SenSeVoice模型微调记录,语音识别垂直领域术语准确率提升至99%
场景:
项目需要开发一个语音下单助手,但在识别能源石油领域的专业名词(如石油产品、仓库、炼油厂等)时准确率较低,导致无法正确匹配下单信息。需对语音识别模型进行微调,提升垂直领域术语的识别准确率。本文复现下之前微调的过程,以作记录。
微调步骤
一.准备数据集
从数据库中查询出所有的商品名称,仓库名称,品牌名称还有地炼厂家名称。如果数据不够,可以从网上搜集一些,以增强数据集的数量和丰富程度。我搜集了大概800条相关的数据,需要先对这些数据整理成规范的文本。
文本整理成txt的就可以,然后每一行一条数据。接下来就是如何把文字转换为音频了。
可以人工录制,当然也可以用语音合成模型。这里我选择了CosyVoice进行TTS转成wav格式的音频。
cosyvoice的安装部署:
1.去魔搭社区找到模型。克隆仓库
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.gitcd CosyVoice2.创建cosyvoice的conda环境并激活。不用命令行,pycharm中也能设置
conda create -n cosyvoice python=3.10conda activate cosyvoice
注意要确保当前激活的环境是cosyvoice,pycharm有时候不靠谱,明明显示的是当前环境,但激活的并不是当前环境
conda info查看:
多的不说,少的不唠。拉取项目后先执行一遍webui.py,看看啥情况。首次运行会下载模型文件CosyVoice2-0.5B,我这里已经提前下载好了,所以指定本地模型地址,注意使用绝对路径。
运行成功后控制台会有地址,端口号8000,打开看一下: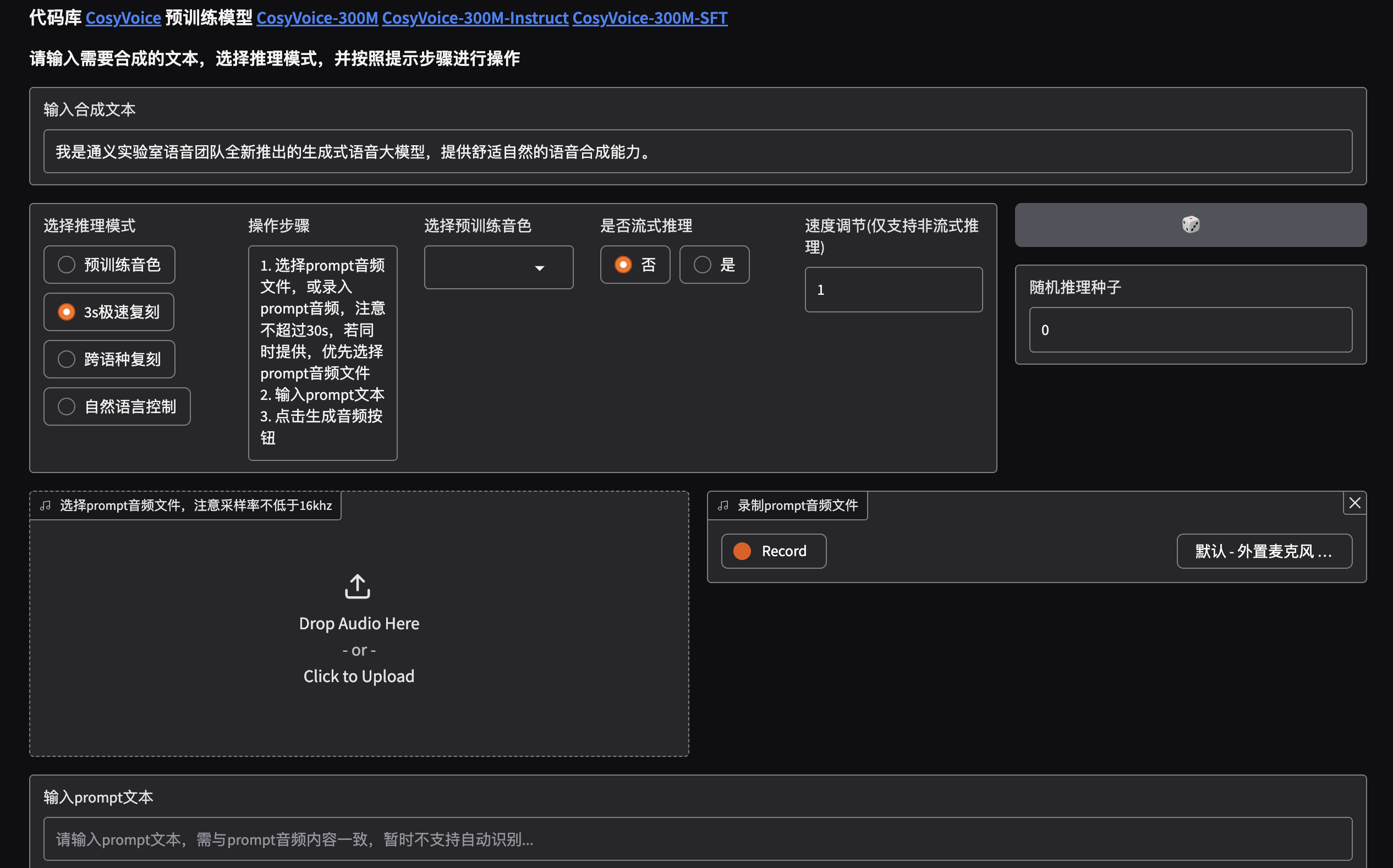
这就是文字合成语音的界面了,合成前需要给一个提示语音,还有prompt提示文本,作为校准用的,这块类似于llm的提示词。提示语音在TTSMarker上生成一段音频文件用就差不多了。
不要把提示文本的内容和音频搞错了,搞错了会导致合成的音频完全不匹配文本内容。当然使用页面合成太麻烦,所以写个脚本让他自己运行把。
在此之前要明确,微调语音模型需要的数据集个的格式是怎么样的:
微调SenseVoice模型的训练集需要准备两个文件,一个是标注文件,另一个是音频文件的绝对路径
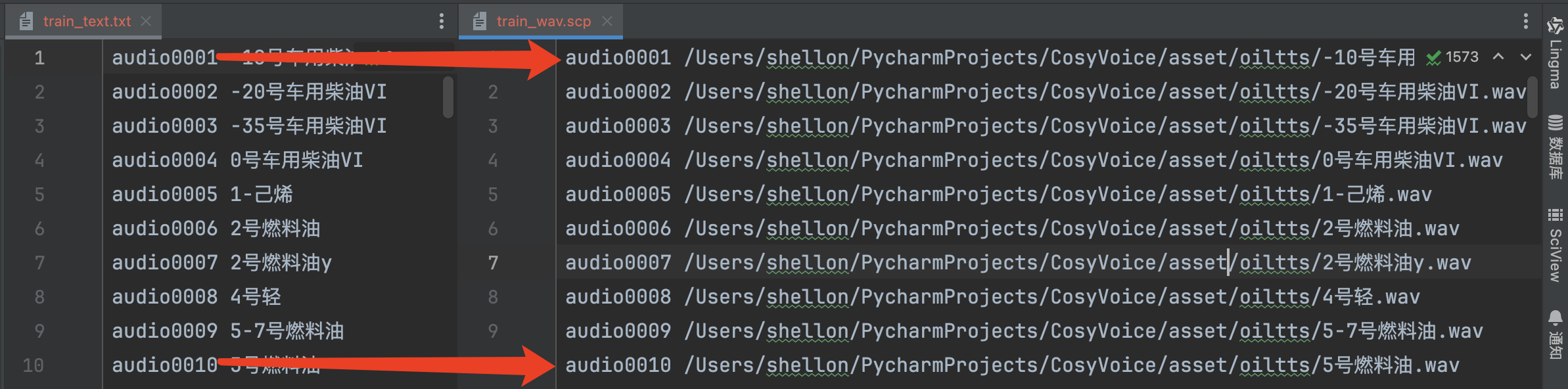
现在有了标注数据,接下来就是将文本合成音频,为了方便操作,音频文件的名称就是标注数据的名称。然后根据音频文件生成txt和scp文件。
#批量语音合成import syssys.path.append(\'third_party/Matcha-TTS\')from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2from cosyvoice.utils.file_utils import load_wavimport torchaudioimport os# 初始化模型cosyvoice = CosyVoice2(\'/Users/shellon/model/iic/CosyVoice2-0.5B\', load_jit=False, load_trt=False, fp16=False)# 加载提示语音,TTSMarker上生成的一段音频prompt_speech_16k = load_wav(\'asset/stand.wav\', 16000)# 输入文档路径和输出音频文件夹路径input_file = \'/Users/shellon/PycharmProjects/CosyVoice/asset/oil.txt\'output_dir = \'/Users/shellon/PycharmProjects/CosyVoice/asset/oiltt\'# 