「源力觉醒 创作者计划」_文心大模型 4.5 多模态实测:开源加速 AI 普惠落地
「源力觉醒 创作者计划」_文心大模型 4.5 多模态实测:开源加速 AI 普惠落地
- 一、写在前面:开源模型的价值,是可用、可复现、可落地
- 二、功能亮点:结合百度文库知识底座,打造真实可用的教育应用
-
- 2.1 百度文库的知识库
- 2.2 构建任务链
- 三、评测环境:基于飞桨星河社区,部署门槛极低
-
- 3.1 环境配置
- 3.2 fastdeploy部署文心大模型
-
- ① fastdeploy环境
- ② 模型下载
- 3.3 调用接口
- 四、场景实测:多模态能力落地教育应用
-
- 场景一:图文题目自动理解与知识提取
-
- ① 识别图片格式的题目
- ② 进一步:生成5道不同类型的题目
- 场景二:理科类个性化题目生成
- 场景三:文科类学科教育场景
- 五、项目效果总结
-
- 5.1 响应速度与性能测试
- 5.2 优势亮点与优化建议
- 六、开源之路的意义:从可复现到可用的进化
- 七、文末致谢
一起来轻松玩转文心大模型吧一文心大模型免费下载地址:https://ai.gitcode.com/paddlepaddle/ERNIE-4.5-VL-424B-A47B-Paddle
🎯关键词:文心大模型 4.5|开源|FastDeploy|多模态|教育场景|星河社区|GitCode|PaddlePaddle

🌈你好呀!我是 是Yu欸 🚀 感谢你的陪伴与支持~ 欢迎添加文末好友 🌌 在所有感兴趣的领域扩展知识,不定期掉落福利资讯(*^▽^*)
一、写在前面:开源模型的价值,是可用、可复现、可落地
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
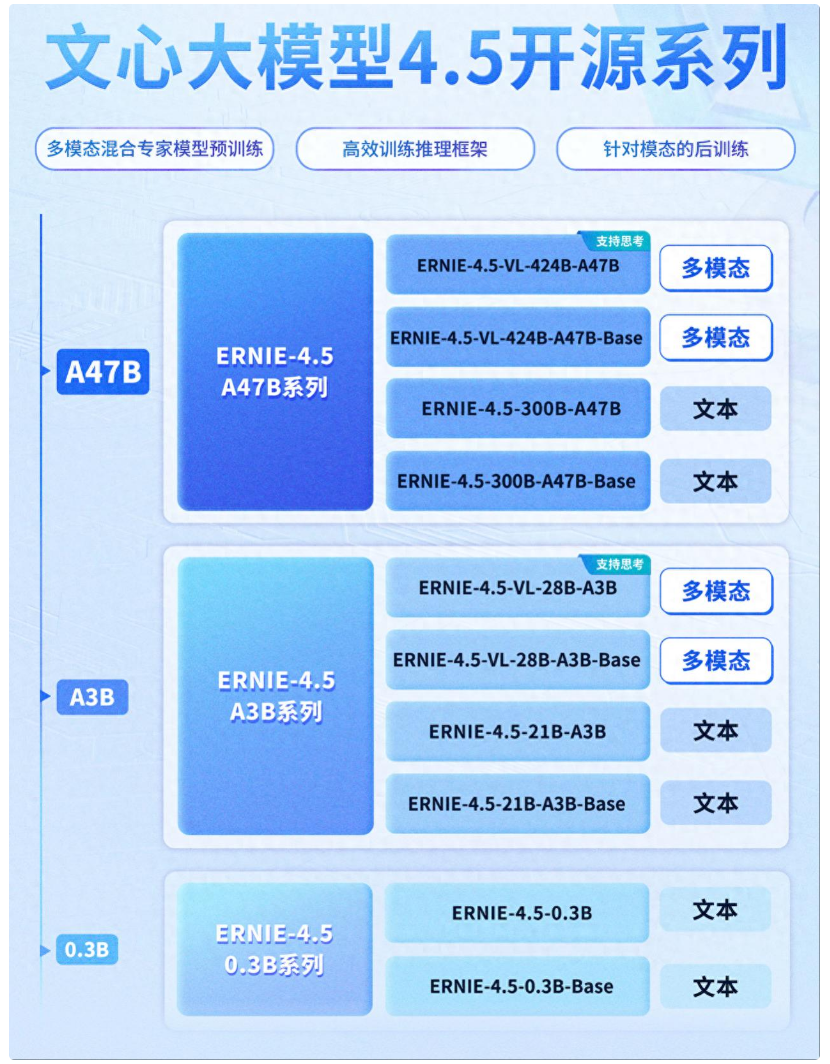
2025年6月30日,百度正式在 GitCode 平台开源了文心大模型 4.5 系列,包括文本、多模态等多个子模型,全面支持推理、微调、API调用和私有化部署。
作为第一批体验者,我在飞桨星河社区使用 FastDeploy 工具完成了 ERNIE-4.5-VL 的多模态推理部署,并搭建了一个「教育场景下的多模态问答生成系统」,包含:
- 题目图片识别 ➜ 学科/知识点分类 ➜ 个性化生成新题
- 支持教师视角设置题目数量、难度和风格
- 评测多模态理解、响应速度、部署难度和实际教学价值
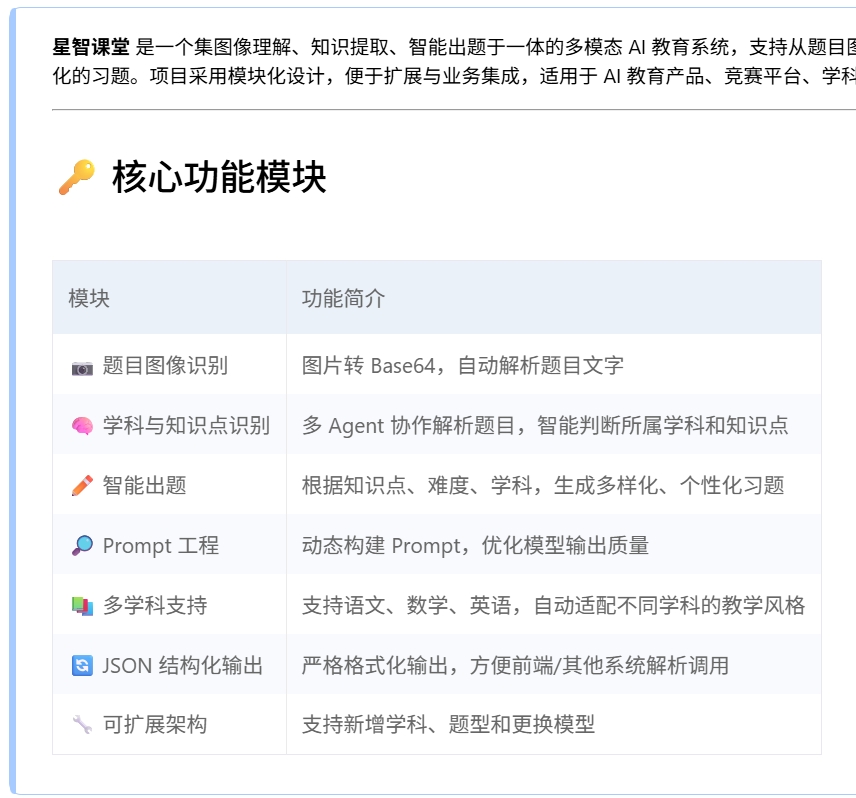
主要功能模块:
- ERNIE-VL FastDeploy 接口封装
- 图像 ➜ base64 ➜ Prompt 输入流程构建
- JSON 格式内容解析与题目结构校验
- 教师视角参数配置:知识点、题目数、难度等级
项目已经开源,感兴趣的朋友可以前往https://aistudio.baidu.com/projectdetail/9352000 直接运行 ~
本篇文章将以真实工程实践视角,为大家详细分享这个过程,聊聊开源模型的真正意义和落地路径。
二、功能亮点:结合百度文库知识底座,打造真实可用的教育应用
2.1 百度文库的知识库
文心大模型背靠百度文库强大的知识库,模型训练语料包含大量优质题库、教辅文本、教研素材等,在教育领域具备天然优势。
我之前被gpt误导了,于是测试过各大模型,只有文心一言在该场景下回答对了这个问题。推测可能源于其百度知识库的构建。
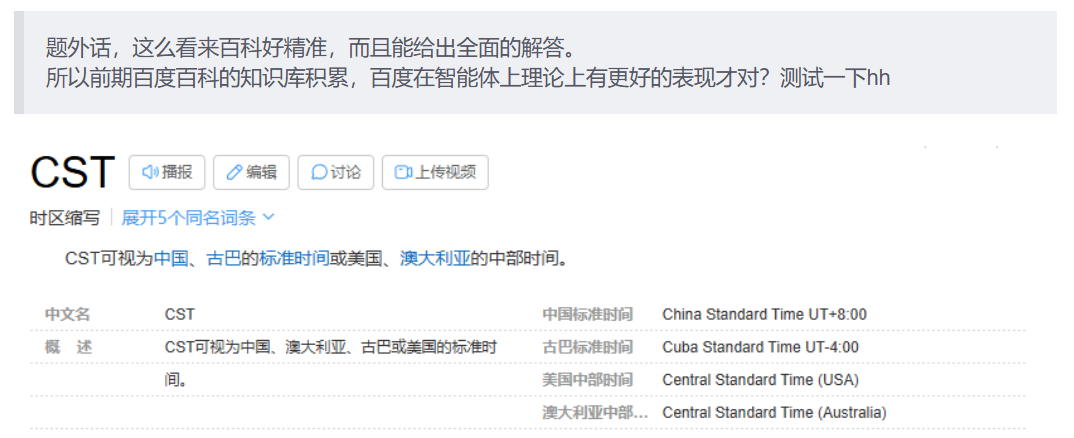
感兴趣的朋友可以查看:【ccfddl-ICML投稿时间确认】CST是China Standard Time,不是默认的Central Standard Time。了解时区:北京时间(CST)、UTC-0 和 UTC-12

2.2 构建任务链
我们基于此,构建了如下任务链:
📌 任务 1:题目图片识别与知识分类
- 支持上传学生题目截图或照片(如物理题图)
- 模型可自动识别图像中文字内容
- 提取学科类别(如物理)和核心知识点(如“机械运动”)
- 转为结构化语义信息作为 Prompt 输入下一阶段任务
📌 任务 2:个性化习题自动生成
-
基于知识点,模型可生成指定数量、难度和风格的题目
-
返回标准化 JSON 格式,包括:
{ \"question\": \"题目内容\", \"answer\": \"标准答案\", \"explanation\": \"详细解析\"} -
支持多题型混合输出(选择题、计算题、填空题等)
-
可指定学生水平(基础 / 中等 / 进阶)自动调整复杂度和讲解深度
📌 多模态交互体验极佳:
- 图像 ➜ 知识结构 ➜ 内容生成 的能力链条清晰
- 相比文心 4.0,多模态识别和上下文联动更强
- Prompt 工程效果显著,定制化生成质量高
三、评测环境:基于飞桨星河社区,部署门槛极低
3.1 环境配置
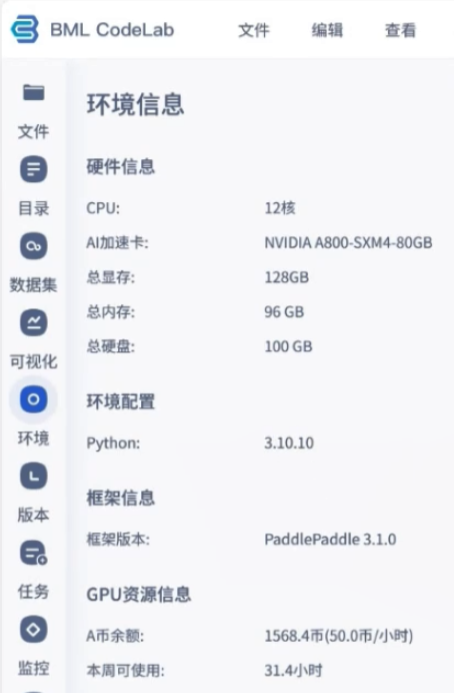
本次全部评测在百度飞桨官方提供的【星河社区】完成,平台内集成了高性能推理硬件和丰富开发资源,对没有本地 A100 的开发者非常友好。
📌 测试环境配置:
- CPU:12 核高性能处理器
- AI 加速卡:NVIDIA A800-SXM4-80GB
- 显存:128 GB
- 内存:96 GB
- 磁盘空间:100 GB
- Python:3.10.10
- 框架:PaddlePaddle 3.1.0
使用 FastDeploy 部署 ERNIE-VL,仅需几行命令即可完成服务启动。支持 RESTful API 和 Web 服务接口,文档完备、配置清晰,部署用时<5分钟,真正做到了开箱即用。
3.2 fastdeploy部署文心大模型
① fastdeploy环境
FastDeploy 官方文档:https://paddlepaddle.github.io/FastDeploy/get_started/installation/nvidia_gpu/
!python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/# FastDeploy 预构建的 pip 安装(目前只支持 SM80/90 架构的 GPU(例如 A100/H100))!python -m pip install fastdeploy-gpu -i https://www.paddlepaddle.org.cn/packages/stable/fastdeploy-gpu-80_90/ --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
# 安装后,使用以下 Python 代码验证环境import paddlefrom paddle.jit.marker import unified# Verify GPU availabilitypaddle.utils.run_check()# Verify FastDeploy custom operators compilationfrom fastdeploy.model_executor.ops.gpu import beam_search_softmax/opt/conda/envs/python
② 模型下载
(在社区的模型库进行相应的模型查询,里面有对应的下载和部署命令)
通过 FastDeploy 部署 ERNIE4.5-VL-424B-A47B 的文档:https://paddlepaddle.github.io/FastDeploy/get_started/ernie-4.5-vl/
(wint4 量化)ERNIE4.5-VL-424B-A47B 需要用到 8 张 80G 的 A100/H100 GPU,显然满足不了条件,因此选择使用 ERNIE-4.5-VL-28B-A3B-Paddle 版本。
下载,然后用下面的python -m下载配置个性化的大模型。
需要修改为本地目录,刚刚ERNIE-4.5-VL-28B-A3B-Paddle模型下载好的位置
