什么是UE8M0 FP8?
什么是UE8M0 FP8?什么是FP8? |下一代国产AI芯片的关键突破
——从算力架构到数据格式的弯道超车
前言
过去十年,AI 芯片的竞争集中在算力规模与制程工艺。但随着摩尔定律趋缓,性能提升不再只是“堆晶体管”的游戏。数据格式的创新,成为提升能效比和带宽利用率的新战场。
近期,国产芯片厂商与产业生态正在积极推动 UE8M0 FP8 标准落地。这种全新的浮点数表示方法,被视为下一代 AI 芯片的关键支点,有望助力国产算力实现弯道超车。

文章目录
- 什么是UE8M0 FP8?什么是FP8? |下一代国产AI芯片的关键突破
-
- 前言
- AI芯片发展历程
-
- 1. 通用计算时代:CPU 为主(1980s-2000s)
- 2. GPU并行计算崛起(2006-2015)
- 3. AI专用芯片(2016-2020)
- 4. FP8 时代的开启(2021-至今)
- 什么是 FP8?
- MXFP8 与块缩放 (Block Scaling)
- UE8M0:为缩放因子而生的特殊格式
-
- 硬件层面的优势
- 为什么对国产芯片至关重要?
-
- 瓶颈:
- 突破口:
- 未来发展趋势
- AI 芯片发展历程与阶段路线图( 思维导图)
- 数据格式对比表与选型决策(含思维导图)
-
-
- 2.1 数据格式对比表
- 2.2 选型决策思维导图
- 总结
-
AI芯片发展历程
要理解 UE8M0 FP8 的意义,必须放到整个芯片技术演进的背景下来看。
1. 通用计算时代:CPU 为主(1980s-2000s)
早期的机器学习主要依赖 CPU 执行浮点运算,编程方便,但并行度有限,算力增长跟不上数据爆炸。
2. GPU并行计算崛起(2006-2015)
2006 年,NVIDIA 推出 CUDA,将 GPU 从图形渲染扩展到通用计算。GPU 的上千个流处理器,可以并行加速深度学习矩阵运算,成为 AI 爆发的基石。
数据格式演变:
- FP32 是主力(高精度,但功耗大)
- FP16 开始应用(节省带宽,精度仍可接受)
3. AI专用芯片(2016-2020)
谷歌 TPU、寒武纪 MLU、华为 Ascend、Graphcore IPU 等相继出现,AI 芯片进入专用化时代。
数据格式演变:
- FP16/BF16 成为训练主力
- INT8 广泛应用于推理(降低功耗)
4. FP8 时代的开启(2021-至今)
深度学习模型参数从百万级跃升到千亿级,带宽与存储成为最大瓶颈。
- NVIDIA Hopper 架构首次引入 FP8 Tensor Core(支持 E4M3/E5M2)
- OCP 社区在 2023 年制定 MXFP8 规范
- 国产芯片厂商积极跟进,寻求带宽弯道超车
什么是 FP8?
FP8(8-bit floating point)是一种8 位浮点数格式,相较传统 FP16、FP32,显著缩小了存储和计算所需的比特数。
- 存储开销更低:比 FP16 缩小一半,比 FP32 缩小 4 倍
- 带宽压力减轻:在 HBM/LPPDDR 受限的情况下更有优势
- 训练与推理兼容:FP8 已逐步用于深度学习的前向推理和反向传播
目前主流 FP8 格式包括:
- E4M3(4 位指数 + 3 位尾数)
- E5M2(5 位指数 + 2 位尾数)
它们主要用于表示张量数据本体。
MXFP8 与块缩放 (Block Scaling)
2023 年,OCP(开放计算项目)提出 MXFP8 微缩放规范。
核心思想:
- 将张量切分为固定大小的“块”
- 每个块共享一个缩放因子(2 的幂次)
- 块内元素以 FP8 表示
好处:
- 动态范围大幅扩展
- 溢出/下溢几率降低
- 误差更可控
也就是说,FP8 不再孤立存在,而是搭配块缩放使用,才能兼顾精度与范围。
UE8M0:为缩放因子而生的特殊格式
在 MXFP8 中,缩放因子本身如何存储非常关键。UE8M0 正是为此设计的格式。
- U (Unsigned):无符号位
- E8 (8 位指数):全比特用于指数表示
- M0 (0 位尾数):不含尾数位
换句话说,UE8M0 仅用指数来表示缩放因子,值域覆盖 2⁻¹²⁷ 到 2¹²⁸,动态范围极大。
硬件层面的优势
-
极致高效
无需浮点乘法,直接通过移位操作即可完成数值缩放,缩短关键路径。 -
动态范围广
超越 E4M3/E5M2,避免单尺度 FP8 易溢出或被压零的缺陷。 -
误差显著降低
使用 UE8M0 缩放后,误差分布趋于平滑,整体信息损失减少。 -
带宽极度节省
- 每 32 个 FP8 数值仅需 1 个 8bit 缩放因子
- 相比传统 32bit 缩放因子,节省 75% 存储流量
为什么对国产芯片至关重要?