确保输出目录存在os.makedirs(output_dir, exist_ok=True)# 读取商品名称并生成语音try: with open(input_file, \'r\', encoding=\'utf-8\') as f: product_names = [line.strip() for line in f if line.strip()] for product_name in product_names: # 过滤掉文件名中的非法字符 safe_filename = \"\".join([c for c in product_name if c.isalnum() or c in [\' \', \'_\', \'-\']]).strip() output_path = os.path.join(output_dir, f\"{safe_filename}.wav\") # 跳过已存在的文件 if os.path.exists(output_path): print(f\"已存在: {output_path},跳过\") continue print(f\"正在生成: {product_name}\") # 生成语音 for i, result in enumerate(cosyvoice.inference_zero_shot( product_name, # 内容文本 \"希望你以后能够做的比我还好呦\", # 指导文本 prompt_speech_16k, stream=False )): # 保存音频 torchaudio.save(output_path, result[\'tts_speech\'], cosyvoice.sample_rate) break # 只保存第一个结果 print(f\"全部完成! 共生成 {len(product_names)} 个音频文件\")except Exception as e: print(f\"发生错误: {e}\")运行完脚本之后,会在指定目录下生成音频文件wav:
有了音频文件,接下来就是生成标注文本和音频路径文件了:
import os#根据音频文件生成标注文本和音频路径文件# 配置路径audio_dir = \"/Users/shellon/PycharmProjects/CosyVoice/asset/oiltts\" # 音频文件目录output_dir = \"/Users/shellon/PycharmProjects/CosyVoice/asset/oilttsvoicedata\" # 标准化文件输出目录# 确保输出目录存在os.makedirs(output_dir, exist_ok=True)# 输出文件路径wav_scp_path = os.path.join(output_dir, \"val_wav.scp\")text_path = os.path.join(output_dir, \"val_text.txt\")# 遍历音频目录,生成标准化文件audio_files = [f for f in os.listdir(audio_dir) if f.endswith(\".wav\")]audio_files.sort() # 按文件名排序保证顺序with open(wav_scp_path, \"w\", encoding=\"utf-8\") as f_wav, \\ open(text_path, \"w\", encoding=\"utf-8\") as f_text: for idx, filename in enumerate(audio_files): # 生成唯一音频ID (格式: audio0001, audio0002...) audio_id = f\"audio{idx + 1:04d}\" # 从文件名提取文本内容(去掉.wav扩展名) text_content = os.path.splitext(filename)[0].strip() # 写入train_wav.scp: [音频ID] [绝对路径] audio_path = os.path.join(audio_dir, filename) f_wav.write(f\"{audio_id} {audio_path}\\n\") # 写入train_text.txt: [音频ID] [文本内容] f_text.write(f\"{audio_id} {text_content}\\n\")print(f\"标准化文件生成完成!