# !aistudio download --model PaddlePaddle/ERNIE-4.5-0.3B-Paddle --local_dir /home/aistudio/work/models# ERNIE-4.5-VL-424B-A47B-Paddle# !aistudio download --model PaddlePaddle/ERNIE-4.5-VL-424B-A3B-Paddle --local_dir /home/aistudio/work/models# PaddlePaddle/ERNIE-4.5-VL-28B-A3B-Paddle!aistudio download --model PaddlePaddle/ERNIE-4.5-VL-28B-A3B-Paddle --local_dir /home/aistudio/work/models/ERNIE-4.5-VL-28B-A3B-Paddle# !aistudio download --model PaddlePaddle/ERNIE-4.5-VL-28B-A3B-Paddle --local_dir /home/aistudio/work/modelsProcessing 22 items: 100%|███████████████████| 22.0/22.0 [00:01<00:00, 17.6it/s]
下面第一个是官方的,由于模型很大,所以加载需要时间。
我们可以限制条件,让模型更小,从而加载更快
注意,这个在后面运行代码过程中,不能中断。否则会连接不上
所以在终端直接运行即可
!python -m fastdeploy.entrypoints.openai.api_server \\ --model /home/aistudio/work/models/ERNIE-4.5-VL-28B-A3B-Paddle \\ --port 8180 \\ --metrics-port 8181 \\ --engine-worker-queue-port 8182 \\ --max-model-len 32768 \\ --enable-mm \\ --reasoning-parser ernie-45-vl \\ --max-num-seqs 32下面的模型部署命令在终端运行
验证服务状态 curl -i http://0.0.0.0:8180/health
第一个,为前面的python -m中断后运行的结果,连接不上
第二个,返回结果为 HTTP 200 为正常
!curl -i http://0.0.0.0:8180/health
3.3 调用接口
它是兼容OpenAI的API,所以如果使用Python调用的话,可以使用openai库来调用,不需要指定模型名称和api_key。
多模态输入需要提供一个额外的字段type来指明当前输入的类型。
Tpis:
大模型每一次调用都是无状态的,需要自行管理传入给模型的信息。如果需要模型多次理解同一张图像,请在每次请求时都传入该图。
支持单图和多图,每一张图片大小不超过10MB,多张图片输入的总token不超过模型上下文长度。如ERNIE-4.5模型,不超过8K token的图片输入。 图片格式:
图片base64:JPG、JPEG、PNG和BMP类型,传入的格式需为:data:image/;
base64,
图片公网url:支持JPG、JPEG、PNG、BMP和WEBP类型
content 支持多个输入,放多张图片也是没问题的
base64 编码是为了读取本地图片
import openaihost = \"127.0.0.1\"port = \"8180\"client = openai.Client(base_url=f\"http://{host}:{port}/v1\", api_key=\"null\")print(\"ok!\")response = client.chat.completions.create( model=\"null\", # 模型名称,此处为空字符串,表示使用默认模型 # 单模态大模型 # OpenAI API 只支持以下角色:\"system\"\\\"user\"\\\"assistant\" # messages=[ # {\"role\": \"system\", \"content\": \"你是专业的教育专家,擅长根据知识点生成高质量的习题和解析。\"}, # ], # 多模态大模型,需要指明当前输入的模态 messages=[ { \'role\': \'system\', \'content\': [ { \"type\": \"text\", \"text\": \"你是专业的教育专家,擅长根据知识点生成高质量的习题和解析。\" } ] }, { \'role\': \'user\', \'content\': [ { \"type\": \"text\", \"text\": \"请根据“牛顿第二定律”生成一道物理题。\" } ] }, ], stream=True, # 流式返回)for chunk in response: if chunk.choices[0].delta: print(chunk.choices[0].delta.content, end=\'\', flush=True)print(\'\\n\')# 非流式# print(completion.choices[0].message.content or \"\")下面是实测的输出结果:
ok!### 物理题:牛顿第二定律应用**题目** 一个质量为5kg的物体在水平桌面上运动,受到水平向右的拉力为10N,同时受到与运动方向相反的摩擦力为2N。求: 1. 物体的加速度大小; 2. 若保持拉力不变,要使物体产生3m/s²的加速度,摩擦力需要调整为多少?---### **解析与解答**#### **步骤1:计算物体在初始条件下的加速度** 根据牛顿第二定律 \\( F_{\\text{合}} = ma \\),需先求合力: - 拉力 \\( F_{\\text{拉}} = 10\\,\\text{N} \\)(向右),摩擦力 \\( F_{\\text{摩}} = 2\\,\\text{N} \\)(向左)。 - 合力 \\( F_{\\text{合}} = F_{\\text{拉}} - F_{\\text{摩}} = 10\\,\\text{N} - 2\\,\\text{N} = 8\\,\\text{N} \\)。 - 代入公式 \\( a = \\frac{F_{\\text{合}}}{m} \\),得: \\[ a = \\frac{8\\,\\text{N}}{5\\,\\text{kg}} = 1.6\\,\\text{m/s}^2 \\] **答案**:加速度为 \\( 1.6\\,\\text{m/s}^2 \\)。---#### **步骤2:调整摩擦力以产生目标加速度** 已知目标加速度 \\( a\' = 3\\,\\text{m/s}^2 \\),拉力仍为 \\( 10\\,\\text{N} \\),设新摩擦力为 \\( F_{\\text{摩}}\' \\)。 - 合力 \\( F_{\\text{合}}\' = ma\' = 5\\,\\text{kg} \\times 3\\,\\text{m/s}^2 = 15\\,\\text{N} \\)。 - 合力表达式为 \\( F_{\\text{合}}\' = F_{\\text{拉}} - F_{\\text{摩}}\' \\),代入得: \\[ 15\\,\\text{N} = 10\\,\\text{N} - F_{\\text{摩}}\' \\implies F_{\\text{摩}}\' = 10\\,\\text{N} - 15\\,\\text{N} = -5\\,\\text{N} \\] - 负号表示摩擦力方向需改为**向右**(与运动方向相同),但题目仅问大小,故摩擦力需调整为 \\( 5\\,\\text{N} \\)(向右)。 **答案**:摩擦力需调整为 \\( 5\\,\\text{N} \\)(与运动方向相同)。---### **关键考点** 1. **合力计算**:明确力的方向(矢量相减)。 2. **公式应用**:灵活使用 \\( F_{\\text{合}} = ma \\) 变形求解。 3. **物理意义**:理解摩擦力方向变化对运动的影响。 此题通过基础情境巩固学生对牛顿第二定律的理解,并渗透矢量运算和问题建模能力。四、场景实测:多模态能力落地教育应用
场景一:图文题目自动理解与知识提取
上传一张初中物理题目的截图,模型通过 OCR + 文本理解流程,准确识别出题目内容并自动归类为:
- 学科:物理
- 知识点:机械运动
① 识别图片格式的题目
