重生学AI第二十集(大结局):完善模型以及学习总结
1.代码优化
这是我们学习容器的时候写的代码
import torch.optimimport torchvisionfrom torch import nnfrom torch.utils.data import DataLoader# CIFAR-10 数据集加载datasets = torchvision.datasets.CIFAR10(root=\'../dataset\', train=False, download=True, transform=torchvision.transforms.ToTensor())my_dl = DataLoader(datasets, batch_size=64)# 自定义神经网络模型class MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.model = nn.Sequential( # 三层卷积和池化 nn.Conv2d(3,32,5,padding=2), nn.MaxPool2d(2), nn.Conv2d(32,32,5,padding=2), nn.MaxPool2d(2), nn.Conv2d(32,64,5,padding=2), nn.MaxPool2d(2), # 展平层 nn.Flatten(), # 线性层 nn.Linear(1024, 64), nn.Linear(64, 10) ) def forward(self, x): x = self.model(x) return x# 模型实例化model = MyModel()# 实例化损失函数(交叉熵损失函数)loss1 = nn.CrossEntropyLoss()# 实例化优化器my_optimizer = torch.optim.SGD(model.parameters(), lr=0.01)for epoch in range(20): total_loss = 0.0 for data in my_dl: imgs, targets = data # 通过模型 计算类别得分 outputs = model(imgs) #损失函数将类别得分转换为概率,并与实际结果进行对比,计算损失值 loss_result = loss1(outputs, targets) #将梯度清零 以免被上一次的梯度影响到 my_optimizer.zero_grad() #反向传播 计算梯度 loss_result.backward() #调用优化器 根据梯度更新参数 my_optimizer.step() total_loss += loss_result print(total_loss)1.1 修改数据集
一个完整的模型是需要测试数据集和训练数据集的,训练数据集是用来训练模型的,测试数据集是测试模型学习成果,就像我们现实生活中的考试一样
