Python 自动化测试之滑块验证码处理_python处理滑块验证码
RPA 机器人流程自动化测试时,登录环节经常会出现各种拦路虎,比如像下面的滑块验证码。
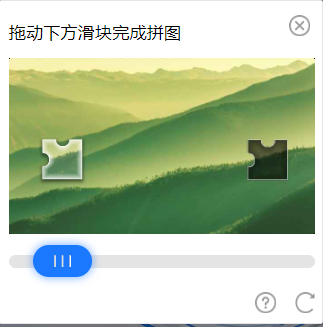
那么,如何通过 Python 的工具自动破解这些滑动验证码呢?
破解思路
关于滑动验证码破解的思路大体上来讲就是以下的步骤:
- 获取背景图和滑块图
- 计算滑块在背景图的位置
- 根据缩放比例及滑块初始位置计算真实的滑动距离
- 模拟拖动滑块,通过验证
关于上面这种的滑块验证,滑块和缺口背景都是分别是一张独立的图片,我们可以把这两张图片下载下来,借助于图像识别的技术,去识别缺口在背景图中的位置,然后按照比例缩放后,再减去滑块当前所在位置,就可以得出需要滑动的距离。
示例讲解
以下以顺丰的函证通的登录为例进行分析 函证通-运营后台系统
初始化浏览器
使用 selenium 初始化打开浏览器,这个属于常规的前置步骤,就不多说了(记得 chromedriver.exe 的版本和浏览器的版本要对应)。
class DriverClass: def __init__(self): self.driver = self._init_driver() def _init_driver(self): try: option = webdriver.ChromeOptions() option.add_experimental_option(\'excludeSwitches\', [\'enable-automation\']) option.add_experimental_option(\'useAutomationExtension\', False) prefs = dict() prefs[\'credentials_enable_service\'] = False prefs[\'profile.password_manager_enable\'] = False prefs[\'profile.name\'] = \"Person 1\" option.add_experimental_option(\'prefs\', prefs) option.add_argument(\'--disable-gpu\') option.add_argument(\"--disable-blink-features=AutomationControlled\") option.add_argument(\'--user-agent=\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36\"\') option.add_argument(\'--no-sandbox\') option.add_argument(\'ignore-certificate-errors\') # option.add_experimental_option(\"debuggerAddress\", \"127.0.0.1:9527\") driver = webdriver.Chrome(r\"./driver/chromedriver.exe\", options=option) driver.implicitly_wait(2) driver.maximize_window() return driver except Exception as e: raise e def get_driver(self) -> webdriver.Chrome: if isinstance(self.driver, webdriver.Chrome): return self.driver raise Exception(\'初始化浏览器失败\')用户名密码输入
然后打开目标网址的登录首页,利用查找到的 XPath 输入用户名,密码 并点击登录按钮。
def handle_login(self): try: print(\"开始登录\") print(f\'login_url: {self.login_url}\') self.driver.get(self.login_url) time.sleep(1) self.driver.find_element(By.XPATH, \'//div/div/input[@name=\"username\"]\').send_keys(self.username) # 用户名 self.driver.find_element(By.XPATH, \'//div/div/input[@name=\"password\"]\').send_keys(self.password) # 密码 self.driver.find_element(By.XPATH, \'//div/div/button/span[contains(text(), \"登 录\")]\').click() # 登录按钮 print(\"等待拖动滑块验证...\") self.solve_captcha() # 登录成功,记录当前页面句柄 self.base_window_handle = self.driver.current_window_handle print(\"登录成功\") return True except Exception as e: print(traceback.format_exc()) self.save_error_img() return False获取图片 XPath
等待滑块图片加载以后,获取背景图和滑块图的 XPath 并获取元素引用(这里需要先切换到新的 iframe)。
time.sleep(5)self.driver.switch_to.frame(\"tcaptcha_iframe\")# 等待元素加载xpath_bg_element = \'//div/div/div/p[@id=\"guideText\"]/following::*/div[@id=\"slideBgWrap\"]/img\'WebDriverWait(self.driver, 5).until(EC.presence_of_element_located((By.XPATH, xpath_bg_element)))bg_element = self.driver.find_element(By.XPATH, xpath_bg_element)xpath_slider_element = \'//div/div/div/p[@id=\"guideText\"]/following::*/div[@id=\"slideBlockWrap\"]/img\'slider_element = self.driver.find_element(By.XPATH, xpath_slider_element)xpath_slider_button = \'//div/div/div/p[@id=\"guideText\"]/following::*/div[@id=\"tcaptcha_drag_thumb\"]\'slider_button = self.driver.find_element(By.XPATH, xpath_slider_button)下载并保存图片
根据元素的 src 属性,获取图片的下载链接,然后下载并保存背景图和滑块图到本地。
