Spark流水线+Gravitino+Marquez数据血缘采集_marquez 部署
1.Openlinage和Marquez简介
1.1 OpenLineage
概述
- OpenLineage 是一个开放标准和框架,用于跨工具、平台和系统捕获数据血缘信息。
- 它定义了通用的数据血缘模型和API,允许不同的数据处理工具(如ETL、调度器、数据仓库)以标准化格式生成血缘元数据。
- 由Linux基金会托管,社区驱动,支持广泛的集成。
核心功能
- 标准化元数据收集:通过统一的规范(基于JSON Schema)描述数据血缘,包括作业(Job)、数据集(Dataset)和运行(Run)等实体。
- 跨工具集成:支持与Airflow、Spark、dbt、Great Expectations等流行数据工具的集成。
- 可扩展性:允许用户自定义提取器(Extractors)或适配器来兼容其他工具。
典型应用场景
- 数据治理(如合规性审计)。
- 故障排查(追踪数据错误来源)。
- 影响分析(评估上游变更对下游的影响)。
1.2. Marquez
概述
- Marquez 是OpenLineage的参考实现,是一个开源元数据服务,专为数据血缘和元数据管理设计。
- 由WeWork团队最初开发,现由社区维护,与OpenLineage深度集成。
- 提供Web UI和API,用于存储、查询和可视化血缘信息。
核心功能
- 元数据存储:持久化存储OpenLineage格式的血缘数据(使用PostgreSQL或兼容的数据库)。
- 血缘可视化:通过Web界面展示数据集、作业和依赖关系的图谱。
- API支持:提供REST API供其他系统访问或写入元数据。
- 与OpenLineage生态集成:自动接收来自支持OpenLineage的工具(如Airflow)的血缘事件。
架构组成
- API服务:处理血缘事件的摄入和查询。
- Web UI:交互式查看血缘关系。
- 后端数据库:存储元数据。
如果需要进一步了解部署或集成细节,可以参考它们的官方文档:
- OpenLineage官网
- Marquez GitHub
2.Gravitino血缘配置