# CIFAR-10 数据集加载train_datasets = torchvision.datasets.CIFAR10(root=\'../dataset\', train=True, download=True, transform=torchvision.transforms.ToTensor())test_datasets = torchvision.datasets.CIFAR10(root=\'../dataset\', train=False, download=True, transform=torchvision.transforms.ToTensor())#dataloadertrain_dataloader = DataLoader(train_datasets, batch_size=64)test_dataloader = DataLoader(test_datasets, batch_size=64)1.2 修改训练步骤
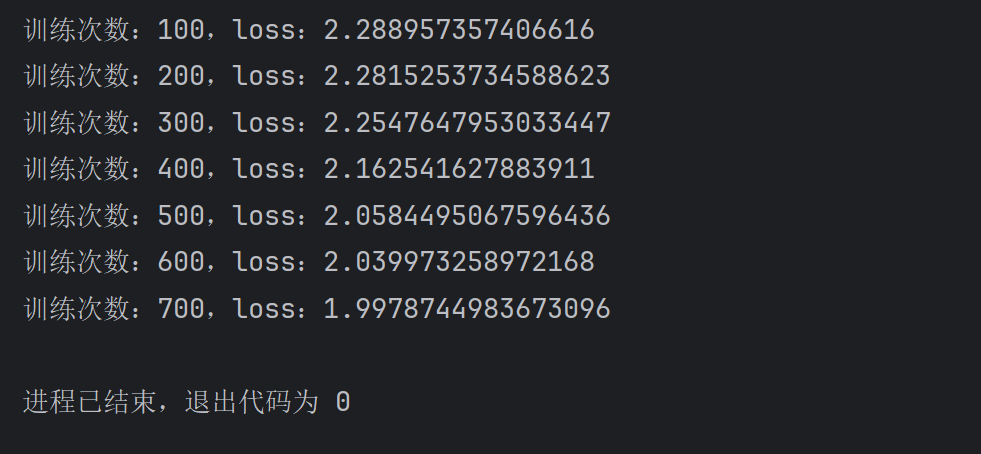
把原来的训练过程修改了一下,并新增了两个变量用来记录训练步数,并且为了方便运行,暂时把运行轮次改为了1
#初始化两个步数total_train_step = 0total_test_step = 0# 训练过程for epoch in range(1): # 开始训练 model.train() for data in train_dataloader: imgs, targets = data # 通过模型 计算类别得分 outputs = model(imgs) #损失函数将类别得分转换为概率,并与实际结果进行对比,计算损失值 loss_result = loss1(outputs, targets) #优化模型 my_optimizer.zero_grad() loss_result.backward() my_optimizer.step() # 每次训练完毕 步数加1 total_train_step += 1 # 每训练100次打印步数和loss值 if total_train_step % 100 == 0: print(\"训练次数:{},loss:{}\".format(total_train_step, loss_result.item()))运行一下看看效果
1.3 增加测试代码
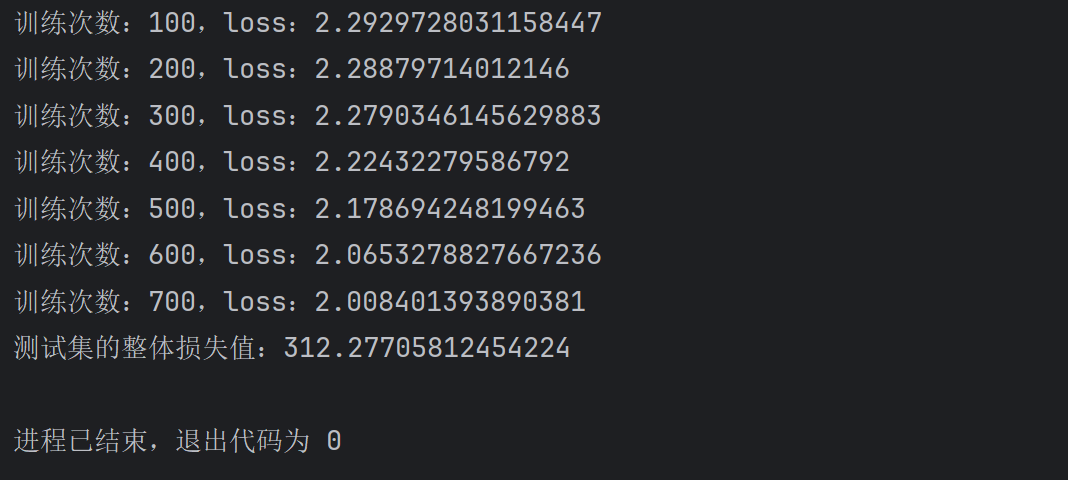
接下来就要增加测试过程,测试过程和训练过程都在训练轮次的循环内,每一轮训练完成后就测试一下这个模型在测试集的表现
