yolov8通道级剪枝讲解(超详细思考版)
为了提升推理速度并降低部署成本,模型剪枝已成为关键技术。本文将结合实践操作,讲解YOLOv8模型剪枝的方法原理、实施步骤及注意事项。
虽然YOLOv8n版本本身参数量少、推理速度快,能满足大多数工业检测需求,但谷歌研究表明:通过对大模型进行裁剪得到的小模型往往性能更优。
本文基于其他博客的剪枝方法的代码实现,专门针对YOLOv8模型进行剪枝优化,能够理解模型剪枝的底层操作。其核心创新点在于利用BN层(Batch Normalization)的特性,实现高效的通道级剪枝操作。
一、剪枝的理论基础
- BN参数的重要性:BN层中的缩放参数(γ)代表了卷积核的重要程度,通过裁剪γ值较小的卷积核,可以实现剪枝。
- 剪枝流程总体架构:
- 训练稀疏模型(引入BN正则化)
- 计算剪枝阈值
- 剪除冗余卷积核
- 微调模型,恢复性能
二、YOLOv8剪枝的具体步骤
1. 预备工作
- 模型训练: 先进行完整训练,获得基准性能指标。
将LL_pruning.py、LL_train.py这两个文件放在根目录下
LL_train.py代码如下所示:from ultralytics import YOLO # 导入YOLO模型库 import os # 导入os模块,用于处理文件路径 root = os.getcwd() # 获取当前工作目录 ## 配置文件路径 name_yaml = os.path.join(root, \"ultralytics/datasets/VOC.yaml\") # 数据集配置文件路径 name_pretrain = os.path.join(root, r\"D:\\practice_demo\\ultralytics\\runs\\detect\\jueyuanzi_yolov8m\\best.pt\") # 预训练模型路径 ## 原始训练路径 path_train = os.path.join(root, \"runs/detect/VOC\") # 原始训练结果保存路径 name_train = os.path.join(path_train, \"weights/last.pt\") # 原始训练模型文件路径 ## 约束训练路径、剪枝模型文件 path_constraint_train = os.path.join(root, \"runs/detect/VOC_Constraint\") # 约束训练结果保存路径 name_prune_before = os.path.join(path_constraint_train, \"weights/last.pt\") # 剪枝前模型文件路径 name_prune_after = os.path.join(path_constraint_train, \"weights/last_prune.pt\") # 剪枝后模型文件路径 ## 微调路径 path_fineturn = os.path.join(root, \"runs/detect/VOC_finetune\") # 微调结果保存路径 def step1_train(): model = YOLO(name_pretrain) # 加载预训练模型 model.train(data=name_yaml, imgsz=640, epochs=300, batch=32, name=path_train) # 训练模型 ## 一定要添加【amp=False】 def step2_Constraint_train(): model = YOLO(name_train) # 加载原始训练模型 model.train(data=name_yaml, imgsz=640, epochs=50, batch=32, amp=False, save_period=1, name=path_constraint_train) # 训练模型 def step3_pruning(): from LL_pruning import do_pruning # 导入剪枝函数 do_pruning(name_prune_before, name_prune_after) # 执行剪枝操作 def step4_finetune(): model = YOLO(name_prune_after) # 加载剪枝后的模型 model.train(data=name_yaml, imgsz=640, epochs=100, batch=32, save_period=1, name=path_fineturn) # 微调模型 # 执行训练、约束训练、剪枝和微调步骤 step1_train() # 训练模型 # step2_Constraint_train() # 进行稀疏训练 # step3_pruning() # 执行剪枝 # step4_finetune() # 微调模型
LL_pruning.py代码如下所示:
from ultralytics import YOLO # 导入YOLO模型import torch # 导入PyTorch库from ultralytics.nn.modules import Bottleneck, Conv, C2f, SPPF, Detect # 导入YOLO模型中的模块import os # 导入os模块,用于处理文件路径# os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"2\" # 可选:指定使用的GPU设备class PRUNE(): def __init__(self) -> None: self.threshold = None # 初始化阈值 def get_threshold(self, model, factor=0.8): \"\"\" 计算剪枝阈值 :param model: YOLO模型 :param factor: 剪枝比例,默认0.8 \"\"\" ws = [] # 存储权重 bs = [] # 存储偏置 for name, m in model.named_modules(): if isinstance(m, torch.nn.BatchNorm2d): # 仅处理BatchNorm2d层 w = m.weight.abs().detach() # 获取权重的绝对值 b = m.bias.abs().detach() # 获取偏置的绝对值 ws.append(w) # 添加权重 bs.append(b) # 添加偏置 print(name, w.max().item(), w.min().item(), b.max().item(), b.min().item()) # 打印权重和偏置的最大最小值 # 合并所有权重 ws = torch.cat(ws) # 计算剪枝阈值 self.threshold = torch.sort(ws, descending=True)[0][int(len(ws) * factor)] def prune_conv(self, conv1: Conv, conv2: Conv): \"\"\" 对卷积层的“相邻”卷积做通道级剪枝。 参数 ---- :param conv1: 第一个卷积层: Conv(Ultralytics封装的Conv模块,内部含 nn.Conv2d + BN + 激活) *上游* 被剪枝的卷积。删除它的某些 输出 通道。 :param conv2: 第二个卷积层: Conv 或 Conv列表 / 纯 nn.Conv2d / None *下游* 接收 conv1 输出的卷积(可能有多支分支)。需要把 输入 通道同步删除。 剪枝规则 -------- 1. 用 conv1 中 BatchNorm 的缩放系数 γ 的绝对值做“重要性”指标。 2. 选出 |γ| >= 全局阈值 的通道索引 keep_idxs(若太少则降低阈值,至少保留8个,防止结构非法)。 3. 在 conv1 中:删掉其它通道 → 需要同时修改 BN 的各种统计量与 nn.Conv2d 的权重/偏置/out_channels。 4. 在 conv2 中:这些被删的只是“输入特征图”,因此只更新 in_channels。 \"\"\" # a. 根据BN中的参数,获取需要保留的index gamma = conv1.bn.weight.data.detach() # 获取BN层的权重 beta = conv1.bn.bias.data.detach() # 获取BN层的偏置 keep_idxs = [] # 存储需要保留的索引 local_threshold = self.threshold # 使用全局阈值 while len(keep_idxs) = local_threshold)[0] # 获取满足条件的索引 local_threshold = local_threshold * 0.5 # 如果不足8个,降低阈值 n = len(keep_idxs) # 保留的卷积核数量 print(n / len(gamma)) # 打印保留的比例 # b. 利用index对BN进行剪枝 conv1.bn.weight.data = gamma[keep_idxs] # 更新BN权重 conv1.bn.bias.data = beta[keep_idxs] # 更新BN偏置 conv1.bn.running_var.data = conv1.bn.running_var.data[keep_idxs] # 更新BN的方差 conv1.bn.running_mean.data = conv1.bn.running_mean.data[keep_idxs] # 更新BN的均值 conv1.bn.num_features = n # 更新BN的特征数量 conv1.conv.weight.data = conv1.conv.weight.data[keep_idxs] # 更新卷积层的权重 conv1.conv.out_channels = n # 更新卷积层的输出通道数 # c. 利用index对conv1进行剪枝 if conv1.conv.bias is not None: conv1.conv.bias.data = conv1.conv.bias.data[keep_idxs] # 更新卷积层的偏置 # d. 利用index对conv2进行剪枝 if not isinstance(conv2, list): conv2 = [conv2] # 确保conv2是列表 for item in conv2: if item is None: continue # 跳过None if isinstance(item, Conv): conv = item.conv # 获取卷积层 else: conv = item conv.in_channels = n # 更新输入通道数 conv.weight.data = conv.weight.data[:, keep_idxs] # 更新卷积层的权重 def prune(self, m1, m2): \"\"\" 对模块进行剪枝 :param m1: 第一个模块 :param m2: 第二个模块 \"\"\" if isinstance(m1, C2f): # 如果m1是C2f模块,获取其cv2 m1 = m1.cv2 if not isinstance(m2, list): # 确保m2是列表 m2 = [m2] for i, item in enumerate(m2): if isinstance(item, C2f) or isinstance(item, SPPF): m2[i] = item.cv1 # 获取C2f或SPPF的cv1 self.prune_conv(m1, m2) # 对卷积层进行剪枝def do_pruning(modelpath, savepath): \"\"\" 执行剪枝操作 :param modelpath: 原始模型路径 :param savepath: 剪枝后模型保存路径 \"\"\" pruning = PRUNE() # 创建PRUNE实例 ### 0. 