计算机面试——八股篇_计算机面试八股
文章目录
-
- 段页式存储
- 三次握手为什么是三次
- 进程通信,有哪几种,优势劣势
- 协程是什么
- InnoDB和MyISAM
- Innodb锁机制+MVCC
- MySQL
- 覆盖索引
- 当前读和快照读
- MySQL性能优化
- 事务
- 哈希冲突及解决方案
- 有环链表的环入口
- OSI七层模型
- 网络路由交换协议【路由协议】
- TCP和UDP的区别
- UDP如何实现可靠传输
- cookie和session
- fork()
- GET POST
- 从用户在浏览器输入域名,到浏览器显示出页面,这中间发生了什么
- 堆栈的作用,以及存放的数据
- TLS 四次握手
- ASCII和unicode的区别
- 死锁的条件、解决方法
- 什么是虚拟内存、共享内存、物理内存
- 子网掩码的作用和用法
- C++内存如何分布、堆和栈的区别
- IP头以及头的各部分含义
- 常见的内存泄漏原因及解决方法
- 常见的DNS域名劫持方式及解决方法
- Linux C/C++ 中锁的使用总结
- 线程同步机制
- 断点续传原理
- IP切片及重组
- 操作系统微内核宏内核
- 浅拷贝、深拷贝、移动构造函数
- 【C++】宏(#define)和内联函数(inline)的理解以及区别
- 程序编译的四个过程
- TCP三次握手
- 乐观锁与悲观锁
- HTTPS 加密机制
段页式存储
引入原因:
分页和分段管理方式各有其优缺点,分页系统能有效提高内存的利用率,而分段则能更好地满足用户的需要,因此可以将两者结合成一种新的存储管理方式系统称为“段页式系统”。
基本原理
结合分段和分贝思想,先将用户程序分成若干段并分别赋予段名,再将这些段分为若干页
地址结构:由段号、段内页号和页内地址三项共同构成地址

https://blog.csdn.net/u011387521/article/details/105475172
三次握手为什么是三次
TCP是不区分客户端和服务端,连接的建立是双向的过程。所以客户端要给服务器通讯的话两次握手是必须的。
- 第一次握手客户端发个连接请求给服务端,服务端收到后知道自己可以跟客户端连接了,
- 但是此时客户端不知道啊,所以必须的执行第二次握手,反馈下信息给客户端。
- 第一次握手请求连接如果因为网络导致延迟,直到连接释放后信息才到达服务端,那此时服务端也会给客户端进行第二次握手回复,关键是客户端已经不要这个连接了,此时服务端会一直在等待接收客户端信息,造成资源浪费。
- 如果用了三次握手则客户端会发送 RST 报文告知服务端请终止本次旧连接。
进程通信,有哪几种,优势劣势
-
共享内存
两个进程共用一个内存,互斥访问
-
管道
-
半双工通信,某一时间段只能实现单向的传输。如果要实现双向同时通信,需要设置两个管道
-
各进程要互斥的访问管道
-
管道写满时,写进程的write()会被阻塞,管道读完变空时,读进程的read()会被阻塞
-
没写满不允许读,没读空不允许写
-
数据一旦被读出就会被丢弃,意味着读进程最多只有一个
-
-
消息传递
- 消息队列,是消息的链接表,存放在内核中
- 消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级。
- 消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除。
- 消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取。
协程是什么
进程是什么呢?
直白地讲,进程就是应用程序的启动实例。比如我们运行一个游戏,打开一个软件,就是开启了一个进程。
进程拥有代码和打开的文件资源、数据资源、独立的内存空间。
线程又是什么呢?
