LLaMa微调对话总结(反面教材)
文章目录
- 技术概要
- 一、环境准备
- 二、微调前工作
-
- 1.数据集下载
- 2.基座模型(llama3-8b-instruct)测试
- 三、微调
-
- 1.数据预处理
- 2.微调
- 3.微调后验证:
- 测试结果
技术概要
任务:多轮对话总结
微调方法:QLoRA
模型:llama3-8b-instruct
数据集:huggingface(dialogsum-test)
https://huggingface.co/datasets/neil-code/dialogsum-test
环境:PyTorch2.1.0、python3.10、ubuntu22.04、cuda12.1
一、环境准备
基础环境如下:PyTorch2.1.0、python3.10、ubuntu22.04、cuda12.1
额外:
pip install modelscopepip install datasets peft bitsandbytes transformers trl pynvml二、微调前工作
1.数据集下载
model_download.py:
import torchfrom modelscope import snapshot_download, AutoModel, AutoTokenizerimport osmodel_dir = snapshot_download(\'LLM-Research/Meta-Llama-3-8B-Instruct\',cache_dir=\'/root/autodl-tmp\', revision=\'master\')2.基座模型(llama3-8b-instruct)测试
base_test.py:
import subprocessimport osfrom datasets import load_datasetfrom transformers import (AutoModelForCausalLM,AutoTokenizer,BitsAndBytesConfig,TrainingArguments,pipeline,logging,)from peft import LoraConfigfrom trl import SFTTrainerfrom tqdm import tqdmimport torchimport timeimport pandas as pdimport numpy as npresult = subprocess.run(\'bash -c \"source /etc/network_turbo && env | grep proxy\"\', shell=True, capture_output=True, text=True)output = result.stdoutfor line in output.splitlines(): if \'=\' in line: var, value = line.split(\'=\', 1) os.environ[var] = valuedataset_name = \"neil-code/dialogsum-test\"dataset = load_dataset(dataset_name)#print(\"dataset形状:\")#print(dataset)def create_prompt_formats(sample): \"\"\" Format various fields of the sample (\'instruction\',\'output\') :param sample: input data \"\"\" INTRO_BLURB = \"Instruct: Below is an instruction that describes a task. Write a response that appropriately completes the request.\" INSTRUCTION_KEY = \"Input: Please Summarize the below conversation.\" RESPONSE_KEY = \"Output:\" blurb = f\"\\n{INTRO_BLURB}\" instruction = f\"{INSTRUCTION_KEY}\" input_context = f\"{sample[\'dialogue\']}\" if sample[\"dialogue\"] else None response = f\"{RESPONSE_KEY}\\n{sample[\'summary\']}\" parts = [part for part in [blurb, instruction, input_context, response] if part] formatted_prompt = \"\\n\\n\".join(parts) sample[\"text\"] = formatted_prompt return sample# 查看⼀下改写后的格式#print(\"改写后的格式:\" + create_prompt_formats(dataset[\'train\'][0])[\'text\'])# 配置模型compute_dtype = getattr(torch, \"float16\")quant_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type=\"nf4\", bnb_4bit_compute_dtype=compute_dtype, # 是否启用双重量化,可以在不损失太多精度的情况下进⼀步减少模型⼤⼩。