时序数据库选型指南:为什么IoTDB是企业级应用的最佳选择_iotdb冷数据
在数字化转型浪潮中,时序数据正成为企业数字资产的核心组成部分。从工业物联网的设备监控到金融市场的实时交易数据,从智慧城市的传感器网络到新能源汽车的运行状态追踪,时序数据无处不在。面对海量、高频、多维的时序数据挑战,选择合适的时序数据库成为决定项目成败的关键因素。
一、时序数据库的技术演进与选型复杂性
时序数据库作为专门处理带时间戳数据的存储系统,在过去十年间经历了从传统关系型数据库的时序扩展到原生时序数据库的技术革命。这一演进过程反映了业界对时序数据特性认知的不断深入:数据写入密集、查询模式相对固定、数据生命周期管理复杂、压缩比要求极高等特点,都对存储架构提出了独特要求。
在全球时序数据库技术图谱中,我们看到了多样化的技术路径。欧美厂商如InfluxDB凭借其云原生理念率先占据市场,TimescaleDB通过PostgreSQL扩展的方式降低了迁移成本,而以Apache IoTDB为代表的开源项目则在工业物联网领域展现出强大的适应性。这种技术多样性既为用户提供了更多选择,也增加了选型的复杂度。
选型复杂性不仅体现在技术架构的差异上,更体现在不同产品对应用场景的适配程度。一个在互联网监控场景下表现出色的时序数据库,未必能够胜任工业制造的严苛环境。因此,深入理解各类时序数据库的技术特性与适用边界,成为做出正确选型决策的前提。
二、核心技术维度分析框架
1. 存储引擎架构设计
存储引擎是时序数据库的技术核心,直接决定了系统的性能上限和扩展能力。主流的存储架构可以分为几种典型模式:基于LSM-Tree的写优化架构、基于列式存储的查询优化架构,以及混合存储架构。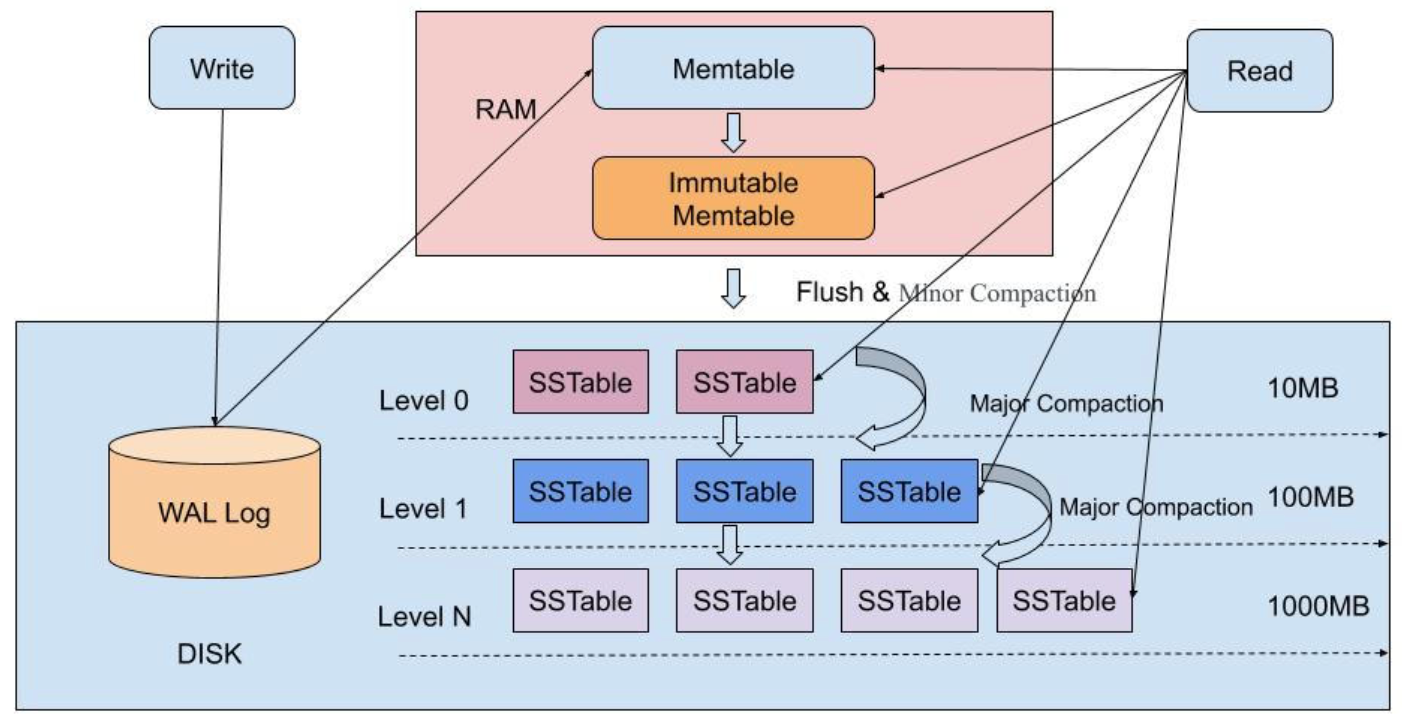
LSM-Tree架构通过将随机写转化为顺序写,天然适配时序数据的高频写入特性。数据首先写入内存中的MemTable,达到阈值后刷写到磁盘形成SSTable,后台异步进行合并操作。这种设计在保证高写入吞吐的同时,通过布隆过滤器等索引结构优化读取性能。
-- IoTDB的存储组织结构示例CREATE DATABASE root.factory.workshop01;CREATE TIMESERIES root.factory.workshop01.device01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE;CREATE TIMESERIES root.factory.workshop01.device01.pressure WITH DATATYPE=DOUBLE, ENCODING=GORILLA;列式存储则通过按列组织数据,实现了更高的压缩比和分析性能。时序数据具有强烈的时间局部性,同一时间窗口内的数据往往具有相似的统计特征,列式存储能够充分利用这一特性进行压缩。
