安装并配置Hadoop HA集群环境
1、Hadoop介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
任务主要内容:下载安装Hadoop包,配置环境变量,配置Hadoop集群,以及HDFS HA配置
2、Hadoop-HA集群搭建过程:
- 解压Hadoop安装包
- 创建Hadoop数据存放的目录
- 配置Hadoop环境变量
- 修改Hadoop配置文件
- 配置core-site.xml文件
- 配置hdfs-site.xml文件
- 配置mapred-site.xml文件
- 配置yarn-site.xml文件
- 配置hadoop-env.sh文件的JAVA_HOME变量
- 配置slaves文件
- 将配置好的Hadoop复制到其他节点对应位置上
- 启动测试Hadoop集群
- 确保slave1、slave2和slave3都已经启动zookeeper集群
- 格式化ZKFC(在master1上执行)
- 格式化后验证,在某个Zookeeper上执行zkCli.sh,这里我们在slave1节点上执行
- 在Zookeeper查看HA集群名称

- 启动Journal集群(分别在slave1、slave2、slave3上执行)
- 格式化集群上的一个NameNode(从master1和master2上任选一个即可,这里我们在master1执行)
- 启动集群中master1上的NameNode
- 将master1上的NameNode数据同步到master2上的NameNode,在master2上执行
- 在master1上关闭dfs进程,重新启动
- 启动Yarn,在master1上执行
- 全部启动完后分别在master1、master2、slave1、slave2、slave3上执行jps是可以看到如下进程:
- 测试HA的高可用性
- 启动后master1的namenode(浏览器中输入master1:50070)和master2(浏览器中输入master2:50070)的namenode如下所示:
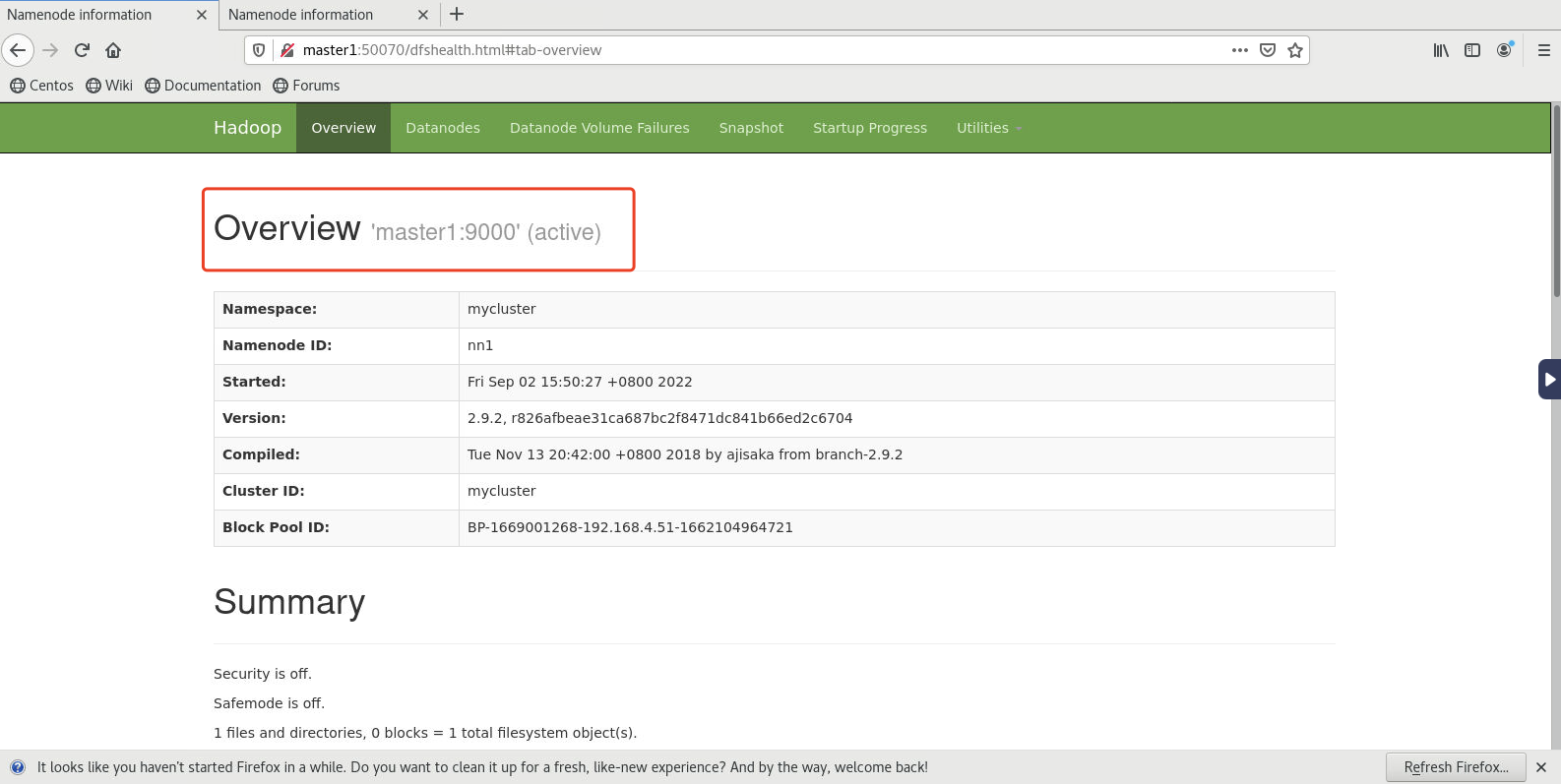
- 此时在状态显示为active的节点上(当前为master1)执行命令关闭namenode
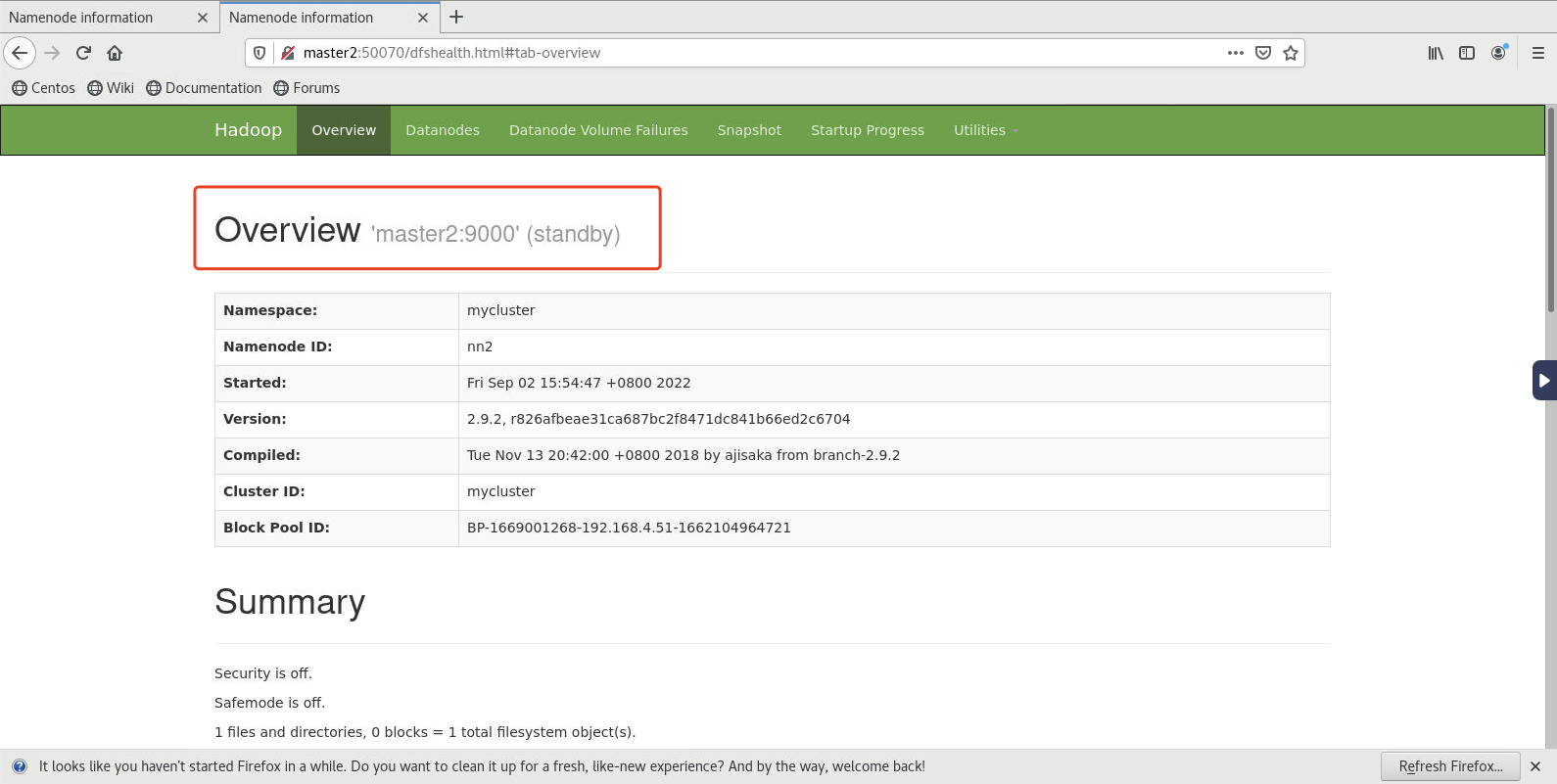
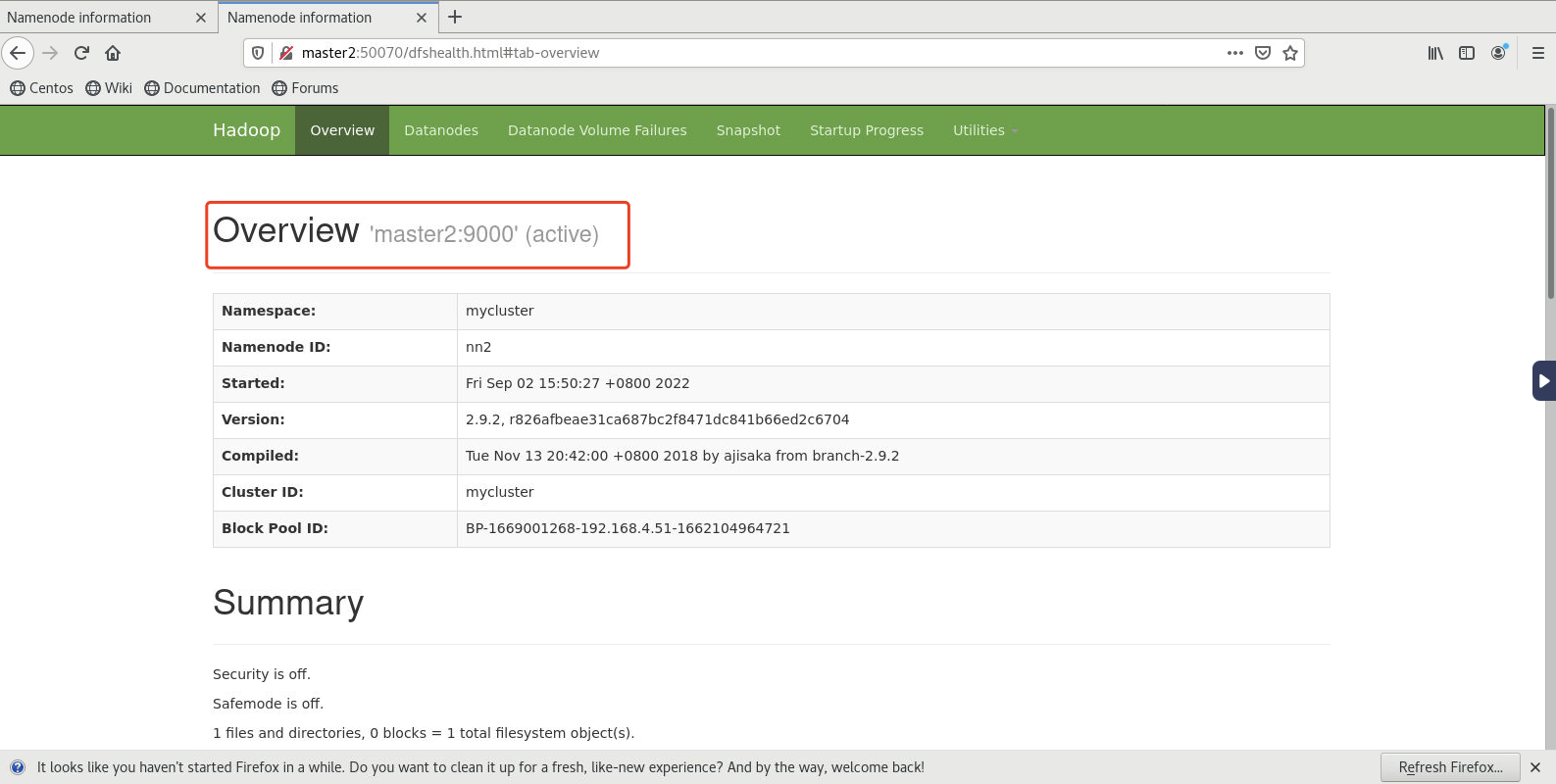
