【C/C++ 面试必看】深入理解内存管理:从内存分布到 new/delete 底层原理

🔥个人主页:爱和冰阔乐
📚专栏传送门:《数据结构与算法》 、C++
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

文章目录
- 前言
- 一、C/C++ 程序的内存分布
-
- 1.内存区域划分与变量定位
- 2. 经典示例分析
- 二、C 语言的动态内存管理
- 三、C++ 的内存管理升级
-
- 1. new/delete操作内置类型
- 2 . 对自定义类型:new/delete 的核心优势
- 3 .malloc/free和new/delete的区别
- 四、深入底层:new/delete 的实现原理
- 五、new和delete的实现原理
- 六、定位 new 表达式
- 七、源码
- 总结
前言
内存管理是 C/C++ 开发的核心能力,也是面试高频考点(比如字节、腾讯等大厂常问malloc与new的区别、new的实现原理)。很多开发者对内存管理的理解停留在 “会用malloc/freenew/delete”,但缺乏对底层逻辑和内存分布的系统认知。本文将从内存区域划分、C 语言动态内存管理、C++ 内存管理升级、底层原理对比四个维度,帮你彻底吃透 C/C++ 内存管理,应对面试和开发中的实际问题。
一、C/C++ 程序的内存分布
1.内存区域划分与变量定位
要理解 C/C++ 程序的内存分布,我们可以先从计算机的核心硬件资源说起:CPU 是负责逻辑运算与指令执行的核心;GPU 作为并行计算能力突出的协处理器,更擅长图形渲染、机器学习等需要大规模重复计算的场景;内存是程序运行时的 “临时工作台”,用于快速存取数据;磁盘则是长期存储数据的 “仓库”。
程序能运行的本质,是源代码经编译后转化为机器可执行的指令。若将操作系统比作一座工厂,那么进程就是工厂里执行具体任务的 “工人”—— 每个程序运行时都会对应一个或多个进程,它们按照编译后的指令开展工作。就像工人干活需要原料和工具,进程的运行也离不开资源支撑:CPU 负责调度执行指令,内存负责存放指令和数据。正因如此,当电脑上同时运行着成百上千个进程时,操作系统必须精准地为它们分配 CPU 时间片与内存空间,才能保证整个 “工厂” 高效运转。
那么C/C++分配内存是以什么形式分配的呢?
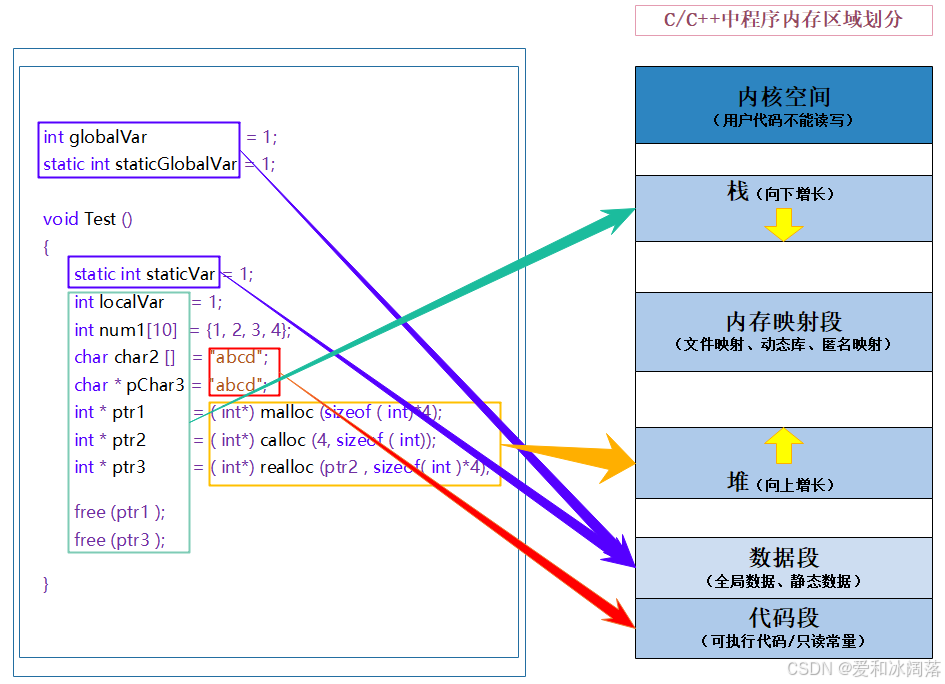
我们写的程序时不同的数据时要分配到不同区域的,如在程序中会有函数调用建立栈帧的局部数据,还有一些需要长期运行的静态变量,全局数据,不被修改的常量数据,需要动态申请的数据如数据结构中的链表
在每个进程下都有以下的空间区域,以下的是虚拟内存需要和物理内存进行映射,在后面的linux中会有介绍
数据存储时需要分区的,下面我们简单介绍下常见的几个区,在linux中会有详细介绍
1 .栈又叫堆栈–非静态局部变量/函数参数/返回值等等,栈是向下增长的。
2 . 内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。(Linux会详细介绍,这里知识了解一下)
3 . 堆用于程序运行时动态内存分配,堆是可以上增长的。
4 . 数据段–存储全局数据和静态数据。
5 . 代码段–可执行的代码/只读常量。
2. 经典示例分析
上面的内存分区我们已经有所了解,下面我们来看这段经典代码,思考每个变量存在哪个内存区域:
int globalVar = 1;static int staticGlobalVar = 1;void Test(){ static int staticVar = 1; int localVar = 1; int num1[10] = { 1, 2, 3, 4 }; char char2[] = \"abcd\"; const char* pChar3 = \"abcd\"; int* ptr1 = (int*)malloc(sizeof(int) * 4); int* ptr2 = (int*)calloc(4, sizeof(int)); int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4); free(ptr1); free(ptr3);}
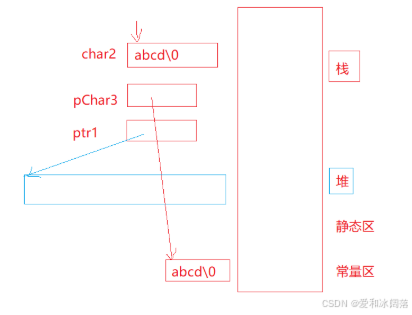
在前五个题目中很容易看出各个变量存放的位置,我们来看后面五个,首先由于a,b,c,d,\\0常量存放在常量区,char2是我们在栈上开辟的5个字节的数组,我们把a,b,c,d,\\0拷贝到栈上,char2数组名代表数组首元素地址也存放在栈中,那么*char2便是首元素也是在栈中
pchar3是栈中的局部变量,占4个字节是存放指针指向a,b,c,d\\的地址,pchar3存放的是a的地址,那么*pchar3就是原来常量区的a
ptr1也是栈上的局部变量的指针,它指向堆上开辟的16个字节的首元素,因此*ptr1就是指向的内容即堆上
二、C 语言的动态内存管理
void Test (){ // 1.malloc/calloc/realloc的区别是什么? int* p2 = (int*)calloc(4, sizeof (int)); int* p3 = (int*)realloc(p2, sizeof(int)*10); // 这里需要free(p2)吗? free(p3 );}【面试题】
1.malloc/calloc/realloc的区别是什么?
2.malloc的实现原理? glibc中malloc实现原理
void* malloc(size_t size)size 字节的连续内存void*,使用时需强转;失败返回 NULLvoid* calloc(size_t n, size_t size)n 个 size 字节的连续内存0NULLvoid* realloc(void* ptr, size_t new_size)new_sizeptr 为 NULL 时,等价于 malloc(new_size);2. 可能“原地扩”或“换地址”,原地址可能被释放;
3. 失败返回
NULL,原地址仍有效三、C++ 的内存管理升级
C 语言的malloc/free在 C++ 中仍可使用,但存在两个致命问题:
1.无法自动初始化(需手动赋值)
2.处理自定义类型时,无法调用构造函数和析构函数(导致对象初始化不完整或资源泄漏)
因此C++又提出了自己的内存管理方式:通过new和delete操作符进行动态内存管理
1. new/delete操作内置类型
内置类型(int、char等)的new/delete用法与malloc/free类似,但更简洁、安全:
void Test(){ // 动态申请一个int类型的空间 int* ptr4 = new int; // 动态申请一个int类型的空间并初始化为10 int* ptr5 = new int(10); // 动态申请10个int类型的空间 int* ptr6 = new int[3]; delete ptr4; delete ptr5; delete[] ptr6;}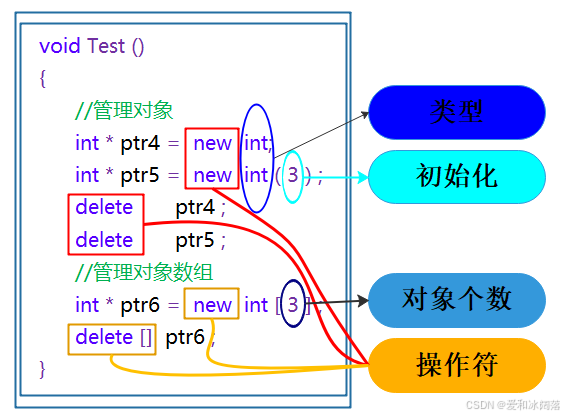
new是关键字不是函数,因此new后面直接跟类型就可以申请对象
申请和释放单个元素的空间,使用new和delete操作符,申请和释放连续的空间,使用new[]和delete[],注意:匹配起来使用
关键注意点:
new与delete、new[ ] 与 delete[ ]必须成对使用!如果用 new[ ] 申请数组,却用 delete释放,会导致内存泄漏(内置类型可能 “看似正常”,但自定义类型会崩溃)