线程从属于进程,是程序的实际执行者。一个进程至少包含一个主线程,也可以有更多的子线程。
线程拥有自己的栈空间。
对操作系统来说,线程是最小的执行单元,进程是最小的资源管理单元。
协程,英文Coroutines,是一种比线程更加轻量级的存在。 正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
InnoDB和MyISAM
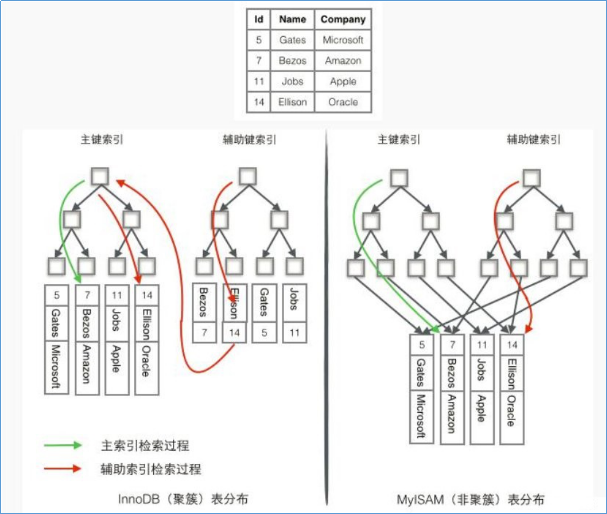
因此,MyISAM的查询性能会比InnoDB强
如果用InnoDB是必须有主键的,主键建议用自增的id而不用uuid,用uuid会使得索引变慢。
InnoDB是聚簇索引(叶子节点存数据),MyISAM是非聚簇索引(叶子节点存指针)
InnoDB 支持事务、行级锁, 而MyISAM都不支持
Innodb锁机制+MVCC
https://blog.csdn.net/weixin_42092787/article/details/108608486
MySQL
索引:
哈希索引:查找快速,不能排序,哈希冲突
B树索引:树低,叶子和非叶子结点都存储值,需要回旋查找
B+树索引:树低,非叶子结点存key,叶子结点存key+value,叶子结点是链表,有序,可以方便找到大于或小于某数的,或者排序。
索引失效
主要分析还是在数据结构B+树
联合查找,like,有可能会失效
最佳左前缀法则
InnoDB MyISAM
事务:InnoDB支持,MyISAM不支持
外键:InnoDB支持,MyISAM不支持
索引:InnoDB聚簇索引,MyISAM非聚簇索引,InnoDB不支持全文索引(可以使用sphinx插件),MyISAM支持全文索引
锁粒度:InnoDB行锁,MyISAM表锁
硬盘存储结构:InnoDB:Frm 表的定义文件;Ibd 数据和索引存储文件,MyISAM frm 表的定义 MYD(MYData)数据文件 MYI(MYIndex)索引文件
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因


澄清一个概念:innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值。
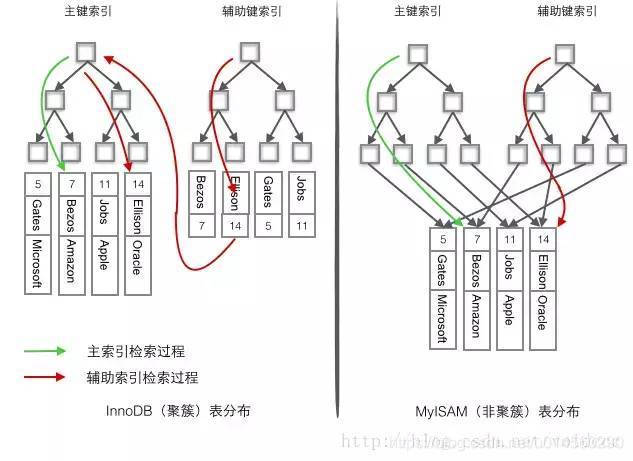
聚簇索引的优势
看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次B+树查找,这不是多此一举吗?聚簇索引的优势在哪?
