DeepSeek DeepEP学习(四)normal combine
整体流程
首先回顾一下dispatch的过程,dispatch是两阶段的,第一阶段是机间同号gpu之间通过rdma的发送,第二阶段是机内通过nvlink的中转,rank0的视角如下所示,combine的过程就是原路返回。
图 1
首先回顾一下dispatch输出。
def internode_dispatch(...):x, x_scales = x if isinstance(x, tuple) else (x, None) if handle is not None: ... else: assert num_tokens_per_rank is not None and is_token_in_rank is not None and num_tokens_per_expert is not None recv_x, recv_x_scales, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, \\ rdma_channel_prefix_matrix, gbl_channel_prefix_matrix, \\ recv_rdma_channel_prefix_matrix, recv_rdma_rank_prefix_sum, \\ recv_gbl_channel_prefix_matrix, recv_gbl_rank_prefix_sum, \\ recv_src_meta, send_rdma_head, send_nvl_head, event = self.runtime.internode_dispatch( x, x_scales, topk_idx, topk_weights, num_tokens_per_rank, num_tokens_per_rdma_rank, is_token_in_rank, num_tokens_per_expert, 0, 0, None, None, None, None, expert_alignment, config, getattr(previous_event, \'event\', None), async_finish, allocate_on_comm_stream) handle = (is_token_in_rank, rdma_channel_prefix_matrix, gbl_channel_prefix_matrix, recv_rdma_channel_prefix_matrix, recv_rdma_rank_prefix_sum, recv_gbl_channel_prefix_matrix, recv_gbl_rank_prefix_sum, recv_src_meta, send_rdma_head, send_nvl_head) return (recv_x, recv_x_scales) if x_scales is not None else recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, EventOverlap(event)然后介绍一下这几个变量,括号中为combine算子中的命名。
rdma_channel_prefix_matrix
发送者视角,shape为{num_rdma_ranks, num_channels},如下图所示,假设row为rdma_rank = 1这行,那么row[i]表示当前rank发送到rdma_rank[1]中前 i 个channel的token总数。
图 2
gbl_channel_prefix_matrix
发送者视角,shape为{num_ranks, num_channels},假设row为rank = 1这行,那么row[i]表示当前rank发送到rank[1]中前 i 个channel的token总数。
send_rdma_head(combined_rdma_head)
shape为{num_tokens, num_rdma_ranks},send_rdma_head[token_idx][dst_rdma_rank] = x,表示dispatch中,第token_idx个token是第x个发送到dst_rdma_rank的,假设当前rank有三个token,如下图,那么token2是第1个发送到node1,是第0个发送到node2的。
因为在combine的过程中需要执行reduce,所以node0需要等到node1和node2都发送过来token2之后才能对token2进行reduce,因此就是通过send_rdma_head进行判断的,当node2发送第0个token,node1发送了第1个token,那么说明token2已经到了,就可以开始执行对token2的reduce。
图 3
send_nvl_head(combined_nvl_head)
shape为{num_rdma_recv_tokens, NUM_MAX_NVL_PEERS},和send_rdma_head差不多,这个记录的是dispatch中机内转发到其他rank的时候,每个token是第几个转发过去的,从而可以执行机内对token的reduce。
recv_rdma_channel_prefix_matrix (rdma_channel_prefix_matrix)
接收端视角,shape为{num_rdma_ranks, num_channels},同理,假设row表示rank = 1这行,那么row[i]表示rdma_rank[1]的前 i 个channel发送过来的token总数
recv_rdma_rank_prefix_sum(rdma_rank_prefix_sum)
shape为{num_rdma_ranks},recv_rdma_rank_prefix_sum[x]表示前x台机器的同号卡一共发送过来多少token
recv_gbl_rank_prefix_sum
shape为{num_ranks},recv_gbl_rank_prefix_sum[x]表示前 i 个rank发送到当前rank的总token数。
recv_gbl_channel_prefix_matrix(gbl_channel_prefix_matrix)
shape为{num_ranks, num_channels},row[1]表示rank[1]的第 i 个channel发送过来的token从哪里开始放,换句话说就是前i - 1个channel的总token数。
角色分配

图 4
还是以rank0的视角为例,第一步绿色的rank1和rank3会将数据发送到rank1的同号卡,他们的角色为kNVLSender;黄色部分负责转发非同号卡的token,他们的角色为kNVLAndRDMAForwarder;最后是蓝色的rank0,负责接收,角色叫kRDMAReceiver,除了这些外,还有coordinator角色,这个后边详细介绍。
