【大模型】一图看懂3D因果卷积!_深度学习卷积神经网络进阶
目录
写在前面
一、什么是“因果”
二、1D卷积与1D因果卷积
1.标准1D卷积
2.1D因果卷积
三、2D卷积与2D因果卷积
1.标准2D卷积
2.2D因果卷积
四、3D卷积与3D因果卷积
1.标准3D卷积
2.3D因果卷积的概念
五、代码实现
六、总结
写在前面
在深度学习领域,卷积神经网络(CNN)已成为处理序列、图像和视频数据的核心架构。随着应用场景的不断扩展,因果卷积(Causal Convolution)的重要性日益凸显,在时间序列预测、语音合成以及视频生成等地方展现出关键作用。
特别是在当前大模型视频生成的研究中,3D因果卷积凭借其独特的时序建模能力,成为确保视频连贯性和时空一致性的关键技术。
本文将系统性地介绍从1D到3D的因果卷积原理,通过直观的动图演示帮助读者理解其工作机制,并重点探讨3D因果卷积在大规模视频生成中的独特价值和应用前景。

下面的动图怎么画的?点这里:【大模型】一图看懂3D因果卷积!
一、什么是“因果”
因果(Causal)指的是输出只依赖于当前及之前时刻/位置的输入,严格禁止使用未来信息,确保时间或空间上的先后顺序不被破坏。
简单地说就是\"不能偷看未来\",就像你不能用明天的天气预报来预测今天的温度,3D因果卷积在处理视频或序列数据时,也严格遵守这个规矩:每一帧的预测只能基于之前看到的画面,绝不作弊看后面的内容。
因果卷积其实很好理解,以下是天气预测示例的图示说明,训练数据是过去7天气象数据,比如我们要预测第五天的温度,我们使用一个窗口为3的卷积进行预测。
在真实天气预报场景中,我们不可能获取明天的真实气象数据来预测今天。标准卷积会导致模型在训练时\"偷看\"未来数据,造成虚假的高准确率。
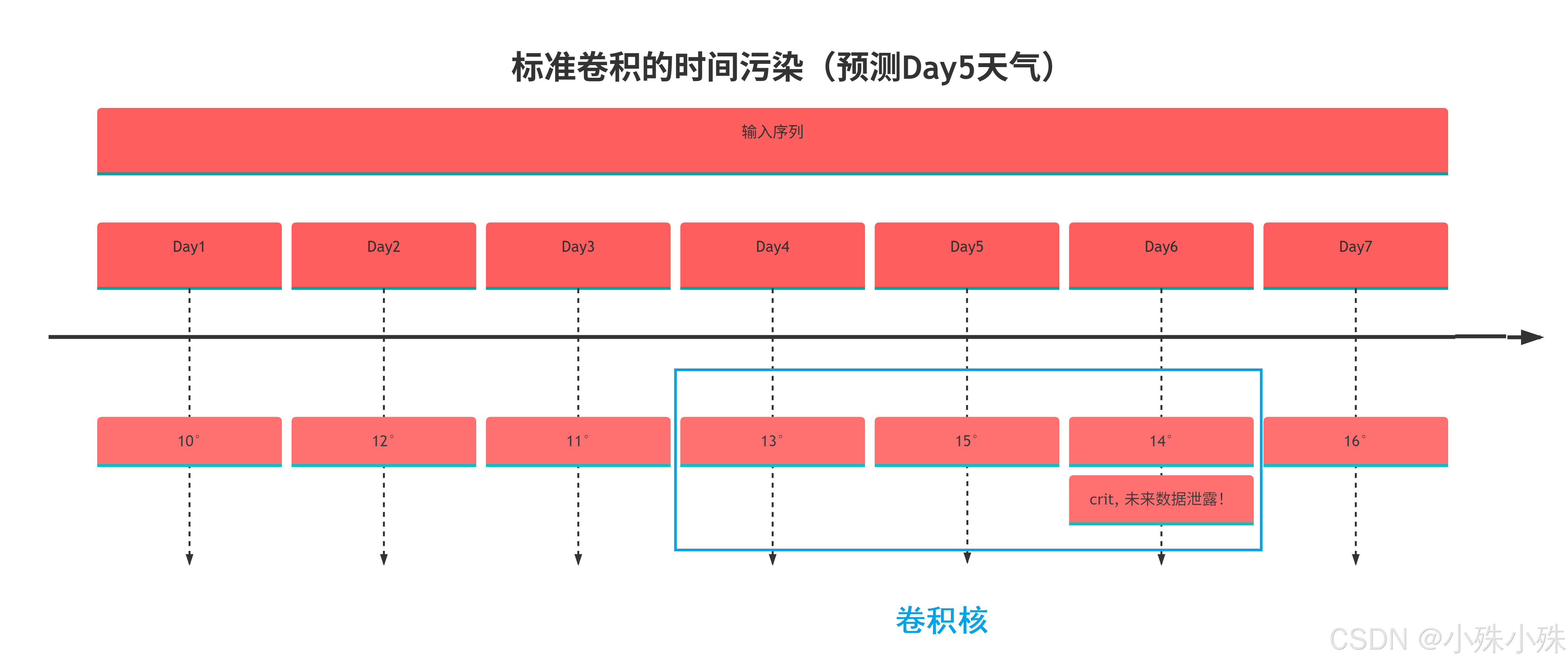
在训练的时候上面的标准卷积在预测Day5时,也使用了Day6的数据造成了数据污染,所以需要使用因果卷积就来避免“偷看未来”的发生。
因果卷积的具体实现其实也很简单,只要mask掉卷积核中时间维度的“未来”部分就可以了。
预测温度的例子展示的其实就是1D因果卷积,下面我们再把卷积慢慢扩展到3D就是3D因果卷积啦!