# 训练过程for epoch in range(1): # 开始训练 model.train() for data in train_dataloader: imgs, targets = data # 通过模型 计算类别得分 outputs = model(imgs) #损失函数将类别得分转换为概率,并与实际结果进行对比,计算损失值 loss_result = loss1(outputs, targets) #优化模型 my_optimizer.zero_grad() loss_result.backward() my_optimizer.step() # 每次训练完毕 步数加1 total_train_step += 1 # 每训练100次打印步数和loss值 if total_train_step % 100 == 0: print(\"训练次数:{},loss:{}\".format(total_train_step, loss_result.item())) # 开始测试 model.eval() total_test_loss = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data outputs = model(imgs) loss_result = loss1(outputs, targets) total_test_loss += loss_result.item() print(\"测试集的整体损失值:{}\".format(total_test_loss)) total_test_step += 1运行代码
1.4 可视化
接下来,我们加入可视化,让他在tensorboard上显示出来
...# 初始化写入器writer = SummaryWriter(\"../logs\")... print(\"训练次数:{},loss:{}\".format(total_train_step, loss_result.item())) writer.add_scalar(\"train_loss\", loss_result.item(), total_train_step) ... print(\"测试集的整体损失值:{}\".format(total_test_loss)) writer.add_scalar(\"test_loss\", total_test_loss, total_test_step) total_test_step += 1...writer.close()再次运行代码,然后打开终端输入指令

打开网址后是这样的
1.5 统计正确率
正确率要用到torch.argmax(input, dim)这个函数,他的作用是从一个向量或多维张量中选择最大值所在的索引。
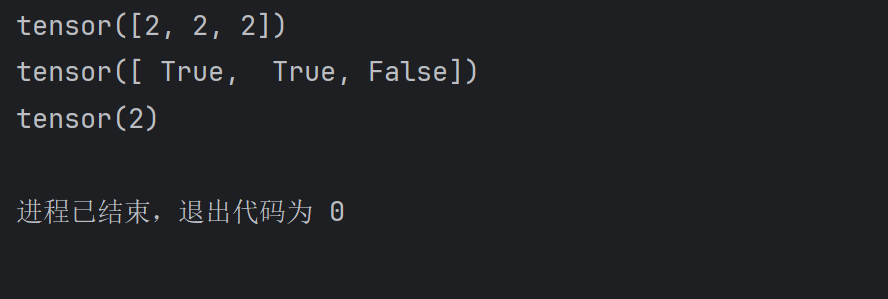
我们通过代码 outputs = model(imgs) 得到的是一个这样的数据
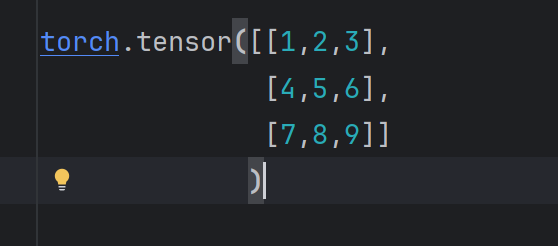
那么,argmax返回的就是【2,2,2】,因为
- 3是列表1中最大的,下标为2;
- 6是列表2中最大的,下标为2;
