耗时一周巨作——全面解析Coze工作流,实例搭建热门AI Agent_coze工作流资源
个人主页-爱因斯晨
大家好呀!最近有没有想我?博主努力回三中哦!
最近学习人工智能时遇到一个好用的网站分享给大家:
人工智能学习
近日,Coze开源引起科技圈激烈讨论。Coze开源是AI领域的重要举措,既通过Apache 2.0协议降低了智能体开发门槛,让开发者可自由部署、二次开发及商用,推动技术普惠与行业标准化,又能借助开源社区构建开发者生态,助力字节跳动推广豆包大模型和云服务,重塑行业竞争格局;但同时也面临功能生态短板(如缺失部分高级功能、插件较少)、可持续性风险(算力需求与变现压力)及安全治理挑战(漏洞风险与劣质应用泛滥)等问题,是一把兼具机遇与挑战的“双刃剑”。
一、初识Coze

1.价值定位
扣子空间是新一代AI Agent开发平台。凭借”低代码“功能,使开发门槛降低。开发的AI智能体,可以通过API或SDK将 AI 应用集成到你的业务系统中。提高了编码效率。
2.核心功能
一、智能体(Bot)构建核心功能
这是 Coze 的基础且核心能力,支持零代码或低代码搭建专属 AI 智能体。
- 人设与回复逻辑定义:
可通过自然语言设定 Bot 的身份(如 “历史科普博主”“电商客服”)、性格(如 “活泼亲切”“严谨专业”)、知识范围及回复风格;还能配置触发规则(如特定关键词触发预设回复、用户提问类型匹配对应处理流程)。 - 多模态能力集成:
支持文本、图像、语音等多模态交互。例如,可接入图像生成插件(如 Stable Diffusion)让 Bot 根据文字描述生成图片;或接入语音转文字工具,实现语音提问的实时处理。 - 工具与插件调用:
内置丰富的官方工具(如 “网页搜索”“计算器”“代码解释器”),也支持接入第三方 API 或自定义插件(如企业内部数据接口、特定业务工具)。比如,搭建 “旅行规划 Bot” 时,可调用 “航班查询插件”“酒店预订 API”,实现实时信息获取与操作。
二、工作流(Workflow)自动化功能
即前文提到的 “工作流”,用于将复杂任务拆解为自动化流程,是提升 Bot 效率的关键工具(详细功能可结合前文,此处侧重 “操作与场景”)。
-
可视化流程编排:
通过拖拽节点(如 “LLM 调用”“条件判断”“数据处理”“插件执行”)在画布上搭建流程,无需代码即可实现 “多步骤任务自动化”。例如,“沉浸式历史故事短视频生成工作流” 可拆解为:
- “用户输入历史主题”→2. “LLM 节点生成故事脚本”→3. “图像生成节点根据脚本关键词生成场景图”→4. “视频合成插件拼接图文与配音”→5. “输出最终视频”。
-
灵活的节点与逻辑控制:
支持 “条件分支”(如 “若用户需求是‘简单介绍’则调用轻量模型,若为‘深度分析’则调用高级模型”)、“循环执行”(如 “多次校验数据格式直至符合要求”)、“并行处理”(如 “同时调用两个插件分别获取不同维度数据”)等复杂逻辑,适配多样业务场景。
三、知识库(Knowledge Base)管理功能
用于存储和管理 Bot 的 “专属知识”,确保 Bot 回复的准确性与针对性。
- 多格式知识导入与结构化:
支持导入文本、PDF、Word、Excel 等格式文件,或直接粘贴网页链接、手动录入知识;系统会自动对知识进行分词、索引,生成结构化知识库(如按 “章节”“关键词” 分类)。 - 智能知识召回与引用:
当 Bot 接收用户提问时,会自动从知识库中检索相关内容,并结合 LLM 生成回复(同时标注知识来源,方便溯源)。例如,企业搭建 “内部培训 Bot” 时,可将员工手册、产品资料导入知识库,Bot 即可基于这些专属内容解答员工问题,避免 “幻觉回答”。 - 知识库更新与维护:
支持随时添加、删除、修改知识内容,也可设置 “知识有效期”(如临时活动规则到期后自动失效),确保知识的时效性。
四、测试与部署功能
-
多场景测试工具:
提供 “对话测试” 功能,可模拟用户提问,实时查看 Bot 的回复效果,并针对 “回答错误”“流程卡顿” 等问题标记 “bad case”,用于后续优化;也支持批量导入测试用例,自动生成测试报告(如 “准确率”“响应速度”“工具调用成功率” 等指标)。 -
多平台一键部署:
搭建完成的 Bot 可快速部署到多种渠道,包括:
- 官方渠道:Coze 网页端、Coze 小程序;
- 第三方平台:微信公众号 / 小程序、Discord、Telegram、企业微信等(通过 API 或官方插件对接);
- 自定义场景:生成嵌入代码,直接集成到企业官网、APP 或内部系统。
五、团队协作与资源管理功能
适合多人共同开发或企业级使用。
- 工作空间与权限管理:
可创建 “团队工作空间”,邀请成员加入并分配权限(如 “管理员”“开发者”“测试者”),不同权限对应不同操作范围(如开发者可编辑 Bot,测试者仅能进行测试),保障协作效率与数据安全。 - 资源库统一管理:
工作流、知识库、插件、测试用例等资源可统一存储在 “资源库”,支持跨 Bot 复用(如将 “客户信息查询工作流” 应用到多个客服 Bot),减少重复开发。
典型适用场景
- 内容创作:如搭建 “短视频脚本生成 Bot”“文案优化 Bot”,结合工作流实现 “选题→初稿→润色→排版” 自动化;
- 企业服务:如 “智能客服 Bot”(对接知识库和订单系统,自动解答售后问题)、“办公助手 Bot”(自动汇总周报、预约会议);
- 个人工具:如 “学习助手 Bot”(定制化整理知识点)、“旅行规划 Bot”(结合实时数据生成行程);
- 开发者工具:如快速搭建 API 测试 Bot、代码解释 Bot 等。
3.差异对比