\\n\" f\"- 音频索引文件: {wav_scp_path}\\n\" f\"- 文本标注文件: {text_path}\\n\" f\"共处理 {len(audio_files)} 个音频文件。\")运行结果:
验证集和测试集同理
生成jsonl文件
jsonl文件的格式要求可自行查阅,这里不再赘述
git上拉取SenseVoice项目
git clone <https://github.com/modelscope/FunASR.git>创建conda虚拟环境
conda create -n sensevoice python=3.10conda activate sensevoiceconda install -y -c conda-forge pynini==2.1.5安装依赖
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com项目安装完成后,cosyvoice生成的标注文本和音频路径文件cpoy到此项目中,然后终端cd到所在目录,执行:
sensevoice2jsonl \\ ++scp_file_list=\'[\"train_wav.scp\", \"train_text.txt\"]\' \\ ++data_type_list=\'[\"source\", \"target\"]\' \\ ++jsonl_file_out=\"train.jsonl\"最终会生成相应的jsonl文件
到这一步,微调需要准备的数据集已经制作好了。
数据集的注意事项
数据质量:准确、无噪声,标注清晰一致。
数据规模:量足够支撑模型学习,避免过拟合。
数据多样性:覆盖多场景、多情况,提升模型泛化能力。
数据相关性:与任务紧密相关,贴合实际应用需求
二.准备微调环境
配置训练参数
在SenseVoice中,执行训练脚本:
/bin/zsh /Users/shellon/PycharmProjects/SenseVoice/finetune.sh直接执行训练会报错,首先是缺trains_ds.py,我找了半天也没在SenseVoice里找到,原来在这个脚本在FunASR项目里,无奈又从git上拉取FunASR项目,然后发现了它: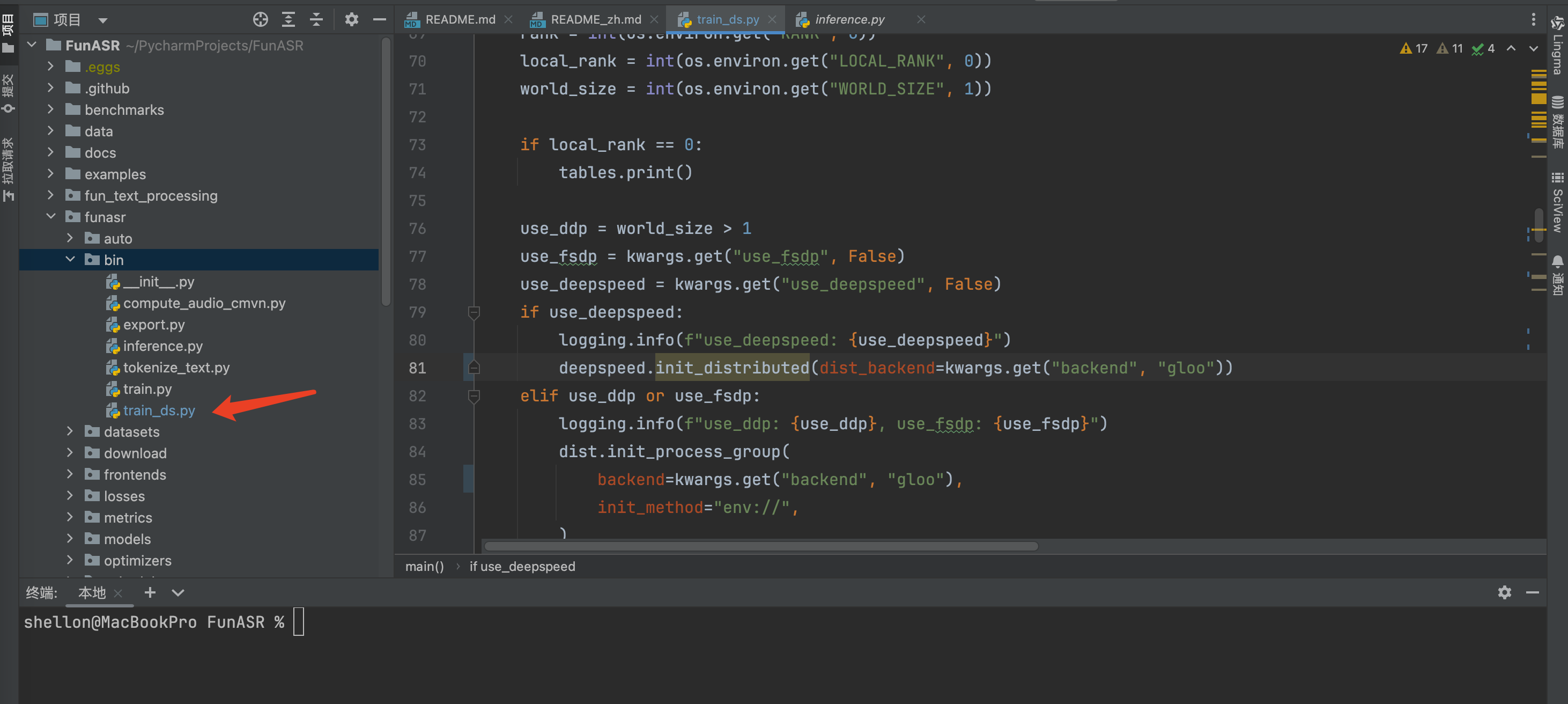
git clone https://github.com/alibaba/FunASR.git cd FunASR pip3 install -e ./funasr 是什么?
funasr 是阿里巴巴开源的语音识别(ASR)工具包,常用于语音模型的训练和推理。
通常 funasr 的安装方式是 pip install funasr 或者通过源码安装。
train_ds.py 的作用。finetune.sh 脚本假设 funasr 包里有 train_ds.py 文件,但实际上并不包含 train_ds.py 这个脚本。
SenseVoice 和 FunASR 的关系
SenseVoice是一个基于 FunASR 框架开发的语音识别模型或应用项目。
FunASR(https://github.com/alibaba/FunASR)是阿里巴巴开源的通用语音识别训练与推理框架,相当于“底层引擎”。SenseVoice 依赖 FunASR 提供的训练、推理、数据处理等底层能力。可以理解为:SenseVoice 是“应用层”,FunASR 是“基础库”。
为什么要单独 clone 并安装 FunASR?