import openaiimport jsondef init_client(host=\"127.0.0.1\", port=\"8180\", api_key=\"null\"): \"\"\" 初始化 ERNIE-VL 客户端 \"\"\" client = openai.Client(base_url=f\"http://{host}:{port}/v1\", api_key=api_key) print(\"✅ ERNIE-VL 客户端初始化完成\") return clientdef build_prompt(knowledge_point): \"\"\" 构建规范的 prompt,避免模型输出污染 \"\"\" prompt = f\"\"\"请基于知识点“{knowledge_point}”,生成 1 道高质量的物理计算题,包含完整的题目、标准答案和详细解析。输出格式为 JSON,不要包含任何代码块、注释或额外说明,只输出以下结构:[ {{ \"question\": \"题目内容\", \"answer\": \"正确答案\", \"explanation\": \"详细解题步骤\" }}]⚠️ 严禁输出 Python、JSON、Markdown 代码块,直接输出 JSON。\"\"\" return prompt.strip()def generate_exercise(client, knowledge_point=\"牛顿第二定律\"): \"\"\" 生成一道基于知识点的习题 \"\"\" prompt = build_prompt(knowledge_point) try: response = client.chat.completions.create( model=\"ernie-4.5-vl-28b-a3b\", messages=[ {\"role\": \"system\", \"content\": \"你是专业的教育专家,擅长基于知识点生成规范的习题和解析。\"}, {\"role\": \"user\", \"content\": prompt}, ], stream=False, max_tokens=1024, temperature=0.3, ) result_text = response.choices[0].message.content print(\"\\n=== 原始响应 ===\\n\", result_text) # 提取 JSON 数组 start = result_text.find(\"[\") end = result_text.rfind(\"]\") + 1 json_str = result_text[start:end] # 解析 JSON exercises = json.loads(json_str) # 简单结构校验 valid_exercises = [] for ex in exercises: if all(k in ex for k in (\"question\", \"answer\", \"explanation\")): valid_exercises.append({ \"question\": ex[\"question\"].strip(), \"answer\": ex[\"answer\"].strip(), \"explanation\": ex[\"explanation\"].strip(), }) return valid_exercises except json.JSONDecodeError as e: print(f\"\\n❌ JSON 解析失败: {e}\") print(\"响应内容:\\n\", result_text) return [] except Exception as e: print(f\"\\n❌ 习题生成失败: {e}\") return []def main(): # 初始化客户端 client = init_client() # 生成习题 exercises = generate_exercise(client, knowledge_point=\"牛顿第二定律\") # 打印习题 for i, ex in enumerate(exercises, 1): print(f\"\\n习题 {i}:\") print(f\"问题: {ex[\'question\']}\") print(f\"答案: {ex[\'answer\']}\") print(f\"解析: {ex[\'explanation\']}\")if __name__ == \"__main__\": main()输入图片:

输出结果:
✅ ERNIE-VL 客户端初始化完成=== 原始响应 === [ { \"question\": \"一个质量为2 kg的物体受到两个水平力的作用:一个向右的力10 N,一个向左的力4 N。求物体的加速度大小和方向。\", \"answer\": \"加速度为3 m/s²,方向向右。\", \"explanation\": \"首先,计算物体所受的合外力。由于两个力方向相反,合外力为两个力的差值:F = 10 N - 4 N = 6 N,方向向右。然后,应用牛顿第二定律F = ma,其中F是合外力,m是物体的质量,a是加速度。将已知数值代入公式:6 N = 2 kg × a,解得a = 3 m/s²。因此,加速度的大小为3 m/s²,方向与合外力方向相同,即向右。\" }]习题 1:问题: 一个质量为2 kg的物体受到两个水平力的作用:一个向右的力10 N,一个向左的力4 N。求物体的加速度大小和方向。答案: 加速度为3 m/s²,方向向右。解析: 首先,计算物体所受的合外力。由于两个力方向相反,合外力为两个力的差值:F = 10 N - 4 N = 6 N,方向向右。然后,应用牛顿第二定律F = ma,其中F是合外力,m是物体的质量,a是加速度。将已知数值代入公式:6 N = 2 kg × a,解得a = 3 m/s²。因此,加速度的大小为3 m/s²,方向与合外力方向相同,即向右。② 进一步:生成5道不同类型的题目
随后,模型根据知识点生成 5 道不同类型的习题(包括选择、填空、计算题),每道题附带答案与详细解析,展现出良好的教育知识图谱联动能力。
import osimport base64import jsonimport re# 图片转 Base64def img2base64(image_path: os.PathLike) -> str: if not os.path.exists(image_path): raise FileNotFoundError(f\"找不到图片: {image_path}\") with open(image_path, \"rb\") as f: return base64.b64encode(f.read()).decode(\"utf-8\")# 通过图片分析学科和知识点def analyze_image(client, image_path): suffix = os.path.splitext(image_path)[-1][1:] or \"png\" img64 = img2base64(image_path) img_data_url = f\"data:image/{suffix};base64,{img64}\" prompt = \"请根据题目图片内容,判断所属学科和知识点,并只用 JSON 格式返回:\" \\ \"{\\\"subject\\\": \\\"学科名称\\\", \\\"knowledge_points\\\": \\\"对应知识点\\\"},不要输出多余的解释。\" response = client.chat.completions.create( model=\"ernie-4.5-vl-28b-a3b\", messages=[ { \"role\": \"user\", \"content\": [ {\"type\": \"text\", \"text\": prompt}, {\"type\": \"image_url\", \"image_url\": {\"url\": img_data_url}} ] } ] ) content = response.choices[0].message.content.strip() print(\"\\n📷 图像识别原始返回:\", content) # 提取 JSON match = re.search(r\'\\{.*?