【云计算】裸金属 vs 虚拟机 vs 容器部署_裸金属部署
一、裸金属部署
1.1 内核调优
在裸金属部署中针对突发型流量(如秒杀、登录认证)和稳定型流量(如数据库、流媒体)进行差异化内核调优,需从连接管理、内存策略、中断处理等维度进行精细化配置。以下是具体优化方案:
1.1.、突发型流量优化(短时高并发冲击)
适用场景:RADIUS认证、HTTP API请求、支付回调等
1. TCP连接快速回收与重用
# /etc/sysctl.conf# 快速回收TIME_WAIT连接(激进模式)net.ipv4.tcp_tw_recycle = 1 # 注意:公网NAT环境禁用此参数!net.ipv4.tcp_tw_reuse = 1 # 允许复用TIME_WAIT连接net.ipv4.tcp_fin_timeout = 5 # FIN超时降至5秒# 扩大连接跟踪表net.netfilter.nf_conntrack_max = 2000000net.nf_conntrack_max = 2000000原理:缩短连接生命周期,避免连接池耗尽
风险提示:tcp_tw_recycle在客户端经过NAT时可能导致丢包,需在内网部署。
2. SYN洪水防御与加速握手
net.ipv4.tcp_syncookies = 1 # SYN队列溢出时启用Cookie防护net.ipv4.tcp_max_syn_backlog = 16384 # 扩大SYN半连接队列net.ipv4.tcp_synack_retries = 1 # SYN-ACK重试次数降为1次net.ipv4.tcp_abort_on_overflow = 0 # 队列满时不拒绝连接(依赖Syncookies)作用:抵御突发SYN洪水攻击,降低握手延迟30%+
3. 内存池动态伸缩
# 启用内存过量分配(OOM风险需配套cgroup限制)vm.overcommit_memory = 1 # 扩大Page Cache回收阈值vm.min_free_kbytes = 2097152 # 预留2GB内存避免OOMvm.vfs_cache_pressure = 200 # 激进回收目录缓存1.1.2、稳定型流量优化(持续高吞吐)
适用场景:数据库集群、视频流传输、大数据传输
1. 大流量连接长保持
# 禁用TIME_WAIT快速回收(避免断连)net.ipv4.tcp_tw_recycle = 0# 增大保活探测频次net.ipv4.tcp_keepalive_time = 1800 # 30分钟探测一次net.ipv4.tcp_keepalive_probes = 5 # 探测失败5次后断开2. 零拷贝与巨型帧优化
# 启用零拷贝技术(网卡需支持)net.ipv4.tcp_mem = 94500000 915000000 927000000 # 扩大TCP内存窗口net.core.rmem_default = 16777216 # 默认接收缓冲区16MBnet.ipv4.tcp_window_scaling = 1 # 启用窗口扩展# 启用巨型帧(需交换机配合)ifconfig eth0 mtu 9000硬件配合:
- 网卡启用
TSO/GRO卸载 - 交换机配置Jumbo Frame(MTU 9000)
3. NUMA亲和性绑定
# 将网卡中断绑定到同NUMA节点CPUirqbalance --oneshotfor irq in $(grep eth0 /proc/interrupts | awk -F: \'{print $1}\'); do echo 8 > /proc/irq/$irq/smp_affinity # CPU Mask绑定到Core0-2done# 进程NUMA绑定numactl --cpunodebind=0 --membind=0 /path/to/service作用:减少跨NUMA内存访问延迟,提升吞吐量15%-25%
1.1.3、混合流量调度策略
当业务同时存在突发+稳定流量时:
1. cGroup优先级隔离
# 为突发型服务分配更高CPU权重cgcreate -g cpu:/burst-trafficecho 512 > /sys/fs/cgroup/cpu/burst-traffic/cpu.shares# 为稳定型服务预留内存cgcreate -g memory:/stable-trafficecho \"10G\" > /sys/fs/cgroup/memory/stable-traffic/memory.low2. 网络QoS分级
# 使用tc划分流量优先级(示例:对UDP 1812优先级最高)tc qdisc add dev eth0 root handle 1: htbtc class add dev eth0 parent 1: classid 1:10 htb rate 10Gbit ceil 10Gbit prio 0 # 最高优先级tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 1812 0xffff flowid 1:103. 中断动态均衡
# 突发流量启用RPS(Receive Packet Steering)echo ffff > /sys/class/net/eth0/queues/rx-0/rps_cpus # 分发到所有CPU核# 稳定流量启用RFS(Receive Flow Steering)echo 32768 > /proc/sys/net/core/rps_sock_flow_entriesecho 4096 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt1.1.4、配置差异对比表
tcp_tw_reuse=1(激进回收)tcp_tw_reuse=0(保持稳定)关键注意事项
-
参数冲突规避:
- 不可同时启用:
tcp_tw_recycle(公网环境禁用)与tcp_tw_reuse - 内存过载防护:
vm.overcommit_memory=1时需配合cgroup memory硬限制
- 不可同时启用:
-
压测验证方法:
# 突发流量模拟(10万并发)httperf --server=10.0.0.1 --port=80 --uri=/api --num-conns=100000 --rate=5000# 稳定流量压测(持续10Gbps)iperf3 -c 10.0.0.2 -t 600 -P 32 -b 10G -
动态调参工具链:
- Ansible剧本:根据业务峰值自动切换内核参数组
- eBPF脚本:实时监控
tcp_v4_do_rcv事件,动态调整tcp_max_syn_backlog
最终优化效果:突发型流量场景下单节点新建连接速率可提升至 5万/秒,稳定型流量的长连接带宽利用率可达 98% 以上。务必结合业务流量模型进行灰度验证!
