【打怪升级 - 03】YOLO11/YOLO12/YOLOv10/YOLOv8 完全指南:从理论到代码实战,新手入门必看教程
引言:为什么选择 YOLO?
在目标检测领域,YOLO(You Only Look Once)系列模型一直以其高效性和准确性备受关注。作为新版本,YOLO系列的新版本总能在前辈的基础上进行了多项改进,包括更高的检测精度、更快的推理速度以及更强的小目标检测能力。
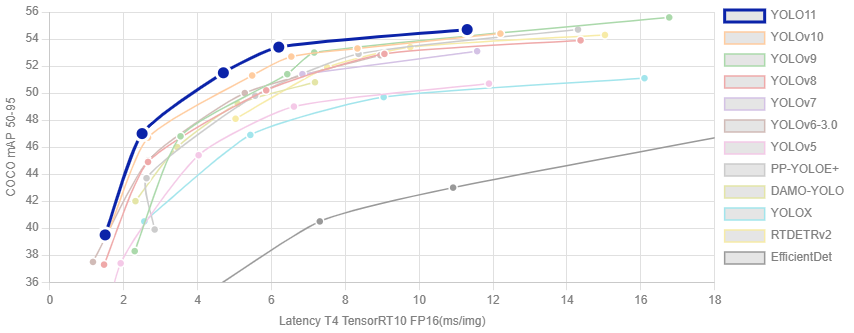
无论是无论是计算机视觉领域的初学者,还是希望快速部署目标检测系统的开发者,YOLO系列 都是一个理想的选择。本指南将带你从理论基础开始,逐步掌握 YOLO系列的核心原理与实战技能。
一、YOLO 核心理论解析
1.1 YOLO 算法的基本思想
YOLO 系列的核心思想是将目标检测任务转化为一个回归问题。与传统的两阶段检测算法(先产生候选区域再进行分类)不同,YOLO 采用单阶段检测策略,直接在一张图片上同时预测目标的位置和类别。
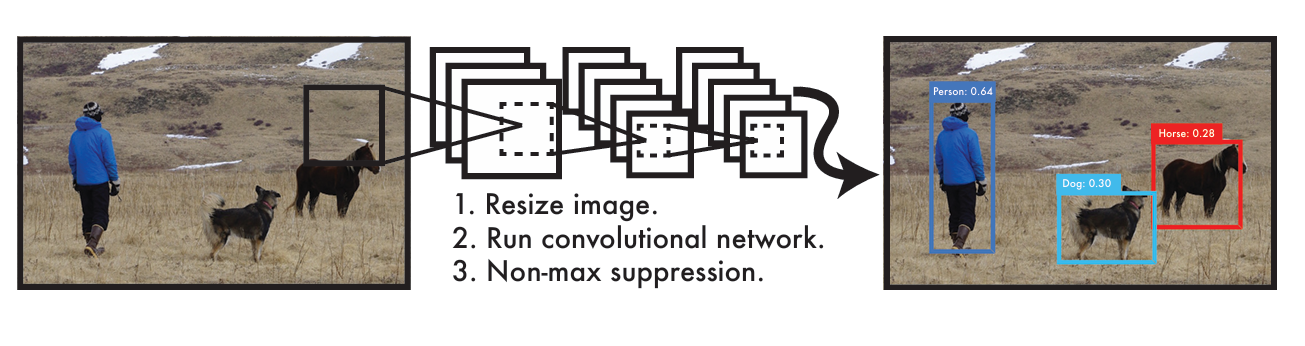
这种设计使得 YOLO 的检测速度远超传统方法,能够满足实时检测的需求。
1.2 YOLO11/12 的核心改进(简单介绍~ 本文侧重实战)
YOLO11 在之前版本的基础上进行了多项关键改进:
-
新的骨干网络:采用更高效的特征提取网络,在减少计算量的同时提升特征表达能力
-
改进的颈部结构:优化了特征融合机制,增强了多尺度特征处理能力
-
优化的损失函数:提高了模型对小目标和遮挡目标的检测能力
-
动态锚框机制:根据不同数据集自动调整锚框参数,提升检测精度
YOLO12 则引入了一种以注意力为中心的架构,它不同于以往YOLO 模型中使用的基于 CNN 的传统方法,但仍保持了许多应用所必需的实时推理速度。该模型通过对注意力机制和整体网络架构进行新颖的方法创新,实现了最先进的物体检测精度,同时保持了实时性能。
1.3 目标检测的基本概念
在深入 YOLO系列 之前,我们需要了解几个关键概念:
-
边界框(Bounding Box):用于定位目标位置的矩形框,通常由 (x, y, w, h) 表示
-
置信度(Confidence):模型对预测框中存在目标的信任程度
-
交并比(IoU):衡量预测框与真实框重叠程度的指标
-
非极大值抑制(NMS):用于去除重复检测框的后处理方法
二、环境搭建:从零开始配置YOLO11/YOLO12/YOLOv10/YOLOv8
2.1 硬件要求
YOLO系列 虽然对硬件要求不算极端,但为了获得良好的训练和推理体验,建议配置:
- CPU:至少 4 核处理器
- GPU:NVIDIA 显卡(推荐 RTX 3060 及以上,支持 CUDA)
- 内存:至少 8GB(推荐 16GB 及以上)
- 硬盘:至少 10GB 空闲空间
2.2 软件安装步骤
参考我们之前的文章(含视频讲解)
【打怪升级 - 01】保姆级机器视觉入门指南:硬件选型 + CUDA/cuDNN/Miniconda/PyTorch/Pycharm 安装全流程(附版本匹配秘籍)
2.2.1 安装 ultralytics
Ultralytics 库已经集成了YOLO11/YOLO12/YOLOv10/YOLOv8,安装命令如下:
pip3 install ultralytics2.2.4 验证安装
from ultralytics import YOLO# 加载预训练模型model = YOLO(\'yolo11n.pt\')# 打印模型信息print(model.info())如果运行无错误并显示模型信息,则安装成功。
三、YOLO11/YOLO12/YOLOv10/YOLOv8 实战:图像与视频检测
3.1 使用预训练模型进行图像检测
YOLO11/YOLO12/YOLOv10/YOLOv8提供了多个预训练模型,从小型模型(n)到大型模型(x),可以根据需求选择:
from ultralytics import YOLOimport cv2# 加载预训练模型model = YOLO(\'yolo11n.pt\') # 小型模型,速度快# model = YOLO(\'yolo11s.pt\') # 中型模型,平衡速度和精度# model = YOLO(\'yolo11m.pt\') # 大型模型,精度更高# model = YOLO(\'yolo11l.pt\') # 更大的模型# model = YOLO(\'yolo11x.pt\') # 最大模型,精度最高# Load a COCO-pretrained YOLO12n model#model = YOLO(\"yolo12n.pt\")# Load a