Kafka如何解决消息积压、堆积问题_kafka消息堆积
目录
1、前言
2、名词解释
3、如何衡量消息的生产量/消费量/积压量
4、常见案例&应对方法
4.1 消费端过载
4.2 消息生产异常导致消费端消费能力不足
4.3 消息中间件异常导致消息消费失败
4.4 消费者业务流程复杂,业务增长后,生产者流量超出消费者能力
4.5 消费者业务流程中存在慢查询
4.6 消费者依赖第三方服务
4.7 消费者组频繁rebalance导致消息积压问题
5、常见处理方案总结
5.1 增加消费者并发处理能力
5.2 提升消费者的消费能力
5.3 提升Kafka集群性能
5.4 调整Kafka的配置参数
5.5 处理积压历史数据
5.6 分离实时数据和历史数据
5.7 流量控制和限流
5.8 动态扩展
5.9 数据分流
5.10 避免重复消费
5.11 监控与告警机制
5.12 异常处理机制
1、前言
Kafka消息积压的问题,核心原因是生产太快、消费太慢,处理速度长期失衡,从而导致消息积压(Lag)的场景,积压到超过队列长度限制,就会出现还未被消费的数据产生丢失的场景。 Kafka消息积压问题是指生产者发送消息的速度大于消费者处理消息的速度,导致大量未消费的消息堆积在Kafka中。如果长时间不解决消息积压,可能会引发资源紧张、服务延迟或崩溃等问题。解决消息积压的关键是提高消费者的消费能力,并优化Kafka集群的整体处理效率。 简单来说,之所以会产生积压,就是消费能力弱所致。
2、名词解释
- Producer :消息生产者,就是向 Kafka broker 发消息的客户端;
- Consumer :消息消费者,向 Kafka broker 取消息的客户端;
- Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由消费组内一个消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker :一个 Kafka 实例就是一个 broker。一个集群由多个 broker 组成。一个broker可以容纳多个 topic。
- Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic;
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
- Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
- leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是 leader。
- follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据的同步。leader 发生故障时,某个 follower 会成为新的 leader。
3、如何衡量消息的生产量/消费量/积压量
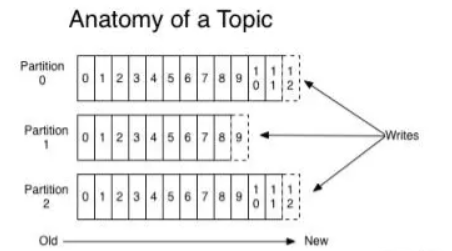
- 生产量:Kafka Topic 在一个时间周期内各partition offset 起止时间差值之和。
- 消费量:Kafka Topic 在一个时间周期内某个消费者的消费量。
- 积压量:Kafka Topic 的某个Consumer Group残留在消息中间件未被及时消费的消息量
4、常见案例&应对方法
4.1 消费端过载
原因:消费任务里有消费任务队列满载,消费线程阻塞,导致系统频繁 fullGC 问题 处理方案:根本解法是提升消费端的能力,增加消费线程数;事前预警,可以增加消费能力监控,以及消息消费积压报警。
4.2 消息生产异常导致消费端消费能力不足
原因:生产者的一些错误导致重复、过多写入任务队列,消息消费能力不足导致该问题。 处理方案: 1)最根本的处理方案是,代码方面增加健壮性处理,避免此类问题的发生。 2)真的遇到此类问题,需要快速止损,此案例是加速消费积压任务,上线增加消费进程,通过加资源方式修复此类问题。 3)提前预警可以增加队列内消息生产量、消费量等的阈值监控/报警。
4.3 消息中间件异常导致消息消费失败