Gravitino血缘事件采集后,默认是输出到日志,如果需要处理,可以实现org.apache.gravitino.lineage.sink.LineageSink进行扩展。
本文便实现此接口,通过http接口将血缘事件发送到Marquez,进行血缘的存储和展示。
package org.apache.gravitino.lineage.sink;import com.fasterxml.jackson.databind.ObjectMapper;import io.openlineage.server.OpenLineage.RunEvent;import java.io.IOException;import java.util.HashMap;import java.util.Map;import org.apache.commons.lang3.StringUtils;import org.apache.gravitino.server.web.ObjectMapperProvider;import org.apache.hc.client5.http.classic.methods.HttpPost;import org.apache.hc.client5.http.classic.methods.HttpPut;import org.apache.hc.client5.http.classic.methods.HttpUriRequestBase;import org.apache.hc.client5.http.impl.classic.CloseableHttpClient;import org.apache.hc.client5.http.impl.classic.CloseableHttpResponse;import org.apache.hc.client5.http.impl.classic.HttpClients;import org.apache.hc.core5.http.ContentType;import org.apache.hc.core5.http.io.entity.StringEntity;import org.slf4j.Logger;import org.slf4j.LoggerFactory;public class LineageHttpSink implements LineageSink { private static final Logger LOG = LoggerFactory.getLogger(LineageHttpSink.class); private String url; private String endpoint; private String method; private Map<String, String> headers; private CloseableHttpClient httpClient; private ObjectMapper objectMapper; private int retryCount; private long retryDelayMs; @Override public void initialize(Map<String, String> configs) { this.url = configs.get(\"http.url\"); this.endpoint = configs.getOrDefault(\"http.endpoint\", \"/api/v1/lineage\"); this.method = configs.getOrDefault(\"http.method\", \"POST\"); this.retryCount = Integer.parseInt(configs.getOrDefault(\"http.retry.count\", \"3\")); this.retryDelayMs = Long.parseLong(configs.getOrDefault(\"http.retry.delay\", \"1000\")); this.headers = parseHeaders(configs.getOrDefault(\"http.headers\", \"\")); this.httpClient = HttpClients.createDefault(); this.objectMapper = ObjectMapperProvider.objectMapper(); LOG.info(\"Initialized HTTP sink with URL: {}{}\", url, endpoint); } @Override @SuppressWarnings(\"deprecation\") public void sink(RunEvent event) { String fullUrl = url + endpoint; for (int attempt = 0; attempt <= retryCount; attempt++) { try { String jsonPayload = objectMapper.writeValueAsString(event); HttpUriRequestBase request = createHttpRequest(fullUrl, jsonPayload); headers.forEach(request::setHeader); try (CloseableHttpResponse response = httpClient.execute(request)) { int statusCode = response.getCode(); if (isSuccessResponse(statusCode)) { LOG.debug(\"Successfully sent lineage event to {}\", fullUrl); return; } else { LOG.warn(\"HTTP request failed with status {}\", statusCode); } } } catch (Exception e) { LOG.warn( \"Attempt {} failed to send lineage event to {}: {}\", attempt + 1, fullUrl, e.getMessage()); if (attempt == retryCount) { LOG.error(\"Failed to send lineage event after {} attempts\", retryCount + 1, e); return; } } if (attempt < retryCount) { try { Thread.sleep(retryDelayMs * (attempt + 1)); } catch (InterruptedException ie) { Thread.currentThread().interrupt(); return; } } } } private HttpUriRequestBase createHttpRequest(String url, String jsonPayload) { HttpUriRequestBase request; switch (method.toUpperCase()) { case \"POST\": request = new HttpPost(url); break; case \"PUT\": request = new HttpPut(url); break; default: throw new IllegalArgumentException(\"Unsupported HTTP method: \" + method); } StringEntity entity = new StringEntity(jsonPayload, ContentType.APPLICATION_JSON); request.setEntity(entity); return request; } private Map<String, String> parseHeaders(String headersString) { Map<String, String> headerMap = new HashMap<>(); if (StringUtils.isNotBlank(headersString)) { String[] pairs = headersString.split(\",\"); for (String pair : pairs) { String[] keyValue = pair.split(\":\", 2); if (keyValue.length == 