【性能优化】彻底搞懂零拷贝技术的应用和原理
文章目录
-
- 一、零拷贝的本质与核心价值
-
- 1.1 零拷贝的技术定义
- 1.2 传统 I/O 的性能瓶颈
- 1.3 零拷贝的核心优势
- 二、零拷贝的底层实现原理
-
- 2.1 Linux 内核的零拷贝机制
-
- 2.1.1 mmap+write:内存映射优化
- 2.1.2 sendfile:内核级数据转发
- 2.1.3 sendfile+DMA Scatter/Gather:硬件辅助优化
- 2.2 Java NIO 的零拷贝实现
-
- 2.2.1 transferTo/transferFrom:跨通道传输
- 2.2.2 Direct ByteBuffer:堆外内存优化
- 2.3 Netty 的零拷贝增强
-
- 2.3.1 CompositeByteBuf:逻辑缓冲区组合
- 2.3.2 FileRegion:文件零拷贝传输
- 2.4 Kafka 的零拷贝实践
-
- 2.4.1 消息持久化:mmap 内存映射
- 2.4.2 消息消费:sendfile 零拷贝传输
- 2.4.3 副本同步:跨节点零拷贝
- 三、零拷贝技术的演进与最佳实践
-
- 3.1 技术演进脉络
- 3.2 实践选型建议
- 3.3 常见误区澄清
- 结语
在高性能系统设计中,数据传输效率是决定系统吞吐量的核心因素。传统数据传输过程中,频繁的内存拷贝和上下文切换会严重消耗 CPU 资源,成为系统性能瓶颈。零拷贝(Zero-Copy) 技术通过减少或消除不必要的数据拷贝操作,大幅提升数据传输效率,已成为高并发、大数据场景下的核心优化手段。本文将从技术本质出发,系统解析零拷贝的作用、底层原理及实践应用,为读者提供权威的技术参考。
一、零拷贝的本质与核心价值
1.1 零拷贝的技术定义
零拷贝并非指 “完全没有数据拷贝”,而是通过技术手段避免在用户态与内核态之间进行不必要的 CPU 数据拷贝,同时减少上下文切换开销。其核心思想是:让数据在存储介质(磁盘)与目标设备(网卡)之间的传输路径最短化,最大限度减少 CPU 参与数据搬运的过程。
在计算机体系结构中,用户态与内核态拥有独立的地址空间,数据在两者间的拷贝需要 CPU 全程参与。零拷贝技术通过优化数据传输路径,跳过 “内核态→用户态→内核态” 的冗余环节,直接在内核态完成数据转发,从根本上降低 CPU 负载。
1.2 传统 I/O 的性能瓶颈

以文件网络传输为例,传统 I/O 流程(如 Java 的FileInputStream+SocketOutputStream)存在不可忽视的性能问题:
- 四次数据拷贝:
-
阶段 1:磁盘数据通过 DMA(直接内存访问)拷贝到内核态页缓存(无需 CPU 参与)。
-
阶段 2:CPU 将内核页缓存数据拷贝到用户态缓冲区(CPU 密集型操作)。
-
阶段 3:CPU 将用户态缓冲区数据拷贝到内核态 Socket 缓冲区(再次消耗 CPU)。
-
阶段 4:Socket 缓冲区数据通过 DMA 拷贝到网卡(无需 CPU 参与)。
- 四次上下文切换:
-
用户态→内核态(发起读操作)。
-
内核态→用户态(读操作完成)。
-
用户态→内核态(发起写操作)。
-
内核态→用户态(写操作完成)。
在 1Gbps 网络环境下,传输 1GB 文件时,传统 I/O 的 CPU 拷贝操作会占用约 25% 的 CPU 核心资源,导致系统无法处理其他业务请求。
1.3 零拷贝的核心优势
-
降低 CPU 利用率:
消除用户态与内核态之间的 CPU 拷贝,将 CPU 资源释放给业务逻辑处理。实测显示,零拷贝可使 I/O 密集型应用的 CPU 占用率降低 40%~60%。
-
提升数据吞吐量:
缩短数据传输路径,减少内存带宽占用。在大文件传输场景中,零拷贝可使单机吞吐量提升 2~3 倍。
-
减少内存占用:
避免数据在用户态与内核态的重复存储,降低内存总线压力,尤其适合内存受限的服务器环境。
-