SenseVoice 项目本身并不包含 FunASR 的全部代码,只是依赖它。需要单独 clone FunASR,并用 pip install -e ./ 方式“开发模式”安装,这样 SenseVoice 代码才能直接调用 FunASR 的底层功能。这两个项目可以在不同目录,但 FunASR 安装好后,SenseVoice 项目就能通过 import funasr 正常调用。
解决了这个问题,在macos上训练问题还是比较多的,首先finetune.sh 参数默认是分布式训练,很明显我没有,finetune.sh参数需要改。另外我电脑上没有GPU,所以设备必须指定为CPU,在train_ds.py中修改
最终运行的finetune.sh和train_ds.py:
finetune.sh
# Copyright FunASR (https://github.com/alibaba-damo-academy/FunASR). All Rights Reserved.# MIT License (https://opensource.org/licenses/MIT)# 微调指令workspace=`pwd`# which gpu to train or finetuneexport CUDA_VISIBLE_DEVICES=\"0\"gpu_num=1# model_name from model_hub, or model_dir in local path## option 1, download model automaticallymodel_name_or_model_dir=\"iic/SenseVoiceSmall\"## option 2, download model by git#local_path_root=${workspace}/modelscope_models#mkdir -p ${local_path_root}/${model_name_or_model_dir}#git clone https://www.modelscope.cn/${model_name_or_model_dir}.git ${local_path_root}/${model_name_or_model_dir}#model_name_or_model_dir=${local_path_root}/${model_name_or_model_dir}# data dir, which contains: train.json, val.jsontrain_data=${workspace}/data/train_data/train.jsonlval_data=${workspace}/data/val_data/val.jsonl# exp output diroutput_dir=\"./outputs\"log_file=\"${output_dir}/log.txt\"deepspeed_config=${workspace}/deepspeed_conf/ds_stage1.jsonmkdir -p ${output_dir}echo \"log_file: ${log_file}\"DISTRIBUTED_ARGS=\" --nnodes ${WORLD_SIZE:-1} \\ --nproc_per_node $gpu_num \\ --node_rank ${RANK:-0} \\ --master_addr ${MASTER_ADDR:-127.0.0.1} \\ --master_port ${MASTER_PORT:-26669}\"echo $DISTRIBUTED_ARGS# funasr trainer pathtrain_tool=/Users/shellon/PycharmProjects/FunASR/funasr/bin/train_ds.py# 打印最终命令,便于调试# echo torchrun $DISTRIBUTED_ARGS $train_tool ...torchrun \\ --nnodes ${WORLD_SIZE:-1} \\ --nproc_per_node $gpu_num \\ --node_rank ${RANK:-0} \\ --master_addr ${MASTER_ADDR:-127.0.0.1} \\ --master_port ${MASTER_PORT:-26669} \\ $train_tool \\ ++backend=gloo \\ ++model=\"${model_name_or_model_dir}\" \\ ++trust_remote_code=true \\ ++train_data_set_list=\"${train_data}\" \\ ++valid_data_set_list=\"${val_data}\" \\ ++dataset_conf.data_split_num=1 \\ ++dataset_conf.batch_sampler=\"BatchSampler\" \\ ++dataset_conf.batch_size=800 \\ ++dataset_conf.sort_size=512 \\ ++dataset_conf.batch_type=\"token\" \\ ++dataset_conf.num_workers=8 \\ ++train_conf.max_epoch=100 \\ ++train_conf.log_interval=1 \\ ++train_conf.resume=true \\ ++train_conf.validate_interval=2000 \\ ++train_conf.save_checkpoint_interval=2000 \\ ++train_conf.keep_nbest_models=20 \\ ++train_conf.avg_nbest_model=10 \\ ++train_conf.use_deepspeed=false \\ ++train_conf.deepspeed_config=${deepspeed_config} \\ ++optim_conf.lr=0.0001参数说明:
epoch 100轮
batch_size 800
keep_nbest_models 训练过程中只保存20个权重
avg_nbest_model=10 用最近10个最优模型做参数平均,提升泛化
lr=0.0001 学习率调整为0.0001
即便有分布式训练的参数,但实际上还是单机cpu训练
其他参数不列举了。。。
train_ds.py
#!/usr/bin/env python3# -*- encoding: utf-8 -*-import osimport sysimport torchimport torch.nn as nnimport hydraimport loggingimport timeimport argparsefrom io import BytesIOfrom contextlib import nullcontextimport torch.distributed as distfrom omegaconf import DictConfig, OmegaConffrom torch.cuda.amp import autocast, GradScalerfrom torch.nn.parallel import DistributedDataParallel as DDPfrom torch.distributed.fsdp import FullyShardedDataParallel as FSDPfrom torch.distributed.algorithms.join import Joinfrom torch.distributed.fsdp.sharded_grad_scaler import ShardedGradScalerfrom funasr.train_utils.average_nbest_models import average_checkpointsfrom funasr.register import tablesfrom funasr.optimizers import optim_classesfrom funasr.train_utils.trainer_ds import Trainerfrom funasr.schedulers import scheduler_classesfrom funasr.train_utils.initialize import initializefrom funasr.download.download_model_from_hub import download_modelfrom funasr.models.lora.utils import mark_only_lora_as_trainablefrom funasr.train_utils.set_all_random_seed import set_all_random_seedfrom funasr.train_utils.load_pretrained_model import load_pretrained_modelfrom funasr.utils.misc import prepare_model_dirfrom funasr.train_utils.model_summary import model_summaryfrom funasr import AutoModeltorch.set_num_threads(8)try: import