2) { headerMap.put(keyValue[0].trim(), keyValue[1].trim()); } } } return headerMap; } private boolean isSuccessResponse(int statusCode) { return statusCode >= 200 && statusCode < 300; } @Override public void close() { if (httpClient != null) { try { httpClient.close(); } catch (IOException e) { LOG.warn(\"Error closing HTTP client\", e); } } LOG.info(\"HTTP sink closed\"); }}在gravitino.conf中添加以下配置
gravitino.lineage.source=httpgravitino.lineage.sinks=log,openlineage gravitino.lineage.openlineage.sinkClass=org.apache.gravitino.lineage.sink.LineageHttpSink gravitino.lineage.openlineage.http.url=http://127.0.0.1:5000gravitino.lineage.openlineage.http.endpoint=/api/v1/lineage gravitino.lineage.openlineage.http.method=POST gravitino.lineage.openlineage.http.headers=Content-Type:application/jsongravitino.lineage.openlineage.http.retry.count=3 gravitino.lineage.openlineage.http.retry.delay=1000其中gravitino.lineage.openlineage.http.url填写的是Marquez地址
gravitino.lineage.openlineage.http.endpoint填写的是Marquez接收血缘事件的接口。
3. 集成演示
如需开启血缘采集功能,首先需要下载 Gravitino OpenLineage 插件 jar 并将其放置到 Spark 的类路径中。
(gravitino-openlineage-plugins/spark-plugin at main · datastrato/gravitino-openlineage-plugins)
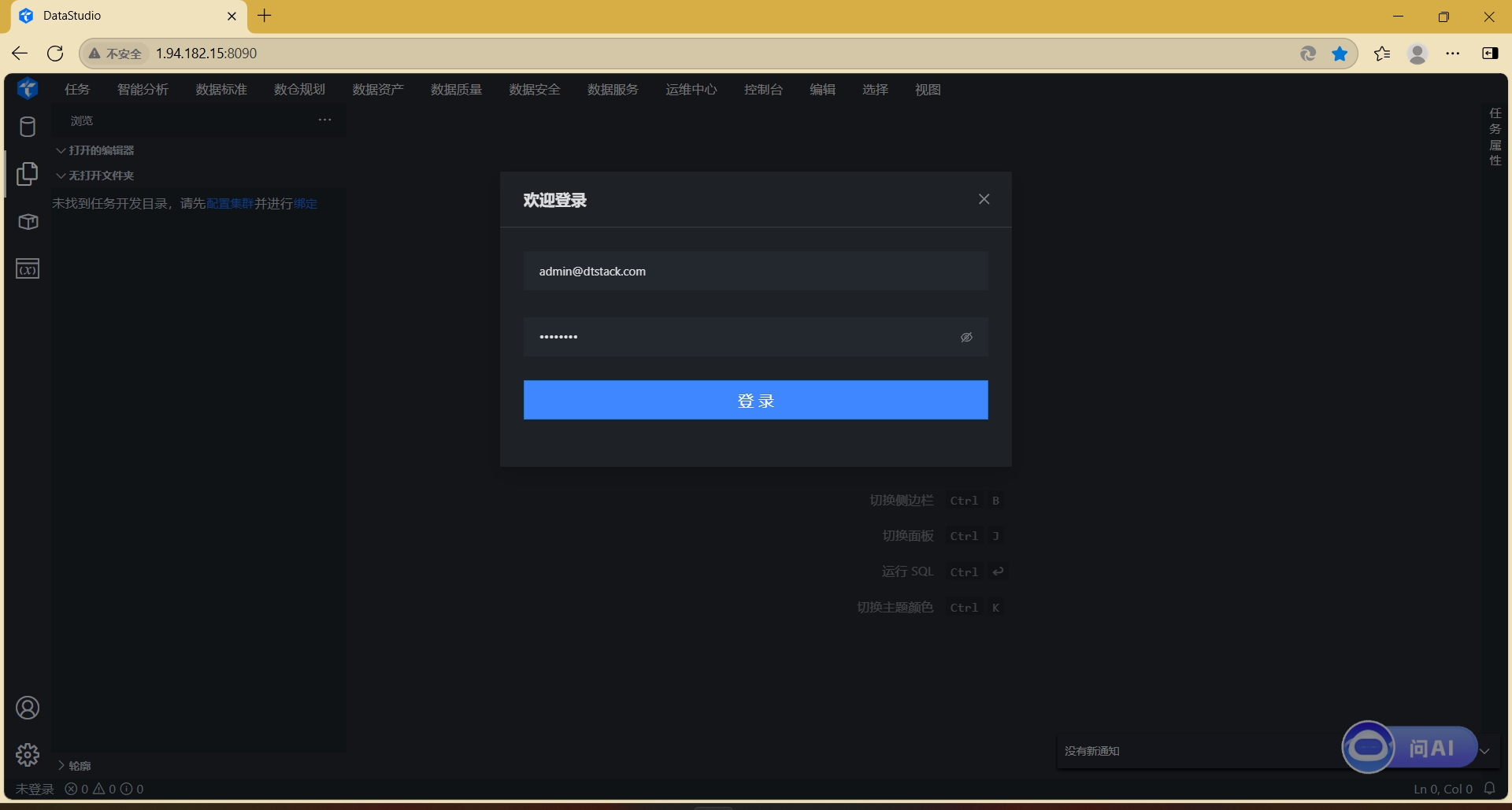
3.1 访问系统登录页面,输入账号密码完成身份验证。
3.2 创建任务
-
入口:通过顶部菜单栏选择 任务开发,或通过快捷入口 快速创建任务。
-
任务类型:选择
SparkPipeline。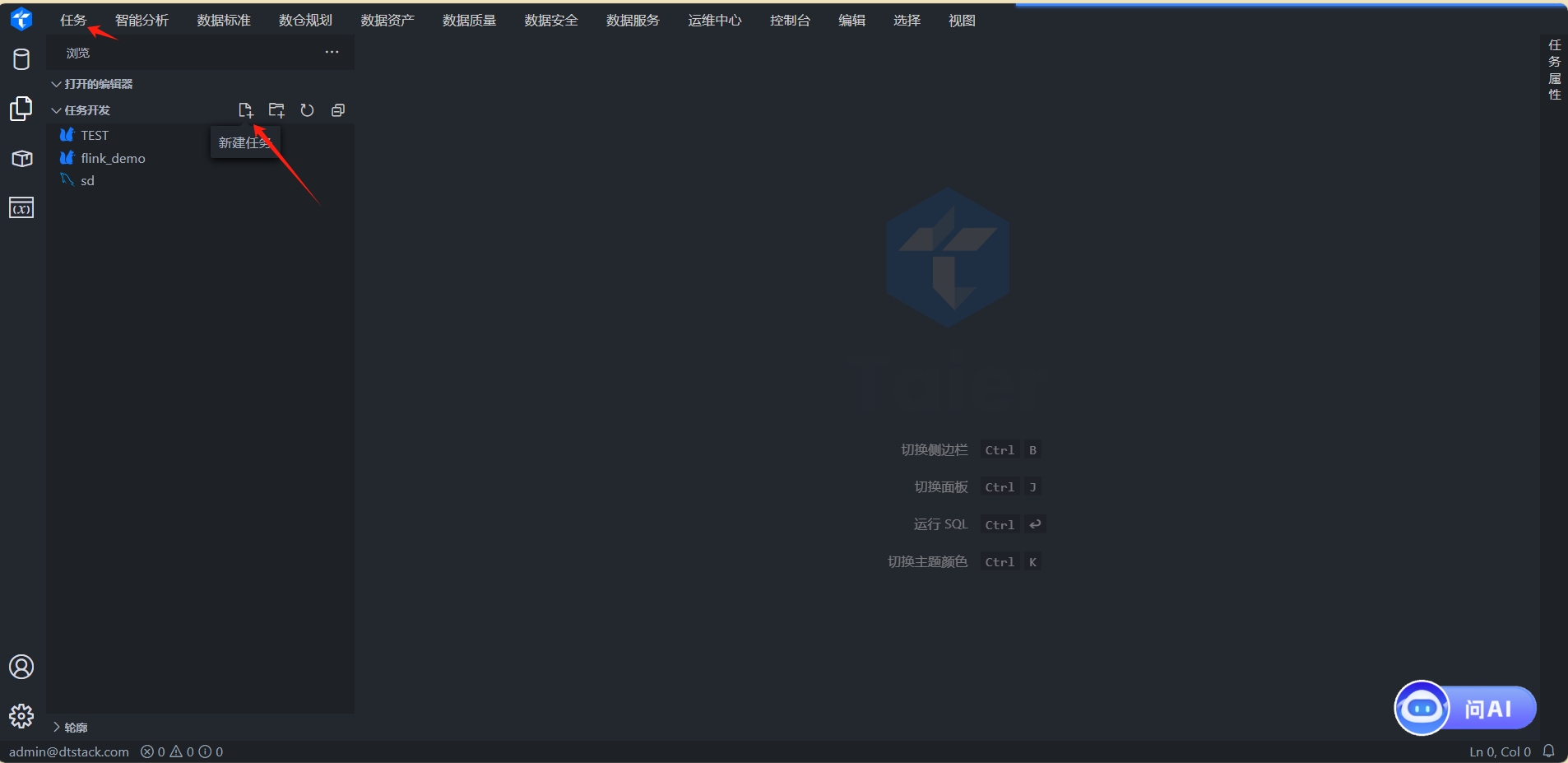
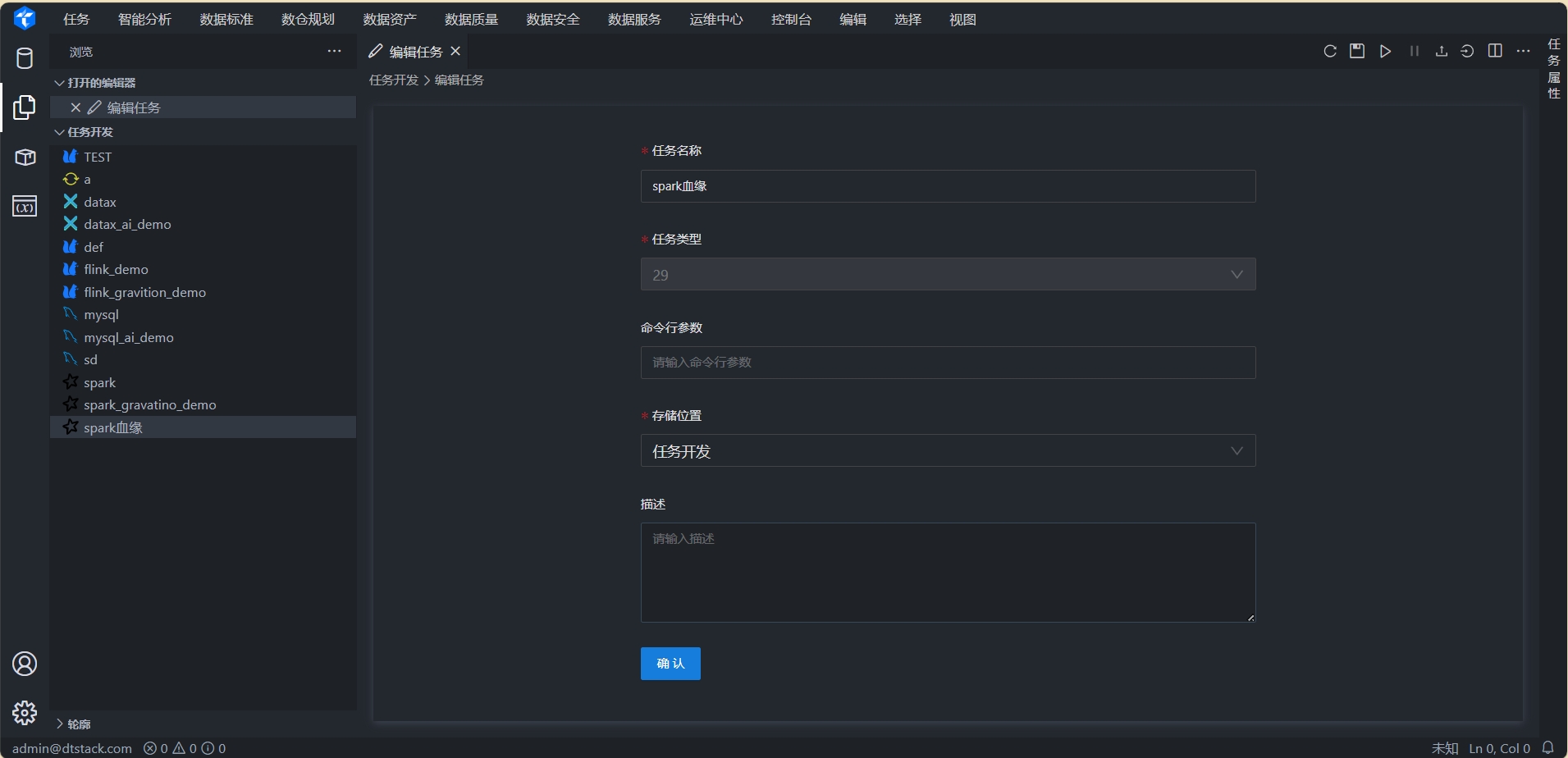
3.3 配置任务
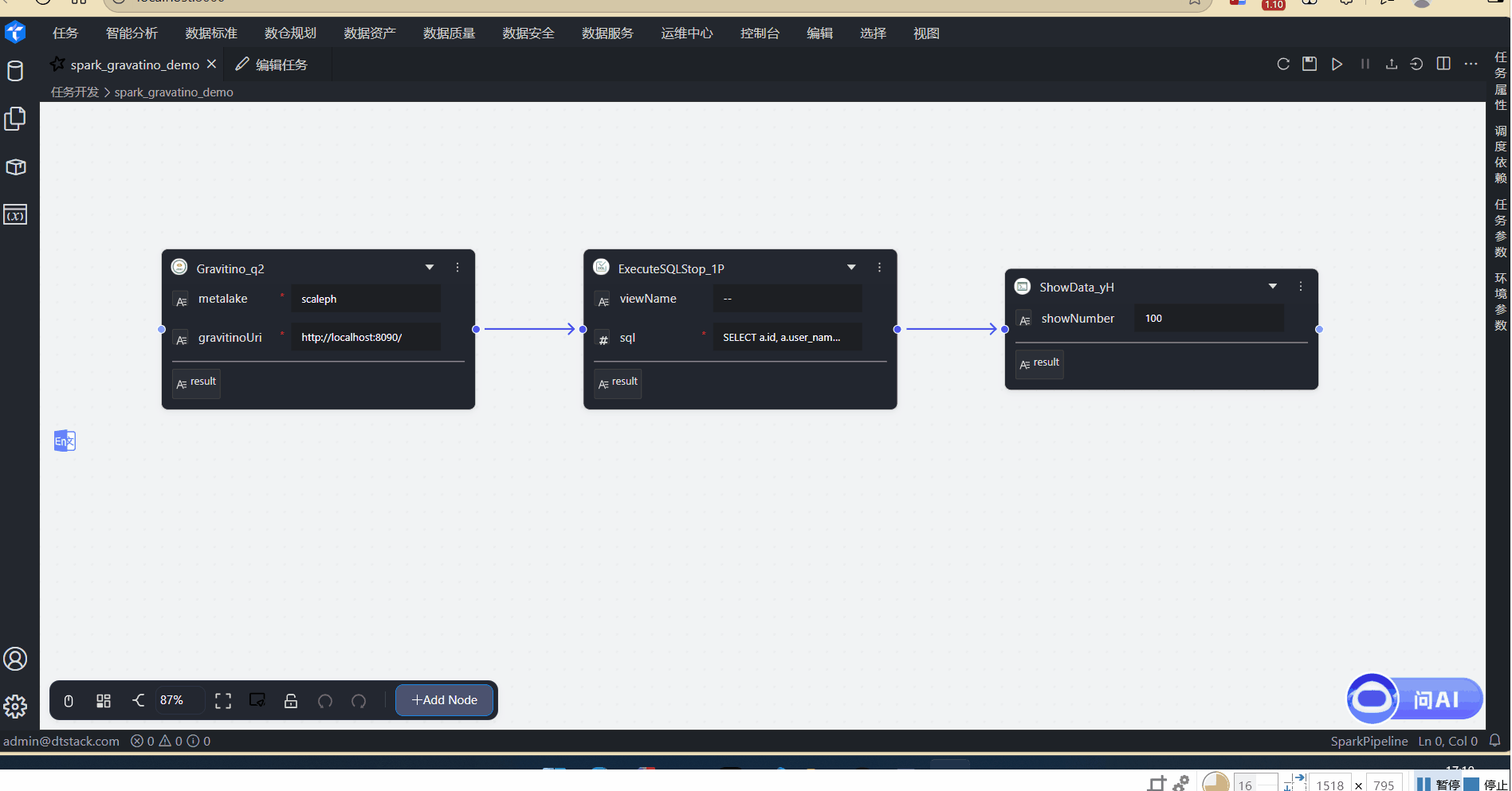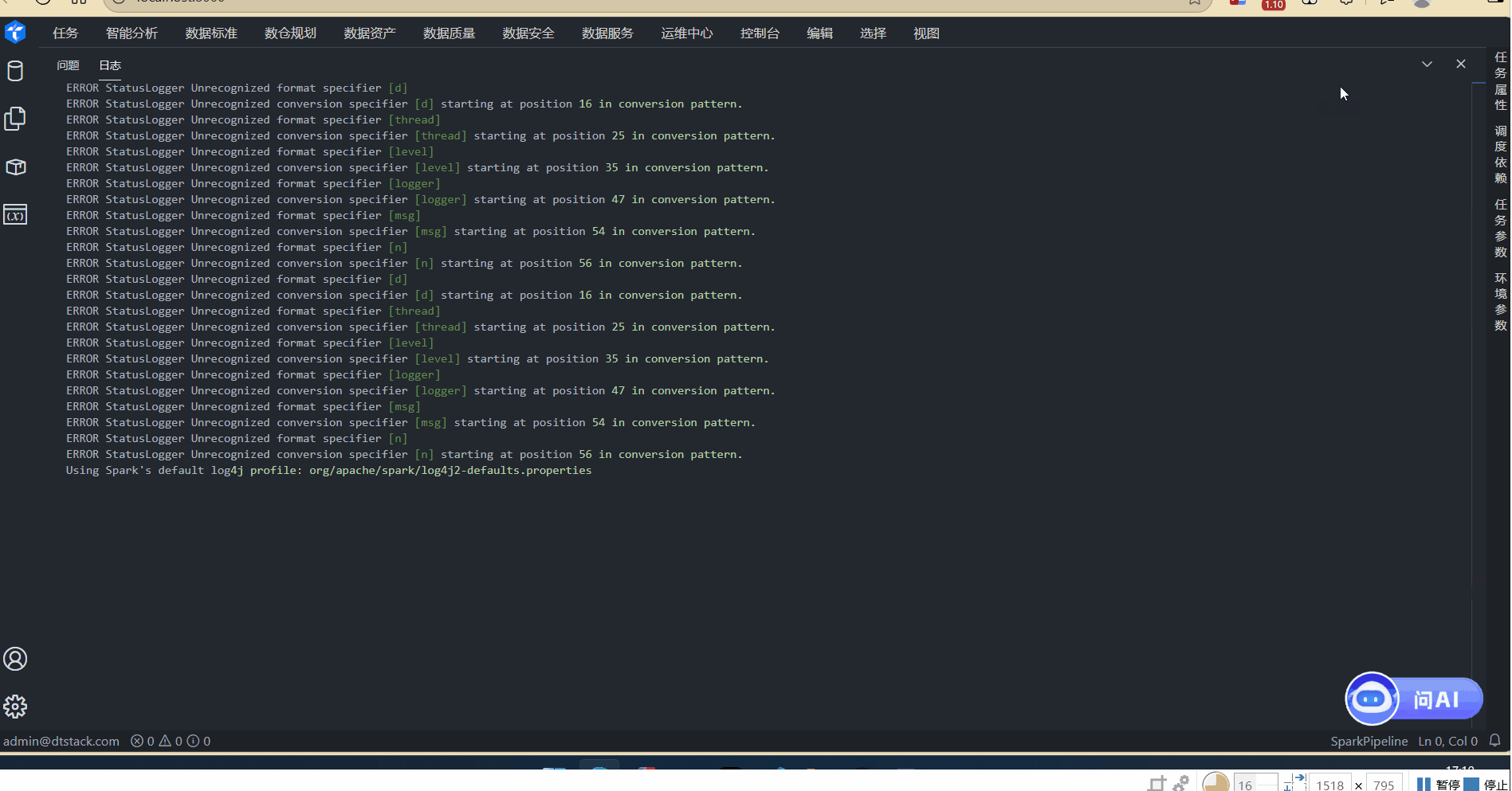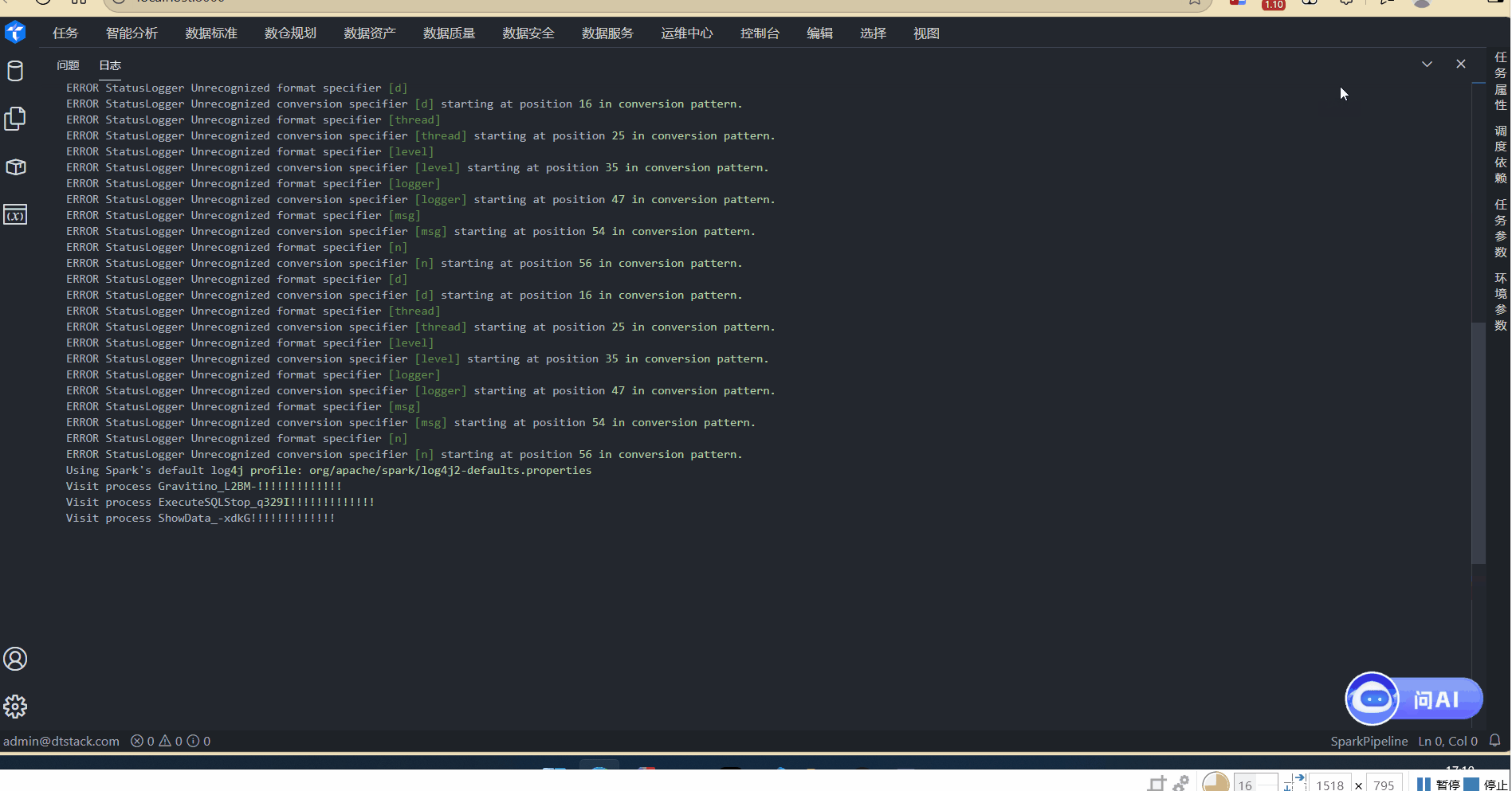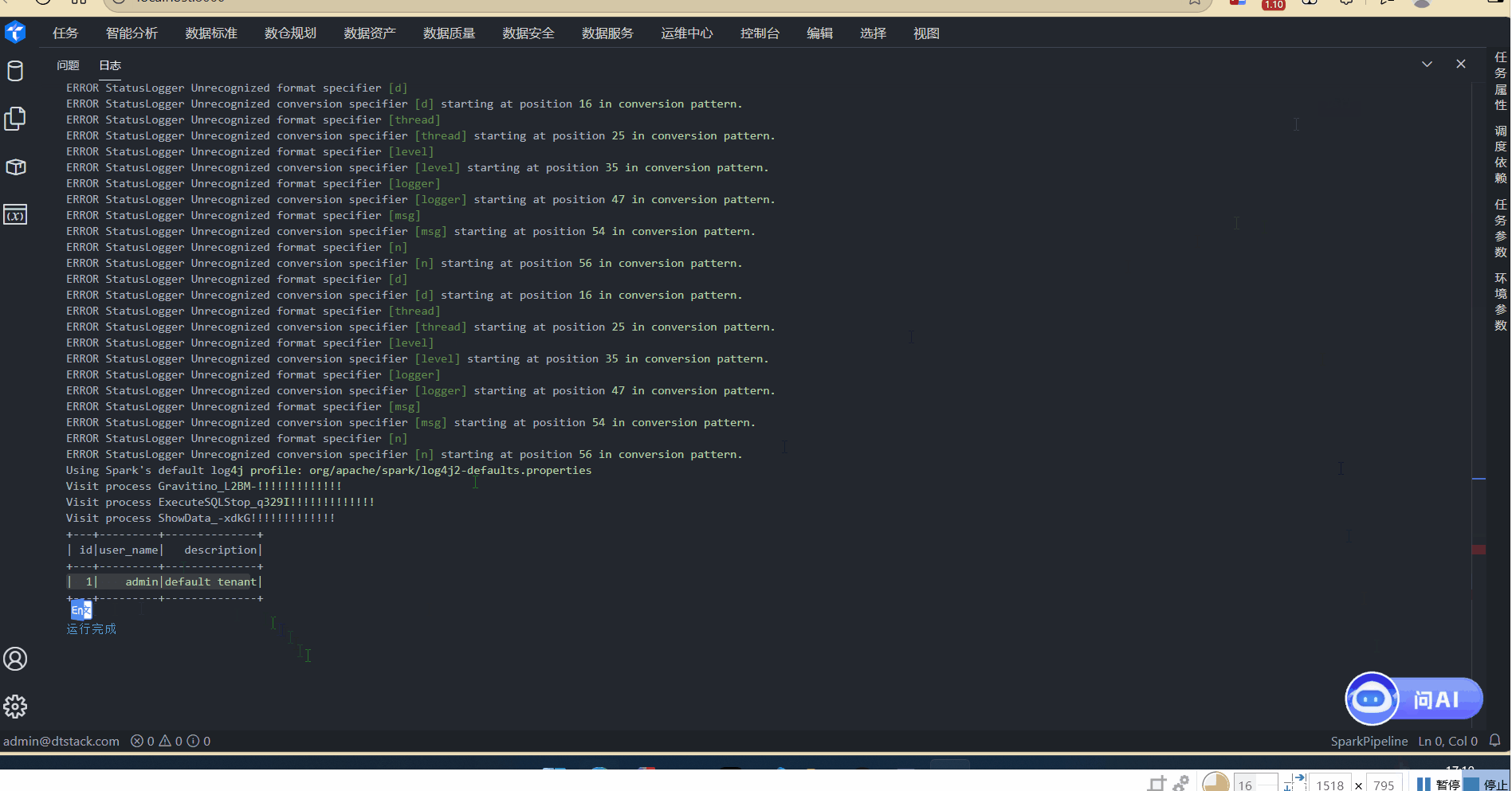
点击任务名称,进入任务详情页。任务节点如下
-
Gravatino节点:配置Gravatino连接信息,并设置
enableLinage为true,开起血缘采集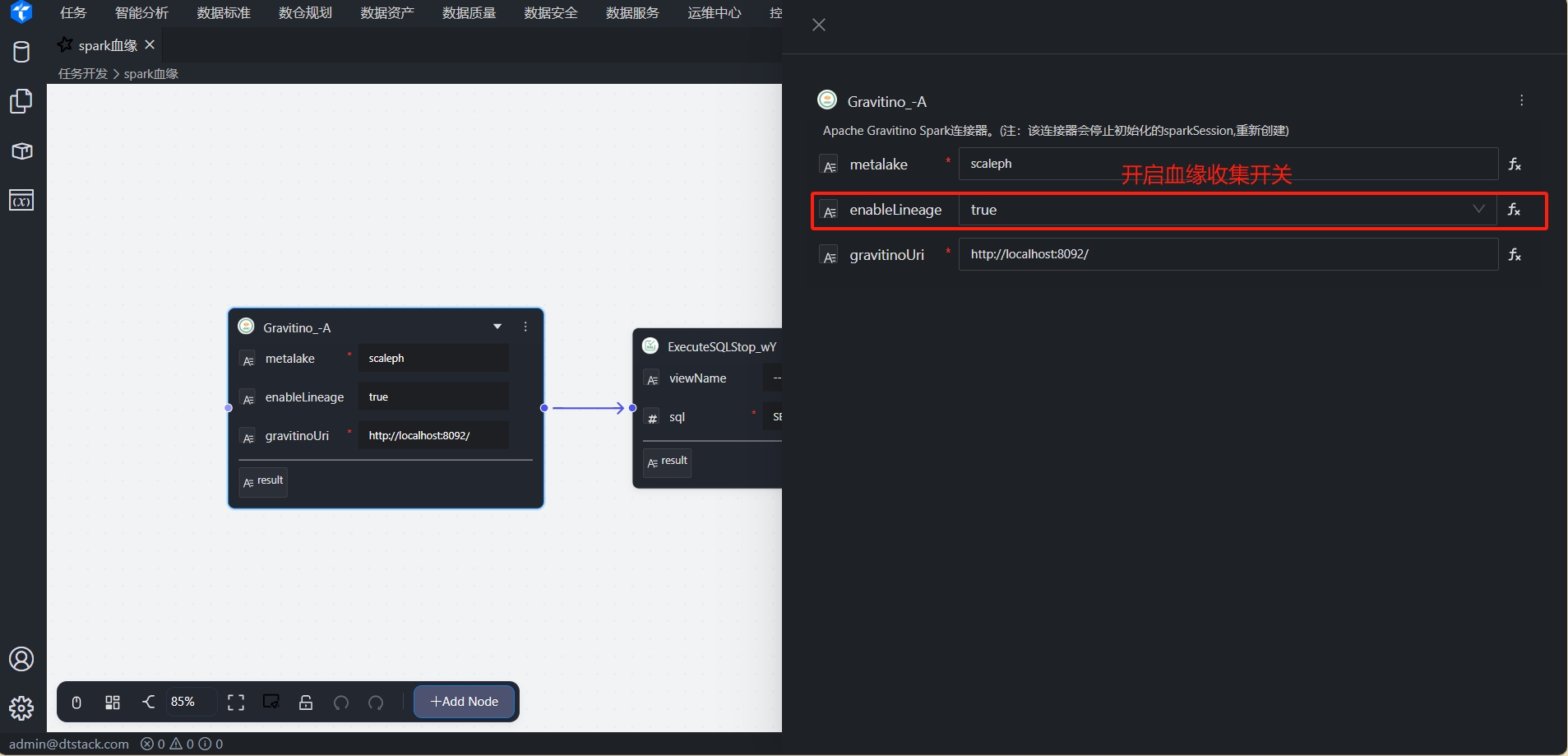
SQLQuery节点:执行sql查询语句。跨catalog实现联邦查询
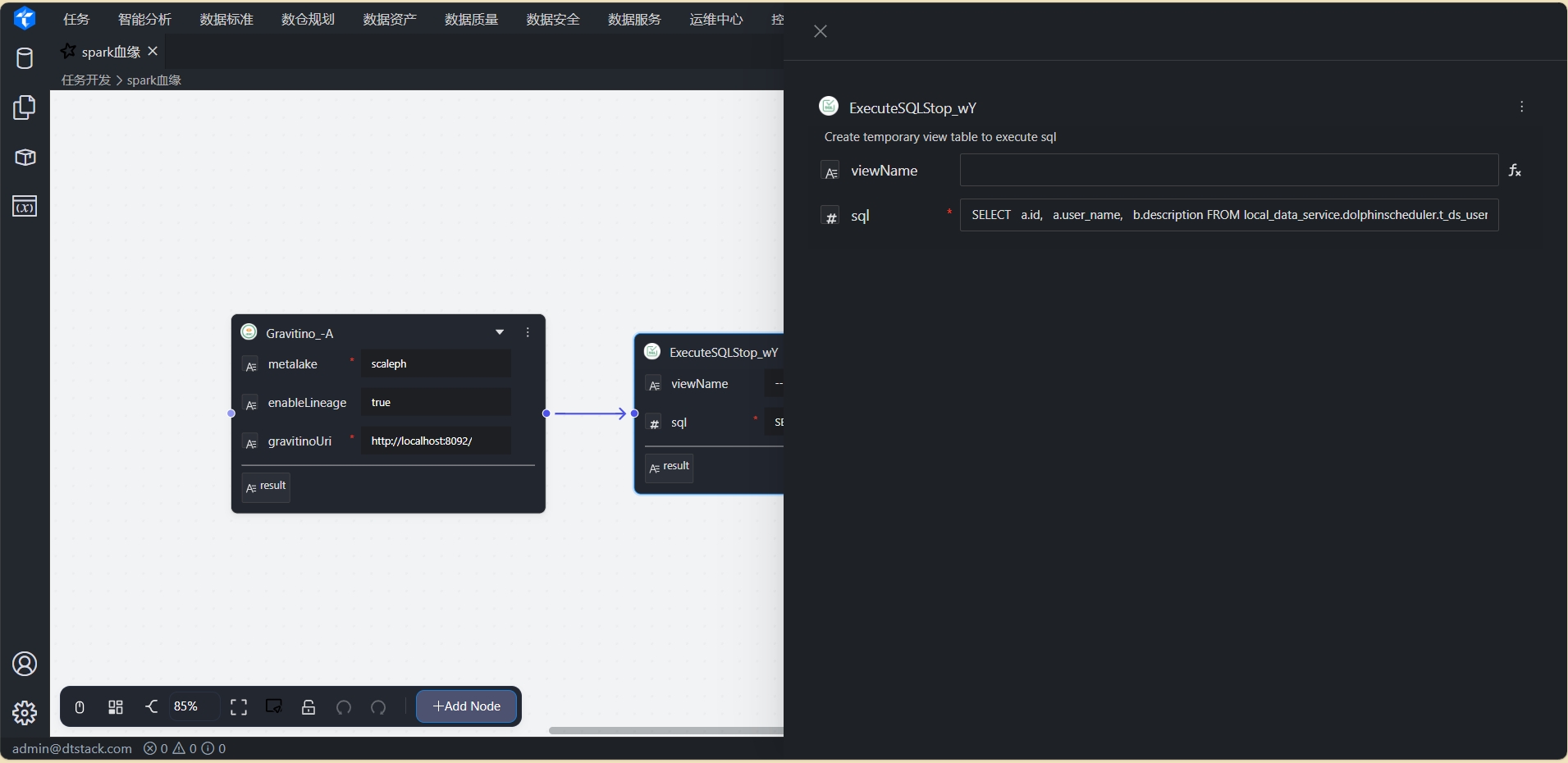
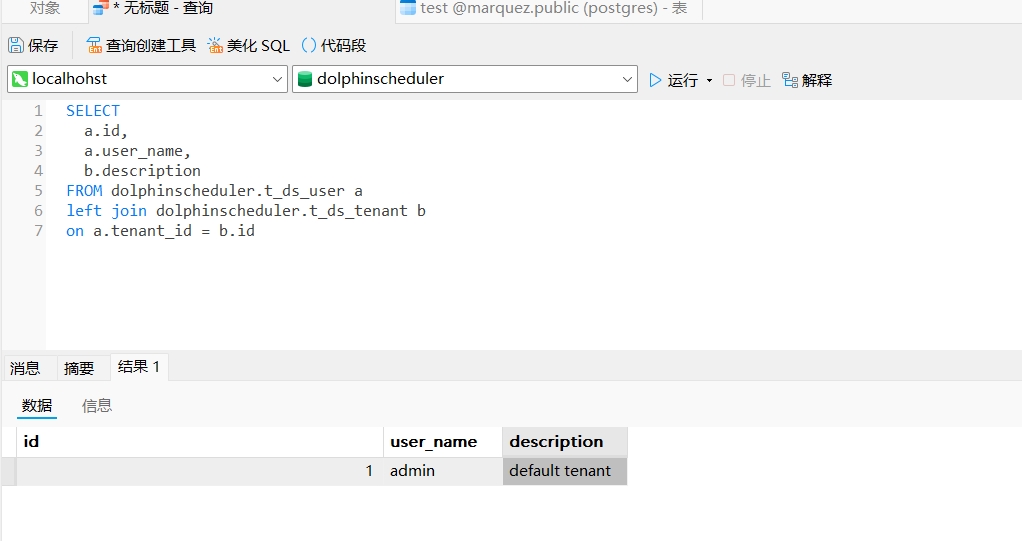
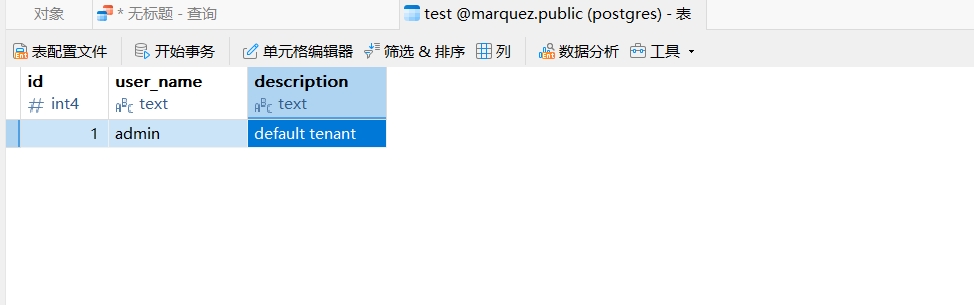