def get_images(self, bg_element, slider_element): # 获取背景图 bg_src = bg_element.get_attribute(\"src\") bg_content = requests.get(bg_src).content # 获取滑块图 slider_src = slider_element.get_attribute(\"src\") slider_content = requests.get(slider_src).content # 下载图片 bg_path = os.path.join(\"img\", \"bg.png\") slider_path = os.path.join(\"img\", \"slider.png\") with open(bg_path, \"wb\") as f: f.write(bg_content) with open(slider_path, \"wb\") as f: f.write(slider_content) return bg_path, slider_path识别滑块在背景图的位置
通过传入保存的背景图和滑块图的路径,并利用 opencv-python 进行二值化灰度处理(一般灰度处理后,去除了非必要的干扰项,识别精度会高一些),再识别滑块在背景图中的位置。


def get_slide_distance(self, bg_path, slider_path): # 读取进行色度图片,转换为numpy中的数组类型数据, slider_pic = cv2.imread(slider_path, 0) background_pic = cv2.imread(bg_path, 0) # 获取缺口图数组的形状 --> 缺口图的宽和高 width, height = slider_pic.shape[::-1] # 将处理之后的图片另存 slider01 = slider_path background_01 = bg_path cv2.imwrite(background_01, background_pic) cv2.imwrite(slider01, slider_pic) # 读取另存的滑块图 slider_pic = cv2.imread(slider01) # 进行色彩转换 slider_pic = cv2.cvtColor(slider_pic, cv2.COLOR_BGR2GRAY) # 获取色差的绝对值 slider_pic = abs(255 - slider_pic) # 保存图片 cv2.imwrite(slider01, slider_pic) # 读取滑块 slider_pic = cv2.imread(slider01) # 读取背景图 background_pic = cv2.imread(background_01) # 比较两张图的重叠区域 result = cv2.matchTemplate(slider_pic, background_pic, cv2.TM_CCOEFF_NORMED) # 获取图片的缺口位置 top, left = np.unravel_index(result.argmax(), result.shape) # 背景图中的图片缺口坐标位置 print(\"当前滑块的缺口位置:\", (left, top, left + width, top + height)) return left计算真实滑动距离
这里是关键步骤了,计算不正确的话很可能导致滑块拖动不到位。
背景图和滑块图在页面上的尺寸和下载到本地的图片尺寸是不一样的,我们上面计算的距离 distance 是以本地图片的尺寸为准,但最后的拖动操作是在页面上进行,所以需要按照缩放比例 scale 将距离转换成页面的距离。
同时由于滑块初始位置没有在背景图的最左边,所以计算的距离还需要减去滑块初始位置距离背景图左边缘的距离 delta。
real_distance = distance * scale - delta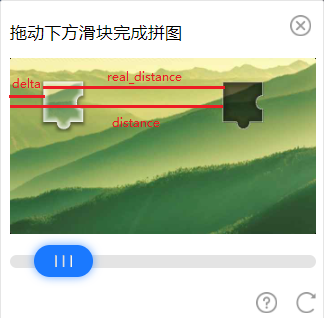
distance = self.get_slide_distance(bg_path, slider_path)# 根据背景图的页面尺寸和实际尺寸调整缩放比bg_width = bg_element.size[\"width\"]real_width = cv2.imread(bg_path).shape[1]scale = bg_width / real_widthprint(f\"图片宽度:{real_width},页面图片宽度:{bg_width},缩放比:{scale}\")# 统一转换成页面的尺寸规格,这里的 delta 大略是滑块初始位置距离背景图左边缘的距离,所以滑动时要减掉这段距离delta = 25real_distance = distance * scale - deltaprint(\"滑动距离:\", real_distance)滑块拖动
直接拖动
计算出滑动距离以后,一般我们可以像下面这样对滑块直接一次性拖动到位。
def slide_verify_by_distance(self, slider, distance): # 执行滑动操作 ActionChains(self.driver).click_and_hold(slider).perform() ActionChains(self.driver).move_by_offset(xoffset=distance, yoffset=0).perform() time.sleep(0.5) ActionChains(self.driver).release().perform() slider.click()多次拖动
有时候有些网站的校验比较严格,直接一次拖动的话可能会触发校验,被反爬虫识别出来是机器人,这个时候,我们也可以将滑动距离拆分成多段,然后进行分段拖动,这样更像是人类的操作。
def get_track(self, distance): # 生成移动轨迹(模拟人类滑动) track = [] current = 0 mid = distance * 0.8 t = 0.2 v = 0 while current < distance: if current < mid: a = 5 # 加速阶段 else: a = -3 # 减速阶段 v0 = v v = v0 + a * t move = v0 * t + 0.5 * a * t * t current += move track.append(round(move)) # 微调误差 track.append(distance - sum(track)) return trackdef slide_verify_by_track(self, slider, track): # 执行滑动操作 ActionChains(self.driver).click_and_hold(slider).perform() for x in track: ActionChains(self.driver).move_by_offset(xoffset=x, yoffset=0).perform() time.sleep(0.5) ActionChains(self.driver).release().perform() slider.click()目前自测顺丰的 函证通,这两种方式进行拖动都是可以的。
完整代码
示例网站完整代码如下(错误的用户名密码也可以进入滑块验证码界面,下面代码可以直接运行):