2 . 对自定义类型:new/delete 的核心优势
这是new/delete与malloc/free的本质区别:对自定义类型,new会自动调用构造函数初始化对象,delete会自动调用析构函数清理资源(如动态内存)
class A{public:A(int a = 0): _a(a){cout << \"A():\" << endl;}~A(){cout << \"~A():\" << endl;}private:int _a;};int main(){// new/delete 和 malloc/free最大区别是 new/delete对于【自定义类型】除了开空间还会调用构造函数和析构函数A* p1 = new A;A* p2 = new A(1); //free(p1);delete p1; delete p2; return 0;}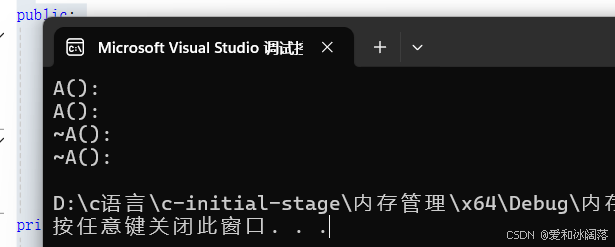
我们在C语言中申请空间失败需要判断下,那么在C++中使用new需要检查吗?
答案是不需要的,这里会引用抛出异常的概念,我们在这里只做简单介绍,后续会详细介绍
new失败了会抛异常,它是由throw(抛出对象),try/catch(对异常进行处理)
换算:
1G = 1024MB = 10241024KB = 10241024*1024Byte
1M 约等于 100w Byte
1G 约等于 10亿 Byte
因此我们发现我们换算成G时根本不需要那么多内存,那么也就很少情况下会失败
那么什么时候下new会失败?在日常情况下是不会失败,因此正常情况下是不需要抛异常。在我们内存没有的时候会失败,如下
int main(){try{// throw try/catch void* p1 = new char[1024 * 1024 * 1024];cout << p1 << endl;void* p2 = new char[1024 * 1024 * 1024];cout << p2 << endl;void* p3 = new char[1024 * 1024 * 1024];cout << p3 << endl;}catch (const exception& e){cout << e.what() << endl;}return 0;}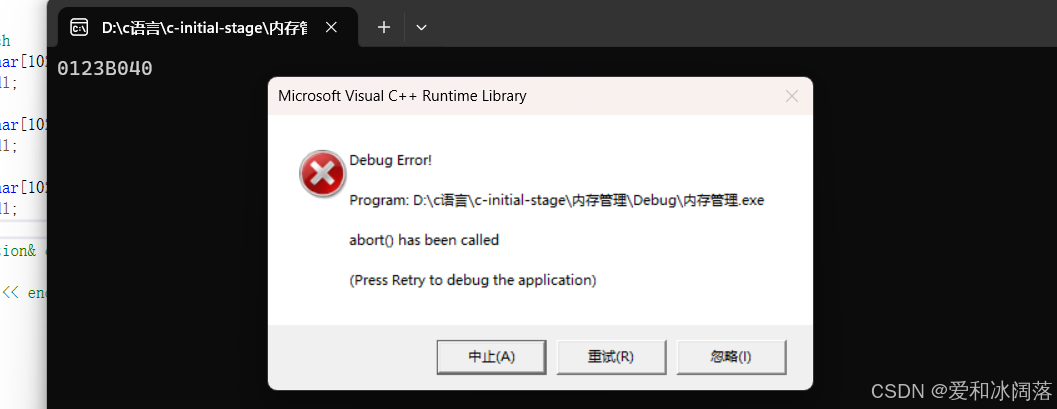
我们发现在X86环境下也就是32位机器下一次申请完1G后就不可以再申请了,这里我们可以使用try——catch进行捕获异常
int main(){try{ //throw try/catch void* p1 = new char[1024 * 1024 * 1024];cout << p1 << endl;void* p2 = new char[1024 * 1024 * 1024];cout << p2 << endl;void* p3 = new char[1024 * 1024 * 1024];cout << p3 << endl;}catch (const exception& e){cout << e.what() << endl;}return 0;}这两种写法都是抛异常
void func(){// throw try/catch int n = 1;while (1){void* p1 = new char[1024 * 1024];cout << p1 << \"->\"<< n<<endl;++n;}}int main(){try{func();}catch (const exception& e){cout << e.what() << endl;}return 0;}
当我们申请内存失败时候,就会报bad allocation代表已经没有内存可以给我们使用了。
这里我们看下电脑上的32位指的是什么?
