【AI深究】特征工程(Feature Engineering)深度解析:原理、算法与工程实践|核心原理、主流方法、数学表达、未来趋势|归一化与标准化、降维、文本、时间、类别型、AutoFE|未来前沿
大家好,我是爱酱。本篇延续将会系统梳理特征工程(Feature Engineering)的定义、核心流程、主流方法、数学表达、工程实践与未来趋势,结合数学公式,帮助你全面理解这一机器学习与AI落地的“灵魂工程”。
注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!
一、什么是特征工程?
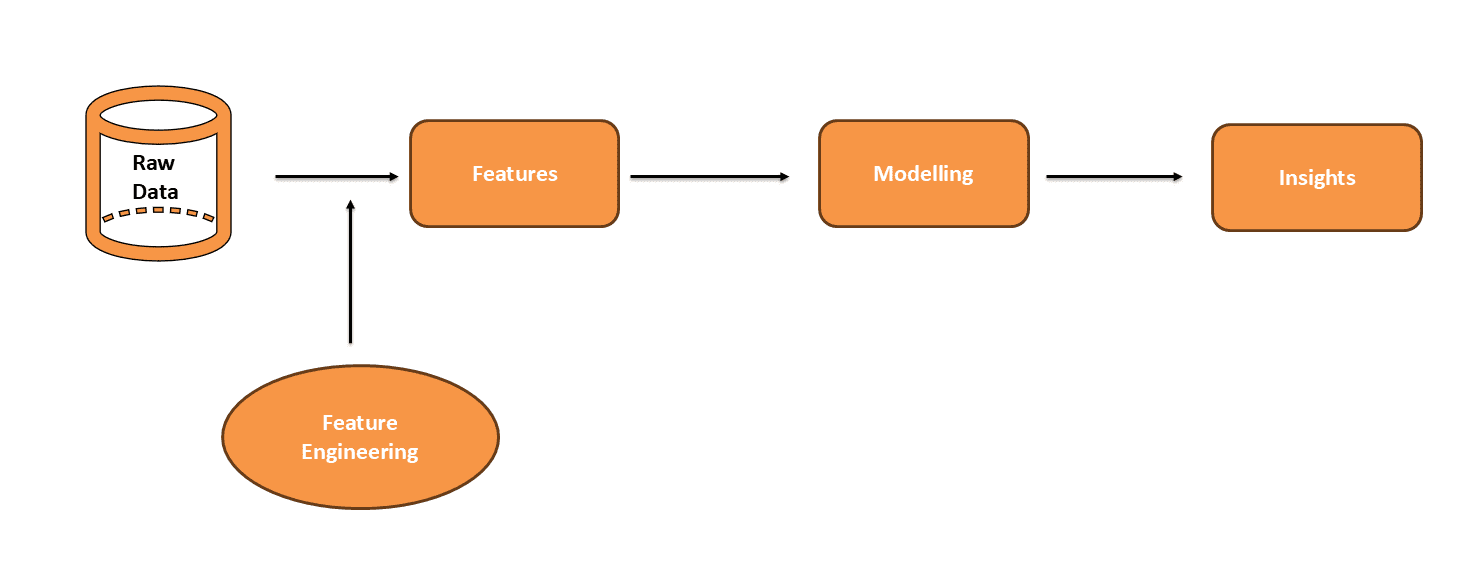
特征工程(Feature Engineering)是指将原始数据(Raw Data)转化为更适合机器学习模型的特征(Feature),以提升模型性能和泛化能力的系统性过程。
-
英文专有名词:Feature Engineering, Feature Extraction, Feature Transformation, Feature Selection
-
本质:用统计、算法和领域知识,把原始观测值“提炼”为模型可理解、可学习的变量,是数据科学中最具创造性和影响力的环节之一。
1.1 特征的定义
-
特征(Feature):可量化的输入变量,代表数据中的某一属性。例如,房价预测中的“面积”、“地段”、“建造年份”。
-
特征工程的目标:让模型“看见”更有价值的信息,降低噪声、冗余和无关因素的影响,从而提升预测准确率和泛化能力。
二、特征工程的核心流程
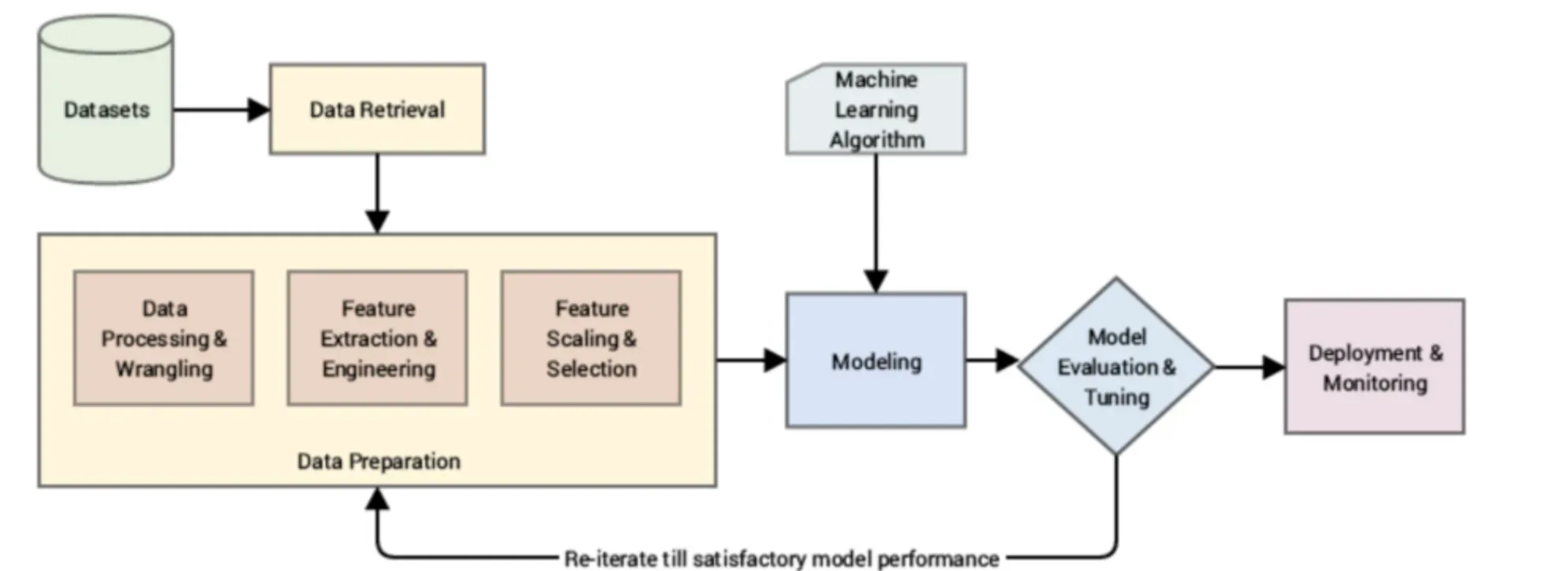
特征工程通常包含以下几个关键步骤:
-
特征创建(Feature Creation)
-
基于原始数据构造新特征,如面积/房价=单价、年龄=当前年份-出生年份等。
-
-