COCO-pretrained YOLOv10n model#model = YOLO(\"yolov10n.pt\")# Load a COCO-pretrained YOLOv8n model#model = YOLO(\"yolov8n.pt\")# 检测单张图片results = model(\'test.jpg\') # 替换为你的图片路径# 处理检测结果for result in results: # 绘制检测框 annotated_img = result.plot() # 显示结果 cv2.imshow(\'YOLO11 Detection\', annotated_img) cv2.waitKey(0) cv2.destroyAllWindows() # 保存结果 result.save(\'result.jpg\')3.2 视频目标检测
YOLO11/YOLO12/YOLOv10/YOLOv8 同样支持视频文件和摄像头实时检测:
from ultralytics import YOLOimport cv2# 加载模型model = YOLO(\'yolo11n.pt\')# Load a COCO-pretrained YOLO12n model#model = YOLO(\"yolo12n.pt\")# Load a COCO-pretrained YOLOv10n model#model = YOLO(\"yolov10n.pt\")# Load a COCO-pretrained YOLOv8n model#model = YOLO(\"yolov8n.pt\")# 视频文件检测video_path = \"input.mp4\"cap = cv2.VideoCapture(video_path)# 获取视频属性width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))fps = cap.get(cv2.CAP_PROP_FPS)# 设置输出视频output_path = \"output.mp4\"fourcc = cv2.VideoWriter_fourcc(*\'mp4v\')out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))while cap.isOpened(): ret, frame = cap.read() if not ret: break # 检测帧 results = model(frame) # 绘制检测结果 annotated_frame = results[0].plot() # 显示帧 cv2.imshow(\'YOLO Video Detection\', annotated_frame) # 写入输出视频 out.write(annotated_frame) # 按q退出 if cv2.waitKey(1) & 0xFF == ord(\'q\'): break# 释放资源cap.release()out.release()cv2.destroyAllWindows()3.3 摄像头实时检测
只需将视频路径替换为摄像头索引即可实现实时检测:
# 摄像头实时检测cap = cv2.VideoCapture(0) # 0表示默认摄像头四、模型训练:自定义数据集训练 YOLO11/YOLO12/YOLOv10/YOLOv8
4.1 数据集准备
YOLO系列需要特定格式的数据集,基本结构如下:
dataset/├── images/│ ├── train/│ │ ├── img1.jpg│ │ ├── img2.jpg│ │ └── ...│ └── val/│ ├── img1.jpg│ ├── img2.jpg│ └── ...└── labels/ ├── train/ │ ├── img1.txt │ ├── img2.txt │ └── ... └── val/ ├── img1.txt ├── img2.txt └── ...每个图像对应一个标签文件,标签格式为:
class_id x_center y_center width height其中所有坐标都是归一化的(0-1 范围)。
4.2 创建配置文件
创建一个 YAML 配置文件(例如 coco8.yaml):
