还没有Python,请访问 python.org 下载并安装最新版本(请确保在安装时勾选 “Add Python to PATH”)。
2. 安装代码编辑器 (推荐):
推荐使用免费且强大的 Visual Studio Code (https://code.visualstudio.com/)。
3. 安装必要的 Python 库:
打开你的命令行工具(Windows用户是CMD或PowerShell,Mac用户是Terminal),输入以下命令并回车:
pip install requests beautifulsoup4requests: 用于发送HTTP网络请求的王者库。beautifulsoup4: 用于解析HTML页面、提取数据的瑞士军刀。
4. 配置你的 Web Unlocker:
这一步至关重要
-
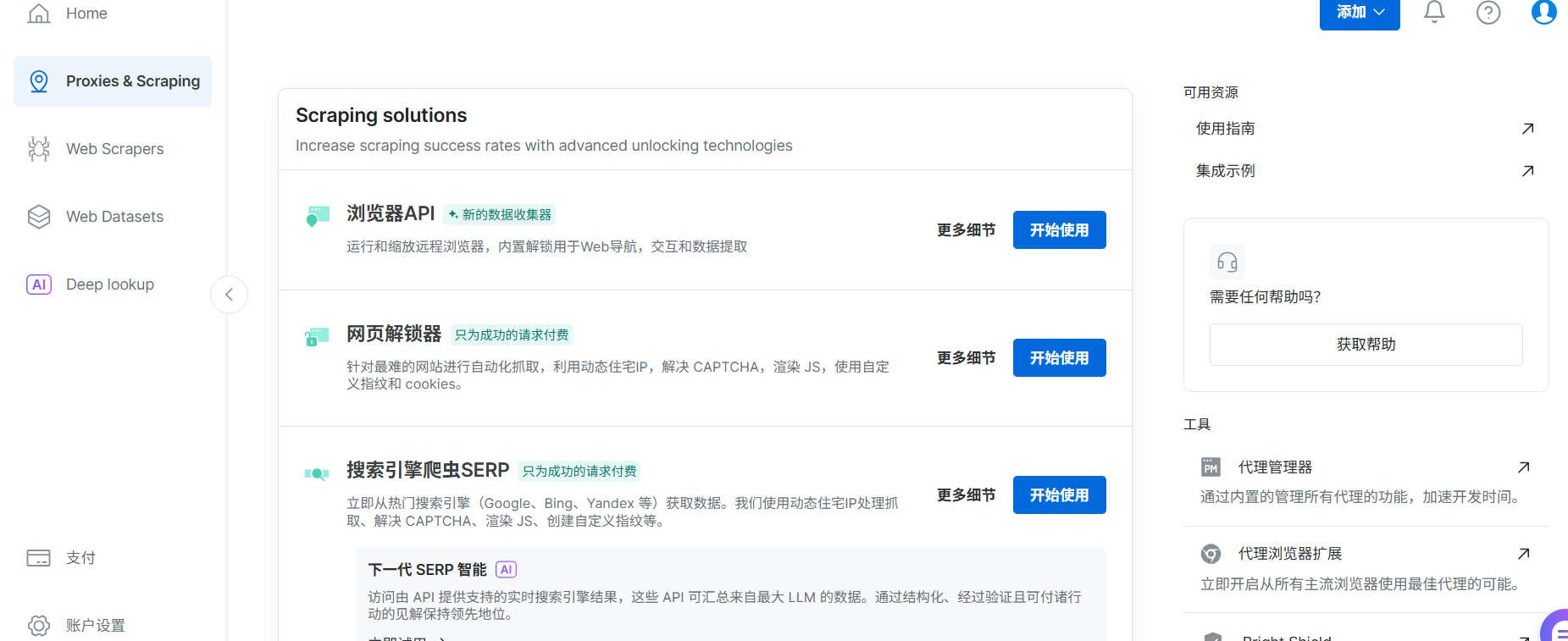
登录 Bright Data,进入“代理和抓取基础架构”。
*
-
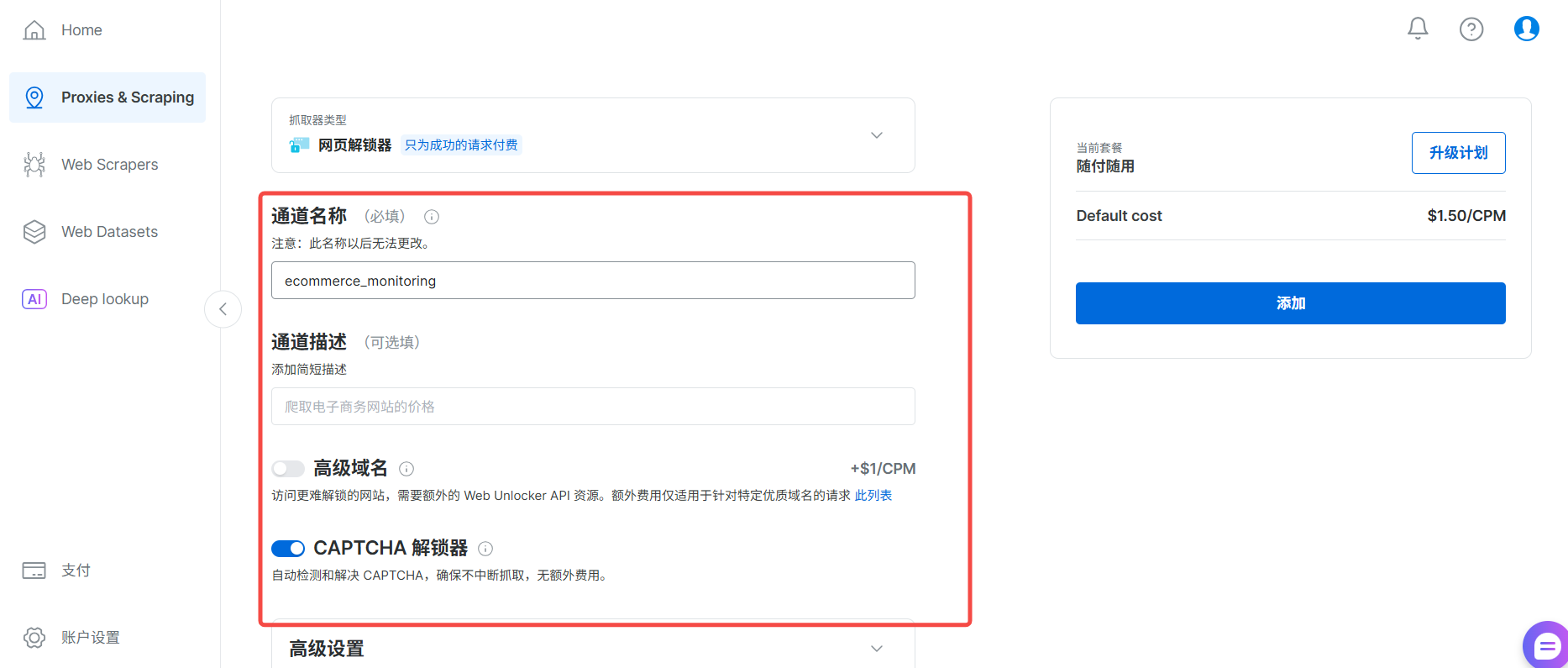
创建一个网页解锁器 类型的 Zone,命名为
ecommerce_monitoring。
-
进入该 Zone 的“访问参数”,找到并复制好你的主机、端口、用户名、密码(API令牌)。
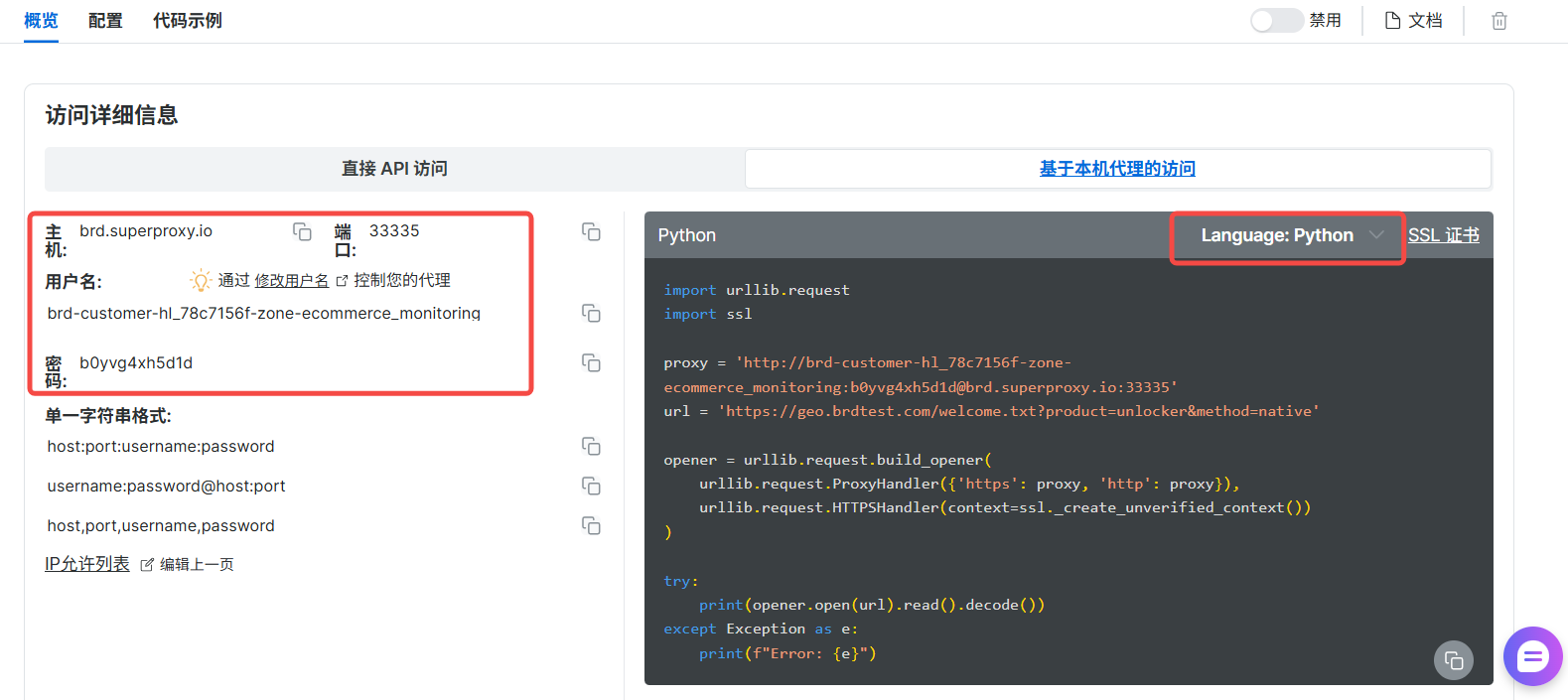
-
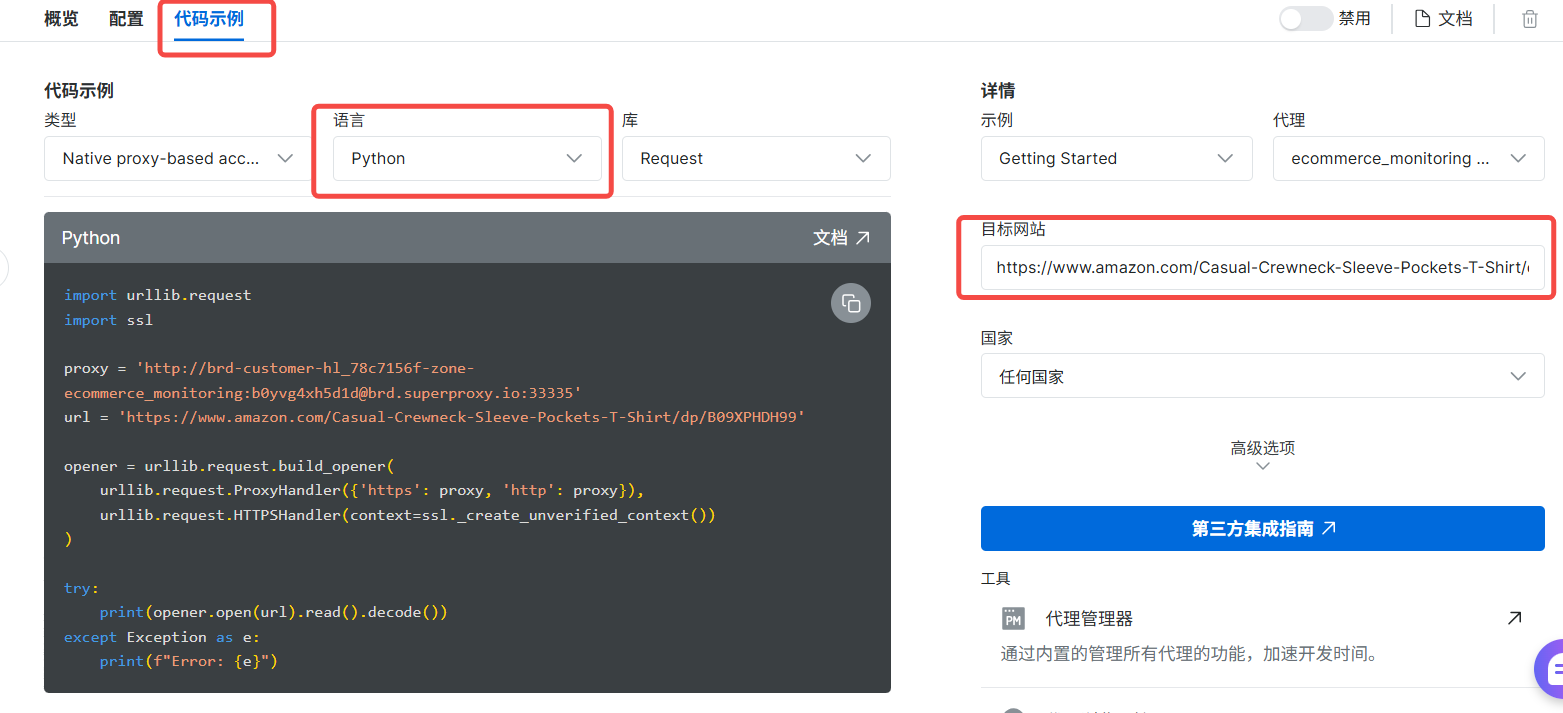
我们还可以让他给出代码示例,我们选取python代码,例如如下图:
2.2 编码实战:逐行构建你的监控机器人
我们不直接扔给你最终代码,而是带你一步步构建它,理解每一部分的作用。
第一步:创建项目结构
在你的电脑上创建一个文件夹,例如 MyMonitor。在其中创建以下文件:
monitor.py: 我们的主程序代码。urls.txt: 用于存放我们要监控的商品链接。data.csv: (程序首次运行后会自动创建)用于存储数据。change_log.txt: (程序首次运行后会自动创建)用于记录变更。
在 urls.txt 文件中,每行放入一个你想监控的商品链接,例如:
https://www.amazon.com/Casual-Crewneck-Sleeve-Pockets-T-Shirt/dp/B09XPHDH99
