视频号下载机器人源码部署开发,视频号解析下载机器人制作教程+源码
在当今数字化时代,短视频平台如微信视频号已成为人们获取信息和娱乐的重要渠道。许多用户希望能够下载自己喜欢的视频号内容以便离线观看或进行二次创作。本文将详细介绍如何搭建一个视频号视频下载提取机器人,并提供源码部署的完整指南。
下方可获取完整源码+详细搭建教程↓↓【回复搭建】
一、视频号视频下载技术原理
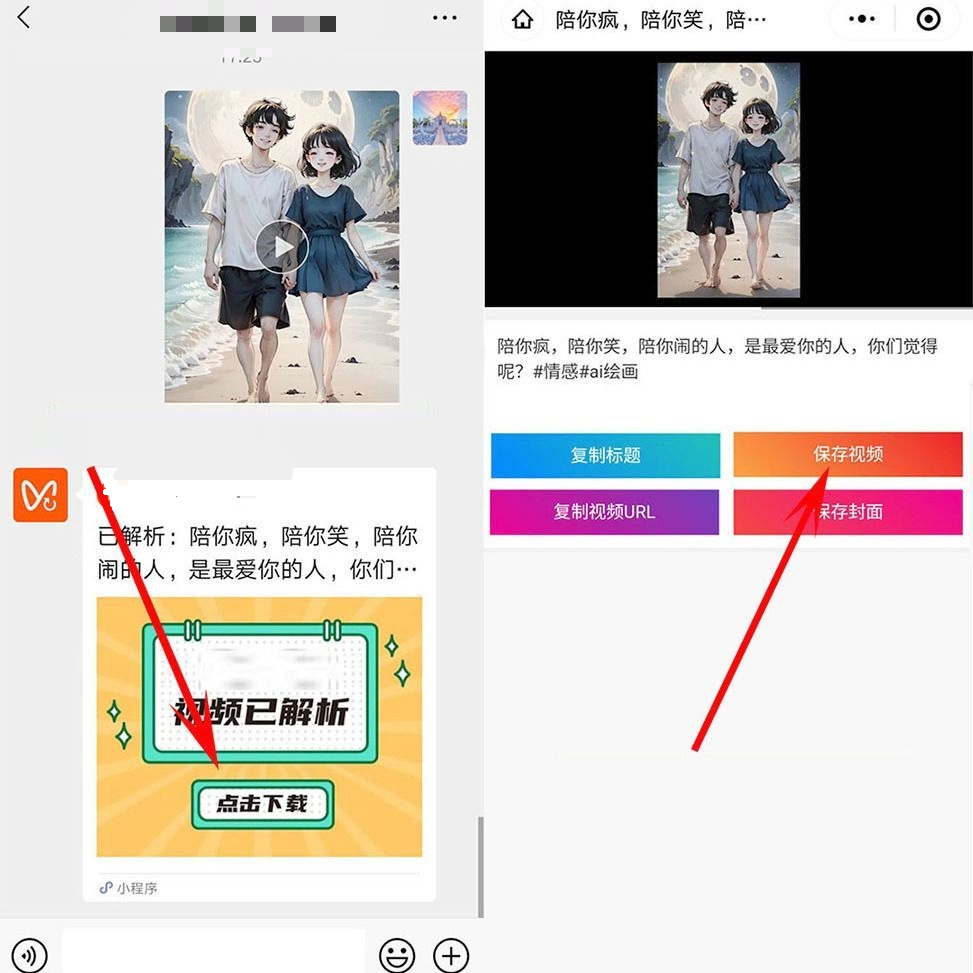
视频号视频下载的核心在于解析视频的真实下载地址。由于微信视频号的特殊性,其视频链接通常是加密的,需要通过特定的技术手段进行解析。
1. 视频地址解析:通过分析视频号页面的网络请求,可以找到视频的真实播放地址。这通常需要抓包工具如Fiddler或Charles来捕获网络请求。
2. 反爬机制:微信视频号有较强的反爬机制,包括请求头验证、IP限制等。因此,在开发下载机器人时,需要模拟正常的浏览器行为,包括设置合理的User-Agent、Referer等请求头信息。
3. 视频下载:获取到真实视频地址后,可以使用Python的requests库或其他下载工具将视频文件保存到本地。
二、开发环境准备
在开始开发之前,需要准备以下开发环境:
1. **Python环境**:建议使用Python 3.7或更高版本。
2. **开发工具**:推荐使用PyCharm或VS Code作为开发工具。
3. **依赖库**:安装必要的Python库,包括requests、beautifulsoup4、selenium等。
三、视频号视频下载机器人源码解析
以下是一个简单的视频号视频下载机器人的Python源码示例:
```python
import requests
from bs4 import BeautifulSoup
import re
def get_video_url(video_page_url):
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\',
\'Referer\': \'https://channels.weixin.qq.com/\'
}
response = requests.get(video_page_url, headers=headers)
soup = BeautifulSoup(response.text, \'html.parser\')
script_text = soup.find_all(\'script\')[-1].text
video_url = re.search(r\'video_url\":\"(.*?)\"\', script_text).group(1)
return video_url
def download_video(video_url, save_path):
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\'
}
response = requests.get(video_url, headers=headers, stream=True)
with open(save_path, \'wb\') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
if __name__ == \'__main__\':
