小红书开源dots.ocr:单一视觉语言模型中的多语言文档布局解析

简介
dots.ocr 是一款强大的多语言文档解析器,它将版面检测与内容识别统一整合到单一视觉语言模型中,同时保持出色的阅读顺序还原能力。尽管其基础模型仅为17亿参数的轻量级大语言模型(LLM),但性能达到了业界顶尖水平(SOTA)。
- 卓越性能:在OmniDocBench基准测试中,dots.ocr 的文本、表格和阅读顺序解析均达到SOTA水平,公式识别效果更可媲美豆包1.5、gemini2.5-pro等参数量大得多的模型。
- 多语言支持:针对低资源语言展现出强大的解析能力,在我们自建的多语言文档测试集上,版面检测与内容识别均取得显著优势。
- 统一简洁架构:依托单一视觉语言模型,dots.ocr 的架构远比依赖复杂多模型流水线的传统方案更精简。仅需调整输入提示词即可切换任务,证明视觉语言模型在检测任务上可比肩DocLayout-YOLO等传统检测模型。
- 高效推理:基于17亿参数的轻量LLM构建,推理速度优于许多基于更大规模基础模型的高性能方案。
性能对比:dots.ocr 与竞品模型
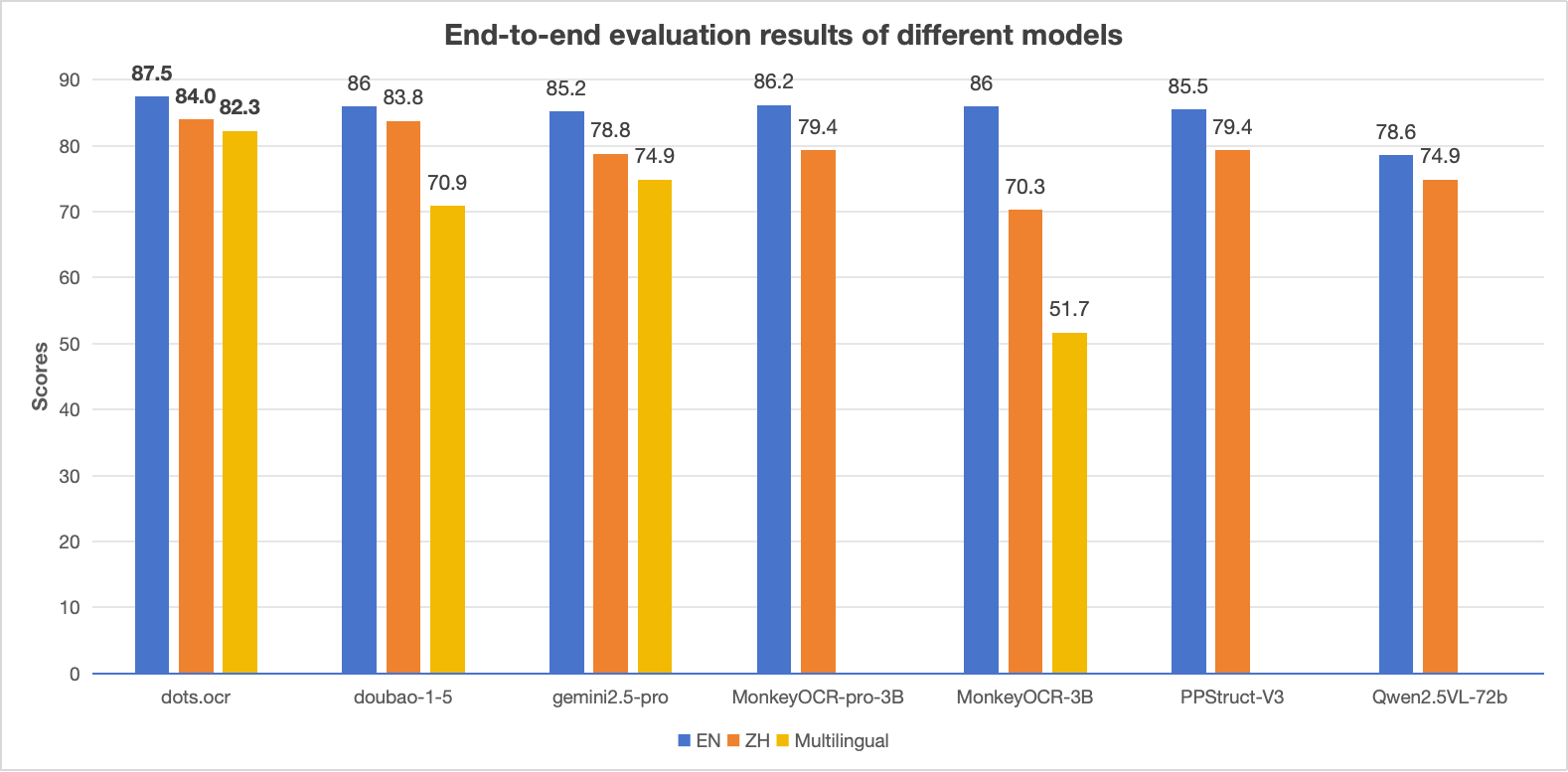
备注:
- EN、ZH 指标为 OmniDocBench 端到端评估结果,Multilingual 指标为 dots.ocr-bench 端到端评估结果。
基准测试结果
- OmniDocBench
不同任务的端到端评估结果
Type
Tools
VLMs
VLMs
跨9种PDF页面类型的端到端文本识别性能。
Type
Report
Paper
Papers
Tools
VLMs
VLMs
备注:
- 指标数据来源于MonkeyOCR、OmniDocBench及我们内部的评估结果。
- 我们在结果Markdown中删除了页眉和页脚单元格。
- 我们使用tikz_preprocess流程将图像分辨率提升至200dpi。
- dots.ocr-bench
这是一个内部基准,包含100种语言的1493张pdf图像。
不同任务的端到端评估结果。
注:
- 我们采用了与 OmniDocBench 相同的指标计算流程。
- 在结果 markdown 中删除了页眉(Page-header)和页脚(Page-footer)单元格。
布局检测
备注:
- prompt_layout_all_en 用于解析全部,prompt_layout_only_en 仅用于检测,请参阅提示
- olmOCR-bench.