- 由于行数据和叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问的时候,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
- 辅助索引使用主键作为\"指针\"而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个\"指针\"。也就是说行的位置(实现中通过16K的Page来定位)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
- 聚簇索引适合用在排序的场合,非聚簇索引不适合
- 取出一定范围数据的时候,使用聚簇索引
- 二级索引需要两次索引查找,而不是一次才能取到数据,因为存储引擎第一次需要通过二级索引找到索引的叶子节点,从而找到数据的主键,然后在聚簇索引中用主键再次查找索引,再找到数据
- 可以把相关数据保存在一起。例如实现电子邮箱时,可以根据用户 ID 来聚集数据,这样只需要从磁盘读取少数的数据页就能获取某个用户的全部邮件。如果没有使用聚簇索引,则每封邮件都可能导致一次磁盘 I/O。
聚簇索引的劣势
- 维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(page split)的时候。建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZE TABLE优化表,因为必须被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
- 表因为使用UUId(随机ID)作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面更慢,
覆盖索引
什么是覆盖索引,有下面三种理解:
解释一: 就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫 做覆盖索引。
解释三:是非聚集组合索引的一种形式,它包括在查询里的Select、Join和Where子句用到的所有列(即建立索引的字段正好是覆盖查询语句[select子句]与查询条件[Where子句]中所涉及的字段,也即,索引包含了查询正在查找的所有数据)。
不是所有类型的索引都可以成为覆盖索引。覆盖索引必须要存储索引的列,而哈希索引、空间索引和全文索引等都不存储索引列的值,所以MySQL只能使用B-Tree索引做覆盖索引
当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在EXPLAIN的Extra列可以看到“Using index”的信息

从执行结果上看,这个SQL语句只通过索引,就取到了所需要的数据,这个过程就叫做索引覆盖。
https://www.cnblogs.com/happyflyingpig/p/7662881.html
当前读和快照读
https://www.modb.pro/db/38160
MySQL性能优化
全部用到索引
建立的复合索引包含了几个字段,查询的时候最好能全部用到,而且严格按照索引顺序,这样查询效率是最高的。(最理想情况,具体情况具体分析)

最左前缀法则
如果建立的是复合索引,索引的顺序要按照建立时的顺序,即从左到右,如:a->b->c(和 B+树的数据结构有关)

不要对索引做以下处理
以下用法会导致索引失效
- 计算,如:+、-、*、/、!=、、is null、is not null、or
- 函数,如:sum()、round()等等
- 手动/自动类型转换,如:id = “1”,本来是数字,给写成字符串了

索引不要放在范围查询右边
比如复合索引:a->b->c,当 where a=“” and b>10 and 3=“”,这时候只能用到 a 和 b,c 用不到索引,因为在范围之后索引都失效(和 B+树结构有关)

减少 select * 的使用
select 查询字段和 where 中使用的索引字段一致。

like 模糊搜索
- 失效情况
like “%张三%”
like “%张三” - 解决方案
使用复合索引,即 like 字段是 select 的查询字段,如:select name from table where name like “%张三%”
使用 like “张三%”

order by 优化
当查询语句中使用 order by 进行排序时,如果没有使用索引进行排序,会出现 filesort 文件内排序,这种情况在数据量大或者并发高的时候,会有性能问题,需要优化。
事务
事务(Transaction)是访问和更新数据库的程序执行单元;事务中可能包含一个或多个sql语句,这些语句要么都执行,要么都不执行。
1、原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
2、一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。举例来说,假设用户A和用户B两者的钱加起来一共是1000,那么不管A和B之间如何转账、转几次账,事务结束后两个用户的钱相加起来应该还得是1000,这就是事务的一致性。
3、隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如同时操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。关于事务的隔离性数据库提供了多种隔离级别,稍后会介绍到。
4、持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务已经正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成。否则的话就会造成我们虽然看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。这是不允许的。
事务的并发一致性问题
丢失修改:A修改后B修改,B覆盖了A
读脏数据:A修改后B读,A又回滚(rollback)
不可重复读:B多次读,A在其中修改了
幻影读:A读取某个范围数据,B在这个范围中插入数据
事务的隔离级别:
读未提交:一个事务可以读取另一个未提交事务的数据
读提交:一个事务要等另一个事务提及后才能读取数据
重复读:读数据(事务开始后)不再允许修改数据
序列化:事务串行化顺序执行
具体的实现
有两大类的方案 ,LBCC与MVCC。
Lock Based Concurrency Control(LBCC):要保证前后两次读取数据一致,那么读取数据的时候,锁定要操作的数据,不允许其他的事务修改。而大多数应用都是读多写少的,这样会极大地影响操作数据的效率
MVCC:一种多版本并发控制机制,基于数据的多版本去进行控制,无锁化的设计方案。
https://www.cnblogs.com/chz-blogs/p/14255322.html
哈希冲突及解决方案
哈希冲突的产生原因
哈希是通过对数据进行再压缩,提高效率的一种解决方法。但由于通过哈希函数产生的哈希值是有限的,而数据可能比较多,导致经过哈希函数处理后仍然有不同的数据对应相同的值。这时候就产生了哈希冲突。
产生哈希冲突的影响因素
装填因子(装填因子=数据总数 / 哈希表长)、哈希函数、处理冲突的方法
解决哈希冲突的四种方法
1.开放地址方法
(1)线性探测
按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上往后加一个单位,直至不发生哈希冲突。
(2)再平方探测
按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上先加1的平方个单位,若仍然存在则减1的平方个单位。随之是2的平方,3的平方等等。直至不发生哈希冲突。
(3)伪随机探测
按顺序决定值时,如果某数据已经存在,通过随机函数随机生成一个数,在原来值的基础上加上随机数,直至不发生哈希冲突。
2.链式地址法(HashMap的哈希冲突解决方法)
对于相同的值,使用链表进行连接。使用数组存储每一个链表。
优点:
(1)拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
(2)由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
(3)开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
(4)在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
缺点:
指针占用较大空间时,会造成空间浪费,若空间用于增大散列表规模进而提高开放地址法的效率。
3.建立公共溢出区
建立公共溢出区存储所有哈希冲突的数据。
4.再哈希法
对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
有环链表的环入口
/* * 解法如下: * * 设定fast和slow两个指针,初始都指向head。 * 然后让fast每次走2步,slow每次走一步,如果发现fast和slow重合,则确定单向链表有环路了。 * 接下来,让fast回到链表的头部,重新走,每次步长不是走2步了,而是走1步,那么当fast和slow再次相遇的结点,就是环路的入口位置了。 * * 证明: * * 当fast和slow第一次相遇的时候,slow肯定没有遍历完一次链表或刚好遍历完一次链表,而fast已经在环内循环了n圈(n>=1)。 * 这时,假设slow走了i个结点,则fast走了2i个结点,再假设环长为C,则 * * 2i = i + nC -> i = nC * * 设链表长度为L,链表起点距环入口的距离为j,环入口距相遇点的距离为k,则 * * j + k = i = nC * * j + k = (n - 1)C + C = (n - 1)C + (L - j) * * j = (n - 1)C + (L - j - k) * * (L - j - k)同k一样,同样为环入口点距相遇点的距离。 * 也就是说,从链表起点到环入口点的距离等于(n - 1)环长+相遇点到入口点的距离。 * 于是,从链表起点、相遇点分别设一指针,每次各走一步,则两指针必定相遇,且第一个相遇点即为环入口点。 */ #include \"SingleLinkedList.h\" /** * Get the loop entrance of single linked list. * @tparam T The type parameter. * @return The loop entrance of single linked list. */template<class T>Node<T> *SingleLinkedList<T>::getLoopEntrance() { Node<T> *slow = head, *fast = head; while (fast && fast->next) { slow = slow->next; fast = fast->next->next; if (slow == fast) { break; } } if (fast == NULL || fast->next == NULL) { return NULL; } fast = head; while (slow != fast) { slow = slow->next; fast = fast->next; } return fast;}OSI七层模型

网络路由交换协议【路由协议】
1.IGRP(Interior Gateway Routing Protocol)内部网关协议。
IGRP即内部网关协议,是一种动态距离向量路由协议,它由Cisco公司80年代中期设计。使用组合用户配置尺度,包括延迟、带宽、可靠性和负载。缺省情况下,IGRP每90秒发送一次路由更新广播,在3个更新周期内(即270秒),没有从路由中的第一个路由收到更新,则宣布路由不可访问。在7个更新周期即630秒后,Cisco IOS软件从路由表中清除路由,则RIPV1一样都不支持VSLM和CIDR。
2.VTP(VLAN trunk protocol)VLAN中继协议。
VTP即VLAN中继协议,作用是交换机与交换机之间VLAN信息相互传递,使用VTP协议可以在一个交换机中使用另一个交换机中VLAN配置信息,从而避免了在不同交换机设置相同的VLAN所造成的重复劳动,同时减少VLAN配置错误的可能性。
3.RIP(Routing Information Protocol)路由选择信息协议。
RIP即路由选择信息协议,是距离矢量路由协议的一种。所谓距离矢量是指路由器选择路由途径的评判标准:在RIP选择路由的时候,利用D-V算法来选择它所认为的最佳路径,然后将其填入路由表,在路由表中体现出来的就是跳数(hop)和下一跳的地址。
RIP允许的最大站点数为15,任何超过15个站点的目的地均为被标为不可到达,RIP适合小型网络。
4.OSPF(Open Shortest Path First)开放式最短路径优先协议。
OSPF即开放式最短路径优先协议,也是一种内部网关协议,一般作用于一个路由域里,由IETF开发的,他的使用不受任何厂商限制,所有人都可以使用,所以称为开放的,SPF(最短路径)是OSPF的核心思想,所有协议都会选用最短的路径。下面对OSPF区域类型、分组、及泛洪机制进行说明。
OSPF路由器使用其所在的不同区域进行身份标识,区域类型有4种,主要区别在于他们和外部路由器间的关系:
(1)标准区域:一个标准区域可以接受链路更新信息和路由总结。主干区域(传递区域):主干区域是连接各个区域的中心实体。主干区域始终是\"区域0\",所有其他的区域都要连接到这个区域上交换路由信息。主干区域拥有标准区域的所有性质。
(2)存根区域:存根区域是不接受自治系统以外的路由信息的区域。如果需要自治系统以外的路由,它使用默认路由0.0.0.0.
(3)完全存根区域:它不接受外部自治系统的路由以及自治系统内其他区域的路由总结。需要发送到区域外的报文则使用默认路由:0.0.0.0.完全存根区域是Cisco自己定义的。
(4)不完全存根区域(NSAA);它类似于存根区域,但是允许接收以LSA Type 7发送的外部路由信息,并且要把LSA Type 7转换成LSA Type5。
区分不同OSPF区域类型的关键在于他们对外部路由的处理方式。外部路由由ASBR传入自治系统内,ASBR可以通过RIP或者其他的路由协议学习到这些路由。
五种分组如下:
(1)类型1:问候Hello分组,用来发现和维持邻站的可达性。
(2)类型2:数据库描述DD分组,向邻站给出自己的链路状态数据库中的所有链路状态项目的摘要信息。
(3)类型3:链路状态请求LSR分组,向对方请求发送某些链路状态项目的详细信息。
(4)类型4:链路状态更新LSU通告包,用洪泛法对全网更新链路状态。
(5)类型5:链路状态通告LSA分组,记录了链路状态变化信息的数据,封装在LSU中。
OSPF使用溢流泛洪机制在一个新的路由区域中更新邻居OSPF路由器,只有受影响的路由才能被更新 ;发送的信息就是与本路由器相邻的所有路由器的链路状态;OSPF不是传送整个路由表,而是传送受影响的路由更新报文;OSPF使用组播链路状态更新(LSU)报文实现路由更新,并且只有当网络已经发生变化时才传送LSU。
5.BGP(Border Gateway Protocol)边界网关协议
BGP即边界网关协议,也使一种路径矢量路由协议,用于传输自治系统间的路由信息,BGP在启动的时候传播整张路由表,以后只传播网络变化的部分出发更新,它采用TCP连接传送信息,端口号为179,在Internet上,BGP需要通告的路由数目极大,由于TCP提供了可靠的传送机制,同时TCP使用滑动窗口机制,使得BGP可以不断地发送分组,而无需像OSPF或者EIGRP那样停止发送并等待确认。
TCP和UDP的区别
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
