LLM实践(二)——基于llama-factory的模型微调、加载和推理_llamafactory加载模型
目录
- SFT的lora微调(以Qwen2.5-7B-Instruct [ DeepSeek-R1-Distill-Qwen-7B ]为基模型)
-
- 1、环境部署
- 2、准备数据与配置
- 3、创建微调配置文件:yaml配置文件
- 4、Lora微调:基于lora微调的yaml配置文件启动lora微调
- 5、启动模型
-
- (1)没有合并模型和微调后的适配器时:基于llama-factory自带的功能
- (2)合并模型和微调后的适配器后,可直接可使用vllm或者脚本启动
- 6、模型调用、推理
-
- (1)使用curl命令(以微调后的Qwen2.5-7B-Instruct模型为例)
- (2)也可以使用python脚本将curl方式代码化(以微调后的DeepSeek-R1-Distill-Qwen-7B模型为例)
- 7、使用transformers脚本加载并进行推理
-
- (1)基于transformers直接加载模型,并直接推理测试
- (2)基于transformer加载模型并使用fastapi创建接口,远程调用推理
- (3)遇到的坑:
SFT的lora微调(以Qwen2.5-7B-Instruct [ DeepSeek-R1-Distill-Qwen-7B ]为基模型)
1、环境部署
- 还是要安装一个单独的conda环境(python=3.10),激活环境;
- 下载llama-factory的GitHub项目:https://github.com/hiyouga/LLaMA-Factory
- 适合当前过程的llama-factory版本:https://download.csdn.net/download/lucky_chaichai/90535396
- 安装依赖:pip install -r requirements.txt;
- 安装llama-factory的工具:pip install -e “.[torch,metrics]”
2、准备数据与配置
- 支持三种数据格式,即alpaca、sharegpt和OpenAI 格式:
- alpaca:基于 Meta 开源的LLaMA 模型构建的一种微调数据集格式,特别用于instruction-tuning。其数据格式的特点是提供了一个明确的任务描述(instruction)、输入(input)和输出(output)三部分。

- sharegpt:来源于ChatGPT与用户对话记录的数据集,主要用于对话系统的训练。更侧重于多轮对话数据的收集和组织,模拟用户与 AI 之间的交互。(这种格式适用性更好,单论对话的时候也可以作为text格式的微调数据)

- OpenAI格式,如:
- alpaca:基于 Meta 开源的LLaMA 模型构建的一种微调数据集格式,特别用于instruction-tuning。其数据格式的特点是提供了一个明确的任务描述(instruction)、输入(input)和输出(output)三部分。
[ { \"messages\": [ { \"role\": \"system\", \"content\": \"系统提示词(选填)\" }, { \"role\": \"user\", \"content\": \"人类指令\" }, { \"role\": \"assistant\", \"content\": \"模型回答\" } ] }]对应的data_info.json配置如下:
{ ……,\"数据集名称\": { \"file_name\": \"data.json\", \"formatting\": \"sharegpt\", \"columns\": { \"messages\": \"messages\" }, \"tags\": { \"role_tag\": \"role\", \"content_tag\": \"content\", \"user_tag\": \"user\", \"assistant_tag\": \"assistant\", \"system_tag\": \"system\" }}- 需要根据LLaMA-Factory/data/中提供的样例准备数据,为json格式,我准备的是alpaca格式,如下(文件名:yanxue_langtext_sftdata.json):
[ { \"instruction\": \"场景:NL2SQL任务中对输入文本进行实体抽取并按数据库表字段生成SQL查询标签,要求按json格式生成。\\n数据库表各类字段信息如下:……\\n现在我将给你一个新的输入,请严格按照输出示例格式生成回复,不要解释说明,不要使用Markdown。\", \"input\": \"查找土壤肥力提升的相关辑刊文献\", \"output\": \"{ \\\"query\\\": [{ \\\"tag\\\": \\\"主题\\\", \\\"kw\\\": \\\"土壤肥力提升\\\", \\\"opt\\\": \\\"\\\", \\\"rel\\\": \\\"\\\"}], \\\"filter\\\": [], \\\"rank\\\": {}, \\\"table\\\": [\\\"学术辑刊\\\"]}\" }, ……] - 要根据数据的具体形式,在LLaMA-Factory/data/data_info.json中配置数据信息,如下:
{ ……,\"yanxue_zs\": { # 数据集名称,在后续进行微调时,在微调的yaml配置文件中需要使用,即dataset的值 \"file_name\": \"yanxue_langtext_sftdata.json\", # 上面准备的数据文件名 \"columns\": { # 我上面准备的数据,每条只有两列数据instruction、output \"prompt\": \"instruction\", \"query\": \"input\", # 没有的话可以省略 \"response\": \"output\" } }}【另外:数据集的准备和data_info.json的配置在LLaMA-Factory/data/README_zh.md中有详细说明】
3、创建微调配置文件:yaml配置文件
- 在LLaMA-Factory/examples/train_lora/文件夹中创建ds_qwen7b_lora_sft.yaml文件:
- 即复制llama3_lora_sft.yaml文件到ds_qwen7b_lora_sft.yaml中,主要更改下述几个参数(其他参数可以不动):
- report_to:可以选择“wandb”,会在wandb平台上显示并记录loss、梯度等的变化情况:
- 首先在官网注册账号,官网地址:https://wandb.ai/site ;
- 然后会在“resource&help”中得到自己的API-KEY;