降低延迟:
通过合并系统调用减少上下文切换(从 4 次降至 1~2 次),单次 I/O 操作延迟可降低 30% 以上。

二、零拷贝的底层实现原理
零拷贝技术的实现涉及硬件(DMA 控制器)、操作系统内核(系统调用)和应用层(API 封装)三个层面,不同场景的技术路径略有差异,但核心逻辑一致。
2.1 Linux 内核的零拷贝机制
Linux 内核提供了三种典型的零拷贝实现,分别适用于不同场景:
2.1.1 mmap+write:内存映射优化
技术原理:
通过mmap()系统调用将内核态页缓存与用户态进程地址空间建立映射关系,使应用程序可直接操作内核缓存数据,避免 “内核→用户态” 的 CPU 拷贝。
完整流程:
-
调用
mmap(fd, size)将文件内容映射到内核页缓存,返回用户态映射地址。 -
磁盘数据通过 DMA 拷贝到内核页缓存(无 CPU 参与)。
-
应用程序直接修改映射地址的数据(操作内核缓存,无拷贝)。
-
调用
write(sockfd, addr, size)将内核页缓存数据 CPU 拷贝到 Socket 缓冲区。 -
Socket 缓冲区数据通过 DMA 拷贝到网卡。
核心优化:减少 1 次 CPU 拷贝(内核→用户态),但仍保留内核态内部的 1 次 CPU 拷贝。
适用场景:需要对文件内容进行修改后再传输的场景(如日志处理),但不适用于超大型文件(可能导致内存映射开销过高)。
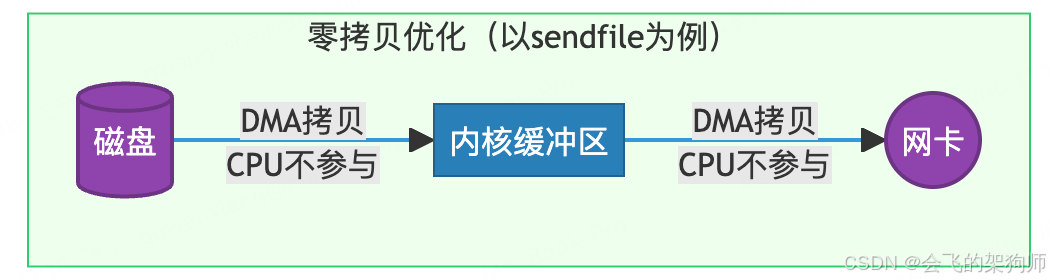
2.1.2 sendfile:内核级数据转发
技术原理:
通过sendfile()系统调用将文件数据在内核态直接从页缓存转发到 Socket 缓冲区,全程无需用户态参与,彻底避免用户态与内核态的交互。
完整流程:
-
调用
sendfile(in_fd, out_fd, offset, count)发起传输。 -
磁盘数据通过 DMA 拷贝到内核页缓存。
-
内核将页缓存数据 CPU 拷贝到 Socket 缓冲区。
-
Socket 缓冲区数据通过 DMA 拷贝到网卡。
-
系统调用返回,全程仅 2 次上下文切换。
核心优化:
-
消除 2 次 CPU 拷贝(内核→用户态、用户态→Socket 缓冲区)。
-
减少 2 次上下文切换(从 4 次降至 2 次)。
适用场景:纯文件传输场景(如 Nginx 静态资源服务),目前 Nginx 默认启用sendfile指令。
2.1.3 sendfile+DMA Scatter/Gather:硬件辅助优化
技术原理:
结合网卡的 DMA Scatter/Gather(散射 - 聚集)特性,内核只需将数据地址和长度等元数据传递给网卡,由 DMA 控制器直接从页缓存读取数据,彻底消除所有 CPU 拷贝。
完整流程:
-
调用
sendfile(in_fd, out_fd, offset, count)发起传输。 -
磁盘数据通过 DMA 拷贝到内核页缓存。
-
内核向网卡传递页缓存地址、数据长度等元数据。
-
网卡 DMA 控制器直接从页缓存读取数据(散射 - 聚集模式)。
核心优化:
-
完全消除 CPU 拷贝(包括内核态内部)。
-
数据传输路径最短化:磁盘→内核缓存→网卡。
依赖条件:
-
网卡必须支持 DMA Scatter/Gather 特性(现代网卡均支持)。
-
Linux 内核版本≥2.4(该版本首次实现此特性)。
性能数据:相比传统 I/O,吞吐量提升可达 300%,CPU 占用率降低 60% 以上。
2.2 Java NIO 的零拷贝实现
Java NIO 通过FileChannel封装了操作系统的零拷贝能力,其实现与底层 OS 紧密相关:
2.2.1 transferTo/transferFrom:跨通道传输
技术原理:
FileChannel.transferTo(position, count, targetChannel)方法直接调用操作系统的零拷贝接口,实现文件通道到目标通道(如 SocketChannel)的内核态数据传输。
底层映射:
-
Linux 系统:映射到
sendfile()系统调用。 -
Windows 系统:映射到
TransmitFile()API。 -
不支持零拷贝的系统:降级为
mmap方式。
流程解析:
-
Java 调用
transferTo()触发 native 方法。 -
JNI 层调用
sendfile()完成内核态数据转发。 -
数据传输路径与内核
sendfile完全一致。
代码示例:
try (FileChannel fileChannel = new FileInputStream(\"data.txt\").getChannel(); SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress(\"127.0.0.1\", 8080))) { long transferred = fileChannel.transferTo(0, fileChannel.size(), socketChannel); System.out.println(\"传输字节数:\" + transferred);} catch (IOException e) { e.printStackTrace();}注意事项:
-
单次
transferTo()调用可能受操作系统限制(如 Linux 默认单次最大传输 64KB),需循环调用直至完成。 -
目标通道必须是可写的
WritableByteChannel(如 SocketChannel、FileChannel)。
2.2.2 Direct ByteBuffer:堆外内存优化
技术原理:
ByteBuffer.allocateDirect(int capacity)分配的堆外内存(直接缓冲区)位于 JVM 堆外,属于操作系统直接管理的内存区域,可减少 JVM 堆与内核缓冲区之间的 CPU 拷贝。
核心优势:
-
直接缓冲区与内核缓冲区共享同一块物理内存,避免 “堆内存→内核缓存” 的 CPU 拷贝。
-
不受 JVM 垃圾回收影响,适合长期复用的缓冲区(如网络通信缓冲区)。
适用场景:频繁的小数据传输(如 RPC 通信),但分配成本较高,建议通过对象池复用。
2.3 Netty 的零拷贝增强
Netty 在 Java NIO 基础上,进一步优化了用户态的零拷贝实现:
2.3.1 CompositeByteBuf:逻辑缓冲区组合
问题背景:
传统 NIO 中,拼接消息头(header)和消息体(body)需将数据拷贝到新缓冲区,如:
// 传统方式:存在2次CPU拷贝ByteBuf all = Unpooled.buffer(header.readableBytes() + body.readableBytes());all.writeBytes(header);all.writeBytes(body);优化实现:
CompositeByteBuf通过逻辑引用组合多个缓冲区,对外呈现为连续缓冲区,避免物理拷贝:
CompositeByteBuf composite = Unpooled.compositeBuffer();composite.addComponents(true, header, body); // 逻辑组合,无拷贝// 读取数据时自动维护偏移量ByteBuf readBuf = composite.readBytes(100);核心价值:在协议编解码场景中,可减少 50% 以上的 CPU 拷贝开销。
2.3.2 FileRegion:文件零拷贝传输
Netty 通过DefaultFileRegion封装文件传输,底层直接调用FileChannel.transferTo():