原因:Kafka broker有一台机器内存故障,导致新代理一台broker不可用,此时业务发布时报获取元数据超时异常 处理方案: 1)如果公司Kafka等此类公共组件集群发生异常且异常未完全恢复,则不要进行上线等操作 2)当上线服务时发生异常应该立即回滚,而不是为了解决积压消息而全量发布 3)于Kafka组件应该设置开关,如果出现问题可以第一时间关闭相关服务,防止强依赖Kafka导致服务不可用 4)在消费Kafka的业务中不要异步使用自己的线程池,特殊情况会打满线程池 5)上线服务可以将故障Kafka节点从配置中删除,再进行上线重启
4.4 消费者业务流程复杂,业务增长后,生产者流量超出消费者能力
原因:消费者业务流程复杂,生产量达到消费上限后,产生消息积压 处理方案: 1)对partition扩容增加partition数量 2)将消费者代码修改为多线程并发消费 3)提高单条消息的处理速度,如:优化业务流程,增加缓存,去掉耗时操作
4.5 消费者业务流程中存在慢查询
表现:同时存在MySQL慢查询问题、以及Kafka消息积压的问题,大概率属于慢查询导致的Kafka消息积压。 原因:消费逻辑中的写MySQL流程存在由于索引不合理导致的慢查询问题 处理方案:慢查询优化
4.6 消费者依赖第三方服务
原因:回调第三方服务,因第三方接口波动,导致网络慢或者异常,从而影响整体消费端的能力。 处理方案: 1)做好监控,及时反馈,让依赖的三方接口做优化 2)控制生产者生产速度 3)消费者做好过滤,避免重复处理
4.7 消费者组频繁rebalance导致消息积压问题
现象: 1)消息积压有报警 2)从Kafka manager看,该topic有3个分区,尾数A的ip消费了两个分区,尾数B和C的ip来回变换的消费2号分区,消费进度没有任何变化;从 broker 端日志看,该消费组在频繁的进行rebalance 原因: 1)max.poll.records = 20,而 max.poll.interval.ms = 1000,也就是说consumer一次最多拉取 20 条消息,两次拉取的最长时间间隔为 1 秒。 也就是说消费者拉取的20条消息必须在1秒内处理完成,紧接着拉取下一批消息。否则,超过1秒后,Kafka broker会认为该消费者处理太缓慢而将他踢出消费组,从而导致消费组rebalance。 根据Kafka机制,消费组rebalance过程中是不会消费消息的,所以看到ip是B和C轮流拉取消息,又轮流被踢出消费组,消费组循环进行rebalance,消费就堆积了 处理方案:消费者客户端减小 max.poll.records 或 增加 max.poll.interval.ms 。RD 将 max.poll.records 设置为1,重启消费者后消费恢复 补充说明: Rebalance 发生的时机有三个:
- 组成员数量发生变化(新加消费者、删除消费者、消费者重启、消费超时等)
- 订阅主题数量发生变化
- 订阅主题的分区数发生变化
consumer客户端相关参数:
- session.timeout.ms
由于broker服务端设置了参数: group.min.session.timeout.ms = 6000 group.max.session.timeout.ms = 300000 客户端 session.timeout.ms 的值必须介于两者之间
- heartbeat.interval.ms : 通常设置值低于 session.timeout.ms 的 1/3
- max.poll.interval.ms
- max.poll.records
5、常见处理方案总结
5.1 增加消费者并发处理能力
增加消费者数量:通过增加消费者实例数量,分散处理压力。Kafka消费者组内的每个消费者可以从不同的分区并行消费消息。如果当前分区数较多,但消费者数量较少,增加消费者可以提高处理速度。 增加分区数量:如果消息的生产速率非常高且单个消费者处理能力有限,可以通过增加分区的数量来提升并发性。每个分区可以对应一个消费者,使得更多消费者能够同时处理消息。 注意:分区的数量应该和消费者数量相匹配,每个分区只能被一个消费者消费,多增加的消费者无法分配到分区。