SELECT a.id, a.user_name, b.description FROM local_data_service.dolphinscheduler.t_ds_user aleft join docker_data_service.dolphinscheduler.t_ds_tenant bon a.tenant_id = b.id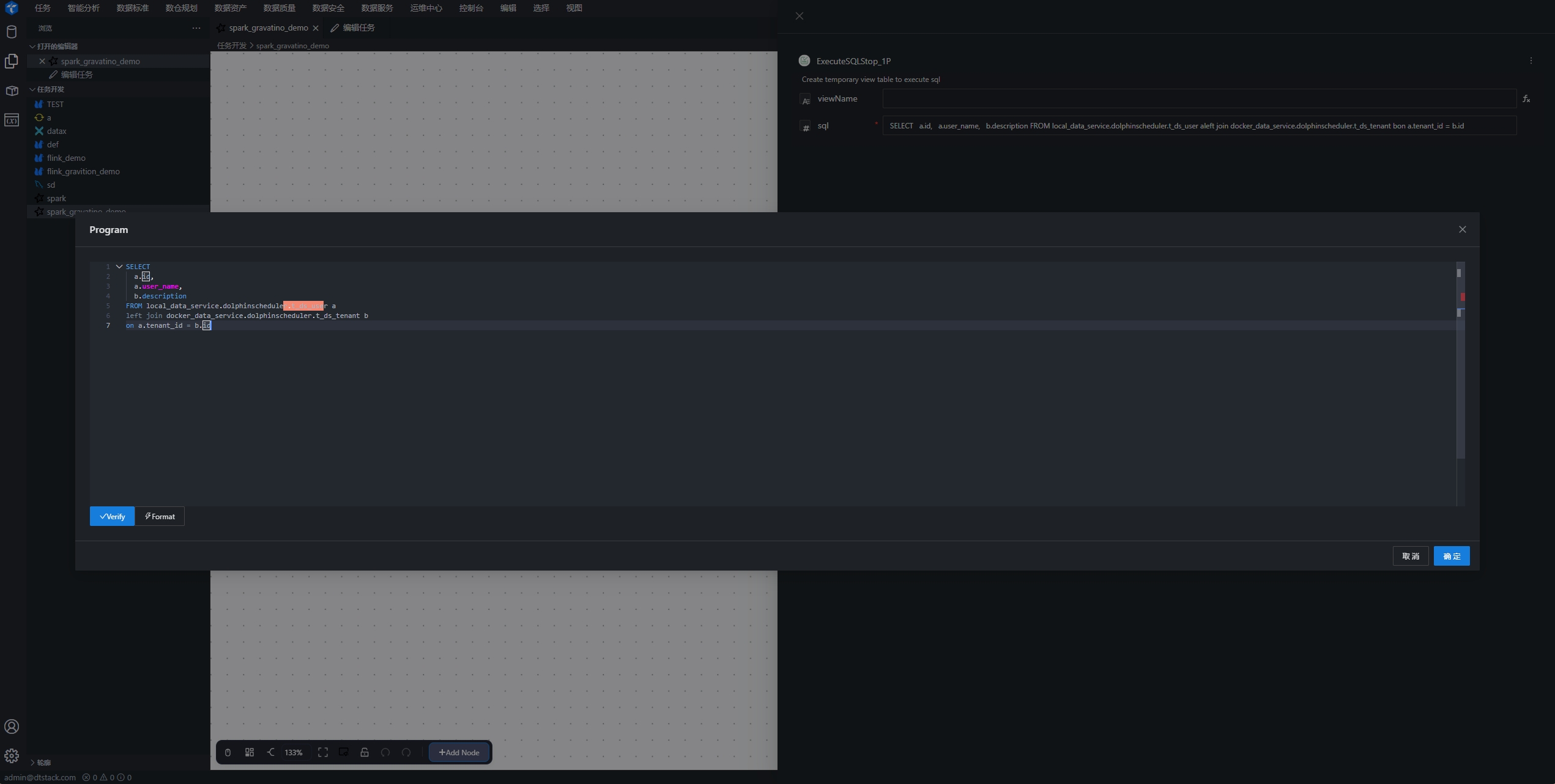
-
PostgresqlWrite节点:将查询结果写入到Postgres。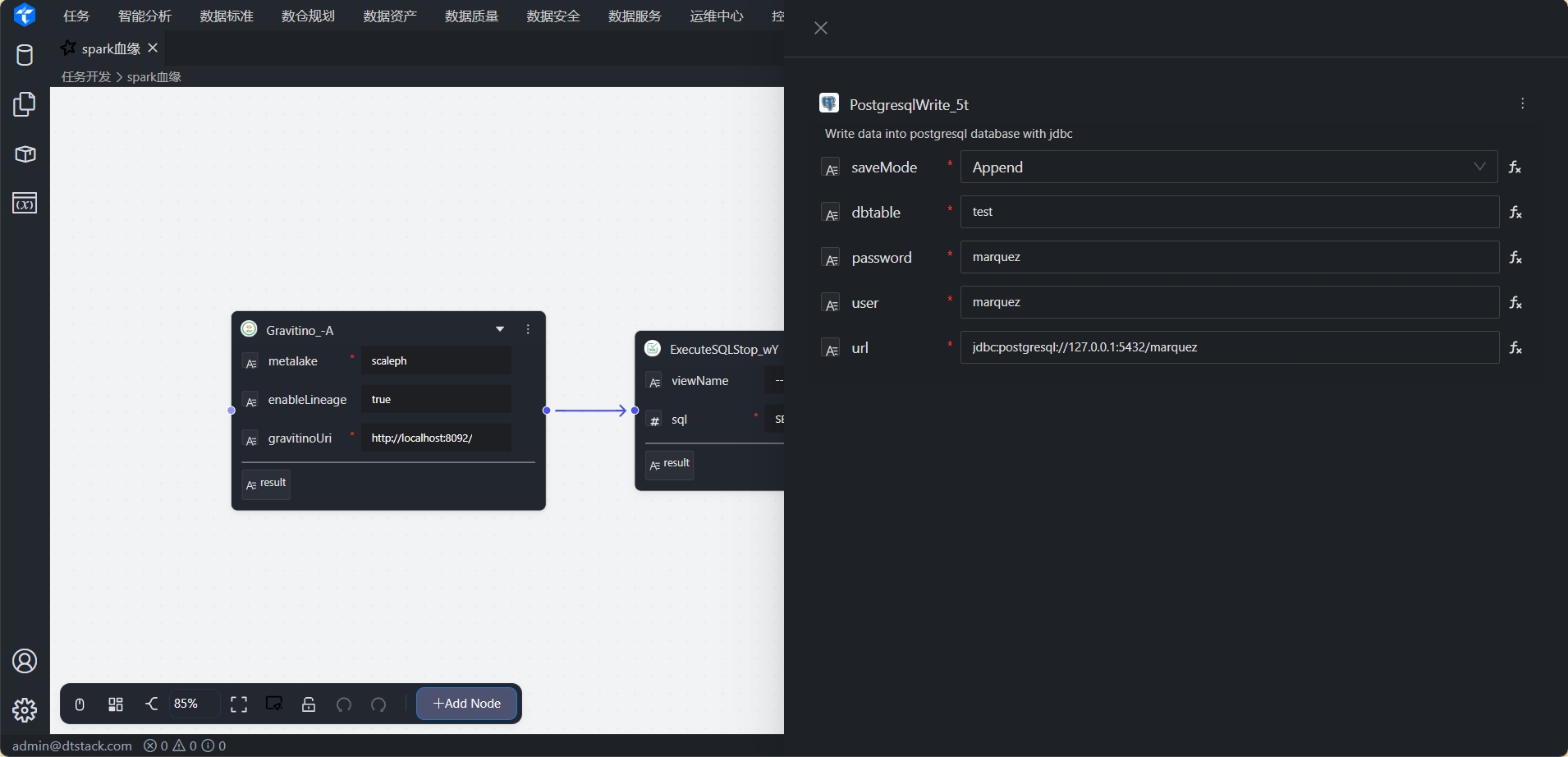
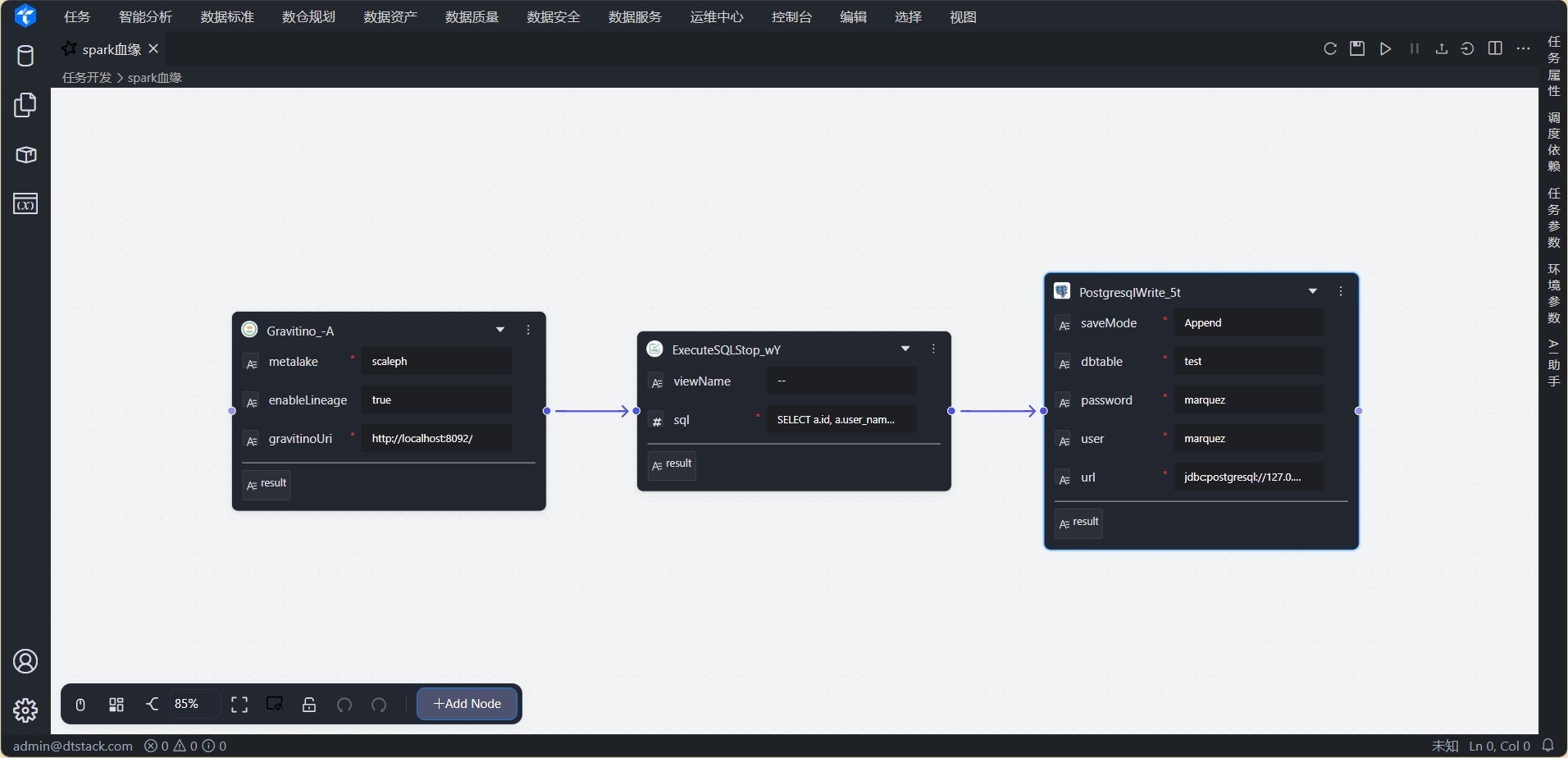
3.4 运行任务
- 点击 运行 按钮启动任务。
3.5 查看血缘
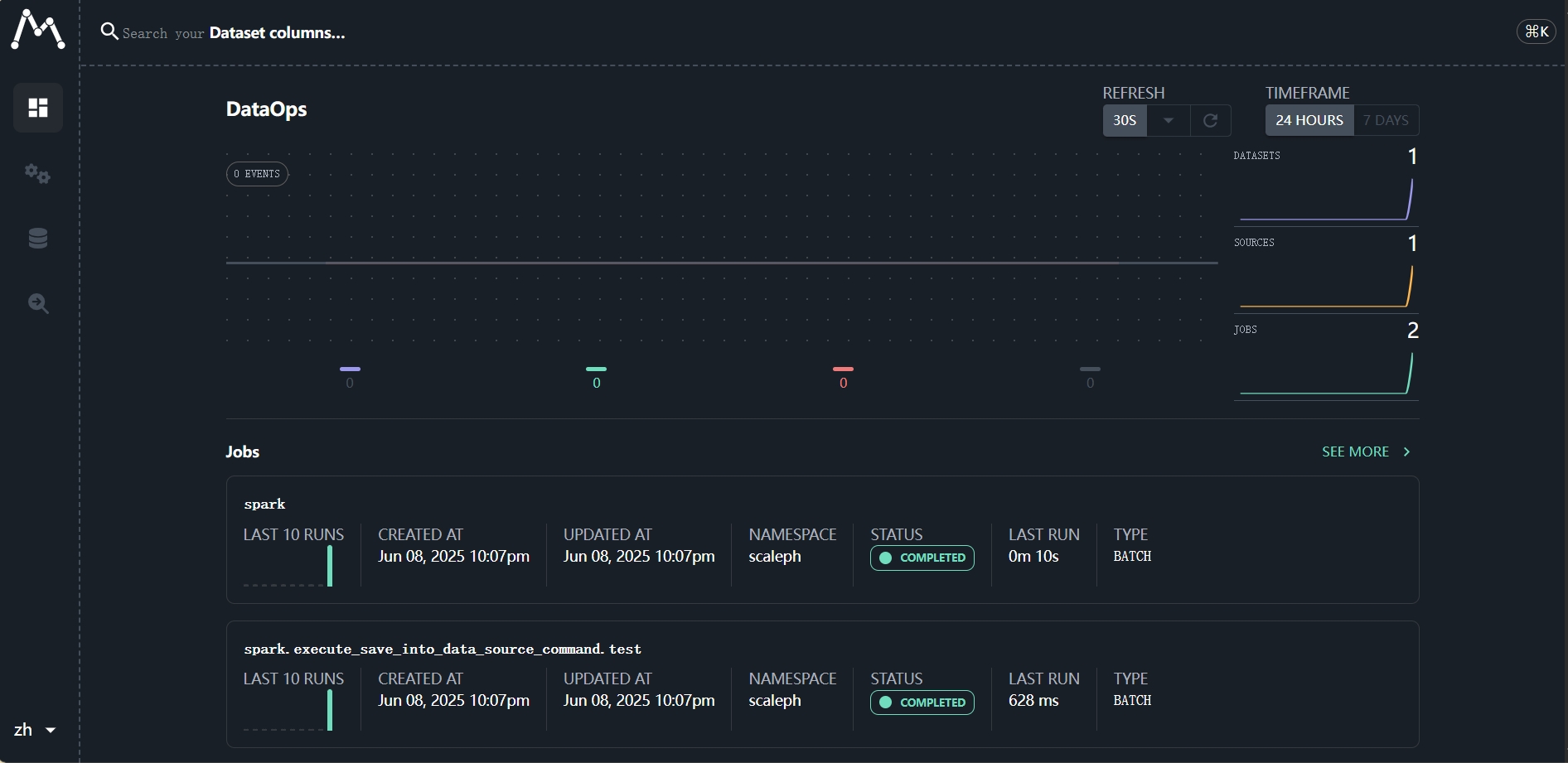
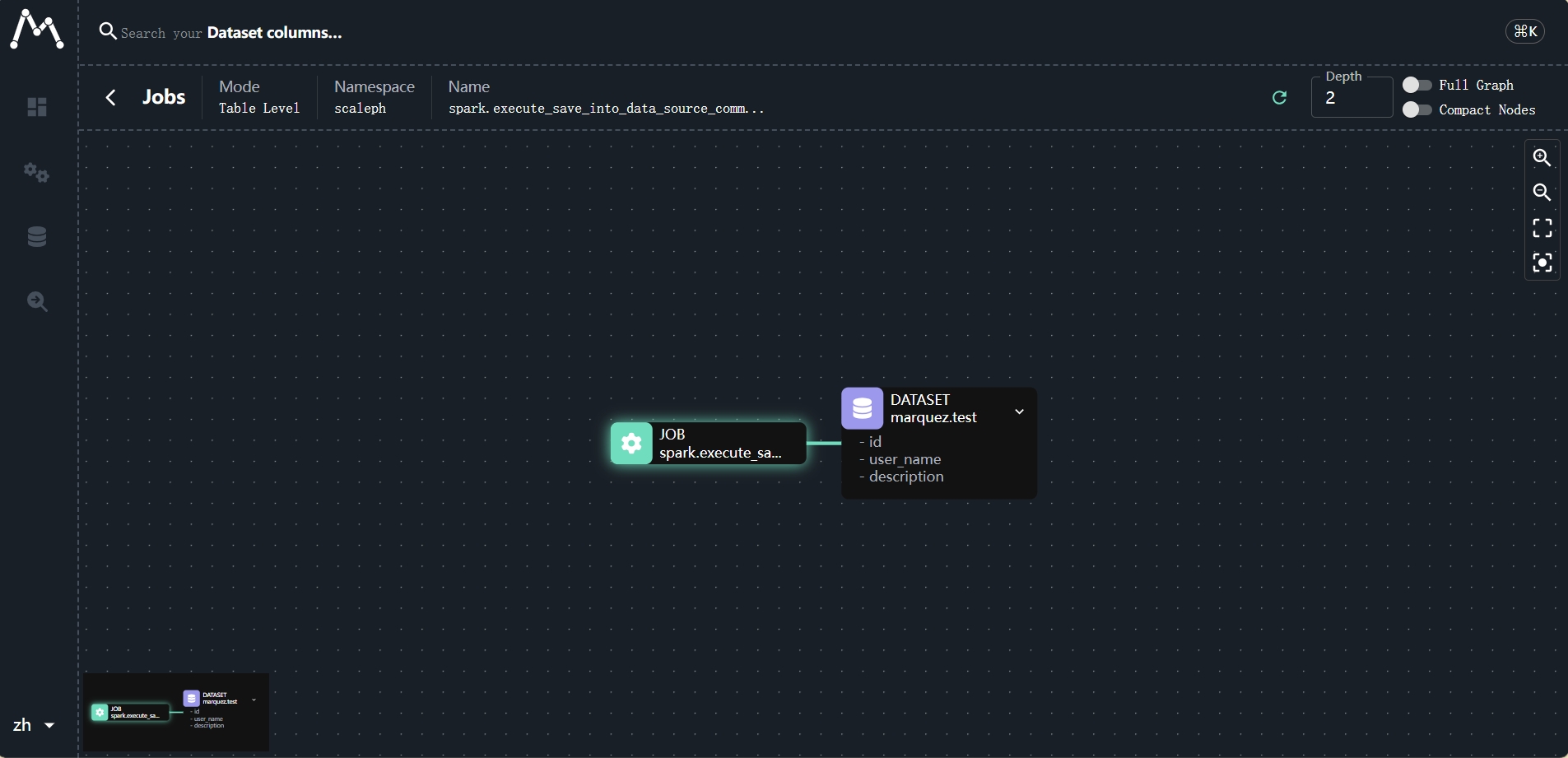
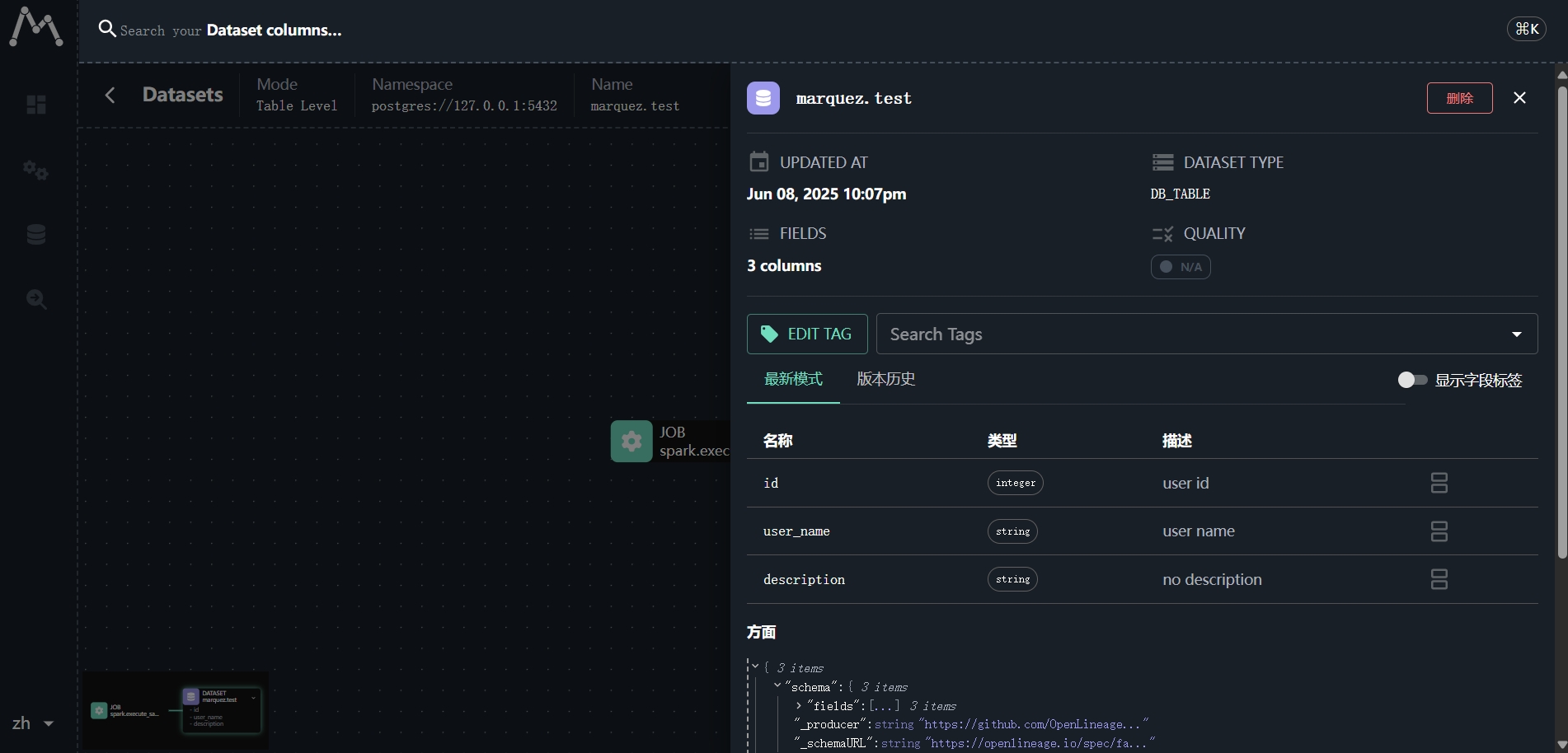
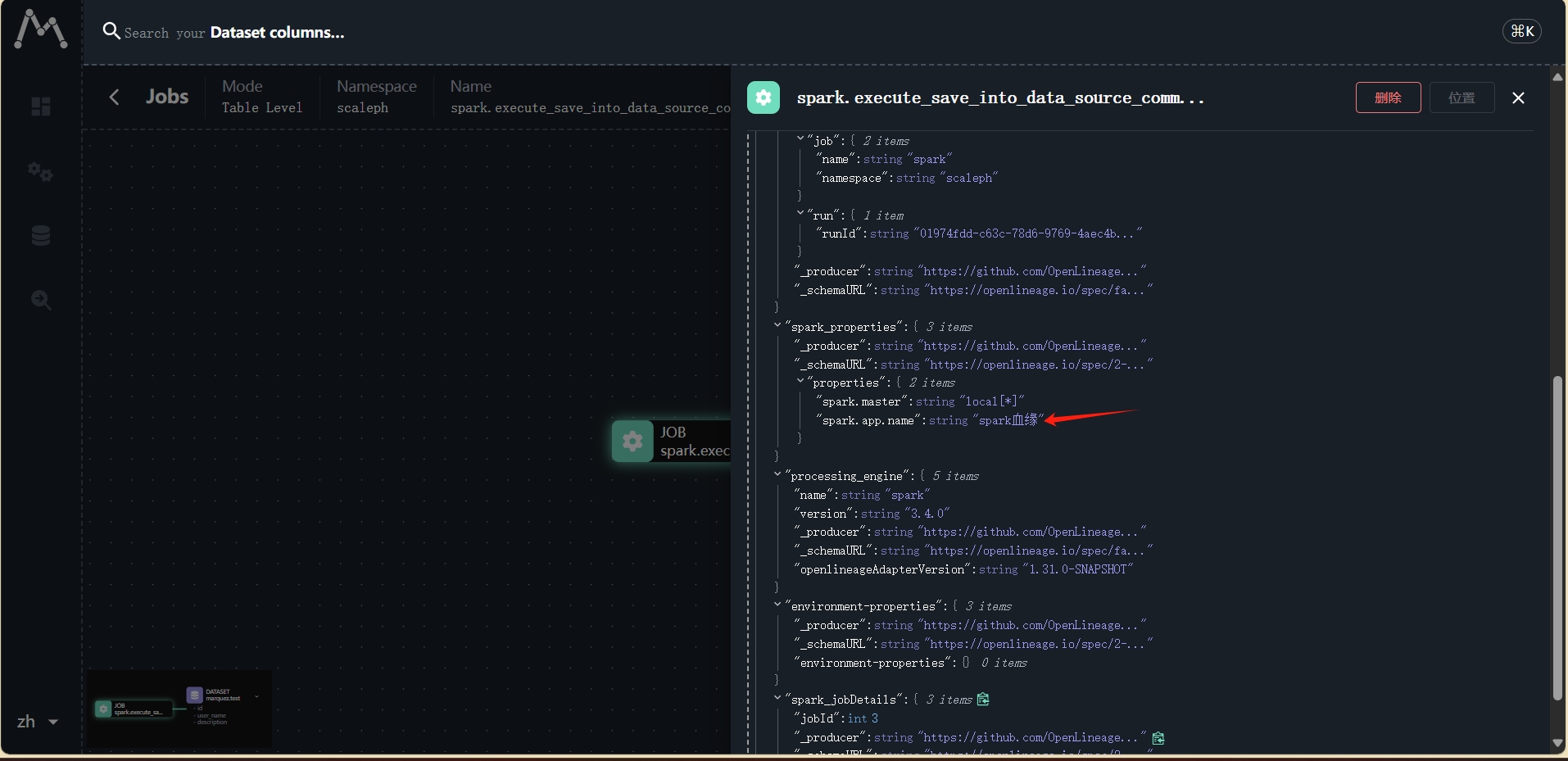
3.6 数据查询
🔗 平台体验地址:DataStudio (http://1.94.182.15:8090)
参考链接:
[1] https://github.com/datastrato/gravitino/
[2] https://datastrato.ai/blog/gravitino-unified-metadata-lake/
.6 数据查询
[外链图片转存中…(img-pQb0YwgS-1749396844654)]
[外链图片转存中…(img-hqrYlduK-1749396844654)]
🔗 平台体验地址:DataStudio (http://1.94.182.15:8090)
参考链接:
[1] https://github.com/datastrato/gravitino/
[2] https://datastrato.ai/blog/gravitino-unified-metadata-lake/
[3] Apache Gravitino Spark connector | Apache Gravitino