- 安装wandb模块:
pip install wandb; - 在对应python环境的命令行中登录wandb:
wandb login,然后输入自己API-KEY就登录成功了,执行训练程序时会返回对应的wandb记录网址,在浏览器中打开即可。
- 我的机器是4090(24G内存),可以跑起来
cutoff_len: 4096的窗口(per_device_train_batch_size: 1),再大就超内存了;
### modelmodel_name_or_path: /home/cqf/models/DeepSeek-R1-Distill-Qwen-7B # 基模型所在地址### methodstage: sftfinetuning_type: loralora_rank: 8lora_target: all # 参与Lora微调部分,比如可以是attention的q_proj,v_projpref_beta: 0.1pref_loss: sigmoid # choices: [sigmoid (dpo), orpo, simpo]### datasetdataset: yanxue_zs # 与data_info.json中定义的“数据集名称”一致template: deepseek3 # 参考GitHub该项目主页的 模型与template对应表cutoff_len: 4096 # 即微调后模型的最大上下文窗口。需要考虑机器的内存### outputoutput_dir: /home/cqf/models/lora_model/deepseek_distill_qwen7b_lora # 微调后的模型存储位置logging_steps: 10save_steps: 500report_to: wandb # choices: [none, wandb, tensorboard, swanlab, mlflow]### trainper_device_train_batch_size: 1gradient_accumulation_steps: 8learning_rate: 5.0e-6num_train_epochs: 3.0### eval# eval_dataset: dpo_en_demo# val_size: 0.14、Lora微调:基于lora微调的yaml配置文件启动lora微调
- 启动lora微调的命令如下:
- 要注意lora微调的yaml配置文件路径与执行该命令时所在的路径之间的对应关系(最好是在llama-factory项目第一层路径下执行,如下);
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train examples/train_lora/ds_qwen7b_lora_sft.yaml -
微调时,wandb上的训练过程曲线(训练曲线、系统状态):
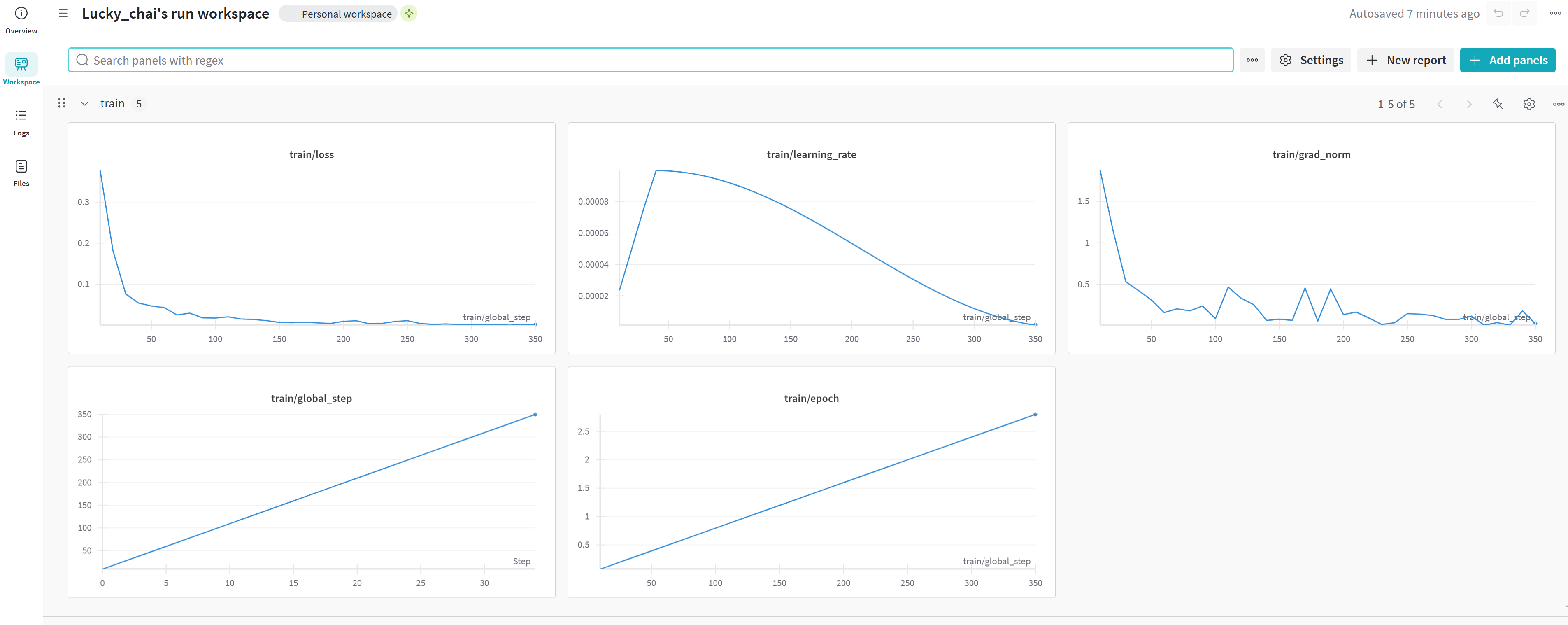
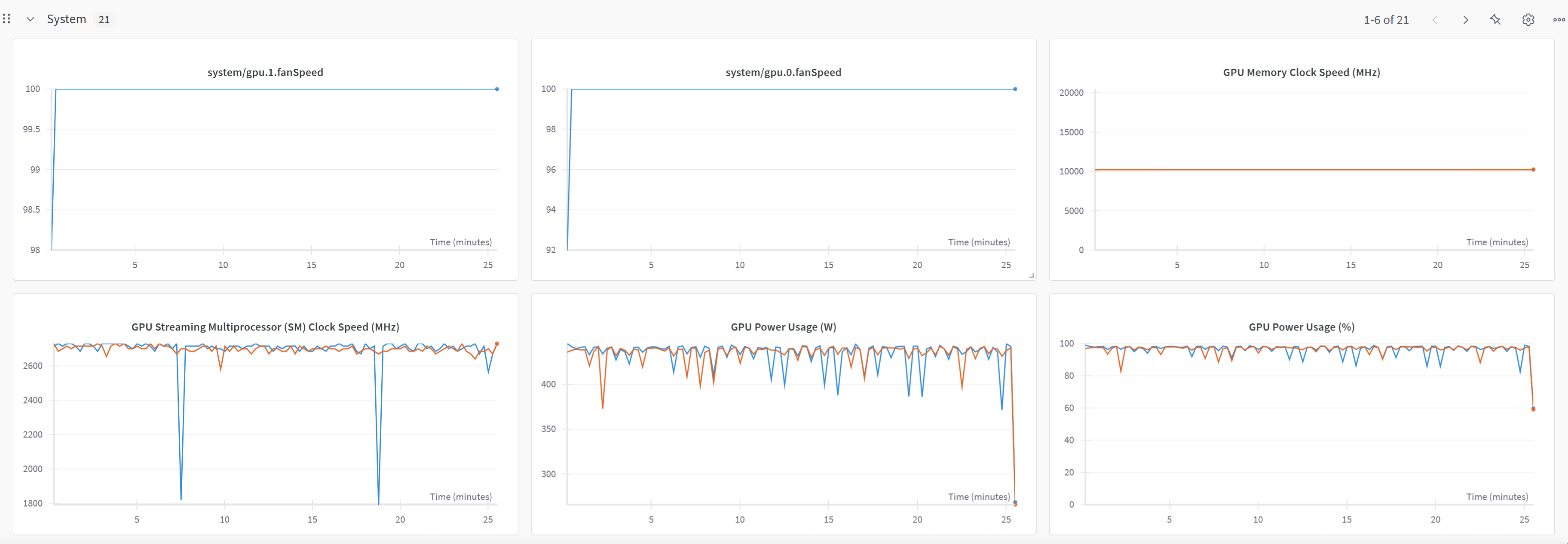
-
显卡情况:

-
微调过程历时等信息:
- 1000条数据,Qwen2.5-7B-Instruct模型,max_len为4096,epoch为3,训练用时25+分钟;

- 1000条数据,Qwen2.5-7B-Instruct模型,max_len为4096,epoch为3,训练用时25+分钟;
-
微调