目前多数国产 AI 芯片仍以 FP16/BF16 + INT8 为主,FP8 支持仍在起步。
瓶颈:
- 国产 HBM/LPPDDR 带宽仍落后于国际顶级水平
- 制程工艺与能效比存在差距
- 算力堆叠的边际效应递减
突破口:
- UE8M0 节省带宽,缓解存储墙问题
- 数据格式创新,弥补制程短板
- 更快产业化:无需等待最先进制程,也能获得算力效率优势
例如:
- 摩尔线程 MUSA 3.1 GPU
- 芯原 VIP9000 NPU
预计 2025 年下半年量产,并联合 DeepSeek、华为等企业验证 UE8M0 格式。
未来发展趋势
AI 芯片演进,正在经历 制程 → 架构 → 数据格式 → 系统协同 的转变:
-
制程驱动(过去)
更小纳米工艺带来更强算力,但成本高、技术封锁严重。 -
架构驱动(现在)
GPU、NPU、IPU、DPU 各自演进,专用化方向明显。 -
数据格式驱动(正在发生)
- FP8 → UE8M0
- Block Scaling、低比特化(INT4/INT2)
- 精度与带宽的平衡成为核心竞争力
-
系统协同(未来)
- 芯片 + 存储 + 网络 + 软件框架一体化优化