“32 位” 通常也和地址总线宽度相关(早期 32 位 CPU 的地址总线多为 32 位)。地址总线的位数决定了 CPU 能 “看到” 的最大内存范围:
32 位地址总线能表示的地址范围是 0~2³²-1(二进制),对应到内存容量就是 4GB(2³² 字节 = 4×1024³ 字节)。这意味着 32 位机器理论上最多只能直接支持 4GB 内存(实际中因硬件占用,可用内存通常更少,比如 3.2~3.5GB)。
3 .malloc/free和new/delete的区别

四、深入底层:new/delete 的实现原理
new和delete是用户进行动态内存申请和释放的操作符,operator new 和operator delete是系统提供的全局函数,new在底层调用operator new全局函数来申请空间,delete在底层通过operator delete全局函数来释放空间
在上面我们讲述了new可以开空间并调用构造函数:new是如何做到 “开空间 + 调构造” 的?答案藏在operator new和operator delete这两个全局函数中
下面我们通过operator new的源码来看下,在这里面它调用了malloc,如果malloc为0,就会抛异常,我们看源码发现operator new的底层就是malloc

operator delete源码:
/*operator delete: 该函数最终是通过free来释放空间的*/void operator delete(void *pUserData){ _CrtMemBlockHeader * pHead; RTCCALLBACK(_RTC_Free_hook, (pUserData, 0)); if (pUserData == NULL) return; _mlock(_HEAP_LOCK); /* block other threads */ __TRY /* get a pointer to memory block header */ pHead = pHdr(pUserData); /* verify block type */ _ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse)); _free_dbg( pUserData, pHead->nBlockUse ); __FINALLY _munlock(_HEAP_LOCK); /* release other threads */ __END_TRY_FINALLY return;}/*free的实现*/#define free(p) _free_dbg(p, _NORMAL_BLOCK)通过上述两个全局函数的实现知道,operator new 实际也是通过malloc来申请空间,如果malloc申请空间成功就直接返回,否则执行用户提供的空间不足应对措施,如果用户提供该措施就继续申请,否则就抛异常。operator delete 最终是通过free来释放空间的。
五、new和delete的实现原理