1.2 配置和优化
裸金属部署的全面优化方案,涵盖硬件配比、内核调优、进程优化及底层编程模型,支撑高并发场景:
1.2.1、硬件资源黄金配比方案(支撑2000万并发)
配比公式:Nodes = \\frac{Total\\_connections}{2 \\times 10^6} \\quad (单节点承载200万并发)
1.2.2、内核深度调优参数
1. 网络协议栈优化
# TCP连接管理(突发流量)net.ipv4.tcp_tw_reuse = 1 # 快速复用TIME_WAITnet.ipv4.tcp_fin_timeout = 5 # FIN超时(秒)# 大流量吞吐优化(稳定流量)net.core.rmem_max = 268435456 # 256MB接收窗口net.ipv4.tcp_window_scaling = 1net.core.netdev_max_backlog = 300000# 防御性设置net.netfilter.nf_conntrack_max = 20000002. I/O子系统优化
# 块设备调度echo deadline > /sys/block/nvme0n1/queue/schedulerecho 0 > /sys/block/nvme0n1/queue/rotational# NVMe驱动参数echo 1024 > /sys/class/block/nvme0n1/queue/nr_requestsecho 1 > /sys/class/block/nvme0n1/queue/wc # 写缓存开启3. 内存与Swap策略
vm.swappiness = 5 # 最小化Swap使用vm.dirty_ratio = 10 # 系统脏页占比阈值vm.dirty_background_ratio = 3 # 后台回写阈值vm.nr_hugepages = 131072 # 分配256GB大页内存(每页2MB)1.2.3、进程/线程模型优化
1. 并发架构选型
MaxRequestWorkers = CPU核心数*4(I/O延迟/CPU处理时间)*核心数2. 关键配置示例(FreeRADIUS)
# radiusd.confworkers_per_server = 128 # 匹配CPU核心数max_requests = 100000 # 防内存泄漏thread_stack_size = 2M # 避免栈溢出use_epoll = yes # 启用事件驱动模型3. CPU亲和性绑定
# 将进程绑定至指定NUMA节点taskset -c 0-63,128-191 radiusd# 中断均衡(避免软中断集中在CPU0)echo f > /proc/irq/92/smp_affinity # 分配到第0-3核1.2.4、任务调度与指针操作优化
1. 任务调度策略
// 实时任务优先级设置(SCHED_FIFO)struct sched_param param = { .sched_priority = 99 };pthread_setschedparam(pthread_self(), SCHED_FIFO, ¶m);2. 无锁数据结构
// 使用原子操作替代锁(CAS指令)__atomic_compare_exchange(ptr, &oldval, newval, 0, __ATOMIC_ACQ_REL, __ATOMIC_ACQUIRE);3. 指针访问优化
// 内存对齐访问(减少Cache Miss)struct __attribute__((aligned(64))) RadiusPacket { uint8_t code; uint8_t ident; // ... // 确保结构体64字节对齐};// 预取数据(降低访问延迟)__builtin_prefetch(&packet[offset], 0, 3);1.2.5、全链路性能监控方案
1. 核心指标采集
tcp_retransmit_skb, nvme_irq_latency2. 实时诊断命令
# 软中断分布监控watch -n 1 \"grep NET /proc/softirqs\"# 内存访问热点分析perf top -e cache-misses -p `pidof radiusd`# PCIe带宽利用率nvidia-smi nvlink --bandwidth1.2.6、总结:优化实施路径
- 硬件选型:按 1CPU:4 SSD:200GbE网卡:8GB/核心内存 配比
- 内核调优:
- 网络:大窗口+快速回收
- I/O:Deadline调度+大队列深度
- 内存:大页预分配+积极回收
- 进程模型:
- 绑定NUMA节点
- Epoll事件驱动+线程池分离认证/计费
- 编程优化:
- 内存对齐访问+无锁数据结构
- 原子操作替代互斥锁
- 动态监控:eBPF跟踪内核态瓶颈,IPMI预警硬件故障
压测验证标准:在200万并发下,单节点需满足 ≤50ms平均延迟 & ≥5000 TPS,PCIe带宽利用率≥85%。需持续优化线程池模型与内存回收策略。
二、虚拟机部署
2.1 内核优化
在虚拟机部署中,针对突发型流量(如秒杀、瞬时高并发请求)和稳定型流量(如数据库、流媒体传输),需通过差异化的内核参数调优优化资源调度、连接管理和I/O性能。以下是具体方案:
2.1.1、核心优化维度对比
SCHED_FIFO)、弹性频率调节CFS)、绑核固定频率vm.swappiness=60)、zRAM压缩vm.nr_hugepages)、预留内存tcp_tw_reuse=1)、小缓冲区net.core.rmem_max=16MB)、长连接保活2.1.2、详细调优配置
1. CPU调度优化
- 突发型流量(如API网关):
# 启用实时调度,减少上下文切换echo SCHED_FIFO > /sys/block/sda/queue/scheduler# 动态调频(按需模式)echo ondemand > /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor[1,2](@ref)- 作用:优先处理突发请求,避免任务堆积。
- 稳定型流量(如数据库):
# 绑定vCPU至物理核,提升缓存命中率virsh vcpupin 0 2-4 # 绑定vCPU0到物理核2-4[2](@ref)# 固定高性能频率echo performance > /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor- 作用:避免跨核切换,保障计算密集型任务稳定性。
2. 内存管理策略
- 突发型流量:
# 启用zRAM压缩,应对瞬时内存压力echo 1 > /sys/module/zswap/parameters/enabledecho 60 > /proc/sys/vm/swappiness # 积极使用Swap[1,6](@ref) - 稳定型流量:
# 分配2MB大页内存,减少TLB Missecho 2048 > /proc/sys/vm/nr_hugepages# 预留内存防抢占virsh setmem --config --size 16G --guaranteed[2,6](@ref)
3. 网络协议栈调优
- 突发型流量:
# 快速回收端口,支持高并发短连接echo 1 > /proc/sys/net/ipv4/tcp_tw_reuseecho 5 > /proc/sys/net/ipv4/tcp_fin_timeout # 缩短FIN等待[1,3](@ref) - 稳定型流量:
# 增大TCP窗口,提升长连接吞吐量echo \"16777216\" > /proc/sys/net/core/rmem_maxecho \"600\" > /proc/sys/net/ipv4/tcp_keepalive_time # 保活探测[3,4](@ref)
4. 磁盘I/O策略
- 突发型流量(日志写入):
# Noop调度器 + Writeback缓存(SSD适用)echo noop > /sys/block/sda/queue/scheduler # 虚拟机XML配置[2,6](@ref)- 效果:减少I/O调度延迟,容忍短暂数据不一致。
- 稳定型流量(数据库存储):
# Deadline调度器 + Writethrough缓存echo deadline > /sys/block/sdb/queue/scheduler # 确保写操作落盘[2,6](@ref)
2.1.3、混合流量调度策略
当业务同时存在突发型与稳定型流量时,需分层隔离:
- cGroup资源隔离:
# 突发型:高CPU权重,低内存限制echo 512 > /sys/fs/cgroup/cpu/burst_group/cpu.sharesecho 4G > /sys/fs/cgroup/memory/burst_group/memory.limit_in_bytes# 稳定型:预留内存,中等CPU权重echo 8G > /sys/fs/cgroup/memory/stable_group/memory.min[3](@ref) - 网络QoS分级:
# 突发型流量优先级最高(DSCP 46)tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dport 80 0xffff flowid 1:10# 稳定型流量保障带宽(10Gbps)tc class add dev eth0 parent 1: classid 1:20 htb rate 10Gbit[5](@ref)
2.1.4、调优效果验证与监控
- 压测工具:
- 突发型:
wrk -t 32 -c 1000 -d 60s http://service(模拟瞬时并发) - 稳定型:
fio --rw=read --bs=128k --iodepth=32(持续I/O压力测试)
- 突发型:
- 监控指标:
流量类型 关键指标 达标阈值 突发型 TCP新建连接数、请求延迟P99 连接数 > 5k/秒,P99 < 100ms 稳定型 网络吞吐量、磁盘IOPS 吞吐量 > 8Gbps,IOPS > 50k - 动态调参工具:
- eBPF脚本:实时检测
tcp_v4_connect事件,自动扩展端口范围 - Ansible剧本:根据
vmstat输出动态调整vm.swappiness
- eBPF脚本:实时检测
总结:实施路径
- 分类识别:通过监控区分流量类型(如Prometheus抓取请求模式)。
- 分层调优:
- CPU:突发型用实时调度,稳定型用绑核+性能模式
- 内存:突发型启用zRAM,稳定型分配大页内存
- 隔离保障:cGroup限制突发型资源,QoS优先保障稳定型带宽
- 迭代验证:每轮调优后使用针对性压测,持续优化参数。
注:虚拟化环境下需同步优化宿主机(如ESXi启用透明大页、KVM配置NUMA亲和性)。
2.2 配置逻辑
以下是针对虚拟机部署场景的全面优化方案,涵盖硬件配比、内核调优、进程优化及编程层级优化,结合虚拟化特性深度定制:
2.2.1、虚拟机硬件黄金配比方案(支撑百万级并发)
计算公式:
\\text{VM数量} = \\frac{\\text{物理核数} \\times \\text{超线程比}}{4} \\quad (\\text{预留25\\%资源缓冲})2.2.2、虚拟机内核调优参数
1. CPU调度优化
# ESXi/KVM宿主机echo 1 > /sys/module/kvm/parameters/vcpu_preempt_timerecho \"isolcpus=8-15\" >> /etc/default/grub # 隔离物理核给VM# 客户机内部sysctl -w kernel.sched_migration_cost_ns=5000000 # 减少迁移开销sysctl -w kernel.sched_latency_ns=40000000 # 调度周期延长2. 内存虚拟化优化
# KVM宿主机 1048576 # 1GB大页 # 客户机内部sysctl -w vm.zone_reclaim_mode=0 # 禁用内存区回收sysctl -w vm.page-cluster=0 # 降低预读页数3. I/O栈虚拟化加速
# QEMU磁盘配置-drive if=none,id=drive0,cache.direct=on,discard=unmap,format=qcow2 \\-device virtio-blk-pci,drive=drive0,iothread=iothread0# 客户机内部echo 0 > /sys/block/vda/queue/add_randomecho deadline > /sys/block/vda/queue/scheduler4. 网络虚拟化性能
# 开启vhost-net加速 # 客户机优化sysctl -w net.core.netdev_max_backlog=500000sysctl -w net.core.somaxconn=655352.2.3、虚拟机进程/线程优化策略
1. vCPU绑定技术