- 查看standby节点上的(当前为master2)namenode,发现自动切换为active
任务实现
1、安装配置Hadoop 2.9.2
在master1服务器解压并配置完成后,再复制到master2及其他的slave服务器。
- 输入【cd /home/software】命令转到/home/software目录下;
- 输入【tar -xzf hadoop-2.9.2.tar.gz -C /home】命令解压;
2、配置Hadoop环境变量
- 修改系统配置文件
[root@master1 software]# vim /etc/profile- 添加如下内容:
export HADOOP_HOME=/home/hadoop-2.9.2export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin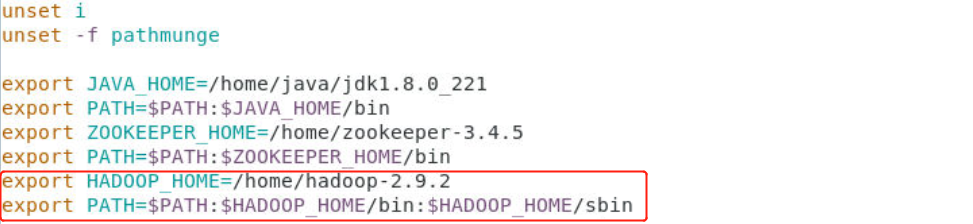
- 使用source 使配置文件生效,命令如下:
[root@master1 software]# source /etc/profile3、配置Hadoop
- 进入Hadoop配置文件夹
[root@master1 software]# cd /home/hadoop-2.9.2/etc/hadoop- 接下来需要配置6个配置文件,分别是
1)core-site.xml
2)hdfs-site.xml
3)mapred-site.xml
4)yarn-site.xml
5)hadoop-env.sh
6)slaves
- 配置core-site.xml文件:
[root@master1 hadoop]# vim core-site.xml- 在之间配置内容如下:
fs.defaultFS hdfs://mycluster hadoop.tmp.dir /home/hadoop/tmp io.file.buffer.size 131702 fs.trash.interval 1440 ha.zookeeper.quorum slave1:2181,slave2:2181,slave3:2181 - 配置 hdfs-site.xml 文件:
[root@master1 hadoop]# vim hdfs-site.xml- 在之间配置内容如下:
dfs.namenode.name.dir /home/hadoop/hdfs/name dfs.datanode.data.dir /home/hadoop/hdfs/data dfs.replication 3 dfs.webhdfs.enabled true dfs.permissions.enabled false dfs.nameservices mycluster dfs.ha.namenodes.mycluster nn1,nn2 dfs.namenode.rpc-address.mycluster.nn1 master1:9000 dfs.namenode.rpc-address.mycluster.nn2 master2:9000 dfs.namenode.http-address.mycluster.nn1 master1:50070 dfs.namenode.http-address.mycluster.nn2 master2:50070 dfs.namenode.shared.edits.dir qjournal://slave1:8485;slave2:8485;slave3:8485/mycluster dfs.journalnode.edits.dir /home/hadoop/data/journal dfs.client.failover.proxy.provider.mycluster org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_rsa dfs.ha.automatic-failover.enabled true - 配置 mapred-site.xml 文件。
首先,输入【mv mapred-site.xml.template mapred-site.xml】命令,从mapred-site.xml.template模板文件复制一个mapred-site.xml文件。
- 配置/home/hadoop-2.9.2/etc/hadoop目录下的mapred-site.xml:
[root@master1 hadoop]# vim mapred-site.xml- 在之间配置内容如下:
mapreduce.framework.name yarn dfs.permissions false mapreduce.jobhistory.address master1:10020 mapreduce.jobhistory.webapp.address master1:19888 mapreduce.job.ubertask.enable true mapreduce.job.ubertask.maxmaps 9 mapreduce.job.ubertask.maxreduces 1 - 配置yarn-site.xml文件,该文件存放在/home/hadoop/hadoop-2.9.2/etc/hadoop目录下