import os.pathimport tracebackimport timeimport requestsimport cv2import numpy as npimport datetimefrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.action_chains import ActionChainsfrom selenium.webdriver.chrome.webdriver import WebDriverfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as EC# 新建 img 目录,存放下载的背景图和滑块图os.makedirs(\"img\", exist_ok=True)# 新建 tmp 目录,存放失败时的截图os.makedirs(\"tmp\", exist_ok=True)def get_current_time(fmt=\"%Y-%m-%d %H:%M:%S\"): return datetime.datetime.now().strftime(fmt)class DriverClass: def __init__(self): self.driver = self._init_driver() def _init_driver(self): try: option = webdriver.ChromeOptions() option.add_experimental_option(\'excludeSwitches\', [\'enable-automation\']) option.add_experimental_option(\'useAutomationExtension\', False) prefs = dict() prefs[\'credentials_enable_service\'] = False prefs[\'profile.password_manager_enable\'] = False prefs[\'profile.name\'] = \"Person 1\" option.add_experimental_option(\'prefs\', prefs) option.add_argument(\'--disable-gpu\') option.add_argument(\"--disable-blink-features=AutomationControlled\") option.add_argument(\'--user-agent=\"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36\"\') option.add_argument(\'--no-sandbox\') option.add_argument(\'ignore-certificate-errors\') # option.add_experimental_option(\"debuggerAddress\", \"127.0.0.1:9527\") driver = webdriver.Chrome(r\"./driver/chromedriver.exe\", options=option) driver.implicitly_wait(2) driver.maximize_window() return driver except Exception as e: raise e def get_driver(self) -> webdriver.Chrome: if isinstance(self.driver, webdriver.Chrome): return self.driver raise Exception(\'初始化浏览器失败\')class HZT: \"\"\"函证通\"\"\" def __init__(self, params): self.name = \"hzt\" self.base_window_handle = \"\" self.login_url = params[\"login_url\"] self.username = params[\"username\"] self.password = params[\"password\"] def init_driver(self): try: print(\'打开浏览器\') dc = DriverClass() self.driver = dc.get_driver() return True except Exception as e: print(\'打开浏览器失败\') print(traceback.format_exc()) return False def close_driver(self): try: if self.driver and isinstance(self.driver, WebDriver): self.driver.quit() else: del self.driver print(\"浏览器正常关闭\") return True except Exception as e: print(traceback.format_exc()) def handle_login(self): try: print(\"开始登录\") print(f\'login_url: {self.login_url}\') self.driver.get(self.login_url) time.sleep(1) self.driver.find_element(By.XPATH, \'//div/div/input[@name=\"username\"]\').send_keys(self.username) # 用户名 self.driver.find_element(By.XPATH, \'//div/div/input[@name=\"password\"]\').send_keys(self.password) # 密码 self.driver.find_element(By.XPATH, \'//div/div/button/span[contains(text(), \"登 录\")]\').click() # 登录按钮 print(\"等待拖动滑块验证...