加载模型 yolo = YOLO(modelpath) # 从指定路径加载YOLO模型 pruning.get_threshold(yolo.model, 0.8) # 获取剪枝阈值,0.8为剪枝率 ### 1. 剪枝c2f中的Bottleneck for name, m in yolo.model.named_modules(): if isinstance(m, Bottleneck): # 仅处理Bottleneck模块 pruning.prune_conv(m.cv1, m.cv2) # 对Bottleneck中的卷积层进行剪枝 ### 2. 指定剪枝不同模块之间的卷积核 seq = yolo.model.model # 获取模型的序列 for i in [3, 5, 7, 8]: # 指定需要剪枝的模块 pruning.prune(seq[i], seq[i + 1]) # 对相邻模块进行剪枝 ### 3. 对检测头进行剪枝 detect: Detect = seq[-1] # 获取检测头 last_inputs = [seq[15], seq[18], seq[21]] # 获取最后输入的模块 colasts = [seq[16], seq[19], None] # 获取与最后输入相连的模块 for last_input, colast, cv2, cv3 in zip(last_inputs, colasts, detect.cv2, detect.cv3): pruning.prune(last_input, [colast, cv2[0], cv3[0]]) # 对输入模块和检测头进行剪枝 pruning.prune(cv2[0], cv2[1]) # 对检测头的卷积层进行剪枝 pruning.prune(cv2[1], cv2[2]) # 对检测头的卷积层进行剪枝 pruning.prune(cv3[0], cv3[1]) # 对检测头的卷积层进行剪枝 pruning.prune(cv3[1], cv3[2]) # 对检测头的卷积层进行剪枝 ### 4. 模型梯度设置与保存 for name, p in yolo.model.named_parameters(): p.requires_grad = True # 设置所有参数的梯度为可计算 # yolo.val() # 验证模型性能 torch.save(yolo.ckpt, savepath) # 保存剪枝后的模型 yolo.model.pt_path = yolo.model.pt_path.replace(\"last.pt\", os.path.basename(savepath)) # 更新模型路径 yolo.export(format=\"onnx\") # 导出为ONNX格式 ## 重新加载模型,修改保存命名,用以比较剪枝前后的onnx的大小 yolo = YOLO(modelpath) # 从指定路径加载YOLO模型 yolo.export(format=\"onnx\") # 导出为ONNX格式if __name__ == \"__main__\": modelpath = \"runs/detect1/14_Constraint/weights/last.pt\" # 原始模型路径 savepath = \"runs/detect1/14_Constraint/weights/last_prune.pt\" # 剪枝后模型保存路径 do_pruning(modelpath, savepath) # 执行剪枝操作2. 稀疏正则训练
- 使用带有 BN正则的训练方式,促进BN参数稀疏化。
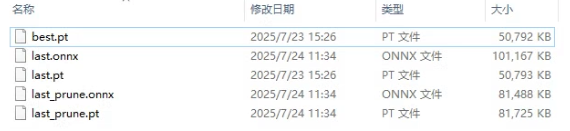
首先加载一个正常训练的yolov8模型权重(.pt文件),在ultralytics/engine/trainer.py中添加如下代码,使得bn参数在训练时变得稀疏。
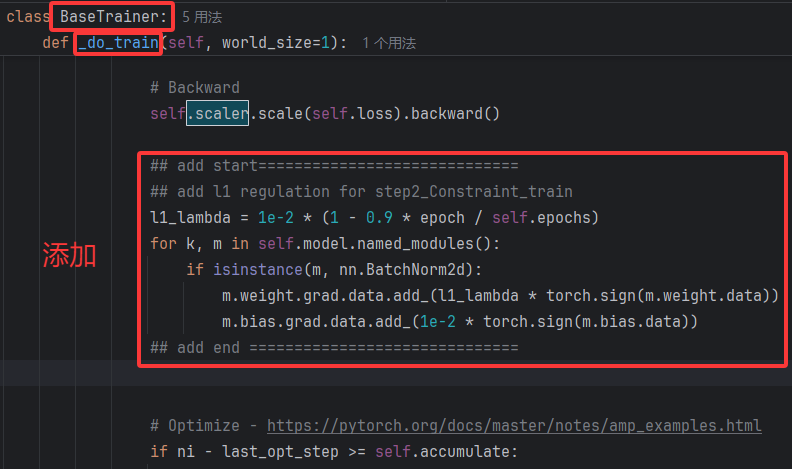
代码中对所有 BatchNorm 层加了 L1 正则,以便自动把不重要的通道“压”成零,后面再统一按阈值剪枝。关键代码如下:
... ## add start============================= ## add l1 regulation for step2_Constraint_train l1_lambda = 1e-2 * (1 - 0.9 * epoch / self.epochs) for k, m in self.model.named_modules(): if isinstance(m, nn.BatchNorm2d): m.weight.grad.data.add_(l1_lambda * torch.sign(m.weight.data)) m.bias.grad.data.add_(1e-2 * torch.sign(m.bias.data)) ## add end ==============================...-
为什么只对 BN 做正则?