上面解释了为啥new和delete可以申请释放空间的底层是因为malloc和free,但是我们在前面的代码演示自定义类型中发现new和delete还会分别调用构造和析构函数。
因此我们可以认为new是由两部分组成
- 调用operator new函数申请空间
- 在申请的空间上执行构造函数,完成对象的构造
同理delete也是由两部分组成:
- 在空间上执行析构函数,完成对象中资源的清理工作
- 调用operator delete函数释放对象的空间
new T[N]的原理:
- 调用operator new[]函数,在operator new[]中实际调用operator new函数完成N个对象空间的申请
- 在申请的空间上执行N次构造函数
delete [ ] 的原理
- 在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理
- 调用operator delete[]释放空间,实际在operator delete[]中调用operator delete来释
放空间
下面我们从编译底层来看下:
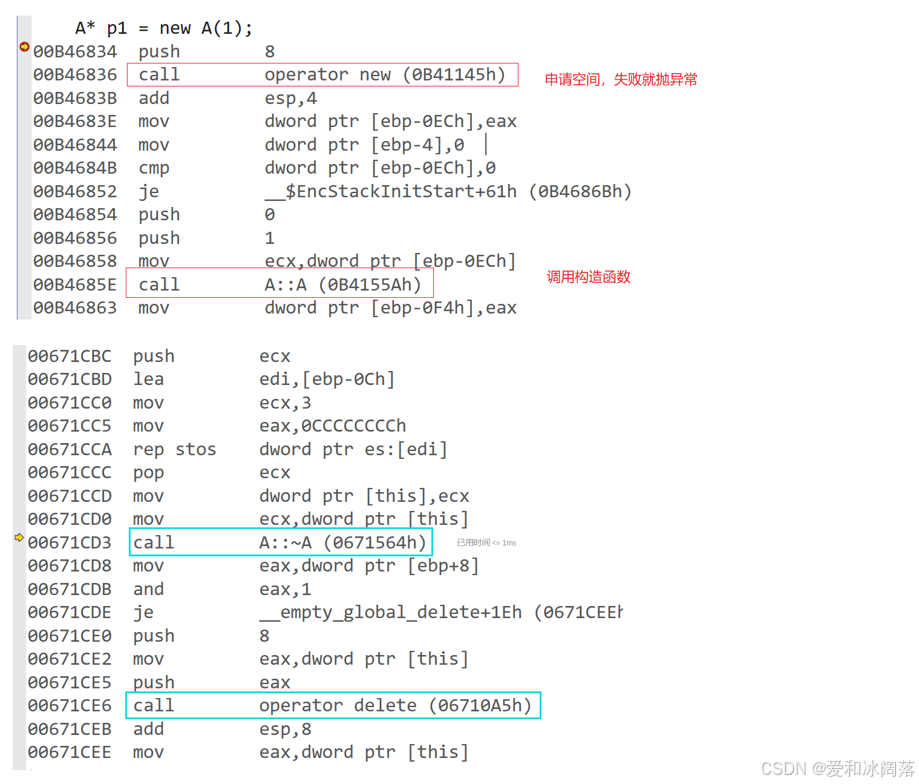
下面我们来看个面试题目,请问这里会内存泄漏或者报错吗
class B{private:int _b1 = 2;int _b2 = 2;};int main(){ int* p1 = new int[10]; // -> malloc delete p1; // -> free //free(p1);}答案是不会,因为是内置类型,不需要调用构造函数和析构函数,底层就是malloc和free
但是如果是自定义类型?
class A{public:A(int a1 = 0, int a2 = 0):_a1(a1), _a2(a2){cout << \"A(int a1 = 0, int a2 = 0)\" << endl;}A(const A& aa):_a1(aa._a1){cout << \"A(const A& aa)\" << endl;}A& operator=(const A& aa){cout << \"A& operator=(const A& aa)\" << endl;if (this != &aa){_a1 = aa._a1;}return *this;}~A(){//delete _ptr;cout << \"~A()\" << endl;}void Print(){cout << \"A::Print->\" << _a1 << endl;}A& operator++(){_a1 += 100;return *this;}private:int _a1 = 1;int _a2 = 1;};class B{private:int _b1 = 2;int _b2 = 2;};int main(){ B*p2=new B[10]; delete p2;A*p3=new A[10];delete p3; return 0;}我发现B没有崩溃,但是A却崩溃,这是为啥,两个delete不都一样吗?为什么一个崩溃一个成功?
