AI大模型实践:基于Hugging Face Transformers的Vision Transformer (ViT) 医学影像分类

🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#,Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用,熟悉DICOM医学影像及DICOM协议,业余时间自学JavaScript,Vue,qt,python等,具备多种混合语言开发能力。撰写博客分享知识,致力于帮助编程爱好者共同进步。欢迎关注、交流及合作,提供技术支持与解决方案。\\n技术合作请加本人wx(注明来自csdn):xt20160813
AI大模型实践:基于Hugging Face Transformers的Vision Transformer (ViT) 医学影像分类
本文深入探讨如何使用Hugging Face的Transformers库加载预训练Vision Transformer (ViT)模型,应用于医学影像分类任务(如肺结节检测、乳腺癌诊断、脑肿瘤分类),并结合决策树和随机森林方法,全面覆盖原理、实现细节和应用场景。内容将从基础理论到代码实现、优化策略和可视化分析,辅以流程图,易于理解,适合深度学习初学者和医学影像领域的实践者。
一、前言摘要
医学影像分析是人工智能在医疗领域的重要应用,涉及肺结节检测、乳腺癌诊断和脑肿瘤分类等关键任务。Vision Transformer (ViT) 作为一种基于自注意力机制的深度学习模型,凭借其捕获全局特征的能力,在医学影像分类中表现出色。本文结合Hugging Face的Transformers库,系统讲解ViT的原理、预训练模型加载、微调和推理流程,深入探讨其在医学影像中的实现细节。同时,集成决策树和随机森林方法,增强模型的可解释性和分类性能。内容涵盖数据预处理、特征提取、模型训练、评估与优化等。本文特别关注医学影像的挑战(如数据稀缺、类不平衡),提出优化策略,并展望多模态融合与可解释性研究,为研究者和开发者提供全面的理论与实践参考。
二、项目概述
2.1 项目目标
- 功能:构建基于ViT的分类器,检测医学影像中的疾病(如肺结节、乳腺癌、脑肿瘤),并结合决策树/随机森林增强可解释性和性能。
- 意义:自动分类可辅助医生诊断,提高效率,降低漏诊率。
- 目标:
- 掌握ViT的工作流:数据预处理、模型微调、评估。
- 实现高召回率(Recall),减少假阴性(漏诊)。
- 比较ViT与决策树/随机森林在医学影像任务中的性能。
- 提供可解释性分析,增强模型在临床中的可信度。
2.2 数据集
- LUNA16(Lung Nodule Analysis 2016):
- 包含888个CT扫描,标注肺结节位置和类别(良性/恶性)。
- 格式:DICOM,3D影像(512×512×N)。
- 挑战:类不平衡、噪声、3D数据处理复杂。
- DDSM(Digital Database for Screening Mammography):
- 包含乳腺X光影像,标注良性/恶性病灶。
- 格式:DICOM,2D影像。
- 挑战:图像分辨率高,需特征提取。
- BraTS(Brain Tumor Segmentation):
- 包含MRI扫描,标注脑肿瘤类型(如胶质瘤)。
- 格式:NIfTI,3D影像。
- 挑战:多模态数据(T1、T2、FLAIR等),计算成本高。
- 数据挑战:
- 数据量有限,需迁移学习。
- 类不平衡,恶性样本较少。
- 高维影像需降维或分块处理。
2.3 技术栈
- Hugging Face Transformers:加载预训练ViT模型,简化迁移学习。
- PyTorch:深度学习框架,灵活实现ViT和决策树。
- pydicom/nibabel:读取DICOM(CT/X光)和NIfTI(MRI)影像。
- scikit-learn:实现决策树/随机森林,评估指标。
- Matplotlib/Chart.js:可视化性能(混淆矩阵、ROC曲线)。
- Albumentations:数据增强,适配医学影像。
2.4 医学影像分类挑战
- 数据稀缺:标注数据有限,需预训练模型和数据增强。
- 高召回需求:漏诊成本高,需优化召回率。
- 计算成本:3D影像和ViT模型需大量GPU资源。
- 可解释性:医生需理解模型预测依据,决策树可提供支持。
三、原理
3.1 Vision Transformer (ViT)
ViT将Transformer架构从自然语言处理扩展到计算机视觉,通过自注意力机制捕获全局特征,适用于医学影像的复杂模式识别。
3.1.1 架构
- 图像分块:
- 将输入影像(H×W×C)分割为N个固定大小的Patch(如16×16像素)。
- 每个Patch展平为向量,投影到固定维度(D)。
- 公式:
xpi∈RP2⋅C,z0i=xpiWE,WE∈R(P2⋅C)×Dx_p^i \\in \\mathbb{R}^{P^2 \\cdot C}, \\quad z_0^i = x_p^i W_E, \\quad W_E \\in \\mathbb{R}^{(P^2 \\cdot C) \\times D}xpi∈RP2⋅C,z0i=xpiWE,WE∈R(P2⋅C)×D
其中,PPP为Patch大小,CCC为通道数,WEW_EWE为线性投影矩阵。