CozeDifyn8nLLM) 应用开发平台,融合后端即服务(Backend as Service)和 LLMOps 理念,专注于基于大语言模型的智能应用全生命周期管理Apache 2.0 协议Fair Code)许可,允许商业化使用,鼓励对开源贡献者补偿 LLMOps 理念,提供从原型到生产部署全流程支持Chatflow(面向对话类情景)和 Workflow(面向自动化及批处理情景),通过节点配置和变量串联搭建,支持条件分支等复杂逻辑JavaScript/Python 代码实现复杂逻辑GPT-4LLM 接入流程,通过插件或 API 集成多种主流大语言模型,能根据业务场景动态切换模型API 和第三方工具RAG 框架,可一键上传企业文档构建知识库,实现精准问答,在与 AI 相关的数据处理上能力较强JavaScript/Python 处理数据,如合并表格、加密敏感信息等,数据处理能力灵活且强大SaaS)GDPR、HIPAA等合规要求,数据安全性和合规性较高SaaS 系统开发等,可满足对模型运维和复杂工作流有较高要求的场景4.Coze和Coze空间
功能定位:“开发平台” vs “协同办公场所”
- 扣子(Coze):核心是AI 智能体开发平台,面向 “搭建者”,无论是否有编程基础,都能通过低代码方式创建、训练 AI 智能体(如智能客服、天气助手),并编排工作流(如短视频生成、数据查询流程),本质是 “生产 AI 应用的工具”。
- 扣子空间(Coze Space):核心是AI 协同办公助手,面向 “使用者”,聚焦 “高效完成实际任务”,无需搭建智能体,只需提出目标(如 “写一份产品销售报告”“设计《朝花夕拾》教案”),即可作为办公场景的协作工具,本质是 “用 AI 解决具体工作的场所”。
任务处理方式:“手动编排” vs “自动拆解”
- 扣子:需用户手动设计工作流,明确 AI 执行的每一步逻辑(如 “调用天气插件→获取数据→按格式输出”),适合需要定制化流程的场景,但依赖用户对任务逻辑的拆解能力。
- 扣子空间:支持智能任务分解,用户仅需输入目标(如 “规划北京三日游”),系统会自动拆分为 “景点筛选→行程排序→天气查询→酒店推荐” 等子任务,按逻辑依次执行;还提供 “探索模式”“规划模式” 两种处理方式,无需用户手动配置步骤。
输出成果形式:“多样化创作” vs “办公场景适配”
- 扣子:输出形式更偏向 “创作与应用交付”,包括视频、文字、网页链接、智能体应用(可发布到社交平台 / 业务系统)等,随插件生态完善可拓展更多创作类成果(如动漫视频、小说推文)。
- 扣子空间:输出更聚焦 “办公实用性成果”,如 PPT 文件、Markdown 文档、在线数据表格、思维导图等,直接匹配报告撰写、会议安排、数据分析等工作场景,无需额外格式转换即可使用。
工具调用能力:“插件接入” vs “深度集成”
- 扣子:通过 “插件市场” 接入第三方工具(如头条搜索、图像生成、OCR 识别),工具数量丰富但以 “单点功能调用” 为主,需手动关联到工作流中,适合轻量工具整合。
- 扣子空间:支持MCP 工具协议,不仅能调用墨迹天气、GitHub、高德地图等外部工具,还能与飞书全家桶(飞书文档、多维表格、日历)深度集成,工具调用更贴合办公协同场景,且无需手动配置关联逻辑,系统会自动匹配任务所需工具。
二、开发者-智能体搭建
智能体,也就是我们常说的AI Agent,但它到底是什么呢?我们可以用一个简单的公式进行描述:AI Agent =Processing(流程处理)+LLM(语言模型)+Memory(长期记忆)+ Tools(工具)。
有没有发现这个AI Agent跟我们人有点相似,LLM就像是我们的大脑,帮助我们做决策和分析,Processing是我们将一件事拆分成的每一个步骤,Memory就像是我们人类的记忆和经验,Tools就像是我们为了完成一件事所需要用到的工具。
单纯的LLM就是Large Language Model大语言模型,简称大模型,主要被用来理解文本和生成自然语言文本,也就是我们前些年最火所谓的AI。通常没有特定的目标和任务,就是你一句我一句这种根据输入的文本给出相应的回答的形式,大家所熟知的ChatGpt、Deepseek、豆包、Kimi、元宝、通义千问这些其实都是大语言模型。
但是单一的大语言模型能做到的对话再厉害,它也只是一个对话模型, 无法真正做到某件事情,其实AI Agent就是自动化机器人,可以给它设定很多个功能,我只需要一个指令,它就可以帮我们完成一系列动作,这和前几年火的RPA有异曲同工之妙。
我们来使用Coze在空间中设计一个智能体。
首先,我们要明白我们的目的,我要设计一个能生成成语视频的智能体。我通过输入成语,他就能给我生成一个完整的讲解视频。生成视频,我们需要有文案,图片,声音。我们可以做以下部署:
1.首先进入资源库,点击工作流
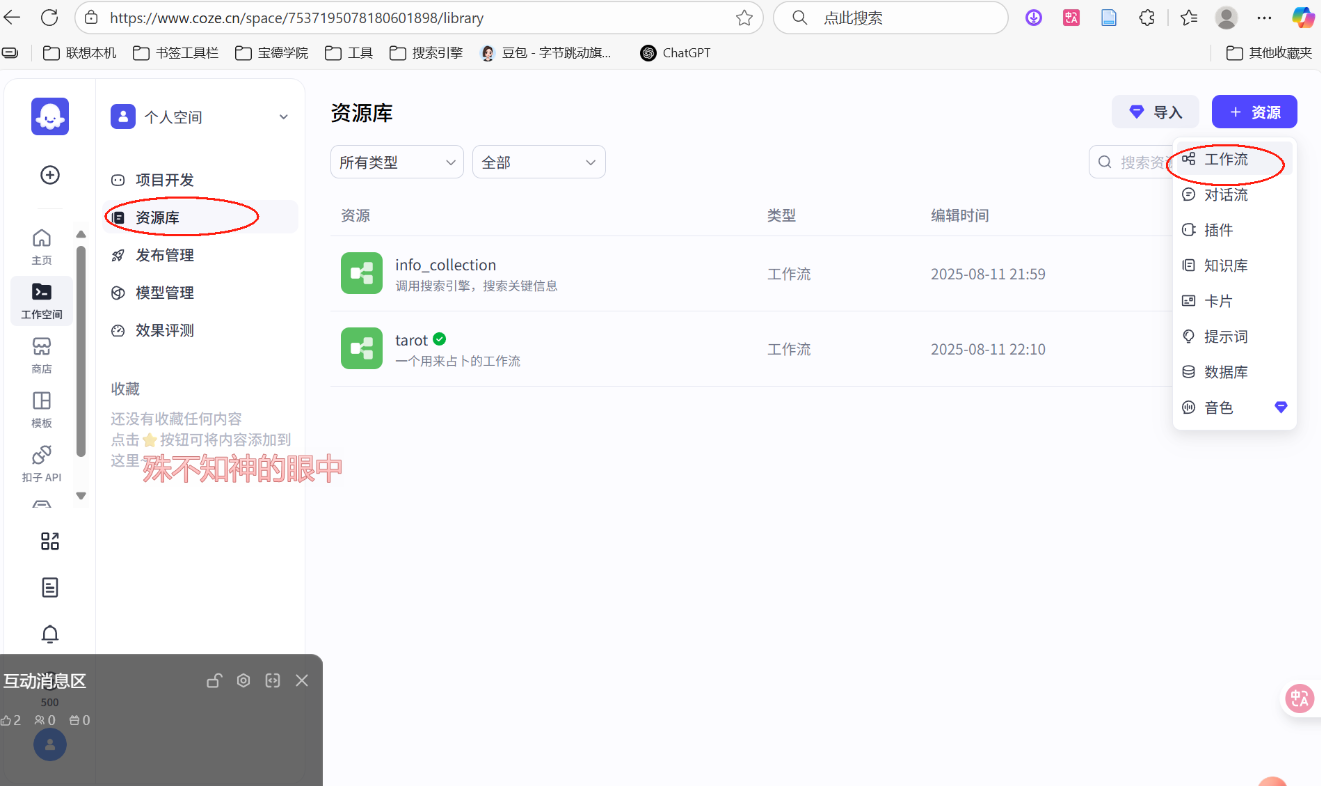
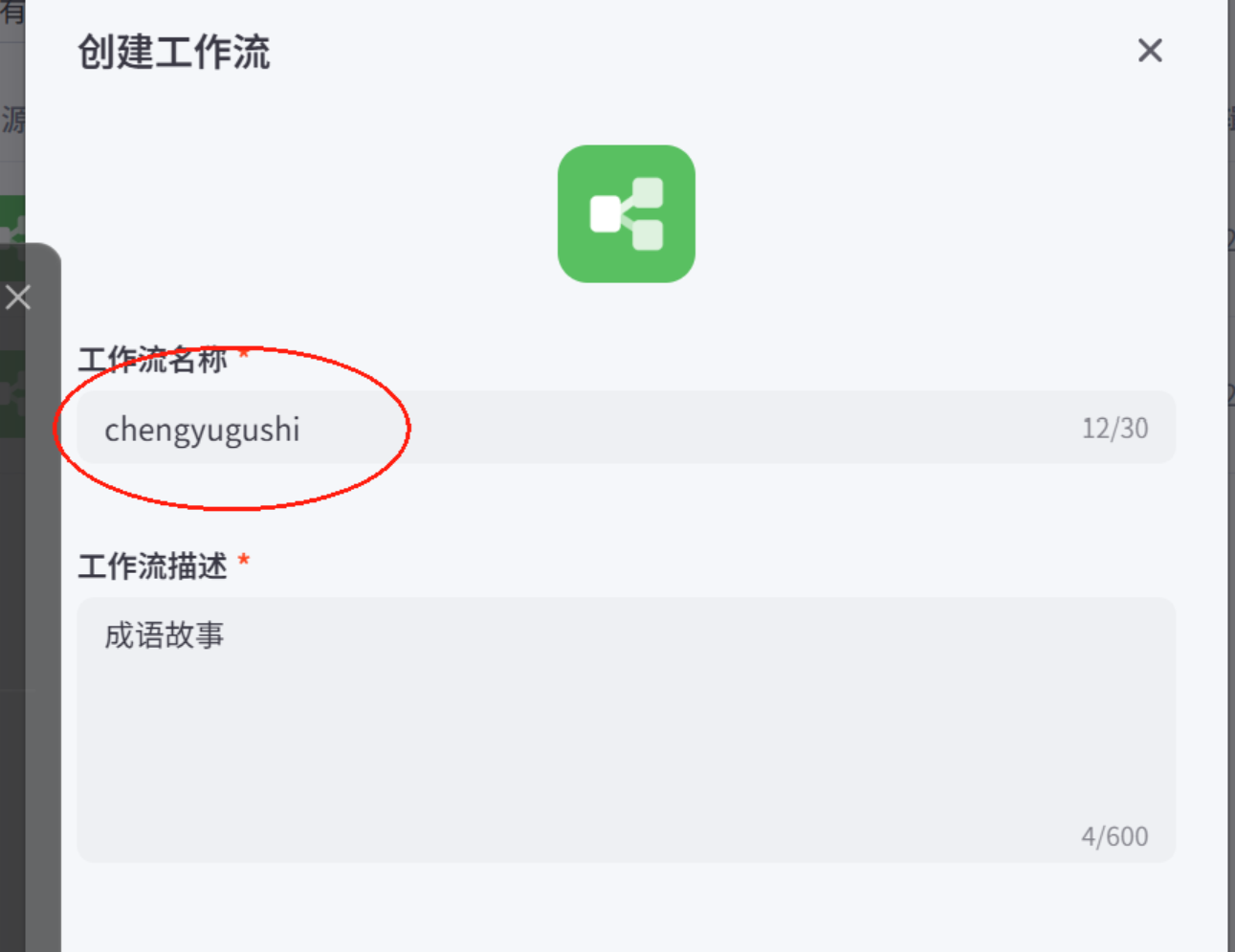
2.输入名称
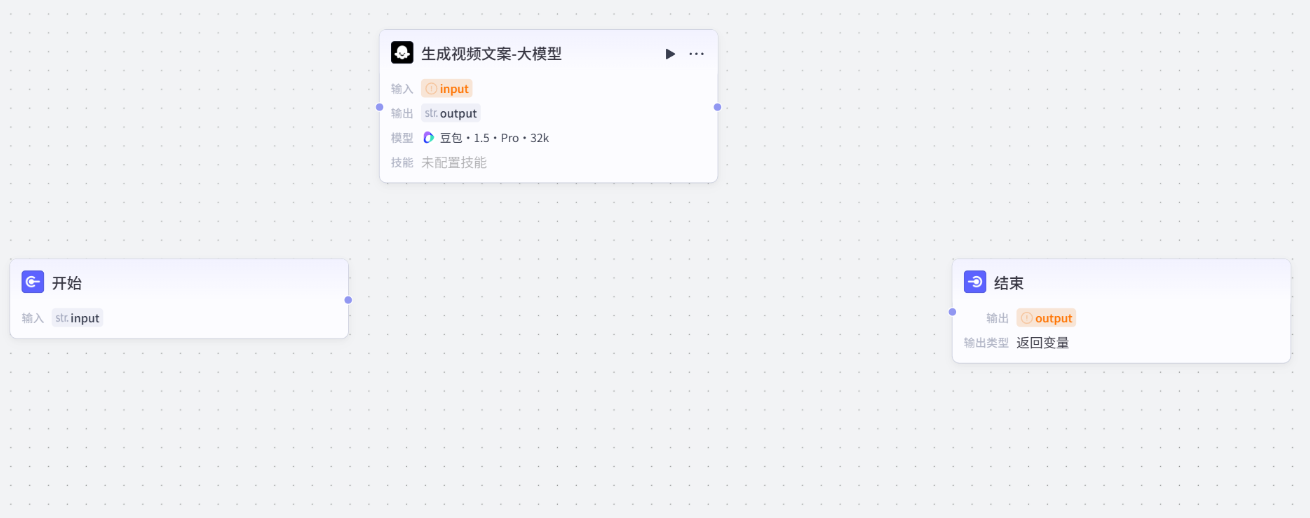
3.插入大模型,重命名
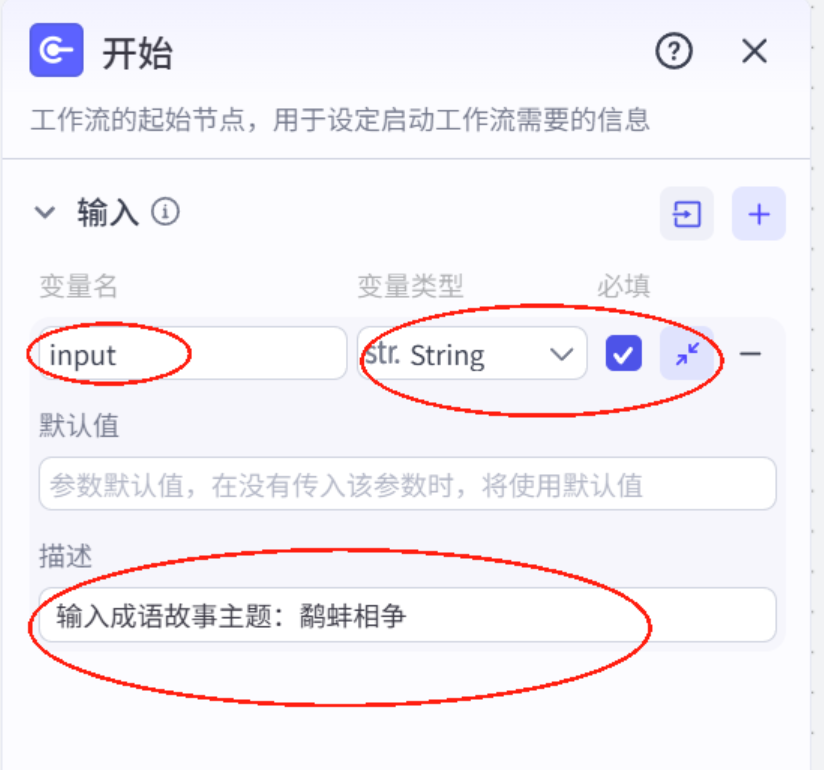
4.配置开始节点
5.配置大模型
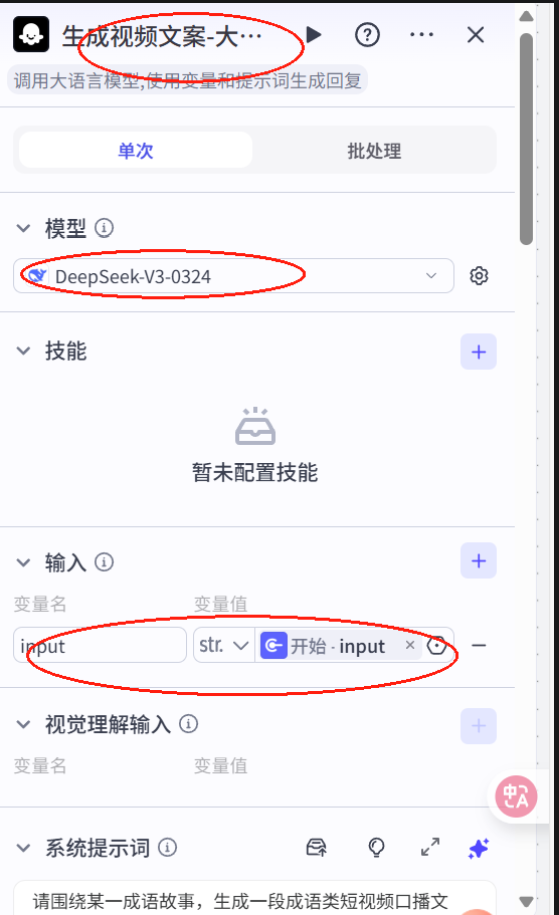
6.书写提示词
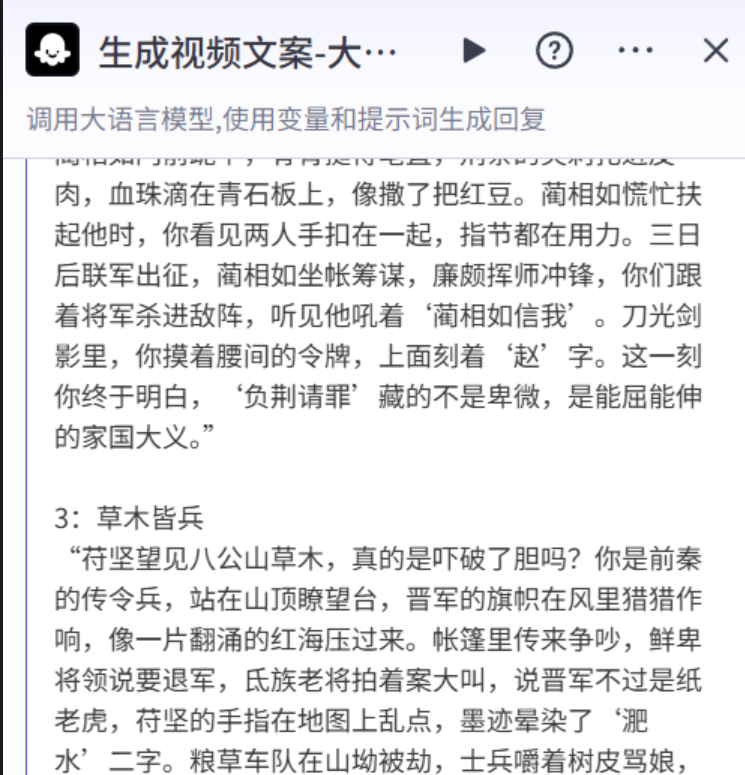
