3DGS代码复现项目理解_3dgs使用的是colmap的稀疏重建还是稠密重建
我当时是跟着3D Gaussian Splatting复现-CSDN博客进行的项目复现,本文主要记录一些对3DGS的项目理解。
代码中关键步骤主要是以下两部:
python convert.py -s datapython train.py -s data -m data/output一、convert.py
其中convert.py中流程大致可分为以下五步
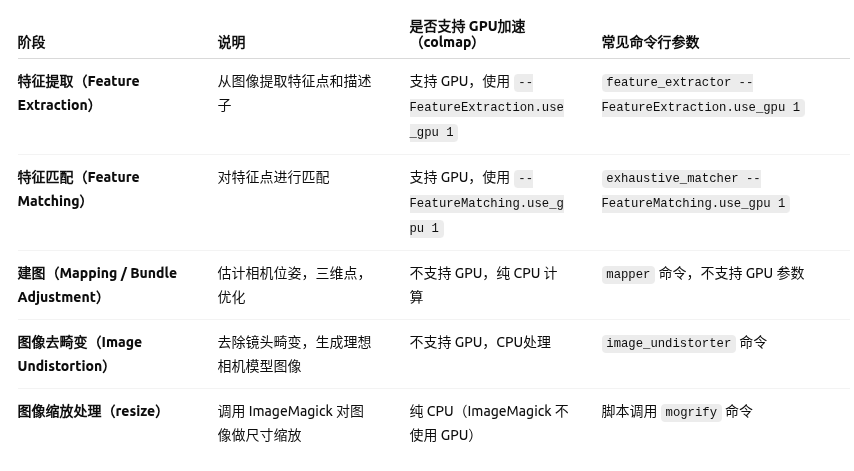
以上前四步都是对colmap的调用,其中前两部可以调用gpu,后三部纯cpu运算。
第一步、特征提取
从输入图像中提取特征点,将图像元信息(大小、相机)、关键点、描述子写入database.db

第二部、特征匹配
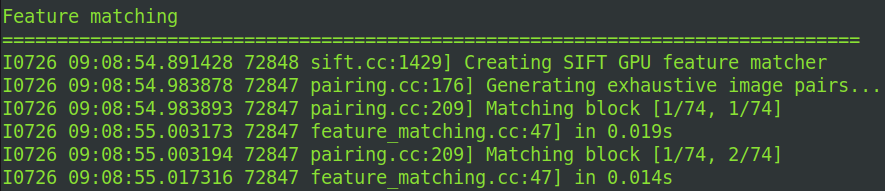
在不同图像间匹配特征点,将图像对之间的匹配信息(匹配点对)写入database.db。我当时很好奇为什么我输入了3669张图,但是进行匹配的时候只有74张,后来了解到这是COLMAP在特征匹配阶段将图像对分组后的 块数量(Blocks),用于 并行匹配优化,而非筛选后的图像数。74是分块数量,由COLMAP根据图像数量和硬件资源自动计算得出。COLMAP的 Exhaustive Matching(穷举匹配) 会:
- 计算所有可能的图像对:对于3669张图,理论上有
3669×3668/2 ≈ 6.7百万对需要匹配。 - 分块处理:为避免内存爆炸和加速匹配,COLMAP将图像对划分为多个块(Blocks),每个块包含一定数量的图像对:
- 日志中的
Matching block [1/74, 1/74]表示当前正在匹配 第1个块与第1个块 的图像对。 - 这里的 74×74 是分块策略的结果(总块数=74,每个块包含约
3669/74≈50张图像)。
- 日志中的
避免一次性加载所有特征点导致OOM(尤其对GPU内存)。便于并行加速,不同块可分配到多个线程或GPU核心同时处理。
 第三部、稀疏建图
第三部、稀疏建图
COLMAP 使用 Ceres Solver (非线性优化库)来执行非线性最小二乘优化,而 Ceres 是一个 纯 CPU 的库。稀疏重建是COLMAP的核心步骤,通过 捆绑调整(Bundle Adjustment, BA) 同时优化相机位姿和3D点云坐标。其实现流程如下:
(1) 输入数据准备
- 特征点匹配结果:从
database.db中加载图像间的特征匹配关系。 - 初始相机参数:由特征提取阶段估计的焦距、畸变等内参。
(2) 增量式重建流程
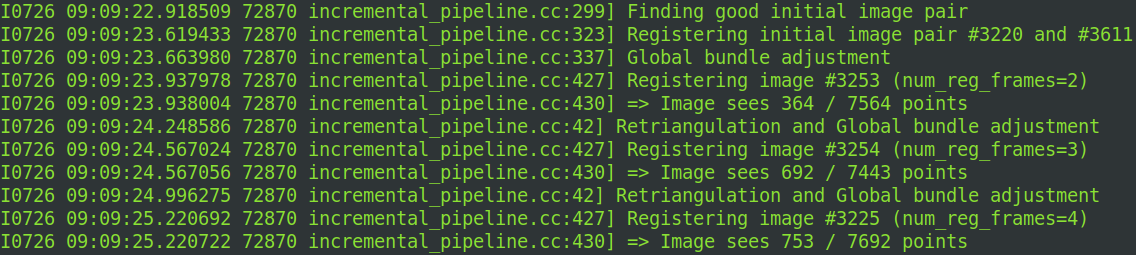
- 初始化:
- 选择匹配点数最多的两幅图像作为初始帧,通过对极几何计算基础矩阵,三角化生成初始3D点云。
- 注册新图像:
- 通过PnP(Perspective-n-Point)算法将新图像与现有3D点云对齐,估计相机位姿。
- 关键指标:如图片2所示,
Image sees 352/1257 points表示当前图像与现有点云的匹配点数(352个匹配点中需至少6个有效点才能成功注册)。
- 三角化新点:
- 对新注册图像中未匹配的特征点进行三角化,扩展3D点云。
- 局部BA(Local Bundle Adjustment):
- 优化当前注册图像及其关联的3D点,减少累计误差。
- 全局BA(Global Bundle Adjustment):