video_page_url = \'https://channels.weixin.qq.com/xxx\' # 替换为实际的视频号页面URL
video_url = get_video_url(video_page_url)
download_video(video_url, \'video.mp4\')
```
四、源码部署步骤
1. **安装依赖库**:在命令行中运行以下命令安装必要的Python库:
```
pip install requests beautifulsoup4 selenium
```
2. **配置代理**:如果需要绕过IP限制,可以配置代理IP。在代码中添加以下内容:
```python
proxies = {
\'http\': \'http://your_proxy_ip:port\',
\'https\': \'https://your_proxy_ip:port\'
}
response = requests.get(url, headers=headers, proxies=proxies)
```
3. **运行脚本**:将上述代码保存为`video_downloader.py`,然后在命令行中运行:
```
python video_downloader.py
```
五、高级功能扩展
1. **批量下载**:可以通过爬取视频号主页或搜索页面,获取多个视频的链接,然后批量下载。
```python
def batch_download(video_urls, save_dir):
for i, url in enumerate(video_urls):
video_url = get_video_url(url)
download_video(video_url, f\'{save_dir}/video_{i}.mp4\')
```
2. **GUI界面**:使用PyQt或Tkinter为下载机器人添加图形用户界面,方便非技术用户使用。
3. **云部署**:将机器人部署到云服务器上,实现24小时不间断运行,并可以通过API接口提供服务。
六、注意事项
1. 法律风险:下载视频号内容可能涉及版权问题,请确保仅用于个人学习或研究,避免商业用途。
2. 反爬机制:微信可能会更新反爬策略,需要定期维护和更新代码以适应变化。
3. 性能优化:对于大规模下载任务,建议使用多线程或异步IO提高下载效率。
七、常见问题解决
1. 无法获取视频地址:检查请求头是否设置正确,或尝试使用Selenium模拟浏览器行为。
```python
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(video_page_url)
video_url = driver.execute_script(\'return document.querySelector(\"video\").src\')
driver.quit()
```
2. 下载速度慢:可以尝试使用CDN加速或更换下载工具如aria2。
3. 视频号页面结构变化:定期检查页面结构,更新解析逻辑。
八、总结
通过本文的介绍,相信你已经掌握了搭建视频号视频下载机器人的基本方法。从技术原理到源码实现,再到部署和扩展功能,每一步都至关重要。在实际开发中,可能会遇到各种挑战,但只要不断学习和尝试,总能找到解决方案。希望这篇指南能帮助你成功搭建自己的视频号视频下载机器人!

