AIGC利器:Flux模型代码基础学习_flowmatcheulerdiscretescheduler
模型链接:black-forest-labs/FLUX.1-dev - Hugging Face
1:模型整体配置:
{
\"_class_name\": \"FluxPipeline\",
\"_diffusers_version\": \"0.30.0.dev0\",
\"scheduler\": [
\"diffusers\",
\"FlowMatchEulerDiscreteScheduler\"(调度器)
(生成步骤控制: 调度器负责定义生成图像时的迭代步骤和时间进程。它确定在每个迭代中如何更新潜在表示,以实现去噪和图像生成。
去噪过程指导: 在扩散模型中,调度器控制去噪过程的步长和方向,确保每一步都朝着生成更清晰图像的目标前进。
参数调整: 根据生成过程的需要,调度器可以调整学习率、噪声水平等参数,以优化生成效果。)
],
\"text_encoder\": [
\"transformers\",
\"CLIPTextModel\"(适合需要视觉上下文的任务。)
],
\"text_encoder_2\": [
\"transformers\",
\"T5EncoderModel\"(更广泛的文本任务)
],
\"tokenizer\": [
\"transformers\",
\"CLIPTokenizer\"(将原始文本转化为模型可以理解的token)
],
\"tokenizer_2\": [
\"transformers\",
\"T5TokenizerFast\"(将原始文本转化为模型可以理解的token)
],
\"transformer\": [
\"diffusers\",
\"FluxTransformer2DModel\"(负责图像生成过程的核心优化)
(主要功能: 作为生成模型的核心,FluxTransformer2DModel负责在潜在空间中进行图像生成。
特征融合: 它接收来自文本编码器的潜在表示,并将其与图像的潜在表示结合,从而在生成过程中考虑文本的语义信息。
迭代优化: 通过调度器的指导,该模型进行多次迭代,逐步生成和细化图像,确保生成的内容与输入文本一致。也可称之为去噪过程。)
],
\"vae\": [
\"diffusers\",
\"AutoencoderKL\"(变分自编码器)
(主要功能: 作为解码器,其负责将生成的潜在表示转换回图像空间,输出最终的图像。
重构能力: 该模块通过学习从潜在表示重构图像,确保生成的图像在视觉上逼真且与输入文本相关。)
]
2:各模块功能:
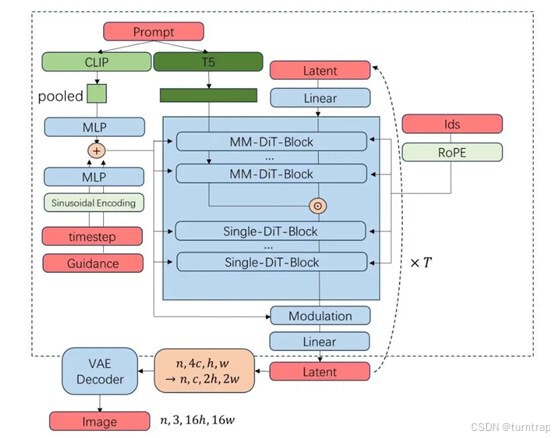
整体流程(来自Stable Diffusion 3「精神续作」FLUX.1 源码深度前瞻解读_flowmatcheulerdiscretescheduler-CSDN博客)
2.1 CLIPTextModel:
{
\"_name_or_path\": \"openai/clip-vit-large-patch14\",
\"architectures\": [
\"CLIPTextModel\"
],
\"attention_dropout\": 0.0,(注意力机制中的dropout比例)
\"bos_token_id\": 0,(句子开头的标记ID)
\"dropout\": 0.0,(模型整体的dropout比例)
\"eos_token_id\": 2,(句子结尾的标记ID)
\"hidden_act\": \"quick_gelu\",
\"hidden_size\": 768,(隐藏层的维度)
\"initializer_factor\": 1.0,
\"initializer_range\": 0.02,
\"intermediate_size\": 3072,(中间层的大小)
\"layer_norm_eps\": 1e-05,
\"max_position_embeddings\": 77,(模型可以处理的最大输入长度)
\"model_type\": \"clip_text_model\",
\"num_attention_heads\": 12,
\"num_hidden_layers\": 12,(隐藏层数量)
\"pad_token_id\": 1,(填充标记的ID)
\"projection_dim\": 768,(投影维度,将文本表示映射到与图像表示相同的空间)
\"torch_dtype\": \"bfloat16\",
\"transformers_version\": \"4.43.3\",
\"vocab_size\": 49408
}
该模块主要负责将输入的prompt转化为池化层嵌入,之后在去噪过程中使得模型能够更容易地(低维,复杂性低)学习到文本与时间步之间的关系。
张量形状变化:
输入:input_ids:[batch_size,max_length]
嵌入层:里面有一个文本嵌入层和一个位置嵌入层(均为可学习参数的Embedding层),返回二者的和,形状为[batch_size,seq_length,hidden_size]
input_ids先进入嵌入层,得到hidden_states,之后进入12个编码层,每一层中先归一化,后经过一个注意力层,然后残差连接,再归一化,之后进入一个多层感知机,再残差连接,最后归一化并输出。后面的模型使用的是其池化层输出pooled_output,形状为[batch_size, hidden_size]
如果一个文本生成多个图像(注意参数num_images_per_prompt),需要重复生成的嵌入向量:调整形状为[batch_size,hidden_size * num_images_per_prompt],之后调整形状为:[batch_size *num_images_per_prompt,hidden_size]
2.2 T5EncoderModel:
{
\"_name_or_path\": \"google/t5-v1_1-xxl\",
\"architectures\": [
\"T5EncoderModel\"
],
\"classifier_dropout\": 0.0,
\"d_ff\": 10240, (前馈层的维度,表示每个前馈网络的隐藏层大小。)
\"d_kv\": 64,
\"d_model\": 4096,(隐藏层的维度,表示每个隐藏状态向量的大小。)
\"decoder_start_token_id\": 0,
\"dense_act_fn\": \"gelu_new\",
\"dropout_rate\": 0.1,
\"eos_token_id\": 1,
\"feed_forward_proj\": \"gated-gelu\",
\"initializer_factor\": 1.0,
\"is_encoder_decoder\": true,
\"is_gated_act\": true,
\"layer_norm_epsilon\": 1e-06,
\"model_type\": \"t5\",
\"num_decoder_layers\": 24,
\"num_heads\": 64,
\"num_layers\": 24,
\"output_past\": true,
\"pad_token_id\": 0,
\"relative_attention_max_distance\": 128,(相对注意力机制的最大距离)
\"relative_attention_num_buckets\": 32,
