Seaborn可视化
4.3.1 什么是Seaborn
Seaborn是一个基于Matplotlib的Python可视化库,旨在简化数据可视化的过程。它提供了更高级的接口,用于生成漂亮和复杂的统计图表,同时也能保持与Pandas数据结构的良好兼容性。
4.3.2 单变量可视化
使用penguins(企鹅)数据集,其中包含7个字段:
- species:企鹅种类(Adelie、Gentoo、Chinstrap)。
- island:观测岛屿(Torgersen, Biscoe, Dream)。
- bill_length_mm:喙(嘴)长度(毫米)。
- bill_depth_mm:喙深度(毫米)。
- flipper_length_mm:脚蹼长度(毫米)。
- body_mass_g:体重(克)。
- sex:性别(Male、Female)。
加载数据:
Pythonimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltplt.rcParams[\"font.sans-serif\"] = [\"KaiTi\"]penguins = pd.read_csv(\"data/penguins.csv\")penguins.dropna(inplace=True)penguins.info()# # Index: 333 entries, 0 to 343# Data columns (total 7 columns):# # Column Non-Null Count Dtype# --- ------ -------------- -----# 0 species 333 non-null object# 1 island 333 non-null object# 2 bill_length_mm 333 non-null float64# 3 bill_depth_mm 333 non-null float64# 4 flipper_length_mm 333 non-null float64# 5 body_mass_g 333 non-null float64# 6 sex 333 non-null object# dtypes: float64(4), object(3)# memory usage: 20.8+ KB直方图
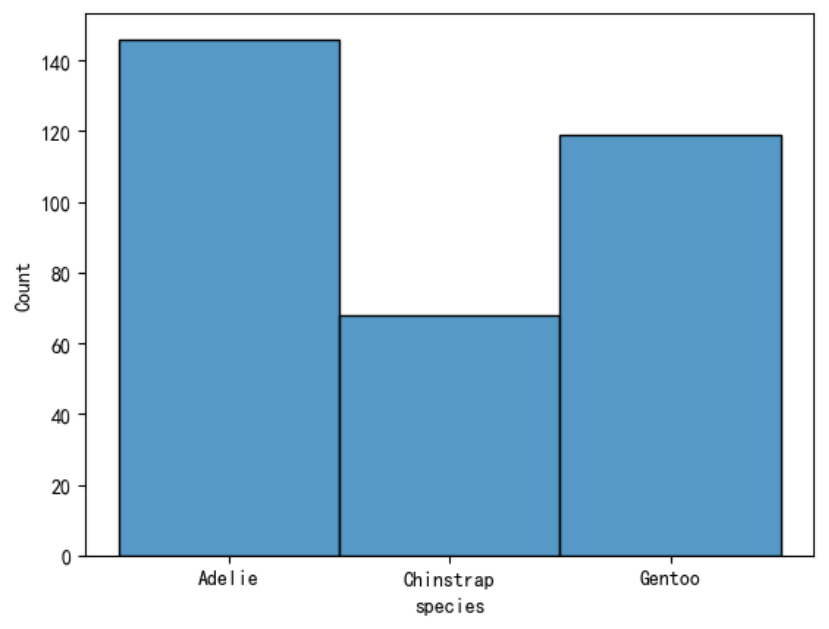
绘制不同种类企鹅数量的直方图。
sns.histplot(data=penguins, x=\"species\")
核密度估计图
核密度估计图(KDE,Kernel Density Estimate Plot)是一种用于显示数据分布的统计图表,它通过平滑直方图的方法来估计数据的概率密度函数,使得分布图看起来更加连续和平滑。核密度估计是一种非参数方法,用于估计随机变量的概率密度函数。其基本思想是,将每个数据点视为一个“核”(通常是高斯分布),然后将这些核的贡献相加以形成平滑的密度曲线。
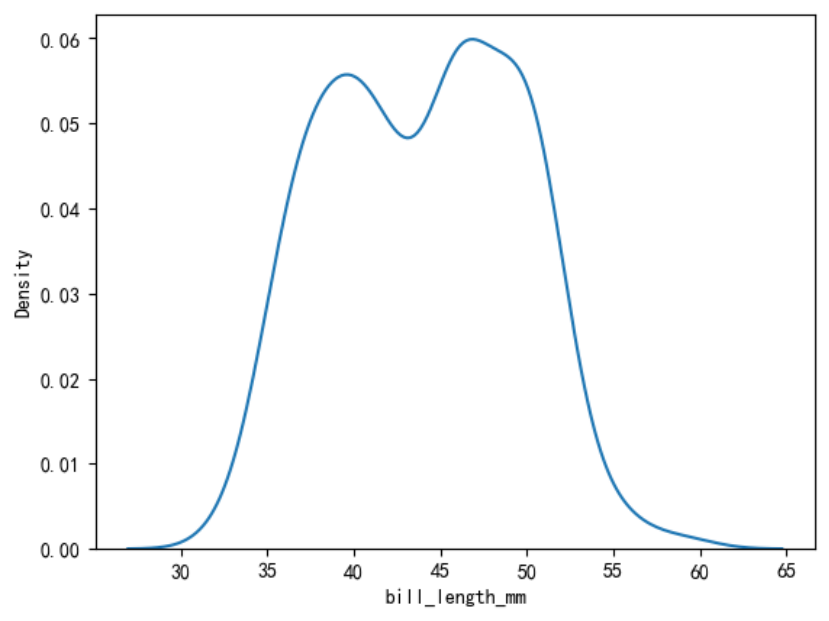
绘制喙长度的核密度估计图。
sns.kdeplot(data=penguins, x=\"bill_length_mm\")
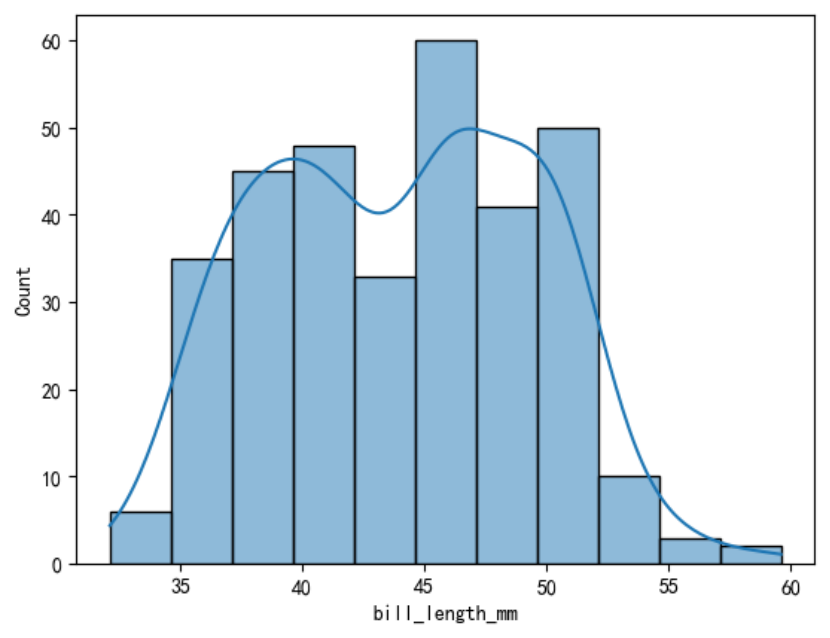
在histplot()中设置kde=True也可以得到核密度估计图。
sns.histplot(data=penguins, x=\"bill_length_mm\", kde=True)
计数图
计数图用于绘制分类变量的计数分布图,显示每个类别在数据集中出现的次数,是分析分类数据非常直观的工具,可以快速了解类别的分布情况。
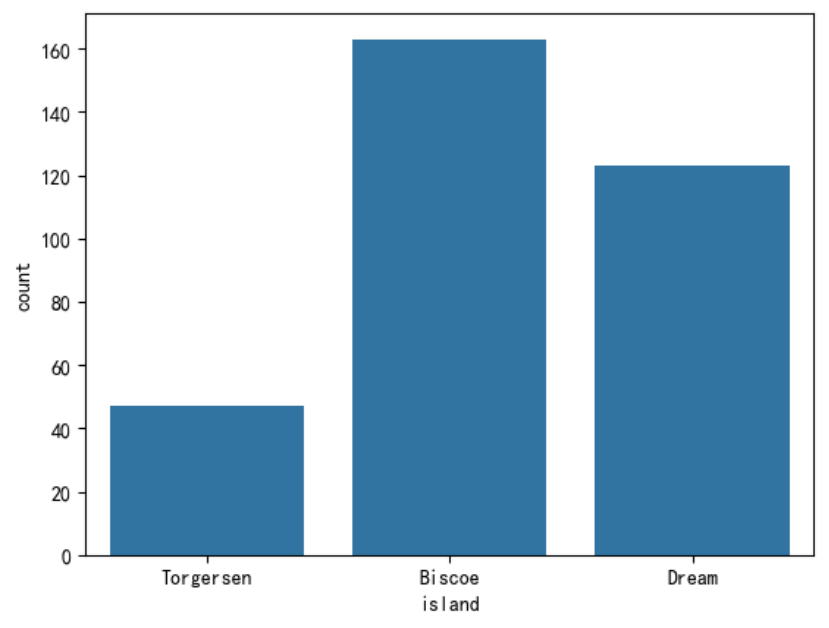
绘制不同岛屿企鹅数量的计数图。
sns.countplot(data=penguins, x=\"island\")
4.3.3 双变量可视化
散点图
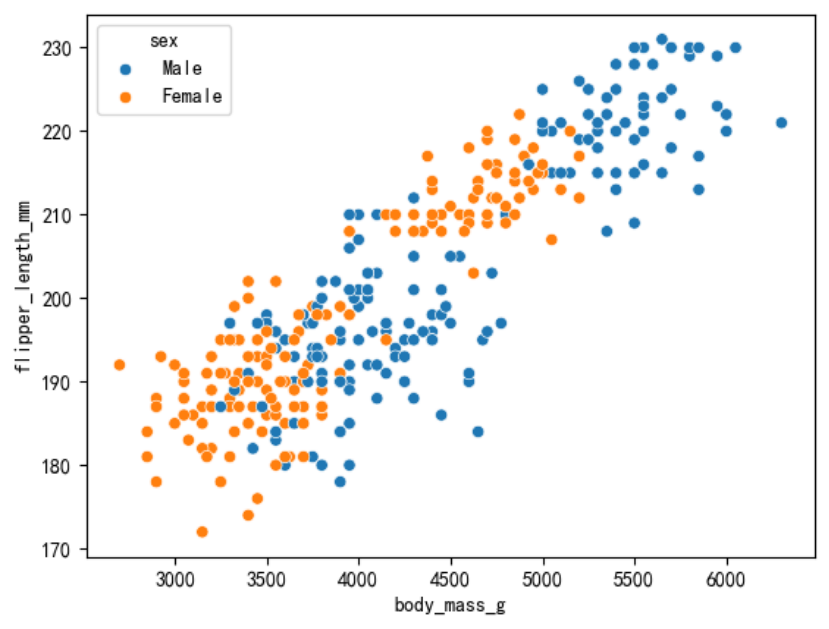
绘制横轴为体重,纵轴为脚蹼长度的散点图。可通过hue参数设置不同组别进行对比。
sns.scatterplot(data=penguins, x=\"body_mass_g\", y=\"flipper_length_mm\", hue=\"sex\")
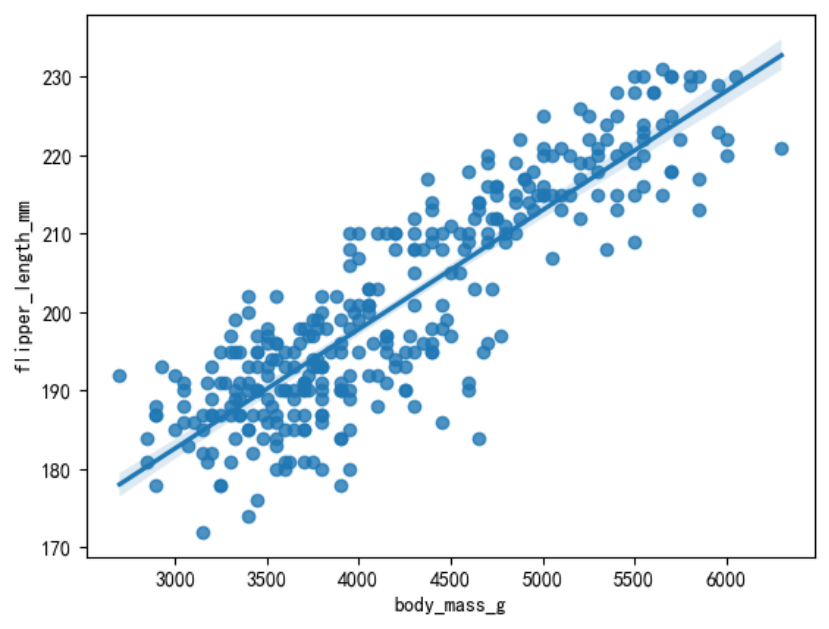
也可以通过regplot()函数绘制散点图,同时会拟合回归曲线。可以通过fit_reg=False关闭拟合。
sns.regplot(data=penguins, x=\"body_mass_g\", y=\"flipper_length_mm\")
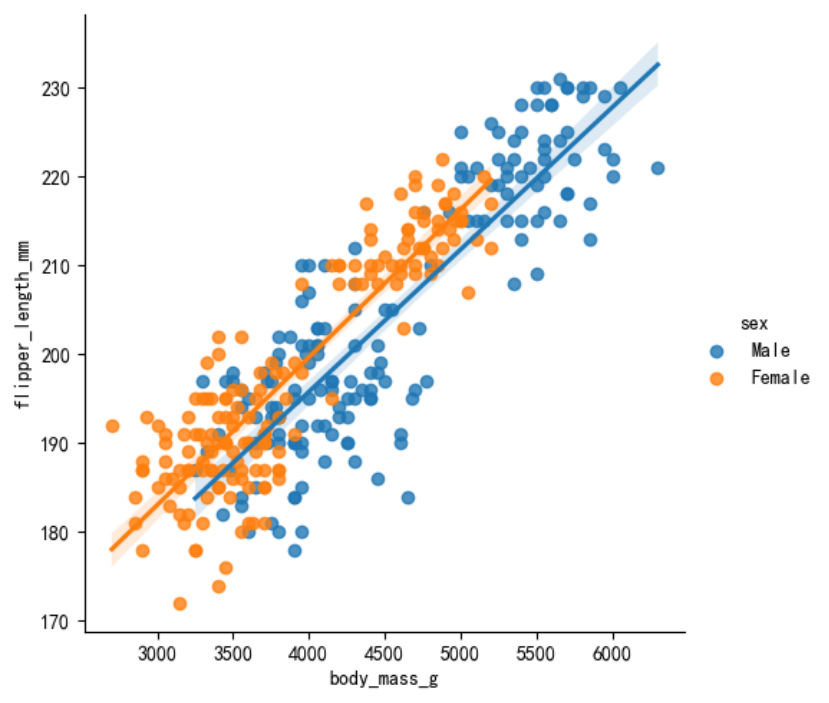
也可以通过lmplot()函数绘制基于hue参数的分组回归图。
sns.lmplot(data=penguins, x=\"body_mass_g\", y=\"flipper_length_mm\", hue=\"sex\")
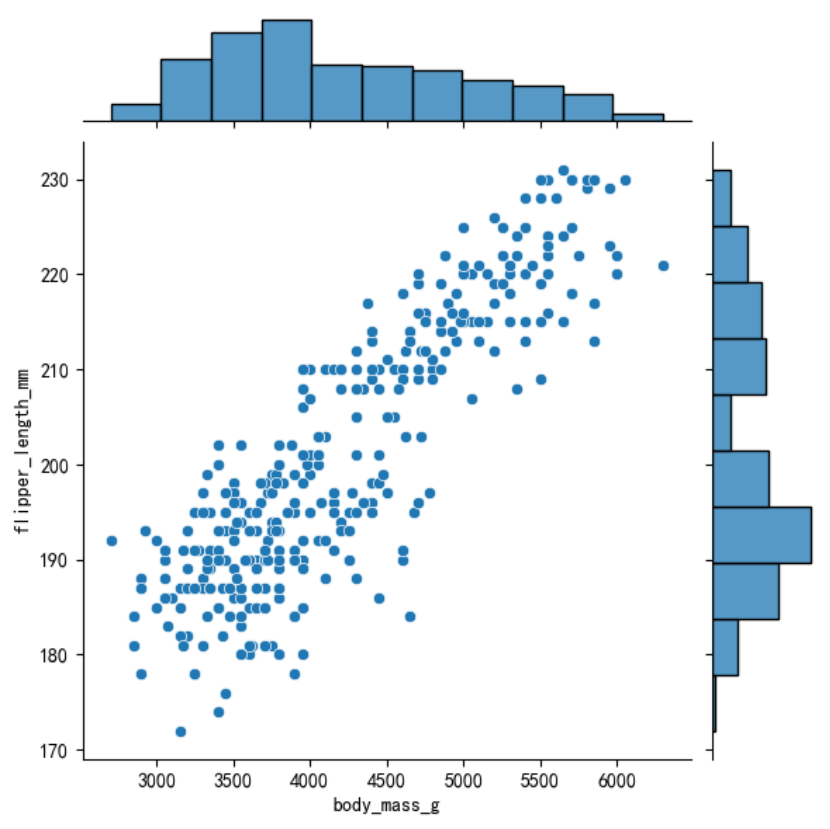
也可以通过jointplot()函数绘制在每个轴上包含单个变量的散点图。
sns.jointplot(data=penguins, x=\"body_mass_g\", y=\"flipper_length_mm\")
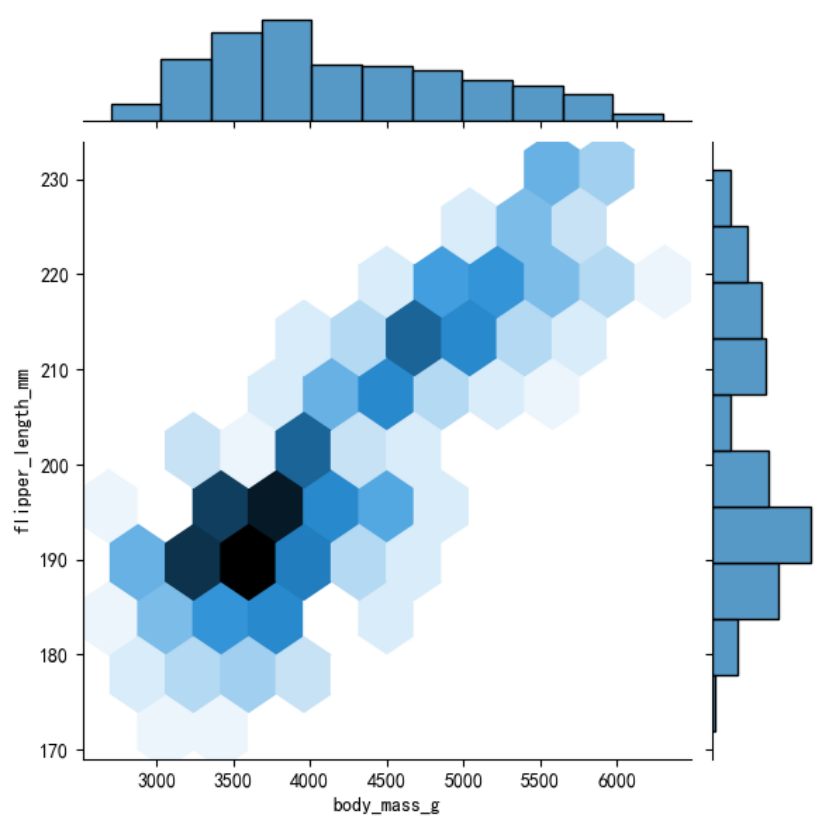
蜂窝图
通过jointplot()函数,设置kind=\"hex\"来绘制蜂窝图。
sns.jointplot(data=penguins, x=\"body_mass_g\", y=\"flipper_length_mm\", kind=\"hex\")
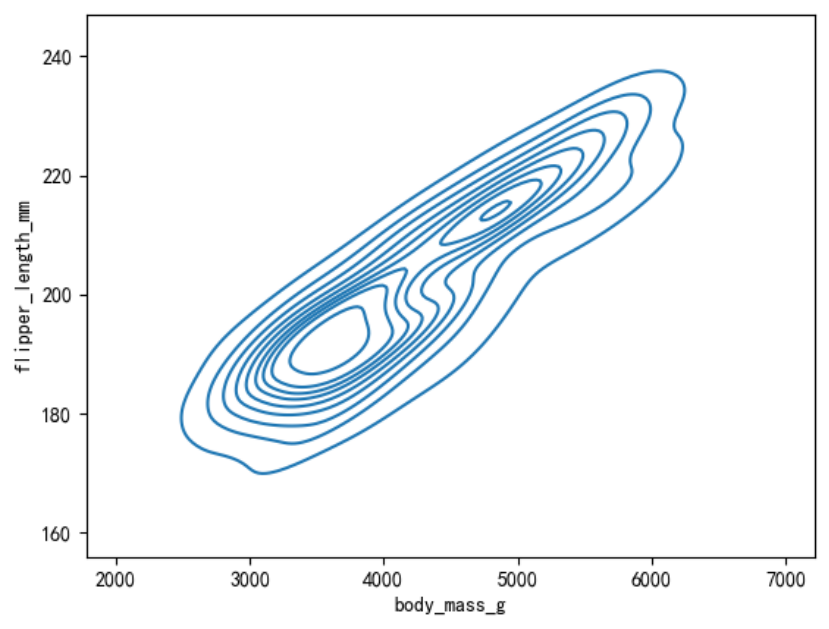
二维核密度估计图
通过kdeplot()函数,同时设置x参数和y参数来绘制二维核密度估计图。
sns.kdeplot(data=penguins, x=\"body_mass_g\", y=\"flipper_length_mm\")
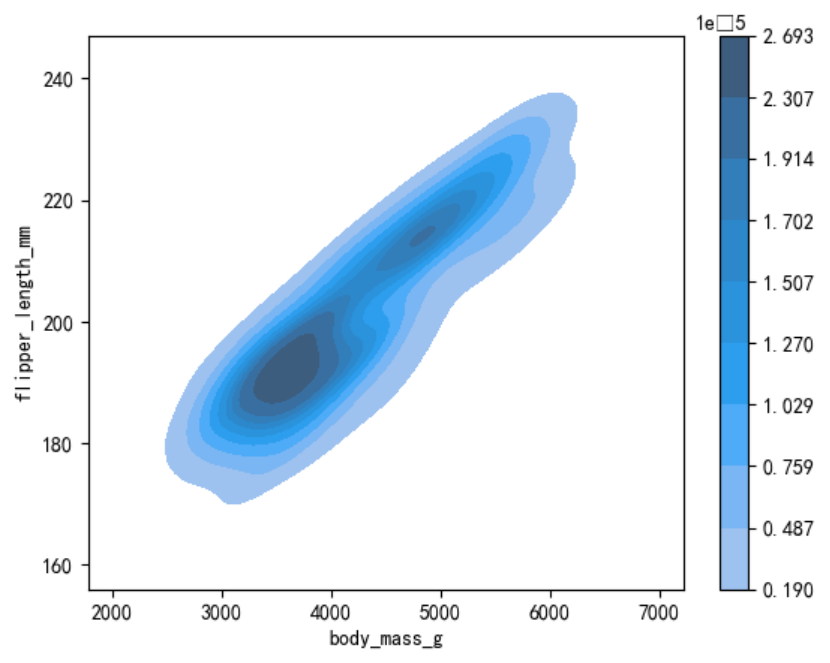
通过fill=True设置为填充,通过cbar=True设置显示颜色示意条。
sns.kdeplot(data=penguins, x=\"body_mass_g\", y=\"flipper_length_mm\", fill=True, cbar=True)
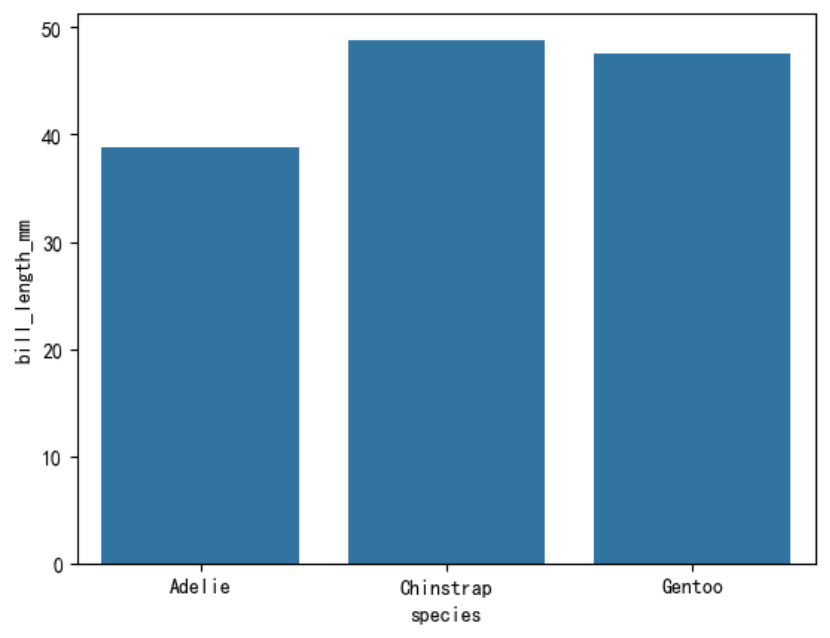
条形图
条形图会按x分组对y进行聚合,通过estimator参数设置聚合函数,并通过errorbar设置误差条,误差条默认会显示。可以通过误差条显示抽样数据统计结果的可能统计范围,如果数据不是抽样数据, 可以设置为None来关闭误差条。
sns.barplot(data=penguins, x=\"species\", y=\"bill_length_mm\", estimator=\"mean\", errorbar=None)
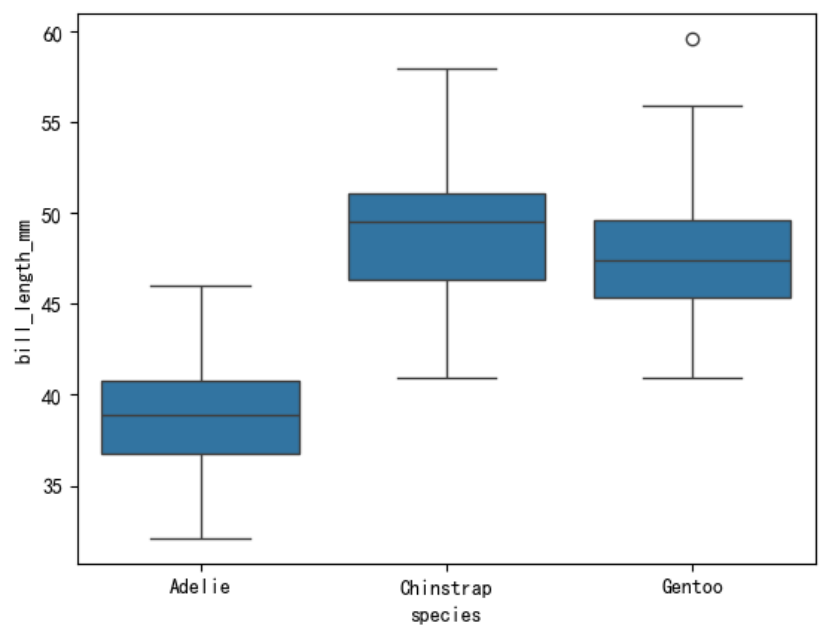
箱线图
箱线图是一种用于展示数据分布、集中趋势、散布情况以及异常值的统计图表。它通过五个关键的统计量(最小值、第一四分位数、中位数、第三四分位数、最大值)来展示数据的分布情况。
箱线图通过箱体和须来表现数据的分布,能够有效地显示数据的偏斜、分散性以及异常值。箱线图的组成部分:
- 箱体(Box):
- 下四分位数(Q1):数据集下 25% 的位置,箱体的下边缘。
- 上四分位数(Q3):数据集下 75% 的位置,箱体的上边缘。
- 四分位间距(IQR, Interquartile Range):Q3 和 Q1 之间的距离,用来衡量数据的离散程度。
- 中位数(Median):箱体内部的水平线,表示数据集的中位数。
- 须(Whiskers):
- 下须:从 Q1 向下延伸,通常是数据集中最小值与 Q1 的距离,直到没有超过1.5倍 IQR 的数据点为止。
- 上须:从 Q3 向上延伸,通常是数据集中最大值与 Q3 的距离,直到没有超过1.5倍 IQR 的数据点为止。
- 异常值(Outliers):
- 超过1.5倍 IQR 的数据被认为是异常值,通常用点标记出来。异常值是数据中相对于其他数据点而言“非常大”或“非常小”的值。
sns.boxplot(data=penguins, x=\"species\", y=\"bill_length_mm\")
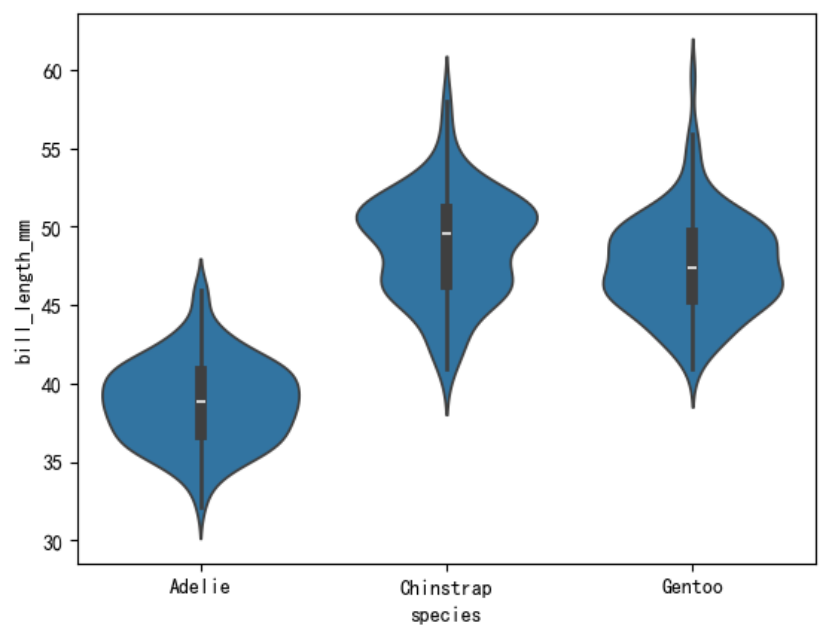
小提琴图
小提琴图(Violin Plot) 是一种结合了箱线图和核密度估计图(KDE)的可视化图表,用于展示数据的分布情况、集中趋势、散布情况以及异常值。小提琴图不仅可以显示数据的基本统计量(如中位数和四分位数),还可以展示数据的概率密度,提供比箱线图更丰富的信息。
sns.violinplot(data=penguins, x=\"species\", y=\"bill_length_mm\")
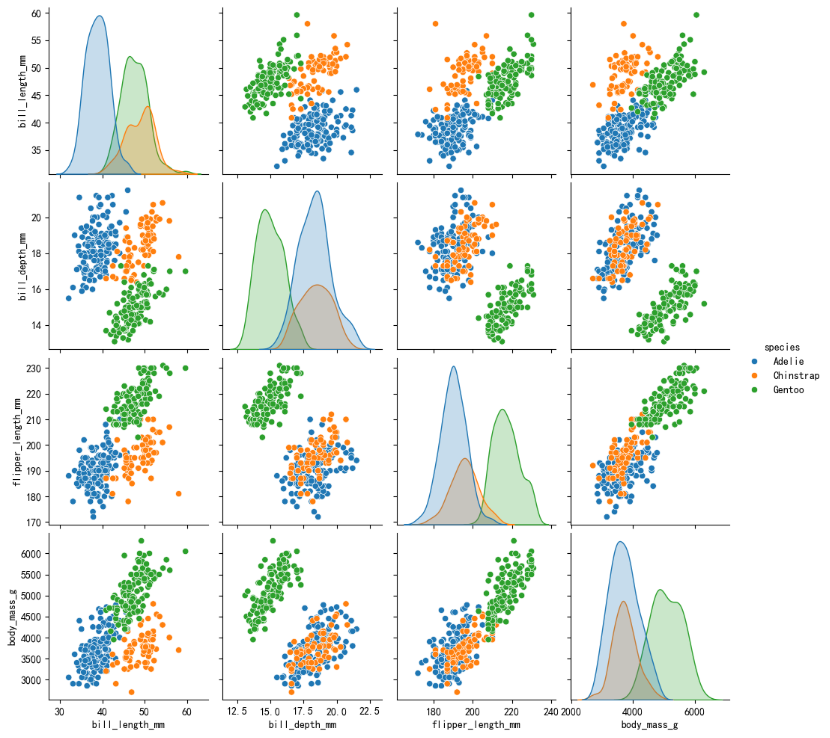
成对关系图
成对关系图是一种用于显示多个变量之间关系的可视化工具。它可以展示各个变量之间的成对关系,并且通过不同的图表形式帮助我们理解数据中各个变量之间的相互作用。
对角线上的图通常显示每个变量的分布(如直方图或核密度估计图),帮助观察每个变量的单变量特性。其他位置展示所有变量的两两关系,用散点图表示。
sns.pairplot(data=penguins, hue=\"species\")
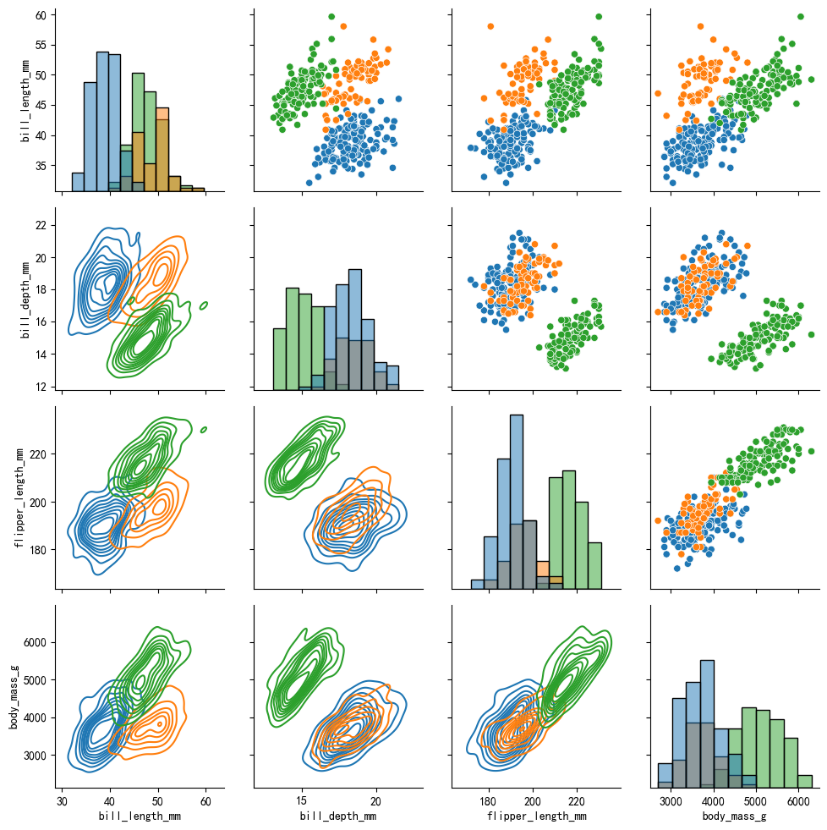
通常情况下成对关系图左上和右下对应位置的图的信息是相同的,可以通过PairGrid()为每个区域设置不同的图类型。
pair_grid = sns.PairGrid(data=penguins, hue=\"species\")
# 通过 map 方法在网格上绘制不同的图形
pair_grid.map_upper(sns.scatterplot) # 上三角部分使用散点图
pair_grid.map_lower(sns.kdeplot) # 下三角部分使用核密度估计图
pair_grid.map_diag(sns.histplot) # 对角线部分使用直方图
4.3.4 多变量可视化
多数绘图函数都支持使用hue参数设置一个类别变量,统计时按此类别分组统计并在绘图时使用颜色区分。
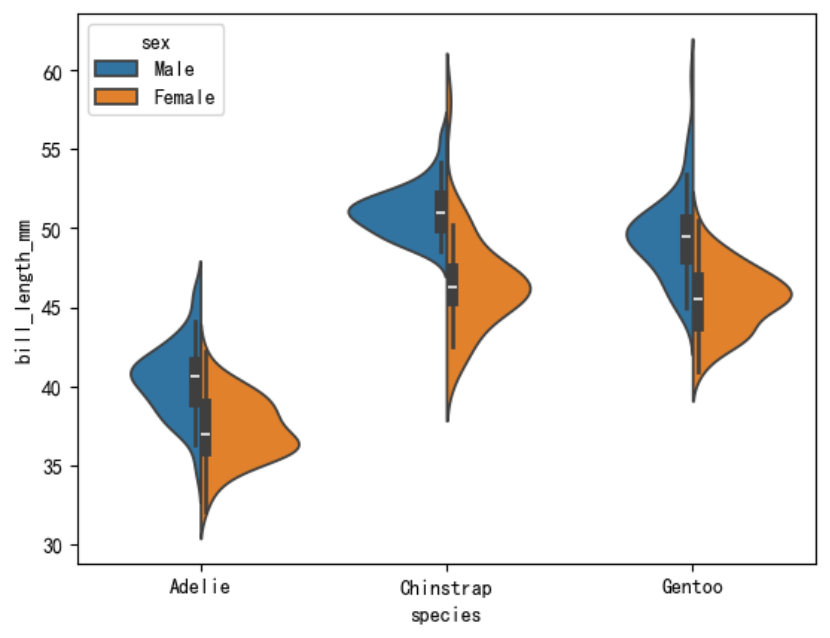
例如对小提琴图设置hue参数添加性别类别:
sns.violinplot(data=penguins, x=\"species\", y=\"bill_length_mm\", hue=\"sex\", split=True)
4.3.5 Seaborn样式
在Seaborn中,样式(style)控制了图表的整体外观,包括背景色、网格线、刻度线等元素。Seaborn提供了一些内置的样式选项,可以通过seaborn.set_style()来设置当前图表的样式。常见的样式有以下几种:
- white:纯白背景,没有网格线。
- dark:深色背景,带有网格线。
- whitegrid:白色背景,带有网格线。
- darkgrid:深色背景,带有网格线(默认样式)。
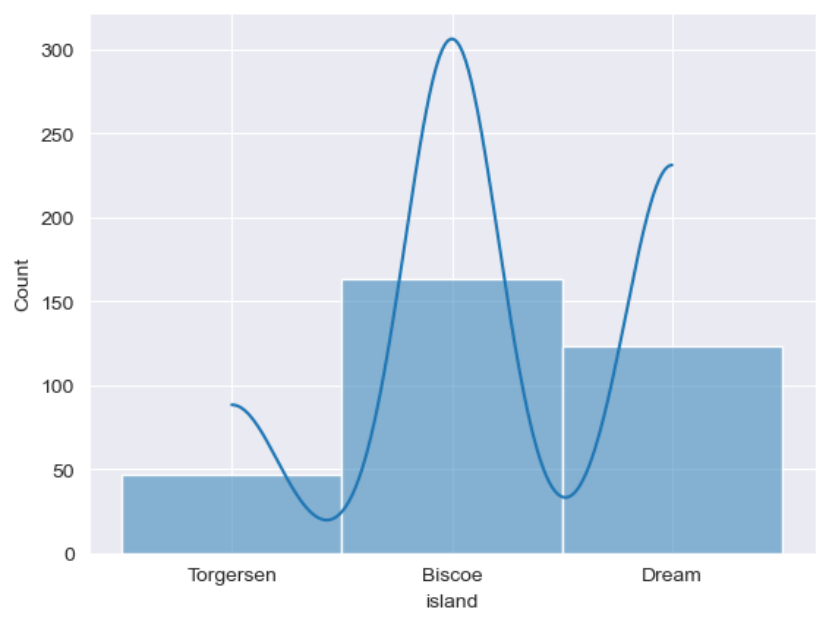
sns.set_style(\"darkgrid\")
sns.histplot(data=penguins, x=\"island\", kde=True)
4.4 Pandas可视化
pandas提供了非常方便的绘图功能,可以直接在DataFrame或Series上调用plot()方法来生成各种类型的图表。底层实现依赖于Matplotlib,pandas的绘图功能集成了许多常见的图形类型,易于使用。
4.4.1 单变量可视化
使用sleep(睡眠健康和生活方式)数据集,其中包含13个字段:
- person_id:每个人的唯一标识符。
- gender:个人的性别(男/女)。
- age:个人的年龄(以岁为单位)。
- occupation:个人的职业或就业状况(例如办公室职员、体力劳动者、学生)。
- sleep_duration:每天的睡眠总小时数。
- sleep_quality:睡眠质量的主观评分,范围从 1(差)到 10(极好)。
- physical_activity_level:每天花费在体力活动上的时间(以分钟为单位)。
- stress_level:压力水平的主观评级,范围从 1(低)到 10(高)。
- bmi_category:个人的 BMI 分类(体重过轻、正常、超重、肥胖)。
- blood_pressure:血压测量,显示为收缩压与舒张压的数值。
- heart_rate:静息心率,以每分钟心跳次数为单位。
- daily_steps:个人每天行走的步数。
- sleep_disorder:存在睡眠障碍(无、失眠、睡眠呼吸暂停)。
加载数据:
import pandas as pd
df = pd.read_csv(\"data/sleep.csv\")
df.info() # 查看数据集信息
# RangeIndex: 400 entries, 0 to 399
# Data columns (total 13 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 person_id 400 non-null int64
# 1 gender 400 non-null object
# 2 age 400 non-null int64
# 3 occupation 400 non-null object
# 4 sleep_duration 400 non-null float64
# 5 sleep_quality 400 non-null float64
# 6 physical_activity_level 400 non-null int64
# 7 stress_level 400 non-null int64
# 8 bmi_category 400 non-null object
# 9 blood_pressure 400 non-null object
# 10 heart_rate 400 non-null int64
# 11 daily_steps 400 non-null int64
# 12 sleep_disorder 110 non-null object
# dtypes: float64(2), int64(6), object(5)
# memory usage: 40.8+ KB
柱状图
柱状图用于展示类别数据的分布情况。它通过一系列矩形的高度(或长度)来展示数据值,适合对比不同类别之间的数量或频率。简单直观,容易理解和比较各类别数据。
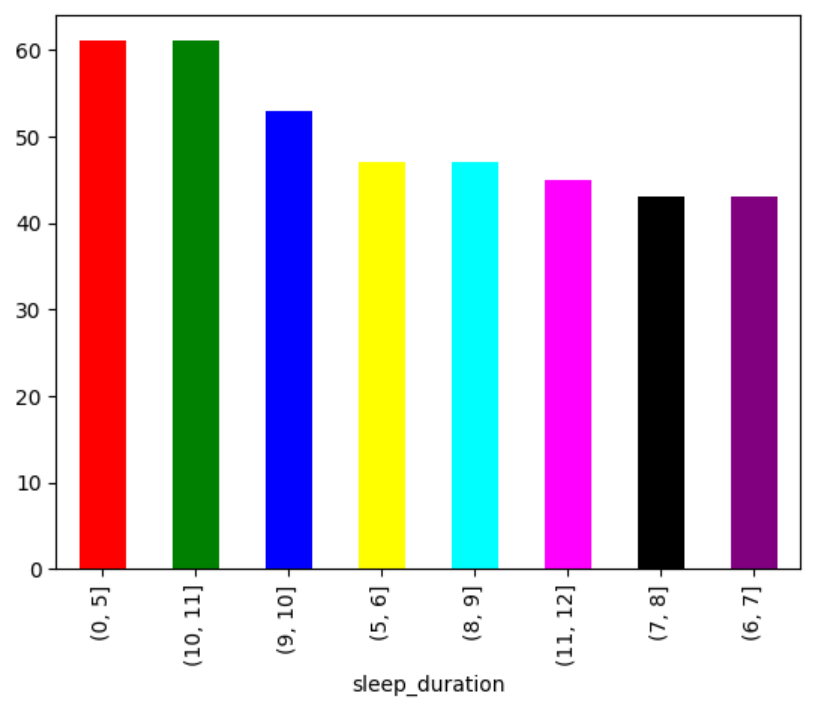
使用柱状图展示不同睡眠时长的数量。
pd.cut(df[\"sleep_duration\"], [0, 5, 6, 7, 8, 9, 10, 11, 12]).value_counts().plot.bar(
color=[\"red\", \"green\", \"blue\", \"yellow\", \"cyan\", \"magenta\", \"black\", \"purple\"]
)
折线图
折线图通常用于展示连续数据的变化趋势。它通过一系列数据点连接成的线段来表示数据的变化。能够清晰地展示数据的趋势和波动。
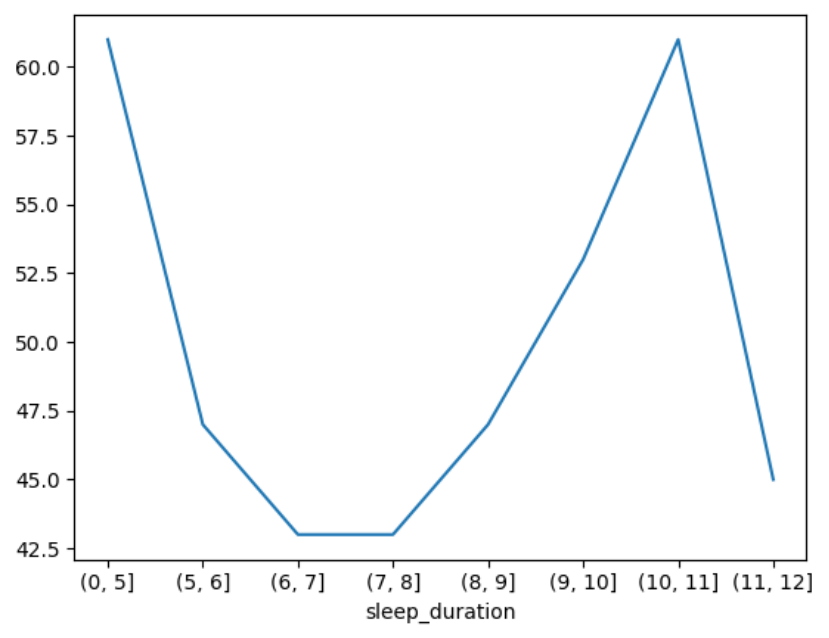
使用折线图展示不同睡眠时长的数量。
pd.cut(df[\"sleep_duration\"], [0, 5, 6, 7, 8, 9, 10, 11, 12]).value_counts().sort_index().plot()
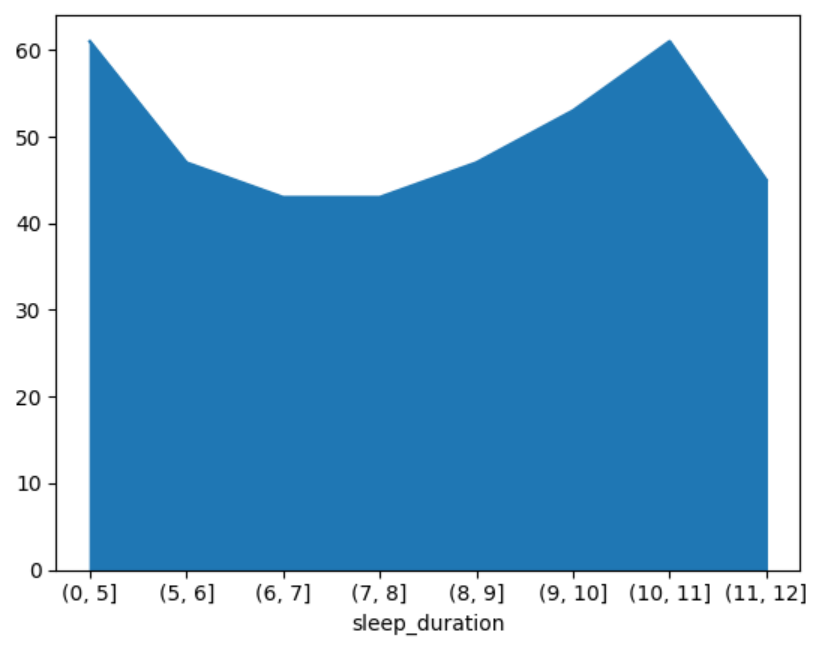
面积图
面积图是折线图的一种变体,线下的区域被填充颜色,用于强调数据的总量或变化。可以更直观地展示数据量的变化,适合用来展示多个分类的累计趋势。
使用面积图展示不同睡眠时长的数量。
pd.cut(df[\"sleep_duration\"], [0, 5, 6, 7, 8, 9, 10, 11, 12]).value_counts().sort_index().plot.area()
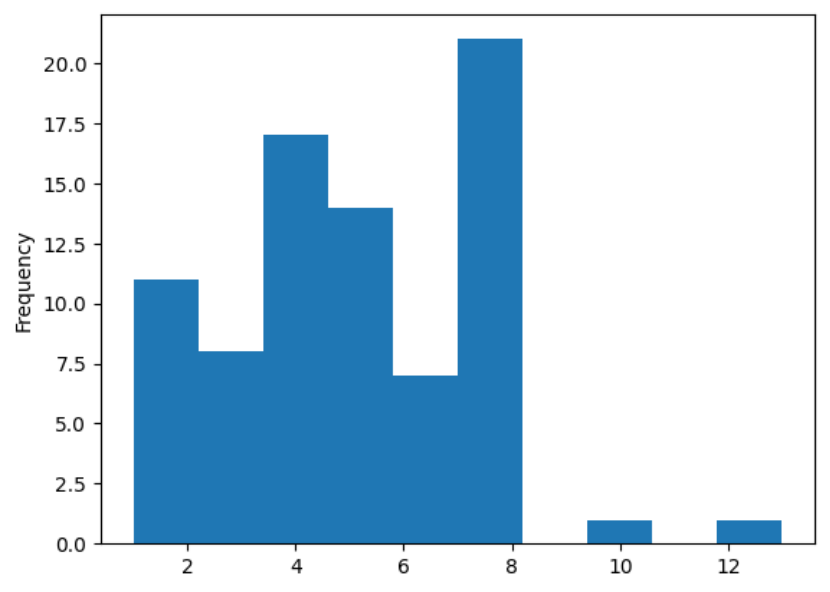
直方图
直方图用于展示数据的分布情况。它将数据范围分成多个区间,并通过矩形的高度显示每个区间内数据的频率或数量。可以揭示数据分布的模式,如偏态、峰度等。
使用直方图展示不同睡眠时长的数量。
df[\"sleep_duration\"].value_counts().plot.hist()
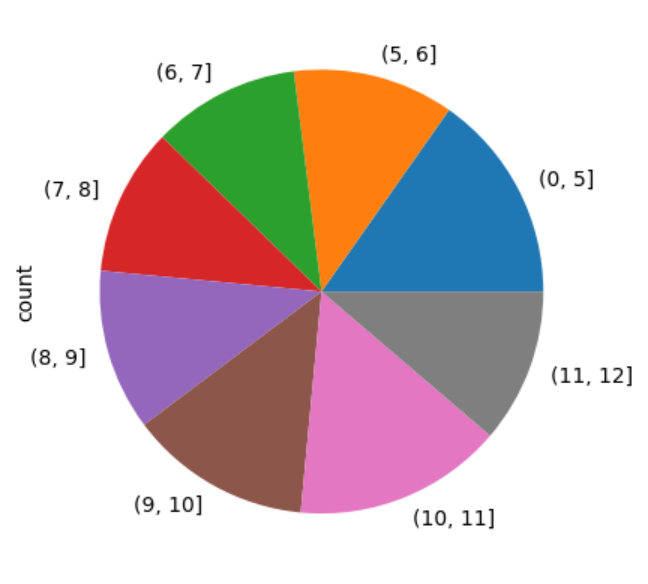
饼状图
饼状图用于展示一个整体中各个部分所占的比例。它通过一个圆形图形分割成不同的扇形,每个扇形的角度与各部分的比例成正比。能够快速展示各部分之间的比例关系,但不适合用于展示过多的类别或比较数值差异较小的部分。
使用饼状图展示不同睡眠时长的占比。
pd.cut(df[\"sleep_duration\"], [0, 5, 6, 7, 8, 9, 10, 11, 12]).value_counts().sort_index().plot.pie()
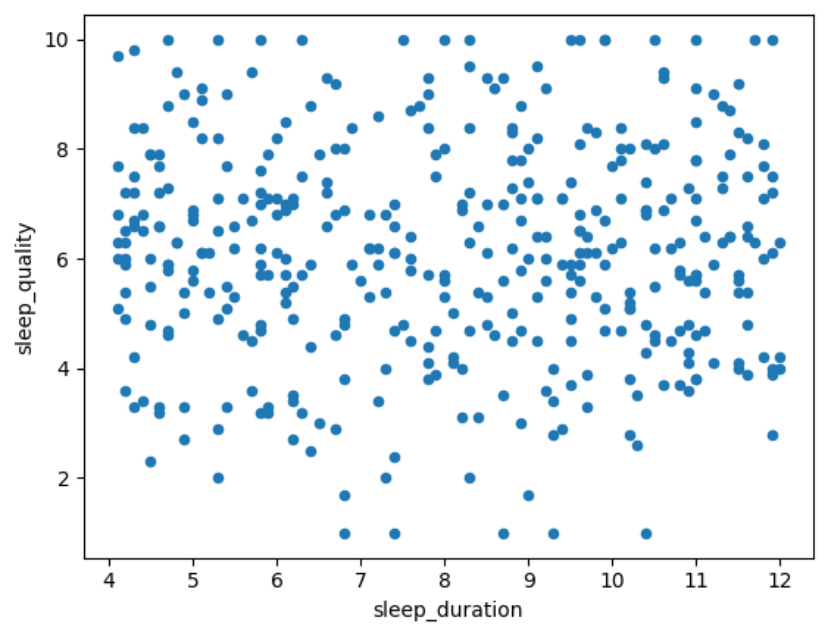
4.4.2 双变量可视化
散点图
散点图通过在二维坐标系中绘制数据点来展示两组数值数据之间的关系。能够揭示两个变量之间的相关性和趋势。
绘制睡眠时间与睡眠质量的散点图。
df.plot.scatter(x=\"sleep_duration\", y=\"sleep_quality\")
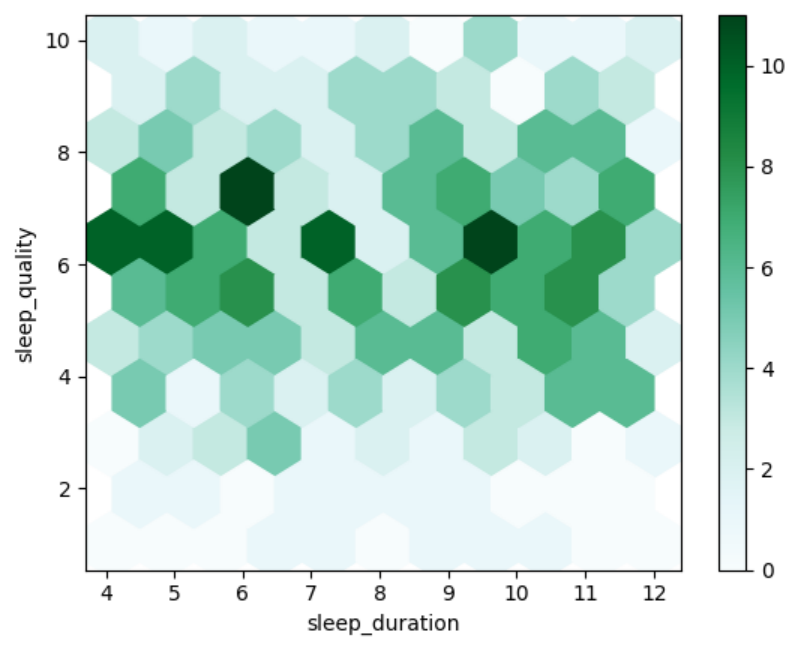
蜂窝图
蜂窝图是散点图的扩展,通常用于表示大量数据点之间的关系。它通过将数据点分布在一个六边形网格中,每个六边形的颜色代表其中的数据密度。适合展示大量数据点,避免了散点图中的过度重叠问题。
绘制睡眠时间与睡眠质量的蜂窝图。
df.plot.hexbin(x=\"sleep_duration\", y=\"sleep_quality\", gridsize=10)
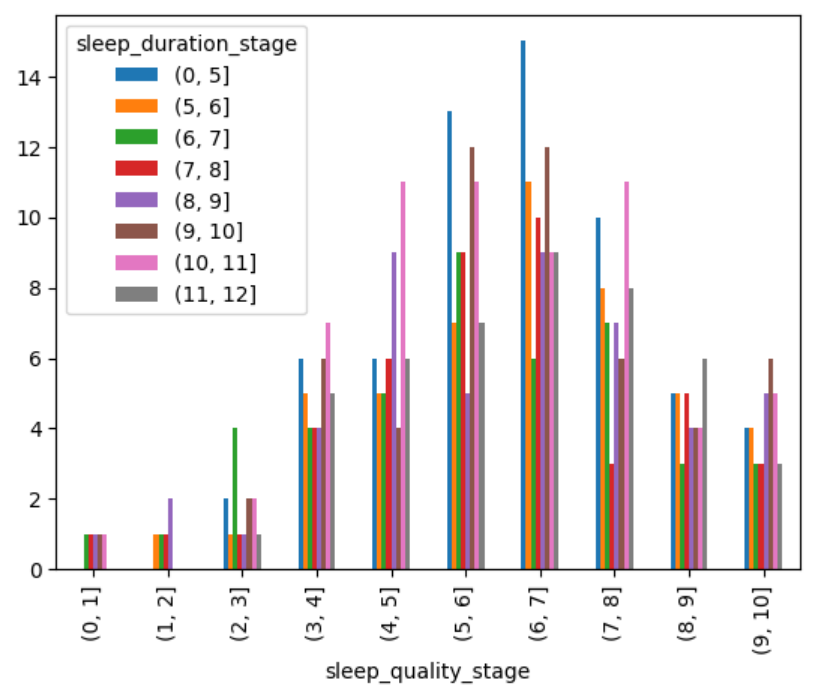
堆叠图
堆叠图用于展示多个数据系列的累积变化。常见的堆叠图包括堆叠柱状图、堆叠面积图等。它通过将每个数据系列堆叠在前一个系列之上,展示数据的累积情况。能够清晰地展示不同部分的相对贡献,适合多个数据系列的比较。
绘制睡眠时间与睡眠质量的堆叠图。
df[\"sleep_quality_stage\"] = pd.cut(df[\"sleep_quality\"], range(11))
df[\"sleep_duration_stage\"] = pd.cut(df[\"sleep_duration\"], [0, 5, 6, 7, 8, 9, 10, 11, 12])
df_pivot_table = df.pivot_table(
values=\"person_id\", index=\"sleep_quality_stage\", columns=\"sleep_duration_stage\", aggfunc=\"count\"
)
df_pivot_table.plot.bar()
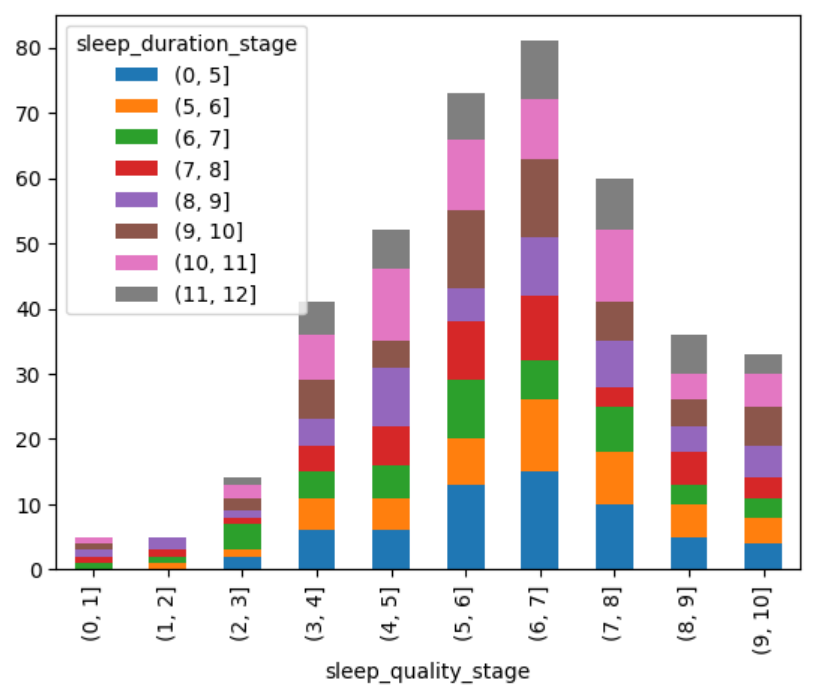
设置stacked=True,会将柱体堆叠。
df_pivot_table.plot.bar(stacked=True)
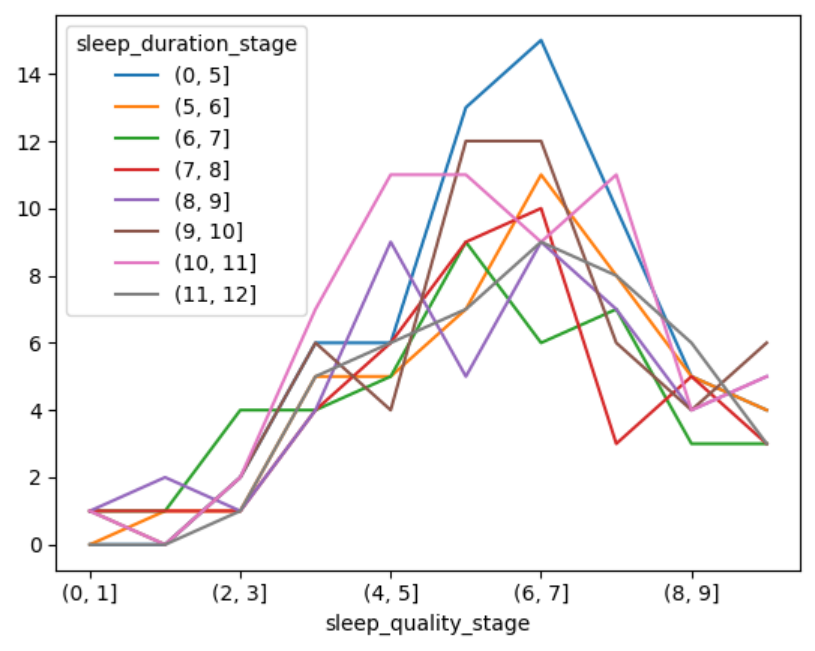
折线图
df_pivot_table.plot.line()
第5章 项目实战:房地产市场洞察与价值评估
数据分析流程
采集数据→确定分析方向→导入数据→数据清洗→数据分析→数据可视化
数据源介绍
字段名
含义
说明
city
城市
房屋所在的城市名称,例如“合肥”、“重庆”等。
address
详细地址
房屋的具体位置,包含街道、交叉口等信息。
area
面积
房屋的面积,单位为平方米(㎡)。
floor
楼层
房屋所在的楼层信息,例如“中层(共18层)”。
name
小区名称
房屋所在的小区或楼盘名称。
price
价格
房屋的总价,单位为“万”或“元”。
province
省份
房屋所在的省份或直辖市名称。
rooms
户型
房屋的户型结构,例如“3室2厅”。
toward
朝向
房屋的朝向,例如“南北向”、“南向”等。
unit
单价
房屋的单价,单位为“元/㎡”。
year
建造年份
房屋的建造年份,例如“2013年建”。
origin_url
原始链接
房屋信息的来源网页链接。
分析及统计问题
编号
问题
分析主题
分析目标
分组字段
指标/方法
A1
哪些变量最影响房价?面积、楼层、房间数哪个影响更大?
特征相关性
了解房屋各特征对房价的线性影响
无
皮尔逊相关系数
A2
全国房价总体分布是怎样的?是否存在极端值?
描述性统计
概览数值型字段的分布特征
无
平均数/中位数/四分位数/标准差
A3
哪些城市房价最高?直辖市与非直辖市差异如何?
城市对比
比较不同城市房价水平
city
均价/单价中位数/箱线图
A4
高价房在面积、楼层等方面有什么特征?
价格分层
识别不同价位房屋特征差异
价格分段(低中高)
列联表/卡方检验
A5
哪种户型最受欢迎?三室比两室贵多少?
户型分析
分析不同户型的市场表现
rooms
占比/平均单价/溢价率
A6
南北向是否真比单一朝向贵?贵多少?
朝向溢价
评估不同朝向的价格差异
toward
方差分析/多重比较
A7
新房比10年老房贵多少?折旧规律如何?
楼龄效应
研究建筑年份对房价的影响
year分段(5年间隔)
趋势线/回归分析
A8
哪些区域交易最活跃?新区和老城区哪个更贵?
区域热度
识别各城市热门交易区域
address(提取区域关键词)
交易量/价格增长率
A9
哪个面积段的性价比最高?超大户型有溢价吗?
面积区间
分析不同面积段的价格特征
area分段(50㎡间隔)
密度图/价格梯度
A10
中层真的比高层贵吗?差价是多少?
楼层差异
比较不同楼层的价格表现
floor(高中低层)
Kruskal-Wallis检验
A11
直辖市房价是否显著更高?单价和总价差异如何?
直辖市vs非直辖市
对比直辖市与非直辖市的房价差异
province
独立样本t检验/曼-惠特尼U检验
代码实现
Python# 1. 导入库import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsplt.rcParams[\'font.sans-serif\'] = [\'STHeiti\'] # 显示中文# 2. 导入数据df = pd.read_csv(\'data/house_sales.csv\')df.info()len(df)# 3. 数据概览print(\'数据概览\')print(\'总记录数:\',len(df))print(\'字段数量:\',len(df.columns))print(\'前5行数据:\')df.head(5)# 4. 数据清洗# 删除无用的数据列df.drop(columns=\'origin_url\',inplace=True)# 缺失值检查print(df.isnull().sum())# 删除缺失值数据df.dropna(inplace=True)# 缺失值检查print(df.isnull().sum())# 处理重复值print(df.duplicated().sum())df.drop_duplicates(inplace=True)print(df.duplicated().sum())print(len(df))# 数据类型的转换# 价格处理(示例:\"128万\" \"$128\"-> 1280000)df[\'price\'] = df[\'price\'].astype(str).str.replace(\'万\', \'\')df[\'price\'] = df[\'price\'].astype(str).str.replace(\'$\', \'\').astype(float).round(1) * 10000# 面积处理(示例:\"90㎡\" -> 90)df[\'area\'] = df[\'area\'].astype(str).str.replace(\'㎡\',\'\').astype(float).round(1)# 单价处理df[\'unit\'] = df[\'unit\'].astype(str).str.replace(\'元/㎡\',\'\').astype(float).round(1)# year处理df[\'year\'] = df[\'year\'].astype(str).str.replace(\'年建\',\'\').astype(int)#朝向处理df[\'toward\'] = df[\'toward\'].astype(\'category\')df.head(10)# 异常数据处理q1 = df[\'price\'].quantile(0.25)q3 = df[\'price\'].quantile(0.75)iqr=q3-q1low=q1-1.5*iqrhigh=q3+1.5*iqrdf = df[(df[\'price\'] > low) & (df[\'price\'] 20) & (df[\'area\'] 50次)toward_counts = df[\'toward\'].value_counts()main_towards = toward_counts[toward_counts > 50].indexdf_toward = df[df[\'toward\'].isin(main_towards)]# 朝向统计toward_stats = df_toward.groupby(\'toward\').agg({ \'price\': [\'mean\', \'median\'], \'unit\': \'median\', \'building_age\': \'mean\'}).sort_values((\'unit\', \'median\'), ascending=False)print(\"\\n各朝向价格表现:\")display(toward_stats)# 方差分析groups = [group[\'unit\'].values for name, group in df_toward.groupby(\'toward\')]# 可视化plt.figure(figsize=(12, 6))sns.boxplot(x=\'toward\', y=\'unit\', data=df_toward, order=toward_stats.index)plt.title(\'不同朝向单价分布\', fontsize=14)plt.xticks(rotation=45)plt.tight_layout()plt.show()\'\'\'问题编号: A7问题: 新房比10年老房贵多少?折旧规律如何?分析主题: 楼龄效应分析目标: 研究建筑年份对房价的影响分组字段: year分段(5年间隔)指标/方法: 趋势线/回归分析\'\'\'\'\'\'问题编号: A8问题: 哪些区域交易最活跃?新区和老城区哪个更贵?分析主题: 区域热度分析目标: 识别各城市热门交易区域分组字段: address(提取区域关键词)指标/方法: 交易量/价格增长率\'\'\'\'\'\'问题编号: A9问题: 哪个面积段的性价比最高?超大户型有溢价吗?分析主题: 面积区间分析目标: 分析不同面积段的价格特征分组字段: area分段(50㎡间隔)指标/方法: 密度图/价格梯度\'\'\'\'\'\'问题编号: A10问题: 中层真的比高层贵吗?差价是多少?分析主题: 楼层差异分析目标: 比较不同楼层的价格表现分组字段: floor(高中低层)指标/方法: Kruskal-Wallis检验\'\'\'\'\'\'问题编号: A11问题: 直辖市房价是否显著更高?单价和总价差异如何?分析主题: 直辖市vs非直辖市分析目标: 对比直辖市与非直辖市的房价差异分组字段: province(直辖市/安徽)指标/方法: 独立样本t检验/曼-惠特尼U检验\'\'\'