- 所有图像和点云参与优化,使用非线性最小二乘法(如Levenberg-Marquardt算法)最小化重投影误差。
运行时还曾出现过两个报错,大致都是由于数据集部分图像特征点少、误差大引起的,少许报错对整体建图影响不大。

- 原因:
- 数值不稳定:BA的雅可比矩阵条件数过大,导致Eigen库无法进行乔列斯基分解(要求矩阵正定)。
- 常见诱因:
- 存在 退化场景(如所有特征点共面或共线)。
- 相机位姿初始值误差过大(如PnP失败后强行注册)。
- 特征匹配存在大量误匹配(噪声干扰)。
![]()
- 原因:
- PnP求解失败:当前图像(#2516)与现有点云的匹配点不足或分布不佳(如所有点集中在图像边缘)。
- 阈值分析:
- COLMAP默认要求至少6个2D-3D匹配点才能尝试PnP,且需满足RANSAC内点比例。
- 虽然显示有352个匹配点,但可能因噪声或遮挡导致有效内点不足。
第四部、图像去畸变
校正镜头畸变(如桶形畸变、枕形畸变),确保图像几何形状准确,为后续稠密重建提供无畸变输入。COLMAP 中图像处理基于 OpenCV(默认后端),OpenCV 默认图像操作(cv::remap, cv::warpAffine, cv::undistort)使用 CPU,此部分计算比较简单,耗时较短。
第五步、可选的多尺度图像生成
为MVS(多视图立体)提供不同分辨率的输入,平衡重建精度与计算效率。调用的 mogrify -resize 来批量压缩图像分辨率是 ImageMagick 命令,用于降低分辨率,加快建图。虽然有第三方 GPU 插件(如 OpenCL backend),但默认 Ubuntu 系统中的 ImageMagick 没启用这些模块。
二、train.py
优化每个高斯点的属性,使它们通过体积渲染方式能够尽可能逼真地重建输入图像的视图,在多个图像视角下,用渲染重投影图去逼近真实图像,通过不断优化每个高斯点属性,实现对整个3D场景的高保真建模。
1️⃣ 初始化准备
关键操作:
-
解析命令行参数(如
--source_path、--model_path、--iterations等) -
初始化日志、TensorBoard、随机种子
-
创建
GaussianModel和优化器
消耗资源情况:
📉 算力低,主要为CPU初始化工作。
2️⃣ 数据加载与Scene构建
关键操作:
-
使用
Scene(dataset, gaussians)加载 COLMAP 重建得到的相机信息和稠密点云 -
构建训练摄像机
scene.getTrainCameras()和高斯点模型
消耗资源情况:
📉 算力中等
-
需要将大量图像(原始图像 + depth、mask等)加载进 GPU,容易导致:
-
CUDA OOM(Out Of Memory)错误
-
初始显存占用过高
-
🔽 输入路径:
-
来自
-s data指定的数据路径:data/
├── images/ ← 原始输入图像
├── sparse/0/ ← COLMAP生成的 .bin 文件
│ ├── cameras.bin
│ ├── images.bin
│ └── points3D.bin
├── depth/(可选) ← 单目深度图(可选)
├── masks/(可选) ← alpha masks(可选)
└── transformed.json(可选) ← NeRF-Synthetic 格式支持
🔼 输出(内存对象):
-
Scene对象:-
所有训练相机(list of
Camera) -
相机信息(内参、外参、分辨率)
-
-
每个
Camera:-
