python中深度学习的算法,如神经网络和卷积神经网络的使用_利用python写深度学习算法
在Python中,有多个深度学习框架可用于实现神经网络和卷积神经网络,如TensorFlow和PyTorch。以下以TensorFlow为例展示简单的神经网络和卷积神经网络的使用。
简单神经网络(全连接神经网络)
1. 安装TensorFlow:如果未安装,可使用 pip install tensorflow 进行安装。
2. 构建并训练简单神经网络:

在这个例子中:
- 加载MNIST手写数字数据集。
- 对数据进行预处理,将图像展平为一维向量并归一化,将标签转换为独热编码。
- 使用 Sequential 模型构建一个简单的全连接神经网络,包含一个隐藏层和一个输出层。
- 编译模型,指定优化器、损失函数和评估指标。
- 训练模型并在测试集上评估。
卷积神经网络(CNN)
1. 构建并训练卷积神经网络:
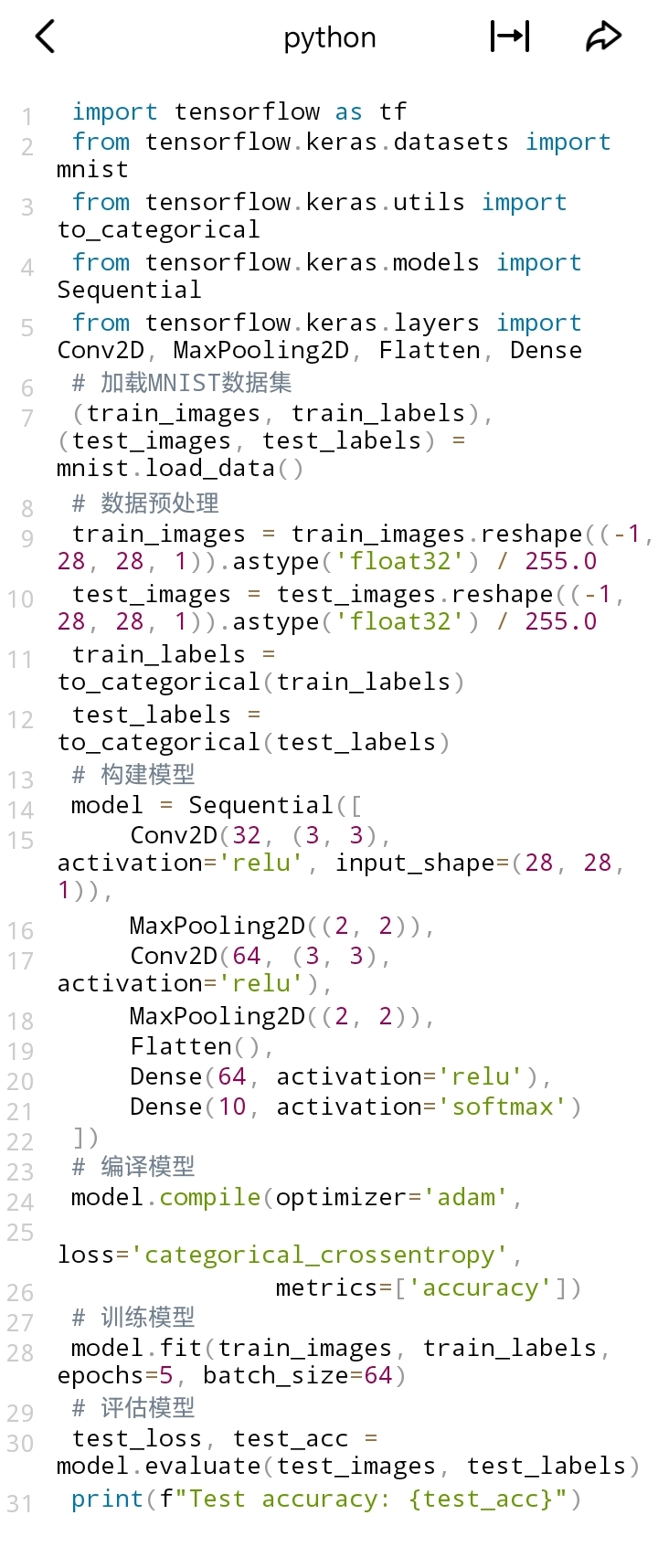
在这个CNN例子中:
- 同样加载MNIST数据集并预处理,但图像保持二维结构并增加通道维度。
- 模型使用 Conv2D 层进行卷积操作, MaxPooling2D 层进行池化操作,以提取图像特征。
- 最后通过 Flatten 层将多维数据展平,再连接全连接层 Dense 进行分类。
- 编译、训练和评估过程与简单神经网络类似。
如果使用PyTorch,代码结构会有所不同,但实现思路类似,都是构建模型、定义损失函数和优化器,然后进行训练和评估。
如何优化神经网络的性能?