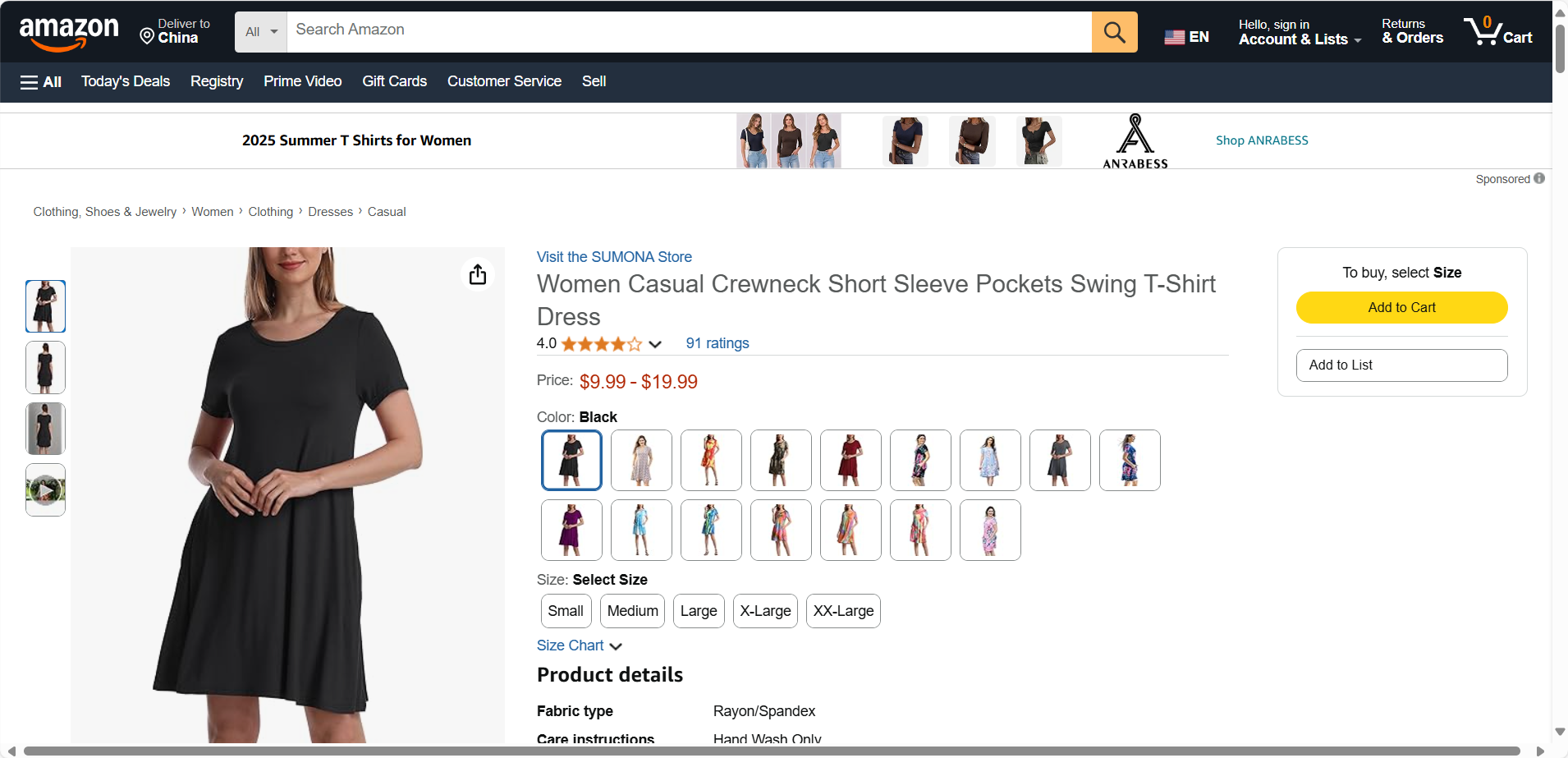
第二步:编写 monitor.py
现在,打开 monitor.py,我们将分块添加并解释代码。
Block 1: 导入模块与配置
# -----------------------------------------------------------------------------# Block 1: 导入模块与全局配置# -----------------------------------------------------------------------------import requestsfrom bs4 import BeautifulSoupimport csvimport osfrom datetime import datetimeimport logging# --- 在此处填入您的 Bright Data Web Unlocker 凭证 ---PROXY_HOST = \'brd.superproxy.io\'PROXY_PORT = 22225PROXY_USER = \'brd-customer-ACCOUNT_ID-zone-ecommerce_monitoring\' # 替换为您的用户名PROXY_PASS = \'YOUR_API_TOKEN\' # 替换为您的API令牌# --- 文件路径配置 ---URL_FILE = \'urls.txt\'DATA_CSV_FILE = \'data.csv\'LOG_FILE = \'change_log.txt\'# --- 构建代理字典 ---proxies = { \'http\': f\'http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}\', \'https\': f\'http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}\'}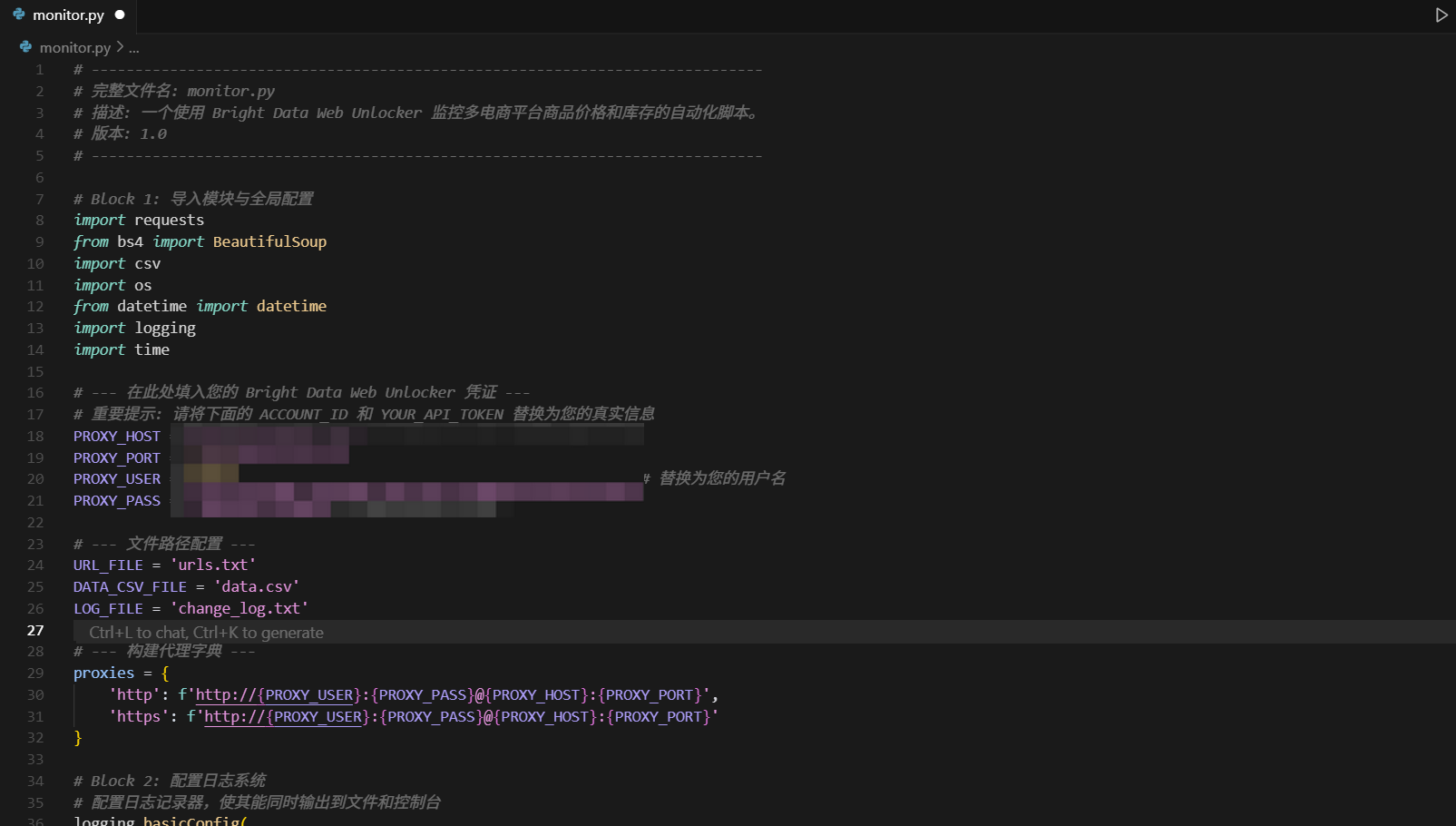
解析: 我们导入了所有需要的库,并集中配置了所有常量,如凭证和文件名。这是一种良好的编程习惯。