双重量化是为了进⼀步量化 quantization constant,也是 Qlora ⾥⾯提出的⼀种⽅式 bnb_4bit_use_double_quant=True, )# 加载模型model_path = \"/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct/\"original_model = AutoModelForCausalLM.from_pretrained( model_path, torch_dtype=compute_dtype, device_map={\"\": 0}, quantization_config=quant_config)# 加载tokenizertokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False,trust_remote_code=True,# add_eos_token=True: 这个参数指示分词器在序列的末尾添加⼀个结束符(EOS,End Of Sentence) padding_side=\"left\",add_eos_token=True,add_bos_token=True) # 填充将被添加到序列的左侧tokenizer.pad_token_id = tokenizer.eos_token_id # 设置推理用的 tokenizereval_tokenizer = AutoTokenizer.from_pretrained(model_path, add_bos_token=True,trust_remote_code=True, use_fast=False)eval_tokenizer.pad_token = eval_tokenizer.eos_tokendef gen(model,p, maxlen=100, sample=True): toks = eval_tokenizer(p, return_tensors=\"pt\") res = model.generate(**toks.to(\"cuda\"), # 将编码后的提示张量移⾄ GPU 以进⾏加速计算 max_new_tokens=maxlen, # ⽣成的最⼤ token 数(100) do_sample=sample,num_return_sequences=1, # 是否在⽣成时采样,生成更多样化 temperature=0.1, num_beams=1, # 使⽤的 beam search 的 beam 数量,设置为 1 意味着不使⽤beam search top_p=0.95,).to(\'cpu\') # 将⽣成的⽂本张量移回 CPU return eval_tokenizer.batch_decode(res,skip_special_tokens=True) # 使⽤分词器将 ⽣成的张量 解码为 字符串 #timefrom transformers import set_seedseed = 42set_seed(seed)index = 10prompt = dataset[\'test\'][index][\'dialogue\']summary = dataset[\'test\'][index][\'summary\']formatted_prompt = f\"Instruct: Summarize the following conversation.\\nInput:{prompt}\\nOutput:\\n\"res = gen(original_model,formatted_prompt,100,)#print(res[0])output = res[0].split(\'Output:\\n\')[1]dash_line = \'-\'.join(\'\' for x in range(100))print(dash_line)print(f\'INPUT PROMPT:\\n{formatted_prompt}\')print(dash_line)print(f\'BASELINE HUMAN SUMMARY:\\n{summary}\\n\')print(dash_line)print(f\'MODEL GENERATION - ZERO SHOT:\\n{output}\')三、微调
1.数据预处理
data_preprocessing.py:
from functools import partialfrom transformers import (AutoModelForCausalLM,AutoTokenizer,BitsAndBytesConfig,TrainingArguments,pipeline,logging,)from peft import LoraConfigfrom trl import SFTTrainerfrom tqdm import tqdmimport torchimport timeimport pandas as pdimport numpy as npimport subprocessimport osfrom datasets import load_datasetfrom transformers import set_seeddef create_prompt_formats(sample): \"\"\" Format various fields of the sample (\'instruction\',\'output\') :param sample: input data \"\"\" INTRO_BLURB = \"Instruct: Below is an instruction that describes a task. Write a response that appropriately completes the request.\" INSTRUCTION_KEY = \"Input: Please Summarize the below conversation.\" RESPONSE_KEY = \"Output:\" blurb = f\"\\n{INTRO_BLURB}\" instruction = f\"{INSTRUCTION_KEY}\" input_context = f\"{sample[\'dialogue\']}\" if sample[\"dialogue\"] else None response = f\"{RESPONSE_KEY}\\n{sample[\'summary\']}\" parts = [part for part in [blurb, instruction, input_context, response] if part] formatted_prompt = \"\\n\\n\".join(parts) sample[\"text\"] = formatted_prompt return sampledef get_max_length(model): \"\"\" 获取模型支持的最大序列长度 参数: model: 预训练模型实例 