混合存储架构则试图在写入性能和查询性能之间找到最佳平衡点,通过智能的数据分层和路由策略,让热数据享受高性能访问,冷数据获得高压缩比存储。
2. 数据压缩与编码技术
时序数据的压缩技术直接影响存储成本和查询性能。传统的通用压缩算法如Gzip、LZ4在时序数据上的效果往往不尽如人意,因为它们没有充分利用时序数据的特殊规律。
专门针对时序数据设计的压缩算法表现更加出色。Gorilla压缩算法利用数值的时间相关性,通过XOR操作和变长编码实现了极高的压缩比。Delta-of-Delta编码则专门针对时间戳的规律性进行优化,将时间间隔的变化量作为编码对象。
// IoTDB中的编码配置示例CREATE TIMESERIES root.sg.d1.s1 WITH DATATYPE=INT32, ENCODING=TS_2DIFF;CREATE TIMESERIES root.sg.d1.s2 WITH DATATYPE=FLOAT, ENCODING=GORILLA;CREATE TIMESERIES root.sg.d1.s3 WITH DATATYPE=TEXT, ENCODING=DICTIONARY;RLE (Run-Length Encoding) 对于存在大量重复值的场景效果显著,特别适合状态类数据。字典编码则通过建立值到编码的映射关系,显著减少重复字符串的存储开销。
3. 分布式架构与一致性保证
随着数据规模的增长,单机存储必然面临容量和性能瓶颈,分布式架构成为必然选择。但分布式带来的复杂性也不容忽视:数据分片策略、副本一致性、故障恢复、负载均衡等问题都需要系统性的解决方案。
时序数据的分布式架构设计需要考虑数据的时间属性。基于时间范围的分片策略能够保证查询的局部性,但可能导致热点问题。基于设备ID的分片则能够平衡负载,但跨设备的时间范围查询性能可能受到影响。
一致性保证是分布式系统的核心挑战。时序数据场景下,很多应用对强一致性的要求并不严格,最终一致性往往能够满足需求。这为系统设计提供了更大的优化空间,可以通过异步复制、批量写入等技术提升性能。
4. 查询引擎与SQL兼容性
查询能力是时序数据库面向用户的最直观体现。一个优秀的时序数据库不仅要支持基本的CRUD操作,更要针对时序数据的常见查询模式进行深度优化。
时序数据的查询具有鲜明特点:范围查询多于点查询、聚合操作频繁、时间窗口计算常见。针对这些特点,专业的时序数据库会提供专门的查询优化器和执行引擎。
SQL兼容性是降低用户学习成本的关键因素。完全兼容SQL标准的时序数据库能够让用户无缝迁移现有应用,但也需要在语言表达能力和执行效率之间做出权衡。