\"tie_word_embeddings\": false,
\"torch_dtype\": \"bfloat16\",
\"transformers_version\": \"4.43.3\",
\"use_cache\": true,
\"vocab_size\": 32128
}
该模块主要负责将输入的prompt转化为高维的文本嵌入,其丰富的语义信息使得在去噪过程中,模型在生成图像时,可以利用这些语义信息与潜在的图像特征进行关联,从而提高生成图像的相关性和准确性。
张量形状变化:
输入:input_ids:[batch_size,max_length]
嵌入层:将input_ids变为嵌入向量[batch_size,max_length,d_model]
进入一个栈,栈内是24个编码层的循环。在每个编码层内,先进入一个自注意力层,在自注意力层中,先归一化,之后经过自注意力机制计算得到输出,将嵌入向量与注意力机制输出相加得到新的向量(残差连接),此时向量形状:[batch_size,max_length,d_model]。之后输入一个前馈层,在该层中,先归一化,之后传入前馈网络,再将结果与之前的向量残差连接并输出。每个编码层输出一个元组:(嵌入向量,位置偏移、注意力权重),最后栈中嵌入向量经过归一化返回。最后prompt_embeds形状为[batch_size, sequence_length,d_model]
如果一个文本生成多个图像,需要重复生成的嵌入向量:prompt_embeds形状为[batch_size, sequence_length* num_images_per_prompt,d_model],之后调整为:[batch_size *num_images_per_prompt,sequence_length,d_model]
2.3 FlowMatchEulerDiscreteScheduler:
{
\"_class_name\": \"FlowMatchEulerDiscreteScheduler\",
\"_diffusers_version\": \"0.30.0.dev0\",
\"base_image_seq_len\": 256,(输入图像序列的基准长度)
\"base_shift\": 0.5,
\"max_image_seq_len\": 4096, 输入图像序列的最大长度)
\"max_shift\": 1.15,
\"num_train_timesteps\": 1000,
\"shift\": 3.0,
\"use_dynamic_shifting\": true
}
该模块主要负责确定训练以及推理过程的时间步,以及在去噪过程中调节图像生成方向。
获取时间步:
生成影响扩散过程中的噪声强度sigmas,每一个时间步对应一个sigma,训练时这个值控制了在该时间步中添加的噪声量。在推理时,这个值决定了模型如何从噪声恢复出逼近真实数据的样本:
sigmas = np.linspace(1.0, 1 / num_inference_steps, num_inference_steps)sigmas是一个等差数列,一开始的值最大,代表一开始要添加的噪声越强,随时间的推移添加的噪音越来越小。随后调用retrieve_timesteps函数获取去噪过程的时间步。该部分主要调用FlowMatchEulerDiscreteScheduler的set_timesteps方法,本模型在确定时间步时会根据输入图像的大小动态调整时间步,这个调整依赖于根据输入图像的尺寸来计算一个偏置参数mu:
def calculate_shift( image_seq_len, base_seq_len: int = 256, max_seq_len: int = 4096, base_shift: float = 0.5, max_shift: float = 1.16,): # 斜率m: m = (max_shift - base_shift) / (max_seq_len - base_seq_len) # 截距: b = base_shift - m * base_seq_len # 给定图像序列长度的偏移量 mu = image_seq_len * m + b return mu之后调用time_shift函数调整sigmas中的每一个元素:
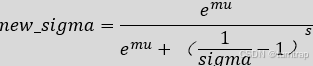
最后将sigmas进行缩放:将其映射到一个与训练阶段相匹配的时间步范围(这样可以确保在推理阶段与训练阶段保持一致性)。将缩放的结果作为推理阶段的时间步返回。
去噪调节:
在获取到第t个时间步的噪音noise_pred后,怎么将潜在图像由第t个时间步阶段回退到第t-1个时间步阶段呢,这时候需要调用FlowMatchEulerDiscreteScheduler的step函数更新潜在图像。
在step函数中,需要获取第t个时间步的噪声强度sigma和第t-1个时间步的噪声强度sigma_next,之后进行缩放:
new_latents=noise_pred+(sigma_next - sigma) * latents2.4 FluxTransformer2DModel:
{
\"_class_name\": \"FluxTransformer2DModel\",
\"_diffusers_version\": \"0.30.0.dev0\",
\"_name_or_path\": \"../checkpoints/flux-dev/transformer\",
\"attention_head_dim\": 128,
\"guidance_embeds\": true,
\"in_channels\": 64,
\"joint_attention_dim\": 4096,(联合注意力维度)
\"num_attention_heads\": 24,
\"num_layers\": 19,
\"num_single_layers\": 38,
\"patch_size\": 1,
\"pooled_projection_dim\": 768(池化投影维度)
}
该模块主要负责融合时间步、引导强度、池化文本嵌入、高维文本嵌入和潜在图像,在去噪过程中预测每一步的噪音图像,对潜在图像进行更新:
在该模块需要注意位置嵌入、时间-引导强度-池化文本融合嵌入和模态融合。
位置嵌入(本模块使用三维旋转位置嵌入):
def get_1d_rotary_pos_embed( dim: int, pos: Union[np.ndarray, int], theta: float = 10000.0,#频率计算的缩放因子 use_real=False,# 是否返回实部和虚部分开的结果 linear_factor=1.0,# 上下文外推的缩放因子 ntk_factor=1.0,#缩放因子 repeat_interleave_real=True,#以特定方式重复真实部分和虚拟部分 freqs_dtype=torch.float32, # torch.float32, torch.float64 (flux)): assert dim % 2 == 0 if isinstance(pos, int): pos = torch.arange(pos) if isinstance(pos, np.ndarray): pos = torch.from_numpy(pos) # [seq_length+h/2*w/2] theta = theta * ntk_factor # (1)间隔为2,生成0到dim的张量:[dim/2] # (2)取前dim/2个:每个除以dim得到频率 