Block 2: 日志记录器配置
# -----------------------------------------------------------------------------# Block 2: 配置日志系统# -----------------------------------------------------------------------------logging.basicConfig( level=logging.INFO, format=\'%(asctime)s - %(levelname)s - %(message)s\', handlers=[ logging.FileHandler(LOG_FILE), # 输出到文件 logging.StreamHandler() # 同时输出到控制台 ])解析: 我们配置了一个强大的日志系统。它会将信息同时打印在屏幕上和change_log.txt文件中,方便我们随时查看发生了什么。
Block 3: 核心抓取与解析函数
# -----------------------------------------------------------------------------# Block 3: 核心抓取与解析函数# -----------------------------------------------------------------------------def scrape_product_data(url): \"\"\" 接收一个URL,使用Web Unlocker抓取页面,并解析出价格和库存。 返回一个包含价格和库存的字典。 \"\"\" try: response = requests.get(url, proxies=proxies, verify=False, timeout=45) response.raise_for_status() # 如果请求失败 (非200状态码), 则抛出异常 soup = BeautifulSoup(response.text, \'html.parser\') price = \"N/A\" stock = \"N/A\" # --- 解析逻辑:这是最需要根据不同网站定制的部分 --- if \'amazon.com\' in url: price_whole = soup.select_one(\'#corePrice_feature_div .a-price-whole\') price_fraction = soup.select_one(\'#corePrice_feature_div .a-price-fraction\') if price_whole and price_fraction: price = f\"{price_whole.get_text(strip=True)}{price_fraction.get_text(strip=True)}\" stock_element = soup.select_one(\'#availability span\') if stock_element: stock = stock_element.get_text(strip=True) elif \'walmart.com\' in url: price_element = soup.select_one(\'span[itemprop=\"price\"]\') if price_element: price = price_element.get_text(strip=True) # Walmart的库存通常显示为 \"Add to cart\" 按钮 stock_element = soup.select_one(\'button[data-testid=\"add-to-cart-section-button\"]\') if stock_element: stock = \"In Stock\" else: stock = \"Out of Stock\" # ... 您可以根据需要添加更多电商平台的解析逻辑 (elif \'ebay.com\' in url: ...) return {\'price\': price, \'stock\': stock} except requests.exceptions.RequestException as e: logging.error(f\"抓取失败 (网络问题): {url} - {e}\") return None except Exception as e: logging.error(f\"抓取失败 (解析或其他问题): {url} - {e}\") return None解析: 这是我们应用的大脑。