[root@master1 hadoop]# vim yarn-site.xml- 在之间配置内容如下:
yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.auxservices.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.ha.enabled true yarn.resourcemanager.ha.automatic-failover.enabledtrue yarn.resourcemanager.cluster-id yarncluster yarn.resourcemanager.ha.rm-ids rm1,rm2 yarn.resourcemanager.hostname.rm1 master1 yarn.resourcemanager.hostname.rm2 master2 yarn.resourcemanager.webapp.address.rm1 master1:8088 yarn.resourcemanager.webapp.address.rm2 master2:8088 yarn.resourcemanager.zk-address slave1:2181,slave2:2181,slave3:2181 yarn.resourcemanager.zk-state-store.parent-path /rmstore yarn.resourcemanager.recovery.enabled true yarn.resourcemanager.store.classorg.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore yarn.nodemanager.recovery.enabled true yarn.nodemanager.address 0.0.0.0:45454 - 配置hadoop-env.sh,配置JAVA_HOME变量。如果不设置,无法正常启动集群。
输入【vim hadoop-env.sh】打开准备修改的配置文件hadoop-env.sh,加入JAVA_HOME环境变量,原始配置文件内容如下:
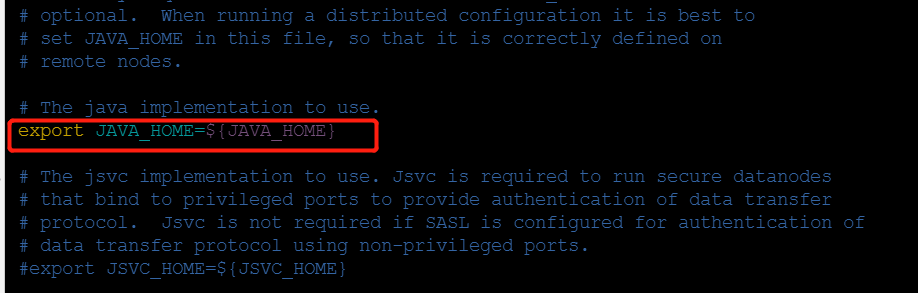
- 修改后如下:
export JAVA_HOME=/home/java/jdk1.8.0_221- 配置slaves文件,该文件存在在/home//hadoop-2.9.2/etc/hadoop目录下,输入如下命令:
[root@master1 hadoop]# vim slaves- 删除默认的localhost,增加3个从节点的IP地址或host主机名。
slave1slave2slave3- 将配置好的Hadoop复制到其他节点对应位置上,通过scp命令发送。
[root@master1 hadoop]# scp -rq /home/hadoop-2.9.2/ master2:/home/[root@master1 hadoop]# scp -rq /home/hadoop-2.9.2/ slave1:/home/[root@master1 hadoop]# scp -rq /home/hadoop-2.9.2/ slave2:/home/[root@master1 hadoop]# scp -rq /home/hadoop-2.9.2/ slave3:/home/- 发生master1的/etc/profile文件到其他节点中
[root@master1 hadoop]# scp /etc/profile master2:/etc/[root@master1 hadoop]# scp /etc/profile slave1:/etc/[root@master1 hadoop]# scp /etc/profile slave2:/etc/[root@master1 hadoop]# scp /etc/profile slave3:/etc/- 发送完成后,在所有节点使用【source /etc/profile】使文件配置生效。
4、启动Hadoop集群并测试。
- 确保slave1、slave2和slave3都已经启动zookeeper集群(zkServer.sh start)
- 格式化ZKFC(在master1上执行)
[root@master1 hadoop]# hdfs zkfc -formatZK- 格式化后验证,在某个Zookeeper上执行zkCli.sh,这里我们在slave1节点上执行
[root@slave1 ~]# zkCli.sh- 在执行【ls /】 会出现下图中红色部分,则表示格式化成功