- 9是列表3中最大的,下标为2;
我们可以测试一下
import torchoutputs = torch.tensor([[1,2,3], [4,5,6], [7,8,9]] )preds = outputs.argmax(1)print(preds)运行结果:

假设列表1、列表2、列表3代表三张图片对于三个分类的预测结果,那么2,2,2就是最终的预测值,代表预测第一张图片是2,第二张图片也是2,第三张也是2,如果这三张图片的真实结果是2,2,1,那么我们就可以求出他们正确的个数,像这样
import torchoutputs = torch.tensor([[1,2,3], [4,5,6], [7,8,9]] )preds = outputs.argmax(1)print(preds)targets = torch.tensor([2,2,1])print(preds == targets)print((preds == targets).sum())运行结果:
代入到我们的训练模型代码中就是这样的
# 开始测试 model.eval() total_test_loss = 0 total_correct = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data outputs = model(imgs) loss_result = loss1(outputs, targets) total_test_loss += loss_result.item() #统计正确的个数 preds = outputs.argmax(1) correct = (preds==targets).sum() total_correct += correct.item() # 计算测试集的准确率 total_accuracy = total_correct/len(test_datasets) print(\"测试集的整体损失值:{}\".format(total_test_loss)) print(\"测试集的整体正确率:{}\".format(total_accuracy)) writer.add_scalar(\"test_loss\", total_test_loss, total_test_step) writer.add_scalar(\"test_accuracy\", total_accuracy, total_test_step) total_test_step += 11.6 保存模型
加入保存模型的代码,让它每训练一轮就保存下来
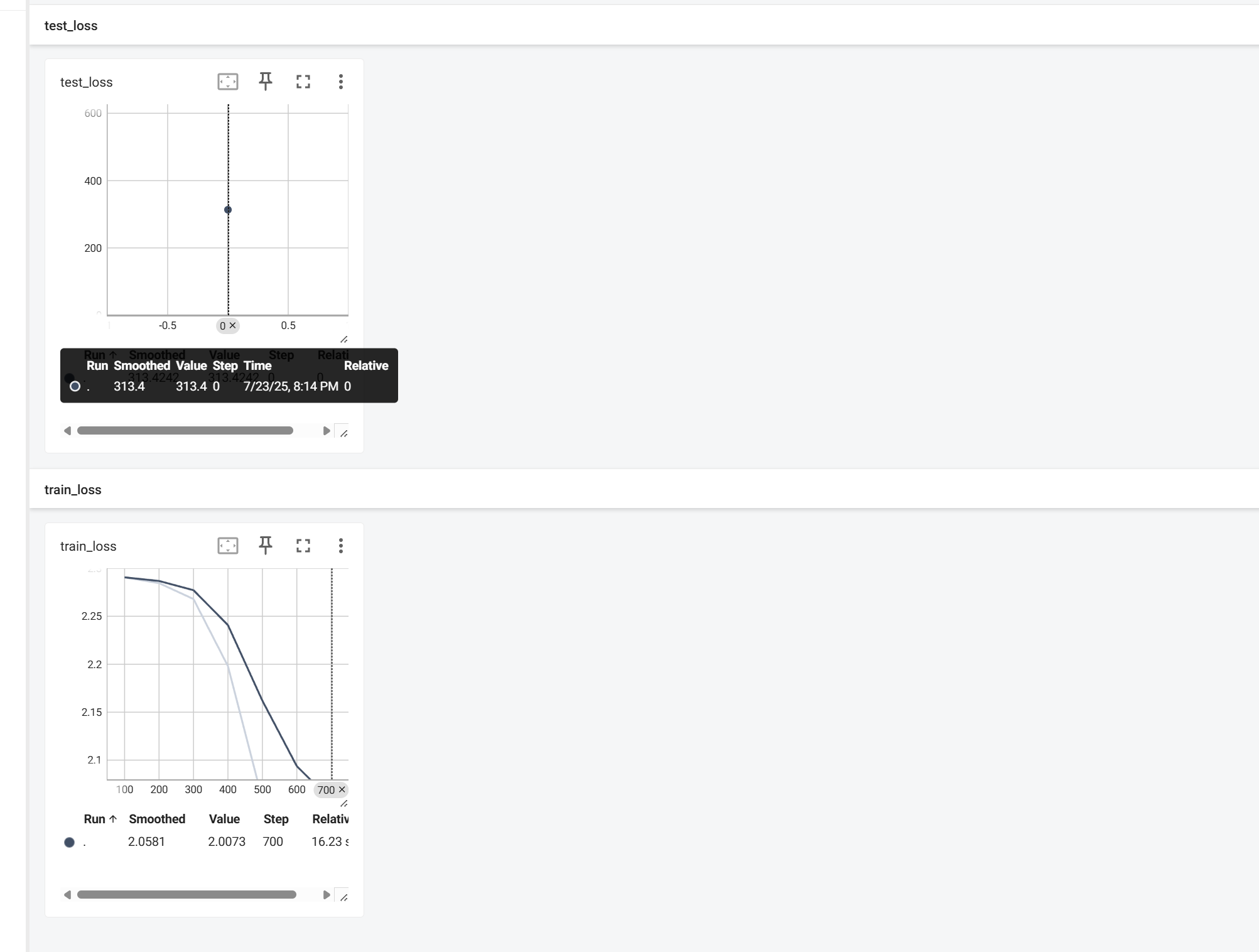
#保存模型 torch.save(model,\"model_{}.pt\".format(epoch))运行看看效果,之前一轮看着效果不太好,我改成3轮了
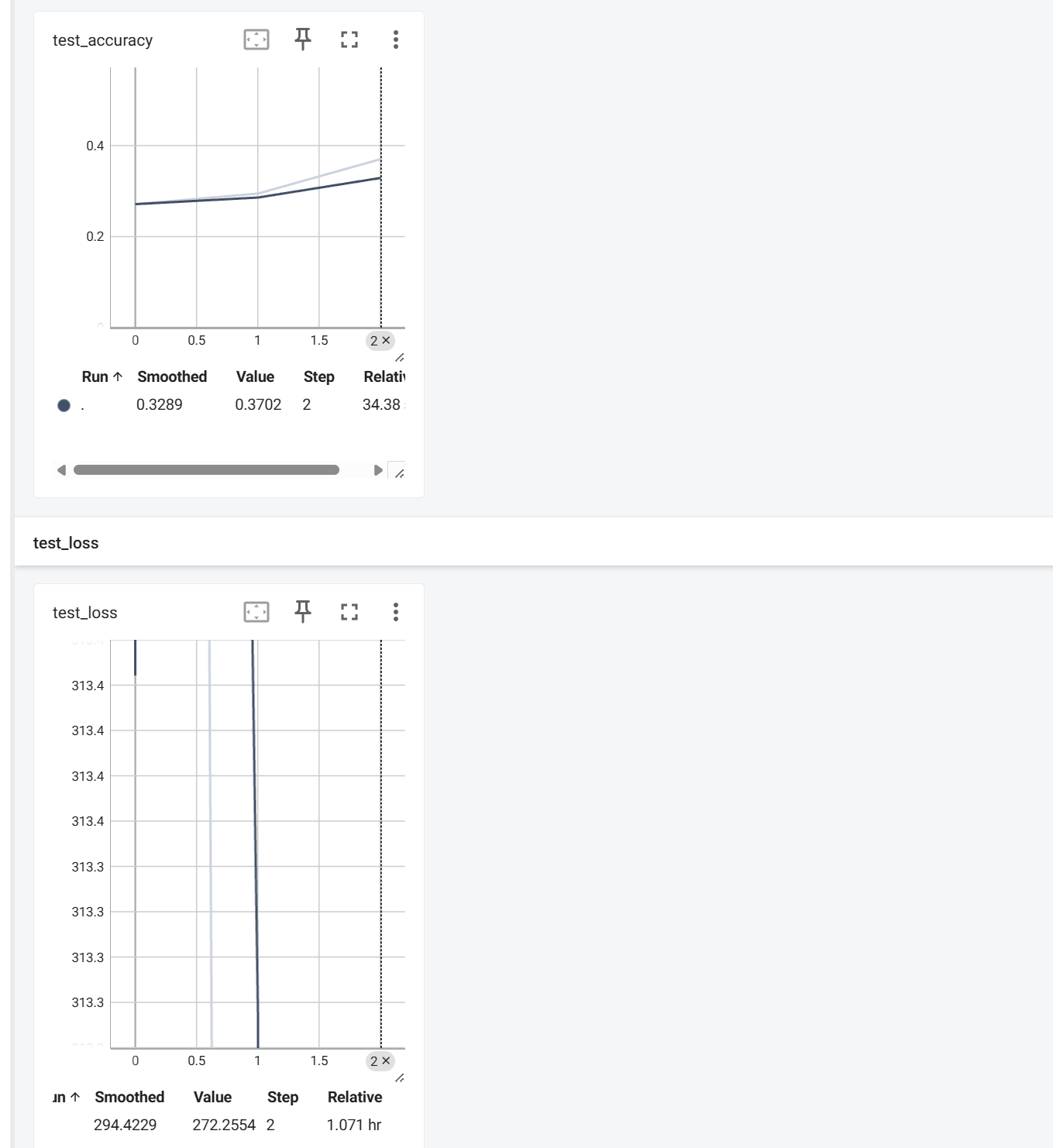