Math
Footers
column
Text
(No Anchor)
(Anchored)
(No Anchor)
(Anchored)
(No Anchor)
(No Anchor)
(No Anchor)
(Anchored)
快速开始
- 安装
安装 dots.ocr
conda create -n dots_ocr python=3.12conda activate dots_ocrgit clone https://github.com/rednote-hilab/dots.ocr.gitcd dots.ocr# Install pytorch, see https://pytorch.org/get-started/previous-versions/ for your cuda versionpip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128pip install -e .如果在安装过程中遇到问题,可以尝试使用我们的Docker镜像以简化配置,并按照以下步骤操作:
git clone https://github.com/rednote-hilab/dots.ocr.gitcd dots.ocrpip install -e .下载模型权重
💡注意:请为模型保存路径使用不含句点的目录名(例如用DotsOCR而非dots.ocr)。这是我们与Transformers集成前的临时解决方案。
python3 tools/download_model.py- 部署
vLLM推理
我们强烈建议使用vLLM进行部署和推理。我们所有的评估结果均基于vLLM 0.9.1版本。Docker镜像基于官方vLLM镜像构建,您也可以参考Dockerfile自行搭建部署环境。
# You need to register model to vllm at firstpython3 tools/download_model.pyexport hf_model_path=./weights/DotsOCR # Path to your downloaded model weights, Please use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`) for the model save path. This is a temporary workaround pending our integration with Transformers.export PYTHONPATH=$(dirname \"$hf_model_path\"):$PYTHONPATHsed -i \'/^from vllm\\.entrypoints\\.cli\\.main import main$/a\\from DotsOCR import modeling_dots_ocr_vllm\' `which vllm` # If you downloaded model weights by yourself, please replace `DotsOCR` by your model saved directory name, and remember to use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`) # launch vllm serverCUDA_VISIBLE_DEVICES=0 vllm serve ${hf_model_path} --tensor-parallel-size 1 --gpu-memory-utilization 0.95 --chat-template-content-format string --served-model-name model --trust-remote-code# If you get a ModuleNotFoundError: No module named \'DotsOCR\', please check the note above on the saved model directory name.# vllm api demopython3 ./demo/demo_vllm.py --prompt_mode prompt_layout_all_enHuggingface 推理
python3 demo/demo_hf.pyHuggingface 推理细节
import torchfrom transformers import AutoModelForCausalLM, AutoProcessor, AutoTokenizerfrom qwen_vl_utils import process_vision_infofrom dots_ocr.utils import dict_promptmode_to_promptmodel_path = \"./weights/DotsOCR\"model = AutoModelForCausalLM.from_pretrained( model_path, attn_implementation=\"flash_attention_2\", torch_dtype=torch.bfloat16, device_map=\"auto\", trust_remote_code=True)processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)image_path = \"demo/demo_image1.jpg\"prompt = \"\"\"Please output the layout information from the PDF image, including each layout element\'s bbox, its category, and the corresponding text content within the bbox.1. Bbox format: [x1, y1, x2, y2]2. Layout Categories: The possible categories are [\'Caption\', \'Footnote\', \'Formula\', \'List-item\', \'Page-footer\', \'Page-header\', \'Picture\', \'Section-header\', \'Table\', \'Text\', \'Title\'].3. Text Extraction & Formatting Rules: - Picture: For the \'Picture\' category, the text field should be omitted. - Formula: Format its text as LaTeX. - Table: Format its text as HTML. - All Others (Text, Title, etc.): Format their text as Markdown.4. Constraints: - The output text must be the original text from the image, with no translation. - All layout elements must be sorted according to human reading order.5. Final Output: The entire output must be a single JSON object.\"\"\"messages = [ { \"role\": \"user\", \"content\": [ { \"type\": \"image\", \"image\": image_path }, {\"type\": \"text\", \"text\": prompt} ] } ]# Preparation for inferencetext = processor.apply_chat_template( messages, tokenize=False, add_generation_prompt=True)image_inputs, video_inputs = process_vision_info(messages)inputs = processor( text=[text], images=image_inputs, videos=video_inputs, padding=True, return_tensors=\"pt\",)inputs = inputs.to(\"cuda\")# Inference: Generation of the outputgenerated_ids = model.generate(**inputs, max_new_tokens=24000)generated_ids_trimmed = [ out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]output_text = processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)print(output_text)3.文档解析
基于vLLM服务器,您可以使用以下命令解析图像或pdf文件:
# Parse all layout info, both detection and recognition# Parse a single imagepython3 dots_ocr/parser.py demo/demo_image1.jpg# Parse a single PDFpython3 dots_ocr/parser.py demo/demo_pdf1.pdf --num_threads 64 # try bigger num_threads for pdf with a large number of pages# Layout detection onlypython3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_layout_only_en# Parse text only, except Page-header and Page-footerpython3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_ocr# Parse layout info by bboxpython3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_grounding_ocr --bbox 