-- IoTDB支持丰富的时序查询语法SELECT temperature, pressure FROM root.factory.** WHERE time >= 2024-01-01T00:00:00 AND time < 2024-01-02T00:00:00GROUP BY ([2024-01-01T00:00:00, 2024-01-02T00:00:00), 1h);-- 支持复杂的时间窗口计算SELECT max_value(temperature), avg(pressure)FROM root.factory.workshop01.device01GROUP BY ([now() - 24h, now()), 1h)FILL(linear);三、Apache IoTDB技术优势深度解析
1. 原生时序存储架构设计
Apache IoTDB从设计之初就专门针对时序数据的特性进行了深度优化。其采用的LSM-Tree变种架构TsFile,通过时间分区和设备分组的双重组织方式,实现了写入性能和查询性能的最佳平衡。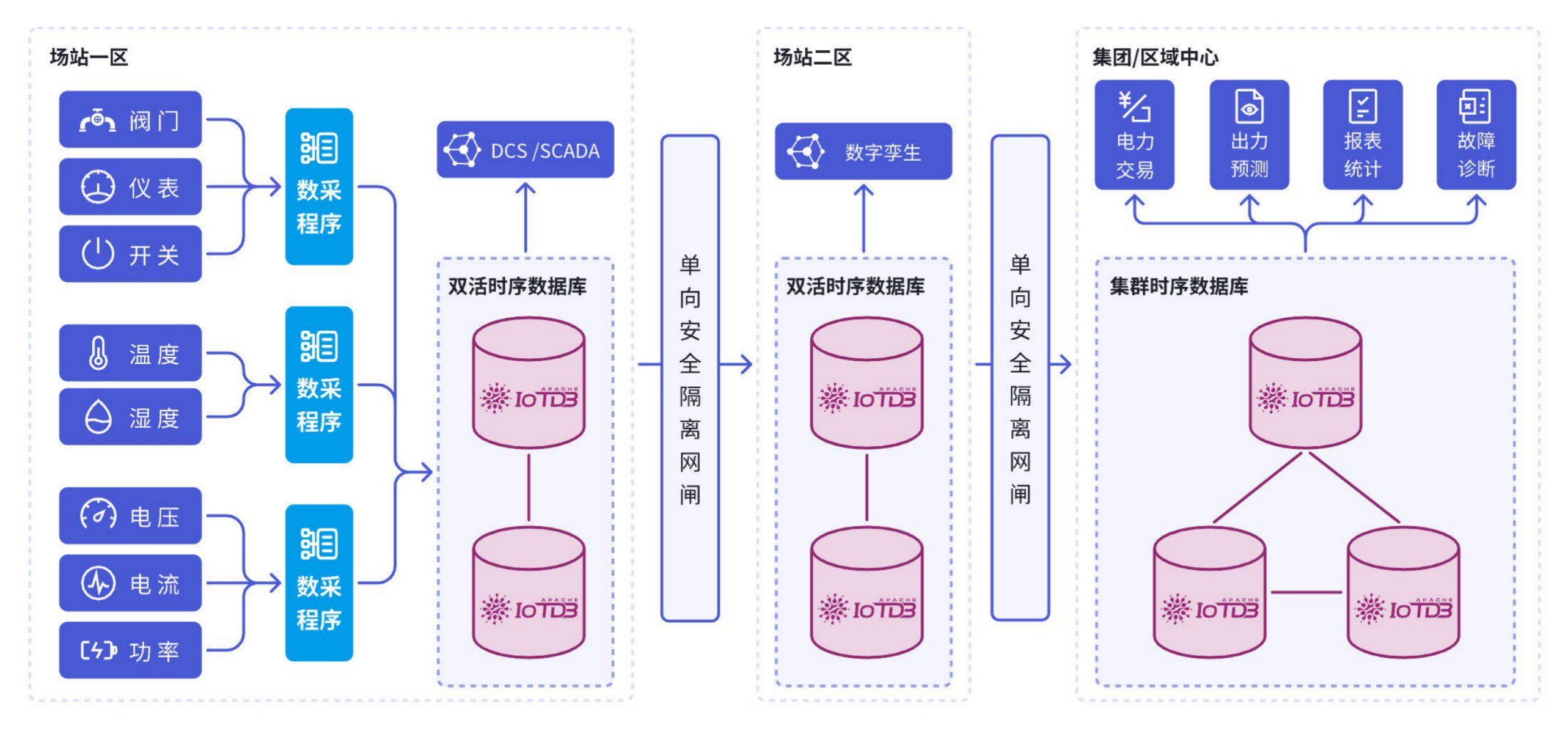
TsFile的设计充分考虑了时序数据的访问模式。数据按照时间顺序写入,自然形成了时间局部性。同时,通过设备维度的组织,保证了单设备查询的高效性。这种设计使得IoTDB在处理高并发写入的同时,依然能够提供优秀的查询性能。
// TsFile的核心数据结构示例public class TsFileSequenceReader { private Map<String, TsFileMetadata> deviceMetadataMap; private BloomFilter bloomFilter; private List<ChunkGroupMetadata> chunkGroupMetadataList;}IoTDB的存储格式针对时序数据进行了深度优化。ChunkGroup按设备组织,Chunk按测点组织,Page是实际的数据页。这种层次化的组织结构既保证了数据的紧凑存储,又支持高效的随机访问。
2. 多级存储与数据生命周期管理
IoTDB提供了完善的多级存储解决方案,能够根据数据的访问频率和重要程度自动进行数据分层。热数据保存在高性能SSD中,温数据迁移到大容量SATA盘,冷数据则可以压缩后存储到低成本的对象存储中。
数据生命周期管理不仅仅是简单的数据迁移,更包括智能的数据采样和聚合。IoTDB支持多级采样策略,可以将原始数据按照不同的时间窗口进行预聚合,既保证了历史数据的可用性,又显著降低了存储成本。
-- IoTDB的TTL和分层存储配置SET TTL TO root.factory.workshop01.** 365d;CREATE CONTINUOUS QUERY cq1 AS SELECT avg(temperature) INTO avg_temp_1h FROM root.factory.workshop01.device01GROUP BY time(1h) FILL(linear);这种分层存储机制在实际应用中效果显著。一个典型的工业物联网项目,通过合理的数据分层策略,可以将存储成本降低80%以上,同时保证查询性能不受明显影响。
