Hive执行原理、MapReduce执行流程、Spark执行流程_hive mapreduce原理
Hive、MapReduce和Spark执行原理详解
Hive执行原理
Hive是基于Hadoop的数据仓库工具,其执行原理主要分为以下几个阶段:
SQL解析阶段
-
语法解析过程:
- HiveQL查询首先通过解析器(Antlr)进行语法解析
- 解析器会将SQL语句转换为语法树结构
- 进行词法分析和语法分析,检查语法正确性
-
抽象语法树生成:
- 生成抽象语法树(AST)
- 例如:
SELECT * FROM users WHERE age > 20会被解析为:- 根节点:SELECT
- 子节点1:FROM (users)
- 子节点2:WHERE (age > 20)
语义分析阶段
-
元数据验证:
- 检查表是否存在、字段是否存在等语义问题
- 验证表和列的数据类型
- 检查UDF函数是否存在
-
逻辑计划生成:
- 生成逻辑执行计划(Operator Tree)
- 进行类型检查和隐式类型转换
- 解析视图定义和子查询
逻辑优化阶段
-
优化规则应用:
- 谓词下推:将过滤条件尽早执行减少数据处理量
- 列裁剪:只读取查询需要的列
- 分区裁剪:只扫描相关的分区
- 连接重排序:优化多表连接顺序
-
优化示例:
SELECT a.name FROM table_a a JOIN table_b b ON a.id=b.id WHERE a.age>20 AND b.salary>5000优化后可能先执行过滤条件再执行连接操作
物理执行计划生成
-
执行引擎选择:
- 将逻辑计划转换为物理计划
- 决定使用MapReduce、Tez还是Spark引擎
- 考虑因素:数据量、查询复杂度、集群资源
-
任务划分:
- 将物理计划分解为多个可并行执行的阶段
- 确定shuffle操作的位置和方式
执行阶段
-
任务提交:
- 将物理计划转换为对应引擎的任务
- 提交到Hadoop集群执行
- 监控任务执行状态
-
执行监控:
- 跟踪任务进度
- 处理失败任务重试
- 收集执行统计信息
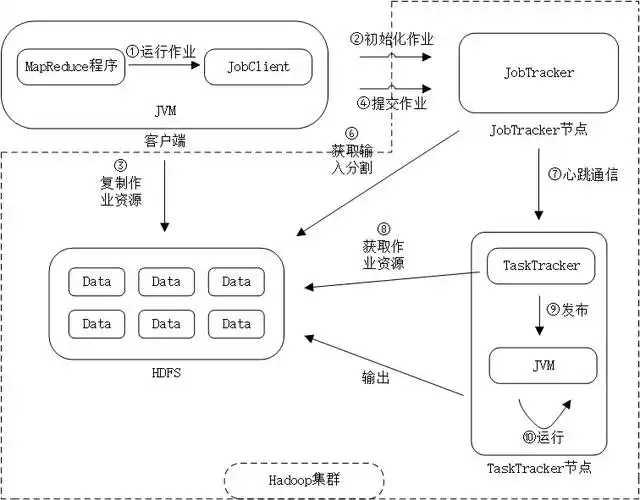
MapReduce执行流程
MapReduce是Hadoop的核心计算框架,其执行流程如下:
Input阶段
-
输入处理:
- InputFormat读取输入数据(如TextInputFormat)
- 将文件分割为多个InputSplit
- 每个分片由一个Map任务处理
-
分片细节:
- 默认分片大小等于HDFS块大小(128MB)
- 确保数据本地性,减少网络传输
Map阶段
-
数据处理:
- 每个Map任务处理一个分片
- 调用map()函数处理每条记录
- 输出中间键值对到内存缓冲区
-
缓冲区管理:
- 默认缓冲区大小100MB
- 缓冲区满时溢写到磁盘(分区、排序、合并)
- 可配置Combiner进行本地聚合
Shuffle阶段
-
数据传输:
- 将Map输出的数据通过网络传输到Reduce节点
- 按照key进行分区(默认使用HashPartitioner)
- 网络传输使用HTTP协议
-
数据重组:
- 每个分区的数据按键排序
- 合并相同key的值(Combiner可选)
- 使用归并排序算法处理大文件
Reduce阶段
-
数据处理:
- 每个Reduce任务处理一个或多个分区
- 对已排序的输入数据调用reduce()函数
- 输出最终结果到HDFS
-
并行度控制:
- Reduce任务数由用户指定
- 影响数据分布和负载均衡
Output阶段
- 结果输出:
- OutputFormat将结果写入存储系统
- 常见格式如TextOutputFormat、SequenceFileOutputFormat
- 支持自定义输出格式
WordCount示例执行流程
-
Map阶段:
- 输入:\"hello world hello\"
- 输出:(hello,1), (world,1), (hello,1)
-
Shuffle阶段:
- 分组后:(hello,[1,1]), (world,[1])
-
Reduce阶段:
- 输出:(hello,2), (world,1)
Spark执行流程
Spark是基于内存的分布式计算框架,其执行流程如下:
应用提交
-
初始化过程:
- 用户提交Spark应用(Driver程序)
- 创建SparkContext(集群连接的入口点)
- 配置执行参数(内存、核数等)
-
资源申请:
- 向资源管理器(YARN/Mesos/Standalone)申请资源
- 获取Executor资源容器
- 建立通信连接
DAG构建
-
RDD转换:
- Spark将用户代码转换为RDD的有向无环图(DAG)
- RDD转换操作(如map、filter)形成DAG的边
- 每个RDD记录其依赖关系
-
示例DAG:
sc.textFile(\"input.txt\") .flatMap(_.split(\" \")) .map((_,1)) .reduceByKey(_+_)- 构成4个RDD的DAG
DAG调度
-
阶段划分:
- DAGScheduler将DAG划分为多个Stage
- Stage边界是shuffle操作(如reduceByKey)
- 每个Stage包含多个可以并行执行的Task
-
优化策略:
- 合并窄依赖操作
- 识别可以流水线执行的操作
- 优化任务调度顺序
任务调度
-
任务分发:
- TaskScheduler将Task分发到Executor执行
- 考虑数据本地性(优先将任务调度到数据所在的节点)
- 处理任务失败和重试
-
资源管理:
- 动态分配资源
- 负载均衡
- 任务优先级调度
任务执行
-
执行流程:
- Executor执行具体的Task
- 对于窄依赖(map/filter),在内存中流水线执行
- 对于宽依赖(reduceByKey/join),需要shuffle数据
-
内存管理:
- 使用内存存储中间结果
- LRU缓存策略
- 可配置存储级别(内存、磁盘等)
结果返回
-
动作触发:
- Action操作(如collect、count)触发作业执行
- 结果返回Driver程序或保存到存储系统
- 显示执行进度和结果
-
结果处理:
- 小结果直接返回Driver
- 大结果写入HDFS等存储系统
- 支持多种输出格式
Spark与MapReduce的关键区别
内存计算机制
-
Spark的内存策略:
- 采用内存优先的计算策略
- 将中间计算结果优先存储在内存中
- 典型示例:在迭代算法(如PageRank)中,Spark比MapReduce快10-100倍
- 仅在内存不足时才会将部分数据溢出到磁盘
-
MapReduce的磁盘策略:
- 强制将每个Map和Reduce阶段的中间结果写入HDFS
- 每次迭代都需要读写磁盘
- 更适合一次性批处理作业
DAG执行引擎
-
Spark的DAG优化:
- 构建有向无环图(DAG)来优化执行计划
- 可以智能地合并多个MapReduce操作
- 减少不必要的shuffle
- 应用场景:ETL流水线中多个连续转换操作可以合并执行
-
MapReduce的线性执行:
- 需要显式地定义每个Map和Reduce阶段
- 每个阶段都需要完整的磁盘I/O
- 缺乏全局优化能力
延迟执行机制
-
Spark的惰性求值:
- 采用惰性求值,遇到Action操作才触发实际计算
- 允许进行全局优化(如谓词下推、列裁剪)
- 示例:filter+join+groupBy的转换链会整体优化后执行
-
MapReduce的立即执行:
- 立即执行每个独立的MapReduce作业
- 缺乏跨作业优化能力
- 需要手动优化作业链
适用场景对比
Spark最适合的场景
-
迭代式算法:
- 机器学习训练
- 图计算算法
- 推荐系统
-
交互式查询:
- 即席查询
- 数据探索分析
- BI工具集成
-
流式处理:
- 实时数据处理
- 复杂事件处理
- 流批一体化
MapReduce最适合的场景
-
一次性批处理:
- ETL数据处理
- 大规模日志分析
- 数据仓库构建
-
高容错需求:
- 关键数据处理
- 长时间运行作业
- 对失败容忍度低的场景