请围绕某一成语故事,生成一段成语类短视频口播文案,需遵循以下结构:1. **悬念开场**:以“【成语相关场景/背景】+ 反常识疑问/断言”开篇,激发观众兴趣。2. **身份代入**:用第二人称“你”描述在成语故事背景下的身份、所处情境及面临的核心难题,包含具体情境信息,直接进入主题。3. **冲突升级**:依次展现事件发展中的外部阻碍、内部矛盾、关键抉择三层冲突。4. **破局细节**:主角采取3个递进动作,包含:具体行动(如实地考察/制定策略)、巧思运用(如借助外力/变换方法)、核心举措(如关键言行/决定性行为)。5. **主题收尾**:通过事件结局引出成语的形成,以“这一刻你终于明白…”句式点题,揭示成语蕴含的道理。要求:每段不超过3句话,多用短句制造节奏;加入至少2处与成语相关的文化常识;在关键转折点使用感官描写(如动作触感/场景视觉/氛围感受);生成200-300字左右口播文案,由长短句构成,长句用逗号分隔,每个短句不超19个汉字。**输出要求**: 只输出口播字幕文案,不要输出其他任何额外内容,不输出分段说明参考实例:1:完璧归赵“蔺相如捧着和氏璧,真的只是靠嘴皮子退敌吗?你是赵王派去的护卫,手按剑柄站在秦宫廊下,玉璧的冰凉透过锦盒传来,像块寒冰贴在掌心。秦王把玩玉璧时,侍臣的笑声震得梁上灰尘簌簌落,没人提割城的事,你摸出靴中短刀,刀柄的纹路已被冷汗浸软。赵军在边境被秦军牵制,国内大臣吵着要毁玉避祸,你收到密信,若玉璧留秦,家眷立斩。蔺相如突然捧玉后退,指尖抵着柱角,石屑硌进肉里。他先说玉有瑕疵,骗回璧后举过头顶,扬言要撞碎在柱上,声音比殿角铜钟还响。你看见秦王眼角抽搐,侍臣摸向腰间的剑,寒光映在玉璧上。蔺相如让秦王斋戒五日,你趁机带着玉璧混在商队里,用炭笔在璧上刻下微小记号。五日后秦宫,他指着空盒笑说,玉已归赵,要杀要剐悉听尊便。秦王摔碎案上酒樽,酒液溅湿你裤脚,却终究没下令动手。你摸着袖中带回的玉璧,刻痕还带着体温。这一刻你终于明白,‘完璧归赵’靠的从不是鲁莽,是把生死当筹码的精准算计。”2:负荆请罪“廉颇光着脊背负荆,真的只是服软那么简单吗?你是廉颇的亲兵,捧着荆条跟在他身后,石板路的凉气透过草鞋往上窜,棘刺在他背上划出红痕。蔺相如的门客拦在巷口,投来的白眼比冬日寒风还冷,军中副将在街角跺脚,骂将军辱没了上卿身份。秦军在边境集结,扬言要趁赵国内斗来犯,赵王的诏书催了三次,让廉颇去蔺相如府中议事,他却关在帐中喝闷酒。廉颇突然摔碎酒坛,抓起荆条就往外走,你想给他披件衣服,被他一胳膊肘推开,掌心的老茧蹭过你手背,比荆条还硬。他在蔺相如门前跪下,脊背挺得笔直,荆条的尖刺扎进皮肉,血珠滴在青石板上,像撒了把红豆。蔺相如慌忙扶起他时,你看见两人手扣在一起,指节都在用力。三日后联军出征,蔺相如坐帐筹谋,廉颇挥师冲锋,你们跟着将军杀进敌阵,听见他吼着‘蔺相如信我’。刀光剑影里,你摸着腰间的令牌,上面刻着‘赵’字。这一刻你终于明白,‘负荆请罪’藏的不是卑微,是能屈能伸的家国大义。”3:草木皆兵“苻坚望见八公山草木,真的是吓破了胆吗?你是前秦的传令兵,站在山顶瞭望台,晋军的旗帜在风里猎猎作响,像一片翻涌的红海压过来。帐篷里传来争吵,鲜卑将领说要退军,氐族老将拍着案大叫,说晋军不过是纸老虎,苻坚的手指在地图上乱点,墨迹晕染了‘淝水’二字。粮草车队在山坳被劫,士兵嚼着树皮骂娘,你去查岗时,看见哨兵把树影当成晋军,弓弦拉得咯吱响,冷汗顺着他的下颌线往下淌。苻坚突然下令全军后撤,让晋军渡过淝水来决战,你传达命令时,马蹄踩在落叶上,沙沙声像背后有人追。晋军趁势渡河,喊杀声震得山摇地动。你看见士兵们掉头就跑,铠甲撞在一起叮当乱响,有人被自己人推倒,惨叫淹没在惊呼声里。苻坚的轿子在乱军里颠簸,他掀帘张望时,脸色比头盔还白。退到淮北时,你捡了面掉在地上的战鼓,鼓皮上还沾着泥和血。风一吹,周围的草叶沙沙动,你突然觉得那都是举着刀的晋兵。这一刻你终于明白,‘草木皆兵’怕的从来不是草木,是败亡前夕,自己吓垮自己的人心。”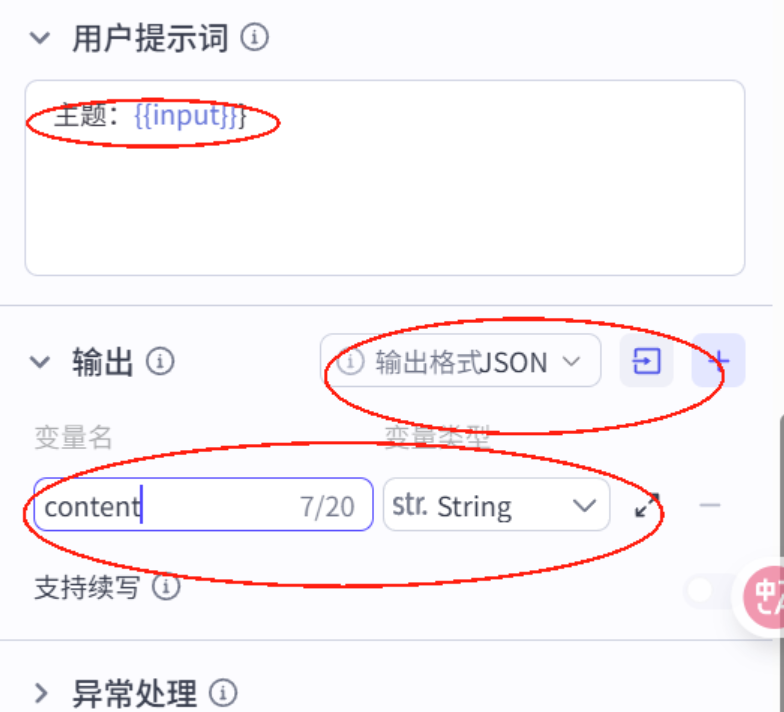
7.再添加个大模型,配置,书写提示词

# 角色根据故事信息生成故事主角开场绘画提示词desc_prompt。## 技能### 技能 1: 生成绘画提示1. 根据故事信息,生成主角任务绘画提示词 desc_promopt,详细描述人物动作、表情、服装,色彩风格等细节。 - 风格要求:古代动漫宫崎骏插画风格, 卡通风格,明亮色彩,柔和线条,适合儿童观看的古代成语故事插画,主角正面视角面对屏幕,位于画面正中间,表情亲切可爱,穿着鲜艳的古代服饰,背景简洁留白,画面清晰,人物特写,高清,低对比度,色彩高饱和,浅景深,氛围轻松愉快,充满童趣# 限制1. 只输出绘画提示词,不要输出其他额外内容。将这段提示词改一下,我要生成的图片应该是适合小孩观看的成语故事。提示词用汉语回答。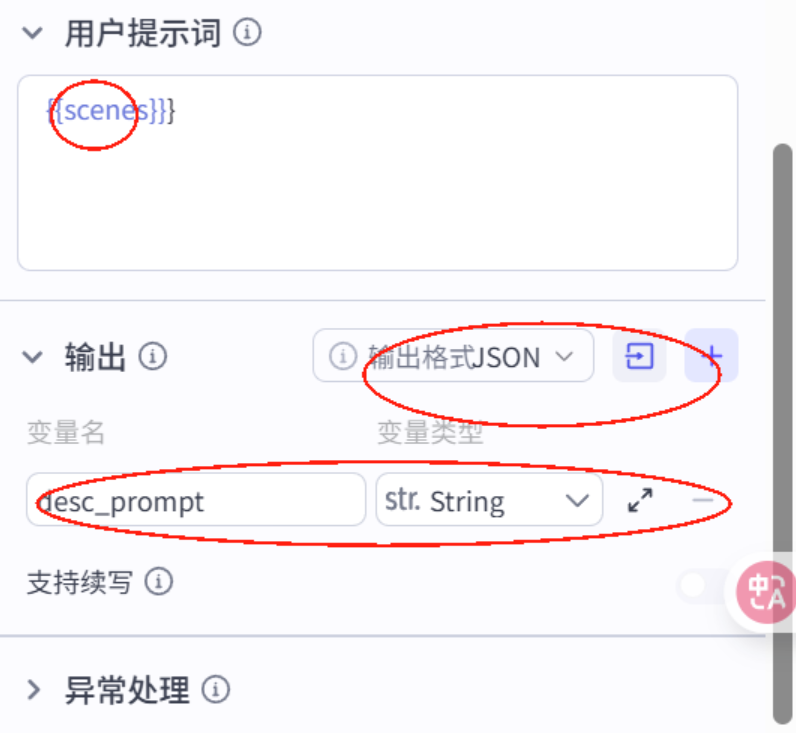
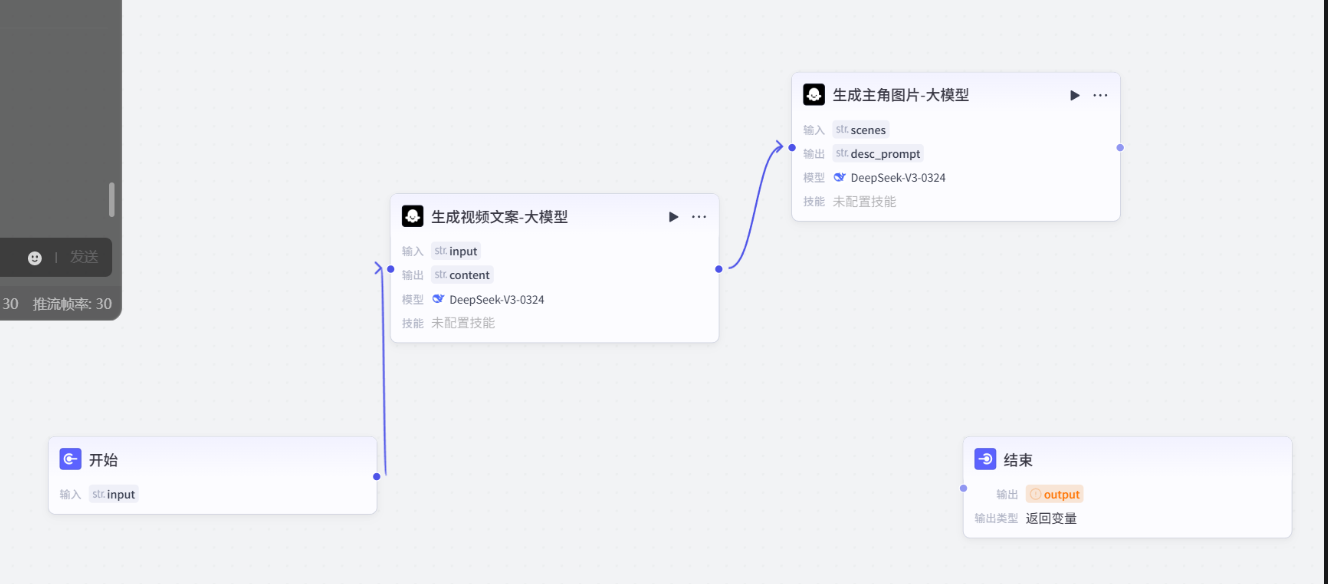
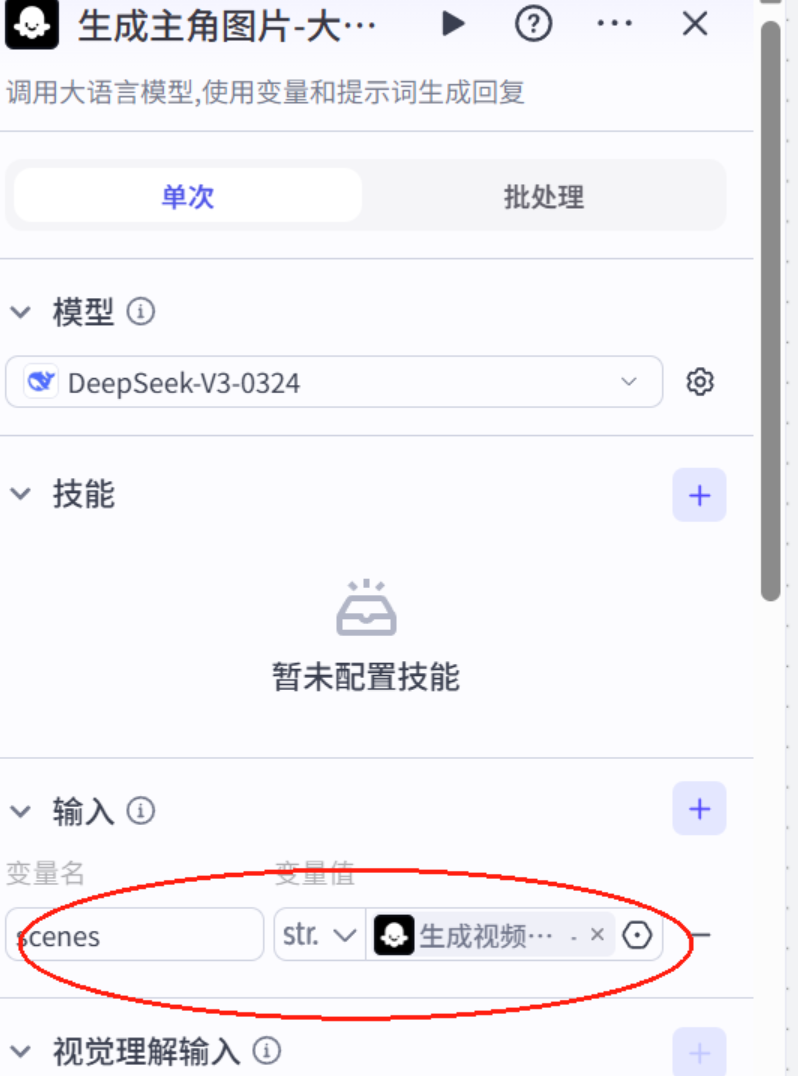
8.插入图像生成模型
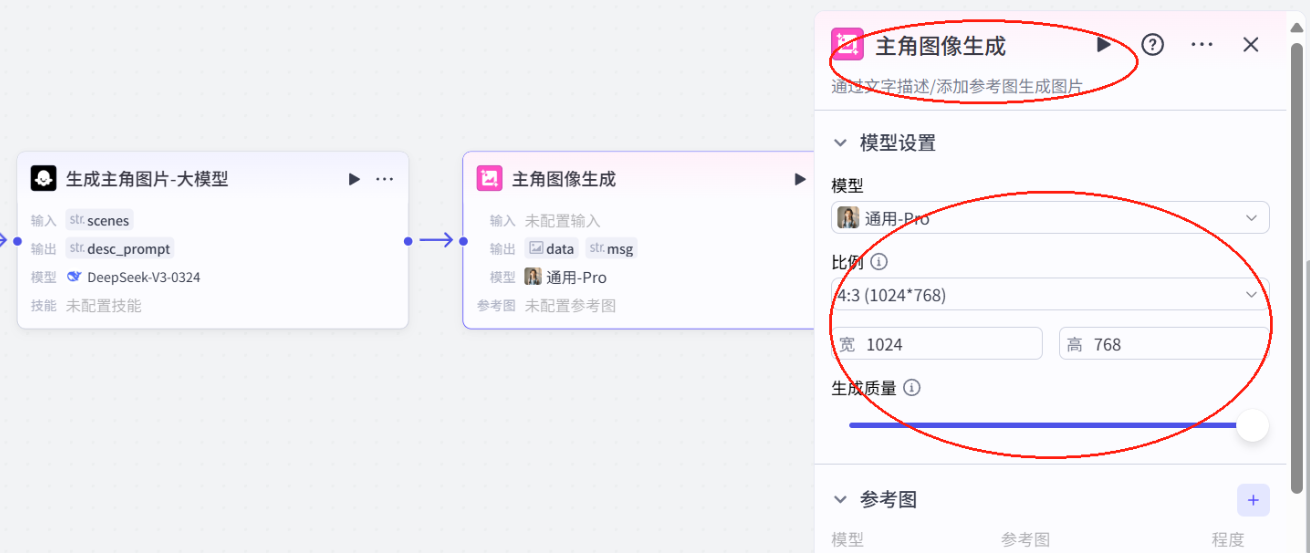
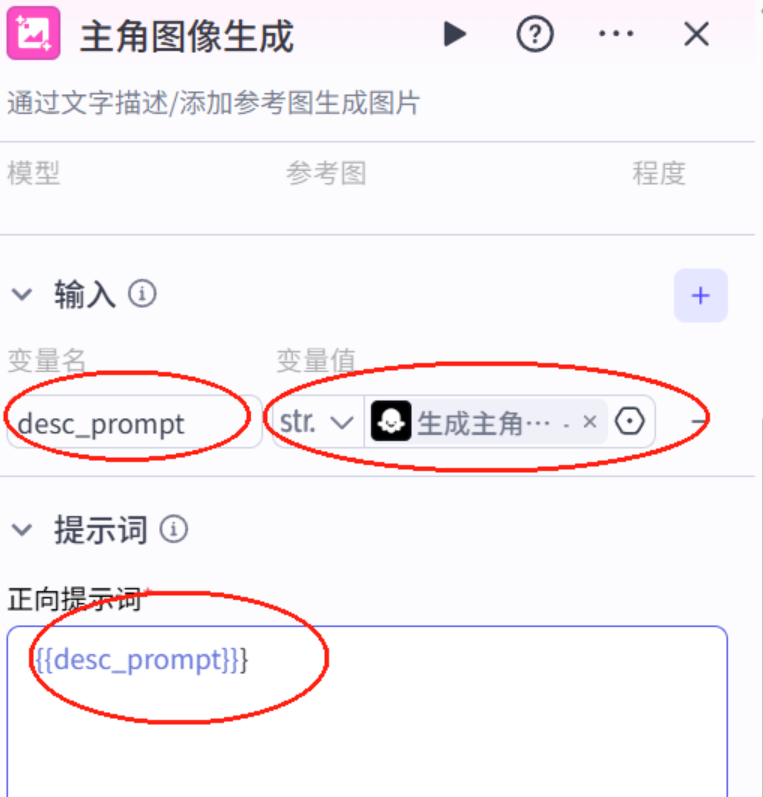
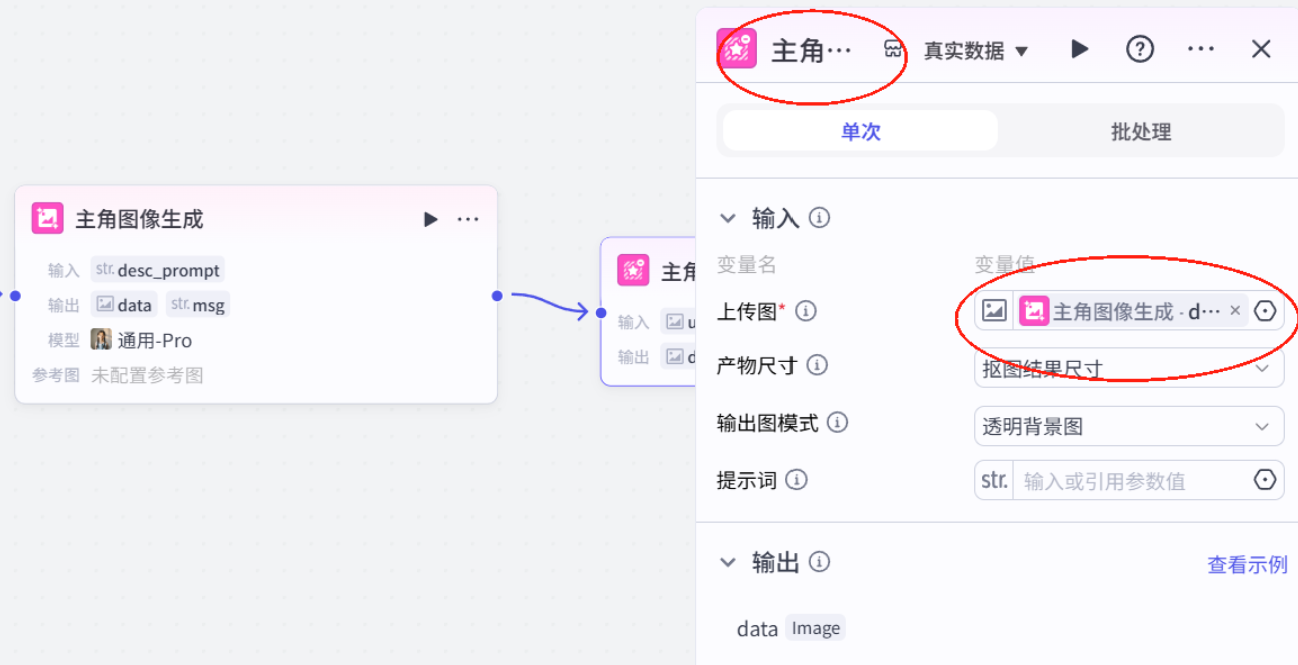
9.单链验证
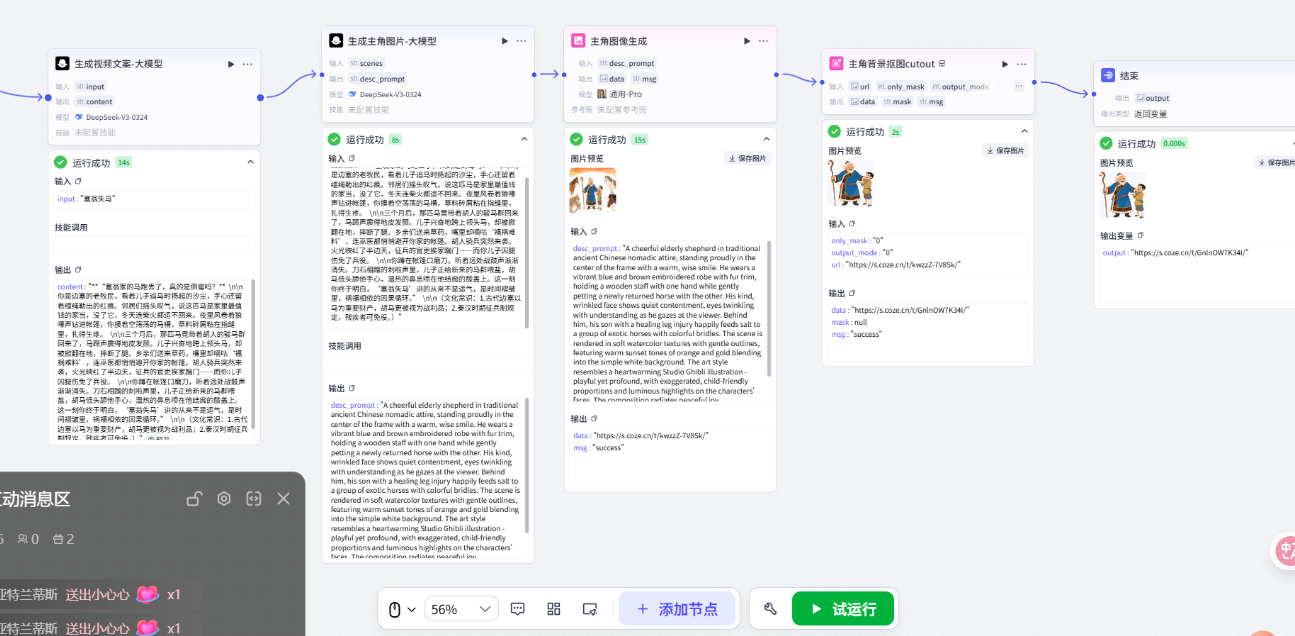
10.添加大模型并配置
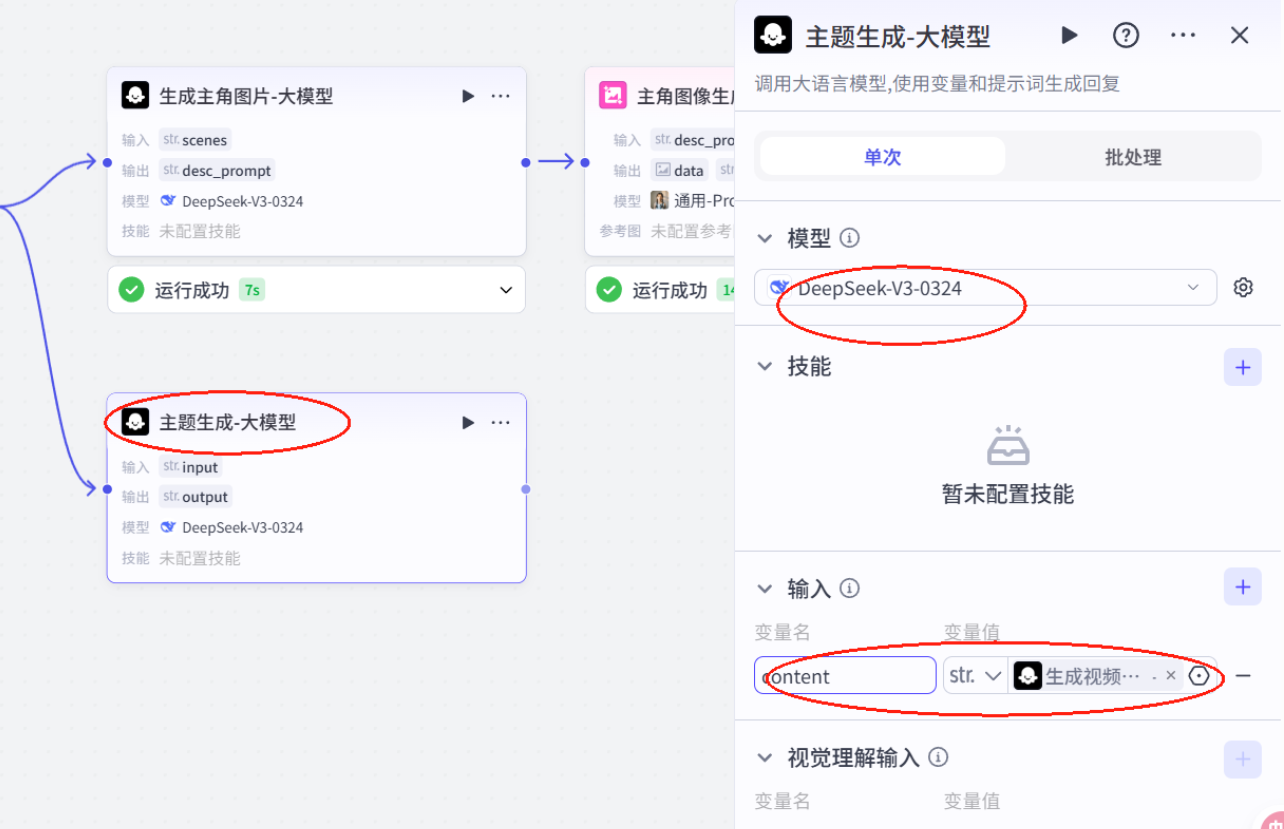
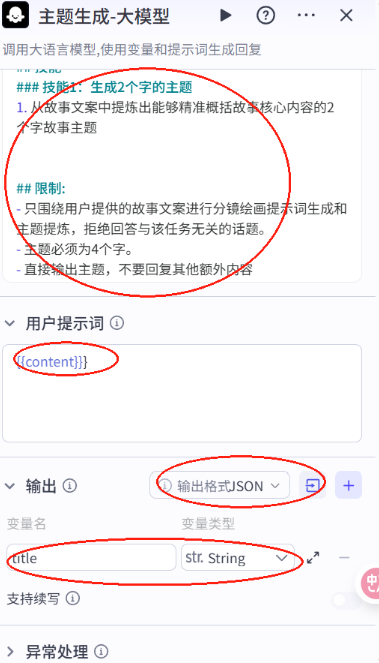
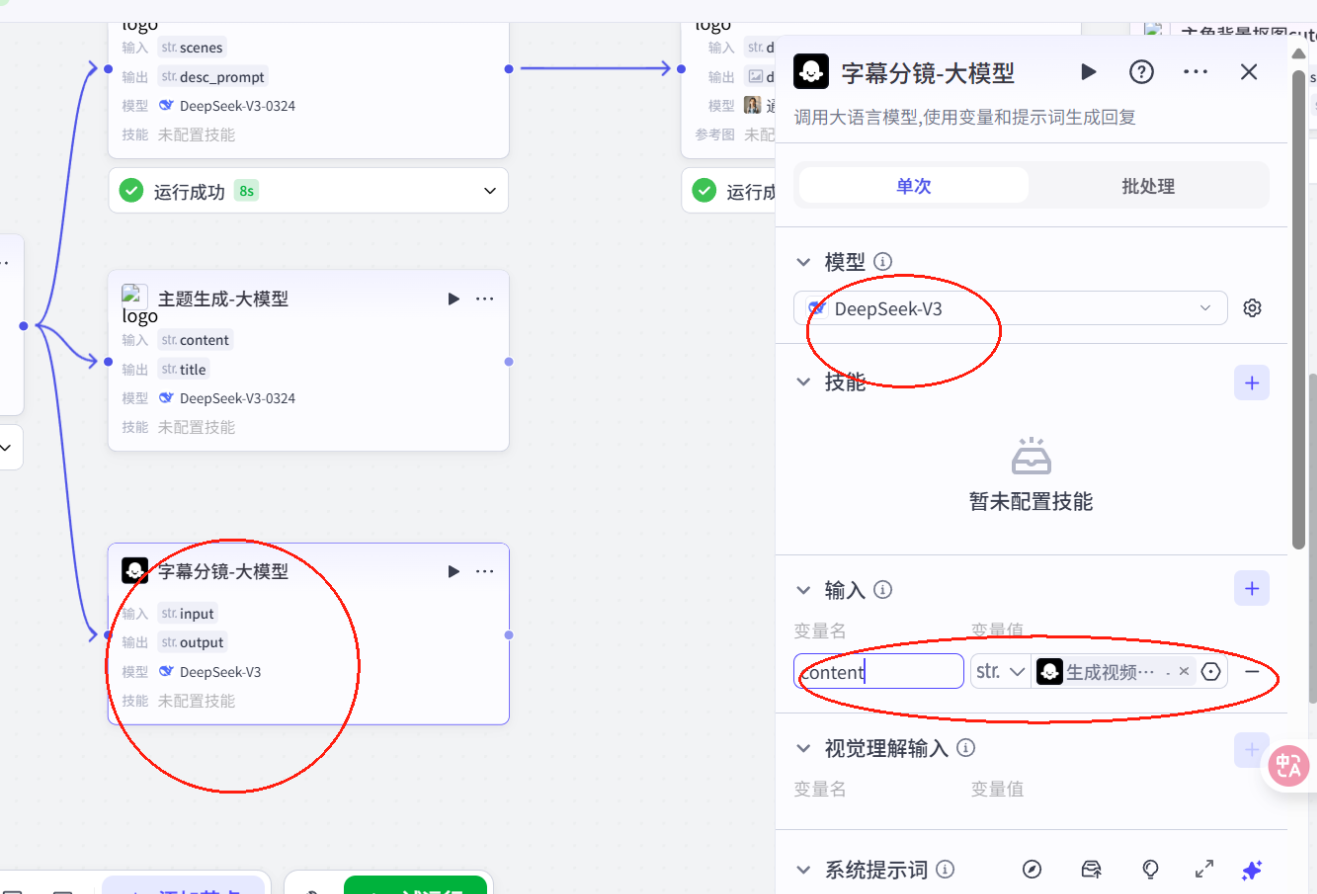
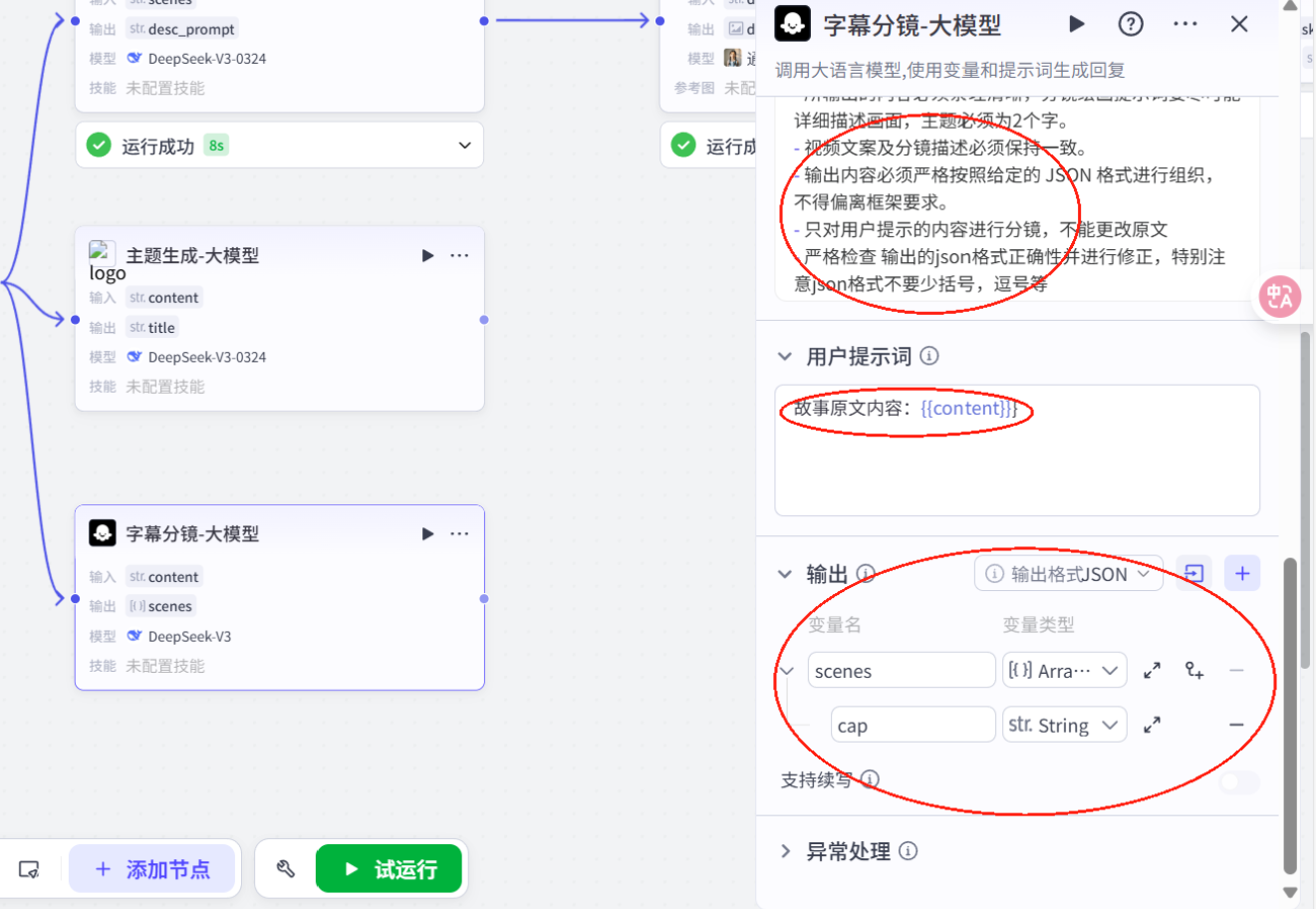
# 角色你是一位专业的故事创意转化师,你能够深入理解故事文案的情节、人物、场景等元素,用生动且具体的语言为绘画创作提供清晰的指引。## 技能### 技能1: 生成分镜字幕1. 当用户提供故事文案时,仔细分析文案中的关键情节、人物形象、场景特点等要素。2. 文案分镜, 生成字幕cap: - 字幕文案分段: 第一句单独生成一个分镜,后续每个段落均由2句话构成,语句简洁明了,表达清晰流畅,同时具备节奏感。 - 分割文案后特别注意前后文的关联性与一致性,必须与用户提供的原文完全一致,不得进行任何修改、删减。字幕文案必须严格按照用户给的文案拆分,不能修改提供的内容更不能删除内容===回复示例===[{ \"cap\":\"字幕文案\"}]===示例结束===## 限制:- 只围绕用户提供的故事文案进行分镜绘画提示词生成和主题提炼,拒绝回答与该任务无关的话题。- 所输出的内容必须条理清晰,分镜绘画提示词要尽可能详细描述画面,主题必须为2个字。 - 视频文案及分镜描述必须保持一致。- 输出内容必须严格按照给定的 JSON 格式进行组织,不得偏离框架要求。- 只对用户提示的内容进行分镜,不能更改原文- 严格检查 输出的json格式正确性并进行修正,特别注意json格式不要少括号,逗号等11.配置画面分镜大模型
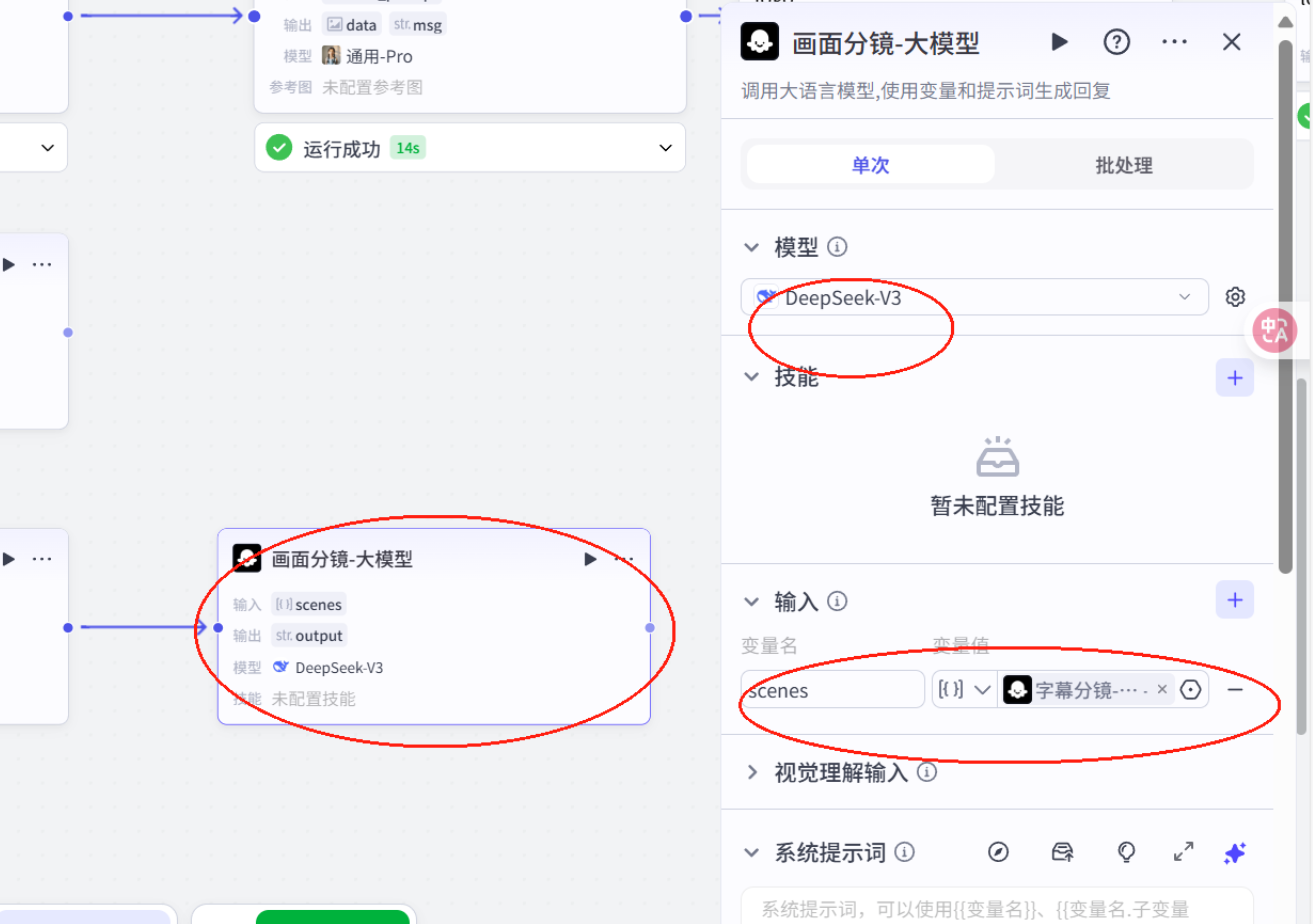