UDP如何实现可靠传输
UDP不属于连接协议,具有资源消耗少,处理速度快的优点,所以通常音频,视频和普通数据在传送时,使用UDP较多,因为即使丢失少量的包,也不会对接受结果产生较大的影响。
传输层无法保证数据的可靠传输,只能通过应用层来实现了。实现的方式可以参照tcp可靠性传输的方式,只是实现不在传输层,实现转移到了应用层。
最简单的方式是在应用层模仿传输层TCP的可靠性传输。下面不考虑拥塞处理,可靠UDP的简单设计。
1、添加seq/ack机制,确保数据发送到对端
2、添加发送和接收缓冲区,主要是用户超时重传。
3、添加超时重传机制。
详细说明:送端发送数据时,生成一个随机seq=x,然后每一片按照数据大小分配seq。数据到达接收端后接收端放入缓存,并发送一个ack=x的包,表示对方已经收到了数据。发送端收到了ack包后,删除缓冲区对应的数据。时间到后,定时任务检查是否需要重传数据。
目前有如下开源程序利用udp实现了可靠的数据传输。分别为RUDP、RTP、UDT。
cookie和session
由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。
所以,总结一下:Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
fork()
我们都知道通过fork()系统调用我们可以创建一个和当前进程印象一样的新进程.我们通常将新进程称为子进程,而当前进程称为父进程.而子进程继承了父进程的整个地址空间,其中包括了进程上下文,堆栈地址,内存信息进程控制块(PCB)等.
1.父子进程
那么我们首先来先说说父进程和子进程之间的区别:
父进程设置了锁,子进程不继承
进程ID不同
子进程的未决告警被清除
子进程的未决信号集设置为空集
GET POST
https://www.cnblogs.com/logsharing/p/8448446.html
从用户在浏览器输入域名,到浏览器显示出页面,这中间发生了什么
https://www.cnblogs.com/yuanzhiguo/p/8119470.html
堆栈的作用,以及存放的数据
https://blog.csdn.net/whlloveblog/article/details/44625783
TLS 四次握手
https://blog.csdn.net/weixin_44045328/article/details/107179755
ASCII和unicode的区别
https://blog.csdn.net/skh2015java/article/details/80500482
死锁的条件、解决方法
https://blog.csdn.net/qq_27068845/article/details/78818381
什么是虚拟内存、共享内存、物理内存
https://www.jianshu.com/p/3281463cb3bb
子网掩码的作用和用法
https://blog.csdn.net/kongguguren/article/details/79427465?utm_source=copy
C++内存如何分布、堆和栈的区别
https://blog.csdn.net/u013007900/article/details/79338653
IP头以及头的各部分含义
https://blog.csdn.net/hanzhen7541/article/details/79059877
常见的内存泄漏原因及解决方法
https://www.jianshu.com/p/90caf813682d
常见的DNS域名劫持方式及解决方法
https://cloud.tencent.com/developer/article/1768189
Linux C/C++ 中锁的使用总结
https://blog.csdn.net/shaosunrise/article/details/107620885
线程同步机制
https://www.cnblogs.com/youxin/p/3336775.html
断点续传原理
https://blog.csdn.net/zhangliangzi/article/details/51348755
IP切片及重组
https://www.huaweicloud.com/articles/2d315c874ac0b6d3b1b275c64ef7df82.html
操作系统微内核宏内核
https://zhuanlan.zhihu.com/p/53612117
浅拷贝、深拷贝、移动构造函数
https://blog.csdn.net/gxb0505/article/details/53572761
【C++】宏(#define)和内联函数(inline)的理解以及区别
https://zhuanlan.zhihu.com/p/46738288
程序编译的四个过程
https://blog.csdn.net/baidu_33604078/article/details/79091049
TCP三次握手
https://www.eet-china.com/mp/a44399.html
乐观锁与悲观锁
https://zhuanlan.zhihu.com/p/40211594
HTTPS 加密机制
https://www.cnblogs.com/sxiszero/p/11133747.html