3. 企业级高可用与容灾能力
IoTDB在企业级可用性方面下足了功夫。其分布式架构支持多副本部署,通过Raft一致性协议保证数据的强一致性。即使在网络分区或节点宕机的情况下,系统依然能够提供服务。
故障恢复能力是IoTDB的另一个亮点。系统支持增量备份和点对点恢复,能够在最短时间内恢复服务。WAL (Write-Ahead Logging) 机制保证了数据的持久性,即使在突然断电的情况下也不会丢失数据。
集群管理功能让大规模部署成为可能。IoTDB提供了完善的监控体系和自动化运维工具,支持动态扩容、负载均衡、故障转移等企业级特性。
四、开发者友好的接口生态
1. 丰富的原生接口支持
IoTDB提供了业界最为丰富的客户端接口支持,覆盖了企业开发中的主流编程语言。从传统的Java、C++到现代的Python、Go,从企业级的C#到前端的Node.js,IoTDB都提供了原生的接口实现。这种全面的语言支持大大降低了企业的技术迁移成本,让不同技术栈的团队都能够快速上手。
Python接口作为数据科学和AI领域的首选,IoTDB提供了特别完善的支持。除了基本的CRUD操作外,还深度集成了Pandas生态,支持将查询结果直接转换为DataFrame,为数据分析师提供了无缝的工作体验。
from iotdb.Session import Sessionimport pandas as pd# 创建连接session = Session(\"127.0.0.1\", \"6667\", \"root\", \"root\")session.open(False)# 执行查询并转换为DataFrameresult = session.execute_query_statement(\"SELECT temperature, pressure FROM root.factory.**\")df = result.todf()# 直接进行数据分析temperature_stats = df[\'temperature\'].describe()session.close()2. 企业级连接池管理
在高并发的生产环境中,连接管理是影响系统性能的关键因素。IoTDB提供了企业级的连接池管理机制,通过SessionPool实现连接的智能复用和负载均衡。连接池支持动态扩缩容、健康检查、故障转移等企业级特性,确保在复杂网络环境下的稳定运行。
from iotdb.SessionPool import PoolConfig, SessionPool# 配置连接池参数pool_config = PoolConfig( host=\"127.0.0.1\", port=\"6667\", user_name=\"root\", password=\"root\", fetch_size=1024, time_zone=\"UTC+8\", max_retry=3)# 