deepspeedexcept: deepspeed = None@hydra.main(config_name=None, version_base=None)def main_hydra(kwargs: DictConfig): if kwargs.get(\"debug\", False): import pdb pdb.set_trace() assert \"model\" in kwargs if \"model_conf\" not in kwargs: logging.info(\"download models from model hub: {}\".format(kwargs.get(\"hub\", \"ms\"))) kwargs = download_model(is_training=kwargs.get(\"is_training\", True), **kwargs) main(**kwargs)def main(**kwargs): # set random seed set_all_random_seed(kwargs.get(\"seed\", 0)) torch.backends.cudnn.enabled = kwargs.get(\"cudnn_enabled\", torch.backends.cudnn.enabled) torch.backends.cudnn.benchmark = kwargs.get(\"cudnn_benchmark\", torch.backends.cudnn.benchmark) torch.backends.cudnn.deterministic = kwargs.get(\"cudnn_deterministic\", True) # open tf32 torch.backends.cuda.matmul.allow_tf32 = kwargs.get(\"enable_tf32\", True) rank = int(os.environ.get(\"RANK\", 0)) local_rank = int(os.environ.get(\"LOCAL_RANK\", 0)) world_size = int(os.environ.get(\"WORLD_SIZE\", 1)) if local_rank == 0: tables.print() use_ddp = world_size > 1 use_fsdp = kwargs.get(\"use_fsdp\", False) use_deepspeed = kwargs.get(\"use_deepspeed\", False) if use_deepspeed: logging.info(f\"use_deepspeed: {use_deepspeed}\") deepspeed.init_distributed(dist_backend=kwargs.get(\"backend\", \"gloo\")) elif use_ddp or use_fsdp: logging.info(f\"use_ddp: {use_ddp}, use_fsdp: {use_fsdp}\") dist.init_process_group( backend=kwargs.get(\"backend\", \"gloo\"), init_method=\"env://\", ) torch.cuda.set_device(local_rank) # rank = dist.get_rank() logging.info(\"Build model, frontend, tokenizer\") device = kwargs.get(\"device\", \"cuda\") kwargs[\"device\"] = \"cpu\" model = AutoModel(**kwargs) # save config.yaml if rank == 0: prepare_model_dir(**kwargs) # parse kwargs kwargs = model.kwargs kwargs[\"device\"] = \"cpu\" tokenizer = kwargs[\"tokenizer\"] frontend = kwargs[\"frontend\"] model = model.model del kwargs[\"model\"] # freeze_param freeze_param = kwargs.get(\"freeze_param\", None) if freeze_param is not None: if \",\" in freeze_param: freeze_param = eval(freeze_param) if not isinstance(freeze_param, (list, tuple)): freeze_param = (freeze_param,) logging.info(\"freeze_param is not None: %s\", freeze_param) for t in freeze_param: for k, p in model.named_parameters(): if k.startswith(t + \".