返回: int: 最大序列长度(如果模型配置未指定,则返回默认值1024) \"\"\" conf = model.config max_length = None # 检查模型配置中可能表示最大长度的不同字段名 for length_setting in [\"n_positions\", \"max_position_embeddings\", \"seq_length\"]: max_length = getattr(model.config, length_setting, None) if max_length: print(f\"找到最大长度: {max_length}\") break # 如果未找到明确配置,使用默认值 if not max_length: max_length = 1024 print(f\"使用默认最大长度: {max_length}\") return max_lengthdef preprocess_batch(batch, tokenizer, max_length): \"\"\" 对批量文本进行分词处理 参数: batch: 包含\'text\'字段的字典,存储原始文本 tokenizer: 预训练分词器 max_length: 最大序列长度限制 返回: Dict: 分词后的结果(包含input_ids, attention_mask等) \"\"\" return tokenizer( batch[\"text\"], max_length=max_length, # 控制最大长度 truncation=True, # 启用自动截断 )def preprocess_dataset(tokenizer: AutoTokenizer, max_length: int,seed,dataset): \"\"\" 完整的LLM微调数据预处理流程 处理步骤: 1. 添加提示模板 2. 批量分词 3. 过滤过长样本 4. 打乱数据集顺序 参数: tokenizer: 预训练分词器 max_length: 最大序列长度 seed: 随机种子(用于可复现的打乱操作) dataset: 原始数据集 返回: Dataset: 预处理后的数据集 \"\"\" print(\"开始数据集预处理...\") # 步骤1:为每条数据添加指令模板 dataset = dataset.map(create_prompt_formats) # 步骤2:创建带固定参数的分词函数 _preprocessing_function = partial( preprocess_batch, max_length=max_length, tokenizer=tokenizer ) # 执行批量分词并移除原始列 dataset = dataset.map( _preprocessing_function, batched=True, # 启用批量处理提升效率 remove_columns=[\'id\', \'topic\', \'dialogue\', \'summary\'], # 移除无用字段 ) # 步骤3:过滤超过长度限制的样本 dataset = dataset.filter(lambda sample: len(sample[\"input_ids\"]) < max_length) # 步骤4:打乱数据顺序 dataset = dataset.shuffle(seed=seed) print(\"数据集预处理完成\") return datasetdataset_name = \"neil-code/dialogsum-test\"dataset = load_dataset(dataset_name)# 配置模型compute_dtype = getattr(torch, \"float16\")quant_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type=\"nf4\", bnb_4bit_compute_dtype=compute_dtype, # 是否启用双重量化,可以在不损失太多精度的情况下进⼀步减少模型⼤⼩。双重量化是为了进⼀步量化 quantization constant,也是 Qlora ⾥⾯提出的⼀种⽅式 bnb_4bit_use_double_quant=True, )# 加载模型model_path = \"/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct/\"original_model = AutoModelForCausalLM.from_pretrained( model_path, torch_dtype=compute_dtype, device_map={\"\": 0}, quantization_config=quant_config)# 加载tokenizertokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False,trust_remote_code=True,# add_eos_token=True: 这个参数指示分词器在序列的末尾添加⼀个结束符(EOS,End Of Sentence) padding_side=\"left\",add_eos_token=True,add_bos_token=True) # 填充将被添加到序列的左侧tokenizer.pad_token_id = tokenizer.eos_token_id seed = 42set_seed(seed)index = 10max_length = get_max_length(original_model)print(max_length)train_dataset = preprocess_dataset(tokenizer, max_length,seed, dataset[\'train\'])\'\'\'Dataset({ features: [\'text\', \'input_ids\', \'attention_mask\'], num_rows: 1999})\'\'\'print(train_dataset)eval_dataset = preprocess_dataset(tokenizer, max_length,seed, dataset[\'validation\'])2.微调
fine_tune.py:
from functools import partialfrom transformers import (AutoModelForCausalLM,AutoTokenizer,BitsAndBytesConfig,TrainingArguments,pipeline,logging,)from peft import LoraConfigfrom trl import SFTTrainerfrom tqdm import tqdmimport torchimport timeimport pandas as pdimport numpy as npimport subprocessimport osfrom datasets import load_datasetfrom transformers import set_seedfrom peft import LoraConfig, get_peft_model, prepare_model_for_kbit_trainingimport transformersdef create_prompt_formats(sample): \"\"\" Format various fields of the sample (\'instruction\',\'output\') :param sample: input data \"\"\" INTRO_BLURB = \"Instruct: Below is an instruction that describes a task. Write a response that appropriately completes the request.\" INSTRUCTION_KEY = \"Input: Please Summarize the below conversation.\" RESPONSE_KEY = \"Output:\" blurb = f\"\\n{INTRO_BLURB}\" instruction = f\"{INSTRUCTION_KEY}\" input_context = f\"{sample[\'dialogue\']}\" if sample[\"dialogue\"] else None response = f\"{RESPONSE_KEY}\\n{sample[\'summary\']}\" parts = [part for part in [blurb, instruction, input_context, response] if part] formatted_prompt = \"\\n\\n\".join(parts) sample[\"text\"] = formatted_prompt return sampledef get_max_length(model): \"\"\" 获取模型支持的最大序列长度 参数: model: 预训练模型实例 返回: int: 最大序列长度(如果模型配置未指定,则返回默认值1024) \"\"\" conf = model.config max_length = None # 检查模型配置中可能表示最大长度的不同字段名 for length_setting in [\"n_positions\", \"max_position_embeddings\", \"seq_length\"]: max_length = getattr(model.config, length_setting, None) if max_length: print(f\"找到最大长度: {max_length}\") break # 如果未找到明确配置,使用默认值 if not max_length: max_length = 1024 print(f\"使用默认最大长度: {max_length}\") return max_lengthdef preprocess_batch(batch, tokenizer, max_length): \"\"\" 对批量文本进行分词处理 参数: batch: 包含\'text\'字段的字典,存储原始文本 tokenizer: 预训练分词器 max_length: 最大序列长度限制 返回: Dict: 分词后的结果(包含input_ids, attention_mask等) \"\"\" return tokenizer( batch[\"text\"], max_length=max_length, # 控制最大长度 truncation=True, # 启用自动截断 )def preprocess_dataset(tokenizer: AutoTokenizer, max_length: int,seed,dataset): \"\"\" 完整的LLM微调数据预处理流程 处理步骤: 1. 添加提示模板 2. 批量分词 3. 过滤过长样本 4. 打乱数据集顺序 参数: tokenizer: 预训练分词器 max_length: 最大序列长度 seed: 随机种子(用于可复现的打乱操作) dataset: 原始数据集 返回: Dataset: 预处理后的数据集 \"\"\" print(\"开始数据集预处理...\") # 步骤1:为每条数据添加指令模板 dataset = dataset.map(create_prompt_formats) # 步骤2:创建带固定参数的分词函数 _preprocessing_function = partial( preprocess_batch, max_length=max_length, tokenizer=tokenizer ) # 执行批量分词并移除原始列 dataset = dataset.map( _preprocessing_function, batched=True, # 启用批量处理提升效率 remove_columns=[\'id\', \'topic\', \'dialogue\', \'summary\'], # 移除无用字段 ) # 步骤3:过滤超过长度限制的样本 dataset = dataset.filter(lambda sample: len(sample[\"input_ids\"]) < max_length) # 步骤4:打乱数据顺序 dataset = dataset.shuffle(seed=seed) print(\"数据集预处理完成\") return dataset# 数据集读取dataset_name = \"neil-code/dialogsum-test\"dataset = load_dataset(dataset_name)# 配置模型compute_dtype = getattr(torch, \"float16\")quant_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type=\"nf4\", bnb_4bit_compute_dtype=compute_dtype, # 是否启用双重量化,可以在不损失太多精度的情况下进⼀步减少模型⼤⼩。