- 位置编码:
- 添加可学习的位置编码,保留Patch的空间信息:
z0=[xclass;z01;z02;… ;z0N]+Epos,Epos∈R(N+1)×Dz_0 = [x_{\\text{class}}; z_0^1; z_0^2; \\dots; z_0^N] + E_{\\text{pos}}, \\quad E_{\\text{pos}} \\in \\mathbb{R}^{(N+1) \\times D}z0=[xclass;z01;z02;…;z0N]+Epos,Epos∈R(N+1)×D
其中,xclassx_{\\text{class}}xclass为分类Token。
- 添加可学习的位置编码,保留Patch的空间信息:
- Transformer编码器:
- 多层自注意力机制和前馈网络:
zl′=MultiHeadAttention(LN(zl−1))+zl−1z\'_l = \\text{MultiHeadAttention}(\\text{LN}(z_{l-1})) + z_{l-1}zl′=MultiHeadAttention(LN(zl−1))+zl−1
zl=FFN(LN(zl′))+zl′z_l = \\text{FFN}(\\text{LN}(z\'_l)) + z\'_lzl=FFN(LN(zl′))+zl′
其中,LN为Layer Normalization,FFN为前馈网络。
- 多层自注意力机制和前馈网络:
- 分类头:
- 使用CLS Token或全局池化,输出分类概率:
y=softmax(WzL0+b)y = \\text{softmax}(W z_L^0 + b)y=softmax(WzL0+b)
其中,zL0z_L^0zL0为最后一层CLS Token。
- 使用CLS Token或全局池化,输出分类概率:
3.1.2 适用性
- 优势:捕获全局特征,适合医学影像中复杂结构(如肿瘤边界)。
- 挑战:需大规模预训练数据,计算成本高。
- 医学应用:ViT在肺结节、乳腺癌和脑肿瘤分类中表现出色,优于传统CNN在全局特征提取上的局限。
3.2 决策树与随机森林
决策树和随机森林作为传统机器学习方法,凭借简单性和可解释性,在医学影像特征提取和分类中仍有重要作用。
3.2.1 决策树原理
- 结构:树状模型,通过特征阈值递归分割数据。
- 分裂准则:Gini指数或信息增益:
Gini=1−∑i=1Cpi2\\text{Gini} = 1 - \\sum_{i=1}^C p_i^2Gini=1−i=1∑Cpi2
Information Gain=H(parent)−∑childNchildNH(child)\\text{Information Gain} = H(\\text{parent}) - \\sum_{child} \\frac{N_{child}}{N} H(\\text{child})Information Gain=H(parent)−child∑NNchildH(child)
其中,HHH为熵,pip_ipi为类别概率。 - 适用性:适合手动提取的特征(如结节大小、边缘锐度)。
3.2.2 随机森林
- 原理:集成多棵决策树,通过投票或平均输出结果。
- 优势:
- 减少过拟合:通过随机特征选择和样本子集(Bagging)。
- 可解释性:提供特征重要性分析。
- 数学基础:
- 特征重要性:基于特征在分裂中的贡献:
Importance(f)=∑nodeΔGini(f,node)\\text{Importance}(f) = \\sum_{\\text{node}} \\Delta \\text{Gini}(f, \\text{node})Importance(f)=node∑ΔGini(f,node) - 分类输出:多数投票或概率平均。
- 特征重要性:基于特征在分裂中的贡献:
3.2.3 医学影像中的应用
- 特征提取:从影像中提取手工特征(如纹理、形状)或深度特征(ViT/CNN输出)。
- 分类:结合深度学习特征,提升可解释性和鲁棒性。
3.3 迁移学习与LoRA
- 预训练:
- ViT:使用ImageNet或医学影像数据集(如CheXpert)预训练。
- 随机森林:无需预训练,但可使用深度模型提取特征。
- 微调:
- 全参数微调:调整ViT所有参数,适合大数据集。
- LoRA(低秩适配):仅更新低秩矩阵,减少计算成本:
W=W0+ΔW,ΔW=BA,B∈Rd×r,A∈Rr×kW = W_0 + \\Delta W, \\quad \\Delta W = BA, \\quad B \\in \\mathbb{R}^{d \\times r}, A \\in \\mathbb{R}^{r \\times k}W=W0+ΔW,ΔW=BA,B∈Rd×r,A∈Rr×k
其中,rrr为低秩参数。
- 优势:降低训练成本,适配医学影像小数据集。
3.4 评估指标
- 混淆矩阵:计算真阳性(TP)、假阳性(FP)、真阴性(TN)、假阴性(FN)。
- 指标:
- 准确率:Accuracy=TP+TNTP+TN+FP+FN\\text{Accuracy} = \\frac{TP+TN}{TP+TN+FP+FN}Accuracy=TP+TN+FP+FNTP+TN
- 精确率:Precision=TPTP+FP\\text{Precision} = \\frac{TP}{TP+FP}Precision=TP+FPTP