BatchNorm 的 γ(scale)系数直接影响通道输出强度:γ ≈ 0 时,该通道几乎不参与后续计算,用它来衡量“重要性”最直观。 -
L1 正则如何“稀疏”?
在反向传播时,为每个 γ/β 的梯度额外加上 ±λ,这会让本就小的 γ 更快被拉向 0,从而在训练中自然分化出大 γ(保留通道)和小 γ(待剪通道)。 -
λ 为何随 epoch 递减?
训练初期靠强正则快速分离;后期减弱正则,避免过度压榨保留通道,给微调留下空间。 -
bias 也正则吗?
虽然偏置对通道筛选作用不如 γ 强,但适度收敛 β 能进一步去除边缘特征,提高稀疏度。
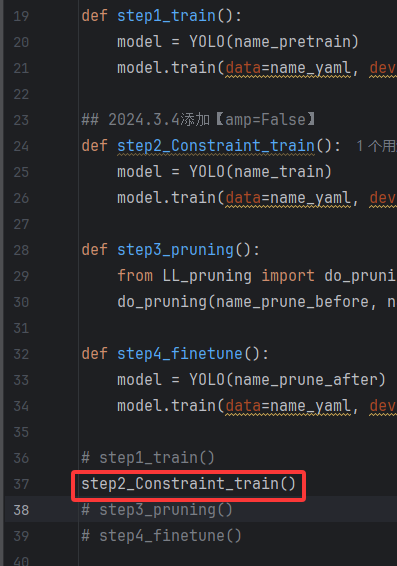
之后在LL_pruning.py中运行方框中的代码
注意事项:
稀疏训练需要关闭混合精度(amp=False)
剪枝依赖于 BatchNorm 的 γ 值作为排序阈值,γ 越小越容易被剪除。若使用 FP16(混合精度),许多接近 0 的 γ 会被量化到同一值甚至下溢为 0,导致排序失真,同时 L1 正则梯度也容易消失,后续剪枝的阈值选择会变得不稳定。而使用 FP32(amp=False)能精确表示这些微小差异,确保稀疏模式可控。
稀疏训练的 batch size 不宜过大
由于关闭了混合精度,模型采用全精度计算,显存占用显著增加。若 batch size 设置过大,可能导致显存溢出(OOM),进而引发训练失败。
稀疏训练阶段要将 patience 设为 0 或较大值
稀疏训练的目标并非短期提升 mAP,而是让 BN 的 γ 在多个 epoch 内逐步被 L1 正则“压缩”。在此期间,验证集指标可能停滞甚至下降。若启用常规早停机制(默认 patience 为几十),训练可能在 γ 尚未充分分化前被提前终止,导致剪枝时阈值模糊、可剪通道不足。
3. 剪枝
执行以下代码;
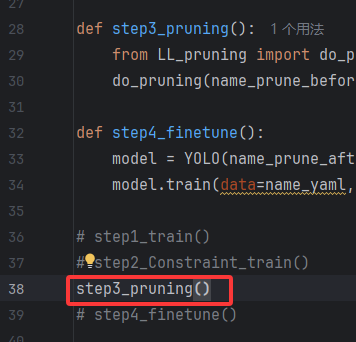