- 异构算力统一调度(GPU+NPU+ASIC)
- AI 芯片不再只是“算力提供者”,而是“系统优化者”
AI 芯片发展历程与阶段路线图( 思维导图)
从 CPU → GPU → 专用 AI 芯片 → FP8/MXFP8 → UE8M0 的技术演进脉络,一图总览。
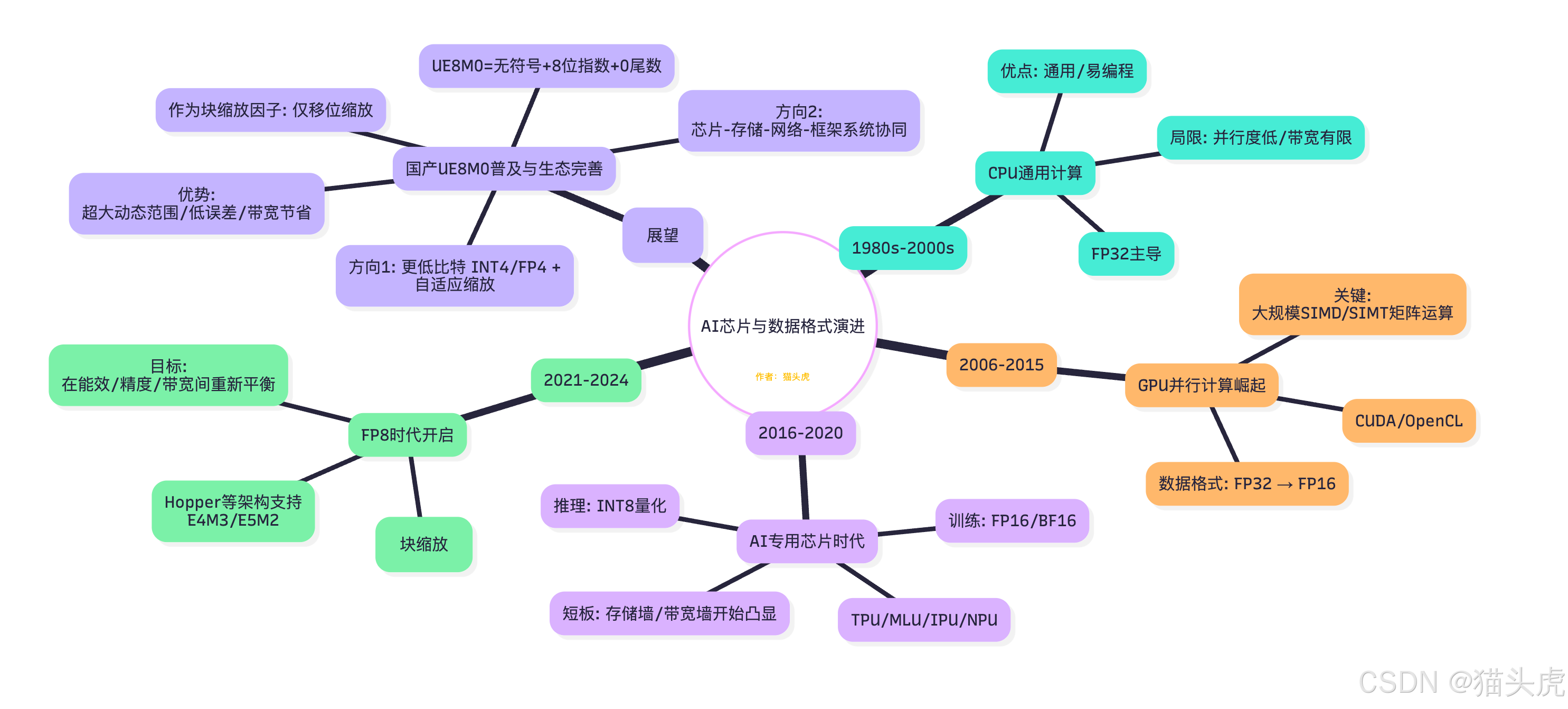
要点小结
- 驱动力迁移:制程 → 架构 → 数据格式 → 系统协同。
- FP8 + 块缩放 提供新的能效/带宽平衡点;UE8M0 专注缩放因子,极简硬件路径与更大动态范围。
- 未来:更低比特(INT4/FP4)、感知分布的自适应缩放、与编译器/通信协议协同优化。
数据格式对比表与选型决策(含思维导图)
一表明晰 FP32/FP16/BF16/FP8(E4M3/E5M2)/UE8M0 的位宽结构、动态范围与典型应用,并给出实践选型思路。
2.1 数据格式对比表
* 注:E4M3/E5M2 的精确范围依规范实现细节而异;UE8M0 为缩放因子表示,与块大小/策略共同决定整体数值行为。
2.2 选型决策思维导图