二、1D卷积与1D因果卷积
1.标准1D卷积
1D卷积主要应用于序列数据处理,如时间序列分析、自然语言处理等。其工作原理是通过一个滑动窗口(卷积核)在输入序列上移动,计算窗口内元素与卷积核的加权和。点击看动图:
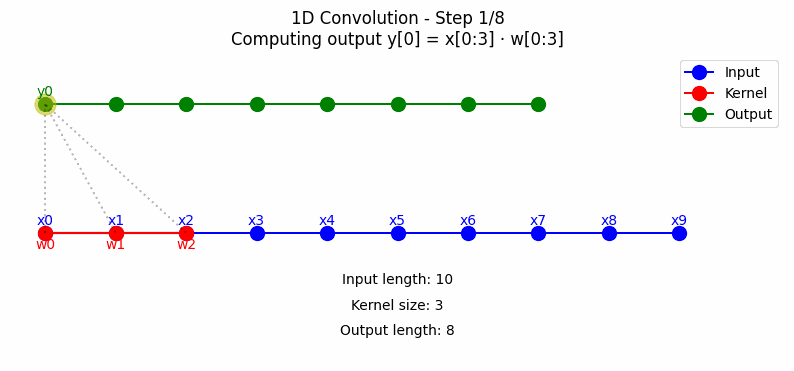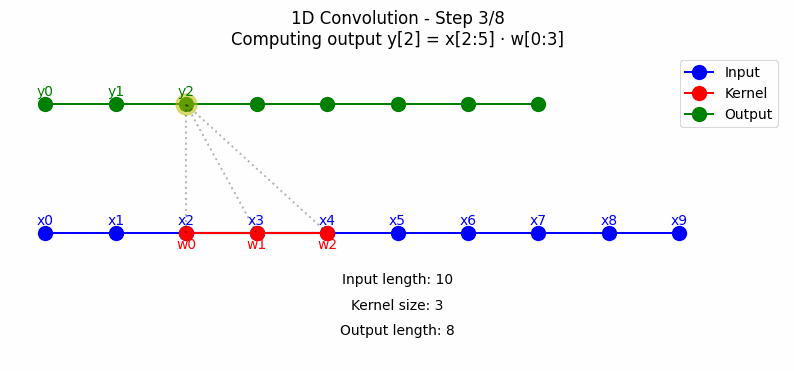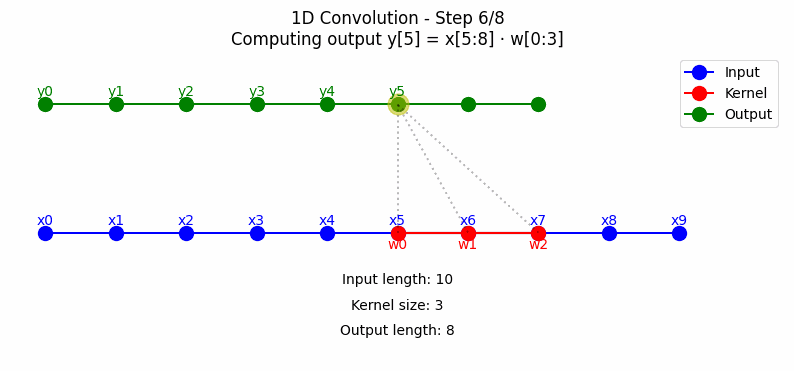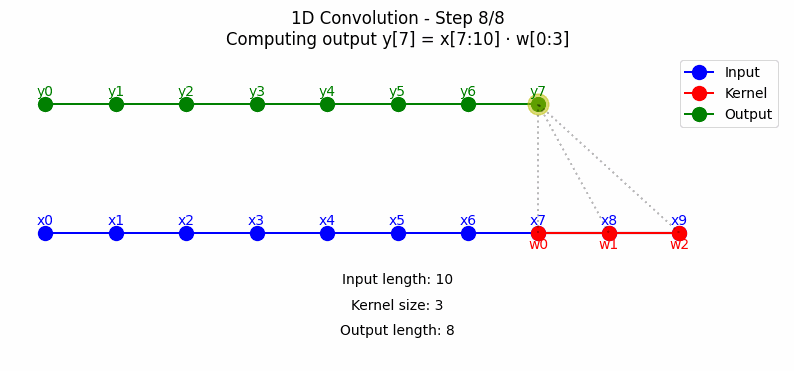
从上图中可以看到,标准1D卷积在每个时间步都考虑当前时刻及其前后相邻的信息进行计算,这可能导致信息\"泄漏\"——即使用未来的信息预测当前输出。
2.1D因果卷积
因果卷积的核心思想是确保模型在时间步t的输出仅依赖于时间步t及之前的输入,不依赖于未来信息。这一特性对于实时预测任务至关重要。点击看动图:

从上图中可以看到因果卷积通过不对称的填充方式(通常只在序列左侧填充)和特定的卷积核设计,确保输出只依赖于当前及历史输入。这种结构在WaveNet等自回归模型中得到广泛应用,能够有效建模长期时间依赖关系。
三、2D卷积与2D因果卷积
1.标准2D卷积
2D卷积是处理图像数据的标准方法,通过在两个空间维度(高度和宽度)上滑动卷积核来提取特征。点击看动图:
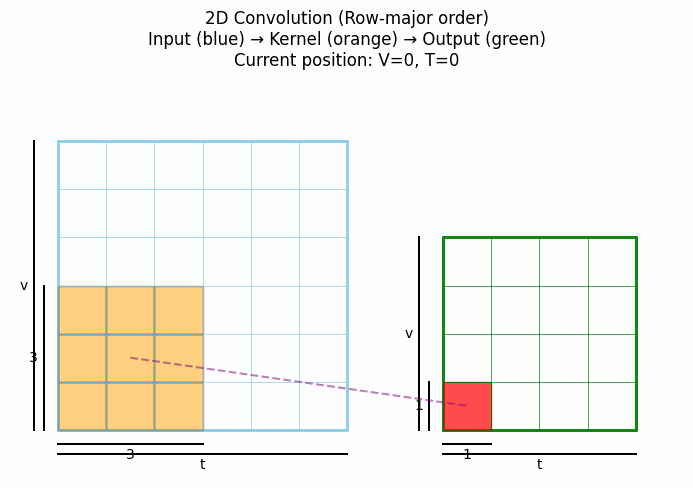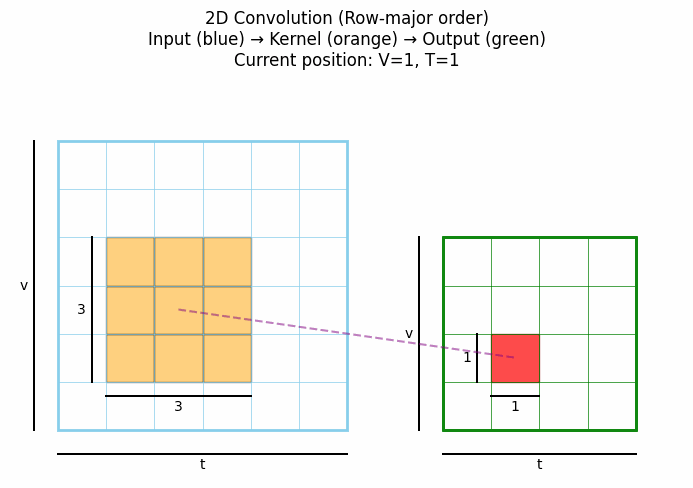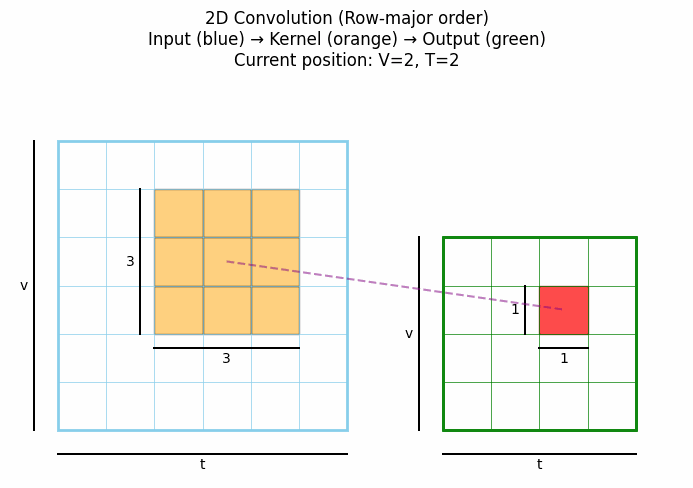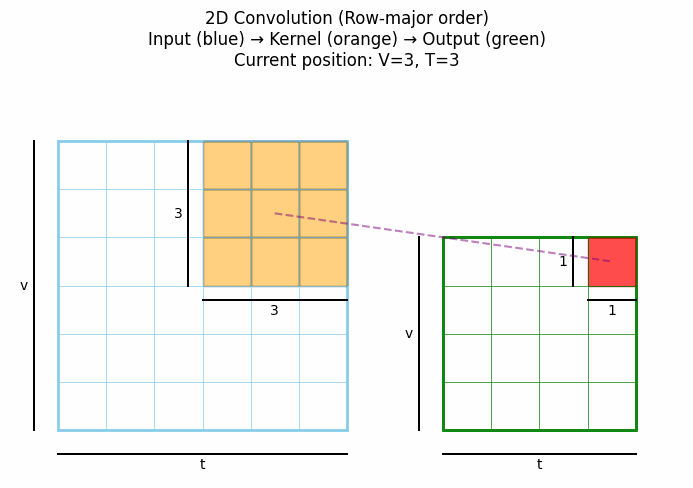