它接收一个URL,通过Web Unlocker发送请求,然后使用BeautifulSoup解析数据。最关键的是,我们通过if \'amazon.com\' in url:这样的逻辑,为不同的电商平台编写了不同的解析规则(CSS选择器)。 这展示了Web Unlocker配合自定义代码的强大灵活性。完善的try...except确保了即使某个链接抓取失败,整个程序也不会崩溃。
Block 4: 数据存储与变更检测
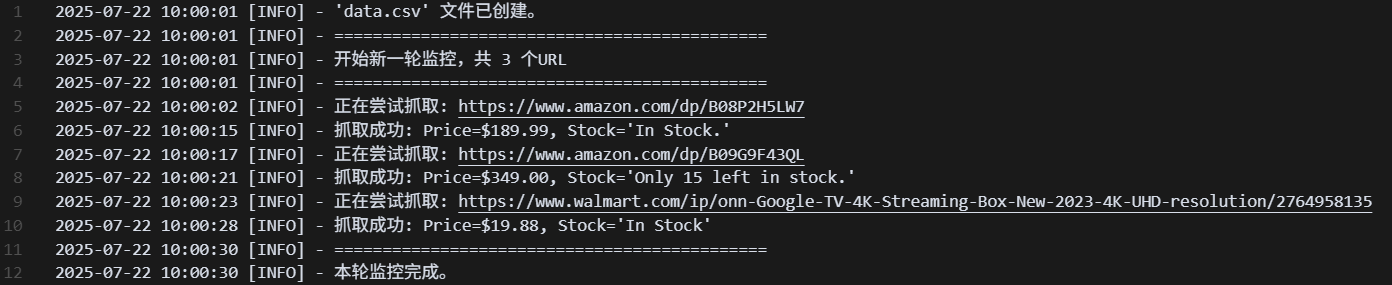
# -----------------------------------------------------------------------------# Block 4: CSV操作与变更检测# -----------------------------------------------------------------------------def get_last_entry(url): \"\"\"获取CSV文件中某个URL的最新一条记录\"\"\" last_entry = {} if not os.path.exists(DATA_CSV_FILE): return last_entry with open(DATA_CSV_FILE, \'r\', encoding=\'utf-8\') as f: reader = csv.DictReader(f) for row in reader: if row[\'url\'] == url: last_entry = row # 持续更新,循环结束后即为最后一条 return last_entrydef main(): \"\"\"主执行函数\"\"\" # 检查CSV文件是否存在,如果不存在则创建并写入表头 if not os.path.exists(DATA_CSV_FILE): with open(DATA_CSV_FILE, \'w\', newline=\'\', encoding=\'utf-8\') as f: writer = csv.writer(f) writer.writerow([\'timestamp\', \'url\', \'price\', \'stock\']) # 读取要监控的URL列表 with open(URL_FILE, \'r\') as f: urls_to_monitor = [line.strip() for line in f if line.strip()] logging.info(f\"开始监控 {len(urls_to_monitor)} 个URL...\") for url in urls_to_monitor: print(f\"\\n--- 正在处理: {url} ---\") current_data = scrape_product_data(url) if current_data: # 获取该URL的上一次记录 last_data = get_last_entry(url) # 写入当前数据到CSV with open(DATA_CSV_FILE, \'a\', newline=\'\', encoding=\'utf-8\') as f: writer = csv.writer(f) timestamp = datetime.now().strftime(\'%Y-%m-%d %H:%M:%S\') writer.writerow([timestamp, url, current_data[\'price\'], current_data[\'stock\']]) print(f\"数据已保存: Price={current_data[\'price\']}, Stock=\'{current_data[\'stock\']}\'\") # --- 变更检测逻辑 --- if last_data: # 确保有历史记录可对比 if last_data.get(\'price\') != current_data[\'price\']: logging.warning(f\"价格变更! URL: {url} | 旧价格: {last_data.get(\'price\')} -> 新价格: {current_data[\'price\']}\") if last_data.get(\'stock\') != current_data[\'stock\']: logging.warning(f\"库存变更! URL: {url} | 旧库存: \'{last_data.get(\'stock\')}\' -> 新库存: \'{current_data[\'stock\']}\'\") logging.info(\"所有URL监控完成。\")if __name__ == \"__main__\": main()解析:
get_last_entry函数负责从我们的data.csv中读出某个URL的最后一次记录,用于后续对比。main函数是程序的入口。它首先确保CSV文件和表头存在。然后,它循环遍历urls.txt中的每一个链接。- 对于每个链接,它调用
scrape_product_data获取当前数据。 - 获取数据后,它立即将带有时间戳的新数据追加到CSV文件中。
- 最精彩的部分来了:它调用
get_last_entry获取历史数据,然后对比当前数据和历史数据的价格与库存。如果发现不一致,就使用logging.warning记录一条黄色的、醒目的警告信息到日志文件和控制台。 if __name__ == \"__main__\":是Python的标准写法,确保main()函数只在直接运行此脚本时执行。

第三部分:自动化部署——让你的机器人7x24小时为你工作
现在你有了一个可以运行的脚本,但总不能每次都手动去点。我们需要让它自动运行。
方案一:Windows 任务计划程序 (Task Scheduler)
- 在Windows搜索框输入“任务计划程序”并打开。
- 在右侧“操作”栏中点击“创建基本任务”。
- 名称: 填入“电商竞品监控”。
- 触发器: 选择“每天”或更频繁的“每小时”(在高级设置里可以设置每10分钟)。
- 操作: 选择“启动程序”。
- 程序或脚本: 点击“浏览”,找到你的
python.exe程序。它通常在C:\\Users\\你的用户名\\AppData\\Local\\Programs\\Python\\PythonXX\\python.exe。 - 添加参数 (可选): 填入你的脚本的完整路径,例如
D:\\MyMonitor\\monitor.py。 - 起始于 (可选): 填入你的脚本所在的文件夹路径,例如