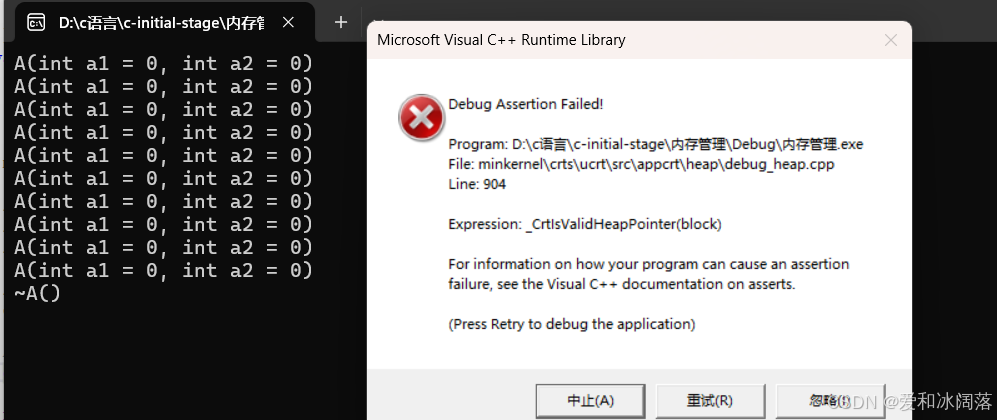
这里我们根据内存对齐算一下,A类型是8字节,B类型也是8字节,经过VS编译器的反汇编的调试,我们发现A多开了4个字节存放10(个数),但是我们new A的时候返回的是下图p3指向的位置,但是申请空间的时候是从4位置开始申请,因此我们delete [ ] 的时候释放的位置应该是从4开始,不能从p3位置释放(不能部分释放)因此p2释放的位置是正确的不会报错,但是p3释放的位置不对,报错。
那么为什么A多开了4个字节存个数,B没有多开空间?B不开是因为编译器优化了,那么为什么B给优化了,因为B没有写析构函数。
A多开的个数是给delete [ ] 用的,因此如果p3使用的是delete [ ],那么p3会往前偏移取到个数,那么delete就知道个数来调用10次析构函数,因此A调用delete p3释放从p3位置开始,且delete对应的是new,只会调用一次析构函数,operator delete释放也是从p3释放,但是申请空间是从4开始,会导致内存泄漏
B原本也需要多开四个字节来存放个数,但是B没有写析构函数,并且B没有资源需要释放,因此B自动生成的析构函数也没有什么用,因此编译器最终给优化了,不需要多开空间,直接调用operator delete 给释放空间即可
但是如果給B写了析构函数,那么编译器就不会优化,也会报错

总结:只要我们规范写好对应的new/delete new[ ]/delete [ ]即可,就不会发生错误
六、定位 new 表达式
定位new表达式是在已分配的原始内存空间中显示调用构造函数初始化一个对象
int main(){A* p1 = new A(1);delete p1; //开空间,没有调用构造函数A* p2 = (A*)operator new(sizeof(A)); //通过定位new显示调用构造 new(p2)A(1); delete p1; //析构函数可以显示调用 p2->~A(); operator delete(p2);//但是构造函数不可以,必须使用定位new//p2->A(1); return 0;}使用格式:
new (place_address) type或者new (place_address) type(initializer-list)
place_address必须是一个指针,initializer-list是类型的初始化列表
在底层来看定位new和普通的new底层都是一样的,那么为什么需要多此一举来显示写?那当然是由其的使用场景:定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用new的定义表达式进行显示调构造函数进行初始化。
内存池(提前申请大块内存,避免频繁new导致的碎片)、高性能场景(减少内存申请开销)。
在编程中有一种技术叫做池化技术:简单来说就是我们建立一个类似池子的东西,将一部分资源存放在其中,更方便更快使用,可以提高性能
常见的池化技术有:内存池 , 线程池 , 连接池等等
下面我们来介绍下内存池,比如我们这里有个业务需要高频申请释放内存块。因为需要高频使用,所以我们建立内存池供我使用,如果不建立,可能会有多个线程一起使用,会排队,效率很低,那么这个专门供我使用的内存是从哪来的?
这里还是从堆要来的,但是内存池别人是使用不了的,专门给我使用,然后我们不断申请释放内存池,这里释放的空间不是回到堆上,是回到内存池中,这样就很方便我们使用
七、源码
内存管理源码
总结
至此,我们已梳理完 C/C++ 内存管理的核心:从内存分区(栈、堆、数据段、代码段的功能与增长特性),到 C 语言 malloc/calloc/realloc/free 的差异与使用陷阱,再到 C++ new/delete 的关键升级 —— 对自定义类型自动调用构造 / 析构函数,也拆透了 new [] 与 delete [] 必须匹配的底层原因(有析构函数的类会多存对象个数,错用必崩溃),还提及了定位 new 与内存池的实践意义(解决高频内存操作的性能与碎片问题)。这些内容不只是大厂面试高频考点,更是实际开发中规避内存泄漏、堆损坏等 bug 的关键,搞懂它们不仅能帮你应对面试,更能让你从 “会写代码” 进阶到 “写好代码”,真正掌握程序的 “内存账本”