从上可见,标准2D卷积在每个位置都考虑中心像素周围所有方向上的邻域信息,没有特定的方向性约束。
2.2D因果卷积
2D因果卷积将因果性概念扩展到二维空间,通常用于图像生成等任务,确保每个像素的生成只依赖于之前已生成的像素(按照某种预定义的顺序,如光栅扫描顺序)。下图中灰色表示卷积核被mask掉的部分。点击看动图:
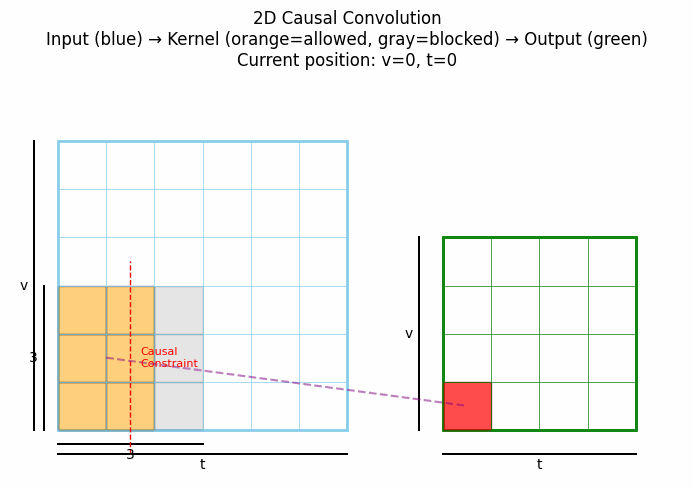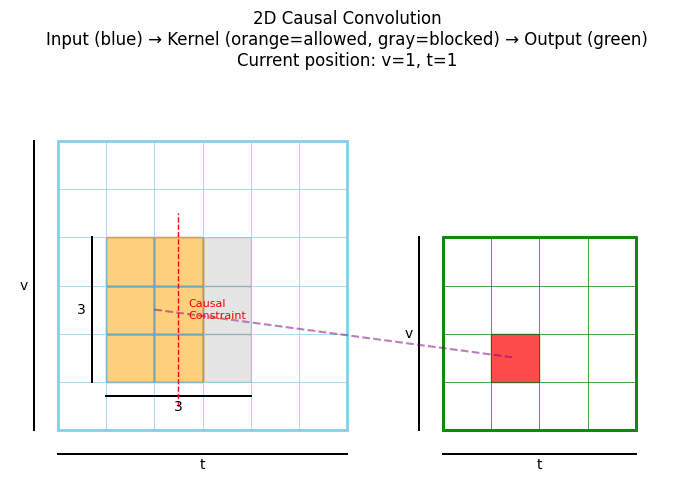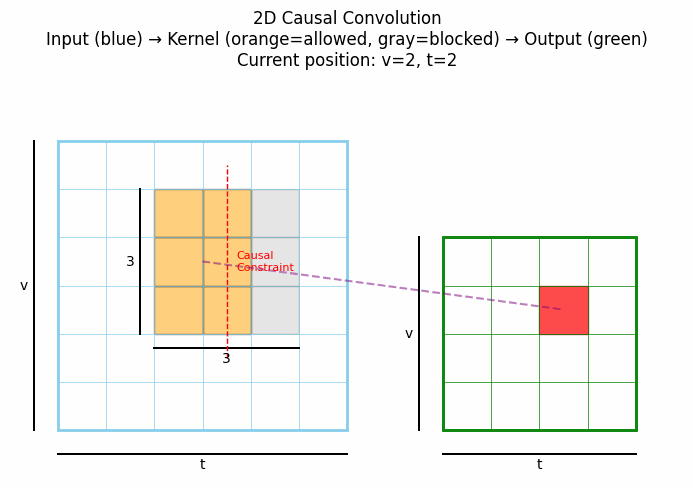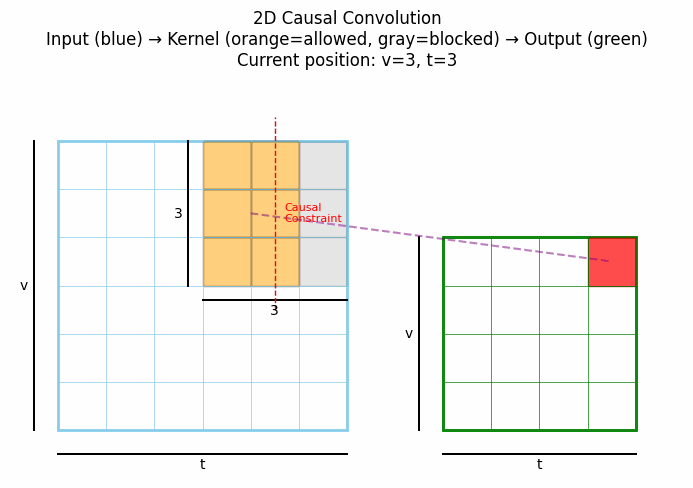
上图展示了2D因果卷积的典型工作方式:在生成当前像素(红色)时,只考虑已经生成的像素,而不考虑尚未生成的像素。这种结构在PixelCNN等自回归图像生成模型中发挥关键作用。
四、3D卷积与3D因果卷积
1.标准3D卷积
3D卷积在视频处理、医学体积数据分析等地方有重要应用,它在2D卷积基础上增加了时间维度(或深度维度)的卷积操作。点击看动图:
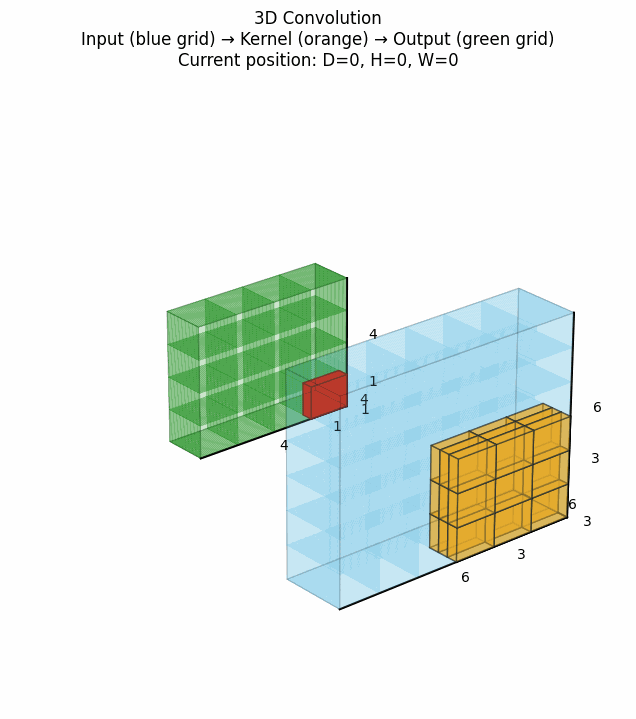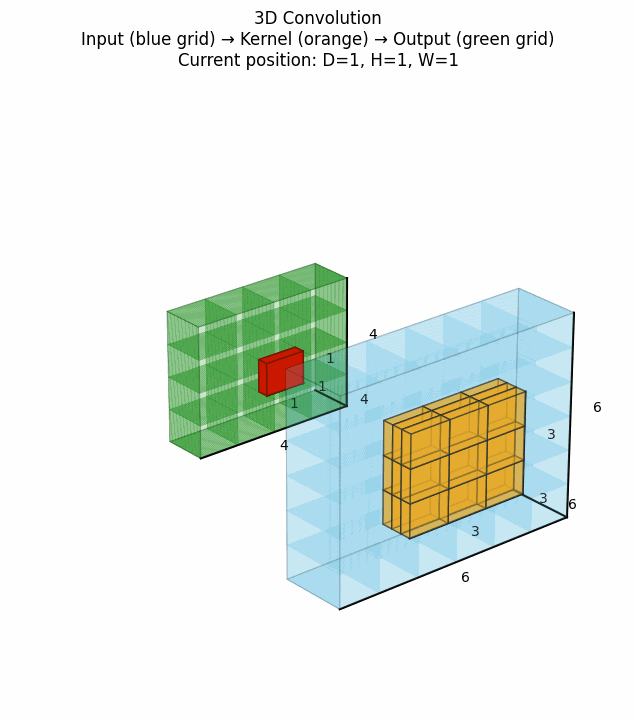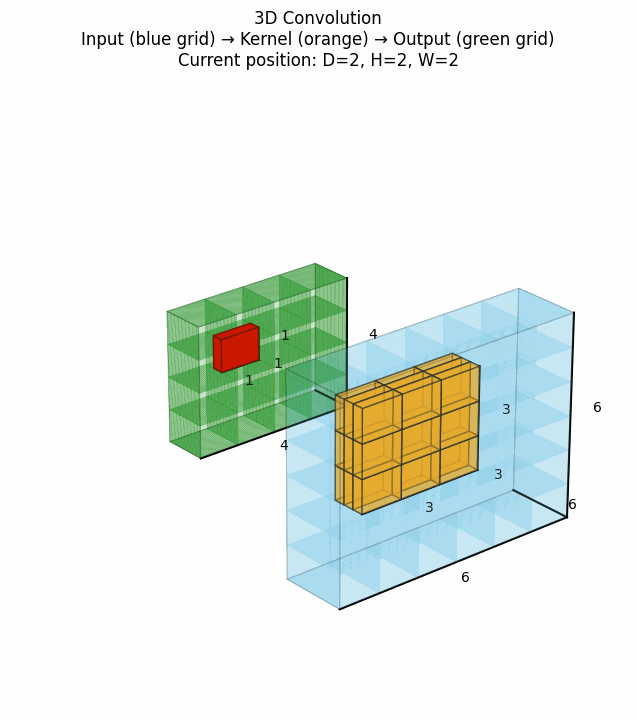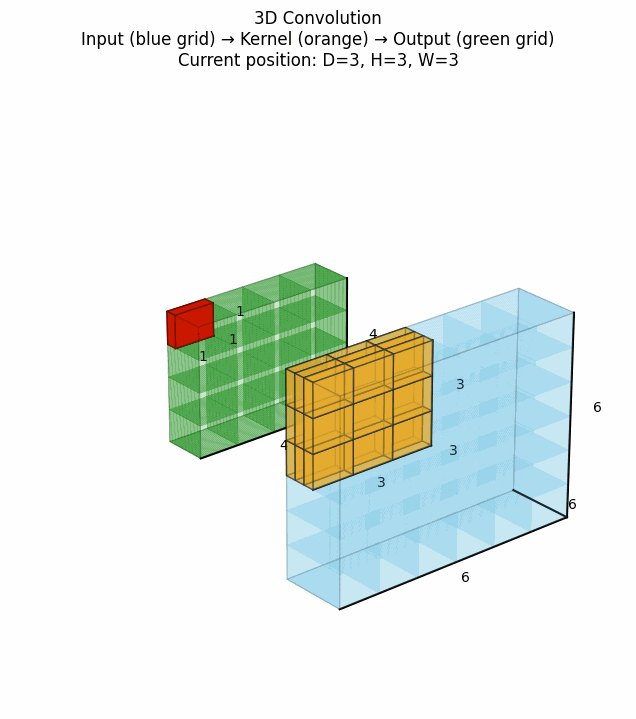
上图展示了3D卷积如何在三个维度上滑动并计算特征。对于视频数据而言,这意味着同时考虑空间和时间邻域的信息。
2.3D因果卷积的概念
3D因果卷积将因果性约束扩展到三维空间,特别适用于视频预测、动态系统建模等任务。它确保在时间步t的输出仅依赖于当前及之前时间步的信息,同时在空间维度上也可以施加类似的因果约束。下图中灰色表示卷积核被mask掉的部分。点击看动图:
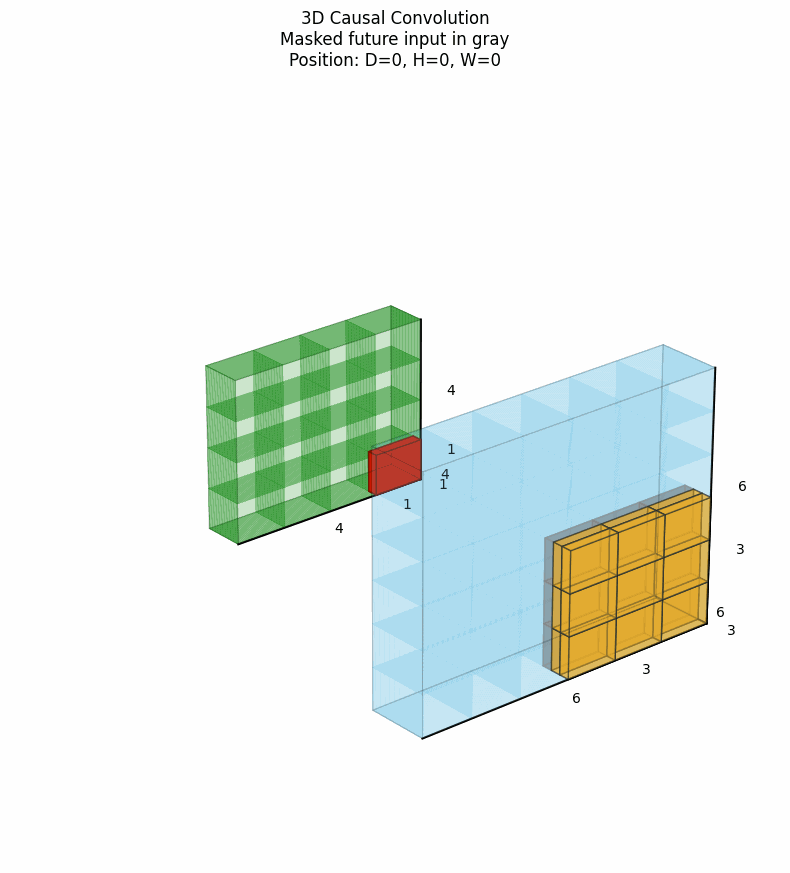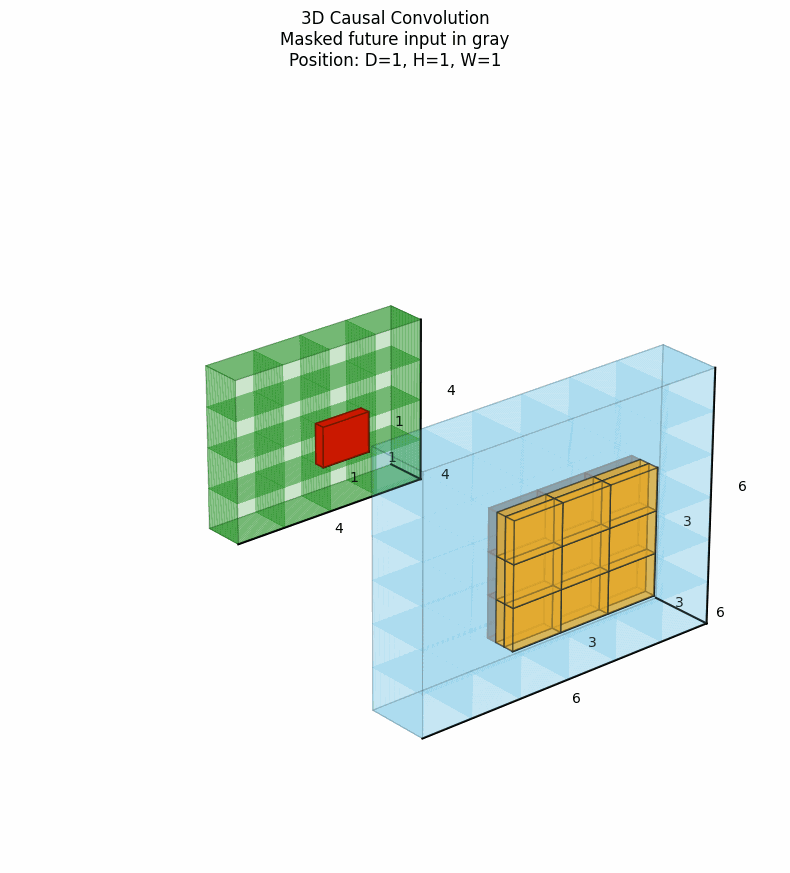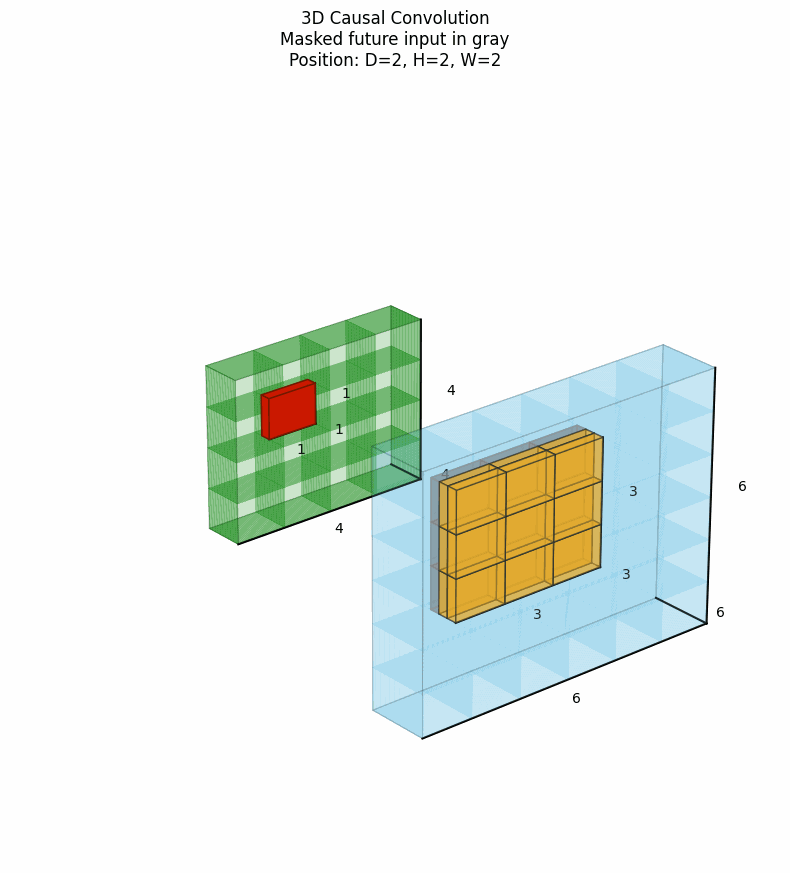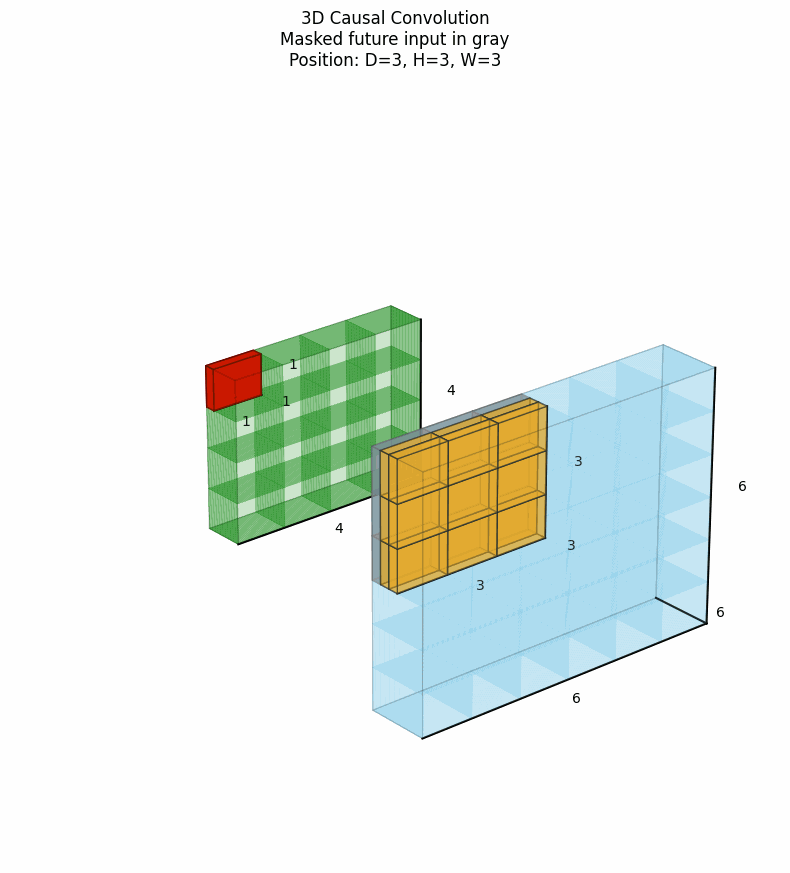
上图展示了时间因果性,在时间维度上,只考虑当前帧及之前的帧,每个像素的生成只依赖于已经处理过的像素区域。
在实际的应用中,比如在视频生成中,如果使用非因果卷积: 可能出现\"雨还没下,地面就先湿了\"的逻辑错误 人物动作可能违反时间顺序(如先看到拳头击中,再看到出拳动作)
五、代码实现
import torchimport torch.nn as nnimport torch.nn.functional as F# -------- 1. 普通 1D 卷积 --------class Conv1D(nn.Module): def __init__(self, in_channels, out_channels, kernel_size): super().__init__() padding = kernel_size // 2 self.conv = nn.Conv1d(in_channels, out_channels, kernel_size, padding=padding) def forward(self, x): return self.conv(x)# -------- 2. 因果 1D 卷积 (权重 Mask 实现) --------class CausalConv1D(nn.Conv1d): def __init__(self, in_channels, out_channels, kernel_size, bias=True): super().