\") or k == t: logging.info(f\"Setting {k}.requires_grad = False\") p.requires_grad = False if local_rank == 0: logging.info(f\"{model_summary(model)}\") trainer = Trainer( rank=rank, local_rank=local_rank, world_size=world_size, use_ddp=use_ddp, use_fsdp=use_fsdp, device=\"cpu\", excludes=kwargs.get(\"excludes\", None), output_dir=kwargs.get(\"output_dir\", \"./exp\"), **kwargs.get(\"train_conf\"), ) model = trainer.warp_model(model, **kwargs) # kwargs[\"device\"] = int(os.environ.get(\"LOCAL_RANK\", 0)) # trainer.device = int(os.environ.get(\"LOCAL_RANK\", 0)) model, optim, scheduler = trainer.warp_optim_scheduler(model, **kwargs) # dataset logging.info(\"Build dataloader\") dataloader_class = tables.dataloader_classes.get( kwargs[\"dataset_conf\"].get(\"dataloader\", \"DataloaderMapStyle\") ) dataloader = dataloader_class(**kwargs) # dataloader_tr, dataloader_val = dataloader_class(**kwargs) scaler = GradScaler(enabled=True) if trainer.use_fp16 or trainer.use_bf16 else None scaler = ShardedGradScaler(enabled=trainer.use_fp16) if trainer.use_fsdp else scaler trainer.resume_checkpoint( model=model, optim=optim, scheduler=scheduler, scaler=scaler, ) dataloader_tr, dataloader_val = None, None for epoch in range(trainer.start_epoch, trainer.max_epoch): time1 = time.perf_counter() for data_split_i in range(trainer.start_data_split_i, dataloader.data_split_num): time_slice_i = time.perf_counter() dataloader_tr, dataloader_val = dataloader.build_iter( epoch, data_split_i=data_split_i, start_step=trainer.start_step ) trainer.train_epoch( model=model, optim=optim, scheduler=scheduler, scaler=scaler, dataloader_train=dataloader_tr, dataloader_val=dataloader_val, epoch=epoch, data_split_i=data_split_i, data_split_num=dataloader.data_split_num, start_step=trainer.start_step, ) trainer.start_step = 0 device = next(model.parameters()).device