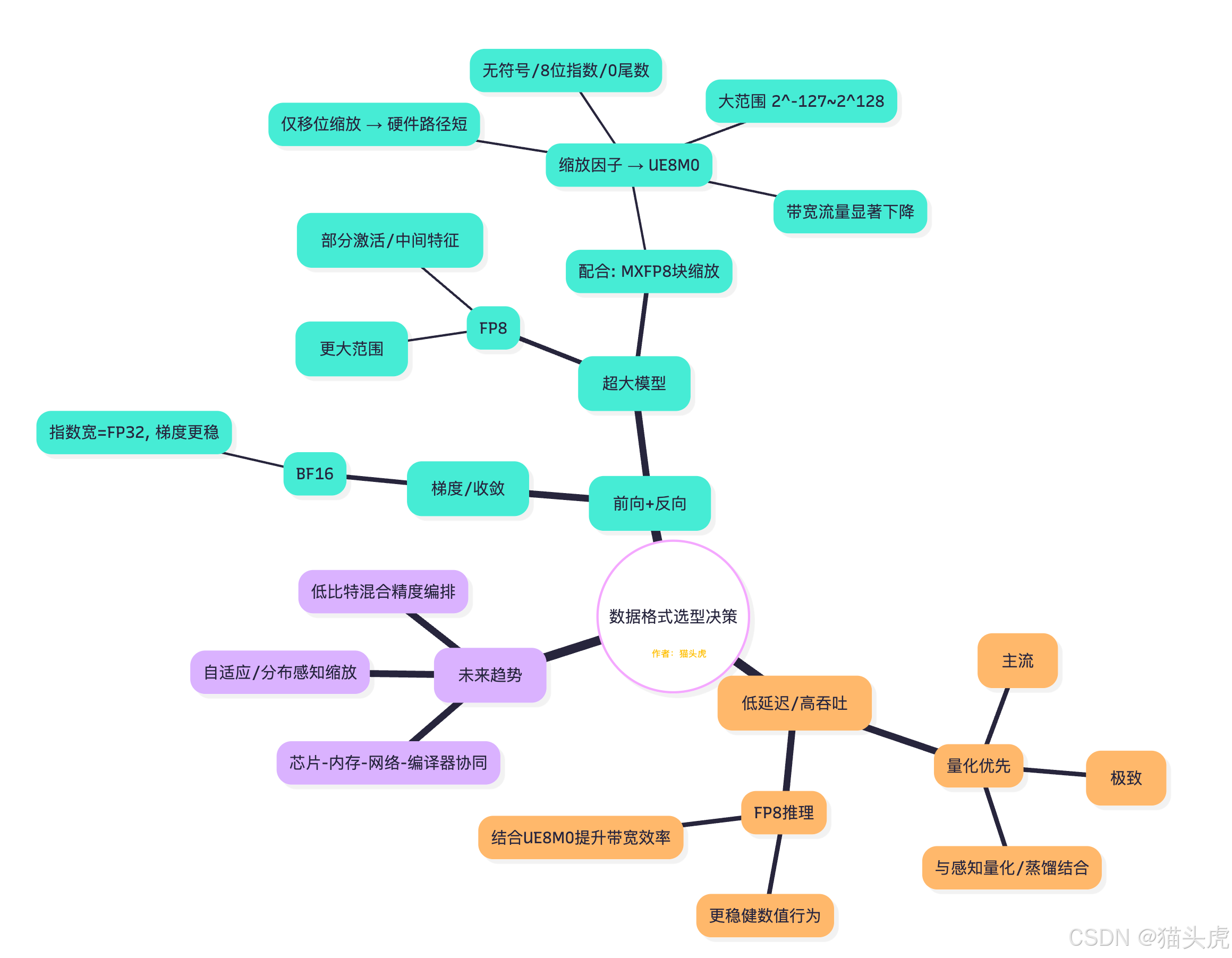
实战建议
- 训练:优先 BF16 做基线;在带宽/显存吃紧时,引入 FP8(E5M2/E4M3)+MXFP8,并以 UE8M0 存储块缩放因子。
- 推理:首选 INT8,极致能效尝试 INT4;若对鲁棒性与迁移精度更敏感,可用 FP8 + UE8M0。
- 系统层:把“数据格式”当作一等公民,与并行切分、通信压缩、编译器重写共同设计。
总结
- UE8M0 是 MXFP8 块缩放格式的缩放因子方案
- 特点:无符号、全指数位、无尾数 → 硬件高效、动态范围大、误差低、带宽节省明显
- 意义:为带宽受限的国产芯片提供突破口,加速 FP8 产业化落地
- 未来:国产芯片将在 2025 年普遍支持 UE8M0 FP8,助力算力生态升级
从制程到数据格式的转变,标志着算力竞争进入新阶段。UE8M0 FP8 不仅是一种数据表示,更是国产 AI 芯片弯道超车的技术支点。
👉 如果你觉得这篇解析有帮助,记得 点赞⭐ 收藏📌 转发分享 给同样关注 AI 硬件的朋友!
#AI芯片 #FP8 #国产算力 #硬件加速 #技术趋势