\") self.solve_captcha() # 登录成功,记录当前页面句柄 self.base_window_handle = self.driver.current_window_handle print(\"登录成功\") return True except Exception as e: print(traceback.format_exc()) self.save_error_img() return False def save_error_img(self): try: now_date = get_current_time(\"%Y%m%d\") file_save_dir = os.path.join(\"tmp\", now_date, self.name) os.makedirs(file_save_dir, exist_ok=True) err_file_path = os.path.join(file_save_dir, f\'{self.name}_err_{get_current_time(fmt=\"%Y%m%d%H%M%S\")}.png\') print(f\"存储错误发生时截图,err_file_path: {err_file_path}\") self.driver.save_screenshot(err_file_path) except Exception as e: print(traceback.format_exc()) def get_slide_distance(self, bg_path, slider_path): # 读取进行色度图片,转换为numpy中的数组类型数据, slider_pic = cv2.imread(slider_path, 0) background_pic = cv2.imread(bg_path, 0) # 获取缺口图数组的形状 --> 缺口图的宽和高 width, height = slider_pic.shape[::-1] # 将处理之后的图片另存 slider01 = slider_path background_01 = bg_path cv2.imwrite(background_01, background_pic) cv2.imwrite(slider01, slider_pic) # 读取另存的滑块图 slider_pic = cv2.imread(slider01) # 进行色彩转换 slider_pic = cv2.cvtColor(slider_pic, cv2.COLOR_BGR2GRAY) # 获取色差的绝对值 slider_pic = abs(255 - slider_pic) # 保存图片 cv2.imwrite(slider01, slider_pic) # 读取滑块 slider_pic = cv2.imread(slider01) # 读取背景图 background_pic = cv2.imread(background_01) # 比较两张图的重叠区域 result = cv2.matchTemplate(slider_pic, background_pic, cv2.TM_CCOEFF_NORMED) # 获取图片的缺口位置 top, left = np.unravel_index(result.argmax(), result.shape) # 背景图中的图片缺口坐标位置 print(\"当前滑块的缺口位置:\", (left, top, left + width, top + height)) return left def get_images(self, bg_element, slider_element): # 获取背景图 bg_src = bg_element.get_attribute(\"src\") bg_content = requests.get(bg_src).content # 获取滑块图 slider_src = slider_element.get_attribute(\"src\") slider_content = requests.get(slider_src).content # 下载图片 bg_path = os.path.join(\"img\", \"bg.png\") slider_path = os.path.join(\"img\", \"slider.png\") with open(bg_path, \"wb\") as f: f.write(bg_content) with open(slider_path, \"wb\") as f: f.write(slider_content) return bg_path, slider_path def slide_verify_by_distance(self, slider, distance): # 执行滑动操作 ActionChains(self.driver).click_and_hold(slider).perform() ActionChains(self.driver).move_by_offset(xoffset=distance, yoffset=0).perform() time.sleep(0.5) ActionChains(self.driver).release().perform() slider.click() def get_track(self, distance): # 生成移动轨迹(模拟人类滑动) track = [] current = 0 mid = distance * 0.8 t = 0.2 v = 0 while current < distance: if current < mid: a = 5 # 加速阶段 else: a = -3 # 减速阶段 v0 = v v = v0 + a * t move = v0 * t + 0.5 * a * t * t current += move track.append(round(move)) # 微调误差 track.append(distance - sum(track)) return track def slide_verify_by_track(self, slider, track): # 执行滑动操作 ActionChains(self.driver).click_and_hold(slider).perform() for x in track: ActionChains(self.driver).move_by_offset(xoffset=x, yoffset=0).perform() time.sleep(0.5) ActionChains(self.driver).release().perform() slider.click() def solve_captcha(self): \"\"\"处理滑块图形验证码\"\"\" try: # 等待滑块图形加载 time.sleep(5) self.driver.switch_to.frame(\"tcaptcha_iframe\") # 等待元素加载 xpath_bg_element = \'//div/div/div/p[@id=\"guideText\"]/following::*/div[@id=\"slideBgWrap\"]/img\' WebDriverWait(self.driver, 5).until(EC.presence_of_element_located((By.XPATH, xpath_bg_element))) bg_element = self.driver.find_element(By.XPATH, xpath_bg_element) xpath_slider_element = \'//div/div/div/p[@id=\"guideText\"]/following::*/div[@id=\"slideBlockWrap\"]/img\' slider_element = self.driver.find_element(By.XPATH, xpath_slider_element) xpath_slider_button = \'//div/div/div/p[@id=\"guideText\"]/following::*/div[@id=\"tcaptcha_drag_thumb\"]\' slider_button = self.driver.find_element(By.XPATH, xpath_slider_button) # 