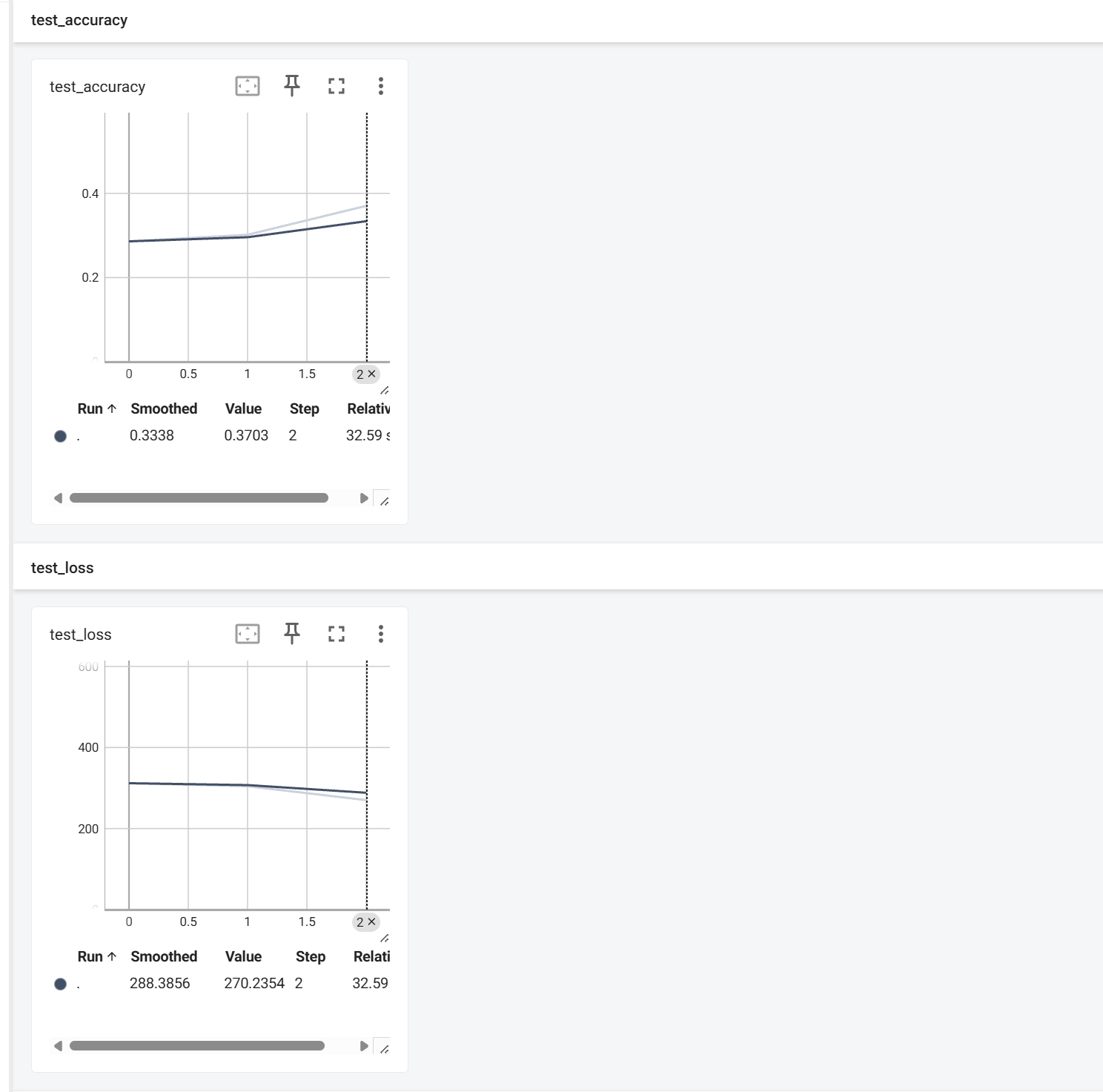
唔。。。这个test_loss看起来很奇怪,于是我把日志文件清空,又重新运行了代码,重启了tensorboard,现在看起来好多了
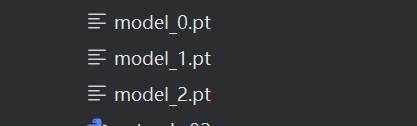
并且模型文件也成功被保存到了项目文件夹中
1.7 GPU加速
GPU加速就是对网络模型、数据、损失函数的计算从CPU转移到GPU上面,因为GPU要比CPU快很多,.to()就是将数据进行设备转移的一个函数。
首先,定义一个device,如果有GPU的话就用GPU,没有就用CPU
...# 定义设备device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")...cuda:0的意思是:如果有多个显卡的话,用第一个GPU,只有一个的话,可以省略掉后面的:0,像这样:device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")
然后将模型、数据、损失函数进行设备转移
...# 模型实例化model = MyModel()model = model.to(device)# 实例化损失函数(交叉熵损失函数)loss1 = nn.CrossEntropyLoss()loss1 = loss1.to(device)...imgs, targets = dataimgs, targets = imgs.to(device), targets.to(device)...最后我们还可以加上时间,来看一下他们的差距
# 训练过程for epoch in range(3): # 开始训练 model.train() start_time = time.time() for data in train_dataloader: imgs, targets = data imgs, targets = imgs.to(device), targets.to(device) # 通过模型 计算类别得分 outputs = model(imgs) #损失函数将类别得分转换为概率,并与实际结果进行对比,计算损失值 loss_result = loss1(outputs, targets) #优化模型 my_optimizer.zero_grad() loss_result.backward() my_optimizer.step() # 每次训练完毕 步数加1 total_train_step += 1 # 每训练100次打印步数和loss值 if total_train_step % 100 == 0: print(\"训练次数:{},loss:{}\".format(total_train_step, loss_result.item())) writer.add_scalar(\"train_loss\", loss_result.item(), total_train_step) end_time = time.time() print(\"训练一轮花费时长:{}\".format(end_time - start_time))直接运行看GPU版本的时长,直接看第一个就好了
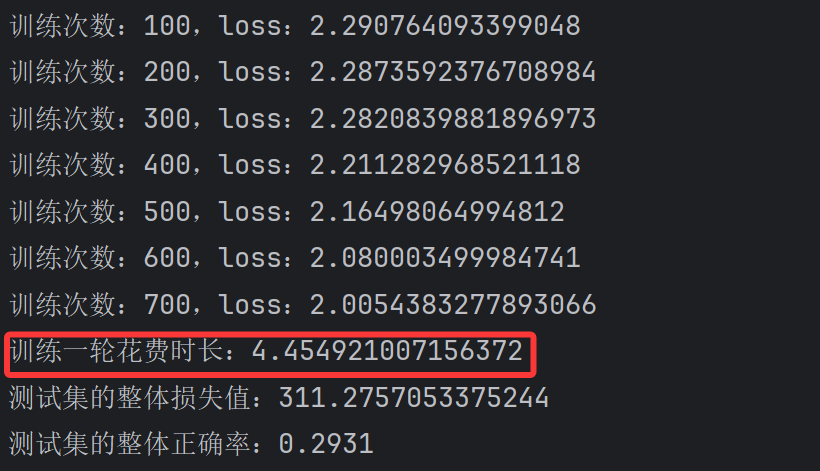
然后把设备那里改成CPU再运行,像这样
# 定义设备device = torch.device(\"cpu\")运行结果:
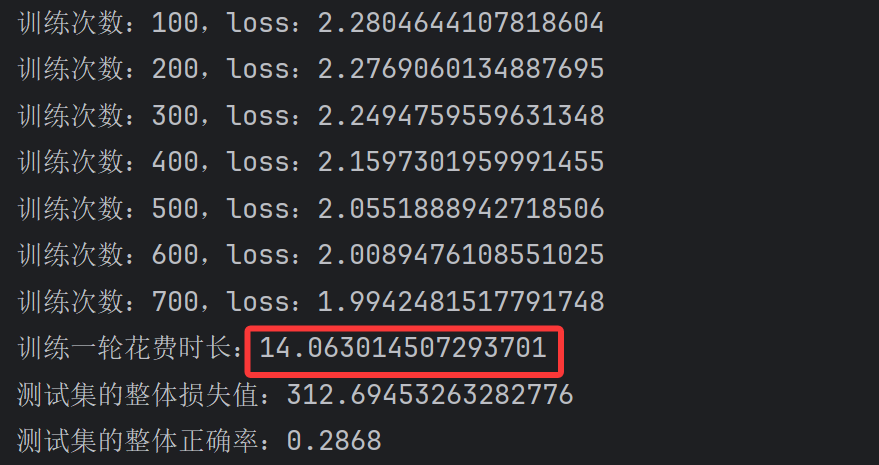
差距就出来了
1.8 完整代码
最后附上完整代码
import timeimport torch.optimimport torchvisionfrom torch import nnfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriter# CIFAR-10 数据集加载train_datasets = torchvision.datasets.CIFAR10(root=\'../dataset\', train=True, download=True, transform=torchvision.transforms.ToTensor())test_datasets = torchvision.datasets.CIFAR10(root=\'../dataset\', train=False, download=True, transform=torchvision.transforms.ToTensor())#dataloadertrain_dataloader = DataLoader(train_datasets, batch_size=64)test_dataloader = DataLoader(test_datasets, batch_size=64)# 初始化写入器writer = SummaryWriter(\"../logs\")# 定义设备device = torch.device(\"cpu\")# device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")# 自定义神经网络模型class MyModel(nn.Module): def __init__(self): super(MyModel, self).