FileRegion region = new DefaultFileRegion(new File(\"largeFile.dat\"), 0, fileLength);channel.writeAndFlush(region).addListener(ChannelFutureListener.CLOSE);优势:文件数据从内核缓存直接传输到网卡,不经过 Netty 的用户态缓冲区,与原生 NIO 相比减少了缓冲区管理开销。
2.4 Kafka 的零拷贝实践
Kafka 作为高性能消息系统,零拷贝是其支撑百万级 TPS 的核心技术:
2.4.1 消息持久化:mmap 内存映射
实现原理:
Kafka 生产者将消息写入RecordAccumulator内存缓冲区后,通过mmap映射到内核页缓存,由操作系统负责异步刷盘(msync)。
优势:
-
避免 “用户缓冲区→内核缓存” 的 CPU 拷贝。
-
利用操作系统页缓存的预读机制,提升磁盘写入效率。
2.4.2 消息消费:sendfile 零拷贝传输
实现原理:
消费者拉取消息时,Kafka broker 通过sendfile将磁盘文件数据从内核页缓存直接传输到 Socket 缓冲区:
-
消息文件数据通过 DMA 加载到内核页缓存(预热后常驻内存)。
-
调用
sendfile将页缓存数据直接转发到网卡(无 CPU 拷贝)。
性能贡献:零拷贝技术使 Kafka 的消息投递延迟降低 40%,单机吞吐量提升至传统消息队列的 3~5 倍。
2.4.3 副本同步:跨节点零拷贝
Kafka 副本间的数据同步通过transferTo实现:
// 副本同步核心代码FileChannel source = new FileInputStream(segmentFile).getChannel();SocketChannel dest = SocketChannel.open(remoteBroker);source.transferTo(0, source.size(), dest);价值:减少集群内部数据传输的 CPU 开销,提升副本同步速度。
三、零拷贝技术的演进与最佳实践
3.1 技术演进脉络
sendfiletransferToCompositeByteBuf3.2 实践选型建议
-
大文件传输:优先选择
sendfile+DMA Scatter/Gather(如 Nginx、FTP 服务)。 -
文件修改 + 传输:使用
mmap+write(如日志处理系统)。 -
Java 网络通信:
- 大文件:
FileChannel.transferTo - 小数据:
DirectByteBuffer+ 对象池 - 协议编解码:Netty
CompositeByteBuf
- 消息队列:借鉴 Kafka 的
mmap持久化 +sendfile传输模式。
3.3 常见误区澄清
-
“零拷贝完全没有拷贝”:错误。零拷贝允许 DMA 拷贝(无 CPU 参与),仅消除 CPU 拷贝。
-
“零拷贝一定比传统 I/O 快”:错误。小文件(<1KB)可能因系统调用开销抵消收益,需测试验证。
-
“Java 零拷贝与操作系统无关”:错误。Java 零拷贝依赖底层 OS 支持,不同系统实现存在差异。
-
“内核态内部无数据拷贝”:错误。在
mmap+write和基础sendfile模式中,内核态内部仍存在 CPU 拷贝(页缓存→Socket 缓冲区),仅sendfile+DMA Scatter/Gather能消除所有 CPU 拷贝。
结语
零拷贝技术的本质是通过优化数据传输路径,减少 CPU 参与的数据搬运,其价值在高并发、大数据场景中尤为突出。从 Linux 内核的sendfile到 Java NIO 的transferTo,再到 Netty 和 Kafka 的场景化优化,零拷贝技术形成了从硬件到应用层的完整优化体系。
理解零拷贝不仅是掌握一项技术,更是领悟性能优化的底层思维 ——通过合理利用系统架构特性,减少不必要的资源消耗,让每一份算力都用在核心业务逻辑上。在未来的分布式系统中,零拷贝技术仍将是提升性能的关键手段,值得每一位工程师深入研究与实践。