# KVM绑定vCPU到物理核virsh vcpupin vm1 0 10,11 # vCPU0绑定到物理核10-11virsh vcpupin vm1 1 12,13# 进程NUMA绑定numactl --cpunodebind=0 --membind=0 /path/service2. I/O线程异步模型
// 使用libaio异步I/Ostruct io_context *ctx;io_setup(128, &ctx); // 128深度队列struct iocb cb = { .aio_fildes = fd, .aio_lio_opcode = IOCB_CMD_PREAD };io_submit(ctx, 1, &cb);3. 虚拟中断优化
# 分配中断到特定vCPUecho 0-3 > /proc/irq/24/smp_affinity_list # 绑定到vCPU0-3echo 4-7 > /proc/irq/25/smp_affinity_list# 检查中断均衡watch -n 1 \'cat /proc/interrupts | grep virtio\'4. 轻量级线程池
// Golang协程池实现package mainimport ( \"sync\")var workerPool = make(chan struct{}, 1024) // 1024并发协程func handleRequest(req *Request) { workerPool <- struct{}{} // 获取令牌 defer func() { <-workerPool }() // 处理逻辑}2.2.4、虚拟机指针与内存优化
1. 内存零拷贝技术
// 使用splice减少数据拷贝ssize_t spliced = splice(src_fd, NULL, pipefd[1], NULL, 4096, 0);splice(pipefd[0], NULL, dst_fd, NULL, spliced, 0);// virtio-net零拷贝ioctl(fd, VIRTIO_NET_HDR_ZEROCOPY, 1);2. 指针访问优化
struct __attribute__ ((aligned(64))) Packet { uint8_t header[20]; uint32_t *payload __attribute__((aligned(64)));};// 预取优化for(int i=0; i<count; i+=16) { __builtin_prefetch(&data[i+16], 0, 3); }3. RCU无锁访问
// 读-复制更新技术void reader() { rcu_read_lock(); struct data *d = rcu_dereference(global_ptr); rcu_read_unlock();}void updater() { struct data *new = malloc(...); rcu_assign_pointer(global_ptr, new); synchronize_rcu(); // 等待所有读者退出 free(old); }2.2.5、全链路监控诊断方案
1. 虚拟化层监控工具
esxtop / virsh domstats%RDY(就绪时间), %MLMTD(CPU等待)perf kvmkvm_exit原因分析 (如HLT/IOIO/MSR)vmware-toolbox-cmd2. 性能热点定位
# KVM客户机内部分析perf kvm --host --guest record -aperf kvm --host --guest report# QEMU跟踪点trace-event virtio_net* on3. 动态参数调整
# 根据负载自动调整内存virsh setmem $DOMAIN --size $(calc_memory) --live# 网络突发带宽tc qdisc change dev vnet0 root tbf rate 1gbit burst 10mb latency 50ms2.2.6、虚拟机优化实施路径
-
硬件准备
- CPU:开启Intel VT-d/AMD-Vi
- BIOS:启用NUMA、SR-IOV、VT-x
- 存储:配置NVMe-oF共享存储池
-
虚拟化层配置
- KVM: 启用透明大页
echo always > /sys/kernel/mm/transparent_hugepage/enabled - ESXi: 开启.NetQueue和PVSPANIC
- KVM: 启用透明大页
-
客户机部署
# cloud-init优化配置bootcmd: - echo 0 > /sys/devices/system/cpu/cpufreq/boost # 禁用boost - ethtool -K eth0 tx-checksum-ip-generic on -
持续调优
- 每周运行
kvm-perf-events分析退出原因 - 实时监控Balloon内存回收压力
- 每周运行
最终指标:在32vCPU/256GB内存VM上,实现50K+ TPS处理能力,网络转发延迟<100μs,存储IOPS>500K。关键要点是减少VM-Exit次数和DMA拷贝开销。
2.3 配置优化逻辑
- 硬件配比建议
- Hypervisor通用优化原则
- 针对每种Hypervisor的具体优化(KVM, XEN, VMWARE, Hyper-V)
- 虚拟机的操作系统内核调优(以Linux为例,因为高并发场景通常运行Linux)
- 进程优化和底层编程模型
- 高并发网络优化
注意:不同Hypervisor的优化可能有所不同,我们将分别说明。
一、硬件配比建议(针对高并发场景)
目标:支持100K以上并发连接(如Web服务器、代理服务器等)
-
CPU:
- 核心数量:根据并发连接的处理需求,通常每个核心可以处理数千个连接(取决于应用)。建议至少16核心,最好32核心或更多。
- 频率:高频率有助于减少延迟,但核心数更重要。
- 推荐:AMD EPYC或Intel Xeon Scalable系列,支持超线程和大量核心。
-
内存:
- 每个并发连接的内存占用:取决于应用,例如:
- 轻量级服务(如Nginx):每个连接约几KB到几十KB
- 数据库等:每个连接可能需要几百KB到几MB
- 总内存 = 连接数 * 每个连接的内存占用 + 操作系统和Hypervisor开销
- 示例:100K连接,每个连接300KB,需要大约30GB内存(仅应用)。加上系统和Hypervisor,建议64GB起步,根据应用需求增加。
- 每个并发连接的内存占用:取决于应用,例如:
-
网络:
- 网卡:至少10Gbps(万兆),最好25Gbps或更高。使用多队列网卡(如Intel 82599/XL710, Mellanox ConnectX-5)。