5.2 提升消费者的消费能力
批量消费:通过批量获取消息,而不是逐条消费,可以显著提升消费性能。调整消费者的批量拉取大小(max.poll.records)来提高每次拉取的消息量。 异步处理:让消费者异步处理消息,而不是同步处理。例如,处理过程中可以将消息放入一个任务队列,然后由后台线程或其他服务处理。 优化消费者逻辑:分析消费者的业务逻辑,优化耗时操作(如数据库操作、IO操作等)。例如,使用批量插入数据库或优化网络通信等。
5.3 提升Kafka集群性能
增加Kafka集群的资源:如果Kafka集群的性能是瓶颈,可以通过增加Kafka Broker的节点数、提升硬件性能(如磁盘、内存、CPU等)来缓解消息积压。 调整分区副本数量:减少分区副本数量(replication.factor)可以提高生产者和消费者的性能,降低副本同步带来的延迟。不过,副本数的减少可能会降低数据的容错性,需谨慎选择。 网络优化:确保网络带宽和稳定性,避免网络延迟和故障成为瓶颈。 消息分区策略优化:合理配置消息队列的分区数和分区策略,确保负载均衡。 消息大小控制:控制消息的大小,避免因单个消息过大而影响系统性能。
5.4 调整Kafka的配置参数
增加消息保留时间:如果消费者一时无法快速处理积压消息,可以通过增加Kafka的保留时间(log.retention.hours等)来延长消息的保存时间,避免因消息过期而丢失。 优化批量生产和压缩:
- 生产者可以启用批量发送(linger.ms)和消息压缩(compression.type),以减少消息的大小和发送的次数,从而提高消息的传输效率。
- 调整生产者批量大小(batch.size)可以减少频繁的网络请求,从而提高整体效率。
调整消费者拉取策略:例如,调整 max.poll.records 和 fetch.min.bytes 等参数,根据实际情况优化拉取数据的量和频率。
5.5 处理积压历史数据
逐步消费历史积压消息:当消息堆积过多时,可以逐步清理积压。增加消费者处理旧的积压消息,或者专门部署任务来处理积压的历史消息,同时继续让其他消费者处理实时流入的新消息。 临时扩大消费能力:在消费积压时,可以临时增加更多消费者处理积压的数据,待积压处理完毕后再减少消费者数量。
5.6 分离实时数据和历史数据
对于大量积压的消息,可以将消息分为两类:实时数据和历史积压数据。创建两个不同的消费者组,一个专门消费实时数据,另一个专门处理历史数据。这种方式可以确保实时数据不受积压影响。
5.7 流量控制和限流
生产者限流:对生产者的消息发送进行限流,避免生产者发送过快,导致消费者处理不过来。可以在生产者应用层控制流量,或者调整Kafka的生产速度限制参数(如linger.ms)。 消费者限流:控制消费者的拉取速率,避免消费者一次性拉取过多消息导致处理缓慢。
5.8 动态扩展
使用自动扩展工具:根据消费积压的情况,动态调整Kafka集群资源或消费者的数量。一些云服务或容器编排工具(如Kubernetes)可以根据监控的积压情况自动扩展资源。
5.9 数据分流
按业务场景划分Topic:如果一个Topic中包含过多不同业务场景的数据,可以考虑将数据按业务拆分成多个Topic,分别由不同的消费者组来处理。这样可以有效分流,避免积压。
5.10 避免重复消费
在解决积压问题时,消费者可能会多次消费同一条消息。确保消费逻辑具备幂等性,避免因重复消费导致数据错误或不一致。
5.11 监控与告警机制
实时监控:实施实时监控系统,监控关键性能指标如消息积压数、处理延迟、生产速度和消费速度等。 告警系统:设定阈值,一旦发现异常立即触发告警,快速响应可能的问题。
5.12 异常处理机制
错误处理策略:合理设置消息的重试次数和重试间隔,避免过多无效重试造成的额外负担。 死信队列管理:对于无法处理的消息,移动到死信队列,并定期分析和处理这些消息。 参考博文: https://juejin.cn/post/7314509615159885875 如何解决kafka消息积压问题_kafka消息堆积怎么解决-CSDN博客 https://juejin.cn/post/7362783257257050112