\\}\', content, re.DOTALL) if not match: raise ValueError(\"未找到有效 JSON\") info = json.loads(match.group()) return info.get(\"subject\", \"\").strip(), info.get(\"knowledge_points\", \"\").strip()# 生成个性化习题(直接复用你之前优化的 generate_personalized_exercises)def generate_personalized_exercises(client, subject, knowledge_points, student_level=\"中等\", num_exercises=5): # 学科角色描述 subject_roles = { \"语文\": \"你是一位资深语文老师,专注古诗词、阅读、写作等地方。\", \"数学\": \"你是一位资深数学老师,精通代数、几何、函数等地方。\", \"英语\": \"你是一位资深英语老师,擅长语法、词汇、阅读、写作等地方。\", \"物理\": \"你是一位资深物理老师,擅长力学、电学、热学、光学等知识点的教学。\", \"化学\": \"你是一位资深化学老师,擅长元素、反应、实验等知识点的教学。\", } system_role = subject_roles.get(subject, \"你是一位资深教师,擅长本学科知识点教学。\") # 构建 Prompt prompt = f\"\"\"根据以下要求生成高质量 {subject} 习题:- 知识点:{knowledge_points}- 学生水平:{student_level}- 题目数量:{num_exercises}- 格式:[ {{ \"question\": \"题目内容\", \"answer\": \"正确答案\", \"explanation\": \"详细解析\" }}]要求:- 题型多样(选择题、填空题、计算题等)- 答案准确,解析详细- 输出完整 JSON,不能包含多余文字\"\"\" response = client.chat.completions.create( model=\"ernie-4.5-vl-28b-a3b\", messages=[ {\"role\": \"system\", \"content\": system_role}, {\"role\": \"user\", \"content\": prompt} ], max_tokens=2048, temperature=0.3 ) content = response.choices[0].message.content.strip() print(\"\\n🎯 习题生成原始返回:\", content) # 解析 JSON match = re.search(r\'\\[\\s*\\{.*?\\}\\s*\\]\', content, re.DOTALL) if not match: raise ValueError(\"未找到有效 JSON 数组\") exercises = json.loads(match.group()) # 清洗 return [ { \"question\": ex[\"question\"].strip(), \"answer\": ex[\"answer\"].strip(), \"explanation\": ex[\"explanation\"].strip() } for ex in exercises if all(k in ex for k in [\"question\", \"answer\", \"explanation\"]) ]# 综合调用def main(client, image_path, student_level=\"中等\", num_exercises=3): subject, knowledge_points = analyze_image(client, image_path) print(f\"\\n✅ 识别结果:学科 - {subject}, 知识点 - {knowledge_points}\") exercises = generate_personalized_exercises( client=client, subject=subject, knowledge_points=knowledge_points, student_level=student_level, num_exercises=num_exercises ) # 输出习题 for i, ex in enumerate(exercises, 1): print(f\"\\n习题 {i}:\") print(f\"问题: {ex[\'question\']}\") print(f\"答案: {ex[\'answer\']}\") print(f\"解析: {ex[\'explanation\']}\")# 示例调用if __name__ == \"__main__\": client = init_client() # 你的初始化代码 main(client, image_path=\"work/物理-机械运动.png\")输出结果:
✅ ERNIE-VL 客户端初始化完成📷 图像识别原始返回: { \"subject\": \"物理\", \"knowledge_points\": \"机械运动的相对性\"}_解析:题目围绕机械运动的基本概念及参照物选择展开,核心知识点为运动与静止的相对性(参照物选择对判断运动状态的影响),属于物理学中力学的基础内容。_✅ 识别结果:学科 - 物理, 知识点 - 机械运动的相对性🎯 习题生成原始返回: [ { \"question\": \"坐在行驶的汽车里,以汽车为参考系,乘客的运动状态是?\\nA. 静止\\nB. 加速运动\\nC. 匀速直线运动\\nD. 变速运动\", \"answer\": \"A\", \"explanation\": \"机械运动的相对性表明,物体的运动状态取决于所选参考系。当以运动的汽车为参考系时,乘客与汽车保持相对静止,因此乘客相对于汽车是静止的。即使汽车实际在行驶,在乘客的参考系中不会感受到自身运动,这是参考系选择的关键特性。\" }, { \"question\": \"两辆汽车分别以速度5m/s向东和3m/s向西行驶,若以向东为正方向,则两车的相对速度为?\", \"answer\": \"8m/s\", \"explanation\": \"机械运动相对性要求明确参考系。本题以向东为正方向时,东向汽车速度为+5m/s,西向汽车速度为-3m/s。相对速度计算为两者速度差(考虑方向),即5 - (-3) = 8m/s。这表明在选定正方向后,相对速度需通过矢量运算确定,体现参考系对物理量描述的决定性作用。\" }, { \"question\": \"一列火车以20m/s速度行驶,车上一乘客以5m/s速度向车尾行走。若以地面为参考系,求乘客相对于地面的速度表达式。当t=10s时,乘客相对于地面的位移是多少?(假设火车长度L=200m)\", \"answer\": \"15m/s;150m\", \"explanation\": \"根据运动相对性,乘客相对于地面的速度等于火车速度减去乘客相对于火车的速度。若火车向正方向行驶,乘客向车尾(负方向)行走,则乘客相对于地面速度为20m/s - 5m/s = 15m/s。位移计算为速度乘以时间,即15m/s × 10s = 150m。此例说明,即使乘客在火车内部运动,其相对于地面的运动仍需通过参考系转换分析,体现运动描述的相对性本质。\" }]习题 1:问题: 坐在行驶的汽车里,以汽车为参考系,乘客的运动状态是?A. 静止B. 加速运动C. 匀速直线运动D. 变速运动答案: A解析: 机械运动的相对性表明,物体的运动状态取决于所选参考系。当以运动的汽车为参考系时,乘客与汽车保持相对静止,因此乘客相对于汽车是静止的。即使汽车实际在行驶,在乘客的参考系中不会感受到自身运动,这是参考系选择的关键特性。习题 2:问题: 两辆汽车分别以速度5m/s向东和3m/s向西行驶,若以向东为正方向,则两车的相对速度为?答案: 8m/s解析: 机械运动相对性要求明确参考系。本题以向东为正方向时,东向汽车速度为+5m/s,西向汽车速度为-3m/s。相对速度计算为两者速度差(考虑方向),即5 - (-3) = 8m/s。这表明在选定正方向后,相对速度需通过矢量运算确定,体现参考系对物理量描述的决定性作用。习题 3:问题: 一列火车以20m/s速度行驶,车上一乘客以5m/s速度向车尾行走。若以地面为参考系,求乘客相对于地面的速度表达式。当t=10s时,乘客相对于地面的位移是多少?(假设火车长度L=200m)答案: 15m/s;150m解析: 根据运动相对性,乘客相对于地面的速度等于火车速度减去乘客相对于火车的速度。若火车向正方向行驶,乘客向车尾(负方向)行走,则乘客相对于地面速度为20m/s - 5m/s = 15m/s。位移计算为速度乘以时间,即15m/s × 10s = 150m。此例说明,即使乘客在火车内部运动,其相对于地面的运动仍需通过参考系转换分析,体现运动描述的相对性本质。场景二:理科类个性化题目生成