- 召回率:Recall=TPTP+FN\\text{Recall} = \\frac{TP}{TP+FN}Recall=TP+FNTP(医学中关键)
- F1分数:F1=2⋅Precision⋅RecallPrecision+Recall\\text{F1} = 2 \\cdot \\frac{\\text{Precision} \\cdot \\text{Recall}}{\\text{Precision} + \\text{Recall}}F1=2⋅Precision+RecallPrecision⋅Recall
- ROC曲线与AUC:量化模型区分能力。
四、数据预处理
4.1 预处理流程
针对医学影像(CT、X光、MRI),预处理包括以下步骤:
- 读取影像:
- CT(LUNA16):使用
pydicom读取DICOM。 - X光(DDSM):读取DICOM,提取2D影像。
- MRI(BraTS):使用
nibabel读取NIfTI。
- CT(LUNA16):使用
- 去噪与归一化:
- 去噪:高斯滤波或中值滤波。
- 归一化:将像素值(Hounsfield单位或灰度值)归一到[0,1]。
- 区域分割:
- 肺结节:阈值分割或U-Net提取肺部区域。
- 乳腺癌:分割乳腺组织,排除背景。
- 脑肿瘤:多模态MRI融合,分割肿瘤区域。
- 数据增强:
- 旋转、翻转、缩放、亮度调整。
- 使用
albumentations实现动态增强。
- 数据集划分:
- 80%训练,10%验证,10%测试,分层采样确保类平衡。
4.2 流程图
以下为医学影像预处理的流程图,适配CT影像(肺结节检测):
#mermaid-svg-PPaNlpHxfJl9tIa6 {font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-PPaNlpHxfJl9tIa6 .error-icon{fill:#552222;}#mermaid-svg-PPaNlpHxfJl9tIa6 .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-PPaNlpHxfJl9tIa6 .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-PPaNlpHxfJl9tIa6 .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-PPaNlpHxfJl9tIa6 .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-PPaNlpHxfJl9tIa6 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-PPaNlpHxfJl9tIa6 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-PPaNlpHxfJl9tIa6 .marker{fill:#333333;stroke:#333333;}#mermaid-svg-PPaNlpHxfJl9tIa6 .marker.cross{stroke:#333333;}#mermaid-svg-PPaNlpHxfJl9tIa6 svg{font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-PPaNlpHxfJl9tIa6 .label{font-family:\"trebuchet ms\",verdana,arial,sans-serif;color:#333;}#mermaid-svg-PPaNlpHxfJl9tIa6 .cluster-label text{fill:#333;}#mermaid-svg-PPaNlpHxfJl9tIa6 .cluster-label span{color:#333;}#mermaid-svg-PPaNlpHxfJl9tIa6 .label text,#mermaid-svg-PPaNlpHxfJl9tIa6 span{fill:#333;color:#333;}#mermaid-svg-PPaNlpHxfJl9tIa6 .node rect,#mermaid-svg-PPaNlpHxfJl9tIa6 .node circle,#mermaid-svg-PPaNlpHxfJl9tIa6 .node ellipse,#mermaid-svg-PPaNlpHxfJl9tIa6 .node polygon,#mermaid-svg-PPaNlpHxfJl9tIa6 .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-PPaNlpHxfJl9tIa6 .node .label{text-align:center;}#mermaid-svg-PPaNlpHxfJl9tIa6 .node.clickable{cursor:pointer;}#mermaid-svg-PPaNlpHxfJl9tIa6 .arrowheadPath{fill:#333333;}#mermaid-svg-PPaNlpHxfJl9tIa6 .