双重量化是为了进⼀步量化 quantization constant,也是 Qlora ⾥⾯提出的⼀种⽅式 bnb_4bit_use_double_quant=True, )# 加载模型model_path = \"/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct/\"original_model = AutoModelForCausalLM.from_pretrained( model_path, torch_dtype=compute_dtype, device_map={\"\": 0}, quantization_config=quant_config)# 加载tokenizertokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False,trust_remote_code=True,# add_eos_token=True: 这个参数指示分词器在序列的末尾添加⼀个结束符(EOS,End Of Sentence) padding_side=\"left\",add_eos_token=True,add_bos_token=True) # 填充将被添加到序列的左侧tokenizer.pad_token_id = tokenizer.eos_token_id seed = 42set_seed(seed)index = 10# 构造⽤于 finetune 的模型(模型实例化)config = LoraConfig( r=32, #Rank lora_alpha=16, target_modules=[\"q_proj\", \"k_proj\", \"v_proj\", \"o_proj\"], # 指定了要在模型中插⼊ LoRA 适配器的模块(LoRA微调参数对象) bias=\"none\", lora_dropout=0.01, # Conventional task_type=\"CAUSAL_LM\", # 指定了任务类型为因果语⾔模型(CAUSAL_LM),这意味着模型将被训练来⽣成⽂本,即每个时刻的输出只依赖于之前的输⼊)# 1 - 启用 梯度检查点(⼀种减少在微调过程中内存使⽤的技术) 以减少微调期间的内存使用original_model.gradient_checkpointing_enable()# 2 - 使用PEFT的 prepare_model_for_kbit_training方法original_model = prepare_model_for_kbit_training(original_model)# 我们需要⼀个新的模型,包含相应的参数 ΔW,同时我们要把原来的参数(W)设置为不可训练,通过 get_peft_model 就可以构造此模型peft_model = get_peft_model(original_model, config)# finetune模型output_dir = \'./peft-dialogue-summary-training/final-checkpoint\' # 模型训练过程中保存输出⽂件⽬录peft_training_args = TrainingArguments( output_dir = output_dir, warmup_steps=1, # 总 batch size = per_device_train_batch_size × gradient_accumulation_steps × GPU数量 per_device_train_batch_size=1, gradient_accumulation_steps=1, max_steps=2000, learning_rate=2e-4, optim=\"paged_adamw_8bit\", logging_steps=100, logging_dir=\"./logs\", save_strategy=\"steps\", save_steps=100, eval_strategy=\"steps\", # evaluation_strategy 已弃用 eval_steps=100, do_eval=True, gradient_checkpointing=True, report_to=\"none\", overwrite_output_dir = \'True\', group_by_length=True,)max_length = get_max_length(original_model)train_dataset = preprocess_dataset(tokenizer, max_length,seed, dataset[\'train\'])eval_dataset = preprocess_dataset(tokenizer, max_length,seed, dataset[\'validation\'])peft_model.config.use_cache = Falsepeft_trainer = transformers.Trainer( model=peft_model, train_dataset=train_dataset, eval_dataset=eval_dataset, args=peft_training_args, data_collator=transformers.DataCollatorForLanguageModeling(tokenizer,mlm=False),)peft_trainer.train()3.微调后验证:
lora_test.py:
from functools import partialfrom transformers import (AutoModelForCausalLM,AutoTokenizer,BitsAndBytesConfig,TrainingArguments,pipeline,logging,)from peft import LoraConfigfrom trl import SFTTrainerfrom tqdm import tqdmimport torchimport timeimport pandas as pdimport numpy as npimport subprocessimport osfrom datasets import load_datasetfrom transformers import set_seedfrom peft import LoraConfig, get_peft_model, prepare_model_for_kbit_trainingimport transformersfrom peft import PeftModeldef gen(model,p, maxlen=100, sample=True): toks = eval_tokenizer(p, return_tensors=\"pt\") res = model.generate(**toks.to(\"cuda\"), # 将编码后的提示张量移⾄ GPU 以进⾏加速计算 max_new_tokens=maxlen, # ⽣成的最⼤ token 数(100) do_sample=sample,num_return_sequences=1, # 是否在⽣成时采样,生成更多样化 temperature=0.1, num_beams=1, # 使⽤的 beam search 的 beam 数量,设置为 1 意味着不使⽤beam search top_p=0.95,).to(\'cpu\') # 将⽣成的⽂本张量移回 CPU return eval_tokenizer.batch_decode(res,skip_special_tokens=True) # 使⽤分词器将 ⽣成的张量 解码为 字符串# 数据集读取dataset_name = \"neil-code/dialogsum-test\"dataset = load_dataset(dataset_name)# 配置模型compute_dtype = getattr(torch, \"float16\")quant_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type=\"nf4\", bnb_4bit_compute_dtype=compute_dtype, bnb_4bit_use_double_quant=True,)# 加载模型model_path = \"/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct/\"base_model = AutoModelForCausalLM.from_pretrained( model_path, torch_dtype=compute_dtype, device_map={\"\": 0}, quantization_config=quant_config)# 设置⽤于推理的tokenizereval_tokenizer = AutoTokenizer.from_pretrained(model_path, add_bos_token=True,trust_remote_code=True, use_fast=False)eval_tokenizer.pad_token = eval_tokenizer.eos_token# 导⼊lora部分参数,并且和base模型合并ft_model = PeftModel.from_pretrained( base_model, \"./peft-dialogue-summary-training/final-checkpoint/checkpoint-1200\", torch_dtype=torch.float16, is_trainable=False)index = 10prompt = dataset[\'test\'][index][\'dialogue\']summary = dataset[\'test\'][index][\'summary\']formatted_prompt = f\"Instruct: Summarize the following conversation.\\nInput:{prompt}\\nOutput:\\n\"res = gen(ft_model,formatted_prompt,100,)#print(res[0])output = res[0].split(\'Output:\\n\')[1]dash_line = \'-\'.join(\'\' for x in range(100))print(dash_line)print(f\'INPUT PROMPT:\\n{formatted_prompt}\')print(dash_line)print(f\'BASELINE HUMAN SUMMARY:\\n{summary}\\n\')print(dash_line)print(f\'PEFT MODEL GENERATION:\\n{output}\')测试结果
我这里好像微调出来的效果还比基座更差了哈哈哈。。。。666
微调前:
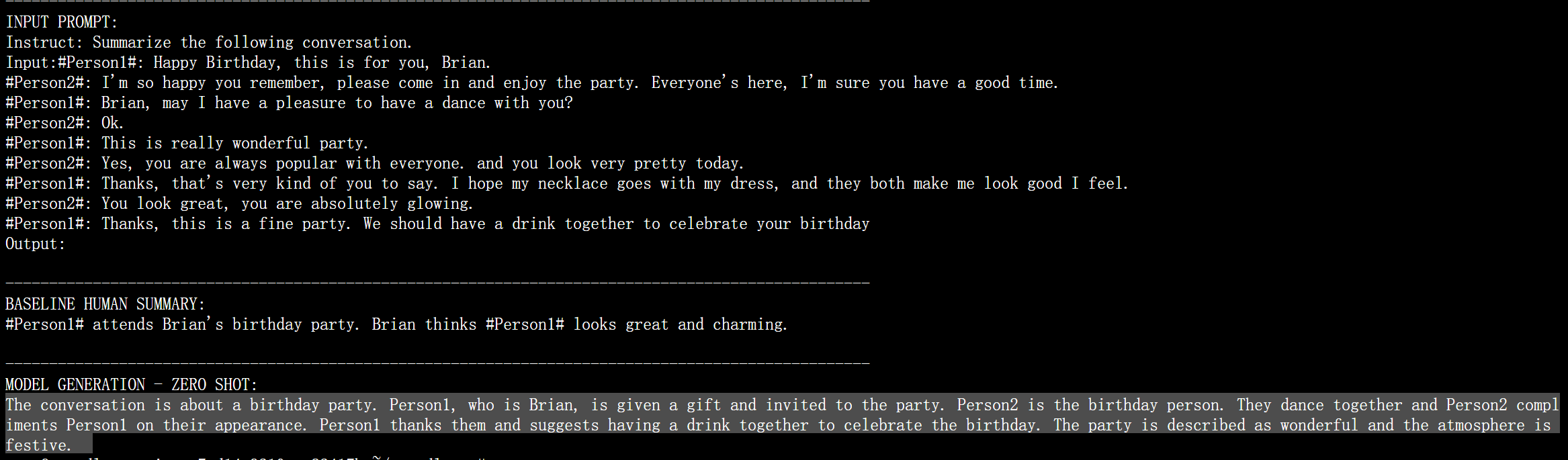
The conversation is about a birthday party. Person1, who is Brian, is given a gift and invited to the party. Person2 is the birthday person. They dance together and Person2 compliments Person1 on their appearance. Person1 thanks them and suggests having a drink together to celebrate the birthday. The party is described as wonderful and the atmosphere is festive.