__init__(in_channels, out_channels, kernel_size, bias=bias) self.register_buffer(\"mask\", self.weight.data.clone()) self.mask.fill_(1) center = kernel_size // 2 self.mask[:, :, center + 1:] = 0 def forward(self, x): self.weight.data *= self.mask return super().forward(x)# -------- 3. 普通 2D 卷积 --------class Conv2D(nn.Module): def __init__(self, in_channels, out_channels, kernel_size): super().__init__() padding = kernel_size // 2 if isinstance(kernel_size, int) else tuple(k // 2 for k in kernel_size) self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding) def forward(self, x): return self.conv(x)# -------- 4. 因果 2D 卷积 (权重 Mask 实现) --------class CausalConv2D(nn.Conv2d): def __init__(self, in_channels, out_channels, kernel_size, bias=True): super().__init__(in_channels, out_channels, kernel_size, bias=bias) kh, kw = kernel_size if isinstance(kernel_size, tuple) else (kernel_size, kernel_size) self.register_buffer(\"mask\", self.weight.data.clone()) self.mask.fill_(1) cy, cx = kh // 2, kw // 2 self.mask[:, :, cy + 1:, :] = 0 self.mask[:, :, cy, cx + 1:] = 0 def forward(self, x): self.weight.data *= self.mask return super().forward(x)# -------- 5. 普通 3D 卷积 --------class Conv3D(nn.Module): def __init__(self, in_channels, out_channels, kernel_size): super().__init__() padding = kernel_size // 2 if isinstance(kernel_size, int) else tuple(k // 2 for k in kernel_size) self.conv = nn.Conv3d(in_channels, out_channels, kernel_size, padding=padding) def forward(self, x): return self.conv(x)# -------- 6. 