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license# COCO8 dataset (first 8 images from COCO train2017) by Ultralytics# Documentation: https://docs.ultralytics.com/datasets/detect/coco8/# Example usage: yolo train data=coco8.yaml# parent# ├── ultralytics# └── datasets# └── coco8 ← downloads here (1 MB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]path: coco8 # dataset root dirtrain: images/train # train images (relative to \'path\') 4 imagesval: images/val # val images (relative to \'path\') 4 imagestest: # test images (optional)# Classesnames: 0: person 1: bicycle 2: car 3: motorcycle 4: airplane 5: bus 6: train 7: truck 8: boat 9: traffic light 10: fire hydrant 11: stop sign 12: parking meter 13: bench 14: bird 15: cat 16: dog 17: horse 18: sheep 19: cow 20: elephant 21: bear 22: zebra 23: giraffe 24: backpack 25: umbrella 26: handbag 27: tie 28: suitcase 29: frisbee 30: skis 31: snowboard 32: sports ball 33: kite 34: baseball bat 35: baseball glove 36: skateboard 37: surfboard 38: tennis racket 39: bottle 40: wine glass 41: cup 42: fork 43: knife 44: spoon 45: bowl 46: banana 47: apple 48: sandwich 49: orange 50: broccoli 51: carrot 52: hot dog 53: pizza 54: donut 55: cake 56: chair 57: couch 58: potted plant 59: bed 60: dining table 61: toilet 62: tv 63: laptop 64: mouse 65: remote 66: keyboard 67: cell phone 68: microwave 69: oven 70: toaster 71: sink 72: refrigerator 73: book 74: clock 75: vase 76: scissors 77: teddy bear 78: hair drier 79: toothbrush# Download script/URL (optional)download: https://github.com/ultralytics/assets/releases/download/v0.0.0/coco8.zip4.3 开始训练
from ultralytics import YOLO# 加载基础模型model = YOLO(\'yolo11n.pt\')# Load a COCO-pretrained YOLO12n model#model = YOLO(\"yolo12n.pt\")# Load a COCO-pretrained YOLOv10n model#model = YOLO(\"yolov10n.pt\")# Load a COCO-pretrained YOLOv8n model#model = YOLO(\"yolov8n.pt\")# 训练模型results = model.train( data=\'custom_data.yaml\', # 配置文件路径 epochs=50, # 训练轮数 imgsz=640, # 输入图像大小 batch=16, # 批次大小 device=0, # GPU编号,-1表示使用CPU workers=4, # 数据加载线程数 project=\'my_yolo11_project\', # 项目名称 name=\'custom_training\' # 训练名称)4.4 训练过程监控
训练过程中,可以通过以下方式监控:
- 控制台输出:包含每轮的损失值、精度等指标
- TensorBoard:运行