优化神经网络性能可以从多个方面入手,以下为你详细介绍:
数据层面
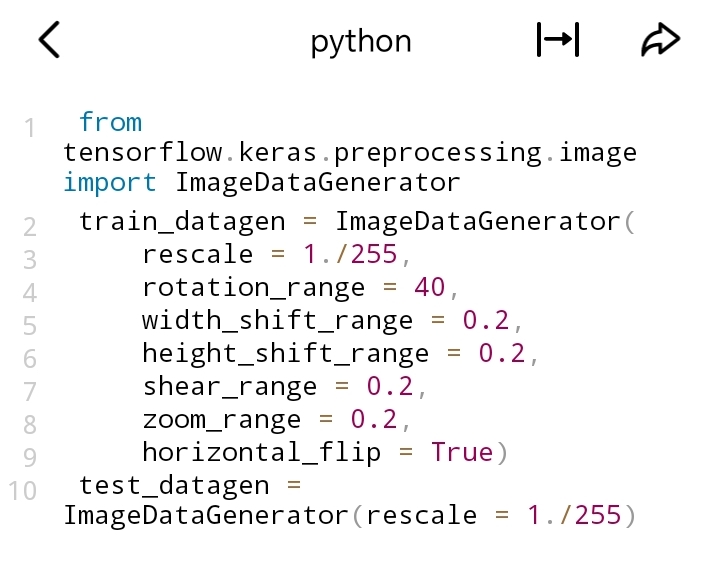
1. 数据增强:通过对训练数据进行变换(如旋转、翻转、缩放等)来增加数据的多样性。在图像领域常用,能防止模型过拟合。
- TensorFlow示例:
2. 数据预处理:对数据进行归一化或标准化处理,有助于加速模型收敛。
- 归一化示例(将数据映射到0 - 1区间):

- 标准化示例(使数据均值为0,标准差为1):

模型架构层面
1. 选择合适的模型架构:根据任务类型选择合适的架构。例如,处理图像任务时,卷积神经网络(CNN)通常优于简单的全连接神经网络;处理序列数据如时间序列或自然语言时,循环神经网络(RNN)及其变体(如LSTM、GRU)表现更好。
2. 调整网络深度和宽度:增加网络深度(层数)可以让模型学习到更复杂的特征,但可能导致梯度消失或梯度爆炸问题。增加宽度(每层神经元数量)可以提高模型的表示能力,但可能导致过拟合。需要通过实验找到合适的深度和宽度。
3. 正则化:
- L1和L2正则化:在损失函数中添加权重的L1或L2范数,防止权重过大。在TensorFlow中,可在层定义时添加正则化项:

- Dropout:在训练过程中随机丢弃一些神经元,防止过拟合。在TensorFlow中:

训练过程层面
1. 优化器选择:不同的优化器对模型收敛速度和性能有影响。
- Adam优化器:结合了Adagrad和RMSProp的优点,通常表现良好。在TensorFlow中:

- SGD(随机梯度下降)及其变体:如带动量的SGD,能加速收敛并在一定程度上避免局部最优解。
2. 学习率调整:学习率过大可能导致模型不收敛,过小则会使训练速度过慢。
- 学习率衰减:随着训练进行逐渐降低学习率。在TensorFlow中:

3. 批大小调整:批大小影响模型的收敛速度和稳定性。较小的批大小可能导致更准确的梯度估计,但收敛速度慢;较大的批大小可以加速训练,但可能错过最优解。需要通过实验确定合适的批大小。
评估与监控层面
1. 使用验证集:将训练数据分为训练集和验证集,在训练过程中监控验证集上的性能指标(如准确率、损失等),防止过拟合。当验证集性能不再提升时,可提前终止训练。
2. 可视化训练过程:使用工具(如TensorBoard)可视化训练过程中的指标变化,有助于分析模型性能,及时发现问题并调整策略。
如何选择合适的优化器和损失函数来优化神经网络性能?