获取并处理图片 bg_path, slider_path = self.get_images(bg_element, slider_element) distance = self.get_slide_distance(bg_path, slider_path) # 根据背景图的页面尺寸和实际尺寸调整缩放比 bg_width = bg_element.size[\"width\"] real_width = cv2.imread(bg_path).shape[1] scale = bg_width / real_width print(f\"图片宽度:{real_width},页面图片宽度:{bg_width},缩放比:{scale}\") # 统一转换成页面的尺寸规格,这里的 delta 大略是滑块初始位置距离背景图左边缘的距离,所以滑动时要减掉这段距离 delta = 25 real_distance = distance * scale - delta print(\"滑动距离:\", real_distance) self.slide_verify_by_distance(slider_button, real_distance) # track = self.get_track(real_distance) # self.slide_verify_by_track(slider_button, track) # 等待用户输入滑动验证码 time.sleep(10) except Exception as e: print(\"滑块验证码处理报错\") print(traceback.format_exc()) traceback.print_exc()if __name__ == \'__main__\': params = { \"login_url\": \"https://hzt.sf-laas.com/login\", \"username\": \"username\", # 用自己的用户名 \"password\": \"password\", # 用自己的密码 } hwc = HZT(params) hwc.init_driver() hwc.handle_login() hwc.close_driver()注意事项
下载链接获取
有时候图片加载比较慢,可能导致元素虽然能获取到,但是 src 属性的图片链接还没加载,这个时候可以等待 src 加载完全后再下载图片。
图片下载报错
有时候图片下载链接虽然获取到了,但是下载的时候报 Max retries exceeded with url,这个时候可以添加个重试机制,下载报错时,等待一段时间后再次下载。
def get_images(self, bg_element, slider_element): for i in range(30): bg_src = bg_element.get_attribute(\"src\") if bg_src: break time.sleep(1) # 获取背景图 bg_src = bg_element.get_attribute(\"src\") # 获取滑块图 slider_src = slider_element.get_attribute(\"src\") try: bg_content = requests.get(bg_src).content slider_content = requests.get(slider_src).content except: time.sleep(1) bg_content = requests.get(bg_src).content slider_content = requests.get(slider_src).content # 下载图片 bg_path = os.path.join(\"img\", \"bg.png\") slider_path = os.path.join(\"img\", \"slider.png\") with open(bg_path, \"wb\") as f: f.write(bg_content) with open(slider_path, \"wb\") as f: f.write(slider_content) return bg_path, slider_path滑块处理重试
有时候滑块验证码首次处理可能不一定顺利,我们可以根据处理后是否还有滑块背景图来判断是否处理成功,如果不成功,重新打开滑块验证码进行处理。
def handle_login(self): try: print(\"开始登录\") print(f\'login_url: {self.login_url}\') self.driver.get(self.login_url) time.sleep(1) self.driver.find_element(By.XPATH, \'//div/div/input[@name=\"username\"]\').send_keys(self.username) # 用户名 self.driver.find_element(By.XPATH, \'//div/div/input[@name=\"password\"]\').send_keys(self.password) # 密码 self.driver.find_element(By.XPATH, \'//div/div/button/span[contains(text(), \"登 录\")]\').click() # 登录按钮 print(\"等待拖动滑块验证...\") self.solve_captcha() try: self.driver.find_element(By.XPATH, \'//div/div/div/p[@id=\"guideText\"]/following::*/div[@id=\"slideBgWrap\"]/img\') self.save_error_img() print(\"滑块背景图依然存在,再次重试处理滑块验证码\") # 关闭滑块验证码并重新点击登录 self.driver.find_element(By.XPATH, \'//div[@id=\"captcha_close\"]\').click() time.sleep(1) self.driver.find_element(By.XPATH, \'//div/div/button/span[contains(text(), \"登 录\")]\').click() # 登录按钮 self.solve_captcha() # 如果滑块背景图还在,说明再次重试失败 self.driver.find_element(By.XPATH, \'//div/div/div/p[@id=\"guideText\"]/following::*/div[@id=\"slideBgWrap\"]/img\') self.save_error_img() return False except: pass # 登录成功,记录当前页面句柄 self.base_window_handle = self.driver.current_window_handle print(\"登录成功\") return True except Exception as e: print(traceback.format_exc()) self.save_error_img() return False