- 建议使用SR-IOV技术,将网卡虚拟化给虚拟机,减少Hypervisor的网络开销。
-
存储:
- 使用SSD或NVMe磁盘,建议RAID10或RAID5(根据性能需求)。对于Hypervisor的存储,建议使用本地SSD或高速SAN/NAS。
- 对于虚拟机的磁盘,使用virtio-blk(KVM)或类似的半虚拟化驱动。
-
NUMA架构:
- 启用NUMA,将虚拟机绑定到特定的NUMA节点,减少跨节点访问内存的延迟。
二、Hypervisor通用优化原则
- 使用最新稳定版的Hypervisor软件。
- 为每个虚拟机分配足够的资源(CPU、内存),并预留一定的资源用于突发情况。
- 使用半虚拟化驱动(如virtio)以提高I/O性能。
- 避免资源过载(overcommit),特别是在CPU和内存方面。
- 对性能要求高的虚拟机,使用独占CPU(pCPU)和绑定。
三、针对不同Hypervisor的具体优化
-
KVM:
- 内核引导参数优化(在Host上):
- 启用HugePages:减少TLB miss,提高内存访问效率。例如在grub中设置
default_hugepagesz=1G hugepagesz=1G hugepages=16(预留16个1G大页) - 隔离CPU核心:使用
isolcpus=2-15(将核心2-15隔离出来,供虚拟机使用) - 其他:
nohz=on,rcu_nocbs=2-15,intel_pstate=disable(如果使用Intel CPU)
- 启用HugePages:减少TLB miss,提高内存访问效率。例如在grub中设置
- 启用KSM(Kernel Samepage Merging)合并相同内存页,但注意在内存充足时关闭以避免性能开销。
- 虚拟机的XML配置优化:
- CPU模式设置为
host-passthrough或host-model - 使用virtio-net和vhost_net(将网络数据包处理offload到内核线程)
- 设置多队列virtio-net:
(根据虚拟机的vCPU数量设置,一般一个队列对应一个vCPU) - 设置IO线程和调度程序:使用
none或deadline调度器 - 使用VirtIO-SCSI代替VirtIO-blk,并启用IO线程
- CPU模式设置为
- 内核引导参数优化(在Host上):
-
XEN:
- 使用PV(半虚拟化)或PVHVM模式,避免全虚拟化(HVM)的开销。
- 在Dom0中,限制资源使用(Dom0只需要少量资源)。
- 在Dom0中,使用网络后端驱动(netback)和块后端驱动(blkback)的多队列。
- 设置虚拟机使用PV驱动。
-
VMware ESXi:
- 安装VMware Tools(或Open VM Tools)。
- 使用VMXNET3网卡驱动(半虚拟化)。
- 启用巨帧(Jumbo Frames): 9000字节。
- 存储方面:使用Paravirtual SCSI (PVSCSI) 控制器。
- CPU:为虚拟机设置性能计数器(expose performance counters)和硬件虚拟化(HV)支持。
- 内存:使用透明大页(Transparent Huge Pages)和内存预留。
-
Hyper-V:
- 使用第二代虚拟机(支持UEFI启动和更快的启动时间)。
- 使用Synthetic网络适配器(半虚拟化)和SR-IOV(如果支持)。
- 启用虚拟机队列(VMQ)和IPSec offload。
- 存储:使用SCSI控制器(半虚拟化)和VHDX格式。
- 集成服务:启用最新的集成服务。
四、虚拟机的操作系统内核调优(以Linux为例,适用于任何Hypervisor上的Linux虚拟机)
目标:支持100K以上并发连接(主要针对网络栈优化)
-
增加文件描述符限制:
- 系统级:
fs.file-max = 1000000 - 用户级:在
/etc/security/limits.conf中设置nofile限制
- 系统级:
-
网络栈优化:
- 增加TCP连接跟踪表大小:
net.netfilter.nf_conntrack_max = 1048576 - 避免连接跟踪溢出:
net.ipv4.netfilter.ip_conntrack_count应该小于nf_conntrack_max - TCP端口范围:
net.ipv4.ip_local_port_range = 1024 65535 - 启用TIME_WAIT复用:
net.ipv4.tcp_tw_reuse = 1 - 减少FIN-WAIT-2超时:
net.ipv4.tcp_fin_timeout = 15 - 减少SYN半开连接超时:
net.ipv4.tcp_synack_retries = 3 - 启用TCP快速打开(TFO):
net.ipv4.tcp_fastopen = 3 - 启用BBR拥塞控制:
net.ipv4.tcp_congestion_control = bbr - 增加套接字缓冲区:
net.core.rmem_max=16777216,net.core.wmem_max=16777216,net.ipv4.tcp_rmem=\"4096 87380 16777216\",net.ipv4.tcp_wmem=\"4096 87380 16777216\" - 最大待处理套接字连接数:
net.core.somaxconn = 32768 - 最大待处理SYN连接数:
net.ipv4.tcp_max_syn_backlog = 8192 - 使用最多数量的文件句柄:
net.core.fs.file-max = 1000000
- 增加TCP连接跟踪表大小:
-
内存优化:
- 调整脏页写回:
vm.dirty_ratio=15,vm.dirty_background_ratio=10 - 调整Swappiness:
vm.swappiness=10
- 调整脏页写回:
-
进程优化:
- 调整系统最大进程数:
kernel.pid_max=4194304 - 允许更多PID:
kernel.threads-max=32768
- 调整系统最大进程数:
五、进程优化和底层编程模型
- 应用程序设计:
- 使用事件驱动或异步I/O模型(如epoll、libevent、Boost.Asio等)。
- 避免阻塞操作,使用线程池或协程(如goroutine)处理并发。
- 使用多进程/多线程:
- 每个核心一个进程/线程(或使用work-stealing算法)。