选择合适的优化器和损失函数对优化神经网络性能至关重要,以下是相关的选择方法及示例:
优化器的选择
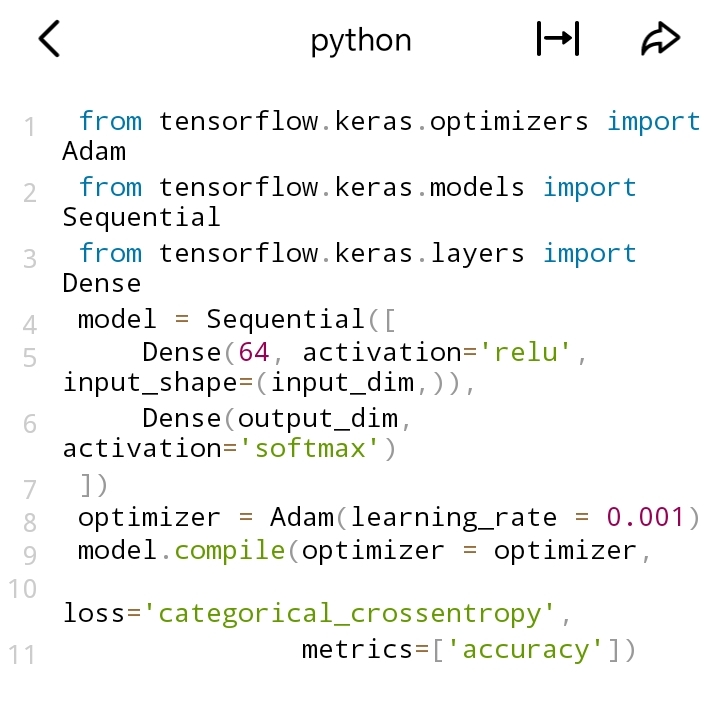
1. Adam优化器
- 适用场景:Adam是一种非常常用的优化器,适用于大多数场景。它结合了Adagrad和RMSProp的优点,能自适应地调整每个参数的学习率,在处理非凸优化问题时表现出色,训练速度通常较快。
- 代码示例(以TensorFlow为例):
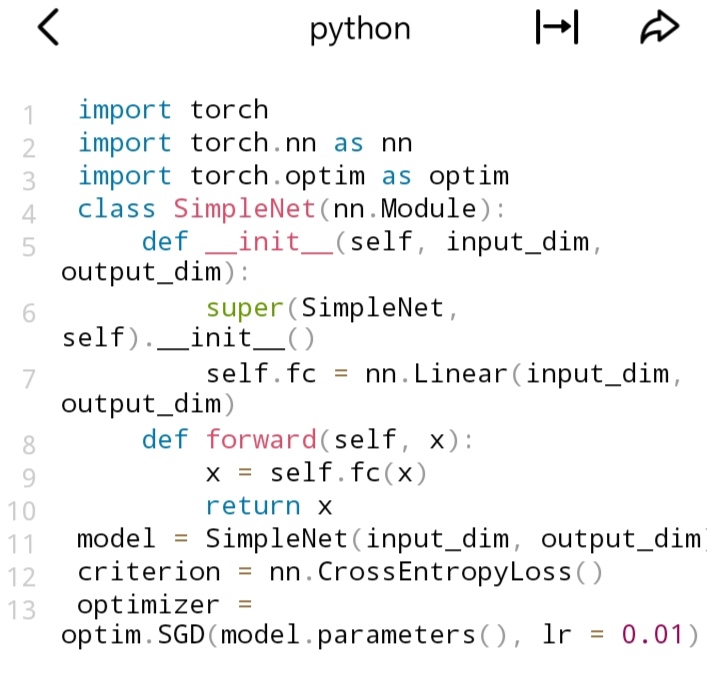
2. SGD(随机梯度下降)及其变体
- SGD:
- 适用场景:简单直观,适用于凸优化问题。当数据集较大时,收敛效果较好,但学习率设置不当可能导致收敛速度慢或不收敛。
- 代码示例(以PyTorch为例):
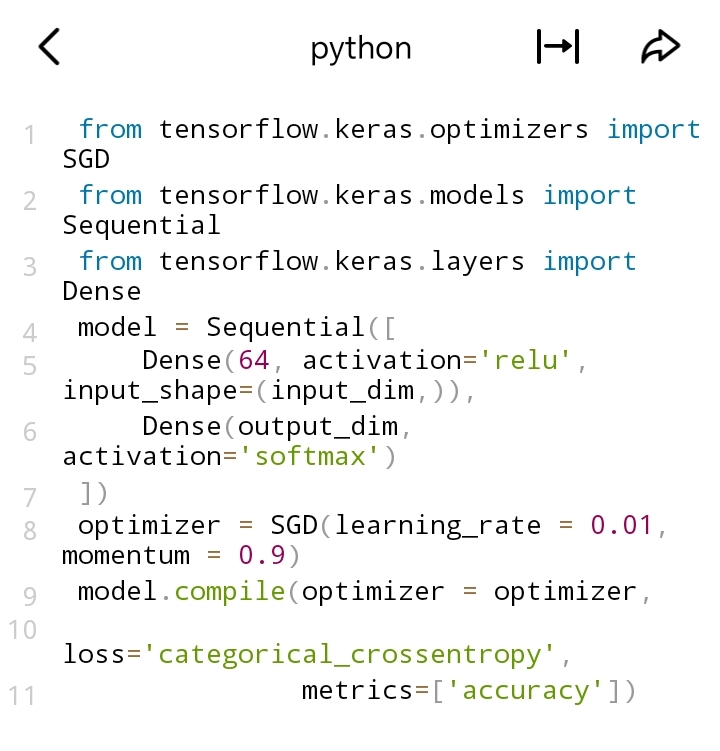
- 带动量的SGD:
- 适用场景:在SGD基础上加入动量项,有助于加速收敛,尤其在参数空间存在沟壑时表现更好,能帮助优化器更快跳出局部最优解。
- 代码示例(以TensorFlow为例):
3. Adagrad:
- 适用场景:能自适应地为每个参数调整学习率,适用于稀疏数据场景。但随着训练进行,学习率会不断衰减,可能导致后期学习速度过慢。
4. Adadelta和RMSProp:
- 适用场景:都是对Adagrad的改进,能避免学习率过度衰减问题。适用于处理非平稳目标函数或存在噪声的情况,在RNN等模型中应用较多。
损失函数的选择
1. 分类问题
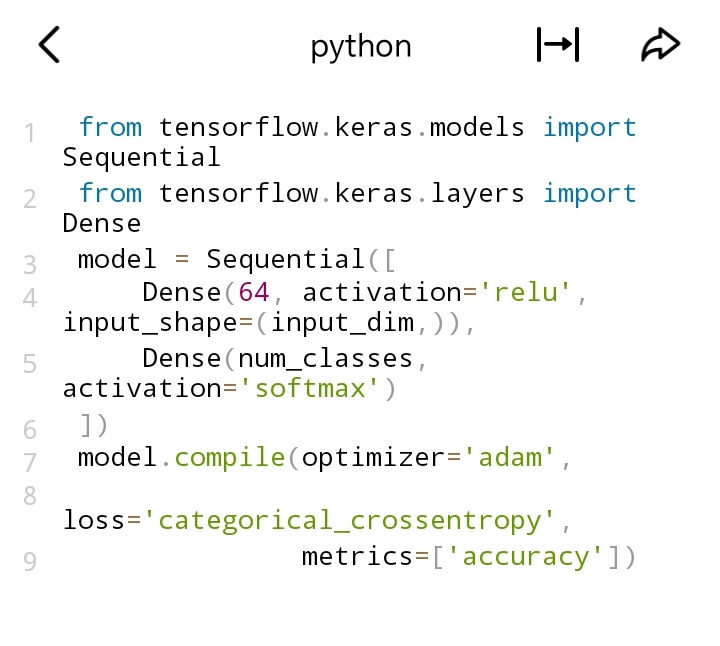
- 交叉熵损失(Cross - Entropy Loss):
- 适用场景:多分类问题常用。对于单标签分类(每个样本只有一个类别标签),使用categorical_crossentropy(独热编码标签);对于多标签分类(每个样本可能有多个类别标签),使用binary_crossentropy(标签为0或1)。