TMA
新版的DeepEP支持了Hopper的TMA指令,支持异步的global memory和shared memory之间的拷贝,可以减少cuda core执行load/store的开销。但此时拷贝变成了异步的,因此需要有机制做到计算之前对访存的同步,以及不同线程之间的同步,这里用的就是mbarrier或者async-group。
mbarrier
mbarrier有一点像bar.sync,可以同步一个block内部的线程,但不同于一个sm只有16个bar,mbarrier是个shared memory上的8字节空间。
除了和bar一样的同步多个线程(通过arrive count),还可以同步TMA这种异步的拷贝(通过expect-tx)。
首先看下初始化
if (lane_id == 0) { mbarrier_init(tma_mbarrier, 1); fence_view_async_shared(); fence_barrier_init(); EP_DEVICE_ASSERT(hidden_bytes + sizeof(uint64_t) <= kNumTMABytesPerWarp);} __syncwarp();DeepEP中一个warp对应一个mbarrier,因此每个warp的lane[0]执行mbarrier的初始化,tma_mbarrier就是shared memory上的一个8字节空间。
__device__ __forceinline__ void mbarrier_init(uint64_t* mbar_ptr, uint32_t arrive_count) { auto mbar_int_ptr = static_cast<uint32_t>(__cvta_generic_to_shared(mbar_ptr)); asm volatile(\"mbarrier.init.shared::cta.b64 [%1], %0;\" :: \"r\"(arrive_count), \"r\"(mbar_int_ptr));} 通过mbarrier.init完成tma_mbarrier的初始化,mbar_ptr为mbarrier的地址,arrive_count就是表示将会有多少个线程执行arrive,expect-tx此时是0。
__device__ __forceinline__ void fence_view_async_shared() { asm volatile(\"fence.proxy.async.shared::cta; \\n\" :: );} 完成初始化之后会执行fence.proxy.async,mbarrier由genric proxy初始化,所以需要fence保证async proxy看见,这里是个双向同步。
__device__ __forceinline__ void fence_barrier_init() { asm volatile(\"fence.mbarrier_init.release.cluster; \\n\" :: );}然后执行fence.mbarrier_init,这个可以保证前序关于mbarrier初始化的操作被其他线程可见,是个轻量级的fence。
然后以kNVLReceivers为例看下使用,如下展示了当前warp对另一个nvl rank转发过来的token的一次处理,num_recv_tokens表示这次需要处理的token数,tma_load_bytes表示一个token对应的向量长度。
for (int chunk_idx = 0; chunk_idx < num_recv_tokens; ++ chunk_idx, -- num_tokens_to_recv) { auto tma_load_bytes = hidden_bytes + (scale_aligned ? scale_bytes : 0); if (lane_id == 0) { tma_load_1d(tma_buffer, shifted, tma_mbarrier, tma_load_bytes); mbarrier_arrive_and_expect_tx(tma_mbarrier, tma_load_bytes); } __syncwarp(); mbarrier_wait(tma_mbarrier, tma_phase); if (lane_id == 0) tma_store_1d(tma_buffer, recv_x + recv_token_idx * hidden_int4, hidden_bytes, false); tma_store_wait(); __syncwarp();}然后lane[0]执行tma的load,将hbm上shifted位置的向量拷贝到shared memory上的tma_buffer,关联到初始化的tma_mbarrier,完成机制为complete_tx::bytes,就是mbarrier的expect-tx机制,设置bytes为tma_load_bytes,那么当他完成的时候,mbarrier的expect-tx会被减去tma_load_bytes。
__device__ __forceinline__ void tma_load_1d(const void* smem_ptr, const void* gmem_ptr, uint64_t* mbar_ptr, int num_bytes,bool evict_first = true) { auto mbar_int_ptr = static_cast<uint32_t>(__cvta_generic_to_shared(mbar_ptr)); auto smem_int_ptr = static_cast<uint32_t>(__cvta_generic_to_shared(smem_ptr)); const auto cache_hint = evict_first ? kEvictFirst : kEvictNormal; asm volatile(\"cp.async.bulk.shared::cluster.global.mbarrier::complete_tx::bytes.L2::cache_hint [%0], [%1], %2, [%3], %4;\\n\" :: \"r\"(smem_int_ptr), \"l\"(gmem_ptr), \"r\"(num_bytes), \"r\"(mbar_int_ptr), \"l\"(cache_hint) : \"memory\");}然后lane[0]通过arrive.expect_tx设置tma_mbarrier的expect_tx为tma_load_bytes,对应load,然后执行arrive。
__device__ __forceinline__ void mbarrier_arrive_and_expect_tx(uint64_t* mbar_ptr, int num_bytes) { auto mbar_int_ptr = static_cast<uint32_t>(__cvta_generic_to_shared(mbar_ptr)); asm volatile(\"mbarrier.arrive.expect_tx.shared::cta.b64 _, [%1], %0; \\n\\t\" :: \"r\"(num_bytes), \"r\"(mbar_int_ptr));}所有线程执行synwarp,并在tma_barrier上进行循环wait,直到tma的load完成,然后切换phase。
__device__ __forceinline__ void mbarrier_wait(uint64_t* mbar_ptr, uint32_t& phase) { auto mbar_int_ptr = static_cast<uint32_t>(__cvta_generic_to_shared(mbar_ptr)); asm volatile(\"{\\n\\t\" \".reg .pred P1; \\n\\t\" \"LAB_WAIT: \\n\\t\" \"mbarrier.try_wait.parity.shared::cta.b64 P1, [%0], %1, %2; \\n\\t\" \"@P1 bra DONE; \\n\\t\" \"bra LAB_WAIT; \\n\\t\" \"DONE: \\n\\t\" \"}\" :: \"r\"(mbar_int_ptr), \"r\"(phase), \"r\"(0x989680)); phase ^= 1; }lane[0]执行tma store,将数据从shared memory拷贝到gloabal memory,完成机制为bulk_group,即bulk async-group。通过cp.async.bulk.commit_group将前序的使用bulk_group完成机制的tma store封装为一个bulk async-group。
_device__ __forceinline__ void tma_store_1d(const void* smem_ptr, const void* gmem_ptr, int num_bytes, bool evict_first = true) { auto smem_int_ptr = static_cast<uint32_t>(__cvta_generic_to_shared(smem_ptr)); const auto cache_hint = evict_first ? kEvictFirst : kEvictNormal; asm volatile(\"cp.async.bulk.global.shared::cta.bulk_group.L2::cache_hint [%0], [%1], %2, %3;\\n\" :: \"l\"(gmem_ptr), \"r\"(smem_int_ptr), \"r\"(num_bytes), \"l\"(cache_hint) : \"memory\"); asm volatile(\"cp.async.bulk.commit_group;\");}最后执行tma_store_wait,因为N为0,所以就等待所有的group完成。
template <int N = 0>__device__ __forceinline__ void tma_store_wait() { asm volatile(\"cp.async.bulk.wait_group.read %0;\" :: \"n\"(N) : \"memory\");}kNVLSender
kNVLSender中每个warp对应一个当前机器上的gpu,用于将token从当前rank发送到dispatch过程里中转这个token过来的gpu。一个warp对应一个dst_nvl_rank。
和dispatch一样,机内的卡间数据收发由fifo进行同步,nvl_channel_x为fifo,位于对端,nvl_channel_head位于本端,nvl_channel_tail位于对端,对于当前rank的一个sm的同步机制如下图所示。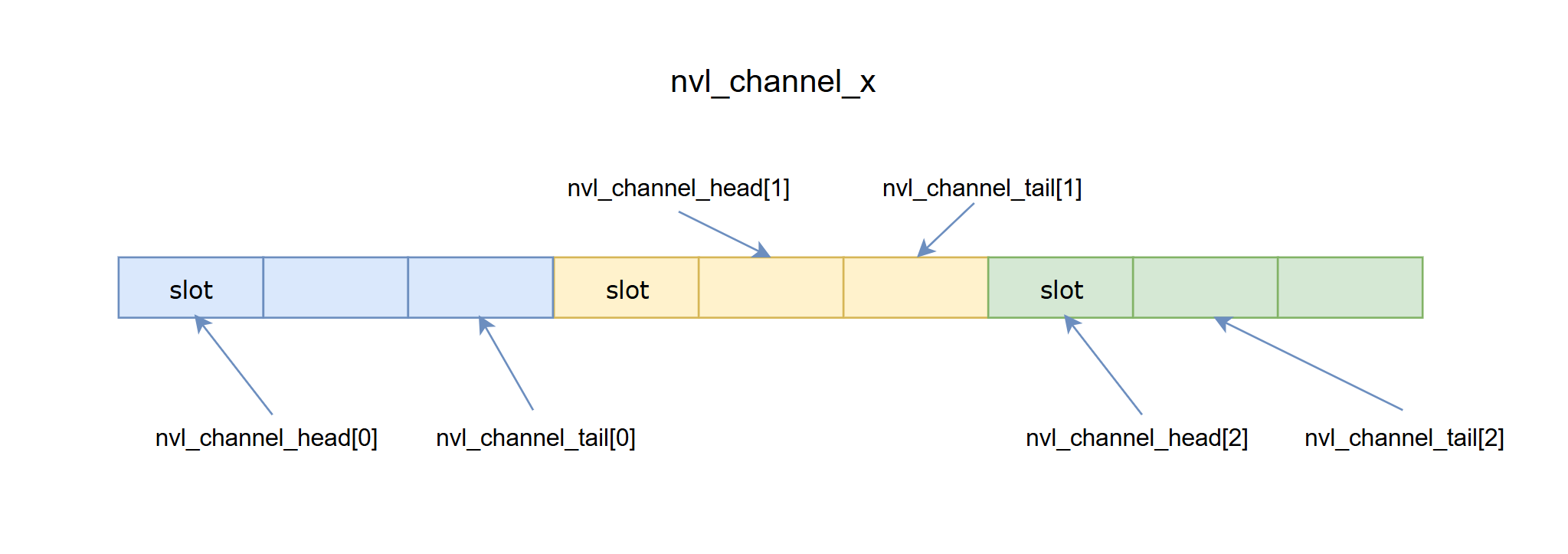
图 5
上图展示了nvl_channel_x中一块buffer的大小,为num_max_nvl_chunked_recv_tokens * num_bytes_per_token,而num_max_nvl_chunked_recv_tokens_per_rdma = num_max_nvl_chunked_recv_tokens / kNumRDMARanks,因此当num_rdma_ranks为3的时候,一块buffer会被切分为三个,分别对应了被对端gpu转发到不同的机器,不同的head,tail被当前warp不同的lane持有,如lane[0]对应rdma_rank[0]。然后获取当前dst_nvl_rank对应的tma_buffer和tma_mbarrier,tma_buffer的前hidden_bytes用于装数据,hidden_bytes之后的uint64为mbarrier,lane[0]负责初始化mbarrier。
if (warp_role == WarpRole::kNVLSender) { // NVL producers const auto dst_nvl_rank = warp_id; auto dst_buffer_ptr = buffer_ptrs[dst_nvl_rank], local_buffer_ptr = buffer_ptrs[nvl_rank]; auto nvl_channel_x = AsymBuffer<uint8_t>(dst_buffer_ptr, num_max_nvl_chunked_recv_tokens * num_bytes_per_token, NUM_MAX_NVL_PEERS, channel_id, num_channels, nvl_rank).advance_also(local_buffer_ptr); auto nvl_channel_head = AsymBuffer<int>(local_buffer_ptr, kNumRDMARanks, NUM_MAX_NVL_PEERS, channel_id, num_channels, dst_nvl_rank).advance_also(dst_buffer_ptr); auto nvl_channel_tail = AsymBuffer<int>(dst_buffer_ptr, kNumRDMARanks, NUM_MAX_NVL_PEERS, channel_id, num_channels, nvl_rank).advance_also(local_buffer_ptr); // TMA stuffs extern __shared__ __align__(1024) uint8_t smem_tma_buffer[]; auto tma_buffer = smem_tma_buffer + dst_nvl_rank * kNumTMABytesPerWarp; auto tma_mbarrier = reinterpret_cast<uint64_t*>(tma_buffer + hidden_bytes); uint32_t tma_phase = 0; if (lane_id == 0) { mbarrier_init(tma_mbarrier, 1); fence_view_async_shared(); fence_barrier_init(); EP_DEVICE_ASSERT(hidden_bytes + sizeof(uint64_t) <= kNumTMABytesPerWarp); } __syncwarp(); ...}如上所述,gbl_channel_prefix_matrix记录了每个rank的channel发送过来的token的前缀和,可以通过前缀和计算出来。
if (warp_role == WarpRole::kNVLSender) {...int token_start_idx = 0, token_end_idx = 0; if (lane_id < kNumRDMARanks) { int prefix_idx = (lane_id * NUM_MAX_NVL_PEERS + dst_nvl_rank) * num_channels + channel_id; token_start_idx = gbl_channel_prefix_matrix[prefix_idx]; token_end_idx = (prefix_idx == num_channels * num_ranks - 1) ? num_tokens : gbl_channel_prefix_matrix[prefix_idx + 1]; } __syncwarp();...}然后开始执行数据发送的流程,如上所述,一个lane对应一个rdma_rank的数据,这里通过all_sync判断是不是所有lane对应的数据都执行结束了。
num_used_slots表示fifo中已经使用了多少个slot,每个lane判断fifo中是否还可以容纳num_max_nvl_chunked_send_tokens个slot,如果有任意一个lane满足条件,那么break,否则循环load head,直到有空间。
if (warp_role == WarpRole::kNVLSender) {while (true) { if (__all_sync(0xffffffff, token_start_idx >= token_end_idx)) break; bool is_lane_ready = false; while (true) { int num_used_slots = cached_channel_tail_idx - cached_channel_head_idx; is_lane_ready = lane_id < kNumRDMARanks and token_start_idx < token_end_idx and num_max_nvl_chunked_recv_tokens_per_rdma - num_used_slots >= num_max_nvl_chunked_send_tokens; if (__any_sync(0xffffffff, is_lane_ready)) break; if (lane_id < kNumRDMARanks and token_start_idx < token_end_idx) cached_channel_head_idx = ld_volatile_global(nvl_channel_head.buffer() + lane_id); } } }}循环所有的rdma_rank,假设当前处理的是current_rdma_idx,如果这个rdma_rank已经完成所有发送,或者fifo空间不足,那么continue换下一个rdma_rank。
本次要发送给current_rdma_idx的token数为num_tokens_in_chunk,通过cached_channel_tail_idx可以计算出应该填充到fifo的哪个slot,如图5,通过加上current_rdma_idx * num_max_nvl_chunked_recv_tokens_per_rdma找到current_rdma_idx对应的位置。
lane[0]首先通过tma_store_wait等待上一次tma store完成,然后通过tma load将用户输入x中对应的token向量拷贝到tma_buffer,通过mbarrier_arrive_and_expect_tx执行arrive和expect-tx操作,最后通过mbarrier_wait等待load完成。
然后通过load/store拷贝source_meta和topk weight到tma buffer,由于这个是genric proxy操作,tma store为async proxy,为了保证数据可见性,所以这里通过tma_store_fence保证数据写入tma buffer,然后syncwarp执行tma store,更新token_start_idx。
执行完这个chunk token的发送后,更新tail,写入到nvl_channel_tail。
while (true) {for (int i = 0; i < kNumRDMARanks; ++ i) { current_rdma_idx = (current_rdma_idx + 1) % kNumRDMARanks; if (__shfl_sync(0xffffffff, (token_start_idx >= token_end_idx) or (not is_lane_ready), current_rdma_idx)) continue; // Sync token start index auto token_idx = static_cast<int64_t>(__shfl_sync(0xffffffff, token_start_idx, current_rdma_idx)); int num_tokens_in_chunk = __shfl_sync(0xffffffff, min(num_max_nvl_chunked_send_tokens, token_end_idx - token_start_idx), current_rdma_idx); // Send by chunk for (int chunk_idx = 0; chunk_idx < num_tokens_in_chunk; ++ chunk_idx, ++ token_idx) { // Get an empty slot int dst_slot_idx = 0; if (lane_id == current_rdma_idx) { dst_slot_idx = (cached_channel_tail_idx ++) % num_max_nvl_chunked_recv_tokens_per_rdma; dst_slot_idx = current_rdma_idx * num_max_nvl_chunked_recv_tokens_per_rdma + dst_slot_idx; } dst_slot_idx = __shfl_sync(0xffffffff, dst_slot_idx, current_rdma_idx); // Load data auto shifted_x_buffers = nvl_channel_x.buffer() + dst_slot_idx * num_bytes_per_token; auto shifted_x = x + token_idx * hidden_int4; if (lane_id == 0) { tma_store_wait(); tma_load_1d(tma_buffer, shifted_x, tma_mbarrier, hidden_bytes); mbarrier_arrive_and_expect_tx(tma_mbarrier, hidden_bytes); } __syncwarp(); mbarrier_wait(tma_mbarrier, tma_phase); // Load source meta if (lane_id == num_topk) *reinterpret_cast<SourceMeta*>(tma_buffer + hidden_bytes) = ld_nc_global(src_meta + token_idx); // Load `topk_weights` if (lane_id < num_topk) *reinterpret_cast<float*>(tma_buffer + hidden_bytes + sizeof(SourceMeta) + lane_id * sizeof(float)) = ld_nc_global(topk_weights + token_idx * num_topk + lane_id); // Issue TMA store tma_store_fence(); __syncwarp(); if (lane_id == 0) tma_store_1d(tma_buffer, shifted_x_buffers, num_bytes_per_token, false); } lane_id == current_rdma_idx ? (token_start_idx = static_cast<int>(token_idx)) : 0; } // Move queue tail tma_store_wait(); __syncwarp(); if (lane_id < kNumRDMARanks and is_lane_ready) st_release_sys_global(nvl_channel_tail.buffer() + lane_id, cached_channel_tail_idx);}kNVLAndRDMAForwarder
kNVLAndRDMAForwarder负责接收kNVLSender发送过来的数据,执行reduce,然后通过rdma发送给对应的节点。
kNumWarpsPerForwarder表示多少个warp对应一个dst_rdma_rank,一共有kNumForwarders个warp,这个值是16,那么以8节点为例,将会有2个warp对应一个节点,这2个warp被称为一个large warp。
forwarder_nvl_head和dispatch中的作用一致,用于记录每个forwarder warp的执行进度,从源gpu发送过来的token只有被多个warp都完成他们对应节点的转发之后,才能向源gpu更新head。forwarder_retired是记录每个warp是否完成所有的token转发。
然后计算自己负责的dst_rdma_rank,计算sub_warp_id,就是在large warp内自己是第几个warp,然后初始化forwarder_nvl_head和forwarder_retired。
初始化完成之后通过sync_forwarder_smem同步kNVLAndRDMAForwarder和forwarder的kCoordinator。
__shared__ volatile int forwarder_nvl_head[kNumForwarders][NUM_MAX_NVL_PEERS];__shared__ volatile bool forwarder_retired[kNumForwarders];if (warp_role == WarpRole::kNVLAndRDMAForwarder) { const auto dst_rdma_rank = warp_id / kNumWarpsPerForwarder; const auto sub_warp_id = warp_id % kNumWarpsPerForwarder; auto send_buffer = dst_rdma_rank == rdma_rank ? rdma_channel_data.recv_buffer(dst_rdma_rank) : rdma_channel_data.send_buffer(dst_rdma_rank); // Advance to the corresponding NVL buffer nvl_channel_x.advance(dst_rdma_rank * num_max_nvl_chunked_recv_tokens_per_rdma * num_bytes_per_token); nvl_channel_head.advance(dst_rdma_rank); nvl_channel_tail.advance(dst_rdma_rank); // Clean shared memory and sync EP_STATIC_ASSERT(NUM_MAX_NVL_PEERS <= 32, \"Invalid number of NVL peers\"); lane_id < NUM_MAX_NVL_PEERS ? (forwarder_nvl_head[warp_id][lane_id] = 0) : 0; lane_id == 0 ? (forwarder_retired[warp_id] = false) : false; sync_forwarder_smem(); }然后获取自己应该需要发送的token数,rdma_channel_prefix_matrix表示其他rdma_rank所有channel发送过来的token的前缀和,因此相减就可以得到自己需要发送的token数num_tokens_to_combine。
num_tokens_prefix表示自己负责token的起始位置,因此对combined_nvl_head进行偏移到自己负责的token区间。
if (warp_role == WarpRole::kNVLAndRDMAForwarder) {int cached_nvl_channel_tail_idx = 0; int num_tokens_to_combine = rdma_channel_prefix_matrix[dst_rdma_rank * num_channels + channel_id];int num_tokens_prefix = channel_id == 0 ? 0 : rdma_channel_prefix_matrix[dst_rdma_rank * num_channels + channel_id - 1];num_tokens_to_combine -= num_tokens_prefix;num_tokens_prefix += dst_rdma_rank == 0 ? 0 : rdma_rank_prefix_sum[dst_rdma_rank - 1];combined_nvl_head += num_tokens_prefix * NUM_MAX_NVL_PEERS;}发送是以chunk为粒度的,每次发送之前需要判断对方rdma_rank的fifo中是否有空闲,对端fifo总的容量是num_max_rdma_chunked_recv_tokens ,已使用的容量是对端fifo的tail - head,tail就是当前rank发送到了哪里,即token_start_idx,head就是对端回复过来的rdma_channel_head,然后判断剩余容量是否足够容纳本次要发送的token数。这个过程是由large warp的第一个warp的lane[0]执行。
for (int token_start_idx = 0; token_start_idx < num_tokens_to_combine; token_start_idx += num_max_rdma_chunked_send_tokens) { // Check destination queue emptiness, or wait a buffer to be released auto token_end_idx = min(token_start_idx + num_max_rdma_chunked_send_tokens, num_tokens_to_combine); auto num_chunked_tokens = token_end_idx - token_start_idx; auto start_time = clock64(); while (sub_warp_id == 0 and lane_id == 0) { // Inequality: `num_max_rdma_chunked_recv_tokens - (tail - head) >= num_chunked_tokens` // Here, `token_start_idx` is the actual tail int num_used_slots = token_start_idx - ld_volatile_global(rdma_channel_head.buffer(dst_rdma_rank)); if (num_max_rdma_chunked_recv_tokens - num_used_slots >= num_chunked_tokens) break; } sync_large_warp(); ...}然后开始执行token的聚合和rdma转发,一个large warp对应一个rdma rank,large warp中一个warp对应一个token。
对端rdma_rank有空闲slot之后,开始等待源gpu的sender有没有将数据发送过来,当前gpu在dispatch的时候可能转发给了多个gpu,因此要等待多个sender将这个token发送回来,这里就是通过combined_nvl_head判断sender是否已经完成这个token的发送,如果sender发送的进度超过了对应的combined_nvl_head,即cached_nvl_channel_tail_idx > expected_head的时候,就说明这个token到了,这里每个lane对应一个gpu,当所有的token都到了,就可以开始执行这些token的combine操作,combine就是将多个sender发送过来的数据,此时存放在各自的nvl_channel_x中,然后通过combine_token将这几个token对应的向量进行求和,然后存到rdma发送buffer中。
最后将各个gpu对应的expect_head填到forwarder_nvl_head,coordinator会根据这个将head回复给源gpu。
for (int token_start_idx = 0; token_start_idx < num_tokens_to_combine; token_start_idx += num_max_rdma_chunked_send_tokens) {...for (int token_idx = token_start_idx + sub_warp_id; token_idx < token_end_idx; token_idx += kNumWarpsPerForwarder) { int expected_head = -1; if (lane_id < NUM_MAX_NVL_PEERS) expected_head = ld_nc_global(combined_nvl_head + token_idx * NUM_MAX_NVL_PEERS + lane_id); while (cached_nvl_channel_tail_idx <= expected_head) { cached_nvl_channel_tail_idx = ld_acquire_sys_global(nvl_channel_tail.buffer(lane_id)); } // Combine current token auto rdma_slot_idx = token_idx % num_max_rdma_chunked_recv_tokens; void* shifted = send_buffer + rdma_slot_idx * num_bytes_per_token; auto recv_fn = [&](int src_nvl_rank, int slot_idx, int hidden_int4_idx) -> int4 { return