freqs = ( 1.0 / (theta ** (torch.arange(0, dim, 2, dtype=freqs_dtype, device=pos.device)[: (dim // 2)] / dim)) / linear_factor ) # 位置id与频率做外积:freqs包含了每个位置的频率信息 freqs = torch.outer(pos, freqs) # [seq_length+h/2*w/2, dim/2] if use_real and repeat_interleave_real: #.repeat_interleave(2, dim=1)在第一维(列)重复2遍 freqs_cos = freqs.cos().repeat_interleave(2, dim=1).float() # [seq_length+h/2*w/2, dim] freqs_sin = freqs.sin().repeat_interleave(2, dim=1).float() # [seq_length+h/2*w/2, dim] return freqs_cos, freqs_sin elif use_real: # stable audio freqs_cos = torch.cat([freqs.cos(), freqs.cos()], dim=-1).float() # [seq_length+h/2*w/2, dim] freqs_sin = torch.cat([freqs.sin(), freqs.sin()], dim=-1).float() # [seq_length+h/2*w/2, dim] return freqs_cos, freqs_sin else: #freqs:相位 #x·x的旋转位置编码=将x逆时针旋转一定度数,有助于保持元素的相对顺序 freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # [seq_length+h/2*w/2, dim/2] return freqs_cis#三维旋转位置编码class FluxPosEmbed(nn.Module): def __init__(self, theta: int, axes_dim: List[int]): super().__init__() self.theta = theta self.axes_dim = axes_dim def forward(self, ids: torch.Tensor) -> torch.Tensor: # 输入张量 ids 的最后一个维度的大小,即轴的数量[16,56,56] n_axes = ids.shape[-1] cos_out = [] sin_out = [] pos = ids.float() is_mps = ids.device.type == \"mps\" freqs_dtype = torch.float32 if is_mps else torch.float64 # 轴的数量必然和位置id的第二维列数相同 for i in range(n_axes): cos, sin = get_1d_rotary_pos_embed( self.axes_dim[i], pos[:, i], repeat_interleave_real=True, use_real=True, freqs_dtype=freqs_dtype ) #cos, sin除最后一维外保持原样,最后一维是axes_dim[i] cos_out.append(cos) sin_out.append(sin) # 在最后一维拼接 freqs_cos = torch.cat(cos_out, dim=-1).to(ids.device) freqs_sin = torch.cat(sin_out, dim=-1).to(ids.device) #形状:[seq_length+h/2*w/2 , sum(n_axes)] return freqs_cos, freqs_sin位置编码的输入是文本id和图像id,文本id为全零的形状为[seq_length,3]的张量,图像id生成过程为:
def _prepare_latent_image_ids(batch_size, height, width, device, dtype): #创建一个高度和宽度均为height和width一半的全零张量,第三个维度为3,代表RGB图像的三个颜色通道。 latent_image_ids = torch.zeros(height // 2, width // 2, 3) #更改第二个通道,为每一行的所有像素点添加一个递增的值 #latent_image_ids[..., 1]的形状是[height // 2, width // 2]。 #torch.arange(height // 2)[:, None]的形状是[height // 2, 1]。 latent_image_ids[..., 1] = latent_image_ids[..., 1] + torch.arange(height // 2)[:, None] # 更改第三个通道,为每一列的所有像素点添加一个递增的值 # torch.arange(width // 2)[ None,:]的形状是[ 1,width//2]。 latent_image_ids[..., 2] = latent_image_ids[..., 2] + torch.arange(width // 2)[None, :] latent_image_id_height, latent_image_id_width, latent_image_id_channels = latent_image_ids.shape #原本形状为[h,w,3],形状变为[h*w,3] latent_image_ids = latent_image_ids.reshape( latent_image_id_height * latent_image_id_width, latent_image_id_channels ) #[h*w,3] return latent_image_ids.to(device=device, dtype=dtype)二者在第0维拼接为位置编码的输入id,形状为[seq_length+h/2*w/2,3],该嵌入在注意力层被应用于q和k上,应用方式为:
# 该函数将旋转嵌入应用于输入张量 x,通常表示注意力机制中的查询或键张量def apply_rotary_emb(#x: [batch_size, heads, seq_length+h//2*w//2, head_dim] x: torch.Tensor, freqs_cis: Union[torch.Tensor, Tuple[torch.Tensor]],# 一个包含两个PyTorch张量的元组,这两个张量分别代表余弦和正弦的频率。 use_real: bool = True, use_real_unbind_dim: int = -1,) -> Tuple[torch.Tensor, torch.Tensor]: if use_real: cos, sin = freqs_cis # [seq_length+h//2*w//2, sum(n_axes)] # 最前面添加两维,以符合x的维度:[batch_size , heads , seq_length+h//2*w//2 , head_dim] cos = cos[None, None] # [1 , 1 , seq_length+h//2*w//2 , sum(n_axes)] sin = sin[None, None] cos, sin = cos.to(x.device), sin.to(x.device) #在最后一维解绑 if use_real_unbind_dim == -1: #*x.shape[:-1]表示将x的前三维维度作为新的x的前三维维度,第四维是自适应,第五维是2,之后取消第五维,分为两部分 x_real, x_imag = x.reshape(*x.shape[:-1], -1, 2).unbind(-1) # [B, S, H, D//2] x_rotated = torch.stack([-x_imag, x_real], dim=-1).flatten(3) elif use_real_unbind_dim == -2: # Used for Stable Audio x_real, x_imag = x.reshape(*x.shape[:-1], 2, -1).unbind(-2) # [B, S, H, D//2] x_rotated = torch.cat([-x_imag, x_real], dim=-1) else: raise ValueError(f\"`use_real_unbind_dim={use_real_unbind_dim}` but should be -1 or -2.\") out = (x.float() * cos + x_rotated.float() * sin).to(x.dtype) return out时间-引导强度-池化文本融合嵌入:
使用CombinedTimestepGuidanceTextProjEmbeddings:
class CombinedTimestepGuidanceTextProjEmbeddings(nn.Module): def __init__(self, embedding_dim, pooled_projection_dim): super().__init__() #生成每个时间步和频率的组合并将其正弦值和余弦值拼接,最终形状为[batch_size,num_channels] self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0) #embedding=inner_dim self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim) self.guidance_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim) self.text_embedder = PixArtAlphaTextProjection(pooled_projection_dim, embedding_dim, act_fn=\"silu\") def forward(self, timestep, guidance, pooled_projection): timesteps_proj = self.time_proj(timestep) timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=pooled_projection.dtype)) guidance_proj = self.time_proj(guidance) guidance_emb = self.guidance_embedder(guidance_proj.to(dtype=pooled_projection.dtype)) time_guidance_emb = timesteps_emb + guidance_emb pooled_projections = self.text_embedder(pooled_projection) conditioning = time_guidance_emb + pooled_projections #形状为[batch_size,num_channels] return conditioningclass Timesteps(nn.Module): def __init__(self, num_channels: int, flip_sin_to_cos: bool, downscale_freq_shift: float, scale: int = 1): super().__init__() self.num_channels = num_channels self.flip_sin_to_cos = flip_sin_to_cos self.downscale_freq_shift = downscale_freq_shift self.scale = scale def forward(self, timesteps): t_emb = get_timestep_embedding( timesteps, self.num_channels, flip_sin_to_cos=self.flip_sin_to_cos, downscale_freq_shift=self.downscale_freq_shift, scale=self.scale, ) return t_embdef get_timestep_embedding( timesteps: torch.Tensor, embedding_dim: int, flip_sin_to_cos: bool = False,#否将嵌入顺序从 sin, cos 翻转为 cos, sin。 downscale_freq_shift: float = 1,#控制维度间频率变化的缩放因子。 scale: float = 1,#应用于嵌入的缩放因子。 max_period: int = 10000,#控制嵌入的最大频率。): assert len(timesteps.shape) == 1, \"Timesteps should be a 1d-array\" half_dim = embedding_dim // 2 exponent = -math.log(max_period) * torch.arange( start=0, end=half_dim, dtype=torch.float32, device=timesteps.device ) exponent = exponent / (half_dim - downscale_freq_shift) emb = torch.exp(exponent) #生成每个时间步和频率的组合:[batch_size, half_dim] emb = timesteps[:, None].float() * emb[None, :] # scale embeddings emb = scale * emb # concat sine and cosine embeddings emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1) # flip sine and cosine embeddings if flip_sin_to_cos: emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1) # zero pad #如果 embedding_dim 是奇数,使用 torch.nn.functional.pad 在第二个维度上补零,以确保输出张量的形状是偶数维度。 if embedding_dim % 2 == 1: emb = torch.nn.functional.pad(emb, (0, 1, 0, 0)) return emb模态融合:
在自注意力层中需要进行模态融合,本模型主要包括文本模态与图像模态,在模态融合前需要进行维度对齐,图像模态由初始的潜在图像[batch_size, num_channels_latents, height, width],经过图像压缩,变为[batch_size, (h/2) * (w /2), in_channels],之后通过一个线性层形状转变为[batch_size, (h/2) * (w /2), inner_dim],其中inner_dim= num_attention_heads * attention_head_dim。
文本模态由形状[batch_size, sequence_length,d_dim]经过一个线性层转变为[batch_size, sequence_length,inner_dim]。
本模型的模态融合具体实现为:先将潜在图像经过映射得到query、key、value,之后调整形状为[batch_size,heads,seq_length,head_dim],同理将文本嵌入映射得到encoder_hidden_states_query_proj、encoder_hidden_states_key_proj、encoder_hidden_states_value_proj,之后调整形状为[batch_size,heads,seq_length,head_dim],最后进行拼接:
query = torch.cat([encoder_hidden_states_query_proj, query], dim=2)key = torch.cat([encoder_hidden_states_key_proj, key], dim=2)value = torch.cat([encoder_hidden_states_value_proj, value], dim=2)之后应用位置嵌入,得到注意力机制的结果,调整形状为[batch_size, seq_length+h//2*w//2, inner_dim],取结果的第一维的前seq_length为encoder_hidden_states,取结果的第一维的后h//2*w//2为hidden_states。
张量形状变化:
模态对齐:潜入图像形状变为[batch_size, (h//2) * (w// 2),inner_dim],融合时间步、引导嵌入、文本池化嵌入变为[batch_size,256],之后变为[batch_size,inner_dim],将高维文本嵌入形状变为[batch_size, sequence_length,inner_dim] ,融合文本id和图像id并进行旋转位置嵌入为[(h/2)*(w/2)+seq_length,16+56+56]。
之后进入19个MMDiT模块循环:
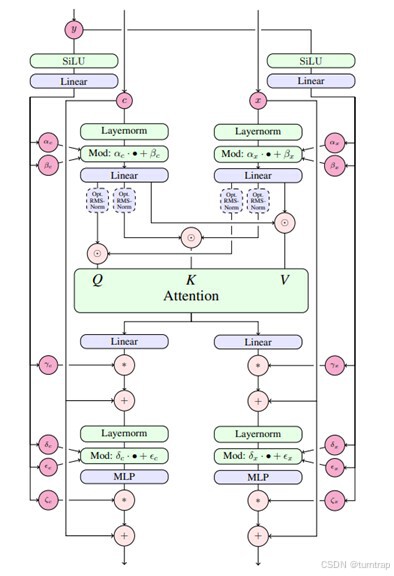
MMDiT模块执行流程
其中,y是时间步-引导嵌入-池化文本嵌入,c是高维文本嵌入,x是潜入图像,具体为:潜在图像hidden_states和高维文本嵌入encoder_hidden_states分别进行(归一化->注意力模块(模态融合)->残差连接->归一化->前馈网络->残差连接),循环后将二者在第二维拼接为hidden_states:[batch_size, (h//2) * (w// 2)+ sequence_length,inner_dim],这是新的hidden_states。
在MMDiT中,需要注意的是自适应归一化AdaLayerNormZero和归一化后利用生成的门控和偏移调整注意力权重:
class AdaLayerNormZero(nn.Module): def __init__(self, embedding_dim: int, num_embeddings: Optional[int] = None, norm_type=\"layer_norm\", bias=True): super().__init__() if num_embeddings is not None: self.emb = CombinedTimestepLabelEmbeddings(num_embeddings, embedding_dim) else: self.emb = None self.silu = nn.SiLU() self.linear = nn.Linear(embedding_dim, 6 * embedding_dim, bias=bias) if norm_type == \"layer_norm\": self.norm = nn.LayerNorm(embedding_dim, elementwise_affine=False, eps=1e-6) elif norm_type == \"fp32_layer_norm\": self.norm = FP32LayerNorm(embedding_dim, elementwise_affine=False, bias=False) else: raise ValueError( f\"Unsupported `norm_type` ({norm_type}) provided. Supported ones are: \'layer_norm\', \'fp32_layer_norm\'.\" ) def forward( self, x: torch.Tensor, timestep: Optional[torch.Tensor] = None, class_labels: Optional[torch.LongTensor] = None, hidden_dtype: Optional[torch.dtype] = None, emb: Optional[torch.Tensor] = None, ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]: if self.emb is not None: emb = self.emb(timestep, class_labels, hidden_dtype=hidden_dtype) emb = self.linear(self.silu(emb)) # 分割成6块:每一块形状【batch_size,embedding_dim(也就是inner_dim)】 #shift_msa:调整多头自注意力输出的偏移量(用法:+) #scale_msa:缩放多头自注意力输出(用法:扩展维度后,*) #gate_msa:控制多头自注意力输出的激活程度(用法:扩展维度后,*) #shift_mlp:用于调整前馈网络(MLP)输出的偏移量 #scale_mlp:用于缩放前馈网络输出 #gate_mlp:用于控制前馈网络输出的激活程度 shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = emb.chunk(6, dim=1) #scale_msa[:, None]形状【batch_size,1,embedding_dim】,*操作在第一维广播(即重复4096次变成【batch_size,4096,inner_dim】) x = self.norm(x) * (1 + scale_msa[:, None]) + shift_msa[:, None] return x, gate_msa, shift_mlp, scale_mlp, gate_mlp在AdaLayerNormZero类中,flux模型需要将输入的emb(即融合的时间步、引导嵌入、文本池化嵌入)和x(即潜在图像)进行处理,创建输出维度为6倍输入维度的线性层用于生成shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp,其功能在代码中均有描述。