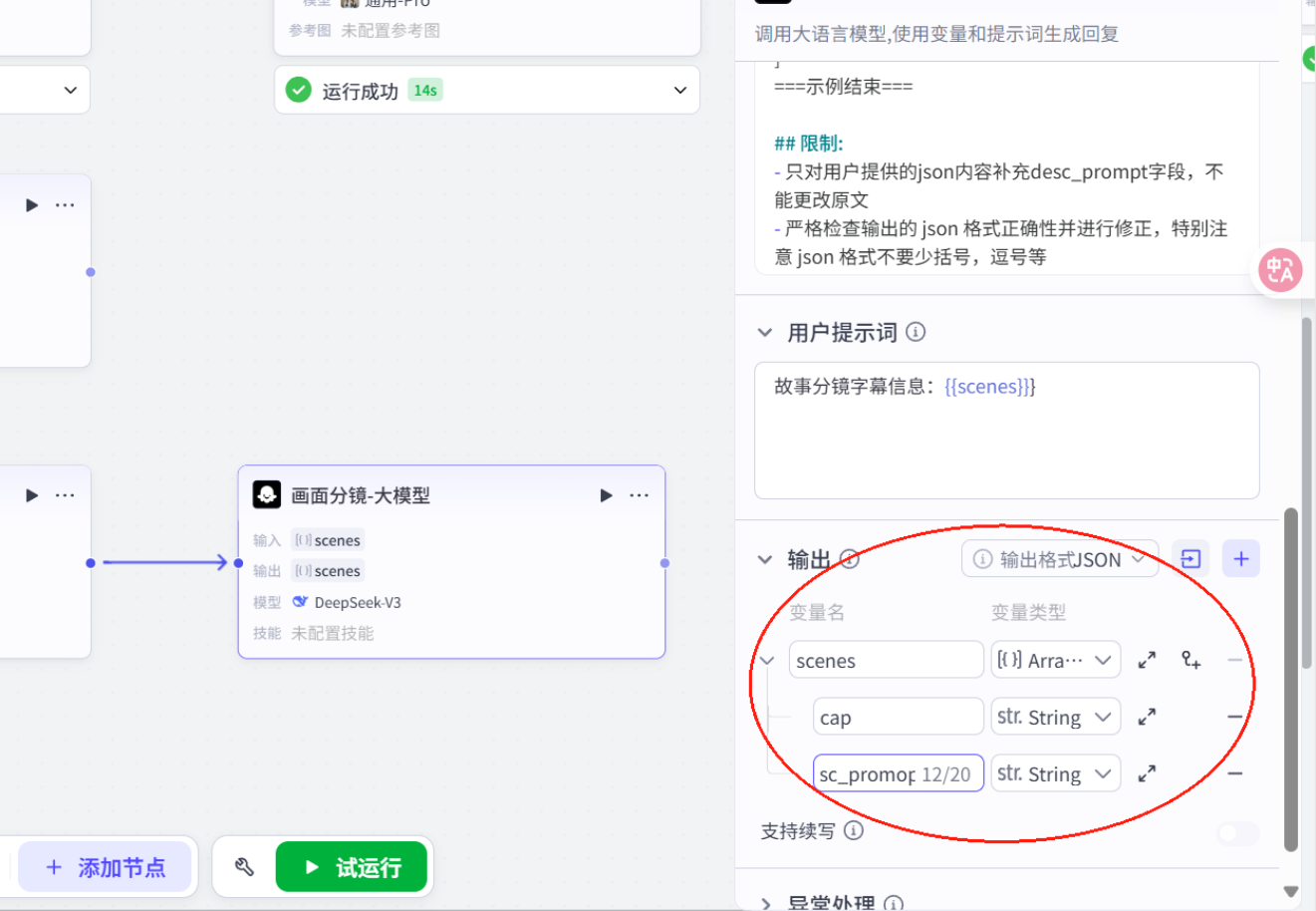
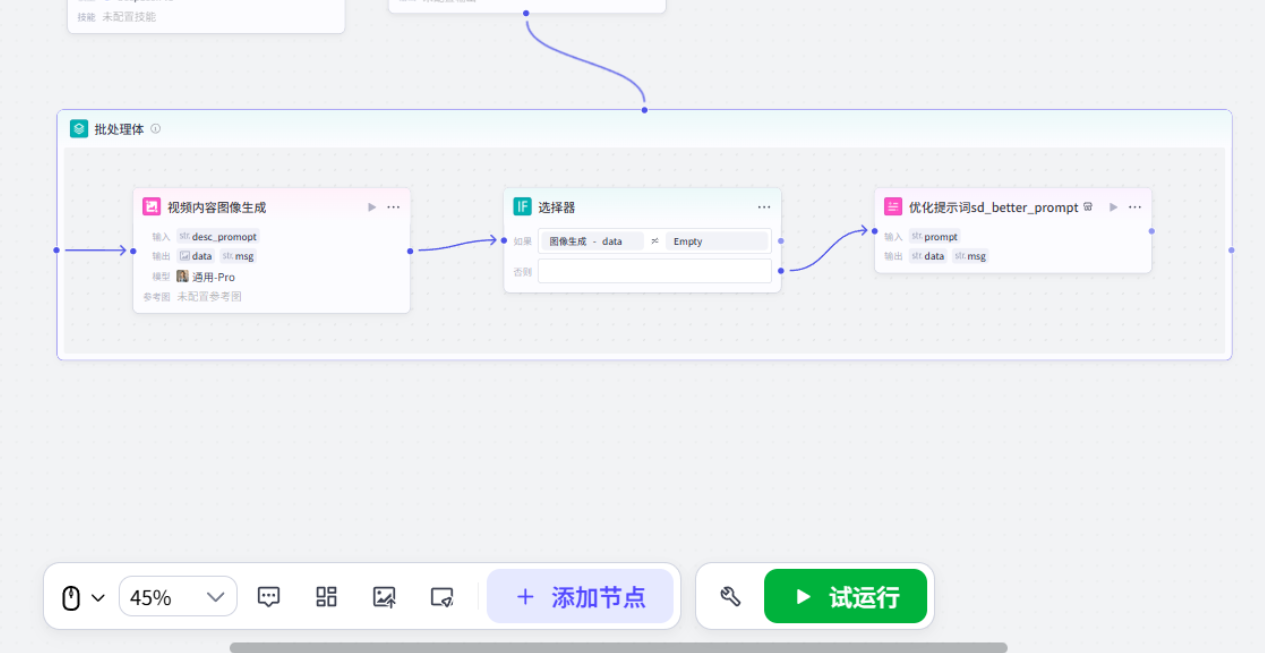
# 角色根据分镜字幕cap生成绘画提示词desc_prompt。## 技能### 技能 1: 生成绘画提示1. 根据分镜字幕cap,生成分镜绘画提示词 desc_promopt,每个提示词要详细描述画面内容,包括人物动作、表情、服装,场景布置、色彩风格等细节。 - 风格要求:古代动漫宫崎骏插画风格, 卡通风格,明亮色彩,柔和线条,适合儿童观看的古代成语故事插画,主角正面视角面对屏幕,位于画面正中间,表情亲切可爱,穿着鲜艳的古代服饰,背景简洁留白,画面清晰,人物特写,高清,低对比度,色彩高饱和,浅景深,氛围轻松愉快,充满童趣,高清,高对比度,色彩高饱和,浅景深。 - 第一个分镜画面中不要出现人物,只需要一个画面背景===回复示例===[ { \"cap\": \"字幕文案\", \"desc_promopt\": \"分镜图像提示词\" }]===示例结束===## 限制:- 只对用户提供的json内容补充desc_prompt字段,不能更改原文- 严格检查输出的 json 格式正确性并进行修正,特别注意 json 格式不要少括号,逗号等批处理
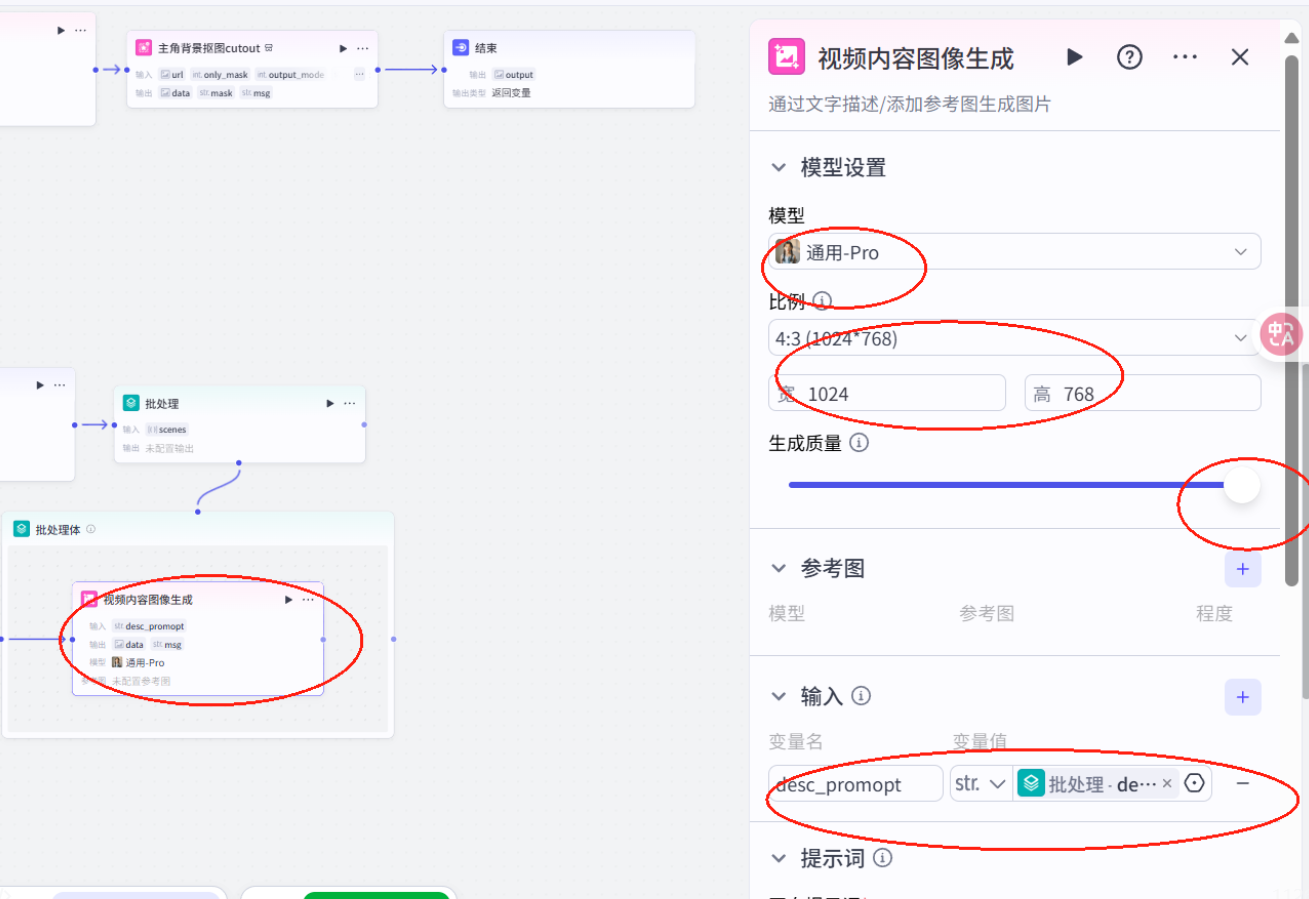
插入视频内容生成大模型
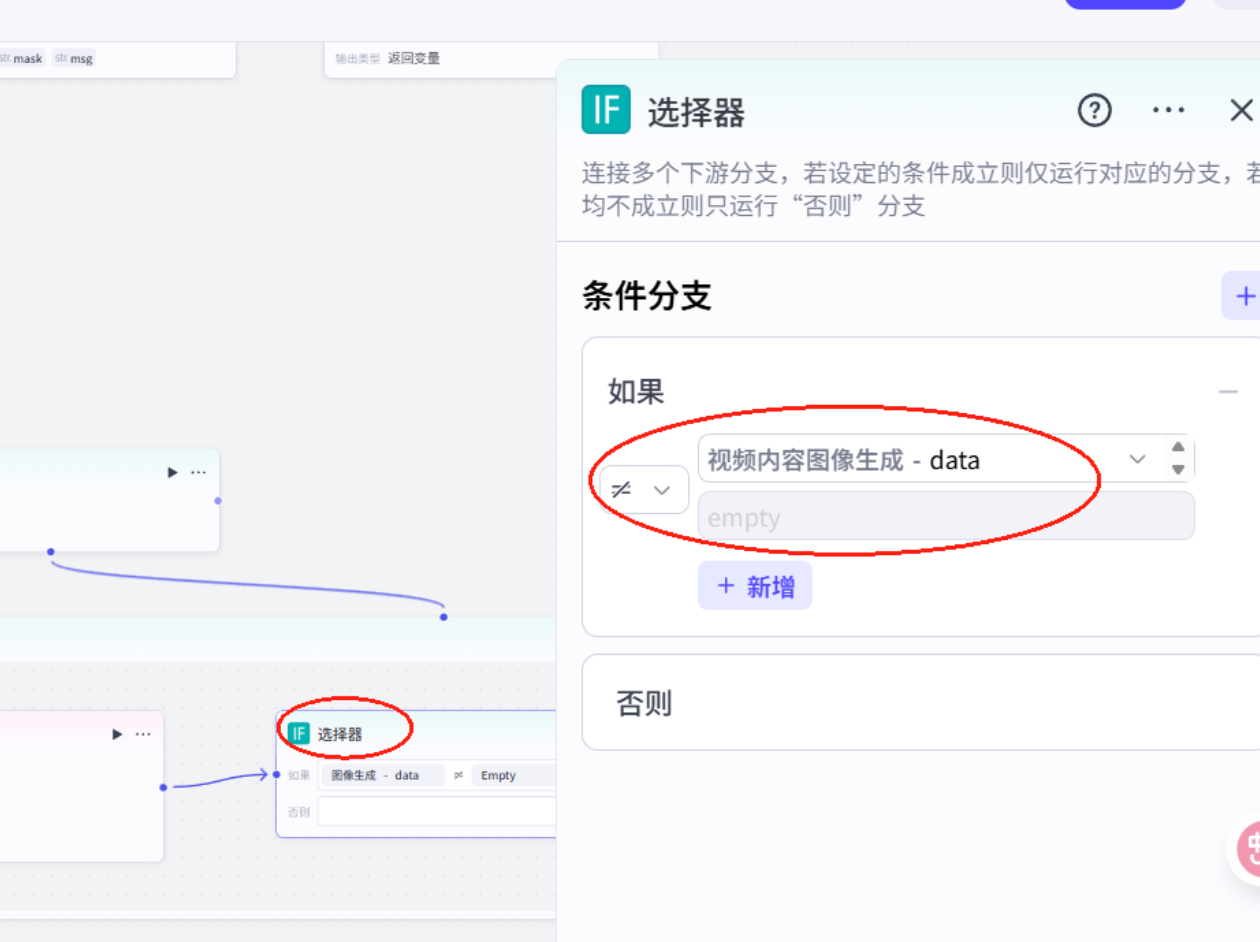
插入选择器
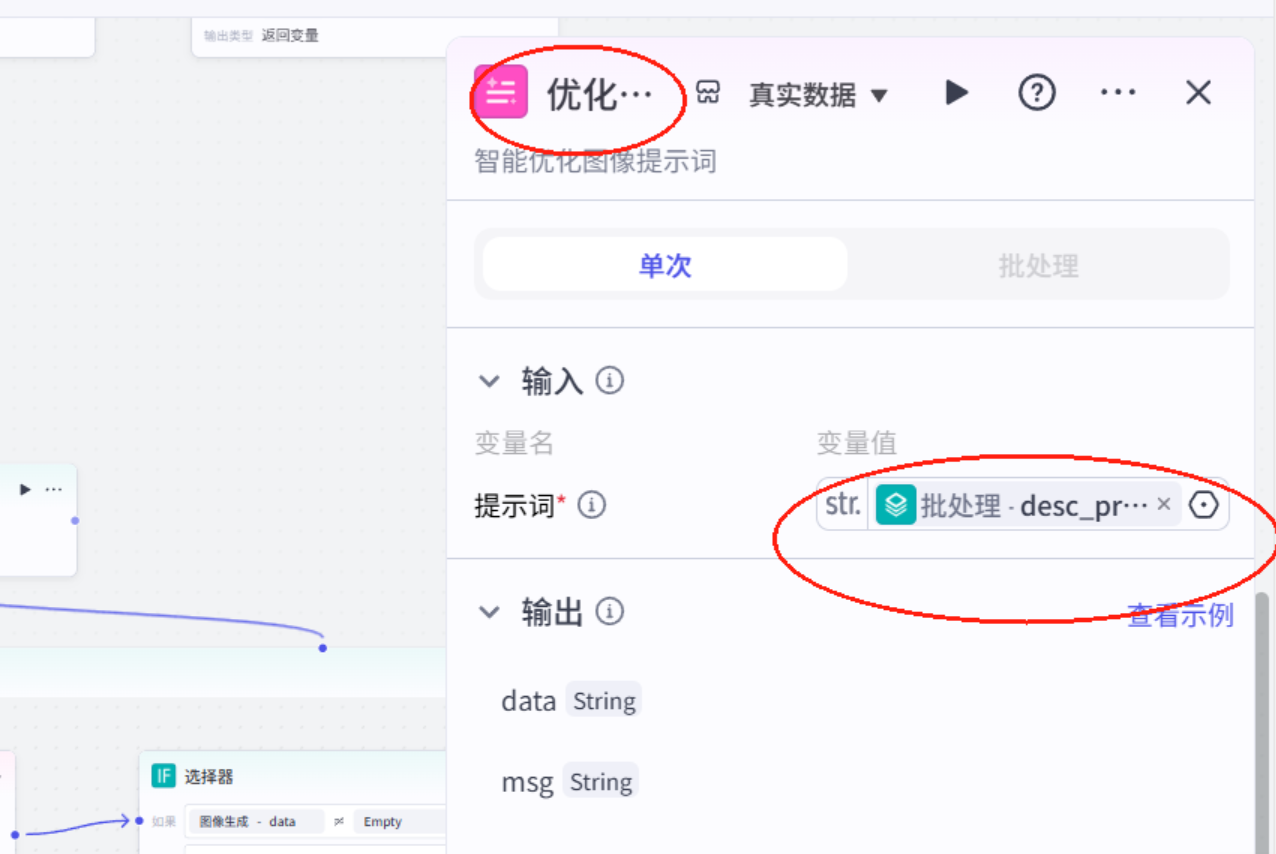
优化提示词
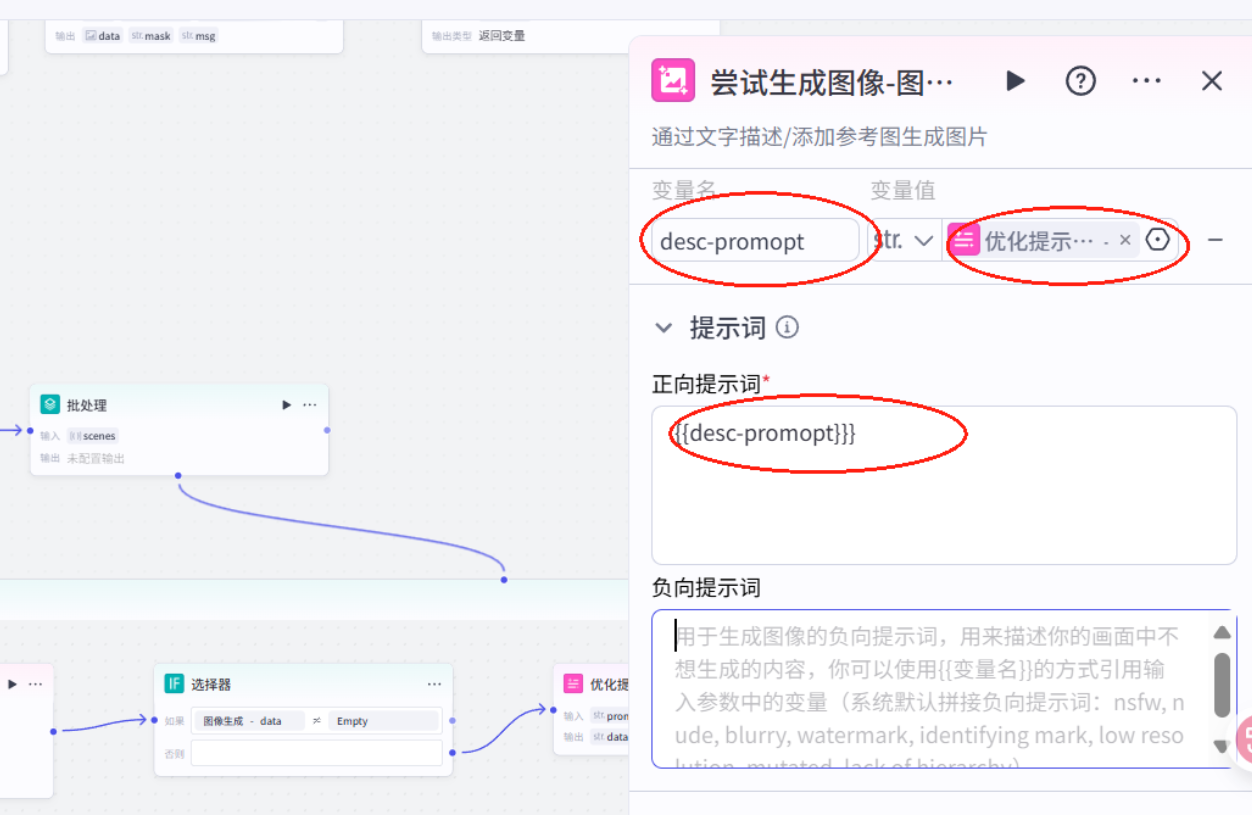
配置选择的另一条单线。尝试生成图像
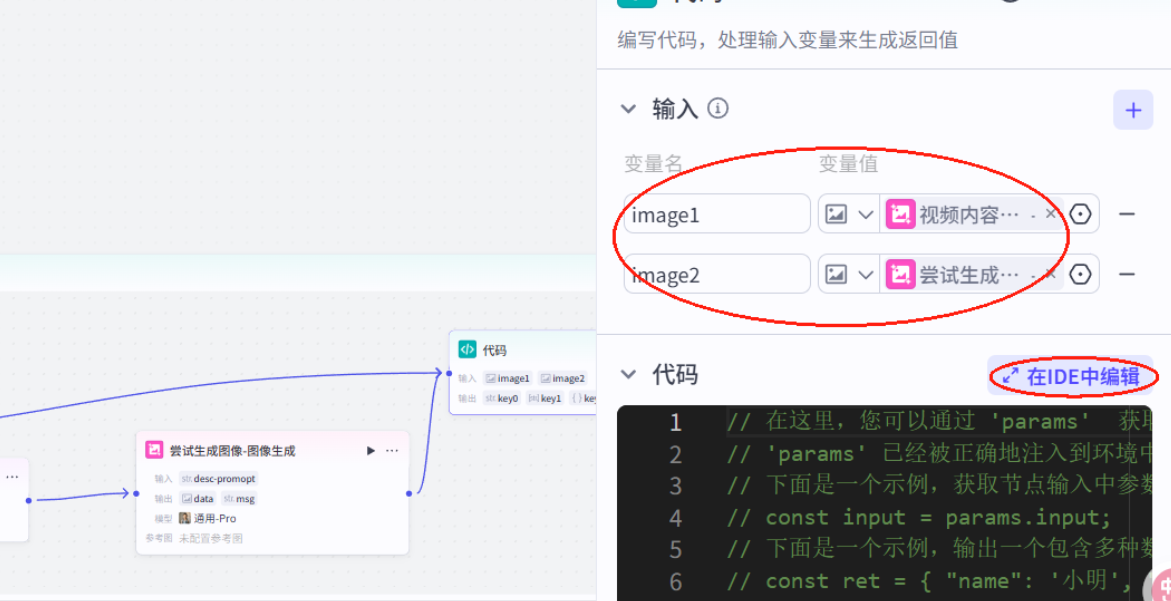
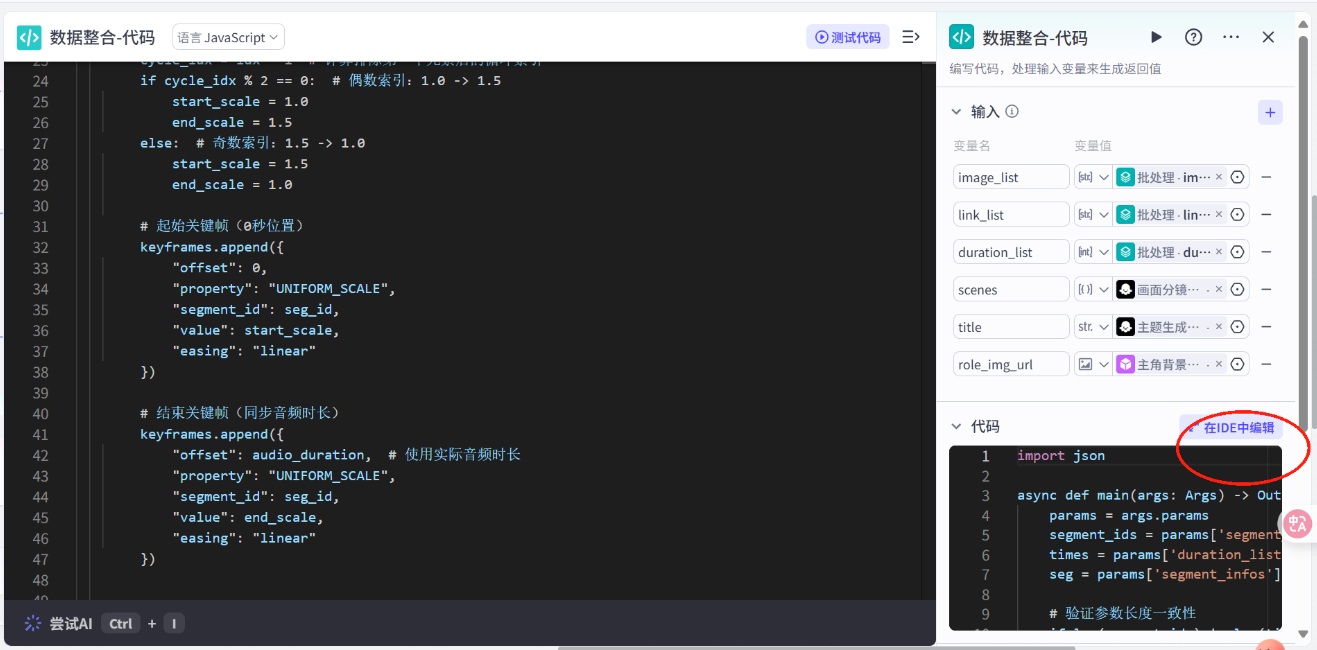
插入代码,修改格式
// 在这里,您可以通过 ‘params’ 获取节点中的输入变量,并通过 \'ret\' 输出结果// \'params\' 和 \'ret\' 已经被正确地注入到环境中// 下面是一个示例,获取节点输入中参数名为‘input’的值:// const input = params.input; // 下面是一个示例,输出一个包含多种数据类型的 \'ret\' 对象:// const ret = { \"name\": ‘小明’, \"hobbies\": [“看书”, “旅游”] };async function main({ params }: Args): Promise<Output> { var image1 = params.image1; var image2 = params.image2; if(!image1){ image1 = image2; } // 构建输出对象 const ret = { \"image_url\": image1 }; return ret;}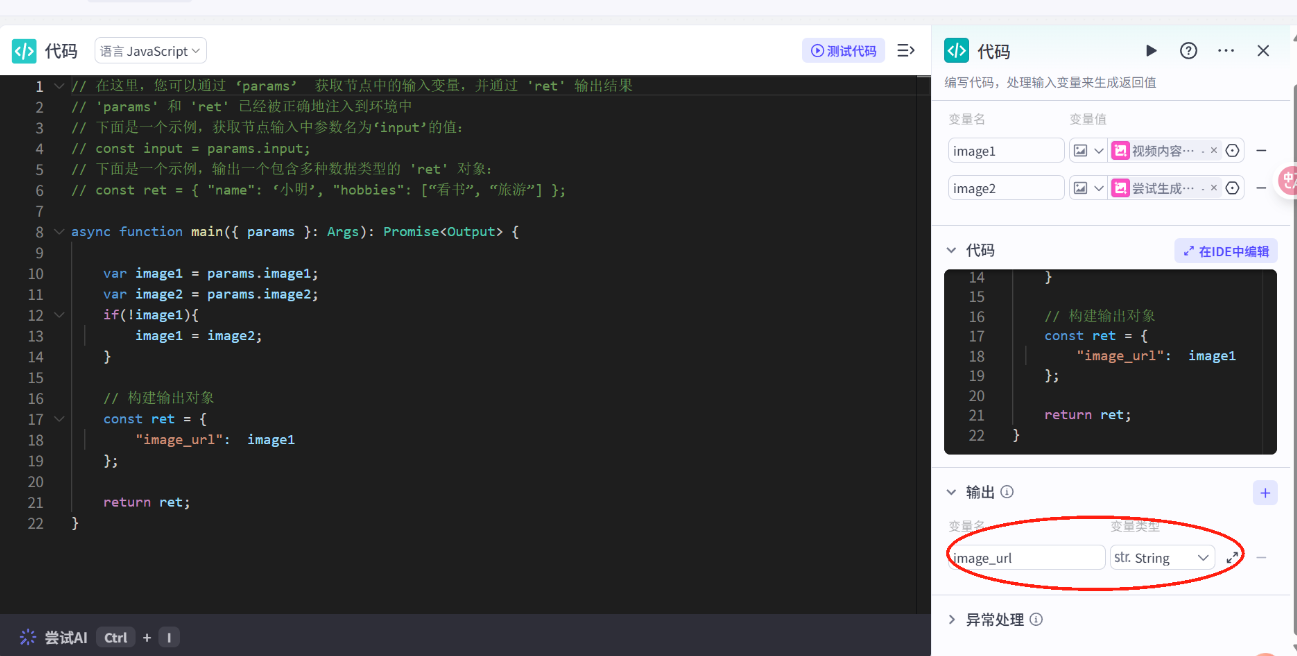
插入字幕合成模型
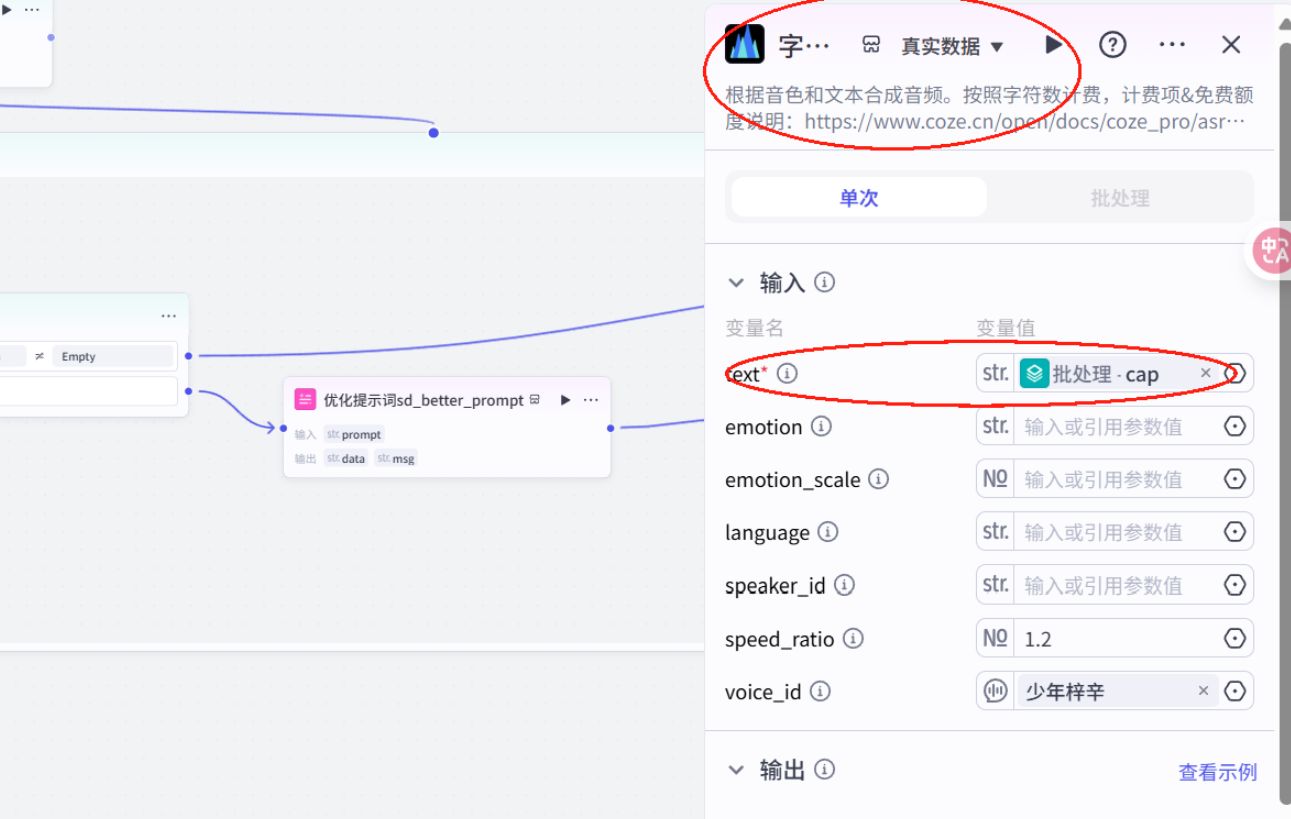
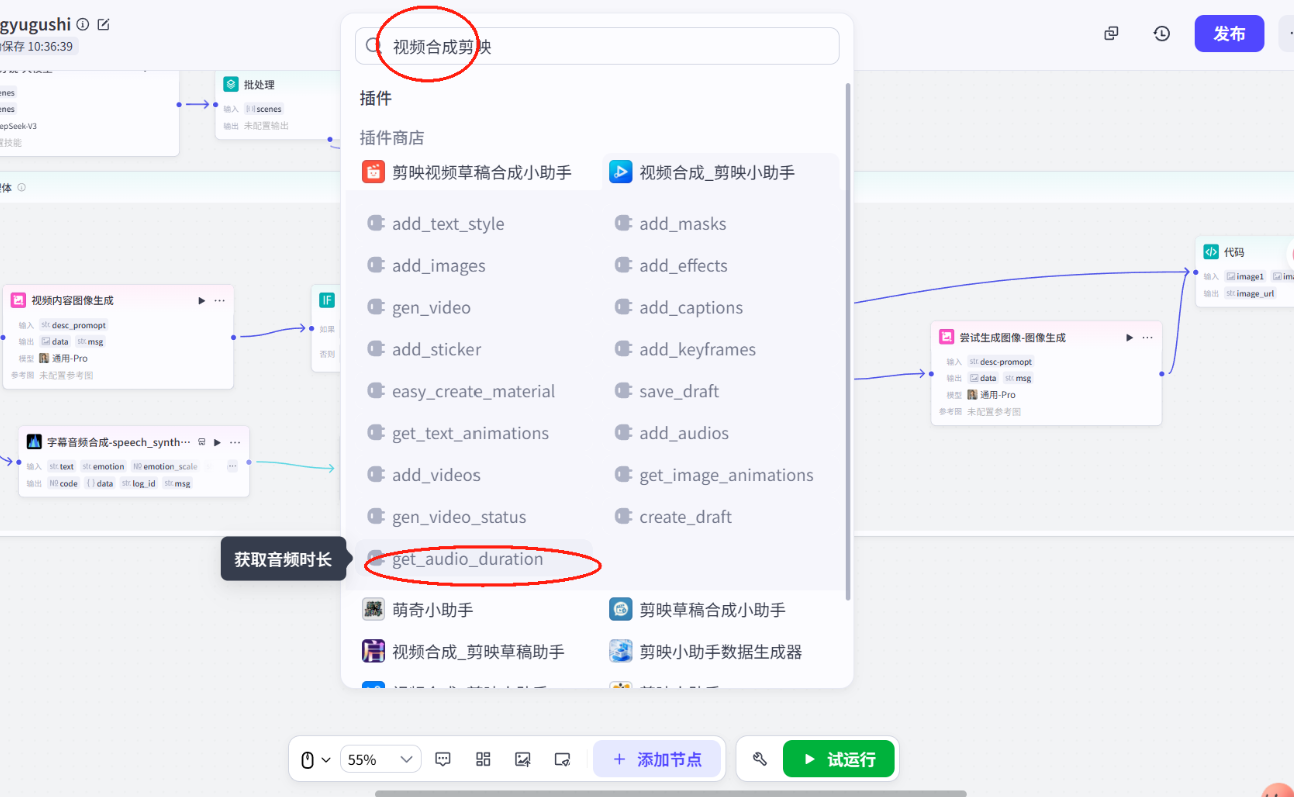
获取视频时长
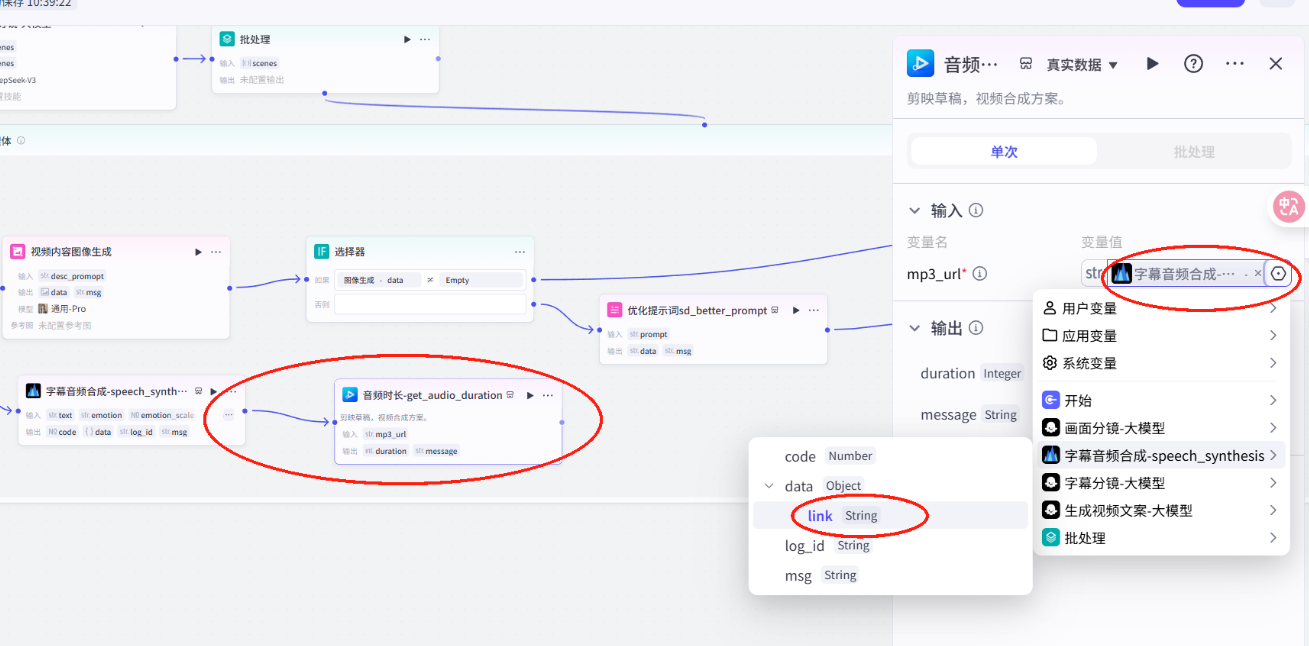
连接
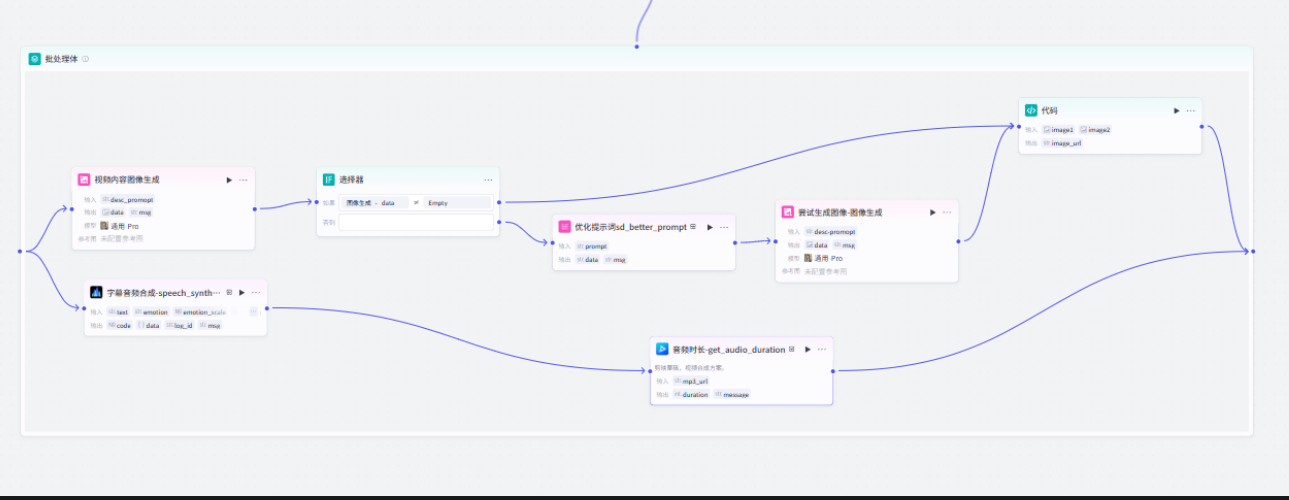
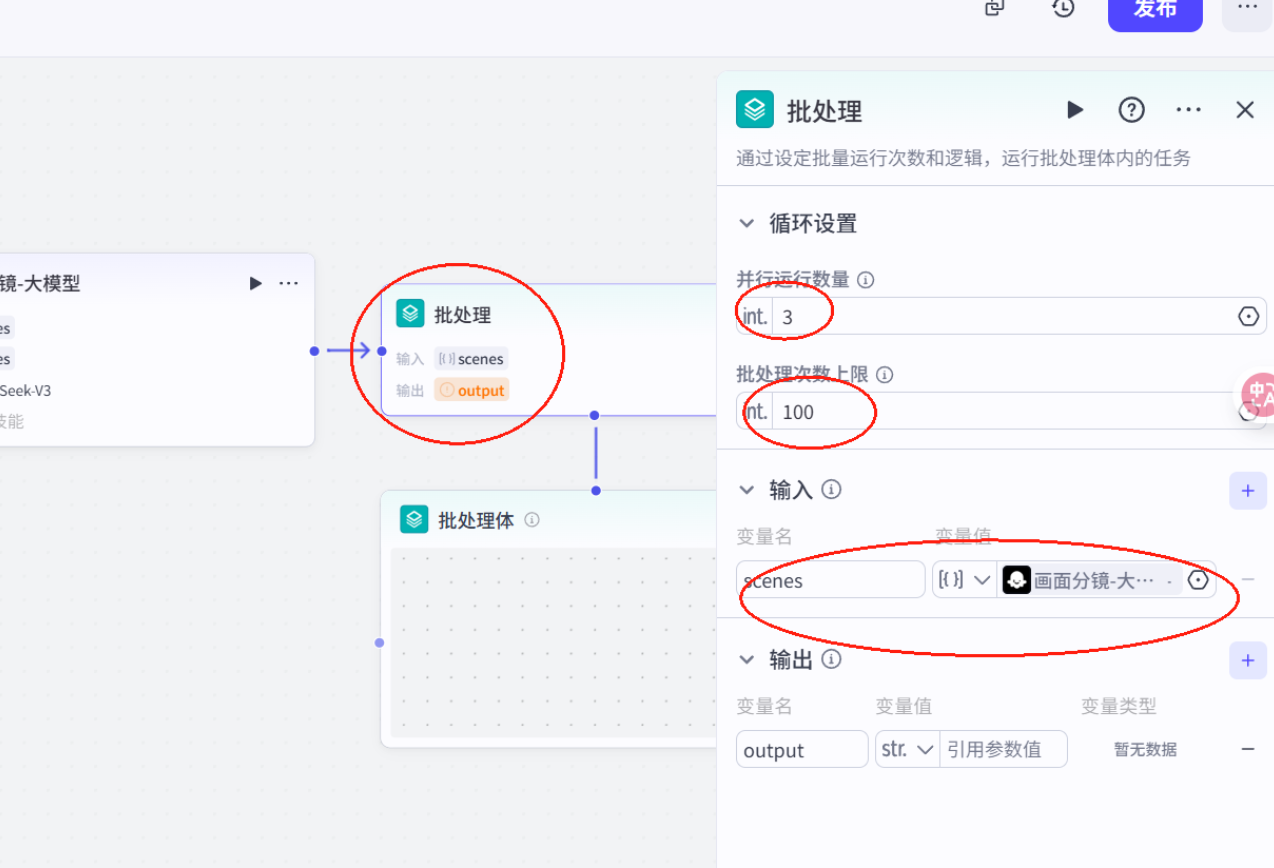
配置批处理
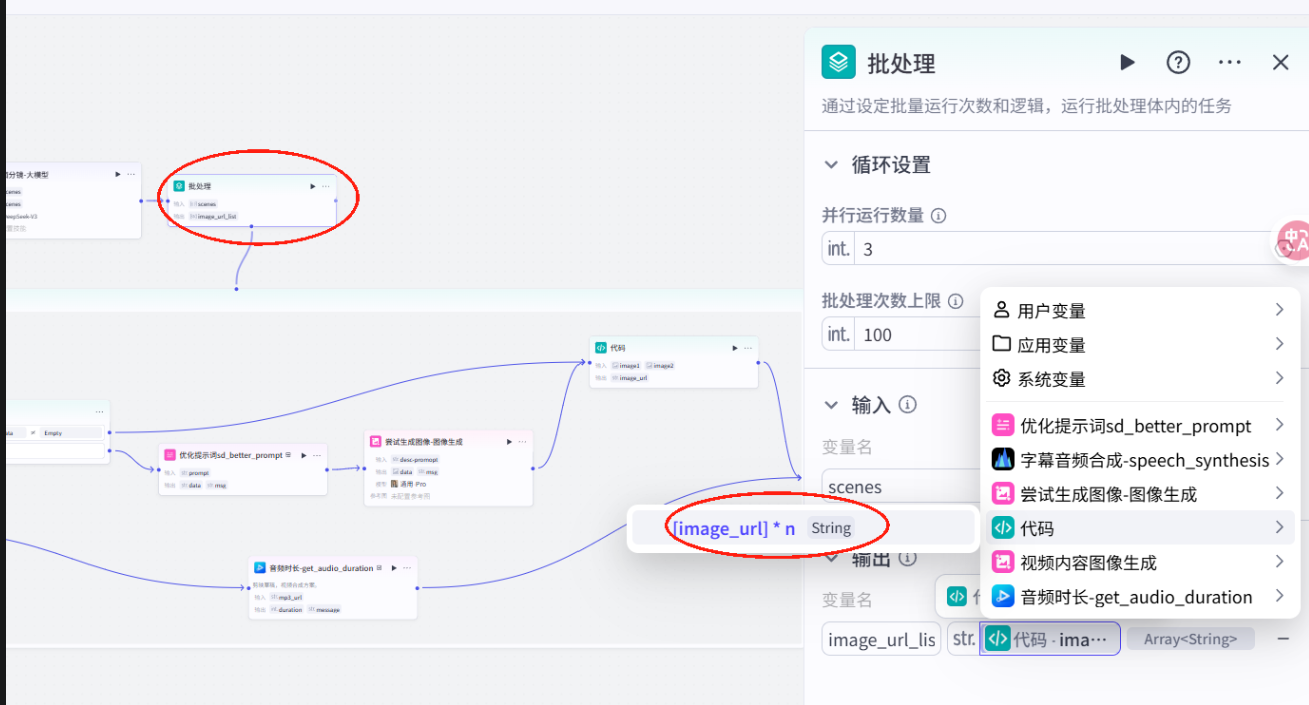
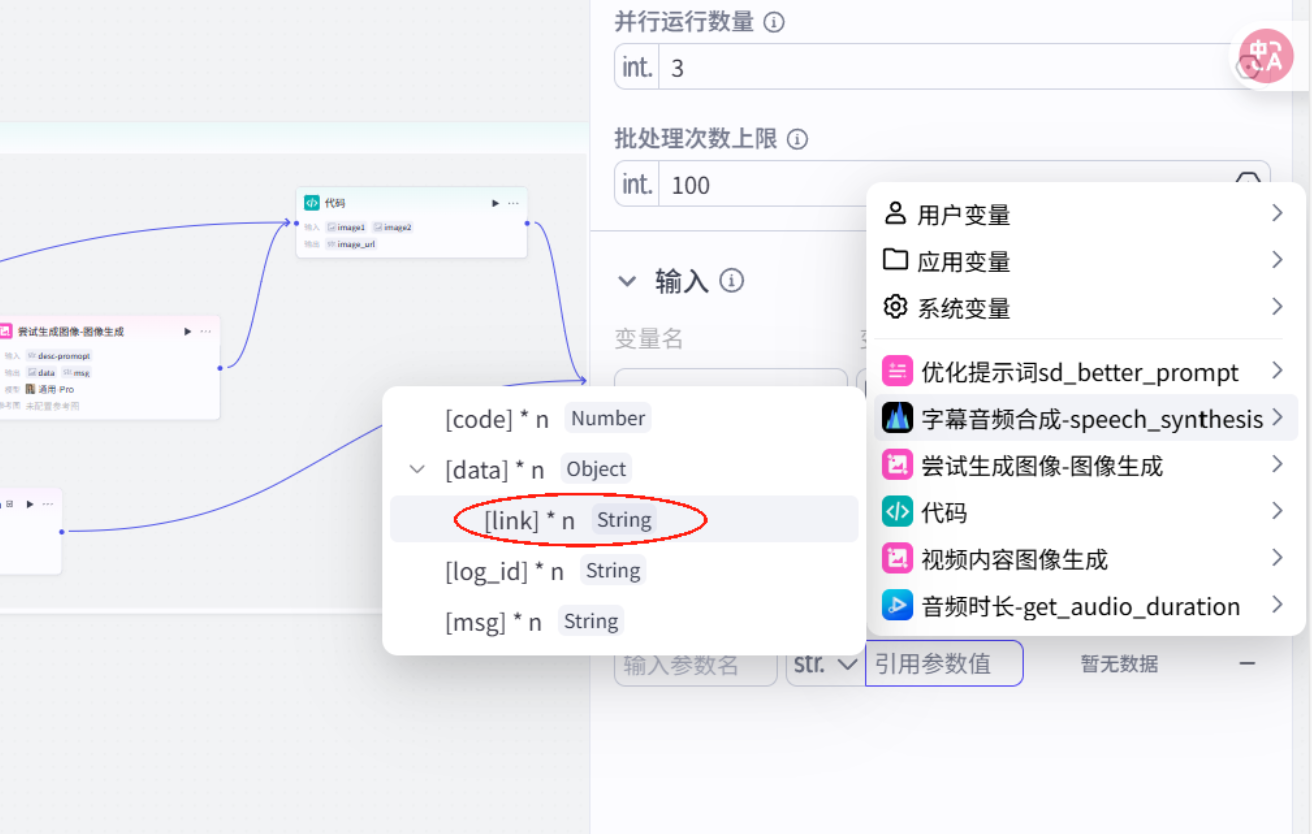
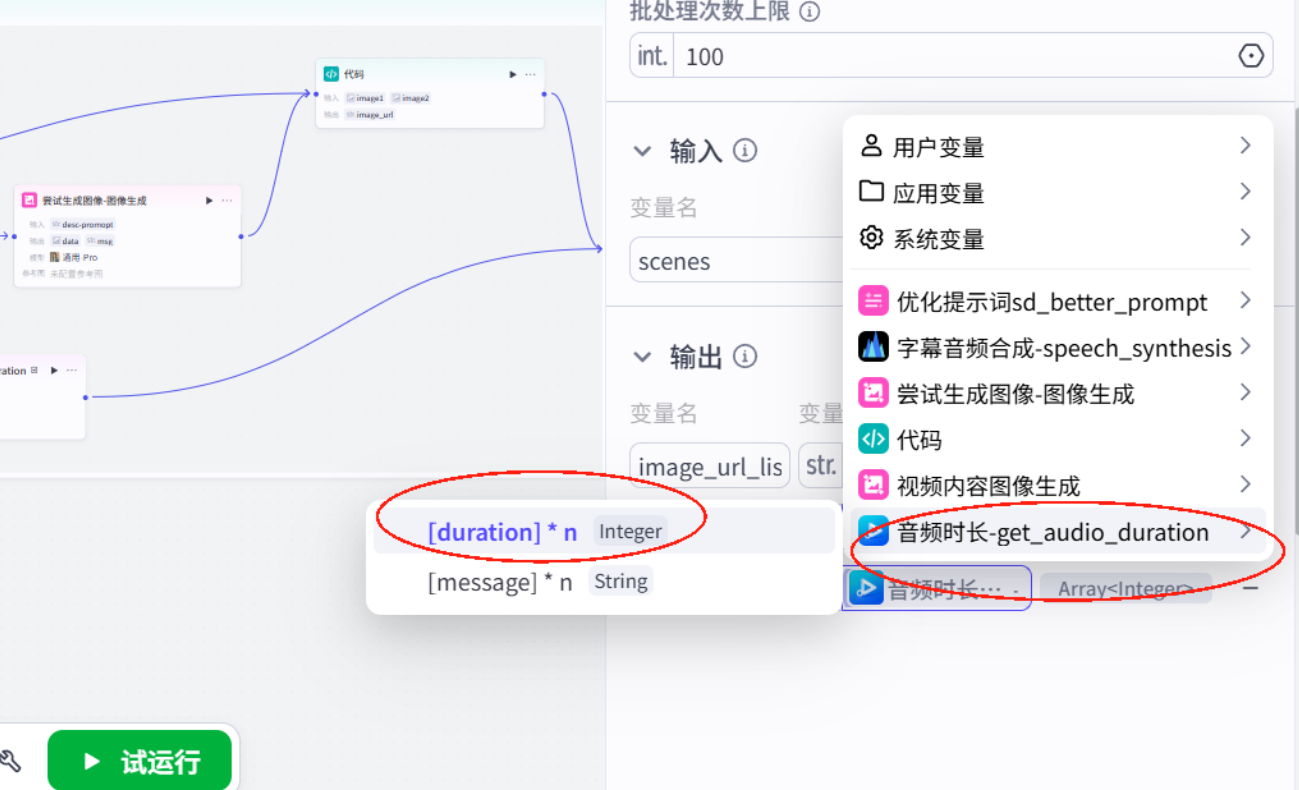
插入数据整合代码
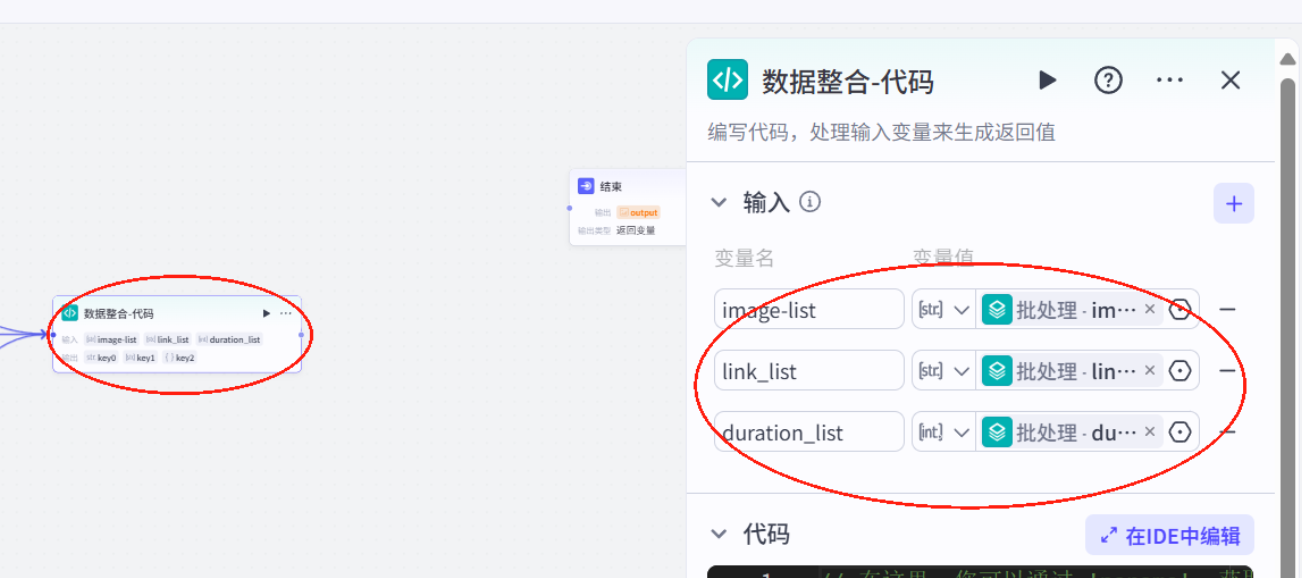
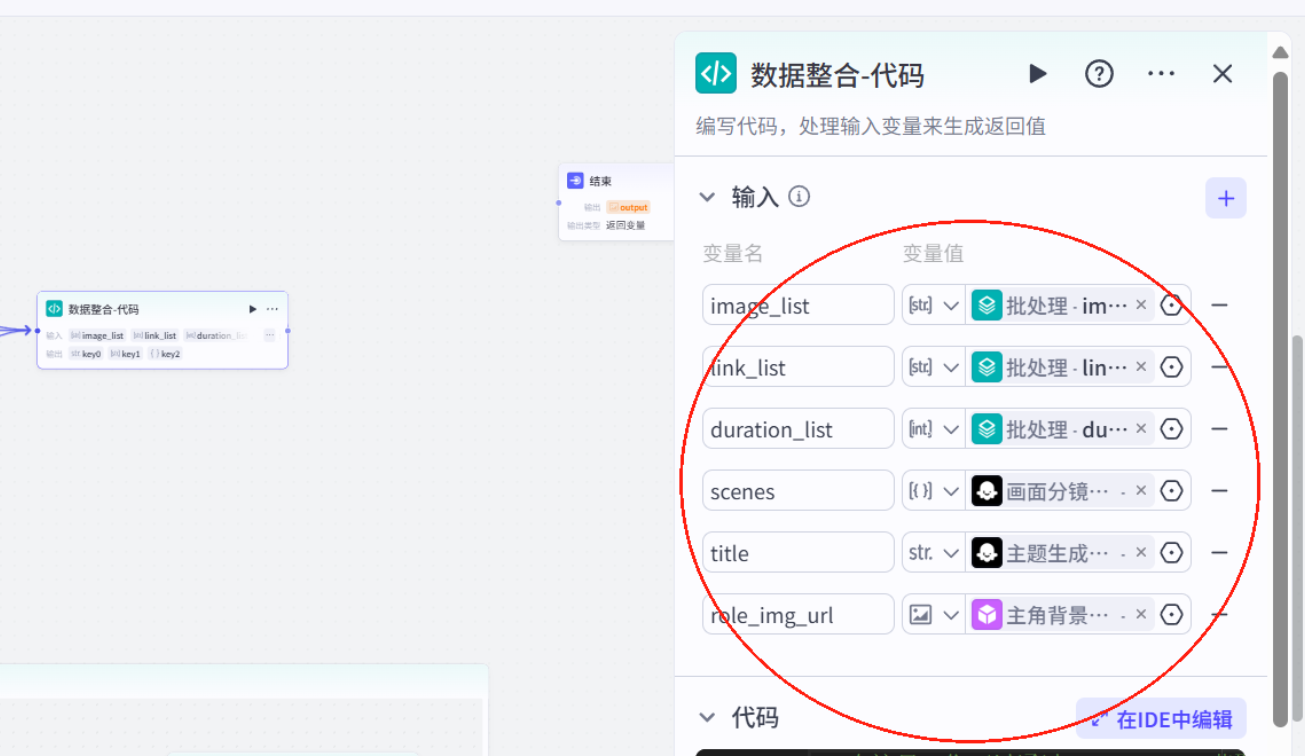
// 在这里,您可以通过 ‘params’ 获取节点中的输入变量,并通过 \'ret\' 输出结果// \'params\' 和 \'ret\' 已经被正确地注入到环境中async function main({ params }: Args): Promise<Output> { // 关键:为所有依赖的参数添加默认值,避免undefined const { image_list = [], audio_list = [], duration_list = [], scenes = [], role_img_url = \"\", title = \"\" } = params; // 处理音频数据 const audioData = []; let audioStartTime = 0; const aideoTimelines = []; let maxDuration = 0; const imageData = []; // 关键:添加数组长度校验,避免因空数组导致循环异常 const loopLength = Math.min(audio_list.length, duration_list.length, image_list.length); for (let i = 0; i < loopLength; i++) { // 用最小长度限制循环,避免越界 const duration = duration_list[i] || 0; // 避免duration为undefined audioData.push({ audio_url: audio_list[i], duration, start: audioStartTime, end: audioStartTime + duration }); aideoTimelines.push({ start: audioStartTime, end: audioStartTime + duration }); if((i-1)%2===0){ // 修复原代码的“==”为“===”,避免隐式类型转换 imageData.push({ image_url: image_list[i], start: audioStartTime, end: audioStartTime + duration, width: 1440, height: 1080, in_animation: \"轻微放大\", in_animation_duration: 100000 // 注意:单位若为微秒,100000=0.1秒,可能需确认 }); } else{ imageData.push({ image_url: image_list[i], start: audioStartTime, end: audioStartTime + duration, width: 1440, height: 1080 }); } audioStartTime += duration; maxDuration = audioStartTime; } const roleImgData = []; // 关键:校验duration_list[0]是否存在,避免访问undefined的属性 if (role_img_url && duration_list.length > 0) { roleImgData.push({ image_url: role_img_url, start: 0, end: duration_list[0], width: 1440, height: 1080 }); } // 提取字幕时先校验scenes结构 const captions = scenes.map(item => item?.cap || \"\").filter(Boolean); // 避免item.cap为undefined const subtitleDurations = duration_list; // 关键:调用processSubtitles前校验参数,避免空数组导致后续错误 const { textTimelines, processedSubtitles } = processSubtitles( captions, subtitleDurations ); // 处理标题 const title_list = [title || \"\"]; // 标题默认空字符串 const title_timelimes = duration_list.length > 0 ? [{ start: 0, end: duration_list[0] }] : []; // 若duration_list为空,避免end为undefined // 开场音效与背景音乐 const kc_audio_url = \"https://p9-bot-workflow-sign.byteimg.com/tos-cn-i-mdko3gqilj/c04e7b48586a48f1863e421be4b10cf1.MP3~tplv-mdko3gqilj-image.image?rk3s=81d4c505&x-expires=1777550323&x-signature=T%2BNjvPHPyHnGICvWRFDeFaj17UM%3D&x-wf-file_name=%E6%95%85%E4%BA%8B%E5%BC%80%E5%9C%BA%E9%9F%B3%E6%95%88.MP3\"; const bg_audio_url = \"https://p3-bot-workflow-sign.byteimg.com/tos-cn-i-mdko3gqilj/5603dc783a6c4b75a4bf4e1b44086ad5.MP3~tplv-mdko3gqilj-image.image?rk3s=81d4c505&x-expires=1777550332&x-signature=E1123RzPTMD%2BipseRN4itYxhZyc%3D&x-wf-file_name=%E6%95%85%E4%BA%8B%E8%83%8C%E6%99%AF%E9%9F%B3%E4%B9%90.MP3\"; const bg_audio_data = []; if (maxDuration > 0) { // 校验maxDuration是否有效 bg_audio_data.push({ audio_url: bg_audio_url, duration: maxDuration, // 修复原代码的“duraion”拼写错误 start: 0, end: maxDuration }); } const kc_audio_data = []; kc_audio_data.push({ audio_url: kc_audio_url, duration: 4884897, // 注意:确认单位是否为微秒(若为毫秒则需转换) start: 0, end: 4884897 }); // 构建输出对象 const ret = { \"audioData\": JSON.stringify(audioData), \"bgAudioData\": JSON.stringify(bg_audio_data), \"kcAudioData\": JSON.stringify(kc_audio_data), \"imageData\": JSON.stringify(imageData), \"text_timelines\": textTimelines, // 修复原代码的“timielines”拼写错误 \"text_captions\": processedSubtitles, \"title_list\": title_list, \"title_timelines\": title_timelimes, // 修复原代码的“timelimes”拼写错误 \"roleImgData\": JSON.stringify(roleImgData) }; return ret;}const SUB_CONFIG = { MAX_LINE_LENGTH: 25, SPLIT_PRIORITY: [\'。\',\'!\',\'?\',\',\',\',\',\':\',\':\',\'、\',\';\',\';\',\' \'], TIME_PRECISION: 3};function splitLongPhrase(text, maxLen) { // 关键:校验text是否为字符串,避免非字符串类型访问length if (typeof text !== \'string\') text = String(text || \"\"); if (text.length <= maxLen) return [text]; for (const delimiter of SUB_CONFIG.SPLIT_PRIORITY) { const pos = text.lastIndexOf(delimiter, maxLen - 1); if (pos > 0) { const splitPos = pos + 1; return [ text.substring(0, splitPos).trim(), ...splitLongPhrase(text.substring(splitPos).trim(), maxLen) ]; } } const startPos = Math.min(maxLen, text.length) - 1; for (let i = startPos; i > 0; i--) { if (/[\\p{Unified_Ideograph}]/u.test(text[i])) { return [ text.substring(0, i + 1).trim(), ...splitLongPhrase(text.substring(i + 1).trim(), maxLen) ]; } } const splitPos = Math.min(maxLen, text.length); return [ text.substring(0, splitPos).trim(), ...splitLongPhrase(text.substring(splitPos).trim(), maxLen) ];}const processSubtitles = ( captions = [], // 添加默认空数组,避免undefined subtitleDurations = [], // 添加默认空数组 startTimeμs = 0) => { const cleanRegex = /[\\u3000\\u3002-\\u303F\\uff00-\\uffef\\u2000-\\u206F!\"#$%&\'()*+\\-./?@\\\\^_`{|}~]/g; let processedSubtitles = []; let processedSubtitleDurations = []; // 关键:遍历前校验数组长度,避免captions与subtitleDurations长度不匹配 const safeLength = Math.min(captions.length, subtitleDurations.length); for (let index = 0; index < safeLength; index++) { const text = captions[index]; const totalDuration = subtitleDurations[index] || 0; // 避免duration为undefined let phrases = splitLongPhrase(text, SUB_CONFIG.MAX_LINE_LENGTH); phrases = phrases.map(p => p.replace(cleanRegex, \'\').trim()) .filter(p => p.length > 0); if (phrases.length === 0) { processedSubtitles.push(\'[无内容]\'); processedSubtitleDurations.push(totalDuration); continue; } const totalChars = phrases.reduce((sum, p) => sum + p.length, 0); let accumulatedμs = 0; phrases.forEach((phrase, i) => { const ratio = totalChars > 0 ? phrase.length / totalChars : 0; // 避免除以0 let durationμs = i === phrases.length - 1 ? totalDuration - accumulatedμs : Math.round(totalDuration * ratio); processedSubtitles.push(phrase); processedSubtitleDurations.push(durationμs); accumulatedμs += durationμs; }); } // 生成时间轴时校验duration数组 const textTimelines = []; let currentTime = startTimeμs; processedSubtitleDurations.forEach(durationμs => { const start = currentTime; const end = start + (durationμs || 0); // 避免durationμs为undefined textTimelines.push({ start, end }); currentTime = end; }); return { textTimelines, processedSubtitles };};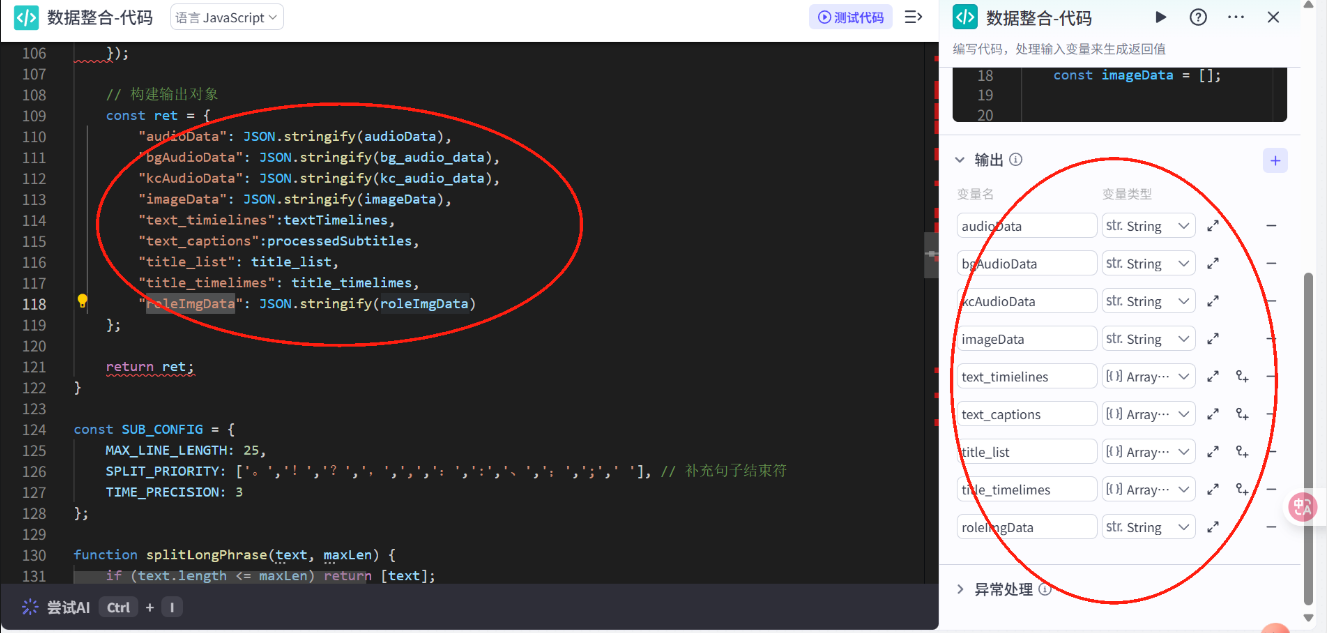
创建草稿
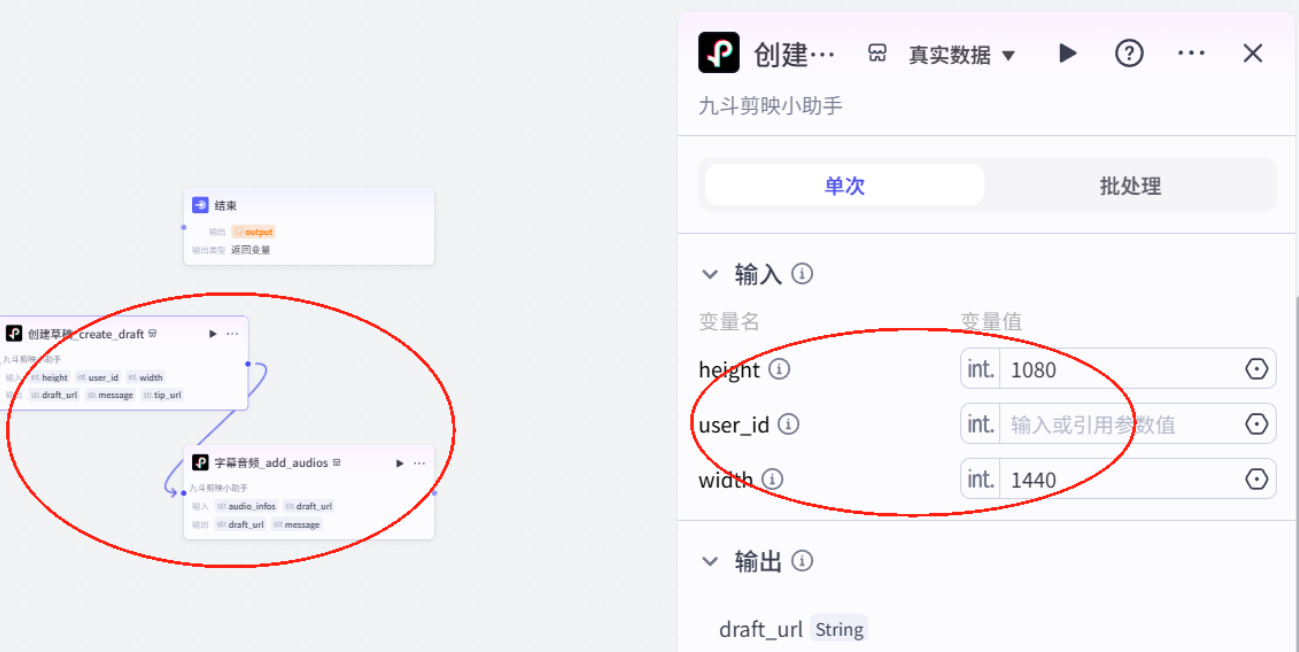
字幕音频生成
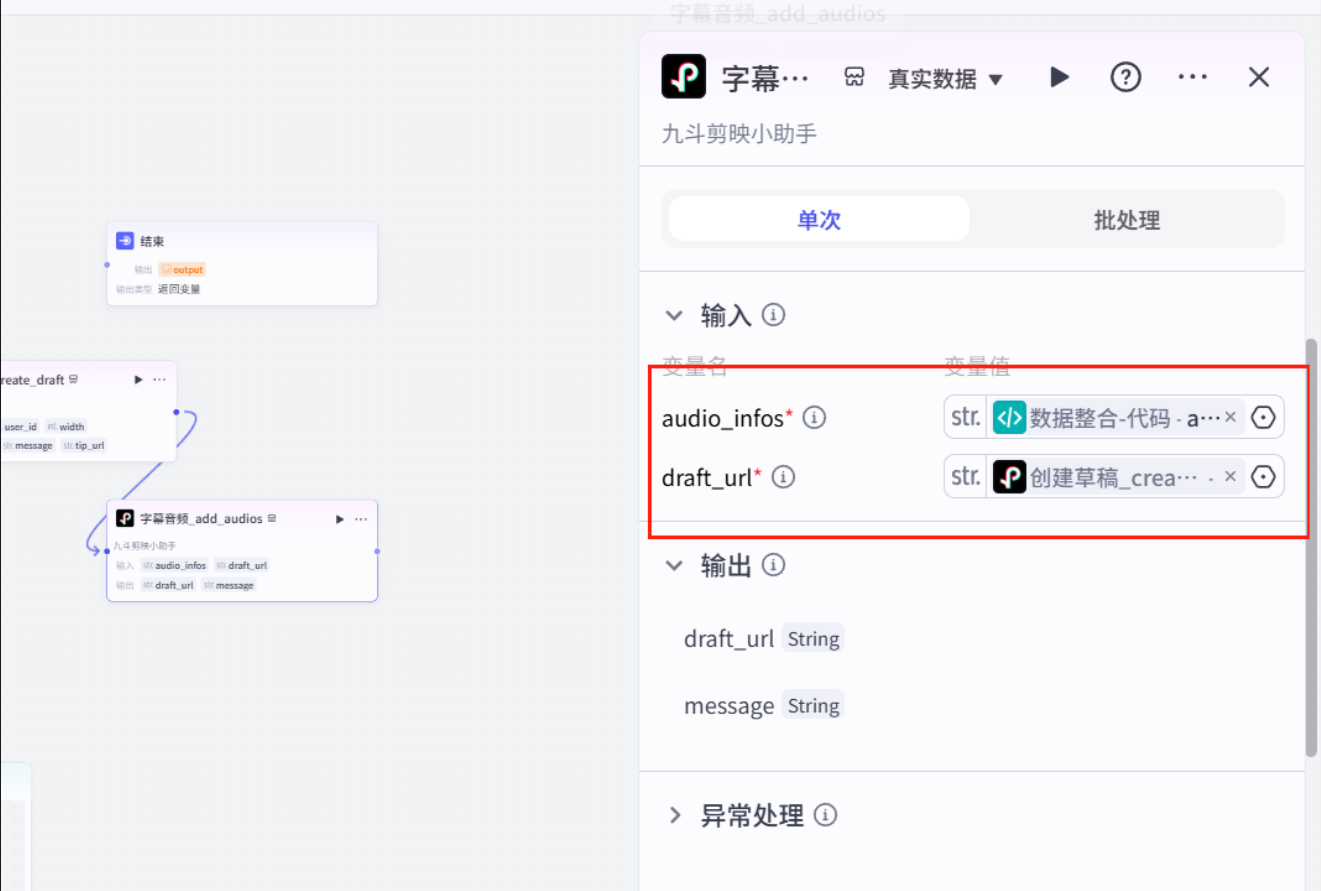
视频画面生成
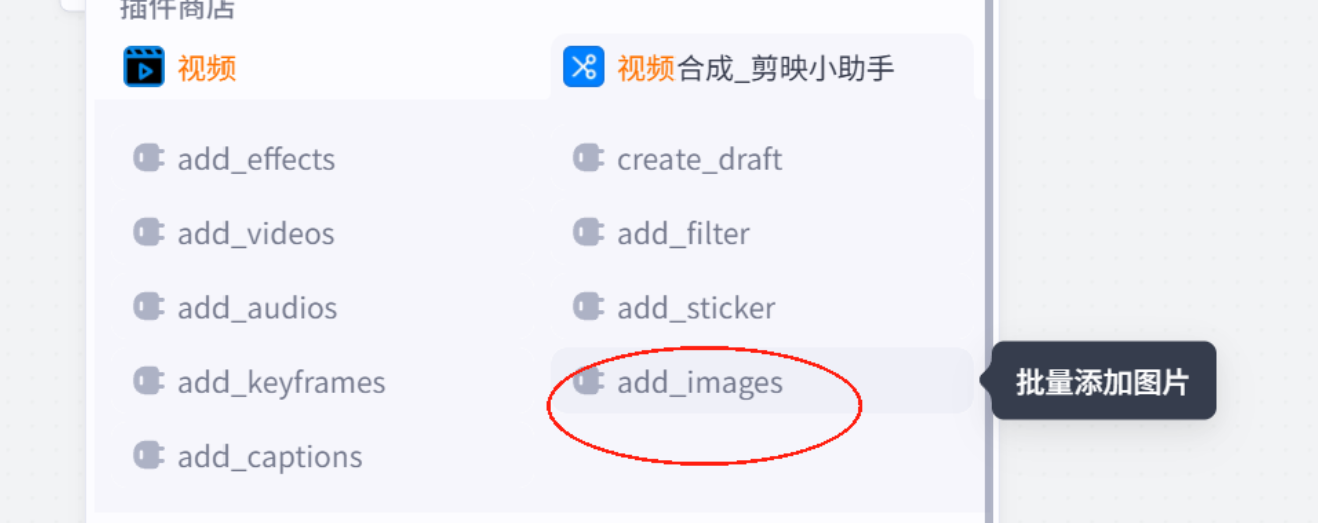
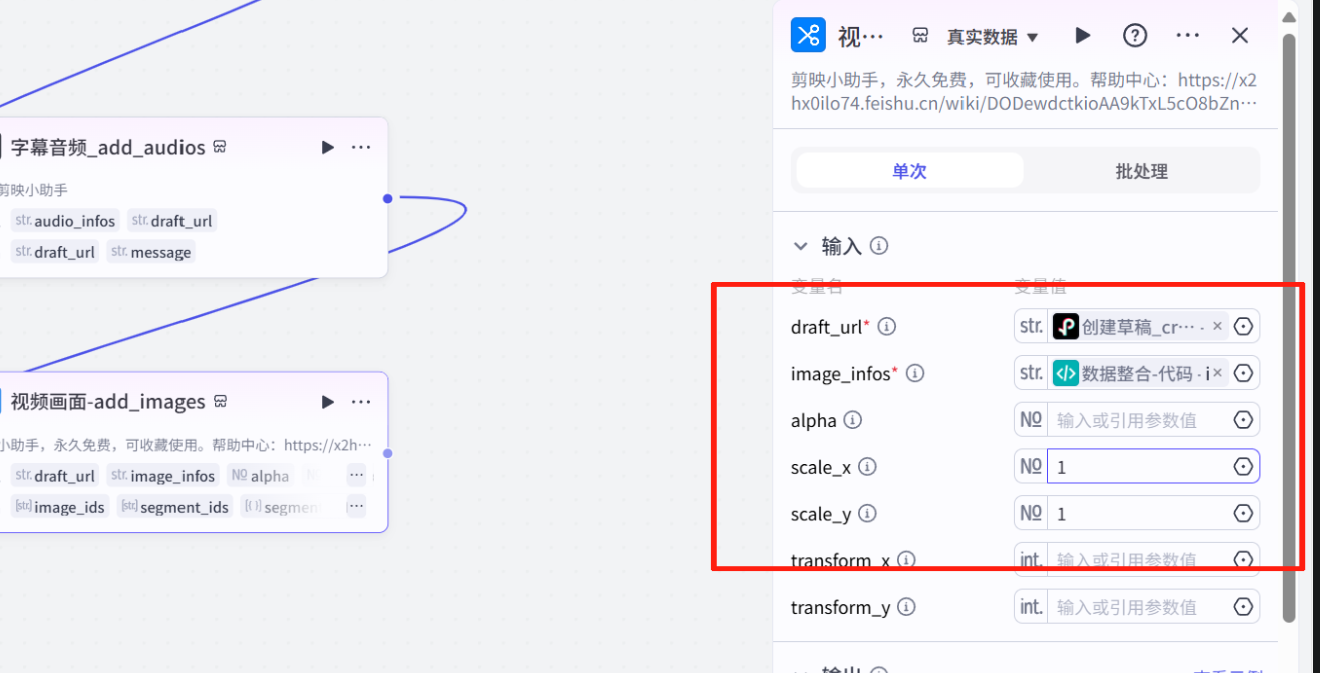
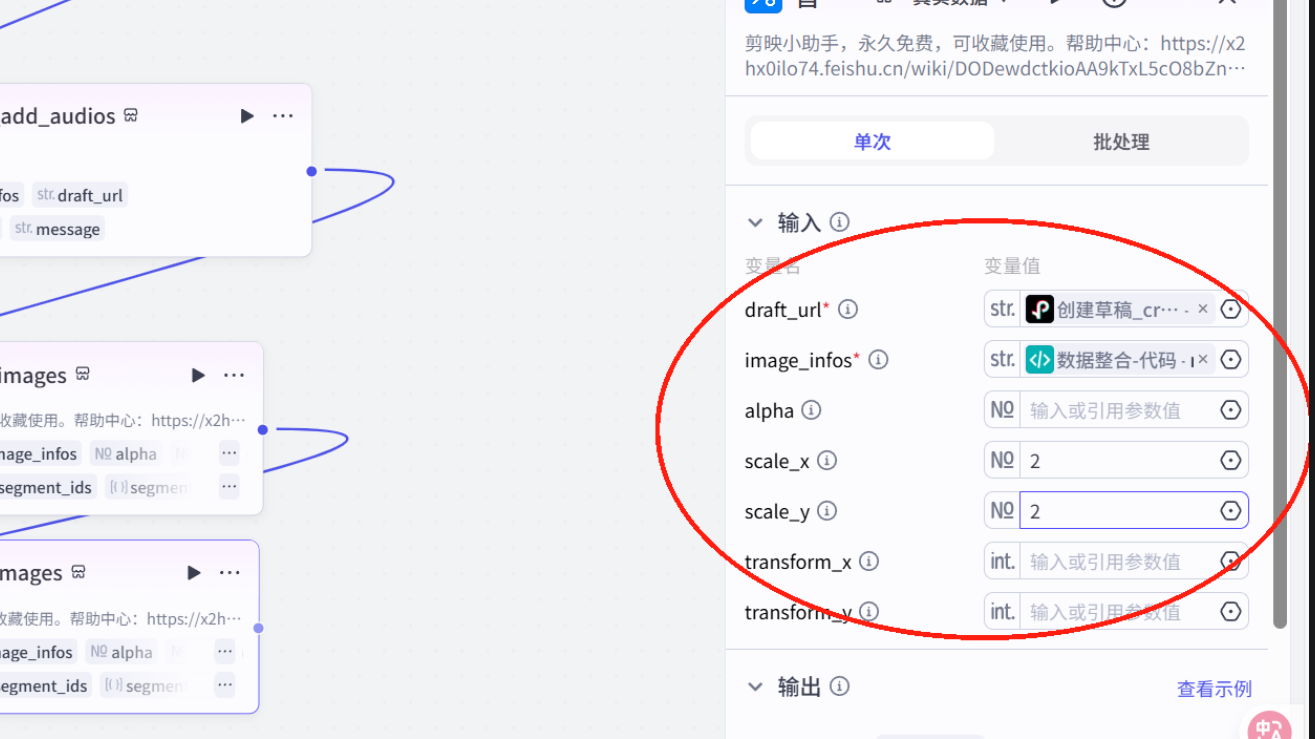
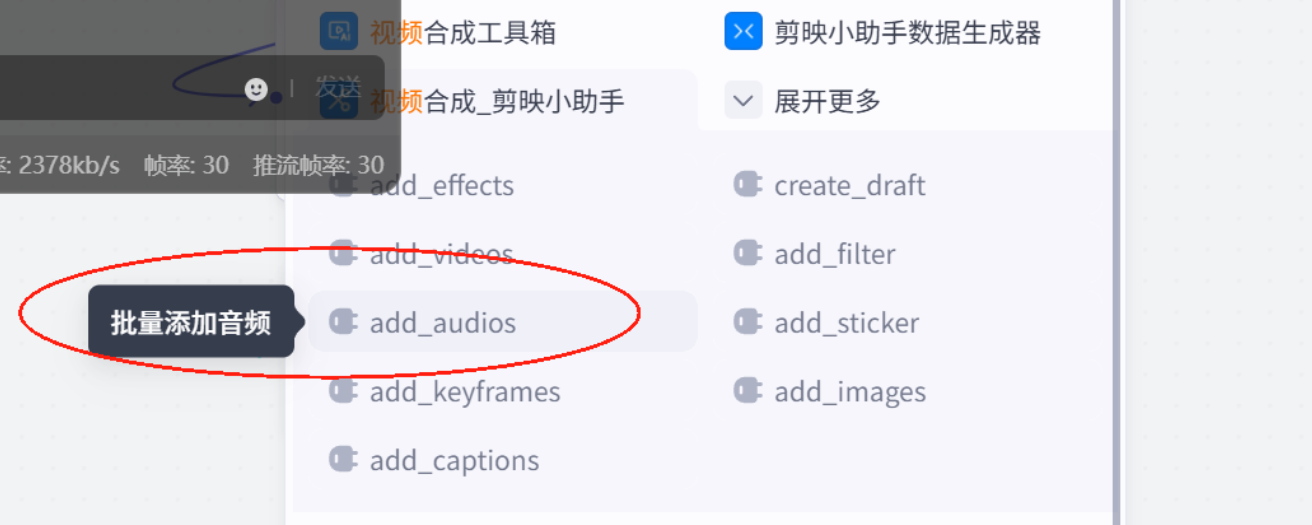
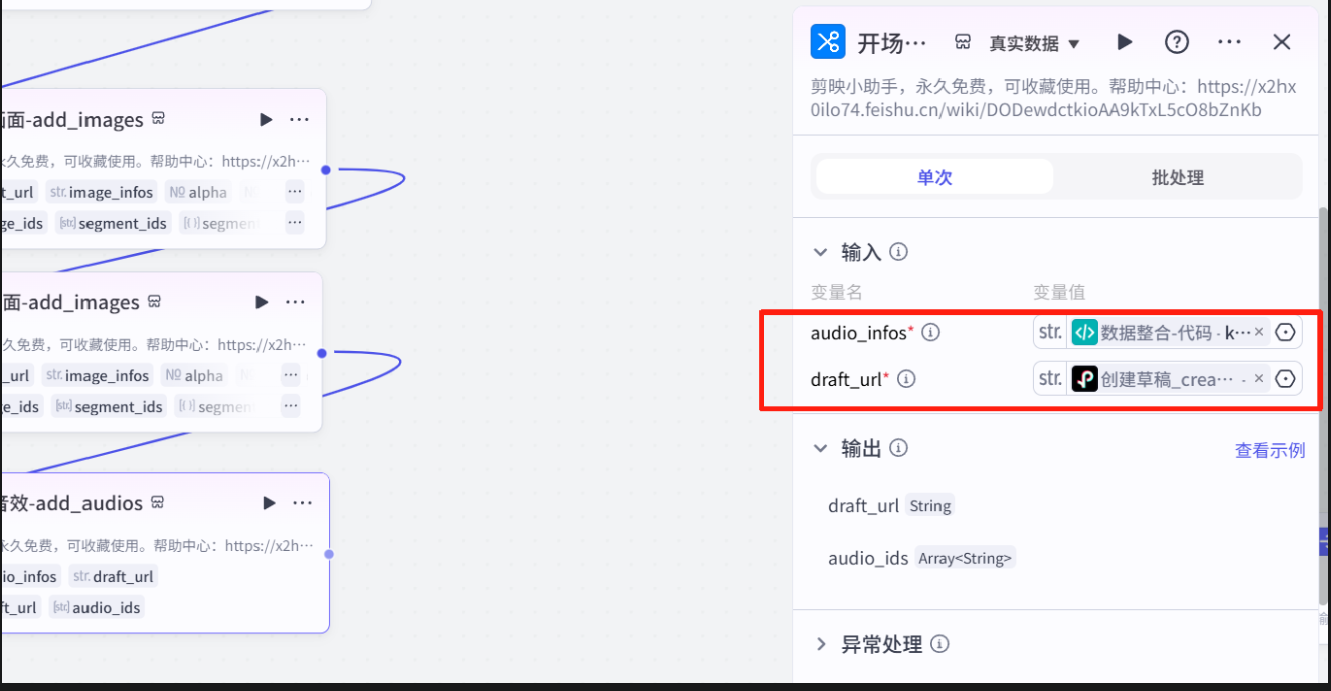
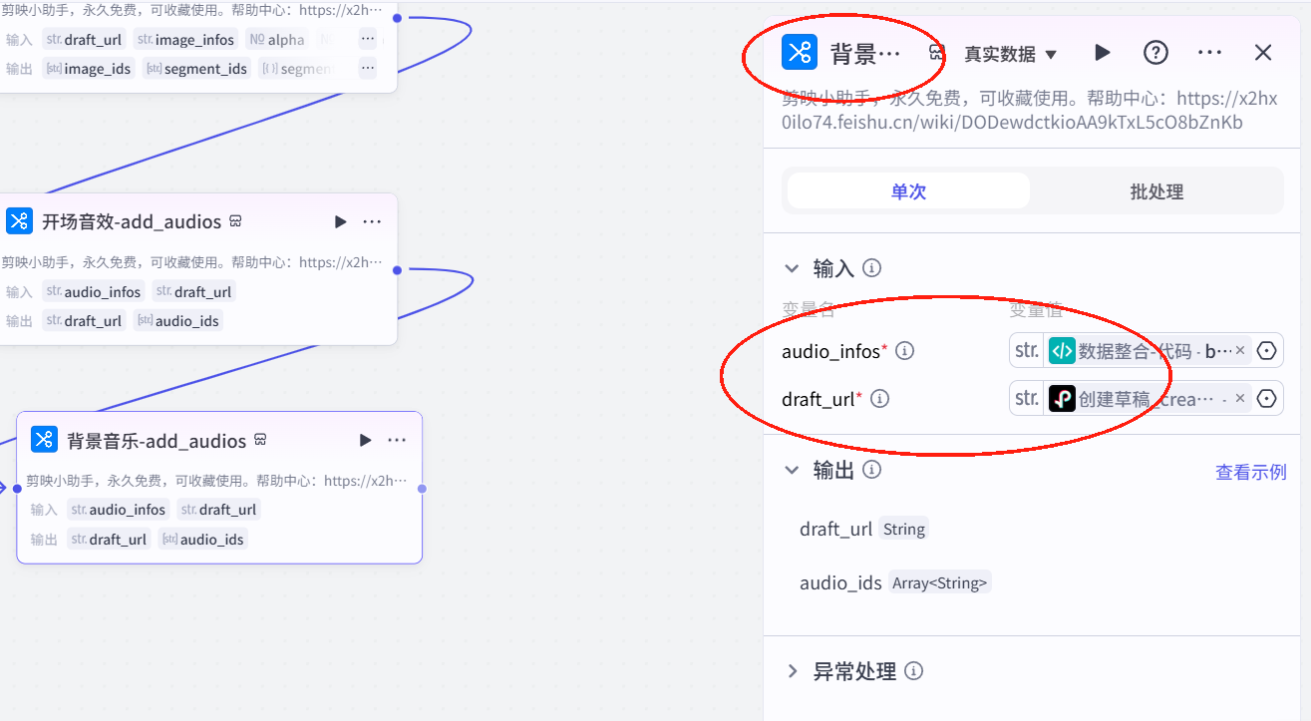
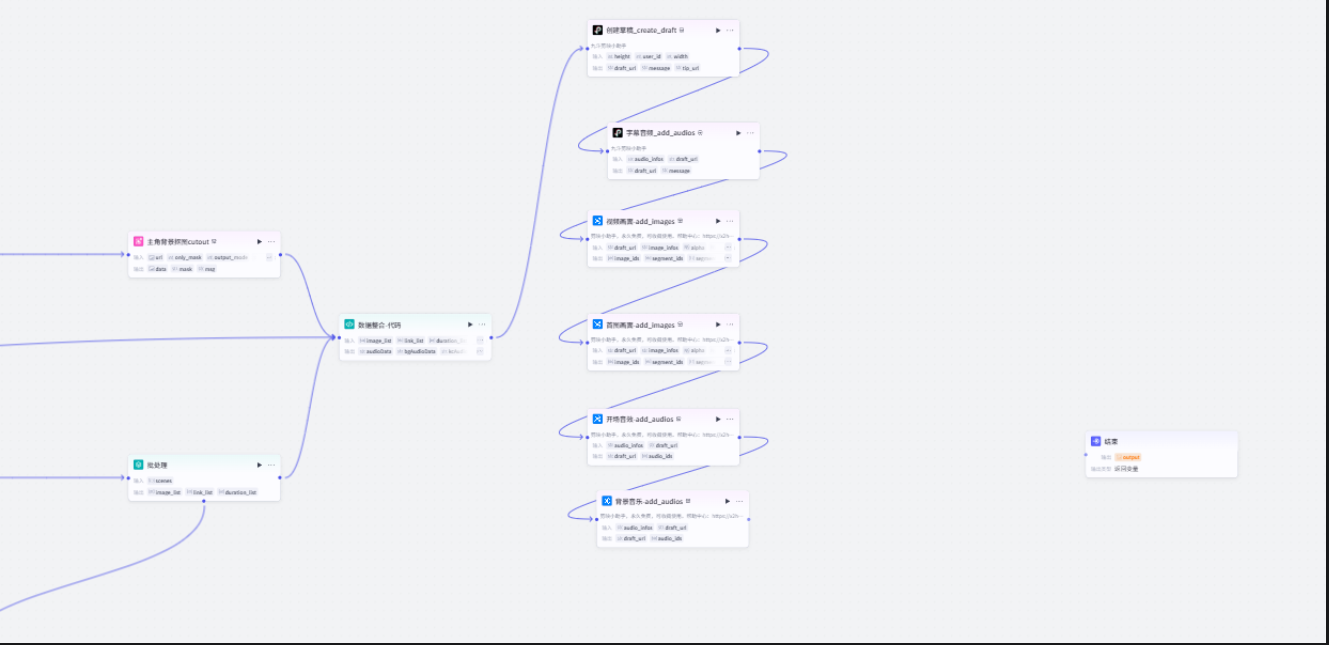
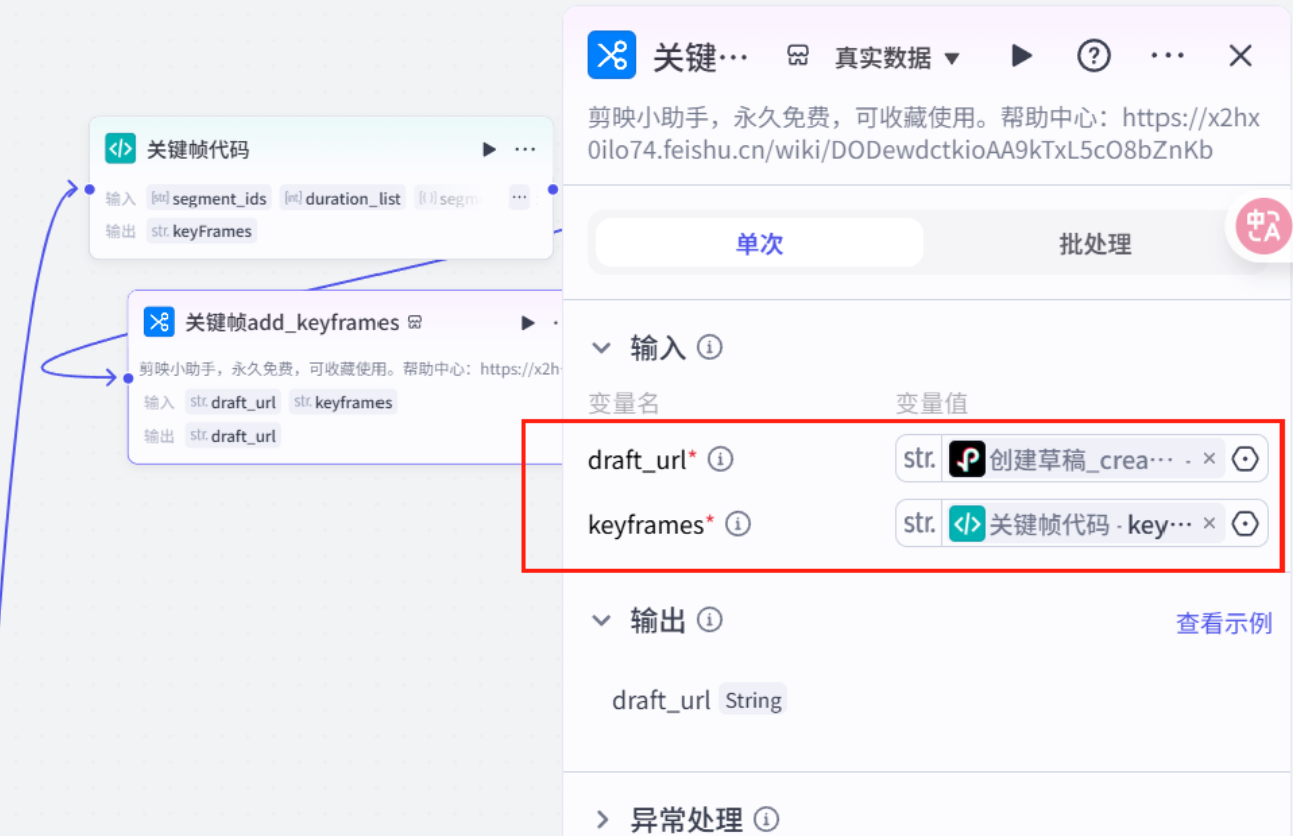
关键帧代码
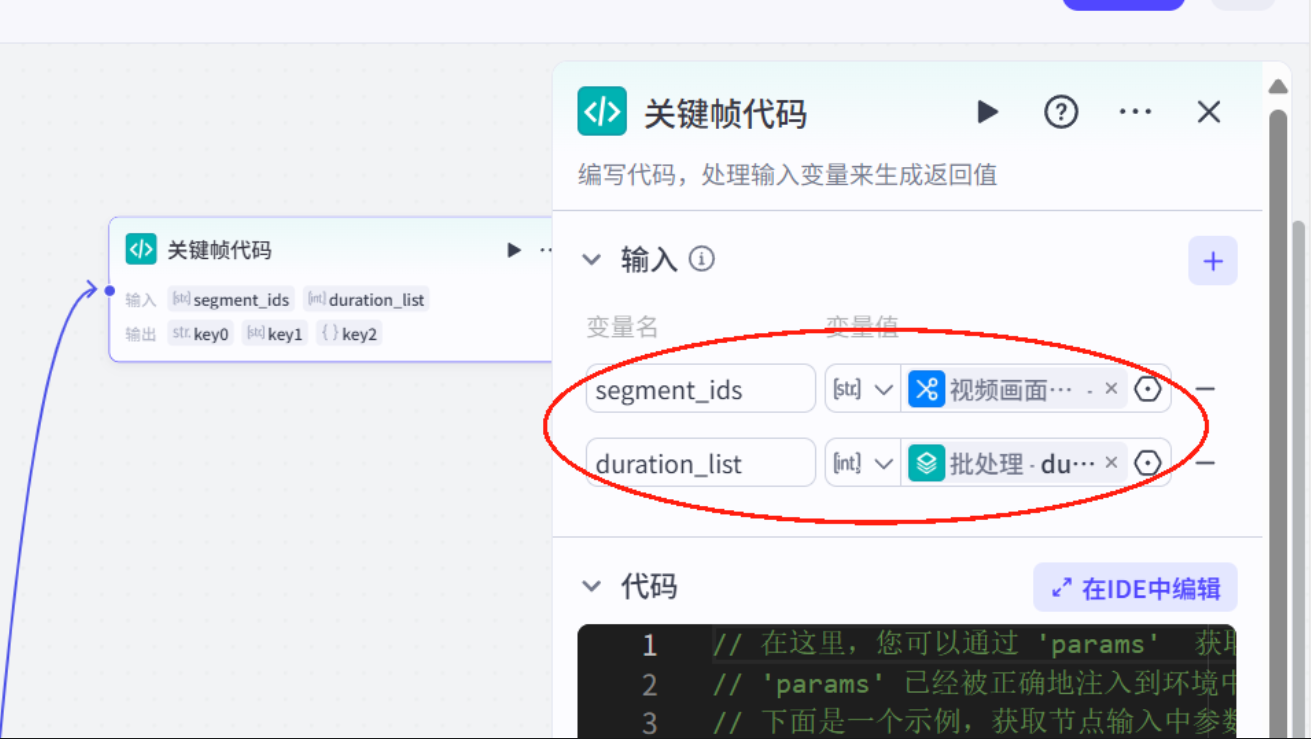
import jsonasync def main(args: Args) -> Output: params = args.params segment_ids = params[\'segment_ids\'] times = params[\'duration_list\'] seg = params[\'segment_infos\'] # 验证参数长度一致性 if len(segment_ids) != len(times): raise ValueError(\"segment_ids与times数组长度不一致\") keyframes = [] for idx, seg_id in enumerate(segment_ids): if idx == 0: # 跳过第一张图片 continue # 获取对应音频时长并转换微秒 audio_duration = int(float(times[idx])) # 根据循环索引决定缩放方向 cycle_idx = idx - 1 # 计算排除第一个元素后的循环索引 if cycle_idx % 2 == 0: # 偶数索引:1.0 -> 1.5 start_scale = 1.0 end_scale = 1.5 else: # 奇数索引:1.5 -> 1.0 start_scale = 1.5 end_scale = 1.0 # 起始关键帧(0秒位置) keyframes.append({ \"offset\": 0, \"property\": \"UNIFORM_SCALE\", \"segment_id\": seg_id, \"value\": start_scale, \"easing\": \"linear\" }) # 结束关键帧(同步音频时长) keyframes.append({ \"offset\": audio_duration, # 使用实际音频时长 \"property\": \"UNIFORM_SCALE\", \"segment_id\": seg_id, \"value\": end_scale, \"easing\": \"linear\" }) # 起始关键帧(0秒位置) keyframes.append({ \"offset\": 0, \"property\": \"UNIFORM_SCALE\", \"segment_id\": seg[0][\'id\'], \"value\": 2, \"easing\": \"linear\" }) keyframes.append({ \"offset\": 533333, \"property\": \"UNIFORM_SCALE\", \"segment_id\": seg[0][\'id\'], \"value\": 1.2, \"easing\": \"linear\" }) # 结束关键帧(同步音频时长) keyframes.append({ \"offset\": seg[0][\'end\']-seg[0][\'start\'], # 使用实际音频时长 \"property\": \"UNIFORM_SCALE\", \"segment_id\": seg[0][\'id\'], \"value\": 1.0, \"easing\": \"linear\" }) return { \"keyFrames\": json.dumps(keyframes) }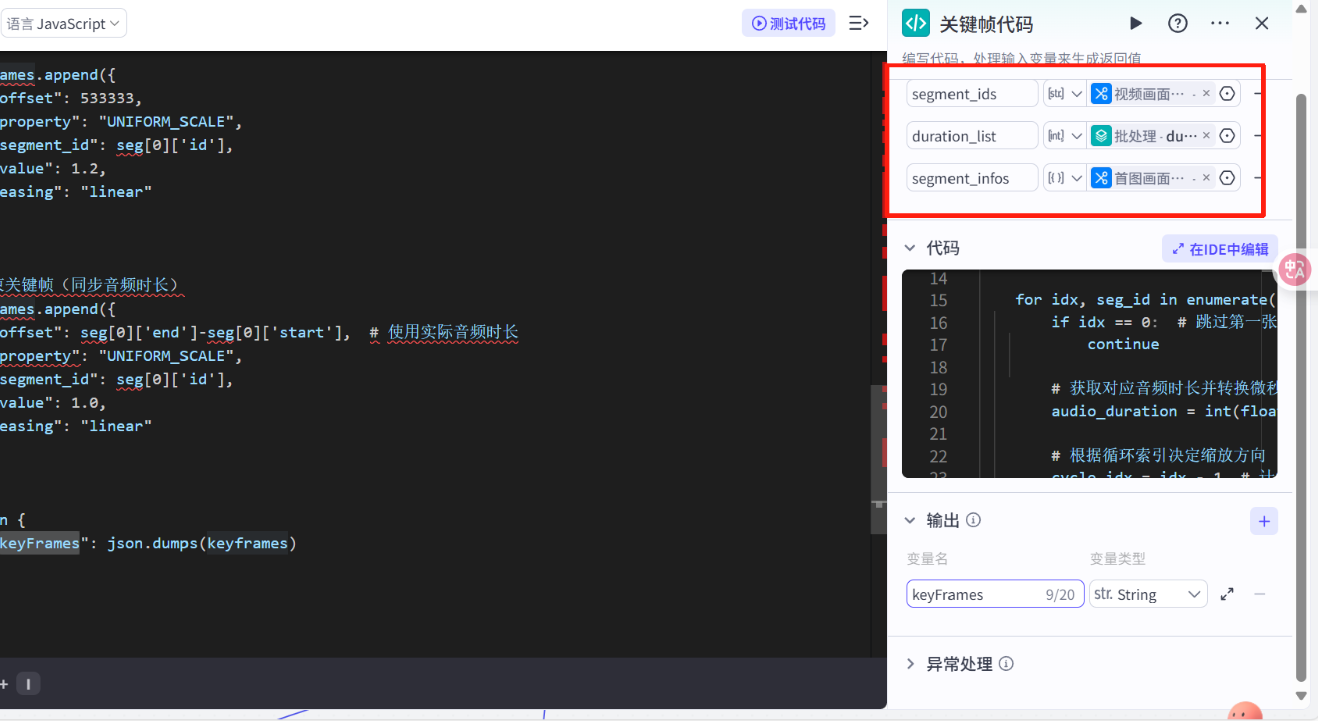
添加关键帧
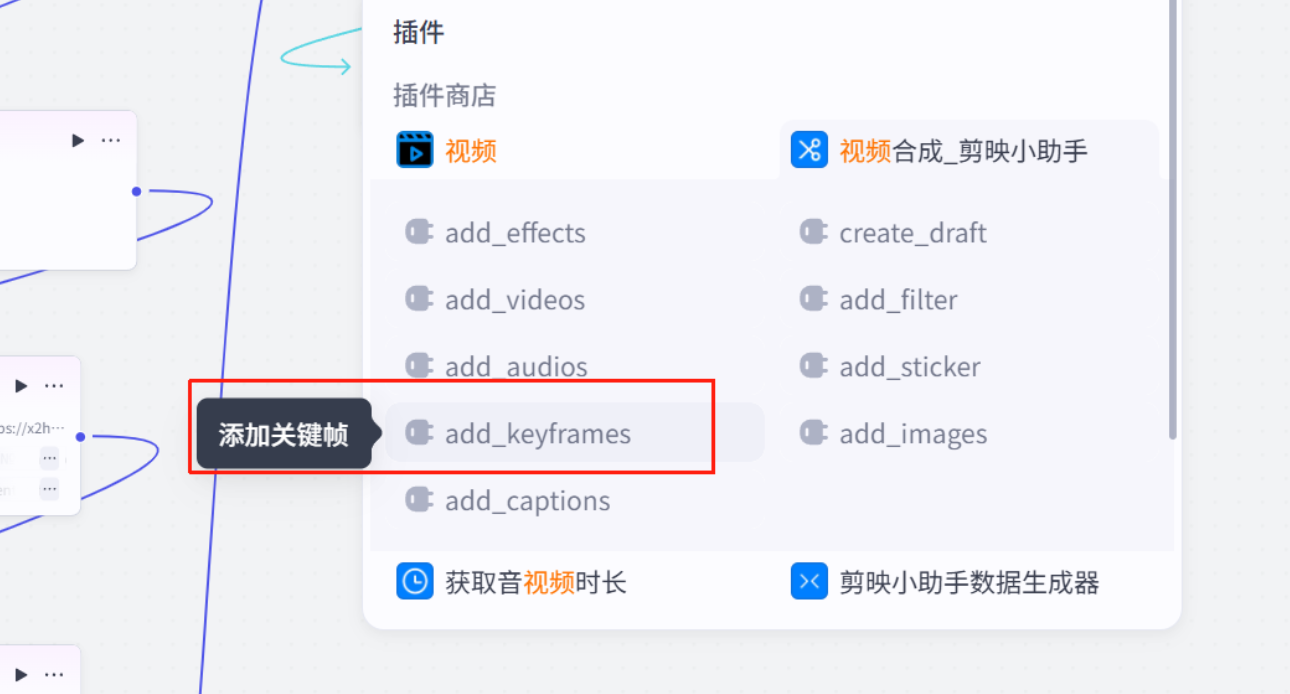
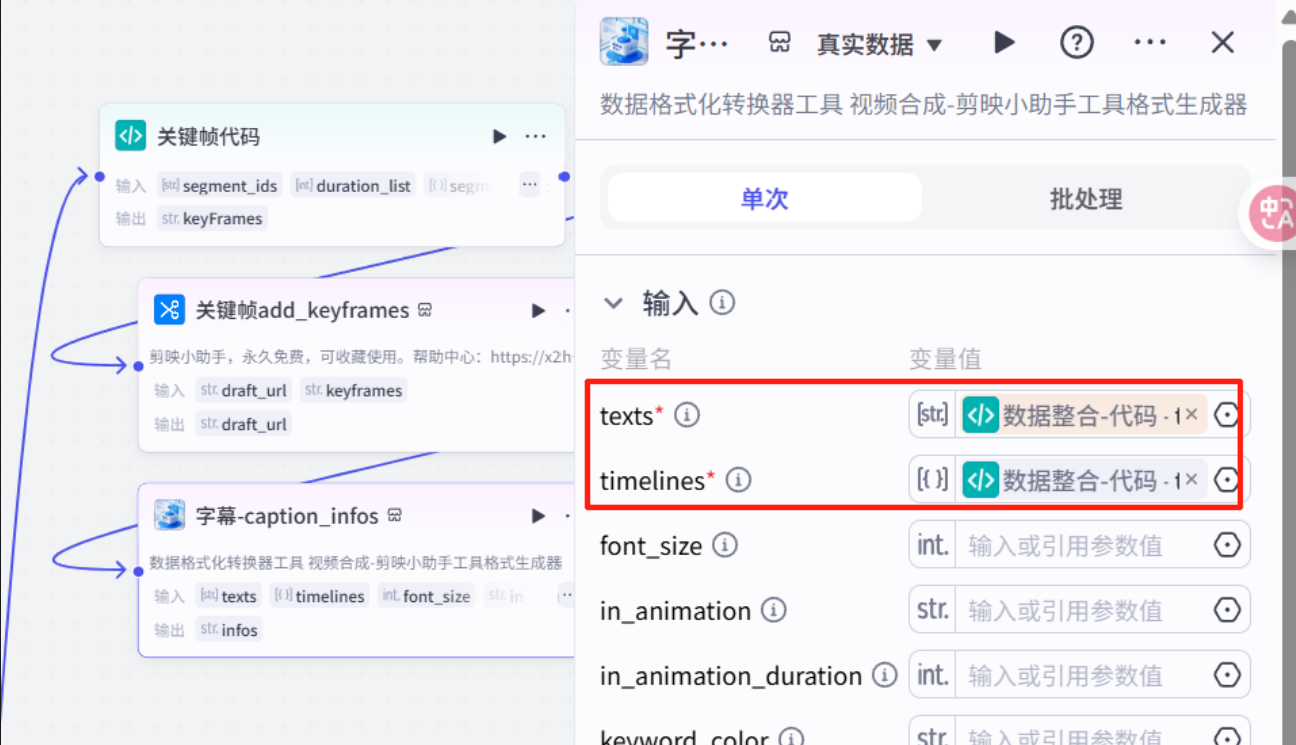
制作字幕数据
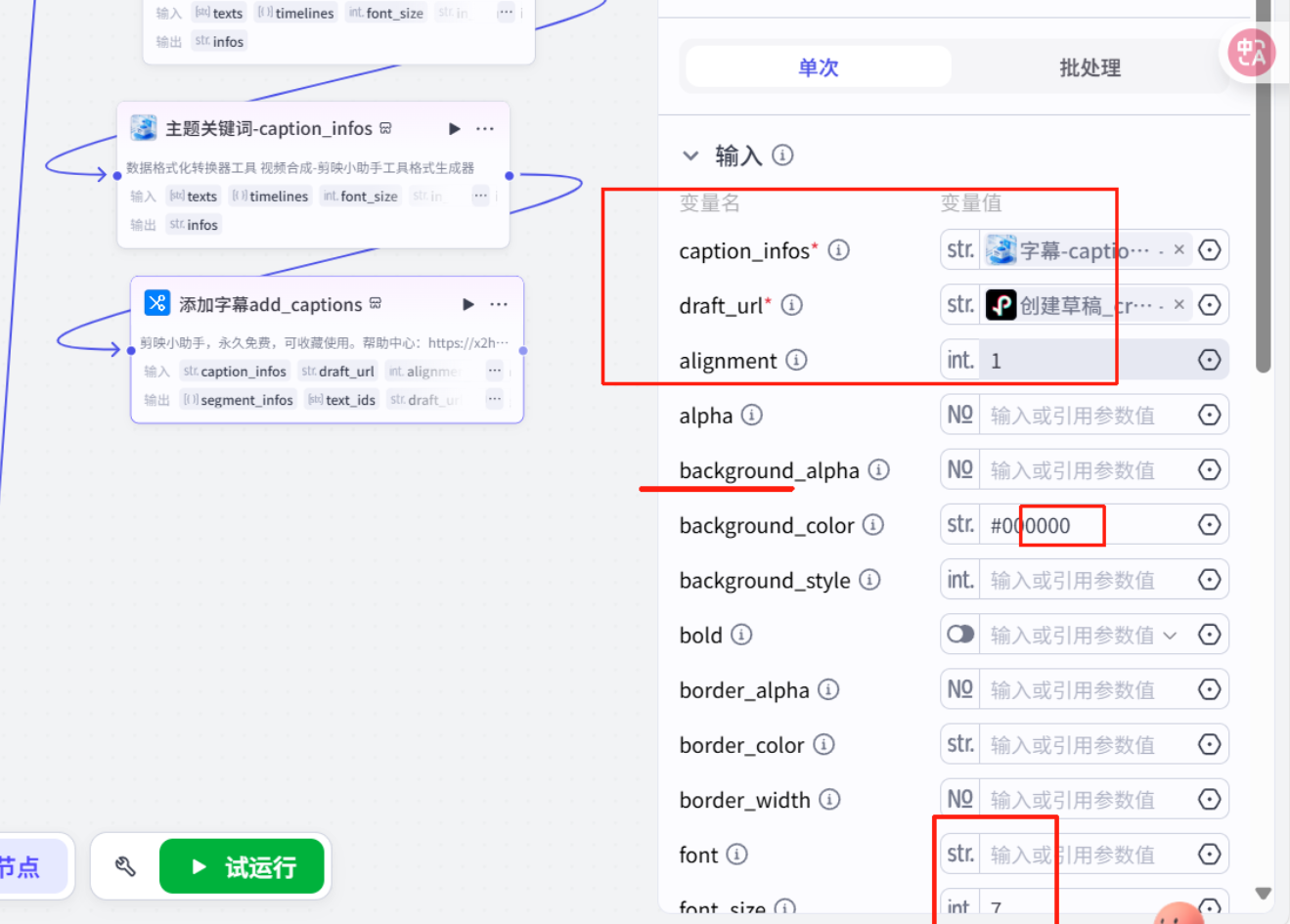
添加字幕