剪枝中的注意点:
在 YOLOv8 中,当进行 split 和 concat 操作时,若剪枝后的通道数不匹配会报错。LL_pruning.py 的剪枝代码怎么避免这一问题,暂时还没研究透,有大佬知道请不吝指教。
关于 do_pruning 方法启用 yolo.val() 后保存的剪枝模型缺失 BN 层的原因:
Ultralytics 的验证 / 导出流程会将 Conv + BatchNorm 静态融合到卷积权重和偏置中,从而提升推理速度和轻量化。这一过程会直接移除 BN 层,因此保存的 yolo.ckpt 是已融合的模型。
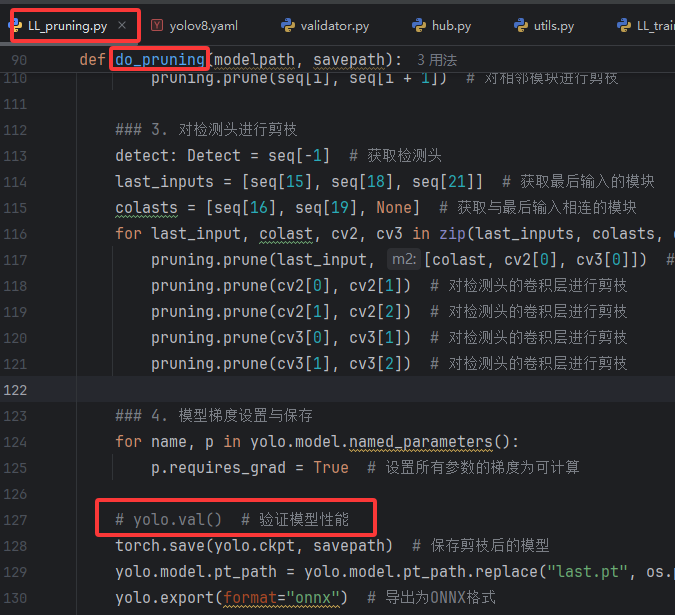
对比剪枝前后的模型文件(last.pt/last_prune.pt)及其 ONNX 转换结果:
剪枝后的 .pt 文件增大,而 ONNX 文件从 43MB 缩减至 36MB。这是因为 .pt 文件包含完整的 checkpoint 元数据,而 ONNX 仅保存精简的推理图结构,因此只需关注 ONNX 文件大小的优化即可。
4. 微调
在第二步稀疏正则训练中将BN约束注释
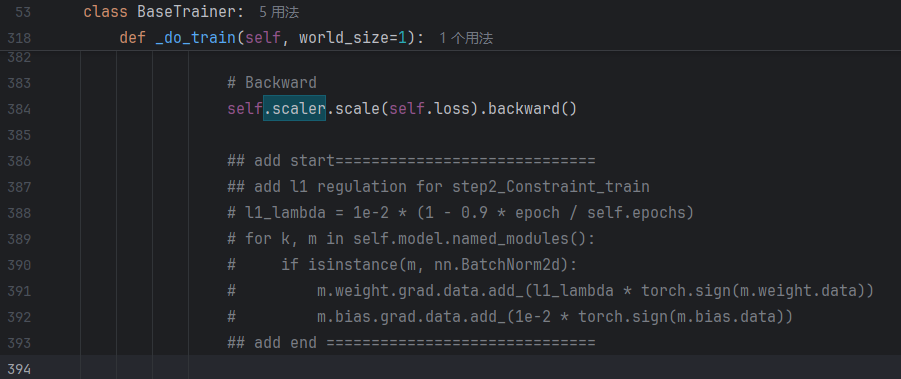
需要注意的是明明加载的是剪枝后的模型,但训练启动时打印的日志却显示为标准版模型的参数。并且经过验证,微调后的模型参数就是标准的yolo模型。所以需要进行一些修改,详细的讲解可以看YOLOv8 剪枝模型加载踩坑记:解决 YAML 覆盖剪枝结构的问题-CSDN博客
修改ultralytics/engine/model.py文件内容:
self.trainer.model包含从YAML文件加载的原始模型配置信息,以及从PT文件加载的剪枝后权重。只需将该变量的网络结构更新为剪枝后的网络结构就行,否则训练后的模型参数不会改变。
运行下面的代码
yolov8模型的剪枝到这就结束了。