在MMDiT模块中,当进行多头自注意力计算后,会生成attn_output和 context_attn_output,之后进行如下操作(二者同理,可看图MMDiT模块执行流程):
#gate_msa表示一个门控信号,用于控制attn_output中的信息流。attn_output = gate_msa.unsqueeze(1) * attn_output#残差连接hidden_states = hidden_states + attn_output#归一化,以后进行放缩与平移norm_hidden_states = self.norm2(hidden_states)norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]#通过前馈网络并使用门控信号控制信息流ff_output = self.ff(norm_hidden_states)ff_output = gate_mlp.unsqueeze(1) * ff_output#残差连接hidden_states = hidden_states + ff_output之后进入38个DiT模块:
hidden_states进行(归一化->线性层->注意力模块->注意力结果与线性层结果第二维拼接[batch_size, (h//2) * (w// 2)+ sequence_length,inner_dim+ inner_dim*4]->线性层->残差连接),输出为hidden_states,形状为[batch_size, (h//2) * (w// 2)+ sequence_length,inner_dim]。
在DiT模块中,与MMDiT模块不同的是,一个是输入只有hidden_states不用进行模态融合;其二是自适应归一化AdaLayerNormZeroSingle只输出x和x, gate_msa,但是自适应归一化的原理和流程基本一致;其三是用了并行注意力层:
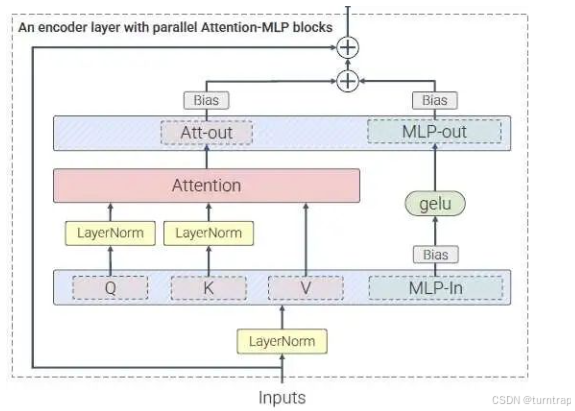
并行自注意层( 来自Stable Diffusion 3「精神续作」FLUX.1 源码深度前瞻解读_flowmatcheulerdiscretescheduler-CSDN博客 )
可以看代码发现注意力层和多层感知机的输入一致,可看作并行,对比MMDiT先进入注意力层后进入多层感知机,是串行的:
#用于后续残差连接residual = hidden_states#自适应归一化norm_hidden_states, gate = self.norm(hidden_states, emb=temb)#输入norm_hidden_states进入多层感知机mlp_hidden_states = self.act_mlp(self.proj_mlp(norm_hidden_states))joint_attention_kwargs = joint_attention_kwargs or {}#输入norm_hidden_states进行多头自主力计算,体现并行性attn_output = self.attn( hidden_states=norm_hidden_states, image_rotary_emb=image_rotary_emb, **joint_attention_kwargs,)#拼接hidden_states = torch.cat([attn_output, mlp_hidden_states], dim=2)gate = gate.unsqueeze(1)#使用门控信号控制信息流hidden_states = gate * self.proj_out(hidden_states)#残差连接hidden_states = residual + hidden_states最后取hidden_states第一维的后(h//2) * (w// 2)部分进行归一化,之后经过线性层作为本模块的输出noise_pred:[batch_size,(h//2) * (w// 2),patch_size * patch_size * out_channels](与一开始潜在图像hidden_states形状完全一致)
去噪循环:先进入FluxTransformer2Dmodel变换器获得noise_pred,之后根据调度器的step方法更新潜在图像latents。
2.5 AutoencoderKL:
{
\"_class_name\": \"AutoencoderKL\",
\"_diffusers_version\": \"0.30.0.dev0\",
\"_name_or_path\": \"../checkpoints/flux-dev\",
\"act_fn\": \"silu\",
\"block_out_channels\": [(每个编码块的输出通道)
128,
256,
512,
512
],
\"down_block_types\": [
\"DownEncoderBlock2D\",
\"DownEncoderBlock2D\",
\"DownEncoderBlock2D\",
\"DownEncoderBlock2D\"
],
\"force_upcast\": true,
\"in_channels\": 3,
\"latent_channels\": 16,(潜在空间特征维度)
\"latents_mean\": null,
\"latents_std\": null,
\"layers_per_block\": 2,
\"mid_block_add_attention\": true,
\"norm_num_groups\": 32,
\"out_channels\": 3,(输出通道)
\"sample_size\": 1024,(输出尺寸)
\"scaling_factor\": 0.3611,
\"shift_factor\": 0.1159,
\"up_block_types\": [
\"UpDecoderBlock2D\",
\"UpDecoderBlock2D\",
\"UpDecoderBlock2D\",
\"UpDecoderBlock2D\"
],
\"use_post_quant_conv\": false,
\"use_quant_conv\": false
}
本模块是将经过去噪生成的潜在图像进行解码,得到生成的图像表示。
首先需要将得到的潜在图像latents解压缩,这时的形状为[batch_size, num_channels_latents, h/ vae_scale_factor , w/vae_scale_factor]
