(使用24GB显存运行Llama-3.1-8B大模型)Python程序使用modelscope和huggingface的transformers导入调用Llama-3.1-8B-Instruct模型_modelscope下载的模型 transformers怎么使用
文章目录
-
-
- 正常导入Llama
- 使用modelscope下载
- 使用transformers导入
- 24GB显存导入
- 拓展
-
正常导入Llama
正常情况下,使用如下代码导入meta-llama/Llama-3.1-8B-Instruct
#需要安装transformers库,pip install即可。from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = \"meta-llama/Llama-3.1-8B-Instruct\"#要导入的大模型名称。model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=\"auto\", device_map=\"auto\")tokenizer = AutoTokenizer.from_pretrained(model_name)但是书接上文,https://liubingqing.blog.csdn.net/article/details/149274975?spm=1011.2415.3001.5331,Llama系列的模型,想要导入是需要申请的,需要在huggingface官网上写一个申请表,而中国大陆这边一般都无法通过申请,申请结果会是reject(不是梯子的问题),所以上述代码无法成功导入。
使用modelscope下载
modelscope是阿里巴巴推出的。在这里可以下载meta-llama/Llama-3.1-8B-Instruct。
#需要安装modelscope库,pip install即可。from modelscope import snapshot_downloadmodel_id=snapshot_download(\"LLM-Research/Meta-Llama-3.1-8B-Instruct\",cache_dir=\"~/modelscope\")#将下载的大模型存放在cache_dir目录下。print(\"model:\",model_id)这个下载需要蛮久的,我花了一两个小时,30个G,也是无语了。
下载好了之后,我们看一下下载的文件。大家可以看到modelscope目录下面有如下目录。
LLM-Research/Meta-Llama-3___1-8B-Instruct
该目录下面有如下文件。
上面有config.json文件,到时候导入大模型的时候我们就使用config.json文件所在的目录。
使用transformers导入
from transformers import AutoModelForCausalLM, AutoTokenizermodel_dir = \"~/modelscope/LLM-Research/Meta-Llama-3___1-8B-Instruct\"model = AutoModelForCausalLM.from_pretrained(model_dir)tokenizer = AutoTokenizer.from_pretrained(model_dir)这个时候有可能会报错,如下:
AutoModelForCausalLM TypeError: argument of type ‘NoneType’ is not iterable
解决办法可以参考:https://github.com/SWivid/F5-TTS/issues/1082,https://github.com/huggingface/transformers/issues/38340。他们说这是一个bug,解决办法就是降低transformers的版本,如下:
pip install transformers==4.51.3安装完了低版本之后,重新运行上述代码,如果jupyter notebook需要重启内核再运行上述代码。发现可以成功导入。
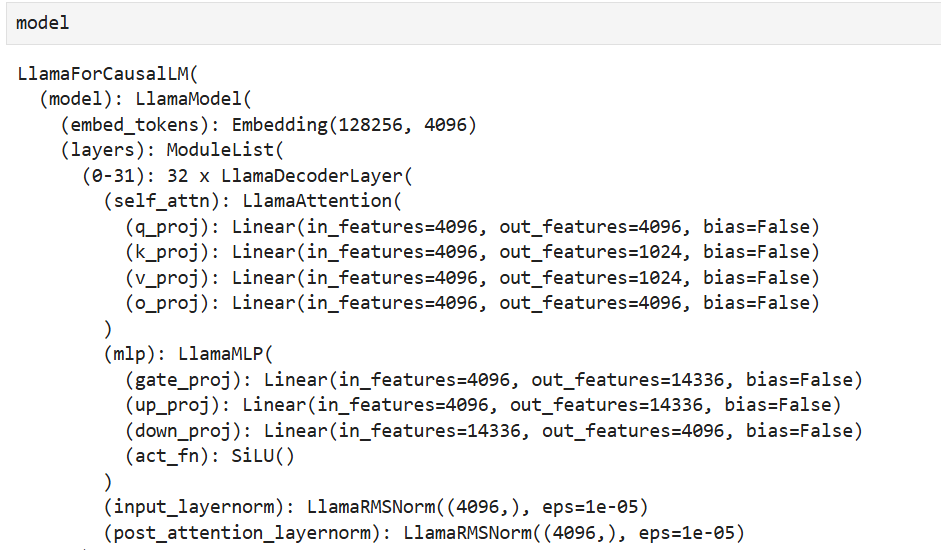

24GB显存导入