ld_nc_global(reinterpret_cast<int4*>(nvl_channel_x.buffer(src_nvl_rank) + slot_idx * num_bytes_per_token) + hidden_int4_idx); }; auto recv_tw_fn = [&](int src_nvl_rank, int slot_idx, int topk_idx) -> float { return ld_nc_global(reinterpret_cast<float*>(nvl_channel_x.buffer(src_nvl_rank) + slot_idx * num_bytes_per_token + hidden_bytes + sizeof(SourceMeta)) + topk_idx); }; combine_token<NUM_MAX_NVL_PEERS, false, dtype_t, NUM_MAX_NVL_PEERS>(expected_head >= 0, expected_head, lane_id, hidden_int4, num_topk, static_cast<int4*>(shifted), reinterpret_cast<float*>(static_cast<int8_t*>(shifted) + hidden_bytes + sizeof(SourceMeta)), nullptr, nullptr, num_max_nvl_chunked_recv_tokens_per_rdma, recv_fn, recv_tw_fn); if (lane_id < NUM_MAX_NVL_PEERS) expected_head < 0 ? (forwarder_nvl_head[warp_id][lane_id] = -expected_head - 1) : (forwarder_nvl_head[warp_id][lane_id] = expected_head + 1);}...}最后通过nvshmemi_ibgda_put_nbi_warp将这些token的向量发送出去,并通过nvshmemi_ibgda_amo_nonfetch_add更新对端rdma_rank的tail指针。
for (int token_start_idx = 0; token_start_idx < num_tokens_to_combine; token_start_idx += num_max_rdma_chunked_send_tokens) {...if (sub_warp_id == kNumWarpsPerForwarder - 1) { if (dst_rdma_rank != rdma_rank) { auto rdma_slot_idx = token_start_idx % num_max_rdma_chunked_recv_tokens; const size_t num_bytes_per_msg = num_chunked_tokens * num_bytes_per_token; const auto dst_ptr = reinterpret_cast<uint64_t>(rdma_channel_data.recv_buffer(rdma_rank) + rdma_slot_idx * num_bytes_per_token); const auto src_ptr = reinterpret_cast<uint64_t>(rdma_channel_data.send_buffer(dst_rdma_rank) + rdma_slot_idx * num_bytes_per_token); nvshmemi_ibgda_put_nbi_warp<true>(dst_ptr, src_ptr, num_bytes_per_msg, translate_dst_rdma_rank<kLowLatencyMode>(dst_rdma_rank, nvl_rank), channel_id, lane_id, 0); } else { memory_fence(); } // Write new RDMA tail __syncwarp(); if (lane_id == 0) { nvshmemi_ibgda_amo_nonfetch_add(rdma_channel_tail.buffer(rdma_rank), num_chunked_tokens,translate_dst_rdma_rank<kLowLatencyMode>(dst_rdma_rank, nvl_rank), channel_id, dst_rdma_rank == rdma_rank); } }...}kRDMAReceiver
kRDMAReceiver逻辑和kNVLAndRDMAForwarder有一点像,dispatch出去了num_combined_tokens,因此需要收这些token回来,token在channel间切分。
因此遍历token_start_idx到token_end_idx,一个warp对应一个token,假设当前在处理第token_idx个token,每个warp中的每个lane对应一个rdma_rank,各自判断负责的rdma_rank发送过来的进度,即rdma_channel_tail,如果大于expect_head,说明token_idx已经被发送回来了,那么通过combine_token将这些向量求和写回用户buffer即可。
if (warp_role == WarpRole::kRDMAReceiver) { int token_start_idx, token_end_idx; get_channel_task_range(num_combined_tokens, num_channels, channel_id, token_start_idx, token_end_idx); int cached_channel_tail_idx = 0; for (int64_t token_idx = token_start_idx + warp_id; token_idx < token_end_idx; token_idx += kNumRDMAReceivers) { int expected_head = -1; if (lane_id < kNumRDMARanks) { expected_head = ld_nc_global(combined_rdma_head + token_idx * kNumRDMARanks + lane_id); (expected_head < 0) ? (rdma_receiver_rdma_head[warp_id][lane_id] = -expected_head - 1) : (rdma_receiver_rdma_head[warp_id][lane_id] = expected_head); } while (cached_channel_tail_idx <= expected_head) { cached_channel_tail_idx = static_cast<int>(ld_acquire_sys_global(rdma_channel_tail.buffer(lane_id))); } __syncwarp(); // Combine current token auto recv_fn = [&](int src_rdma_rank, int slot_idx, int hidden_int4_idx) -> int4 { return ld_nc_global(reinterpret_cast<const int4*>(rdma_channel_data.recv_buffer(src_rdma_rank) + slot_idx * num_bytes_per_token) + hidden_int4_idx);}; auto recv_tw_fn = [&](int src_rdma_rank, int slot_idx, int topk_idx) -> float { return ld_nc_global(reinterpret_cast<const float*>(rdma_channel_data.recv_buffer(src_rdma_rank) + slot_idx * num_bytes_per_token + hidden_bytes + sizeof(SourceMeta)) + topk_idx);}; combine_token<kNumRDMARanks, true, dtype_t, kNumTopkRDMARanks>(...); }}kCoordinator
最后是kCoordinator,对于receiver,需要根据处理token的进度回复head给forwarder,对于forwarder,需要回复token到sender,这个操作是通过kCoordinator实现的。
我们先看对于receiver的coordinator,last_rdma_head表示上次回复的head,一个lane对应一个rdma_rank,不断循环直到所有receiver都完成工作。receiver中一个warp处理一个token,一个lane对应一个rdma_rank,执行的进度被保存到rdma_receiver_rdma_head,如下所示,
图 5
因此对于一个rdma_rank,回复的head应该是对应这列中的最小值,就是最慢的warp对应的进度,比如对于rdma_rank0,此时应该回复5,然后将这个head通过nvshmemi_ibgda_amo_nonfetch_add回复给对应的rdma rank。
同理对于forwarder。
else { is_forwarder_sm ? sync_forwarder_smem() : sync_rdma_receiver_smem(); const auto num_warps_per_rdma_rank = kNumForwarders / kNumRDMARanks; int last_rdma_head = 0; int last_nvl_head[kNumRDMARanks] = {0}; int dst_rdma_rank = lane_id < kNumRDMARanks ? lane_id : 0; int dst_nvl_rank = lane_id < NUM_MAX_NVL_PEERS ? lane_id : 0; while (true) { if (not is_forwarder_sm and __all_sync(0xffffffff, lane_id >= kNumRDMAReceivers or rdma_receiver_retired[lane_id])) break; if (is_forwarder_sm and __all_sync(0xffffffff, lane_id >= kNumForwarders or forwarder_retired[lane_id])) break; if (not is_forwarder_sm) { int min_head = std::numeric_limits<int>::max(); #pragma unroll for (int i = 0; i < kNumRDMAReceivers; ++ i) if (not rdma_receiver_retired[i]) min_head = min(min_head, rdma_receiver_rdma_head[i][dst_rdma_rank]); if (min_head != std::numeric_limits<int>::max() and min_head >= last_rdma_head + num_max_rdma_chunked_send_tokens and lane_id < kNumRDMARanks) { nvshmemi_ibgda_amo_nonfetch_add(rdma_channel_head.buffer(rdma_rank), min_head - last_rdma_head, translate_dst_rdma_rank<kLowLatencyMode>(dst_rdma_rank, nvl_rank), channel_id + num_channels, dst_rdma_rank == rdma_rank); last_rdma_head = min_head; } } else { // Find minimum head for NVL ranks #pragma unroll for (int i = 0; i < kNumRDMARanks; ++ i) { int min_head = std::numeric_limits<int>::max(); #pragma unroll for (int j = 0; j < num_warps_per_rdma_rank; ++ j) if (not forwarder_retired[i * num_warps_per_rdma_rank + j]) min_head = min(min_head, forwarder_nvl_head[i * num_warps_per_rdma_rank + j][dst_nvl_rank]); if (min_head != std::numeric_limits<int>::max() and min_head > last_nvl_head[i] and lane_id < NUM_MAX_NVL_PEERS) st_relaxed_sys_global(nvl_channel_head.buffer_by(dst_nvl_rank) + i, last_nvl_head[i] = min_head); } } }}