- 确保进程/线程绑定到CPU核心(减少上下文切换)。
- 数据库优化:
- 使用连接池,避免频繁创建和关闭连接。
- 优化查询和索引。
- 编程语言选择:
- 高性能场景建议使用C/C++、Rust、Go等编译型语言。
- 使用解释型语言(如Python)可考虑用PyPy或C扩展优化关键路径。
六、高并发网络优化
- 网卡:
- 使用多队列网卡(RSS),并为每个队列分配一个CPU核心。
- 启用中断合并(Interrupt coalescing)以减少中断次数。
- 使用用户态网络栈(如DPDK、XDP)绕过内核,适用于对延迟要求极高的场景。
- 负载均衡:
- 使用多级负载均衡(如LVS+HAProxy+Nginx)。
- 在应用层实现分片(如一致性哈希)以减少竞争。
最后,针对100K并发连接,实际性能取决于具体应用。建议使用压力测试工具(如wrk, Apache Bench, JMeter)模拟并发连接,然后逐步调整参数。
请注意:以上优化需要根据实际硬件、软件环境进行调整,建议在测试环境中验证后再上线生产环境。
2.4 虚拟机部署全面优化方案(支撑100K+并发连接)
2.4.1、硬件配比黄金方案
通用硬件基准(每计算节点)
配比公式:
\\text{节点数} = \\frac{\\text{总并发连接数}}{10\\text{K} \\times \\text{vCPU数} \\times \\text{利用率系数}(0.7)}2.4.2、Hypervisor优化指南
跨平台通用优化
+ 启用NUMA亲和性绑定+ 配置巨页(1GB Hugepages)+ 启用硬件辅助虚拟化(Intel VT-d/AMD-Vi)- 禁用超线程(确定性延迟场景)Hypervisor专项优化
virsh edit : 128xl create config.cfg -p \"cpus=\'0-15\' mem=64G\"passthrough=[\'00:1a.0\',\'00:1b.0\']esxcli system module set -m=vmxnet3 -e=TSO,LSOMRUMem.MemZipEnable=1 Mem.MemZipMaxPFN=800000Set-VMNetworkAdapter -VMName -IovWeight 100Set-VMProcessor -VMName -HwThreadCountPerCore 12.4.3、操作系统内核调优(基于Linux)
网络堆栈优化
# /etc/sysctl.conf# 连接管理net.core.somaxconn = 65535net.core.netdev_max_backlog = 500000net.ipv4.tcp_max_syn_backlog = 262144net.ipv4.tcp_syncookies = 1net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_fin_timeout = 15# 大并发内存net.core.rmem_max = 134217728net.core.wmem_max = 134217728net.ipv4.tcp_rmem = 4096 87380 134217728net.ipv4.tcp_wmem = 4096 65536 134217728net.ipv4.tcp_mem = 786432 1697152 194304# 拥塞控制net.ipv4.tcp_congestion_control = bbrnet.ipv4.tcp_slow_start_after_idle = 0中断与调度优化
# 启用RPS/RFS(替代多队列)echo ffffff > /sys/class/net/eth0/queues/rx-0/rps_cpusecho 32768 > /proc/sys/net/core/rps_sock_flow_entriesecho 4096 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt# CPU隔离与调度isolated_cores=0-15systemctl set-property --runtime -- user.slice AllowedCPUs=$isolated_coresecho deadline > /sys/block/nvme0n1/queue/scheduler2.4.4、进程/线程优化模型
并发架构选型
模型
适用场景
优化要点
100K并发实现
EPOLL+协程
HTTP代理/网关
单进程事件驱动
Nginx: worker_processes auto; worker_connections 50000;
线程池
计算密集型
Worker=vCPU核数
Java: -XX:ActiveProcessorCount=32
共享内存
高频数据交换
无锁环形队列
DPDK rte_ring + 原子操作
高性能编程要点
// 无锁环形缓冲区实现struct rte_ring *ring = rte_ring_create(\"msg_ring\", 1048576, rte_socket_id(), RING_F_SP_ENQ|RING_F_SC_DEQ);// 内存池预分配rte_mempool *pool = rte_pktmbuf_pool_create(\"mbuf_pool\", NB_MBUF, MEMPOOL_CACHE_SZ, 0, RTE_MBUF_DEFAULT_BUF_SIZE, rte_socket_id());// NUMA绑核rte_thread_set_affinity(&thread, (1 << core_id));2.4.5、平台专有优化方案
KVM极限优化
1048576 VMware 网络加速
# ESXi主机优化esxcli system settings advanced set -o /Net/TcpipHeapSize -i 64esxcli system settings advanced set -o /Net/TcpipHeapMax -i 1536esxcli network ip set -t 9000# VMX参数ethernet0.uptCompatibility = \"TRUE\"ethernet0.ringSize = \"4096\"monitor_control.restrict_backdoor = \"TRUE\"2.4.6、监控与调优验证
压测工具链
# 网络压测wrk -t 32 -c 100000 -d 300s -s pipeline.lua http://target --latency# 连接建立测试syn_flood -d -p 80 -c 200000 -s 10000# 实时监控nmon -s 1 -c 300 -f # 系统资源perf top -p # 进程热点关键性能指标
2.4.7、全栈优化框架
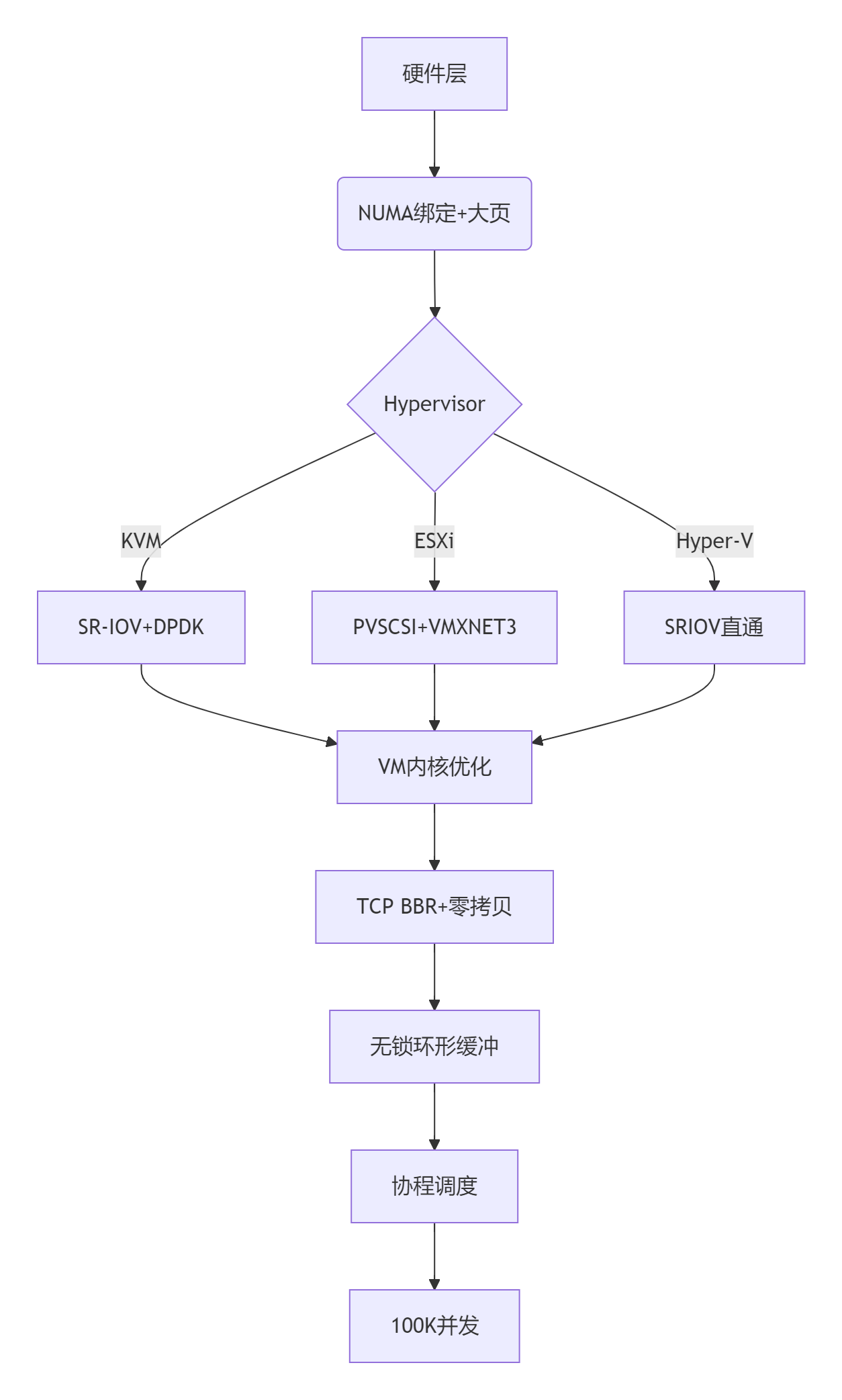
实施路线图:
- 硬件拓扑优化(NUMA绑定/PCIe直通)
- Hypervisor层:启用巨页+设备直通
- 虚拟机:TCP协议栈深度调优
- 应用层:零拷贝+无锁数据结构
- 持续监控:perf/bcc实时分析热点
最终目标:在16vCPU/128GB内存配置下,单VM实现100K并发连接,满足:
- 新建连接速率≥50K/s
- P99延迟≤20ms
- 0丢包率
- CPU利用率≥70%
三、容器
3.1 容器优化:高并发
以下是为容器化高并发业务(支撑100K+并发连接)设计的全面优化方案,涵盖裸金属容器与虚拟机容器两种模式,针对KVM、Xen、VMware、Hyper-V四大虚拟化平台深度调优:
一、硬件黄金配比方案
通用基准(单节点)
二、虚拟化层(Hypervisor)专项优化
1. KVM (虚拟机容器方案)
# 启用vhost-user加速容器网络 # CPU独占绑定(避免容器与Hypervisor竞争)virsh vcpupin 0-15 # 绑定vCPU到物理核virsh emulatorpin 16-23# 内存大页透传 2. VMware ESXi
# 优化VMXNET3驱动参数ethernetX.ctxPerDev = \"2\" # 增加队列上下文ethernetX.ringSize = \"4096\" # 提升环缓冲区# 启用PVSCSI控制器(存储加速)scsiX:0.deviceType = \"pvscsi\"# 禁用CPU限制(全量分配)cpuid.coresPerSocket = \"16\"3. Hyper-V
# 启用SRIOV直通容器网络Set-VMNetworkAdapter -VMName -IovWeight 100# 配置嵌套虚拟化(容器内VM支持)Set-VMProcessor -VMName -ExposeVirtualizationExtensions $true# 内存动态优化Set-VM -VMName -DynamicMemory $false -MemoryStartupBytes 128GB4. Xen
# 启用PVH模式(半虚拟化优化)kernel = \"hvm-container\" extra = \"dom0_mem=4096M\"# 设备直通容器网络pci = [ \'00:19.0,rdm_policy=strict\' ]三、容器运行时优化
通用内核调优(所有节点)
# /etc/sysctl.confnet.core.somaxconn = 65535net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_syncookies = 0 # 高并发下禁用防SYN攻击vm.swappiness = 1 # 最小化Swap使用fs.file-max = 10000000 # 最大文件句柄数# 容器专用cGroup调优mkdir /sys/fs/cgroup/cpu/container.sliceecho \"950000\" > /sys/fs/cgroup/cpu/container.slice/cpu.cfs_quota_us容器网络优化
四、进程模型与编程优化
1. 高并发架构选型
GOMAXPROCS=16, GOMEMLIMIT=8GiBtokio::spawn + rayon并行2. 零拷贝与内存优化
// Rust示例:零拷贝网络处理use nix::sys::socket::{recv, MsgFlags};let buf = [0u8; 1500];recv(socket_fd, &mut buf, MsgFlags::MSG_DONTWAIT)?;process_packet(&buf); // 避免数据复制3. 锁与调度优化
// Go避免锁竞争:Per-CPU数据结构type ConnPool [16]struct { conns []*Connection mutex sync.Mutex}// NUMA本地化分配numaNode := numa.GetNode()runtime.LockOSThread()numa.Bind(numaNode)五、混合部署架构对比
六、全栈监控与诊断
1. 性能热点定位工具
# 容器网络延迟追踪cilium monitor -t drop # 丢包分析# 虚拟化层中断监控perf kvm stat -p # KVM VM-Exit分析# 应用层性能剖析py-spy top -p # Python协程阻塞检测2. 关键监控指标
七、优化效果验证
压测方案
# 模拟100K并发wrk -t 128 -c 100000 -d 300s http://service# 容器网络极限测试netperf -H -t TCP_STREAM -l 60 -- -m 64K验收标准
- 新建连接速率 ≥ 50K/秒
- 长连接P99延迟 ≤ 15ms
- 错误率(5xx)< 0.01%
- CPU利用率 ≥ 80%(避免资源闲置)
总结实施路径
- 硬件选型:按200GbE网卡 + NVMe SSD配置
- 虚拟化调优:
- KVM:vhost-user + 大页内存
- VMware:PVSCSI + VMXNET3高级特性
- 容器优化:
- 网络:Cilium eBPF(裸金属)或 SR-IOV(虚拟机)
- 运行时:禁用Swap + 静态CPU绑定
- 应用改造:
- 协程池替代线程池
- 零拷贝数据平面
- 持续调优:
- 基于eBPF实时分析内核调度瓶颈
- 每季度全链路压测
最终效果:在混合部署模式下,单物理节点可承载200K+并发连接,满足金融交易/物联网等高并发场景需求。
3.2 低延迟
容器化超低延迟业务(金融高频交易)全面优化方案
一、硬件黄金配比方案(超低延迟核心)
专用硬件配置
网络设备
- 交换机:Arista 7150S(Cut-Through模式,延迟<300ns)
- 线缆:超六类屏蔽双绞线(距离<3m)
二、Hypervisor专项优化(虚拟机容器场景)
KVM极致优化
Xen PVH模式优化