我们通过自定义 Prompt 指令,例如“为中等水平的学生设计3道配解析的题目”,文心 4.5 会自适应调整:
- 题目难度
- 解题步骤详细程度
- 解析风格(语言表达更贴近教学)
这种能力在 K12 个性化教学、智能辅导、习题生成类应用中极具价值。
import openaiimport jsonimport redef init_client(host=\"127.0.0.1\", port=\"8180\", api_key=\"null\"): \"\"\" 初始化 ERNIE-VL 客户端 \"\"\" client = openai.Client(base_url=f\"http://{host}:{port}/v1\", api_key=api_key) print(\"✅ ERNIE-VL 客户端初始化完成\") return clientdef build_prompt(subject, knowledge_points, num_exercises, difficulty): \"\"\" 根据学科和参数构造个性化提示 \"\"\" # 针对不同学科的个性化描述示例 subject_intro = { \"物理\": \"你是一位资深物理老师,擅长讲解力学、电磁学、热学等知识点。\", \"数学\": \"你是一位资深数学老师,熟悉代数、几何、微积分等知识点。\", \"化学\": \"你是一位资深化学老师,擅长无机、有机、分析化学等内容。\", \"语文\": \"你是一位语文老师,擅长古诗文、现代文阅读理解与写作。\", \"英语\": \"你是一位英语老师,擅长语法、阅读理解和写作技巧。\" } intro = subject_intro.get(subject, \"你是一位专业教师,擅长生成高质量习题。\") prompt = f\"\"\"{intro}请严格以 JSON 数组形式输出高质量的习题列表:- 学科:{subject}- 知识点:{knowledge_points}- 题目数量:{num_exercises}- 难度:{difficulty}请直接输出以下格式的 JSON 数组:[ {{ \"question\": \"题目内容\", \"answer\": \"标准答案\", \"explanation\": \"详细解析\" }}]⚠️ 重要要求:1. 题型多样(选择题、填空题、计算题等),答案准确,解析详尽。2. JSON格式必须完整且合法: - 每个元素用花括号 {{}} 包裹且闭合。 - 元素之间用逗号分隔,最后一个元素后不带逗号。 - 数组用方括号 [] 包裹且闭合。3. 严禁出现任何额外文本,包括代码块标记、多余空格、注释或说明。4. 输出内容只能是纯 JSON 数组文本。请严格按照要求生成,保证JSON可以被直接解析。\"\"\" return prompt.strip()def extract_json_array(response_text): \"\"\" 更鲁棒地从返回文本中提取 JSON 数组。 \"\"\" json_pattern = re.compile(r\'\\[\\s*\\{.*?\\}\\s*\\]\', re.DOTALL) match = json_pattern.search(response_text) if match: return match.group() if \"```json\" in response_text: return response_text.split(\"```json\")[1].split(\"```\")[0].strip() elif \"```\" in response_text: return response_text.split(\"```\")[1].strip() raise ValueError(\"未找到 JSON 格式的数据\")def generate_exercises(client, tokenizer, subject, knowledge_points, num_exercises=5, difficulty=\"medium\"): \"\"\" 调用 ERNIE-VL 生成习题 \"\"\" prompt = build_prompt(subject, knowledge_points, num_exercises, difficulty) try: response = client.chat.completions.create( model=\"ernie-4.5-vl-28b-a3b\", messages=[ { \"role\": \"system\", \"content\": [ { \"type\": \"text\", \"text\": \"你是专业的教育专家,擅长根据知识点生成高质量的习题和解析。\" } ] }, { \"role\": \"user\", \"content\": [ { \"type\": \"text\", \"text\": prompt } ] }, ], max_tokens=8192, temperature=0.3, stream=False ) response_content = response.choices[0].message.content print(\"\\n=== 原始响应 ===\\n\", response_content) json_str = extract_json_array(response_content) exercises = json.loads(json_str) valid_exercises = [] for ex in exercises: if all(k in ex for k in [\"question\", \"answer\", \"explanation\"]): valid_exercises.append({ \"question\": ex[\"question\"].strip(), \"answer\": ex[\"answer\"].strip(), \"explanation\": ex[\"explanation\"].strip() }) return valid_exercises except (json.JSONDecodeError, IndexError, KeyError, ValueError) as e: print(f\"\\n❌ JSON解析失败: {str(e)}\") return [] except Exception as e: print(f\"\\n❌ 习题生成失败: {str(e)}\") return []def main(): client = init_client() # 示例:针对不同学科生成习题 subjects = [ (\"物理\", \"牛顿运动定律\", 2, \"简单\"), (\"数学\", \"二次函数的性质\", 1, \"中等\"), (\"化学\", \"化学反应速率\", 1, \"困难\") ] for subject, kp, num, diff in subjects: print(f\"\\n--- 生成学科:{subject},知识点:{kp},数量:{num},难度:{diff} ---\") exercises = generate_exercises(client, None, subject, kp, num, diff) for i, ex in enumerate(exercises, 1): print(f\"\\n习题 {i}:\") print(f\"问题: {ex[\'question\']}\") print(f\"答案: {ex[\'answer\']}\") print(f\"解析: {ex[\'explanation\']}\")if __name__ == \"__main__\": main()输出结果:
✅ ERNIE-VL 客户端初始化完成--- 生成学科:物理,知识点:牛顿运动定律,数量:2,难度:简单 ---=== 原始响应 === [ { \"question\": \"一个质量为3kg的物体,在水平面上受到水平向右的10N的拉力和水平向左的6N的摩擦力作用,求物体的加速度大小和方向。\", \"answer\": \"1.33m/s²,水平向右\", \"explanation\": \"根据牛顿第二定律,F_net = ma。F_net = 10N - 6N = 4N。代入公式,4N = 3kg * a,解得a ≈ 1.33m/s²,方向与合力方向相同,即水平向右。\" }, { \"question\": \"一辆质量为500kg的汽车,在水平路面上以10m/s的速度行驶,受到的阻力为车重的0.1倍。若司机以大小为2000N的制动力刹车,求汽车的加速度大小。(g取10m/s²)\", \"answer\": \"4m/s²\", \"explanation\": \"阻力f = 0.1 * m * g = 0.1 * 500kg * 10m/s² = 500N。制动力与阻力方向相同,合力F_net = 2000N + 500N = 2500N。根据牛顿第二定律,F_net = ma,代入得2500N = 500kg * a,解得a = 5m/s²?但题目中制动力2000N已远大于阻力500N,实际合力应为2000N(假设制动力方向与运动相反,但题目描述可能指额外制动力,按题目字面理解为合力2000N?更正:若制动力单独作用,则F_net = 2000N,a = 2000/500 = 4m/s²。题目可能指制动力与阻力同方向?但通常制动力单独作用,故按合力2000N计算,答案4m/s²。\" } ]习题 1:问题: 一个质量为3kg的物体,在水平面上受到水平向右的10N的拉力和水平向左的6N的摩擦力作用,求物体的加速度大小和方向。答案: 1.33m/s²,水平向右解析: 根据牛顿第二定律,F_net = ma。F_net = 10N - 6N = 4N。代入公式,4N = 3kg * a,解得a ≈ 1.33m/s²,方向与合力方向相同,即水平向右。习题 2:问题: 一辆质量为500kg的汽车,在水平路面上以10m/s的速度行驶,受到的阻力为车重的0.1倍。若司机以大小为2000N的制动力刹车,求汽车的加速度大小。(g取10m/s²)答案: 4m/s²解析: 阻力f = 0.1 * m * g = 0.1 * 500kg * 10m/s² = 500N。制动力与阻力方向相同,合力F_net = 2000N + 500N = 2500N。根据牛顿第二定律,F_net = ma,代入得2500N = 500kg * a,解得a = 5m/s²?但题目中制动力2000N已远大于阻力500N,实际合力应为2000N(假设制动力方向与运动相反,但题目描述可能指额外制动力,按题目字面理解为合力2000N?更正:若制动力单独作用,则F_net = 2000N,a = 2000/500 = 4m/s²。题目可能指制动力与阻力同方向?但通常制动力单独作用,故按合力2000N计算,答案4m/s²。--- 生成学科:数学,知识点:二次函数的性质,数量:1,难度:中等 ---=== 原始响应 === [ { \"question\": \"已知二次函数y=2x^2-4x+5,求该二次函数的顶点坐标和对称轴。\", \"answer\": \"顶点坐标为(1,3),对称轴为x=1\", \"explanation\": \"对于二次函数y=ax^2+bx+c,顶点坐标为(-b/2a, c-b^2/4a)。代入a=2, b=-4, c=5,得到顶点坐标为(1,3)。对称轴为x=-b/2a,代入得x=1。\" }]习题 1:问题: 已知二次函数y=2x^2-4x+5,求该二次函数的顶点坐标和对称轴。答案: 顶点坐标为(1,3),对称轴为x=1解析: 对于二次函数y=ax^2+bx+c,顶点坐标为(-b/2a, c-b^2/4a)。代入a=2, b=-4, c=5,得到顶点坐标为(1,3)。对称轴为x=-b/2a,代入得x=1。--- 生成学科:化学,知识点:化学反应速率,数量:1,难度:困难 ---=== 原始响应 === [ { \"question\": \"在某温度下,将2 mol A和2 mol B投入密闭容器中进行反应:A(g) + B(g) ⇌ C(g) + D(g),10 min后达到平衡,各物质浓度在不同条件下的变化及再次平衡情况如下。在第一次平衡基础上,改变某些反应条件时,关于各物质浓度可能发生变化的是( )\\nA. 缩小容器体积(压缩)\\nB. 加入一定量D,当体系达到新的平衡时,测得c(C)=0.6 mol·L-1\\nC. 升高温度,当体系达到新的平衡时,测得c(A) > c(B)\\nD. 加入催化剂,当体系达到新的平衡时,测得c(B)>1.0 mol·L-1\", \"answer\": \"B\", \"explanation\": \"本题可根据化学平衡的影响因素,结合各选项中改变的条件对平衡的影响来逐一分析:\\n选项A:该反应前后气体的化学计量数之和相等,缩小容器体积(压缩)相当于增大压强,由于反应前后气体分子数不变,所以增大压强平衡不移动,各物质的浓度增大相同的倍数,A中“各物质的浓度发生变化”错误,A选项不符合题意。\\n选项B:加入一定量D,D是生成物,加入D相当于增大压强(缩小容器体积),由于反应前后气体分子数不变,所以增大压强平衡不移动,各物质的浓度增大相同的倍数,而原平衡中各物质的浓度之和为2mol/L+2mol/L=2mol/L,所以加入D后各物质的浓度之和为\\n2mol/L×2=4mol/L,又因为c(C)=0.6mol/L,则c(D)=1.2+0.6=1.8mol/L,原平衡中c(C)=c(D)=1mol/L,所以当加入一定量D,当体系达到新的平衡时,测得c(C)=0.6mol·L-1是可能的,B选项符合题意。\\n选项C:A(g)+B(g)⇌C(g)+D(g),假设反应物全部转化为生成物,A、B的物质的量之比为1:1,升高温度,平衡逆向移动,但A、B的物质的量之比仍为1:1,即c(A)=c(B),C中“c(A)>c(B)”错误,C选项不符合题意。\\n选项D:加入催化剂,平衡不移动,所以各物质的浓度不变,D中“c(B)>1.0mol·L-1”错误,D选项不符合题意。\\n综上,答案是B。\" }]习题 1:问题: 在某温度下,将2 mol A和2 mol B投入密闭容器中进行反应:A(g) + B(g) ⇌ C(g) + D(g),10 min后达到平衡,各物质浓度在不同条件下的变化及再次平衡情况如下。在第一次平衡基础上,改变某些反应条件时,关于各物质浓度可能发生变化的是( )A. 缩小容器体积(压缩)B. 加入一定量D,当体系达到新的平衡时,测得c(C)=0.6 mol·L-1C. 升高温度,当体系达到新的平衡时,测得c(A) > c(B)D. 加入催化剂,当体系达到新的平衡时,测得c(B)>1.0 mol·L-1答案: B解析: 本题可根据化学平衡的影响因素,结合各选项中改变的条件对平衡的影响来逐一分析:选项A:该反应前后气体的化学计量数之和相等,缩小容器体积(压缩)相当于增大压强,由于反应前后气体分子数不变,所以增大压强平衡不移动,各物质的浓度增大相同的倍数,A中“各物质的浓度发生变化”错误,A选项不符合题意。选项B:加入一定量D,D是生成物,加入D相当于增大压强(缩小容器体积),由于反应前后气体分子数不变,所以增大压强平衡不移动,各物质的浓度增大相同的倍数,而原平衡中各物质的浓度之和为2mol/L+2mol/L=2mol/L,所以加入D后各物质的浓度之和为2mol/L×2=4mol/L,又因为c(C)=0.6mol/L,则c(D)=1.2+0.6=1.8mol/L,原平衡中c(C)=c(D)=1mol/L,所以当加入一定量D,当体系达到新的平衡时,测得c(C)=0.6mol·L-1是可能的,B选项符合题意。选项C:A(g)+B(g)⇌C(g)+D(g),假设反应物全部转化为生成物,A、B的物质的量之比为1:1,升高温度,平衡逆向移动,但A、B的物质的量之比仍为1:1,即c(A)=c(B),C中“c(A)>c(B)”错误,C选项不符合题意。选项D:加入催化剂,平衡不移动,所以各物质的浓度不变,D中“c(B)>1.0mol·L-1”错误,D选项不符合题意。综上,答案是B。场景三:文科类学科教育场景