- 输入下面命令,查看我们配置的HA集群名称
[root@slave1 ~]# ls /hadoop-ha
- 然后输入【quit】退出Zookeeper客户端
- 启动Journal集群(分别在slave1、slave2、slave3上执行)
# hadoop-daemon.sh start journalnode- 格式化集群上的一个NameNode(从master1和master2上任选一个即可,这里我们在master1执行)
[root@master1 ~]# hdfs namenode -format -clusterId mycluster- 启动集群中master1上的NameNode
[root@master1 ~]# hadoop-daemon.sh start namenode- 将master1上的NameNode数据同步到master2上的NameNode,在master2上执行
[root@master2 ~]# hdfs namenode -bootstrapStandby- 在master1上关闭dfs进程,重新启动
[root@master1 ~]# stop-dfs.sh[root@master1 ~]# start-dfs.sh- 启动Yarn,在master1上执行
[root@master1 ~]# start-yarn.sh- 全部启动完后分别在master1、master2、slave1、slave2、slave3上执行jps是可以看到下面这些进程的
- 输入【jps】命令,可以查看启动的守护进程,分别为:
5、测试HA的高可用性
- 启动后master1的namenode(浏览器中输入master1:50070)和master2(浏览器中输入master2:50070)的namenode如下所示:
- 此时在状态显示为active的节点上(当前为master1)执行如下命令关闭namenode
[root@master1 ~]# hadoop-daemon.sh stop namenode- 再次查看standby节点上的(当前为master2)namenode,发现自动切换为active
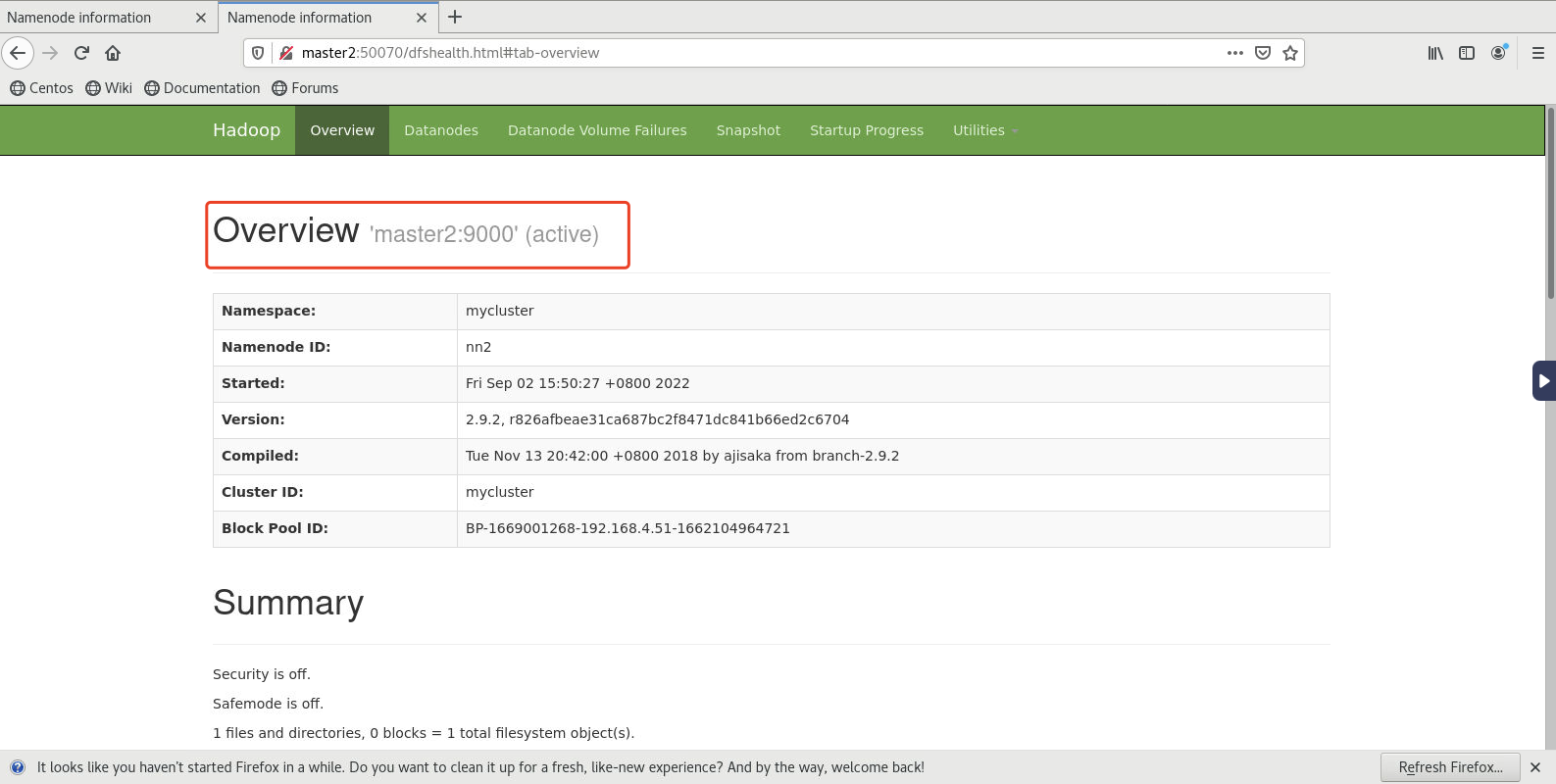
备注:测试完成记得重新开启master1的namenode。
在master1中启动namenode
[root@master1 ~]# hadoop-daemon.sh start namenode