D:\\MyMonitor。这很重要,可以确保程序能找到urls.txt等相对路径的文件。 - 完成创建。
方案二:macOS / Linux 的 Cron Job
- 打开终端。
- 输入
crontab -e来编辑你的定时任务列表。 - 在文件的最后添加一行,格式如下:
*/15 * * * * /usr/bin/python3 /path/to/your/MyMonitor/monitor.py >> /path/to/your/MyMonitor/cron_output.log 2>&1解释:
*/15 * * * *: 代表每15分钟执行一次。/usr/bin/python3: 你的Python解释器的绝对路径(可以通过which python3命令找到)。/path/to/your/MyMonitor/monitor.py: 你的脚本的绝对路径。>> ... 2>&1: 这会将所有输出(包括错误)都追加到cron_output.log文件中,便于排查问题。
结论:你已掌握开启数据之门的钥匙
恭喜你!如果你能完整地跟随本手册走到这里,你已经不再是一个被动的信息接收者。你已经亲手构建了一个企业级的、可扩展的、自动化的商业情报系统。
- 你掌握了使用 Web Unlocker 绕过反爬虫屏障的核心技术。
- 你学会了用 Python 和 BeautifulSoup 对任何网站进行精准的数据提取。
- 你构建了一个能持久化存储数据 (CSV) 并能智能检测变更 (Log) 的实用应用。
- 你了解了如何通过系统工具实现7x24小时自动化,将自己从重复劳动中解放出来。
我们已经能够明白网页解锁器,它能够将复杂的网站爬取为简单的html,我们只需要专注于网页爬取就可以了
现在,理论学习已经结束,是时候让代码为你创造真正的价值了。
🔥 最终行动号召:立即将蓝图变为现实!🔥
纸上得来终觉浅,绝知此事要躬行。你已经拥有了这份最详尽的作战蓝图,现在,你需要的是开启这一切的钥匙。
➡️ 点击此处,立即注册并试用 Bright Data Web Unlocker,获取免费的抓取额度!
用我们提供的代码,和你申请到的免费额度,去运行你的第一个监控任务。当你看到data.csv和change_log.txt中出现第一条由你亲手缔造的数据时,你会明白,一个全新的、由数据驱动的世界,正在向你敞开大门。