.original_image→ 图像 tensor(来自images/) -
.R,.T,.K→ 相机姿态 + 内参 -
.depth,.mask(如存在)
-
3️⃣ 主训练循环
for iteration in range(first_iter, opt.iterations + 1):每轮训练中做的主要事情:
-
随机选取一个相机视角
-
用当前高斯模型进行渲染(
render()) -
与GT图像进行损失计算
-
根据损失反向传播
-
执行优化器 step() 更新高斯参数
渲染细节:
-
位于
render_pkg = render(...) -
会输出:
-
图像
-
可见点 mask
-
视空间点分布
-
半径等几何信息
-
消耗资源情况:
⚠️ 训练阶段显存消耗最大!
-
原因:
-
渲染过程需要构建高斯混合模型并投影到图像平面
-
高斯点数量多、SH系数高(如
sh_degree=3时是 16 通道) -
每张图分辨率高 × 图像 + 深度 + mask × FP32 载入 GPU
-
-
常见报错:
-
torch.cuda.OutOfMemoryError: Tried to allocate X MiB
-
示例:
image = render(viewpoint_cam, gaussians, pipe, bg)[\"render\"] loss = l1_loss(image, gt_image) loss.backward()🔽 输入:
-
从
Scene.getTrainCameras()中选一个相机 -
当前高斯点信息
-
渲染参数(
PipelineParams)
🔼 输出:
-
中间渲染结果(内存中):
render_pkg = { \"render\": torch.Tensor(C, H, W), ← 渲染图像 \"depth\": torch.Tensor(H, W), ← 渲染深度图 \"viewspace_points\": Tensor(N, 3), ← 可见点坐标 \"visibility_filter\": BoolTensor(N), ← 哪些点可见 \"radii\": Tensor(N), ← 点投影半径}
4️⃣ 损失计算与优化
损失包含:
-
L1损失
l1_loss(image, gt_image) -
SSIM损失(结构相似度)
-
可选:深度损失(invdepth 与 GT 深度图)
优化器:
-
Adam或SparseAdam(可选) -
同时优化:
-
高斯位置、形状、方向、透明度、SH颜色、曝光量
-
消耗资源情况:
🔁 计算显存中等偏高,取决于损失组件是否启用、是否启用depth监督
5️⃣ 可视化与检查点保存
每隔 --save_iterations 进行:
-
保存当前高斯模型状态为
.pth -
可选:渲染结果保存图像用于可视化
-
可选:记录到 TensorBoard
示例:
if iteration in saving_iterations: scene.save(iteration)消耗资源情况:
📉 I/O密集型,GPU负载较低,但可能会卡顿(取决于模型大小)
📁 最终完整点云保存(含可视化):
data/output/iteration_7000/
├── point_cloud/
│ ├── point_cloud.ply ← 高斯点导出
│ └── stats.txt ← 点数量等统计
└── renders/
├── train_view_*.png ← 可视化图像
└── test_view_*.png