可以看到的是,上述代码,大模型默认是放在cpu上的,模型的参数的精度是float32,如果你想要将这个8B的模型放到24GB显存的GPU上,例如3090,4090,是不行的,显存不够,8B的模型默认大概需要30GB的显存。
那怎么办呢?我们将精度由默认的float32降低为float16,此时需要的显存会降低一半,也就是大概15GB。
import torchdevice = torch.device(\"cuda:2\")model=model.half().to(device)在 PyTorch 中,half() 是将张量数据类型转换为 16 位浮点型(即半精度浮点型)的方法。半精度浮点型比单精度浮点型占用更少的内存空间,但相应的精度也会受到一定的影响。看下面代码:
class Model(nn.Module): def __init__(self): super(Model,self).__init__() self.linear=nn.Linear(3,5) def forward(self,x): return self.linear(x)model=Model()#默认是float32model=model.half()#数据类型转化为float16#如果再继续half()呢?不变,还是float16model=model.half()#还是float16#也就是说,half一定变成float16### 拓展model=model.double()#double一定变成float64model=model.float()#float一定变成float32,这是默认的.在给定模型的情况下,将模型的参数和计算结果使用半精度浮点型进行存储和计算可以显著减少 GPU 内存的使用,从而允许更大的 batch size 和更深的网络结构,加速训练过程。但需要注意的是,在某些场景下,使用半精度浮点型可能会降低模型的精度和收敛速度,因此需要根据具体情况进行权衡和选择。
还是上面这个例子,我们查看一下float32和float16情况下模型的权重(self.linear线性层那个权重)
tensor([[-0.4974, -0.5157, 0.4132],
[ 0.4699, 0.2312, 0.0953],
[ 0.1286, 0.5104, -0.1663],
[-0.5107, -0.3395, -0.0041],
[ 0.1334, -0.3829, 0.4807]]
tensor([[-0.4973, -0.5156, 0.4133],
[ 0.4700, 0.2312, 0.0953],
[ 0.1287, 0.5103, -0.1664],
[-0.5107, -0.3394, -0.0041],
[ 0.1334, -0.3828, 0.4807]]
大家发现没有,我们把精度变小了,有几个数值发生了变化,例如第一行0.4132变成了 0.4133.但是我们也发现,这种变化是很微小的,通常不会对模型的推理有太大影响.
所以,好处更加明显,那就是通过float16,相比于float32,我们可以把显存降低了一半.一般一个8B的大模型,如果你按照默认的float32,24GB的显存是放不下的,这个时候选用float16就可以.
拓展
另外,还记得我们之前的那个导入代码吗?我们可以填入以下参数torch_dtype=\"auto\",其也会自动将模型的参数精度变成16位浮点数。
model = AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype=\"auto\")next(model.parameters()).dtype结果如下:
torch.bfloat16
也可以在24GB的GPU中导入。
有人说,我就是不想要将精度将为一半,就是要float32,那么怎么办呢?可以使用如下参数device_map=\"auto\"。
model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=\"auto\")这个参数`device_map=\"auto\"会将模型的各个层放在不同的GPU上,自动的。这样,虽然我们一个GPU 24GB装不下8B的模型,但是多个GPU可以呀。
大家可以使用nvidia-smi看看显卡占用情况,会发现,多个显卡都在运行自己的程序。
完结撒花