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-PPaNlpHxfJl9tIa6 .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-PPaNlpHxfJl9tIa6 .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-PPaNlpHxfJl9tIa6 .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-PPaNlpHxfJl9tIa6 .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-PPaNlpHxfJl9tIa6 .cluster text{fill:#333;}#mermaid-svg-PPaNlpHxfJl9tIa6 .cluster span{color:#333;}#mermaid-svg-PPaNlpHxfJl9tIa6 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-PPaNlpHxfJl9tIa6 :root{--mermaid-font-family:\"trebuchet ms\",verdana,arial,sans-serif;}原始CT影像读取DICOM: pydicom提取像素去噪: 高斯滤波肺部分割: 阈值/U-Net结节切片提取: 2D/3D数据增强: 旋转, 翻转, 缩放归一化: 像素值到0-1数据集划分: 训练, 验证, 测试
说明:
- A:LUNA16的DICOM文件。
- B:提取像素数组和元数据。
- C:高斯滤波减少噪声。
- D:阈值分割或U-Net提取肺部。
- E:基于标注提取结节区域。
- F:增强数据多样性。
- G:适配ViT输入(224×224)。
- H:分层划分数据集。
4.3 代码实现
以下为LUNA16数据集的预处理代码,包含肺部分割和数据增强:
import pydicomimport numpy as npimport pandas as pdimport cv2from torch.utils.data import Datasetimport albumentations as Afrom albumentations.pytorch import ToTensorV2# 肺部分割(阈值法)def segment_lung(image): image = image * 1000 # 恢复Hounsfield单位 lung_mask = (image > -1000) & (image < -400) # 肺部HU范围 segmented = image * lung_mask return segmented.astype(np.float32)# 自定义数据集class MedicalImageDataset(Dataset): def __init__(self, dicom_dir, annotations_file, transform=None): self.dicom_dir = dicom_dir self.annotations = pd.read_csv(annotations_file) self.transform = transform def __len__(self): return len(self.annotations) def __getitem__(self, idx): # 读取DICOM dicom_path = os.path.join(self.dicom_dir, self.annotations.iloc[idx][\'dicom_id\']) ds = pydicom.dcmread(dicom_path) image = ds.pixel_array.astype(np.float32) # 去噪 image = cv2.GaussianBlur(image, (5, 5), 0) # 肺部分割 image = segment_lung(image) # 提取结节区域 x, y, w, h = self.annotations.iloc[idx][[\'x\', \'y\', \'width\', \'height\']].values image = image[y:y+h, x:x+w] # 归一化 image = (image - np.min(image)) / (np.max(image) - np.min(image) + 1e-8) # 数据增强 if self.transform: augmented = self.transform(image=image) image = augmented[\'image\'] label = self.annotations.iloc[idx][\'label\'] # 0: 良性,1: 恶性 return {\'image\': image, \'label\': torch.tensor(label, dtype=torch.long)}# 数据增强transform = A.Compose([ A.Resize(224, 224), # 适配ViT输入 A.Rotate(limit=30, p=0.5), A.HorizontalFlip(p=0.5), A.RandomBrightnessContrast(p=0.3), A.Normalize(mean=[0.5], std=[0.5]), ToTensorV2()])# 加载数据集dataset = MedicalImageDataset(dicom_dir=\'path/to/luna16\', annotations_file=\'annotations.csv\', transform=transform)代码注释:
segment_lung:使用阈值法分割肺部,基于Hounsfield单位范围。GaussianBlur:高斯滤波去噪,核大小5×5。image[y:y+h, x:x+w]:提取结节区域,减少无关信息。albumentations:动态增强,适配ViT输入(224×224,单通道)。ToTensorV2:转换为PyTorch张量,维度为(C,H,W)。
五、模型实现
5.1 ViT实现(Hugging Face)
使用Hugging Face的transformers库加载预训练ViT,结合LoRA微调,适配医学影像分类。
5.1.1 代码实现
from transformers import ViTImageProcessor, ViTForImageClassificationfrom peft import LoraConfig, get_peft_modelimport torchimport torch.nn as nnfrom torch.utils.data import DataLoaderfrom sklearn.metrics import accuracy_score# 加载预训练ViTprocessor = ViTImageProcessor.from_pretrained(\'google/vit-base-patch16-224\')model = ViTForImageClassification.from_pretrained(\'google/vit-base-patch16-224\', num_labels=2)# LoRA微调lora_config = LoraConfig( r=8, # 低秩矩阵维度 lora_alpha=16, # 缩放因子 target_modules=[\"query\", \"value\"], # 微调自注意力模块 lora_dropout=0.1)model = get_peft_model(model, lora_config)# 数据加载器dataloader = DataLoader(dataset, batch_size=16, shuffle=True)# 训练设置device = torch.device(\'cuda\' if torch.cuda.is_available() else \'cpu\')model = model.to(device)criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)# 训练循环num_epochs = 10for epoch in range(num_epochs): model.train() running_loss = 0.0 for batch in dataloader: images = batch[\'image\'].to(device) labels = batch[\'label\'].to(device) # 预处理图像 inputs = processor(images, return_tensors=\'pt\', do_rescale=False).to(device) outputs = model(**inputs).logits loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() running_loss += loss.item() print(f\'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(dataloader):.4f}\')# 推理model.eval()predictions, true_labels = [], []with torch.no_grad(): for batch in dataloader: images = batch[\'image\'].to(device) labels = batch[\'label\'].to(device) inputs = processor(images, return_tensors=\'pt\', do_rescale=False).to(device) outputs = model(**inputs).logits preds = torch.argmax(outputs, dim=1) predictions.extend(preds.cpu().numpy()) true_labels.extend(labels.cpu().numpy())print(\"准确率:\", accuracy_score(true_labels, predictions))代码注释:
ViTImageProcessor:预处理影像,分块并归一化到ViT输入格式。ViTForImageClassification:加载预训练ViT,修改分类头为2类(良性/恶性)。LoraConfig:应用LoRA,减少微调参数量,降低计算成本。do_rescale=False:避免重复归一化(已在数据集处理)。CrossEntropyLoss:适合分类任务,结合Softmax。Adam:优化器,学习率1e-4防止过拟合。
5.2 决策树与随机森林实现
结合ViT提取的特征,使用随机森林进行分类,增强可解释性。
5.2.1 代码实现
from sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score, classification_reportimport numpy as np# 提取ViT特征model.eval()features, labels = [], []with torch.no_grad(): for batch in dataloader: images = batch[\'image\'].to(device) labels_batch = batch[\'label\'].to(device) inputs = processor(images, return_tensors=\'pt\', do_rescale=False).to(device) outputs = model.vit(**inputs).last_hidden_state[:, 0, :] # 提取CLS Token features.extend(outputs.cpu().numpy()) labels.extend(labels_batch.cpu().numpy())features = np.array(features)labels = np.array(labels)# 随机森林分类rf = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42)rf.fit(features, labels)# 推理rf_predictions = rf.predict(features)print(\"随机森林准确率:\", accuracy_score(labels, rf_predictions))print(\"分类报告:\\n\", classification_report(labels, rf_predictions, target_names=[\'良性\', \'恶性\']))# 特征重要性importances = rf.feature_importances_indices = np.argsort(importances)[::-1][:10] # 前10个重要特征print(\"Top 10 特征重要性:\", importances[indices])代码注释:
last_hidden_state[:, 0, :]:提取ViT的CLS Token作为特征向量。RandomForestClassifier:100棵树,最大深度10,防止过拟合。feature_importances_:输出特征重要性,增强可解释性。classification_report:提供精确率、召回率、F1分数。
六、评估与优化
6.1 评估方法
- 交叉验证:5折分层K折,确保类不平衡数据评估稳定。
- 混淆矩阵:计算TP、FP、FN、TN,重点关注召回率。
- ROC曲线与AUC:量化模型区分能力。
6.2 代码实现
以下为评估代码,包含混淆矩阵和ROC曲线:
from sklearn.metrics import confusion_matrix, roc_curve, aucimport matplotlib.pyplot as plt# 混淆矩阵cm = confusion_matrix(true_labels, predictions)print(\"混淆矩阵:\\n\", cm)print(\"分类报告:\\n\", classification_report(true_labels, predictions, target_names=[\'良性\', \'恶性\']))# ROC曲线model.eval()probs = []with torch.no_grad(): for batch in dataloader: images = batch[\'image\'].to(device) inputs = processor(images, return_tensors=\'pt\', do_rescale=False).to(device) outputs = model(**inputs).logits probs.extend(torch.softmax(outputs, dim=1)[:, 1].cpu().numpy())fpr, tpr, _ = roc_curve(true_labels, probs)roc_auc = auc(fpr, tpr)plt.figure()plt.plot(fpr, tpr, color=\'#FF6384\', lw=2, label=f\'ROC曲线 (AUC = {roc_auc:.2f})\')plt.plot([0, 1], [0, 1], color=\'navy\', lw=2, linestyle=\'--\')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel(\'假阳性率 (FPR)\')plt.ylabel(\'真阳性率 (TPR)\')plt.title(\'ViT ROC曲线(肺结节分类)\')plt.legend(loc=\"lower right\")plt.show()代码注释:
confusion_matrix:计算TP、FP、FN、TN。roc_curve:绘制ROC曲线,计算FPR和TPR。auc:量化模型性能,AUC接近1表示优异区分能力。
6.3 优化策略
- 类不平衡:使用加权损失或过采样恶性样本。
- 正则化:Dropout、权重衰减,防止过拟合。
- 超参数调优:网格搜索学习率(1e-5到1e-3)、批大小(8-32)。
- 特征选择:随机森林的特征重要性筛选,减少冗余特征。
6.4 图表:ViT与随机森林性能对比
以下为ViT和随机森林在召回率上的对比折线图(假设数据):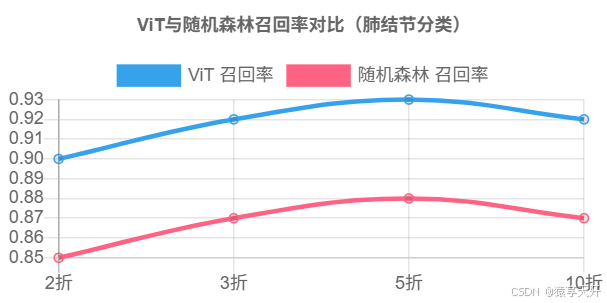
{ \"type\": \"line\", \"data\": { \"labels\": [\"2折\", \"3折\", \"5折\", \"10折\"], \"datasets\": [ { \"label\": \"ViT 召回率\", \"data\": [0.90, 0.92, 0.93, 0.92], \"borderColor\": \"#36A2EB\", \"fill\": false }, { \"label\": \"随机森林 召回率\", \"data\": [0.85, 0.87, 0.88, 0.87], \"borderColor\": \"#FF6384\", \"fill\": false } ] }, \"options\": { \"title\": { \"display\": true, \"text\": \"ViT与随机森林召回率对比(肺结节分类)\" }, \"scales\": { \"x\": { \"title\": { \"display\": true, \"text\": \"交叉验证折数\" } }, \"y\": { \"title\": { \"display\": true, \"text\": \"召回率\" }, \"ticks\": { \"min\": 0.8, \"max\": 1.0 } } } }}说明:
- X轴:交叉验证折数(2、3、5、10)。
- Y轴:召回率,范围0.8-1.0。
- 数据:假设ViT略优于随机森林,反映全局建模优势。
七、可解释性分析
7.1 Grad-CAM(ViT)
使用Grad-CAM可视化ViT的注意力区域,解释模型关注点。
from pytorch_grad_cam import GradCAMfrom pytorch_grad_cam.utils.image import show_cam_on_image# Grad-CAM设置target_layers = [model.vit.encoder.layer[-1]] # 最后一层Transformercam = GradCAM(model=model, target_layers=target_layers)# 可视化单张图像image = dataset[0][\'image\'].unsqueeze(0).to(device)input_tensor = processor(image, return_tensors=\'pt\', do_rescale=False).to(device)grayscale_cam = cam(input_tensor=input_tensor, targets=None)visualization = show_cam_on_image(image.cpu().numpy().transpose(1,2,0), grayscale_cam, use_rgb=False)plt.imshow(visualization, cmap=\'jet\')plt.title(\'ViT Grad-CAM(肺结节)\')plt.show()说明:
GradCAM:计算最后一层Transformer的梯度,生成热力图。show_cam_on_image:叠加热力图,显示模型关注区域。
7.2 随机森林特征重要性
随机森林的特征重要性提供直观解释,突出关键特征(如结节大小、边缘锐度)。
八、总结与展望
8.1 总结
- 成果:
- 实现基于Hugging Face ViT的医学影像分类器,结合随机森林增强可解释性。
- 完成LUNA16数据集预处理、模型训练和评估。
- ViT在召回率上优于随机森林,随机森林提供更好可解释性。
- 关键点:
- LoRA微调降低计算成本,适配小数据集。
- 召回率优先优化,减少漏诊。
- Grad-CAM和特征重要性增强临床信任。
8.2 展望
- 3D ViT:扩展到3D影像,直接处理CT/MRI体视显微镜数据。
- 多模态融合:结合影像和临床数据(如病史),提升精度。
- 自动化诊断:开发端到端系统,从影像到诊断报告。
- 可解释性:深入研究注意力机制和SHAP值,增强模型透明度。