- 代码示例(以TensorFlow为例,多分类):
- Hinge损失:
- 适用场景:主要用于支持向量机(SVM),在二分类问题中,特别是当希望最大化类别间隔时使用。
2. 回归问题
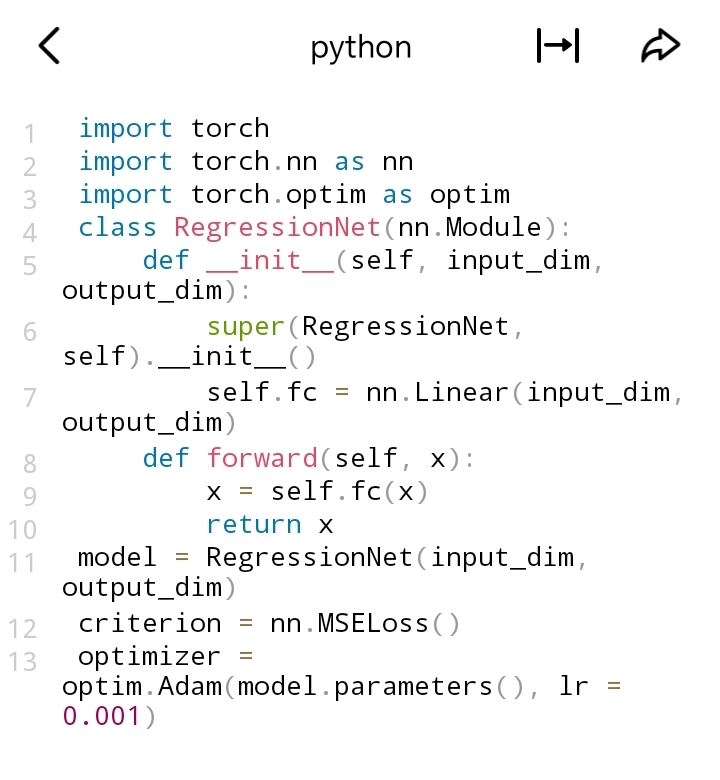
- 均方误差损失(Mean Squared Error, MSE):
- 适用场景:最常用的回归损失函数,计算预测值与真实值之间差值的平方的均值,能反映预测值的平均误差程度,适用于大多数回归场景。
- 代码示例(以PyTorch为例):
- 平均绝对误差损失(Mean Absolute Error, MAE):
- 适用场景:计算预测值与真实值之间差值的绝对值的均值,对异常值的鲁棒性比MSE好,当数据中存在较多异常值时可考虑使用。