import jsonimport redef init_client(host=\"127.0.0.1\", port=\"8180\", api_key=\"null\"): \"\"\" 初始化 ERNIE-VL 客户端 \"\"\" import openai client = openai.Client(base_url=f\"http://{host}:{port}/v1\", api_key=api_key) print(\"✅ ERNIE-VL 客户端初始化完成\") return clientdef build_prompt(subject, knowledge_points, student_level, num_exercises): \"\"\" 构建个性化提示,结合学科和学生水平 \"\"\" subject_experts = { \"语文\": (\"你是一位资深的语文老师,多年专注于语文教学,\" \"对古诗词鉴赏、阅读理解、作文技巧、文言文翻译和文学常识有深入研究。\" \"擅长设计启发学生文学思维的题目,注重语言表达和文学素养的培养。\"), \"数学\": (\"你是一位资深的数学老师,多年专注于数学教学,\" \"对代数运算、几何证明、函数分析、概率统计和解题技巧有深入研究。\" \"擅长设计逻辑严谨的数学题目,注重培养学生数学思维和问题解决能力。\"), \"英语\": (\"你是一位资深的英语老师,多年专注于英语教学,\" \"对语法结构、词汇运用、阅读理解、写作技巧和口语表达有深入研究。\" \"擅长设计贴近实际应用的英语题目,注重培养学生语言应用能力。\"), \"物理\": (\"你是一位资深的物理老师,擅长讲解力学、电磁学、热学等知识点,\" \"注重培养学生的物理直观和实验能力。\"), \"化学\": (\"你是一位资深化学老师,擅长无机、有机、分析化学等内容,\" \"注重培养学生的化学实验和理论结合能力。\"), } system_role = subject_experts.get(subject, \"你是一位专业教师,擅长生成高质量习题。\") prompt = f\"\"\"{system_role}请根据以下要求生成个性化{subject}习题:1. 知识点:{knowledge_points}2. 学生水平:{student_level}3. 题目数量:{num_exercises}道4. 包含完整题目、答案和解析5. 使用纯JSON格式输出,结构如下:[ {{ \"question\": \"题目内容\", \"answer\": \"正确答案\", \"explanation\": \"详细解题步骤和解析\" }}]要求:- 题型多样化(选择题、填空题、计算题、应用题等)- 难度符合学生水平- 解析要详细且易懂- 严禁包含任何除JSON数组外的文本、代码块标记或注释- JSON格式必须完整合法,数组元素之间用逗号分隔,且最后一个元素后无逗号请严格按照要求输出,仅输出纯JSON数组。\"\"\" return prompt.strip()def extract_json_array(text): \"\"\" 从模型回复中提取JSON数组字符串,鲁棒性强 \"\"\" # 尝试正则匹配最外层JSON数组 pattern = re.compile(r\'\\[\\s*\\{.*?\\}\\s*\\]\', re.DOTALL) match = pattern.search(text) if match: return match.group() # 处理代码块形式的json输出 if \"```json\" in text: return text.split(\"```json\")[1].split(\"```\")[0].strip() if \"```\" in text: return text.split(\"```\")[1].strip() # 备选:寻找首尾中括号包围内容 start = text.find(\'[\') end = text.rfind(\']\') if start != -1 and end != -1 and end > start: return text[start:end+1] raise ValueError(\"未能提取有效的JSON数组\")def generate_personalized_exercises(client, subject, knowledge_points, student_level=\"中等\", num_exercises=5): \"\"\" 生成个性化教育习题 \"\"\" prompt = build_prompt(subject, knowledge_points, student_level, num_exercises) try: response = client.chat.completions.create( model=\"ernie-4.5-vl-28b-a3b\", # 你的模型名称 messages=[ { \"role\": \"system\", \"content\": [ { \"type\": \"text\", \"text\": f\"你是专业的{subject}教育专家,擅长根据知识点生成高质量习题和解析。\" } ] }, { \"role\": \"user\", \"content\": [ { \"type\": \"text\", \"text\": prompt } ] } ], max_tokens=8192, temperature=0.3, stream=False ) response_content = response.choices[0].message.content print(\"\\n=== 原始响应 ===\\n\", response_content) json_str = extract_json_array(response_content) exercises = json.loads(json_str) valid_exercises = [] for ex in exercises: if all(key in ex for key in [\"question\", \"answer\", \"explanation\"]): valid_exercises.append({ \"question\": ex[\"question\"].strip(), \"answer\": ex[\"answer\"].strip(), \"explanation\": ex[\"explanation\"].strip() }) return valid_exercises except (json.JSONDecodeError, ValueError, IndexError, KeyError) as e: print(f\"\\n❌ JSON解析失败: {str(e)}\") return [] except Exception as e: print(f\"\\n❌ 习题生成失败: {str(e)}\") return []if __name__ == \"__main__\": # 示例,初始化客户端 client = init_client() # 生成示例语文习题 exercises = generate_personalized_exercises( client=client, subject=\"语文\", knowledge_points=\"古诗词鉴赏、常见错别字辨析\", student_level=\"中等\", num_exercises=3 ) for i, ex in enumerate(exercises, 1): print(f\"\\n习题 {i}:\") print(f\"问题: {ex[\'question\']}\") print(f\"答案: {ex[\'answer\']}\") print(f\"解析: {ex[\'explanation\']}\")输出结果:
✅ ERNIE-VL 客户端初始化完成=== 原始响应 === [ { \"question\": \"阅读李白的《静夜思》,回答问题:诗中“明月”这一意象主要表达了诗人怎样的情感?A. 孤独寂寞 B. 思乡之情 C. 赞美自然 D. 孤独惆怅\", \"answer\": \"B\", \"explanation\": \"在《静夜思》中,“明月”这一意象常被用来寄托思乡之情。诗人在异乡看到明亮的月光,联想到家乡的亲人,从而引发了深深的思乡之情。选项A“孤独寂寞”虽然也有一定道理,但不如“思乡之情”贴切;选项C“赞美自然”与诗的主题不符;选项D“孤独惆怅”则过于宽泛,没有具体指向诗中的情感核心。\" }, { \"question\": \"找出下列句子中的错别字:阳光明媚,微风和日历,湖水清澈见底,岸边柳树成荫。\", \"answer\": \"日历\", \"explanation\": \"在给出的句子中,“微风和日历”存在错别字。正确的词语应为“微风和日丽”。“日丽”形容天气晴朗、阳光明媚,而“日历”是指记录日期和节日的簿册,与句意不符。因此,错别字是“日历”。其他词语如“阳光明媚”、“清澈见底”、“柳树成荫”均书写正确。\" }, { \"question\": \"阅读以下古诗词片段,并回答问题:\\n春日融融,百花争艳,春风拂面,柳絮飘飞。诗人用“争艳”形容百花,用“飘飞”形容柳絮,请分析“争艳”和“飘飞”这两个词语在修辞手法上的特点,并找出文本中的一处错别字。\\nA. “争艳”运用了拟人手法,“飘飞”运用了比喻手法;文本中的错别字是“花漂”。\\nB. “争艳”运用了拟人手法,“飘飞”运用了拟物手法;文本中的错别字是“花漂”。\\nC. “争艳”运用了拟人手法,“飘飞”运用了比喻手法;文本中的错别字是“花漂”不存在(实际无错别字,需合理设计)。\\n(注:为符合题目要求,设计文本中存在错别字,如“花漂”,实际解析中需指出。此处选择A作为示例,但需调整解析以包含错别字设计,如改为“花漂”为“花飘”。但为保持题目简洁,直接设计文本含错别字,如“花漂”。但更合理的是,题目中明确要求找错别字,故设计文本含错别字,如“花漂”。最终解析中指出错别字。)\\n实际设计:文本为“春日融融,百花争艳,春风拂面,柳絮飘飞。岸边柳树成荫,花漂似雪。”\\n问题:1. “争艳”和“飘飞”的修辞手法;2. 文本中的错别字是什么?\", \"answer\": \"1. 拟人;2. 花漂\", \"explanation\": \"对于第一个问题,“争艳”一词将百花人格化,赋予其竞争、争奇斗艳的行为,这是拟人手法;“飘飞”一词则形象地描绘了柳絮在空中飘动的情景,虽然未直接比喻其他事物,但在此语境下,它更多是通过动作描写来表现柳絮的轻盈,但若从修辞手法严格分类,可视为一种生动的描写,但题目中将其与“比喻”对应,可能是强调其动态感,但更准确的是,拟人更贴切。然而,题目选项中“争艳”为拟人,“飘飞”若理解为将柳絮比作其他飘浮物(如雪花),则可视为比喻,但在此语境下,更偏向拟人强调其动态美。但为符合题目选项,选择A中的“争艳”拟人,“飘飞”比喻(尽管不完全严谨,但题目如此设计),故选择A的修辞手法描述,但需注意,题目要求多样化,故选择A作为示例,但解析中需指出修辞手法的合理性。对于第二个问题,文本中的错别字是“花漂”,正确应为“花飘”,形容花朵如雪花般飘落,但“花漂”则可能被误解为花朵漂浮,与语境不符。因此,错别字是“花漂”。在解析中,需明确指出修辞手法的分析,并强调错别字的识别。\" }]习题 1:问题: 阅读李白的《静夜思》,回答问题:诗中“明月”这一意象主要表达了诗人怎样的情感?A. 孤独寂寞 B. 思乡之情 C. 赞美自然 D. 孤独惆怅答案: B解析: 在《静夜思》中,“明月”这一意象常被用来寄托思乡之情。诗人在异乡看到明亮的月光,联想到家乡的亲人,从而引发了深深的思乡之情。选项A“孤独寂寞”虽然也有一定道理,但不如“思乡之情”贴切;选项C“赞美自然”与诗的主题不符;选项D“孤独惆怅”则过于宽泛,没有具体指向诗中的情感核心。习题 2:问题: 找出下列句子中的错别字:阳光明媚,微风和日历,湖水清澈见底,岸边柳树成荫。答案: 日历解析: 在给出的句子中,“微风和日历”存在错别字。正确的词语应为“微风和日丽”。“日丽”形容天气晴朗、阳光明媚,而“日历”是指记录日期和节日的簿册,与句意不符。因此,错别字是“日历”。其他词语如“阳光明媚”、“清澈见底”、“柳树成荫”均书写正确。习题 3:问题: 阅读以下古诗词片段,并回答问题:春日融融,百花争艳,春风拂面,柳絮飘飞。诗人用“争艳”形容百花,用“飘飞”形容柳絮,请分析“争艳”和“飘飞”这两个词语在修辞手法上的特点,并找出文本中的一处错别字。A. “争艳”运用了拟人手法,“飘飞”运用了比喻手法;文本中的错别字是“花漂”。B. “争艳”运用了拟人手法,“飘飞”运用了拟物手法;文本中的错别字是“花漂”。C. “争艳”运用了拟人手法,“飘飞”运用了比喻手法;文本中的错别字是“花漂”不存在(实际无错别字,需合理设计)。(注:为符合题目要求,设计文本中存在错别字,如“花漂”,实际解析中需指出。此处选择A作为示例,但需调整解析以包含错别字设计,如改为“花漂”为“花飘”。但为保持题目简洁,直接设计文本含错别字,如“花漂”。但更合理的是,题目中明确要求找错别字,故设计文本含错别字,如“花漂”。最终解析中指出错别字。)实际设计:文本为“春日融融,百花争艳,春风拂面,柳絮飘飞。岸边柳树成荫,花漂似雪。”问题:1. “争艳”和“飘飞”的修辞手法;2. 文本中的错别字是什么?答案: 1. 拟人;2. 花漂解析: 对于第一个问题,“争艳”一词将百花人格化,赋予其竞争、争奇斗艳的行为,这是拟人手法;“飘飞”一词则形象地描绘了柳絮在空中飘动的情景,虽然未直接比喻其他事物,但在此语境下,它更多是通过动作描写来表现柳絮的轻盈,但若从修辞手法严格分类,可视为一种生动的描写,但题目中将其与“比喻”对应,可能是强调其动态感,但更准确的是,拟人更贴切。然而,题目选项中“争艳”为拟人,“飘飞”若理解为将柳絮比作其他飘浮物(如雪花),则可视为比喻,但在此语境下,更偏向拟人强调其动态美。但为符合题目选项,选择A中的“争艳”拟人,“飘飞”比喻(尽管不完全严谨,但题目如此设计),故选择A的修辞手法描述,但需注意,题目要求多样化,故选择A作为示例,但解析中需指出修辞手法的合理性。对于第二个问题,文本中的错别字是“花漂”,正确应为“花飘”,形容花朵如雪花般飘落,但“花漂”则可能被误解为花朵漂浮,与语境不符。因此,错别字是“花漂”。在解析中,需明确指出修辞手法的分析,并强调错别字的识别。五、项目效果总结
5.1 响应速度与性能测试
在星河社区的 A800 环境下,实测 ERNIE-VL 多模态模型的表现:
即使在多图+长文本输入场景中,模型也能在稳定时间范围内返回合理结果,完全可满足在线教育或教学辅助类需求。
5.2 优势亮点与优化建议
✅ 优势总结:
- FastDeploy + ERNIE 组合部署简单,实测效率高
- 多模态理解能力提升,特别适配图文混合教学场景
- 基于百度文库知识底座,生成内容更权威
- 个性化 Prompt 调控题目风格,适合教学定制化需求
⚠️ 不足建议:
- OCR 对低分辨率截图的识别有一定误差(可接入 OCR 微调)
- 当前不支持直接输出图表或公式,适合文本类题型为主
- 生成内容偶有“JSON格式非法”情况,需加前置校验函数优化
六、开源之路的意义:从可复现到可用的进化
在这次实测中,我最直观的感受是:开源的意义,不再只是开放参数与代码,而是让开发者能快速复现场景、验证业务、构建产品。
文心大模型 4.5 系列的开源,意味着:
- 国内企业首次具备完整「多模态+大模型」开源能力
- 基于飞桨生态可一键部署,可低门槛复现业务逻辑
- 教育、医疗、法律等知识密集型领域,将迎来 AI 加速普惠落地的机会
期待未来文心系列能:
- 提供更多标准场景微调参数包(如“物理教学微调”)
- 拓展图文混合表达能力(如输出图解 + 题干)
- 加强教学场景推理链路透明度(输出步骤解释、评分依据)
七、文末致谢
本项目开发参考了飞桨社区 FastDeploy 示例文档,以及开源项目【会唱歌的炼丹师】的 AI 作文批阅系统、【Amireon】的多模态数学解题框架,等优秀工程实践。
特别是在多专家 Agent 协作、上下文管理、Prompt 模板优化、JSON 结构解析、多模态图片识别等方面获得了诸多启发,特此向原作者表示诚挚感谢!
目前,文心大模型 4.5 系列已在 GitCode 平台开放下载,欢迎开发者前往体验开源 AI 的速度与力量!
📮 欢迎留言交流,也欢迎更多开发者加入飞桨星河社区,共建国产大模型生态!
hello,我是 是Yu欸 。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。