tensorboard --logdir=my_yolo_project/custom_training查看详细曲线 - 训练生成的图表:保存在
my_yolo11_project/custom_training/results.png
五、模型评估与优化
5.1 评估模型性能
训练完成后,可以评估模型在验证集上的表现:
# 评估模型metrics = model.val()# 打印评估指标print(f\"mAP@0.5: {metrics.box.map50:.3f}\")print(f\"mAP@0.5:0.95: {metrics.box.map:.3f}\")关键评估指标:
- mAP@0.5:IoU 阈值为 0.5 时的平均精度
- mAP@0.5:0.95:IoU 阈值从 0.5 到 0.95 的平均精度
5.2 模型优化策略
如果模型性能不理想,可以尝试以下优化策略:
-
增加训练数据:收集更多多样化的样本(用的最多的方法~)
-
数据增强
:在训练时使用更多数据增强方法
model.train(data=\'custom_data.yaml\', epochs=50, augment=True) -
调整学习率:根据训练曲线调整学习率
-
使用更大的模型:如从 yolo11n 换成 yolo11s 或更大的模型
-
延长训练时间:增加训练轮数
-
调整图像大小:尝试更大的输入尺寸(如 800 或 1024)
六、模型部署
6.1 导出为其他格式
YOLO11/YOLO12/YOLOv10/YOLOv8 支持导出为多种部署格式:
# 导出为ONNX格式model.export(format=\'onnx\')# 导出为TensorRT格式(需要安装TensorRT)model.export(format=\'engine\')# 导出为CoreML格式(适用于iOS设备)model.export(format=\'coreml\')6.2 构建简单的 Web 应用
使用 Flask 构建一个简单的 YOLO目标检测 Web 服务:
from flask import Flask, request, jsonifyfrom ultralytics import YOLOimport cv2import base64import numpy as npapp = Flask(__name__)model = YOLO(\'yolo11n.pt\')# yolo12n#model = YOLO(\"yolo12n.pt\")# yolov10n#model = YOLO(\"yolov10n.pt\")# yolov8n#model = YOLO(\"yolov8n.pt\")@app.route(\'/detect\', methods=[\'POST\'])def detect(): # 获取图像数据 data = request.json img_data = base64.b64decode(data[\'image\']) nparr = np.frombuffer(img_data, np.uint8) img = cv2.imdecode(nparr, cv2.IMREAD_COLOR) # 检测 results = model(img) # 处理结果 detections = [] for result in results: for box in result.boxes: x1, y1, x2, y2 = box.xyxy[0].tolist() conf = box.conf[0].item() cls = box.cls[0].item() detections.append({ \'class\': model.names[int(cls)], \'confidence\': conf, \'bbox\': [x1, y1, x2, y2] }) return jsonify({\'detections\': detections})if __name__ == \'__main__\': app.run(host=\'0.0.0.0\', port=5000)七、常见问题与解决方案
- 训练时显存不足
- 减小批次大小(batch size)
- 减小输入图像尺寸(imgsz)
- 使用更小的模型
- 检测精度低
- 检查数据集标注是否准确
- 增加训练轮数
- 尝试更大的模型
- 调整学习率策略
- 推理速度慢
- 使用更小的模型
- 减小输入图像尺寸
- 确保使用 GPU 进行推理
- 导出为 TensorRT 等优化格式
结语
通过本指南,你已经掌握了 YOLO系列 的基本理论和实战技能,包括环境搭建、模型使用、自定义训练和部署应用。