创建连接池session_pool = SessionPool(pool_config, max_pool_size=10, wait_timeout_in_ms=5000)# 使用连接池session = session_pool.get_session()# 执行业务操作...session_pool.put_back(session)3. 高性能批量写入机制
针对时序数据高频写入的特点,IoTDB设计了多种优化的批量写入接口。Tablet接口通过按设备组织数据,大幅提升写入效率;NumpyTablet则进一步利用NumPy的高性能数组操作,在内存占用和序列化性能上实现了显著优化。
实际测试中,使用NumpyTablet相比传统的Record写入方式,性能提升可达到5-10倍,内存占用减少60%以上。这种性能优势在大规模IoT数据采集场景中尤为明显。
import numpy as npfrom iotdb.utils.NumpyTablet import NumpyTabletfrom iotdb.utils.TSDataType import TSDataType# 使用NumPy构建高性能数据写入np_values = [ np.array([25.5, 26.1, 24.8], TSDataType.FLOAT.np_dtype()), np.array([1013.2, 1012.8, 1014.1], TSDataType.DOUBLE.np_dtype())]np_timestamps = np.array([1640995200000, 1640995260000, 1640995320000], TSDataType.INT64.np_dtype())tablet = NumpyTablet(\"root.factory.device01\", [\"temperature\", \"pressure\"], [TSDataType.FLOAT, TSDataType.DOUBLE], np_values, np_timestamps)session.insert_tablet(tablet)这种完整的开发者生态体系,不仅降低了IoTDB的使用门槛,更重要的是为企业的长期技术演进提供了坚实基础。无论是从单体应用到微服务架构的演进,还是从传统部署到云原生的转型,IoTDB都能提供平滑的迁移路径和持续的技术支持。
下载链接:https://iotdb.apache.org/zh/Download/
企业版官网链接:https://timecho.com
选择合适的时序数据库,就是为企业的数字化未来做出的重要投资。在这个关键决策中,Apache IoTDB无疑是一个值得深入考虑的选择。其丰富的接口生态、企业级的功能特性、以及持续演进的技术路线,都为企业的数字化转型提供了强有力的技术保障。