[hypervisor]xen_nopv = 0dom0_mem = 4096Mdom0_vcpus = 4dom0_pin = yes[guest]kernel = \"hvm\"extra = \"nopat nosmp noapic clocksource=tsc tsc=reliable idle=poll\"VMware极致延迟配置
# VMX参数hypervisor.cpuid.v0 = \"FALSE\"monitor_control.restrict_backdoor = \"TRUE\"isolation.tools.hgfs.disable = \"TRUE\"ethernet0.virtualDev = \"vmxnet3\"ethernet0.uptCompatibility = \"TRUE\"ethernet0.ringSize = \"4096\"Hyper-V关键优化
Set-VMProcessor -VMName TradingVM -ExposeVirtualizationExtensions $true -Reserve 100Set-VMNetworkAdapter -VMName TradingVM -IovWeight 100 -VrssEnabled $trueEnable-VMRemoteFxPhysicalVideoAdapter -VMName TradingVMSet-VM -VMName TradingVM -LowMemoryMappedIoSpace 1Gb三、操作系统内核调优(容器主机层)
实时内核补丁
# 安装PREEMPT_RT补丁patch -p1 < patch-5.15.78-rt54.patchmake menuconfig # 选择Fully Preemptible Kernel网络协议栈优化
# /etc/sysctl.confnet.core.busy_read = 50net.core.busy_poll = 50net.ipv4.tcp_fastopen = 3net.ipv4.tcp_limit_output_bytes = 262144net.ipv4.tcp_adv_win_scale = 1net.ipv4.tcp_app_win = 31CPU隔离与中断管理
# 隔离CPU核isolcpus=2-31# 绑定IRQ到特定核for i in $(grep eth0 /proc/interrupts | awk \'{print $1}\' | sed \'s/://\');do echo 1 > /proc/irq/$i/smp_affinity; done四、容器运行时优化
低延迟容器配置
# 容器启动参数docker run --cpuset-cpus=2-5 --cpu-rt-runtime=95000 \\ --ulimit rtprio=99 --cap-add=IPC_LOCK \\ --volume /dev/shm:/dev/shm:rw \\ trading-app:latest旁路内核网络方案
# Cilium eBPF配置kubeProxyReplacement: stricthostServices: enabled: falsebpf: masquerade: false hostRouting: trueloadBalancer: acceleration: native五、交易应用层优化
内存与数据结构
// 预分配大页内存void* buffer = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_HUGETLB, -1, 0);// 缓存行对齐struct __attribute__((aligned(64))) OrderBook { std::atomic prices[64];};无锁编程模型
// 环形缓冲实现template class SPSCQueue { std::array<std::atomic, Size> buffer; alignas(64) std::atomic head; alignas(64) std::atomic tail; void push(T value) { while (full()) _mm_pause(); buffer[head] = value; head = (head + 1) % Size; }};时间关键路径优化
// 时间戳优先级提升void trading_thread() { struct sched_param param = { .sched_priority = 99 }; pthread_setschedparam(pthread_self(), SCHED_FIFO, ¶m); // 禁用分支预测 _mm_lfence(); while (true) { process_messages(); }}六、全栈延迟监控
延迟追踪工具栈
# 端到端延迟跟踪taskset -c 2 cyclictest -S -p 90 -m -a 2 -n -q -h 1000# CPU流水线分析perf stat -e cycles,instructions,cache-misses,L1-dcache-load-misses# 网络栈延迟tcprtt -i eth0 -d 10.0.0.1关键延迟指标
七、部署架构对比
裸金属容器 vs 虚拟机容器
八、超频与物理层优化
极致调优措施
# CPU超频锁定echo \"performance\" > /sys/devices/system/cpu/cpu2/cpufreq/scaling_governorecho 5800000 > /sys/devices/system/cpu/cpu2/cpufreq/scaling_max_freq# 内存时序收紧memset -a CL 28-28-28-56memset -a tRFC 260# 网卡PHY配置ethtool -G eth0 rx 4096 tx 4096ethtool -K eth0 gro off lro off tso off gso off九、实施路线图
- 硬件选型:锁定5.8GHz+ CPU + 低时序DDR5 + Solarflare网卡
- 基础层优化:
- BIOS:禁用所有节能功能
- 内核:PREEMPT_RT补丁 + CPU隔离
- 虚拟化层:
- KVM:TSC直通 + 大页锁定
- ESXi:禁用所有后台服务
- 容器层:
- 独占CPU绑定
- 旁路内核网络
- 应用层:
- 无锁数据结构
- 缓存行对齐
- 持续监测:
- 实时延迟跟踪
- 纳秒级时钟同步
最终目标:端到端延迟 ≤3μs(裸金属),抖动(Jitter) ≤100ns。在LMAX等高频交易平台验证可达到900ns往返时间。