因果 3D 卷积 (权重 Mask 实现) --------class CausalConv3D(nn.Conv3d): def __init__(self, in_channels, out_channels, kernel_size, bias=True): super().__init__(in_channels, out_channels, kernel_size, bias=bias) kd, kh, kw = kernel_size if isinstance(kernel_size, tuple) else (kernel_size, kernel_size, kernel_size) self.register_buffer(\"mask\", self.weight.data.clone()) self.mask.fill_(1) cd, cy, cx = kd // 2, kh // 2, kw // 2 self.mask[:, :, cd + 1:, :, :] = 0 self.mask[:, :, cd, cy + 1:, :] = 0 self.mask[:, :, cd, cy, cx + 1:] = 0 def forward(self, x): self.weight.data *= self.mask return super().forward(x)# -------- main 测试函数 --------def main(): print(\"Testing all 6 types of convolution...\\n\") # 1D x1d = torch.randn(2, 3, 10) print(\"Conv1D Output:\", Conv1D(3, 4, 3)(x1d).shape) print(\"CausalConv1D Output:\", CausalConv1D(3, 4, 3)(x1d).shape) # 2D x2d = torch.randn(2, 3, 8, 8) print(\"Conv2D Output:\", Conv2D(3, 4, 3)(x2d).shape) print(\"CausalConv2D Output:\", CausalConv2D(3, 4, 3)(x2d).shape) # 3D x3d = torch.randn(2, 3, 5, 8, 8) print(\"Conv3D Output:\", Conv3D(3, 4, 3)(x3d).shape) print(\"CausalConv3D Output:\", CausalConv3D(3, 4, 3)(x3d).shape)if __name__ == \"__main__\": main()六、总结
最后总结一下因果卷积的特点:
-
防止信息泄漏:因果卷积确保输出仅依赖当前及历史输入,避免“偷看未来”,保持时间或空间顺序的严格性。
-
实现简单:通过掩码(Mask)强制屏蔽未来信息,无需复杂结构调整即可实现因果性。
-
视频生成优势:3D因果卷积在视频生成中保障时空一致性,避免逻辑错误(如动作顺序颠倒)。
-
具备广泛应用潜力:在多模态学习、交互系统、智能生成等前沿领域,因果卷积都展现出独特优势。
-
上面的动图怎么画的?点这里:【大模型】一图看懂3D因果卷积!
好了关于3D因果卷积的内容就介绍到这。
关注不迷路(*^▽^*),暴富入口==》 https://bbs.csdn.net/topics/619691583