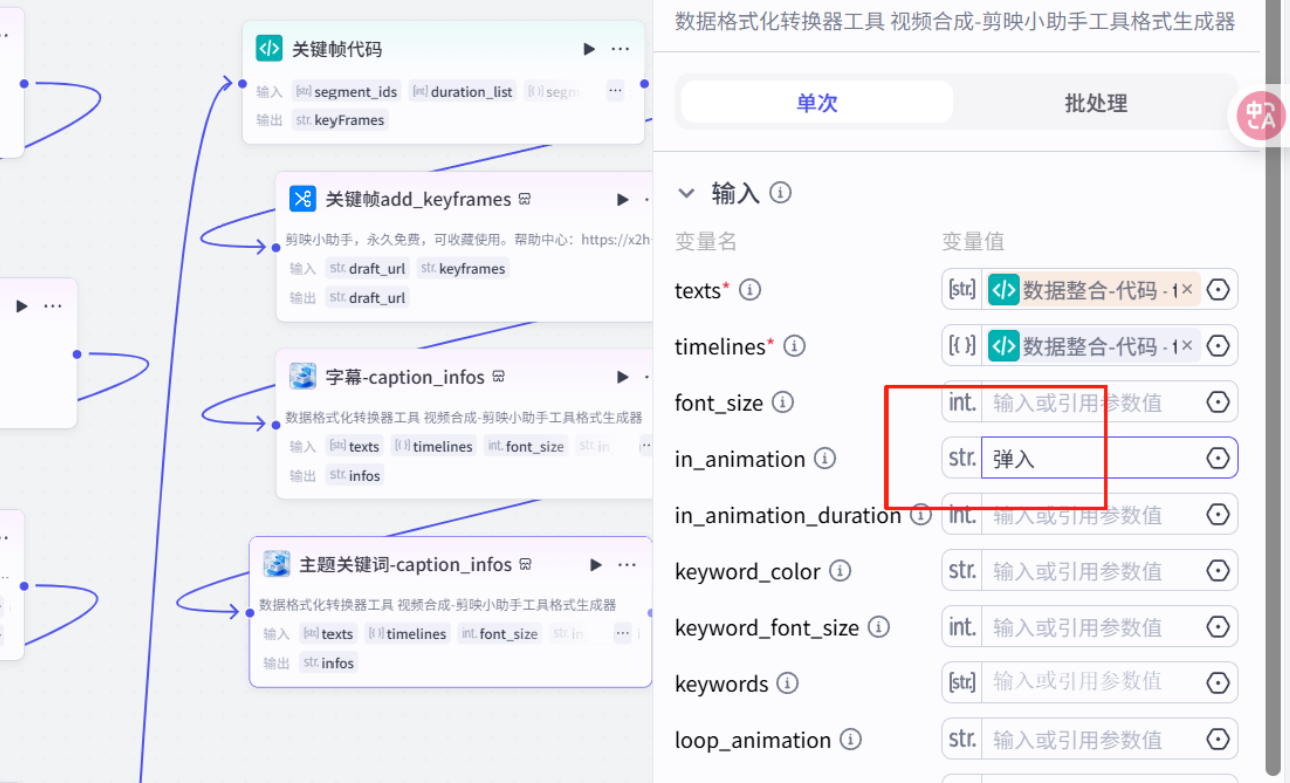
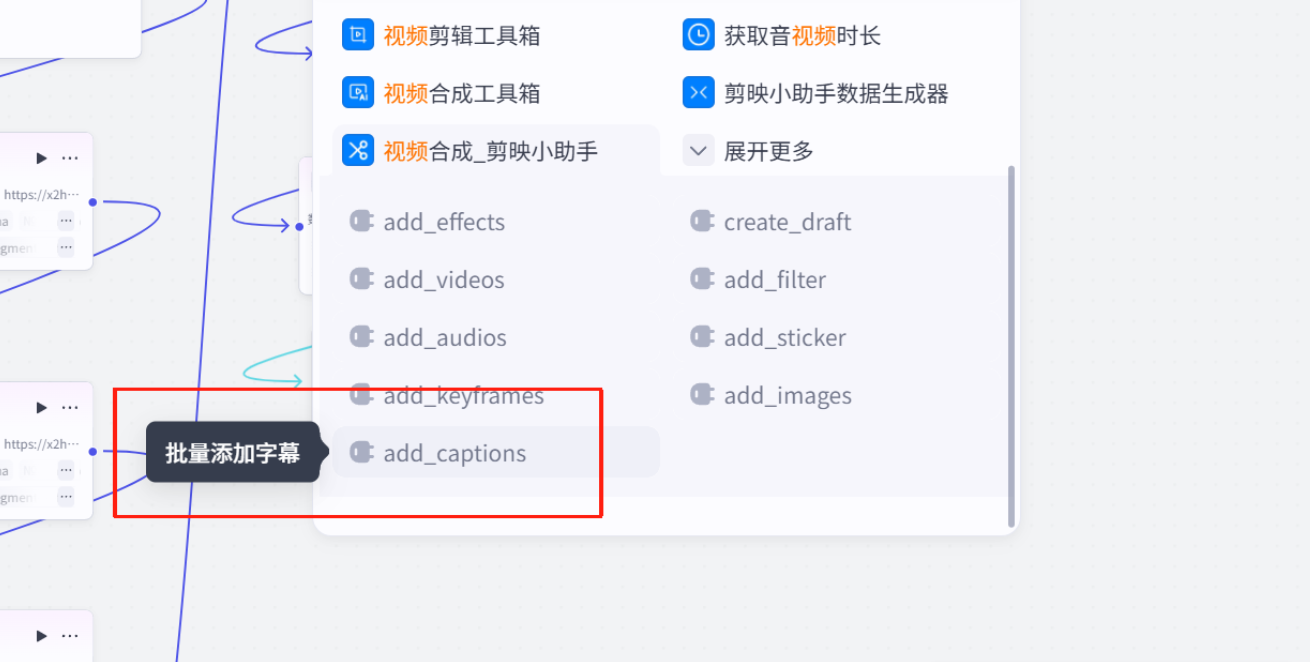
批量添加字幕
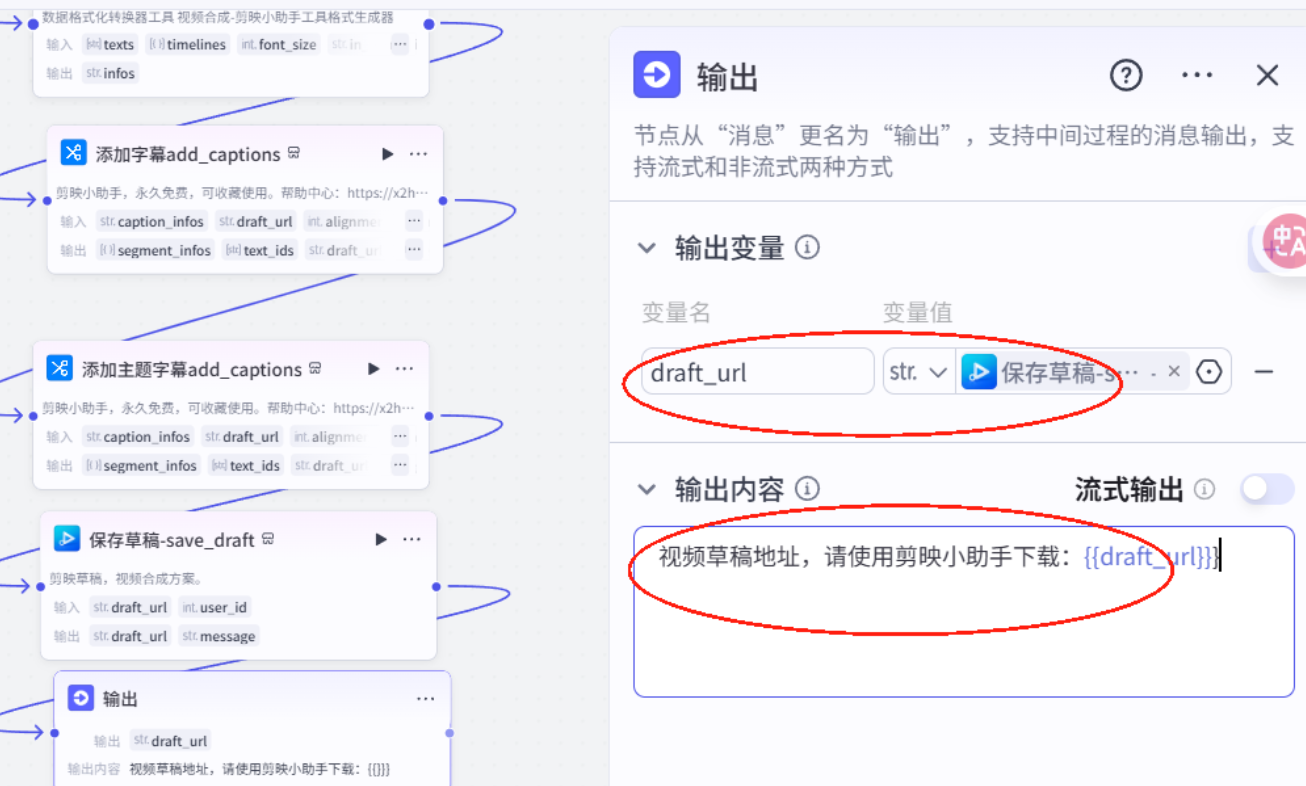
输出
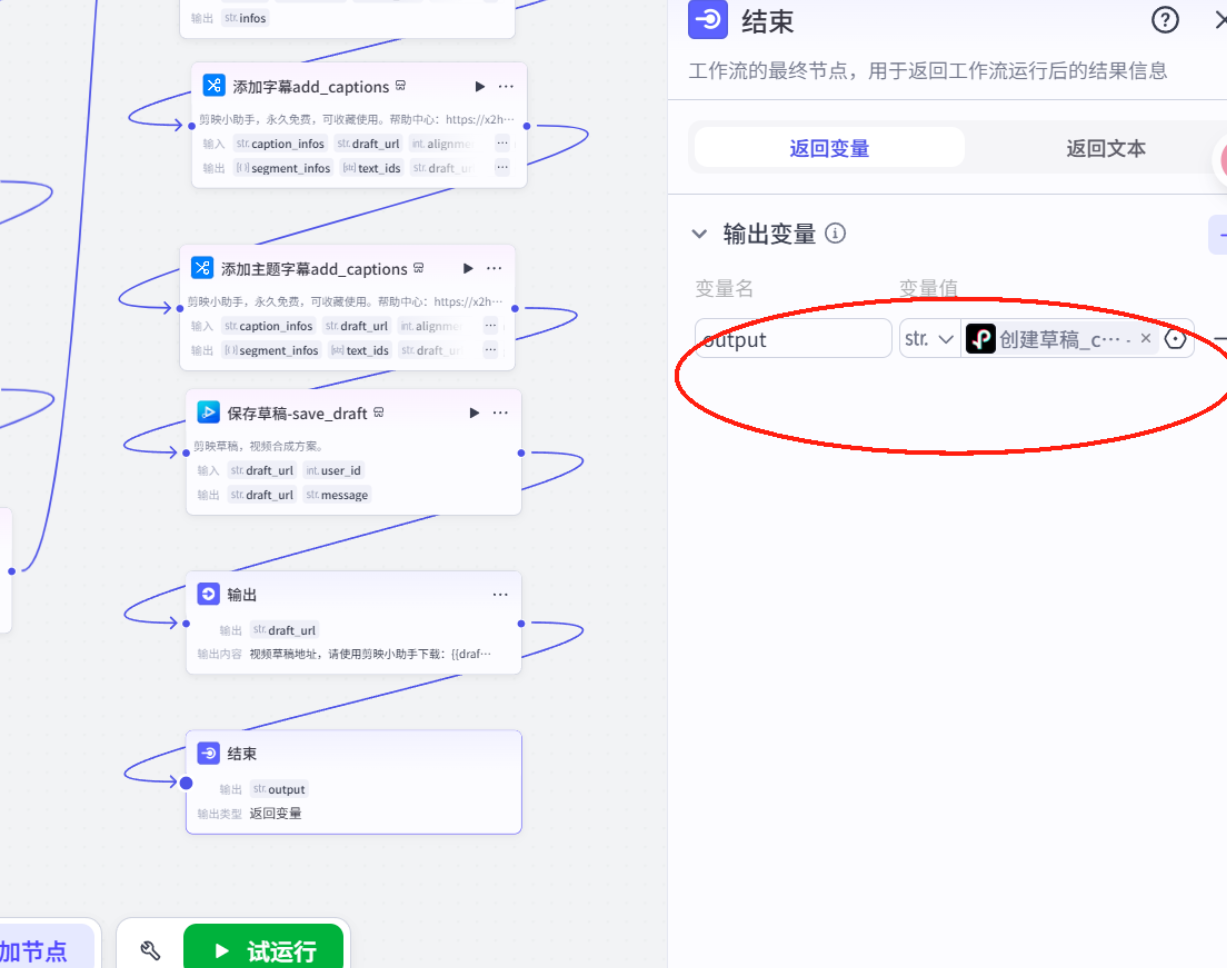
结束
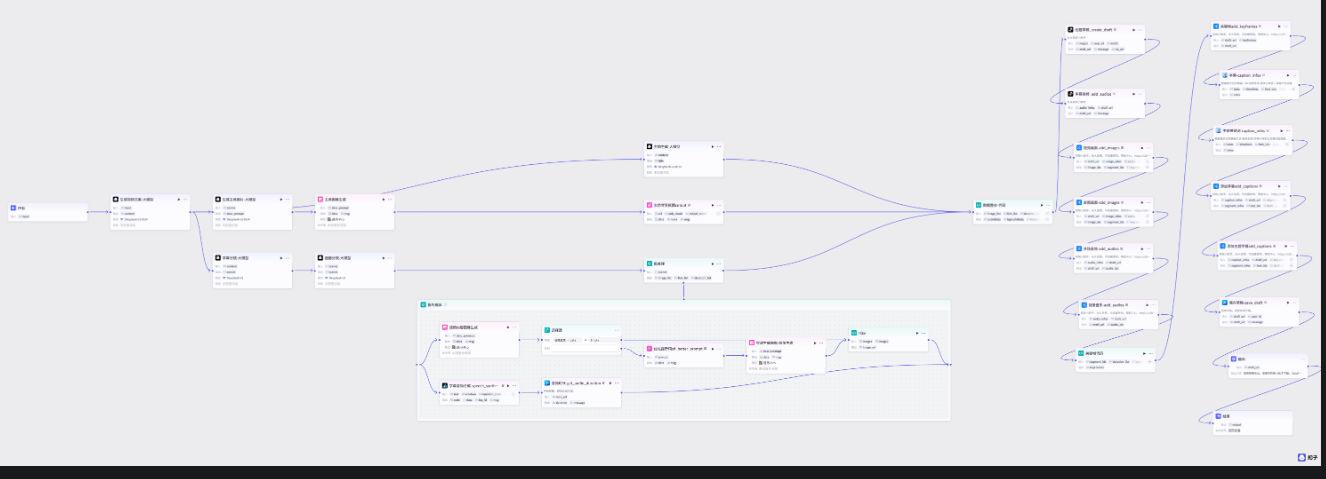
这样我们的工作流就做好了,后续会更新制作后的视频
三、关于开源
2025 年 7 月 26 日,Coze 宣布开源,发布了 Coze Studio 和 Coze Loop 两大项目,采用 Apache 2.0 协议,允许免费使用、修改甚至商业化部署。开发者可通过 [Coze Studio GitHub](https://github.com/coze - dev/coze - studio) 和 [Coze Loop GitHub](https://github.com/coze - dev/cozeloop) 获取开源代码。
四、本地配置与在线使用对比
1.在线版 Coze
优点
- 功能全面且丰富
- 插件生态完善:拥有成百上千个官方及第三方插件,覆盖智能硬件、新闻阅读、图像生成(如 ByteArtist、豆包图像大模型)、天气查询(墨迹天气)、代码执行等多领域,能满足内容创作、办公协作、生活服务等多样化需求。
- 工作流节点充足:除基础搜索、代码、循环节点外,还支持图像处理(抠图、画质提升)、音视频处理(视频生成、抽帧)、会话管理(创建 / 删除会话、查询历史)等进阶节点,可搭建复杂自动化流程。
- 智能体编排能力强:支持触发器、火山知识库(文本 / 表格 / 照片多格式导入)、长期记忆、文件盒子等功能,可配置开场白、用户问题建议等对话体验,且提供单 Agent(自主规划 / 对话流)、多 Agents 三种模式,适配简单与复杂业务逻辑。
- 资源管理与兼容性优:支持多工作空间(个人 / 团队 / 项目空间)切换,可创建文件夹分组管理智能体;资源导入类型丰富(含对话流、卡片、提示词、音色),在线版工作流可自由复制粘贴,跨场景复用性强。
- 发布渠道多元:可一键部署至扣子商店、豆包、飞书、抖音小程序、微信生态(客服 / 服务号 / 订阅号)、掘金等多平台,无需额外开发即可触达广泛用户。
- 辅助功能实用:支持 AI 自动生成智能体图标、AI 优化提示词,降低设计与文案编写门槛,提升开发效率。
- 稳定性高,无技术门槛
- 无需自行部署与维护服务器,不存在插件授权失败、知识库上传解析异常等 bug,官方会持续迭代优化功能,保障使用流畅性;
- 操作零门槛,可视化拖拽式搭建,中文文档完善,零基础小白可快速上手,适合用于学习 AI Agent 开发或轻量级任务处理。
缺点
- 数据安全自主性低:数据存储在 Coze 官方云端,无法完全掌控数据归属,对于对数据隐私要求极高的企业(如金融、医疗行业),可能存在合规风险。
- 定制化自由度有限:无法深度修改底层代码与架构,若需开发专属插件或适配特殊业务场景,扩展能力弱于开源版。
- 可能存在功能限制:免费版可能对插件使用数量、工作流运行次数、存储容量等有额度限制,企业级功能需付费解锁。
2.开源版(本地部署)Coze 优缺点
优点
- 数据安全与合规性强:可将数据完全存储在企业内部服务器或本地数据库,无需依赖第三方云端,能满足金融、医疗等行业的数据隐私要求;支持代码审计,可自主排查系统安全漏洞,保障业务合规。
- 定制化与扩展性高:基于 Apache 2.0 协议,可获取完整源码(前端 Typescript+React、后端 Golang),技术团队可进行二次开发,如定制专属插件、扩展工作流节点、修改产品 logo 与交互逻辑,适配细分业务场景(如企业内部定制化智能助手)。
- 无云端功能限制:不存在在线版的插件使用、工作流运行次数等额度限制,可根据业务需求无限扩展,适合高并发、高频次的自动化任务场景。
缺点
- 功能缺失严重
- 插件数量极少:仅 18 个基础插件,无在线版的图像生成、头条搜索、飞书生态等高频插件,且官方需到 Q3 才升级插件生态,当前无法满足多样化需求;
- 核心功能缺失:无触发器、长期记忆、文件盒子、多工作空间等关键功能,智能体仅支持单 Agent 模式,无法处理复杂逻辑;
- 辅助功能缺失:无 AI 生成图标、AI 优化提示词功能,资源管理无文件夹分组,工作流无法粘贴在线版内容,开发效率低。
- 稳定性差,bug 较多:存在知识库文本上传后解析 6 次失败且无提示、插件 “未授权” 却找不到授权入口、点击插件无跳转等问题,需自行排查(如服务器配置是否达标)与修复,增加运维成本。
- 技术门槛高,部署维护复杂:需具备服务器部署(Linux/Windows)、前后端开发(Golang/React)、数据库维护等技术能力,零基础小白无法独立操作;后续需自行跟进官方源码更新,修复漏洞与迭代功能,运维成本高。
- 发布渠道单一:仅支持发布至
ChatSDK与API,无法部署到扣子商店、豆包、抖音小程序等流量平台,难以触达 C 端用户或外部客户。
3、适用场景与人群建议
- 辅助功能缺失:无 AI 生成图标、AI 优化提示词功能,资源管理无文件夹分组,工作流无法粘贴在线版内容,开发效率低。
- 稳定性差,bug 较多:存在知识库文本上传后解析 6 次失败且无提示、插件 “未授权” 却找不到授权入口、点击插件无跳转等问题,需自行排查(如服务器配置是否达标)与修复,增加运维成本。
- 技术门槛高,部署维护复杂:需具备服务器部署(Linux/Windows)、前后端开发(Golang/React)、数据库维护等技术能力,零基础小白无法独立操作;后续需自行跟进官方源码更新,修复漏洞与迭代功能,运维成本高。
- 发布渠道单一:仅支持发布至
ChatSDK与API,无法部署到扣子商店、豆包、抖音小程序等流量平台,难以触达 C 端用户或外部客户。