def _unpack_latents(latents, height, width, vae_scale_factor): #vae_scale_factor:用于调整潜在图像分辨率的因子 #num_patches:被分割的块数 batch_size, num_patches, channels = latents.shape height = height // vae_scale_factor width = width // vae_scale_factor latents = latents.view(batch_size, height, width, channels // 4, 2, 2) #新形状:[batch_size, num_channels_latents, height, 2 , width, 2 ] latents = latents.permute(0, 3, 1, 4, 2, 5) latents = latents.reshape(batch_size, channels // (2 * 2), height * 2, width * 2) return latents之后根据配置的调节因子对潜在图像放缩和平移,然后调用vae的decode方法解码。
使用的类为:
class Decoder(nn.Module): def __init__( self, ch: int,# 解码器中的初始通道数为 128 out_ch: int,# 输出图像的通道数为 3 ch_mult: list[int],# 通道的倍增系数表,定义不同分辨率层的通道数扩展情况 num_res_blocks: int,# 每个分辨率层包含两个残差块,用于特征提取 in_channels: int,# 输入的图像通道数为 3 resolution: int,# 输入图像的目标分辨率 z_channels: int,#输入图像的通道数 ): super().__init__() self.ch = ch self.num_resolutions = len(ch_mult) self.num_res_blocks = num_res_blocks self.resolution = resolution self.in_channels = in_channels self.ffactor = 2 ** (self.num_resolutions - 1) # compute in_ch_mult, block_in and curr_res at lowest res block_in = ch * ch_mult[self.num_resolutions - 1] curr_res = resolution // 2 ** (self.num_resolutions - 1) self.z_shape = (1, z_channels, curr_res, curr_res) # 卷积 self.conv_in = nn.Conv2d(z_channels, block_in, kernel_size=3, stride=1, padding=1) # 中间层 self.mid = nn.Module() self.mid.block_1 = ResnetBlock(in_channels=block_in, out_channels=block_in) self.mid.attn_1 = AttnBlock(block_in) self.mid.block_2 = ResnetBlock(in_channels=block_in, out_channels=block_in) #上采样 self.up = nn.ModuleList() for i_level in reversed(range(self.num_resolutions)): block = nn.ModuleList() attn = nn.ModuleList() block_out = ch * ch_mult[i_level]# #依次为512,512,256,128 for _ in range(self.num_res_blocks + 1): block.append(ResnetBlock(in_channels=block_in, out_channels=block_out)) block_in = block_out up = nn.Module() up.block = block up.attn = attn if i_level != 0: up.upsample = Upsample(block_in)#除最顶层外h与w倍增 curr_res = curr_res * 2 self.up.insert(0, up) # 将该层插入到上采样模块的第一层 # end self.norm_out = nn.GroupNorm(num_groups=32, num_channels=block_in, eps=1e-6, affine=True) self.conv_out = nn.Conv2d(block_in, out_ch, kernel_size=3, stride=1, padding=1) def forward(self, z: Tensor) -> Tensor: # z to block_in h = self.conv_in(z) # middle h = self.mid.block_1(h) h = self.mid.attn_1(h) h = self.mid.block_2(h) # upsampling for i_level in reversed(range(self.num_resolutions)): for i_block in range(self.num_res_blocks + 1): h = self.up[i_level].block[i_block](h) if len(self.up[i_level].attn) > 0: h = self.up[i_level].attn[i_block](h) if i_level != 0: h = self.up[i_level].upsample(h) # end h = self.norm_out(h) h = swish(h) h = self.conv_out(h) return h给定参数为:
ae_params=AutoEncoderParams( resolution=256, in_channels=3, ch=128, out_ch=3, ch_mult=[1, 2, 4, 4], num_res_blocks=2, z_channels=16, scale_factor=0.3611, shift_factor=0.1159,)输入的潜在图像z形状为[batch_size, num_channels_latents, h/ vae_scale_factor , w/vae_scale_factor]:[1,16,128,128]
首先进行卷积操作:conv_in将z从【1, 16, 128, 128】映射到【1, 512, 128, 128】。这是通过一个卷积层(nn.Conv2d(z_channels, block_in, kernel_size=3, stride=1, padding=1))实现的,其中z_channels = 16,block_in = 512。输出形状: 【1, 512, 128, 128】。
之后经过中间层,中间层包含两个ResnetBlock和一个注意力层,经过处理形状不变:【1, 512, 128, 128】。
最后是上采样层,一共有四层,每层有3个ResnetBlock和一个注意力层,除了上采样层的第一层(最顶层)外,都有一个上采样模块:
class Upsample(nn.Module): def __init__(self, in_channels: int): super().__init__() self.conv = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1) def forward(self, x: Tensor): x = nn.functional.interpolate(x, scale_factor=2.0, mode=\"nearest\") x = self.conv(x) return x在上采样层的潜在图像形状变化为:
第1层(i_level = 3,最低分辨率层)
输入形状: 【1, 512, 128, 128】。该层有3个ResnetBlock:
第一个ResnetBlock:输入为【1, 512, 128, 128】,输出为【1, 512, 128, 128】。
第二个ResnetBlock:输入为【1, 512, 128, 128】,输出为【1, 512, 128, 128】。
第三个ResnetBlock:输入为【1, 512, 128, 128】,输出为【1, 512, 128, 128】。
上采样操作:将分辨率从128×128扩大到256×256。
输出形状: 【1, 512, 256, 256】。
第2层(i_level = 2)
输入形状: 【1, 512, 256, 256】。该层有3个ResnetBlock:
第一个ResnetBlock:输入为【1, 512, 256, 256】,输出为【1, 512, 256, 256】。
第二个ResnetBlock:输入为【1, 512, 256, 256】,输出为【1, 512, 256, 256】。
第三个ResnetBlock:输入为【1, 512, 256, 256】,输出为【1, 512, 256, 256】。
上采样操作:将分辨率从256×256上采样到512×512。
输出形状: 【1, 512, 512, 512】。
第3层(i_level = 1)
输入形状: 【1, 512, 512, 512】。该层有3个ResnetBlock:
第一个ResnetBlock:输入为【1, 512, 512, 512】,输出为【1, 256, 512, 512】。
第二个ResnetBlock:输入为【1, 256, 512, 512】,输出为【1,256, 512, 512】。
第三个ResnetBlock:输入为【1, 256, 512, 512】,输出为【1, 256, 512, 512】。
上采样操作:将分辨率从512×512上采样到1024×1024。
输出形状: 【1, 256, 1024, 1024】。
第4层(i_level = 0,最高分辨率层)
输入形状: 【1, 128, 1024, 1024】。该层有3个ResnetBlock:
第一个ResnetBlock:输入为【1, 256, 1024, 1024】,输出为【1, 128, 1024, 1024】。
第二个ResnetBlock:输入为【1, 128, 1024, 1024】,输出为【1, 128, 1024, 1024】。
第三个ResnetBlock:输入为【1, 128, 1024, 1024】,输出为【1, 128, 1024, 1024】。
不进行上采样,因为分辨率已经是目标大小。
输出形状: 【1, 128, 1024, 1024】。
最后再进行卷积操作,将z从【1, 128, 1024, 1024】映射到【1,3, 1024, 1024】。
在解码中用到的ResnetBlock如下,它用于在神经网络中引入跳跃连接使得网络能够更容易地进行梯度传播,
class ResnetBlock(nn.Module): def __init__(self, in_channels: int, out_channels: int): super().__init__() self.in_channels = in_channels out_channels = in_channels if out_channels is None else out_channels self.out_channels = out_channels #组归一,不依赖于批量大小,因此适合较小批次或动态批次大小的训练 self.norm1 = nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True) self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1) self.norm2 = nn.GroupNorm(num_groups=32, num_channels=out_channels, eps=1e-6, affine=True) self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1) if self.in_channels != self.out_channels: self.nin_shortcut = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0) def forward(self, x): h = x h = self.norm1(h) h = swish(h) h = self.conv1(h) h = self.norm2(h) h = swish(h) h = self.conv2(h) #当输入输出通道数不一致时,通过该卷积层调整通道数使其一致,方便残差连接 if self.in_channels != self.out_channels: x = self.nin_shortcut(x) return x + h完成解码以后,利用vae的图像生成方法将图像表示(形状【1,3, 1024, 1024】)转化为PIL图像。
首先将图像表示由张量类型变为numpy数组,之后将图像的像素值从[0, 1]范围(对应于浮点型图像)转换到[0, 255]范围(对应于uint8类型的图像),然后取整为整数类型(uint8)。随后调用Image库的fromarray方法传入图像表示,得到一个图像对象,即为最后的结果:一个分辨率为1024x1024的RGB图像。
3.示例代码:
import torchfrom diffusers import FluxPipelinepipe = FluxPipeline.from_pretrained(\"black-forest-labs/FLUX.1-dev\", torch_dtype=torch.bfloat16)pipe.enable_model_cpu_offload() #save some VRAM by offloading the model to CPU. Remove this if you have enough GPU powerprompt = \"A boy with short hair, glasses, 1.8 meters tall, wearing a light green short down jacket, blue jeans, beige Martin boots, and a gray shirt inside the down jacket\"image = pipe( prompt, height=1024, width=1024, guidance_scale=3.5, num_inference_steps=50, max_sequence_length=512, generator=torch.Generator(\"cpu\").manual_seed(0)).images[0]image.save(\"flux-dev.png\")运行结果:


