华为云开发者空间 × DeepSeek-R1 智能融合测评:云端开发与AI客服的协同进化
前言:
华为开发者空间,是为全球开发者打造的专属开发者空间,致力于为每位开发者提供一台云主机、一套开发工具和云上存储空间,当普惠云资源遇见推理大模型,企业服务与开发效能的范式革命正在加速。华为云开发者空间:开箱即用的云端开发引擎!
一、华为云开发者空间介绍
华为于2024年HDC大会推出开发者空间服务,为开发者提供终身免费的云主机资源(2核CPU/4GB内存/5GB存储+180小时/年),支持Web端一键访问预置CodeArts IDE、JDK、Python等工具链,彻底解决本地环境配置繁琐问题。其创新设计聚焦三大能力:
- 场景化沙箱环境:分钟级创建鸿蒙、昇腾、鲲鹏等开发沙盒,预置Redis、FunctionGraph等实战案例模板,支持高校教学与企业实训;
- 端云协同数据管理:云主机配置与代码工程实时同步至云端,支持跨设备无缝续接开发,5GB存储空间保障资产安全中转;
- 生态资源集成:聚合沃土云创计划、开源激励及ModelArts AI服务入口,形成“学习-开发-部署-变现”闭环。
二、开发者空间云主机免费领取
免费领取地址: https://developer.huaweicloud.com/space/devportal/desktop?utm_source=csdndspace&utm_adplace=csdncxlhdp
点击链接登录注册华为云账户就可以了
进去之后的主界面就是这样的
配置云主机
选择你喜欢的系统镜像就,就可以一键配置了,节约了装系统的烦恼。
我这里习惯使用Ubuntu的,直接点击安装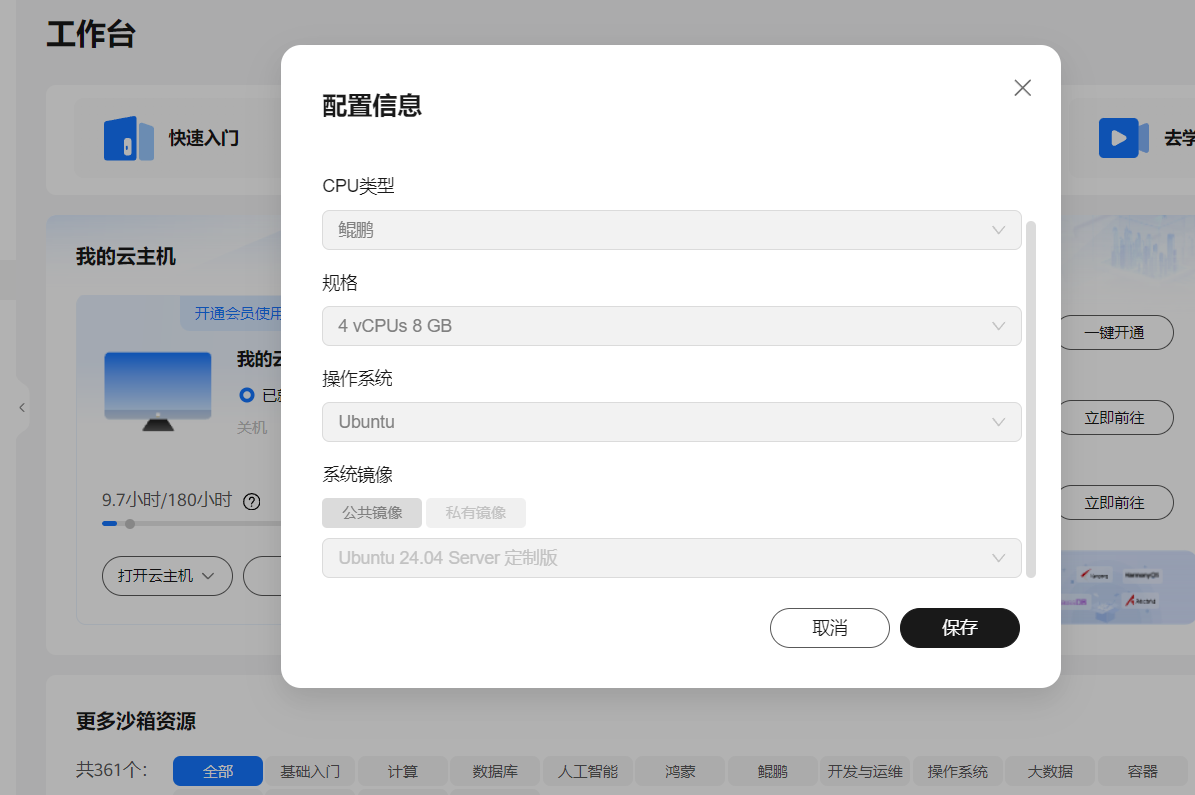
配置好信息后,进入云主机
等待镜像初始化

进入云主机后,系统界面就是这样的
打开命令行
到这一步就算领取成功了
三、云主机上安装部署deepSeek
DeepSeek-R1:逻辑密集型任务的推理专家
作为国产开源大模型代表,DeepSeek-R1在客服场景展现三大差异化优势:
- 链式思维推理:通过多步逻辑拆解处理复杂查询,在FAQ解析、政策条款解释等任务中准确率超传统模型30%;
- 检索增强生成(RAG)兼容性:与ChatWiki等知识库系统深度适配,支持PDF/Word等多格式文档向量化,实现动态知识更新;
- 企业级部署友好:API轻量化设计,5秒内完成千字符级响应,适配官网、App、微信等多渠道嵌入。
功能协同价值矩阵
3.1 下载安装Ollama
Ollama 是一个强大的开源工具,旨在帮助用户轻松地在本地运行、部署和管理大型语言模型(LLMs)。它提供了一个简单的命令行界面,使用户能够快速下载、运行和与各种预训练的语言模型进行交互。Ollama 支持多种模型架构,并且特别适合那些希望在本地环境中使用 LLMs 的开发者和研究人员。
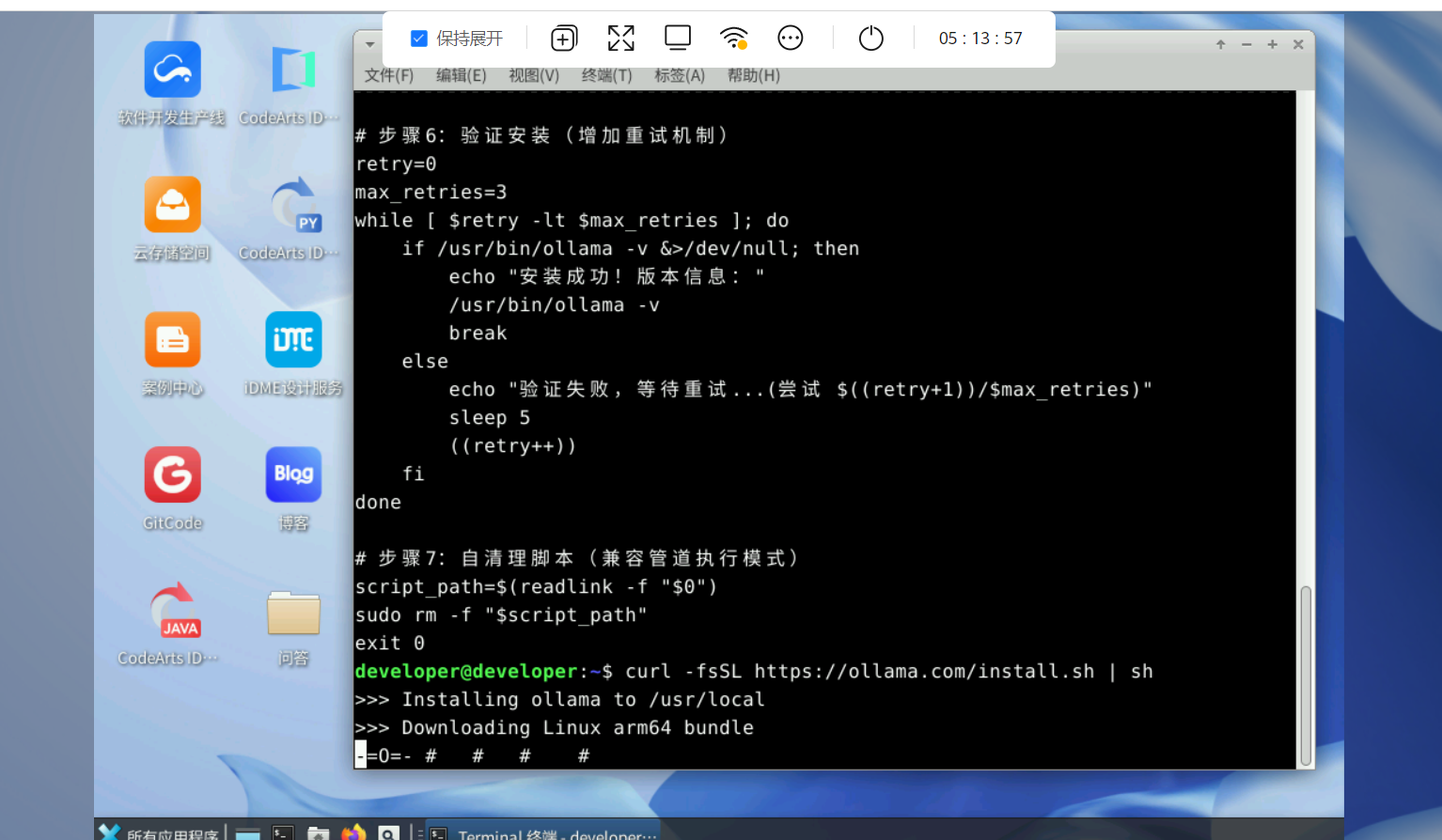
下载命令:
curl -fsSL https://ollama.com/install.sh sh或者这个镜像地址curl -fsSL https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0035/install.sh | sudo bash安装完成如下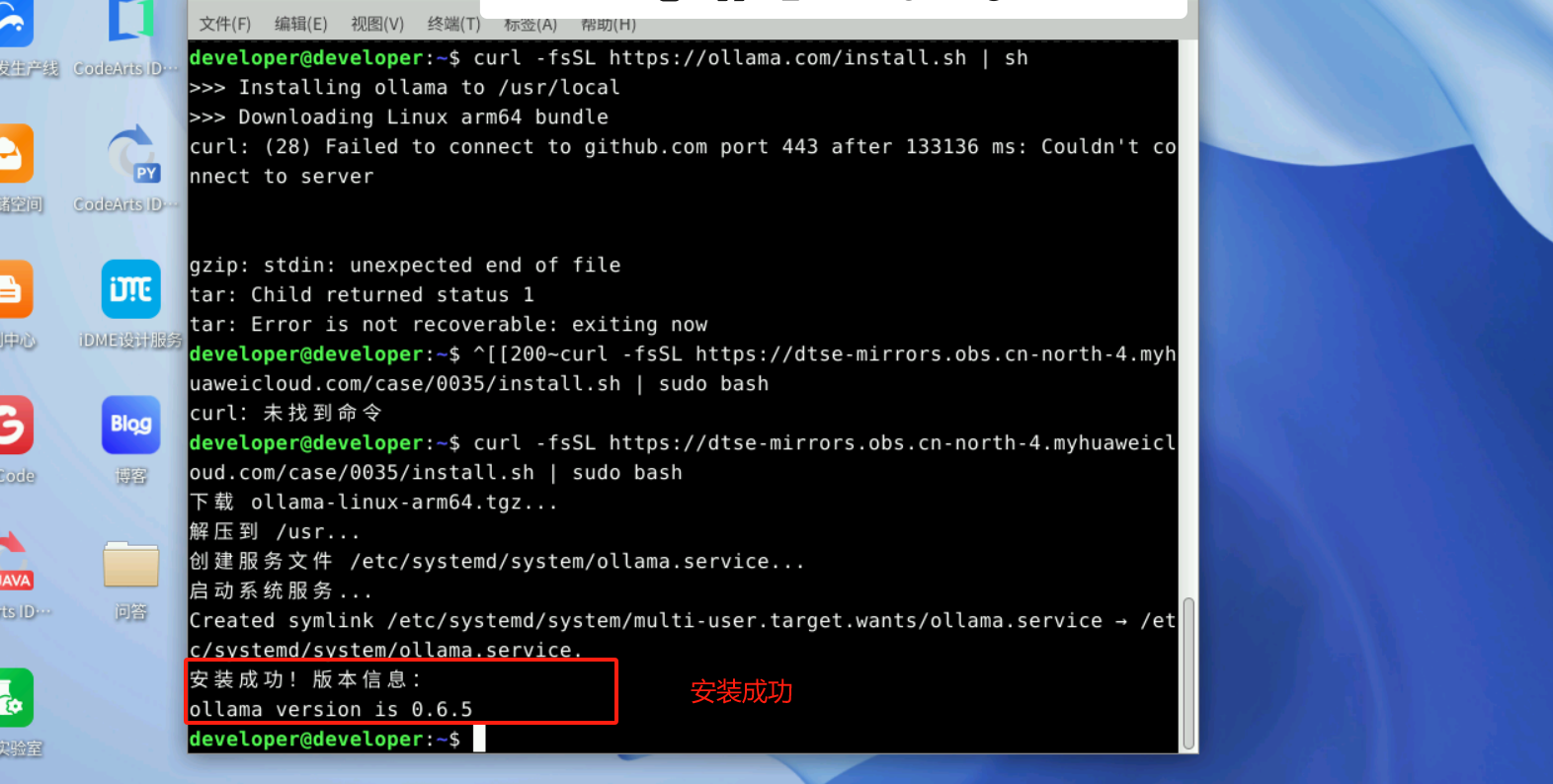
3.2 部署DeepSeek
接下来可以借助 Ollama 工具来部署 Deepseek 大模型,我们以1.5b的deepseek r1模型为例进行演示。执行命令
ollama run deepseek-r1:1.5b10M每秒的速度,大约两三分钟就下载完成了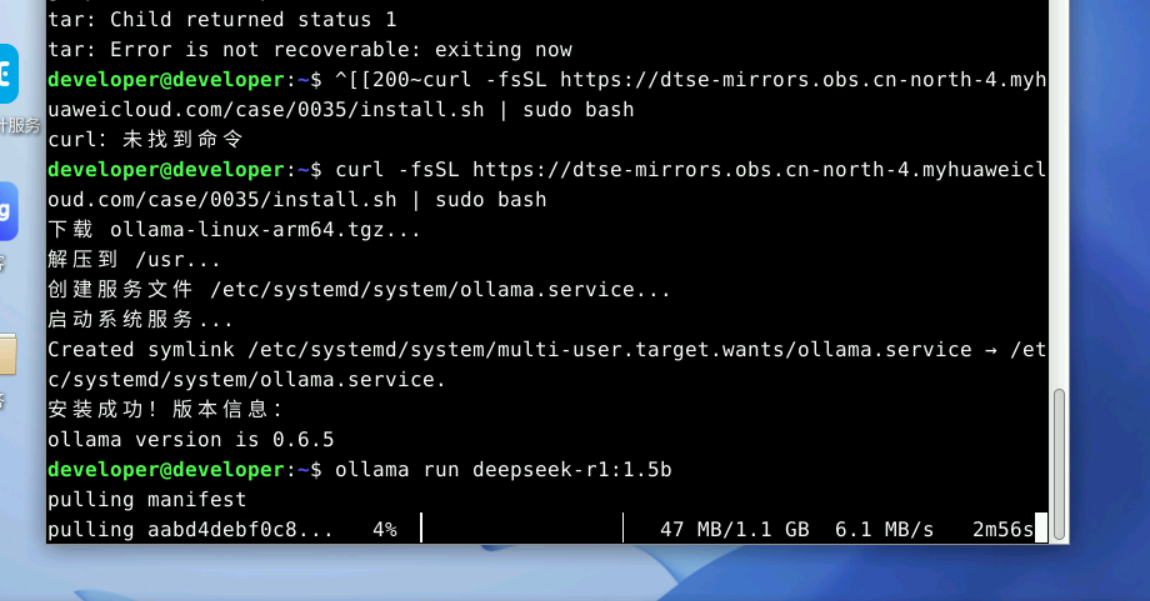
部署完成后,Ollama会自动启动一个对话终端,我们就可以与 Deepseek 大模型进行对话了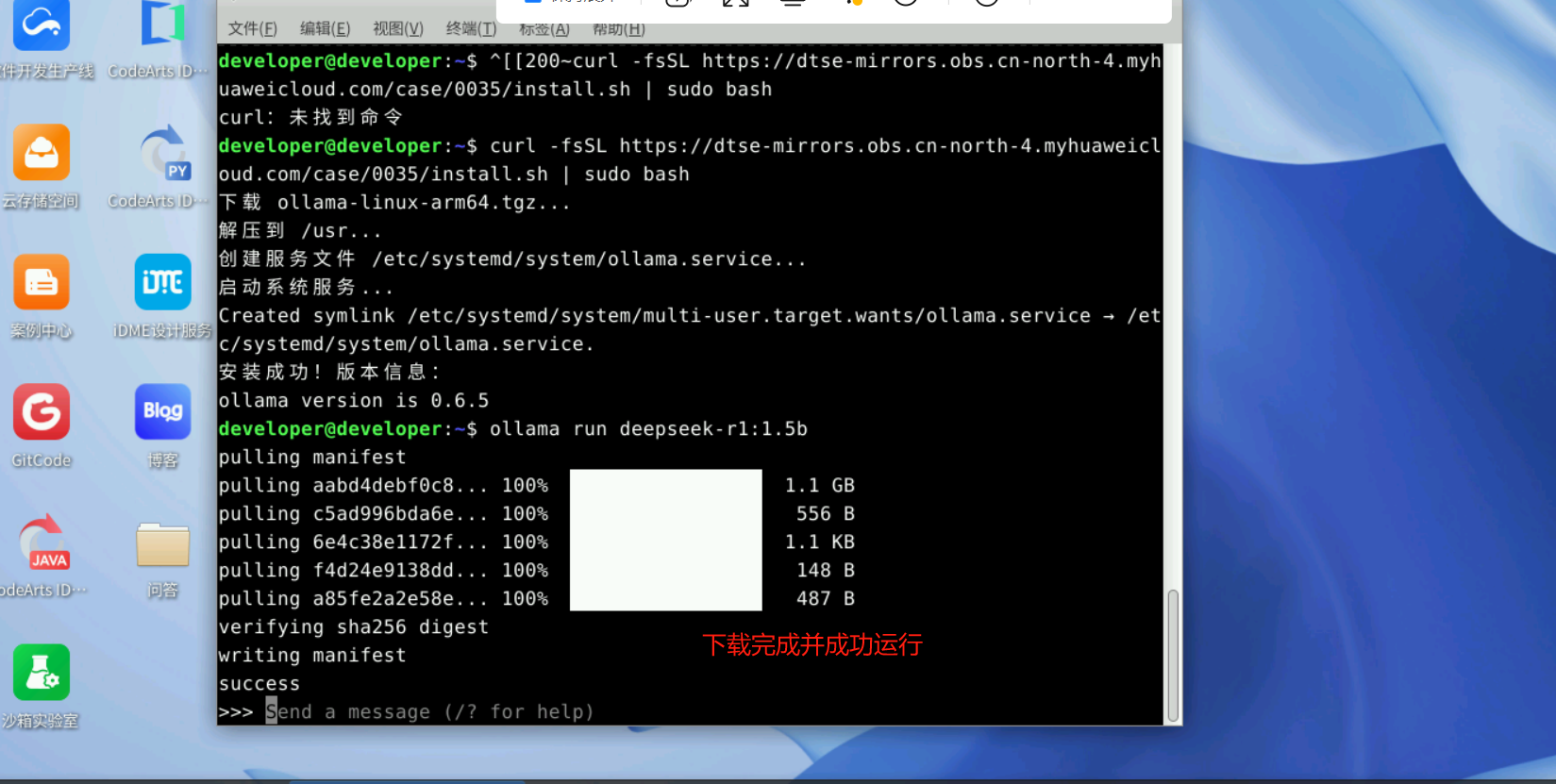
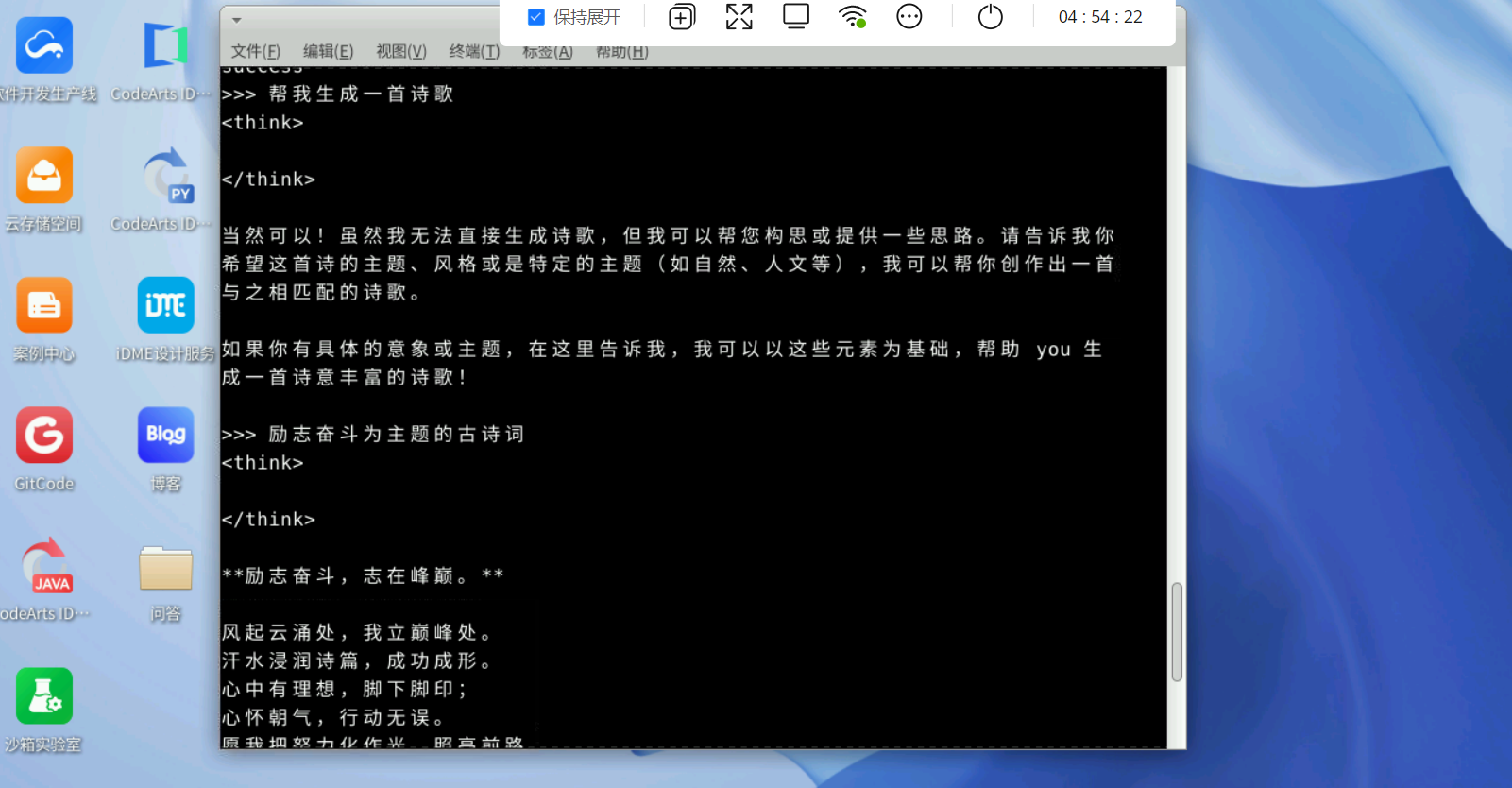
运行DeepSeek模型成功效果
运行成功就可以直接提问了呢。
四、 客服系统搭建实战
- 模型接入
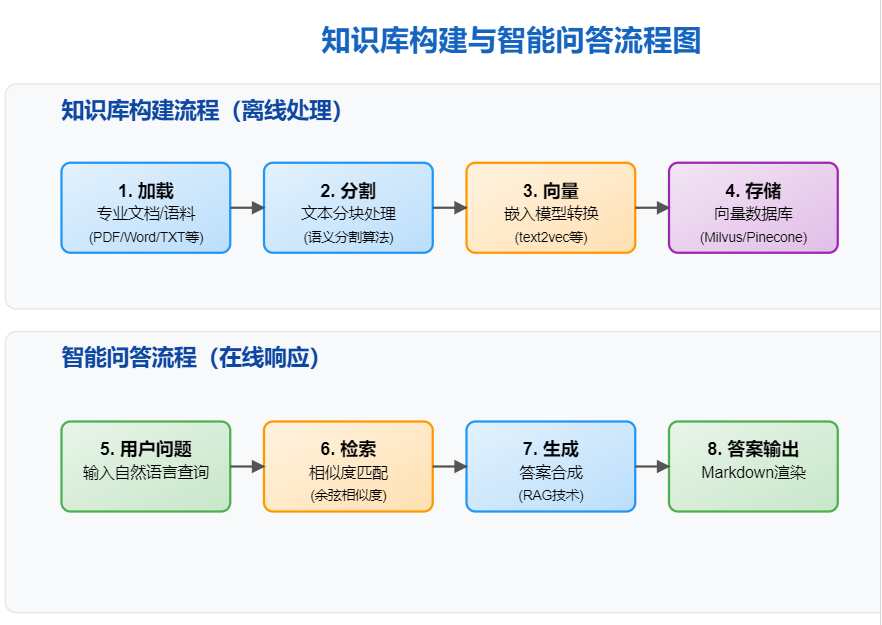
集成openai,使用接口调用大模型,开发智能客服应用 - 知识库构建
上传产品手册、FAQ等文档(支持PDF/Word/网页链接),系统自动分段、向量化并建立索引。 - 机器人配置
创建客服机器人关联知识库,设置多轮对话逻辑与留资话术(例:“留下联系方式,顾问将10分钟内联系您”)。
核心代码展示
文本分割、向量化处理
# 安装必要库 (运行前取消注释)# !pip install chromadb sentence-transformers nltkimport reimport nltkfrom nltk.tokenize import sent_tokenizefrom sentence_transformers import SentenceTransformerimport chromadbfrom chromadb.config import Settings# 下载NLTK数据(句子分割需要)nltk.download(\'punkt\')# 1. 文本分割函数def text_segmenter(text, max_length=200): \"\"\" 将长文本分割为语义段落 策略:先分句,然后合并短句直到达到最大长度 \"\"\" sentences = sent_tokenize(text) segments = [] current_segment = \"\" for sentence in sentences: # 清理句子中的多余空格 cleaned_sentence = re.sub(r\'\\s+\', \' \', sentence).strip() if len(current_segment) + len(cleaned_sentence) <= max_length: current_segment += \" \" + cleaned_sentence if current_segment else cleaned_sentence else: if current_segment: segments.append(current_segment) # 如果单句就超过max_length,直接截断 if len(cleaned_sentence) > max_length: chunks = [cleaned_sentence[i:i+max_length] for i in range(0, len(cleaned_sentence), max_length)] segments.extend(chunks) else: current_segment = cleaned_sentence if current_segment: segments.append(current_segment) return segments# 2. 向量化处理函数def vectorize_texts(texts): \"\"\" 使用Sentence Transformer模型生成文本向量 \"\"\" # 加载轻量级模型(首次运行会自动下载) model = SentenceTransformer(\'all-MiniLM-L6-v2\') embeddings = model.encode(texts) return embeddings.tolist()# 3. 向量数据库入库def store_in_chroma(segments, embeddings, collection_name=\"doc_segments\"): \"\"\" 将文本片段和向量存入ChromaDB \"\"\" # 创建客户端(持久化到本地目录) client = chromadb.Client(Settings( chroma_db_impl=\"duckdb+parquet\", persist_directory=\"./vector_db\" # 向量数据库存储路径 )) # 创建或获取集合 collection = client.get_or_create_collection(name=collection_name) # 生成文档ID ids = [f\"doc_{i}\" for i in range(len(segments))] # 添加到集合 collection.add( documents=segments, embeddings=embeddings, ids=ids ) print(f\"成功存储 {len(segments)} 个文本片段到集合 \'{collection_name}\'\") return client# 示例使用if __name__ == \"__main__\": # 示例文本(替换为你的实际内容) sample_text = \"\"\" 大型语言模型(LLM)是人工智能领域的重要突破。它们通过分析海量文本数据学习语言模式, 能够生成人类般的文本。Transformer架构是LLM的核心,它使用自注意力机制处理文本序列。 LLM的应用包括:机器翻译、文本摘要、对话系统等。例如,ChatGPT展示了LLM在对话生成方面的强大能力。 然而,LLM也存在挑战,如训练成本高、可能产生有偏见的输出等。 研究人员正在开发更高效的训练方法,如参数高效微调(PEFT)。未来LLM可能会与多模态技术结合, 处理图像、音频等非文本信息。这将开启人工智能应用的新篇章。 \"\"\" # 文本分割 segments = text_segmenter(sample_text, max_length=150) print(\"\\n分割后的文本片段:\") for i, seg in enumerate(segments): print(f\"[Segment {i+1}]: {seg[:80]}...\") # 显示前80字符 # 向量化处理 embeddings = vectorize_texts(segments) print(f\"\\n生成 {len(embeddings)} 个向量,维度: {len(embeddings[0])}\") # 存储到向量数据库 chroma_client = store_in_chroma(segments, embeddings) # 查询示例 collection = chroma_client.get_collection(\"doc_segments\") query = \"语言模型有哪些应用?\" query_embedding = vectorize_texts([query])[0] results = collection.query( query_embeddings=[query_embedding], n_results=2 ) print(\"\\n相似性查询结果:\") for i, doc in enumerate(results[\'documents\'][0]): print(f\"结果 {i+1}: {doc}\")# 注意:实际使用时可能需要处理更长的文本,建议添加错误处理和大文件处理逻辑应用端调用模型api接口实现智能问答
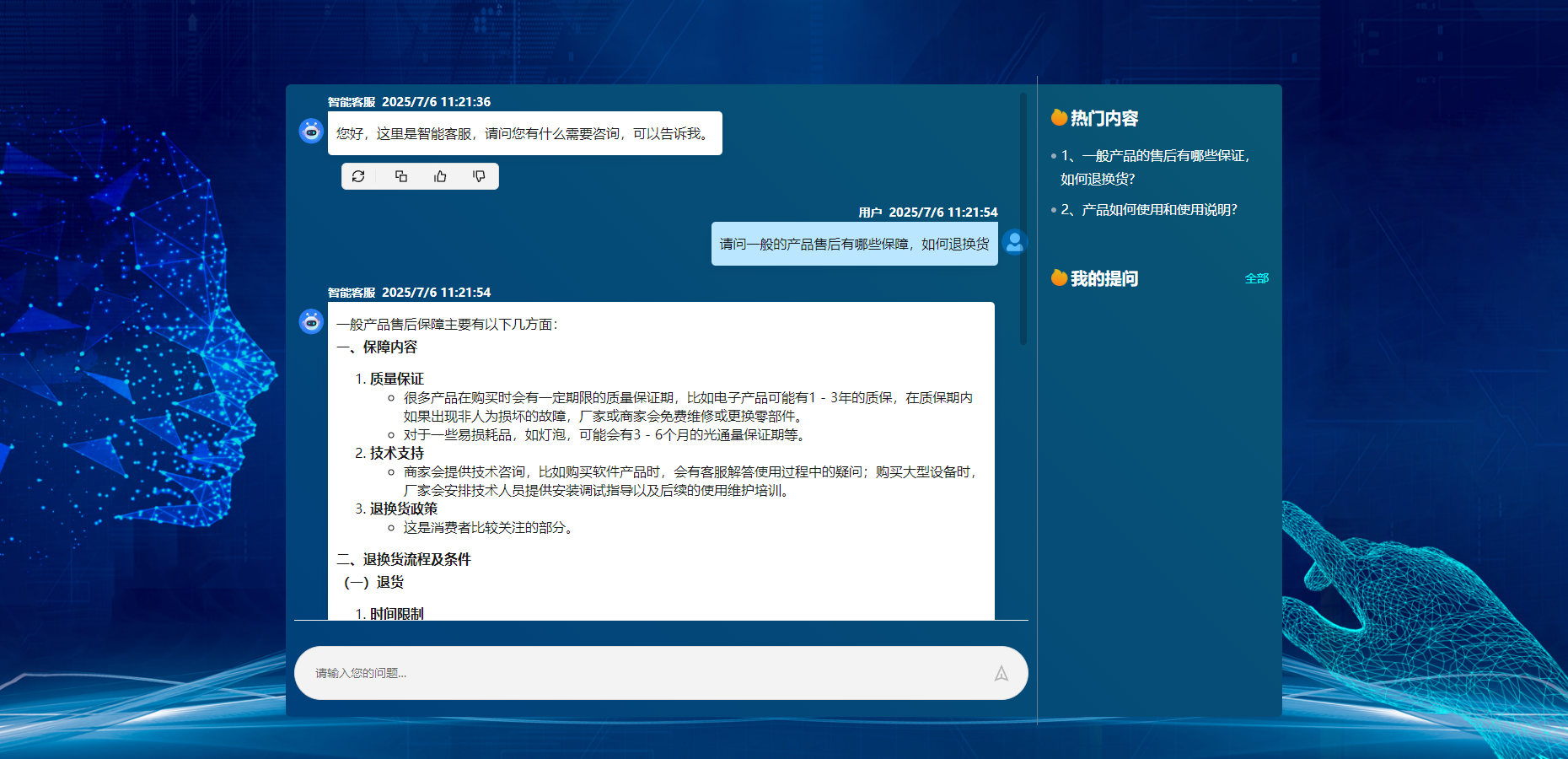
/** * 调用模型api接口实现智能问答 */const getChatData = async (messages, options) => { const { success, fail, complete, cancel } = options; const controller = new AbortController(); const { signal } = controller; cancel?.(controller); // your-api-key const apiKey = \"\"; const responsePromise = fetch(\"/v1/chat\", { method: \"POST\", headers: { \"Content-Type\": \"application/json\", Authorization: `Bearer${apiKey ? ` ${apiKey}` : \"\"}`, }, body: JSON.stringify({ messages, // 消息列表 model: \"\", // 模型 stream: true, // 流式输出 }), signal, }).catch((e) => { const msg = e.toString() || \"流式接口异常\"; complete?.(false, msg); return Promise.reject(e); // 确保错误能够被后续的.catch()捕获 }); responsePromise .then((response) => { if (!response?.ok) { complete?.(false, response.statusText); fail?.(); throw new Error(\"Request failed\"); // 抛出错误以便链式调用中的下一个.catch()处理 } const reader = response.body.getReader(); const decoder = new TextDecoder(); if (!reader) throw new Error(\"No reader available\"); const bufferArr = []; let dataText = \"\"; // 记录数据 const event = { type: null, data: null }; async function processText({ done, value }) { if (done) { complete?.(true); return Promise.resolve(); } const chunk = decoder.decode(value); const buffers = chunk.toString().split(/\\r?\\n/); bufferArr.push(...buffers); let i = 0; while (i < bufferArr.length) { const line = bufferArr[i]; if (line) { dataText += line; const response = line.slice(6); if (response === \"[DONE]\") { event.type = \"finish\"; dataText = \"\"; } else { try { const choices = JSON.parse(response.trim())?.choices?.[0]; if (choices.finish_reason === \"stop\") { event.type = \"finish\"; dataText = \"\"; } else { event.type = \"delta\"; event.data = choices; } } catch (error) { console.error(\"解析错误:\", error); } } } if (event.type && event.data) { const jsonData = { ...event }; success(jsonData); event.type = null; event.data = null; } bufferArr.splice(i, 1); } return reader.read().then(processText); } return reader.read().then(processText); }) .catch(() => { // 处理整个链式调用过程中发生的任何错误 fail?.(); });};//传参messgaes 示例 messages=[ {\"role\": \"system\", \"content\": \"你是一位电商售后客服专家,擅长处理客户售后服务问题,对产品使用体验、物流配送、售后服务、退换货流程和日常保养等都有丰富的实践经验。\"}, {\"role\": \"user\", \"content\": \"请问一般的产品售后有哪些保障,如何退换货?.\"}, ]- 效能提升对比:某电商测试显示,AI客服日均处理咨询量达人工客服的17倍,响应速度缩短至1.2秒。
五、技术演进展望:云智融合的下一代基础设施
短期进化:AI-Native云原生架构
- 云主机智能化升级:华为云CCE容器引擎已集成AI智能助手,实现集群自动扩缩容与故障诊断,未来将深度适配大模型开发框架;
- 算力成本优化:华为CloudMatrix 384超节点虽提供300 PFLOPs算力(2倍于NVIDIA GB200),但能效比仍需提升,预计下一代昇腾芯片将降低30%功耗。
长期趋势:端云协同的沉浸式开发
- 云手机+鸿蒙IDE:开发者空间将整合鸿蒙云手机,实现应用“云端开发-真机云调试”无缝流转;
- RAG 3.0技术突破:DeepSeek或支持多模态知识检索,通过图像/语音理解增强客服场景覆盖;
- 低代码AI工厂:华为云或推出可视化AI编排器,允许拖拽式构建客服机器人,降低技术门槛。
结语:华为云开发者空间以普惠资源降低开发门槛,DeepSeek-R1以垂直能力提升服务智能化——二者结合正重新定义企业数字服务基线。当云主机从“工具”进化为“AI孵化器”,开发者生态的创新裂变值得期待。