这段对话是关于生日聚会的。第一个人布莱恩收到了一份礼物,并被邀请参加聚会。第二个人是过生日的人。他们一起跳舞,第二个人称赞第一个人的外表。第一人向他们表示感谢,并建议一起喝一杯庆祝生日。晚会被形容为精彩绝伦,气氛喜庆。
微调后:
checkpoint-500:
#Person1# gives Brian a birthday gift. Brian invites #Person1# to the party. #Person1# dances with Brian. Brian
thinks #Person1# looks great. They have a drink together to
celebrate Brian’s birthday. #Person1# thanks Brian.
#Person1# thinks the party is wonderful. #Person1# feels happy. #Person1# thanks Brian again. #Person1# thinks
the party is great. #Person1# feels happy. #Person1
#Person1#送给布莱恩一份生日礼物。布莱恩邀请某人参加聚会。#Person1#和布莱恩跳舞。布莱恩认为#Person1#看起来很棒。他们一起喝酒庆祝布莱恩的生日。谢谢,布莱恩。#Person1#认为这个聚会很棒。#Person1#感到快乐。再次感谢布莱恩。#Person1#认为这个派对很棒。#Person1#感到快乐。# Person1
checkpoint-1200:
#Person1# gives Brian a birthday gift and they dance together. Brian thinks #Person1# looks great and they have a drink together.
#Person1# thinks the party is wonderful. #Person2# thinks #Person1# is popular with everyone. #Person1# thanks #Person2# for the
compliment. #Person2# thinks #Person1# looks great. #Person1#
thinks the party is wonderful. #Person2# thinks #Person1# is popular
with
#Person1#送给布莱恩一份生日礼物,他们一起跳舞。布莱恩认为#Person1#看起来很棒,他们一起喝了一杯。#Person1#认为这个聚会很棒。#Person2#认为#Person1#很受大家欢迎。#人物1#感谢#人物2#的赞美。#Person2#认为#Person1#看起来很棒。#Person1#认为这个聚会很棒。#Person2#认为#Person1#很受欢迎
checkpoint-1900:
#Person1# gives Brian a birthday gift and they dance together. Brian thinks #Person1# looks great. #Person1# thanks and suggests having a
drink together. #Person2# agrees. #Person1# thinks the party is
wonderful. #Person2# thinks #Person1# is popular with everyone.
#Person1# feels #Person1# looks good. #Person2# thinks #Person1# is absolutely glowing. #Person1# thanks. #Person2#
#Person1#送给布莱恩一份生日礼物,他们一起跳舞。布莱恩认为#Person1#看起来很棒。谢谢,并建议一起喝一杯。# Person2 #表示同意。#Person1#认为这个聚会很棒。#Person2#认为#Person1#很受大家欢迎。#Person1#感觉#Person1#看起来不错。#Person2#认为#Person1#非常耀眼。# Person1 #谢谢。# Person2 #