__init__() self.model = nn.Sequential( # 三层卷积和池化 nn.Conv2d(3,32,5,padding=2), nn.MaxPool2d(2), nn.Conv2d(32,32,5,padding=2), nn.MaxPool2d(2), nn.Conv2d(32,64,5,padding=2), nn.MaxPool2d(2), # 展平层 nn.Flatten(), # 线性层 nn.Linear(1024, 64), nn.Linear(64, 10) ) def forward(self, x): x = self.model(x) return x# 模型实例化model = MyModel()model = model.to(device)# 实例化损失函数(交叉熵损失函数)loss1 = nn.CrossEntropyLoss()loss1 = loss1.to(device)# 实例化优化器my_optimizer = torch.optim.SGD(model.parameters(), lr=0.01)#初始化两个步数total_train_step = 0total_test_step = 0# 训练过程for epoch in range(3): # 开始训练 model.train() start_time = time.time() for data in train_dataloader: imgs, targets = data imgs, targets = imgs.to(device), targets.to(device) # 通过模型 计算类别得分 outputs = model(imgs) #损失函数将类别得分转换为概率,并与实际结果进行对比,计算损失值 loss_result = loss1(outputs, targets) #优化模型 my_optimizer.zero_grad() loss_result.backward() my_optimizer.step() # 每次训练完毕 步数加1 total_train_step += 1 # 每训练100次打印步数和loss值 if total_train_step % 100 == 0: print(\"训练次数:{},loss:{}\".format(total_train_step, loss_result.item())) writer.add_scalar(\"train_loss\", loss_result.item(), total_train_step) end_time = time.time() print(\"训练一轮花费时长:{}\".format(end_time - start_time)) # 开始测试 model.eval() total_test_loss = 0 total_correct = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data imgs, targets = imgs.to(device), targets.to(device) outputs = model(imgs) loss_result = loss1(outputs, targets) total_test_loss += loss_result.item() #统计正确的个数 preds = outputs.argmax(1) correct = (preds==targets).sum() total_correct += correct.item() # 计算测试集的准确率 total_accuracy = total_correct/len(test_datasets) print(\"测试集的整体损失值:{}\".format(total_test_loss)) print(\"测试集的整体正确率:{}\".format(total_accuracy)) writer.add_scalar(\"test_loss\", total_test_loss, total_test_step) writer.add_scalar(\"test_accuracy\", total_accuracy, total_test_step) total_test_step += 1 #保存模型 torch.save(model,\"model_{}.pt\".format(epoch))writer.close()2. 学习总结
至此,对于人工神经网络的学习可以初步画个句号了,通过这些天的学习,我们学会了
- Conda安装Pytorch 以及环境配置(第一集、第二集)
- Pycharm和Jupyter的安装配置(第三集、第四集、第五集)
- 实现Dataset类来自定义数据集(第六集)
- 使用add_scalar()和add_image()将数据和图片添加到tensorboard中进行可视化(第七集、第八集)
- 通过transforms将图片进行处理的多种方式(第九集、第十集、第十一集)
- 转为张量数据:totensor()
- 归一化:Normalize()
- 修改尺寸(Resize)
- 随机裁剪(RandomCrop)
- 打包的容器(Compose)
- 内置数据集(CIFAR10)以及数据加载器DataLoader(第十二集)
- 如何搭建神经网络以及卷积层Conv2d(第十三集)
- 最大池化层、非线性激活函数、全连接层(线性层)(第十四集、第十五集、第十六集)
- 损失函数、反向传播和优化器(第十七集、第十八集)
- VGG16模型的认识和学习、模型的保存与加载(第十九集)
- 最后对整个模型进行优化和完善(本集)
最后总结一下人工神经网络的实现步骤:
- 准备数据集和数据加载器
- 搭建人工神经网络
- 定义各种网络层并实现前向传播forward()对数据进行处理
- 实例化模型、损失函数和优化器
- 定义训练的轮数,然后再分别定义训练过程和测试过程
- 对代码进行优化,如:进行GPU加速、保存模型等
- 将需要的信息进行输出或者可视化(损失值、正确率等)
学海无涯,前路漫漫,以后学习新知识还会继续分享的,再见