if device.type == \"cuda\": with torch.cuda.device(device): torch.cuda.empty_cache() time_escaped = (time.perf_counter() - time_slice_i) / 3600.0 logging.info( f\"\\n\\nrank: {local_rank}, \" f\"time_escaped_epoch: {time_escaped:.3f} hours, \" f\"estimated to finish {dataloader.data_split_num} data_slices, remaining: {dataloader.data_split_num-data_split_i} slices, {(dataloader.data_split_num-data_split_i)*time_escaped:.3f} hours, \" f\"epoch: {trainer.max_epoch - epoch} epochs, {((trainer.max_epoch - epoch - 1)*dataloader.data_split_num + dataloader.data_split_num-data_split_i)*time_escaped:.3f} hours\\n\" ) trainer.start_data_split_i = 0 trainer.validate_epoch(model=model, dataloader_val=dataloader_val, epoch=epoch + 1) scheduler.step() trainer.step_in_epoch = 0 trainer.save_checkpoint( epoch + 1, model=model, optim=optim, scheduler=scheduler, scaler=scaler ) time2 = time.perf_counter() time_escaped = (time2 - time1) / 3600.0 logging.info( f\"\\n\\nrank: {local_rank}, \" f\"time_escaped_epoch: {time_escaped:.3f} hours, \" f\"estimated to finish {trainer.max_epoch} \" f\"epoch: {(trainer.max_epoch - epoch) * time_escaped:.3f} hours\\n\" ) trainer.train_acc_avg = 0.0 trainer.train_loss_avg = 0.0 if trainer.rank == 0: average_checkpoints( trainer.output_dir, trainer.avg_nbest_model, use_deepspeed=trainer.use_deepspeed ) trainer.close()if __name__ == \"__main__\": main_hydra()三.开始训练
训练过程查看训练集和验证集的损失启动tensorboard面板
pip install tensorboardtensorboard --port 6007 --logdir exp/tensorboard 经过8个小时的cpu训练完成,loss如下图: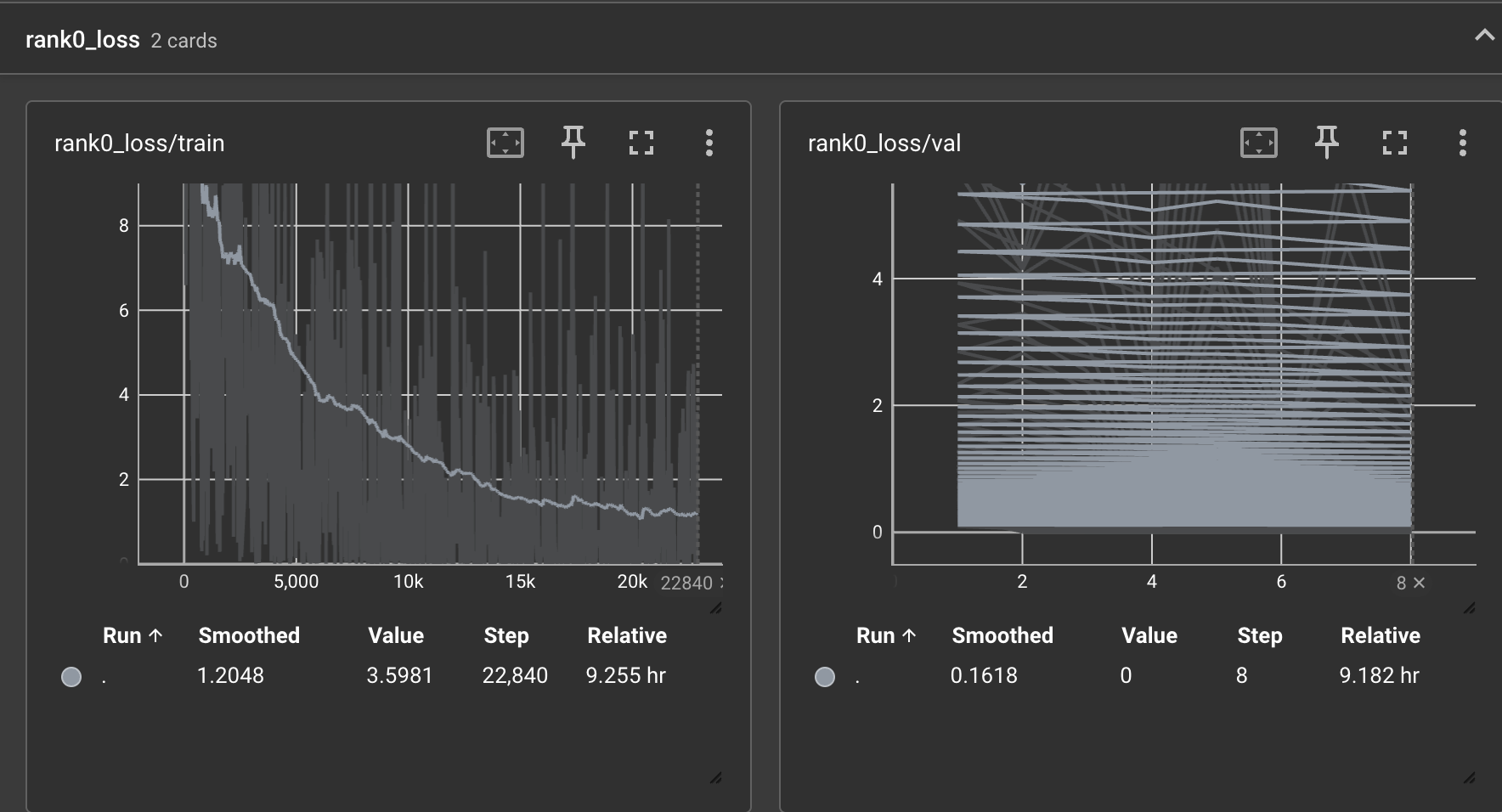
看上去感觉模型还没有彻底收敛,还可以继续训练。
训练完成保存的权重:
多的不说,少的不唠,直接跑一遍试试效果再说:
在SenseVoice的webui.py中,加入训练保存的权重路径,对比测试一下: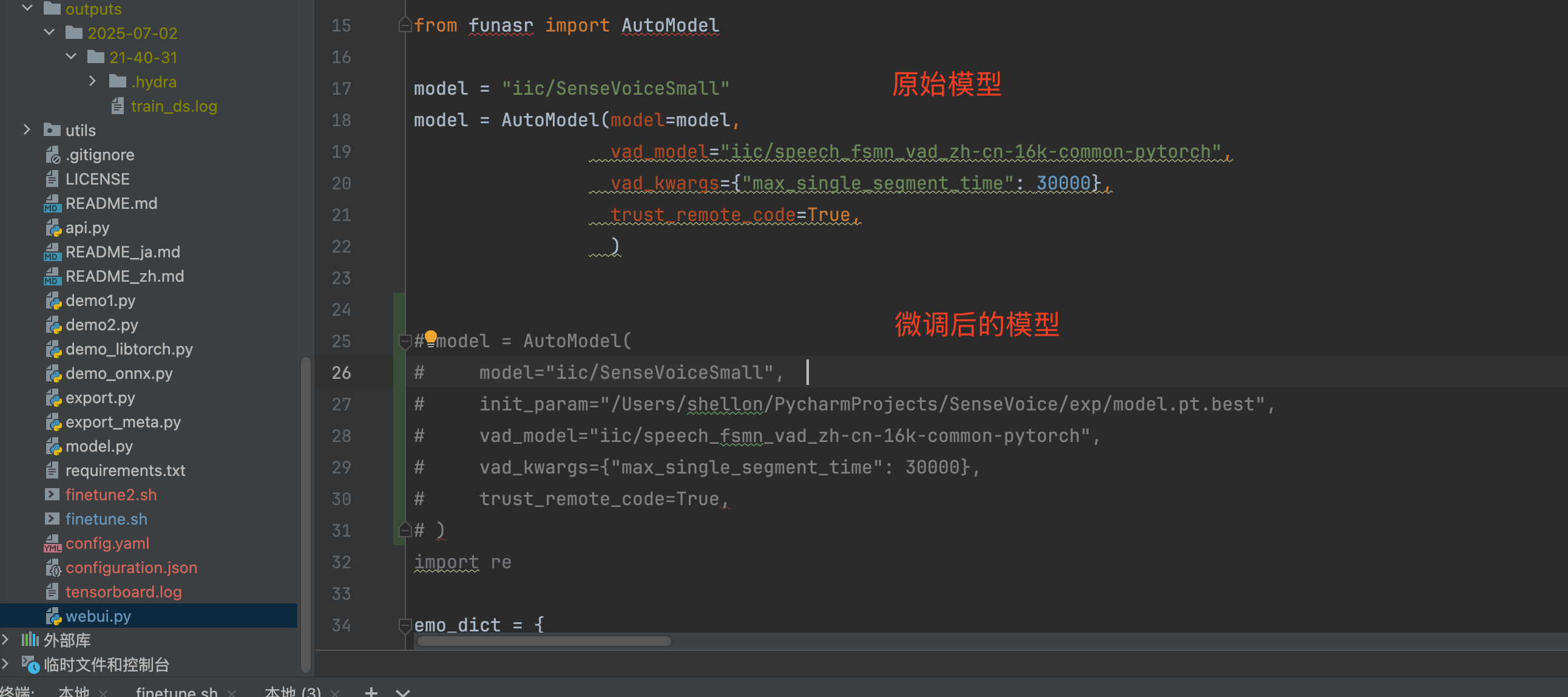
四.验证测试
测试效果示例:
原始模型: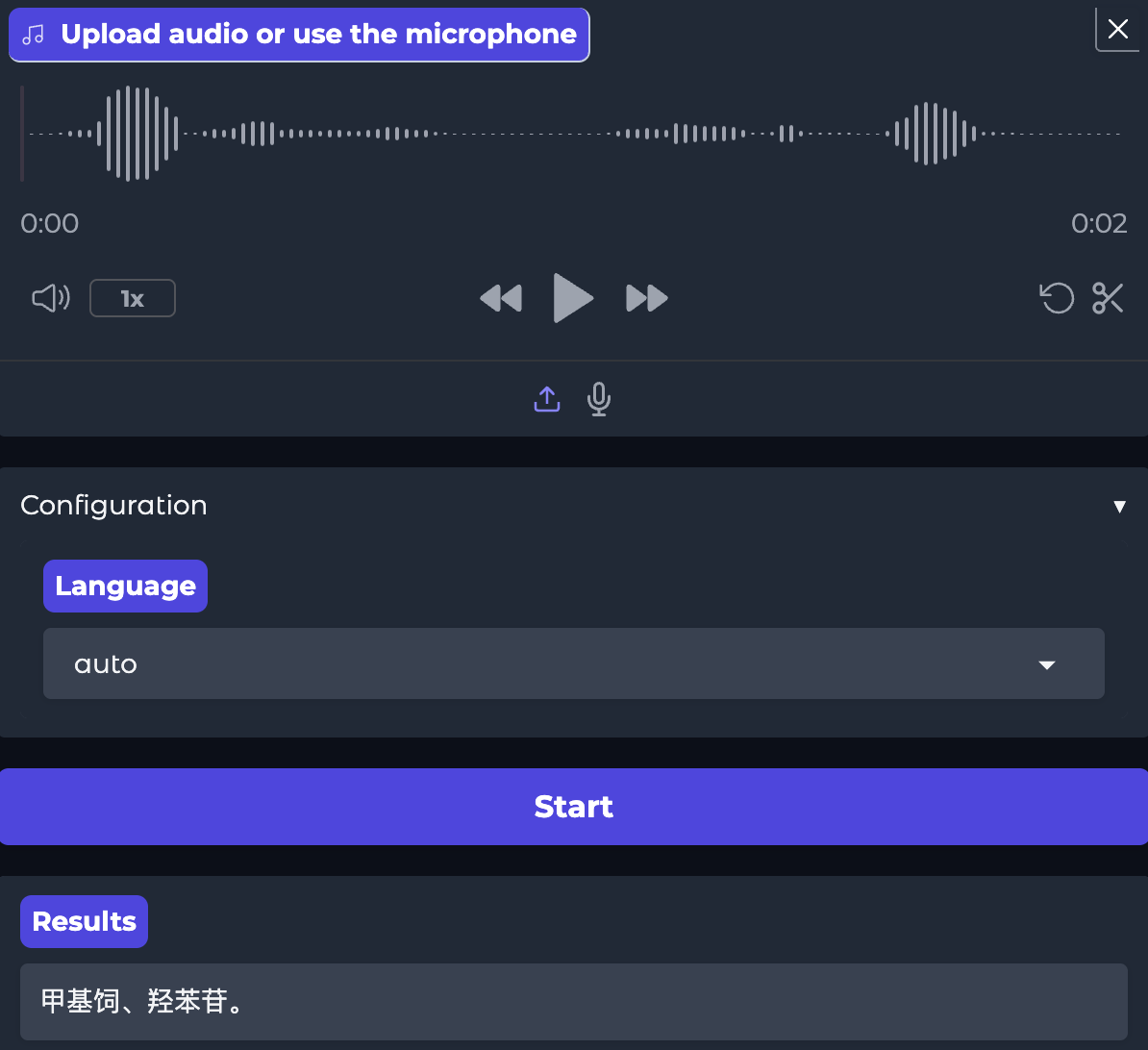
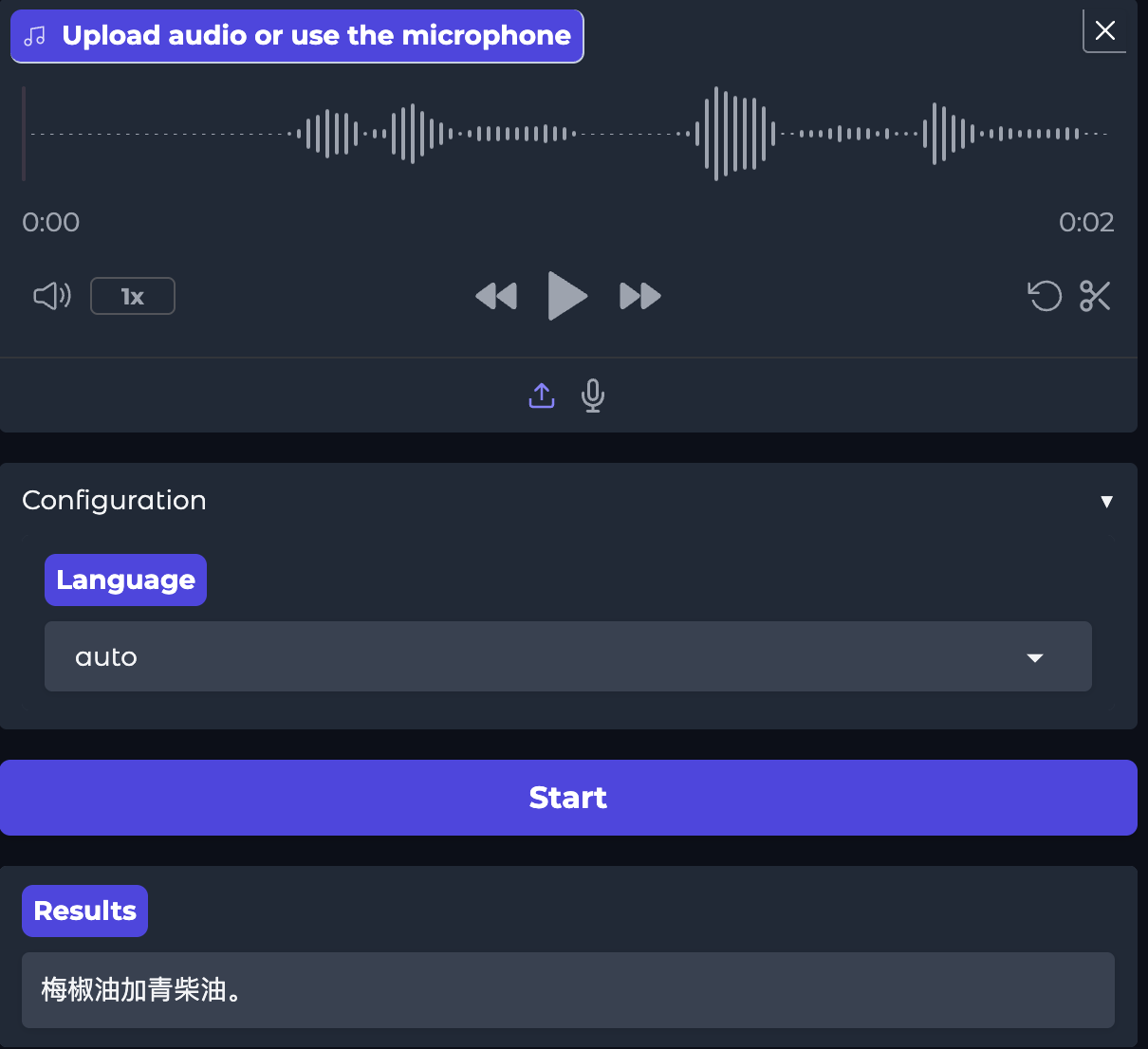
微调后的模型: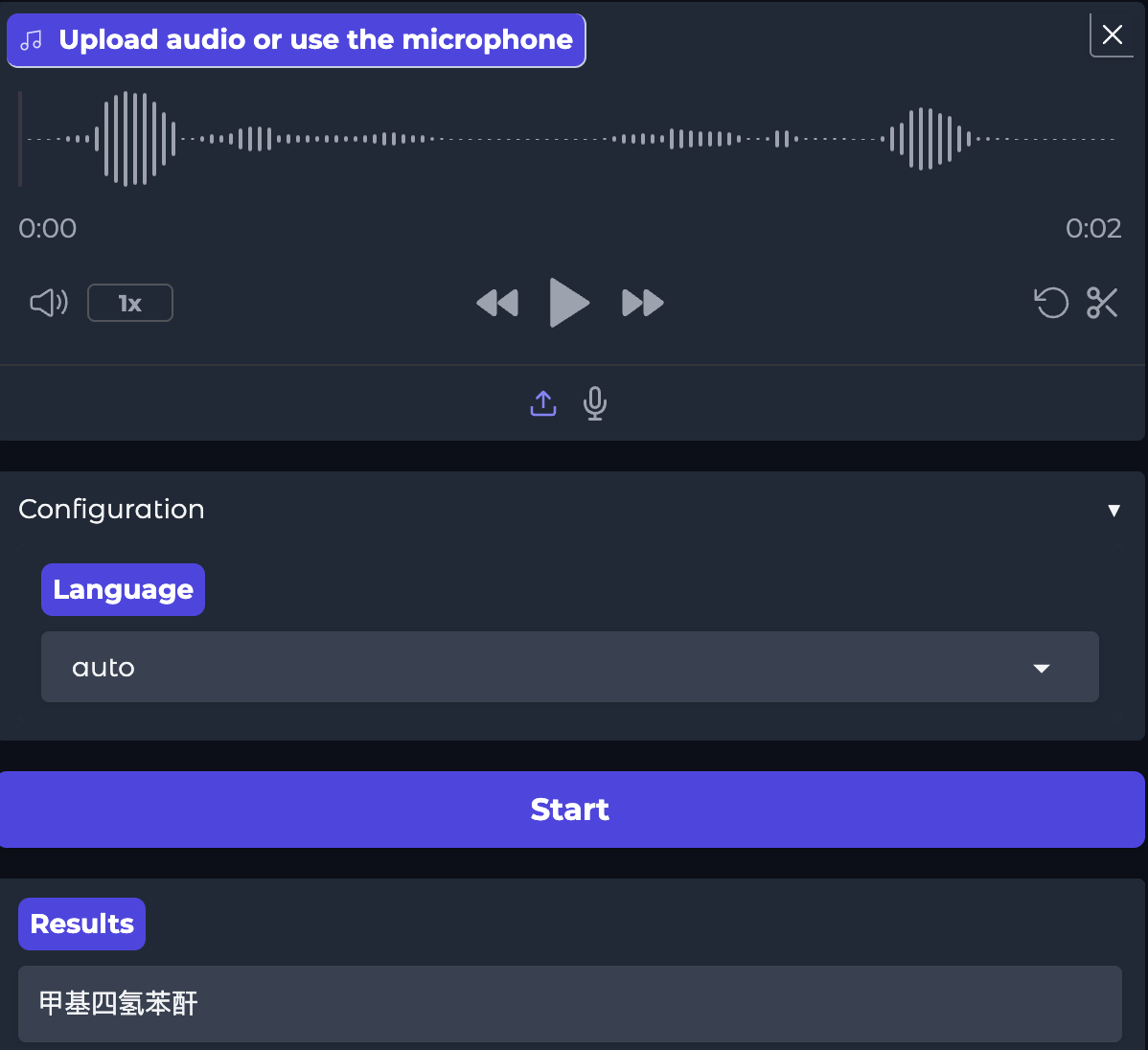
经过后面的测试,微调后模型的识别率从原来的36.4%,提升到99.7%,提升效果显著。至此模型训练完成。
总结
在微调训练的过程中,数据集的制作至关重要,虽然可以通过cosyvoice,python脚本方式辅助生成数据集,但是还是需要人工审核一次,确保生成的音频数据发音正确还有数据的完整性。
另外就是微调参数的配置,除了会影响到训练速度之外,更会直接影响到最终的训练效果,也需要多注意。
后面有时间再整理下模型部署的记录。。。。。。。