特征变换(Feature Transformation)
-
对特征进行数学变换,如标准化、归一化、对数变换、分箱(Binning)等。
-
-
特征提取(Feature Extraction)
-
从高维或非结构化数据中提取低维、信息密集的新特征,如PCA、LDA、文本的TF-IDF、图像的边缘检测等。
-
-
特征选择(Feature Selection)
-
筛选出最相关、最有用的特征,剔除冗余和噪声,常用方法有过滤法(Filter)、包裹法(Wrapper)、嵌入法(Embedded)。
-
-
特征评估与迭代(Feature Evaluation & Iteration)
-
通过模型验证、特征重要性分析、可视化等手段,不断优化特征集。
-
三、特征工程的数学表达
3.1 特征变换(Feature Transformation)
假设原始数据集为 ,特征变换函数为
,则:
常见如归一化(Min-Max Scaling):
标准化(Z-score):
3.2 特征构造(Feature Construction)
如构造交互特征:
或组合特征:
3.3 特征提取(以PCA为例)
主成分分析(PCA)目标:
降维后的特征:
3.4 特征选择(以L1正则化为例)
Lasso回归目标函数:
四、主流特征工程方法体系
4.1 数值型特征工程
-
归一化、标准化、分箱、对数/幂变换
-
多项式特征、交互特征、比值/差值特征
4.2 类别型特征工程
-
One-Hot编码、标签编码、目标编码(Target Encoding)、频率编码
-
类别组合、分组聚合统计特征
4.3 时间序列与日期特征工程
-
提取年、月、日、节假日、工作日等
-
滞后特征、滑动窗口统计(均值、方差、最大最小值等)
4.4 文本与非结构化数据特征工程
-
Bag-of-Words、TF-IDF、N-gram、词嵌入(Word2Vec、BERT等)
-
图像特征(边缘、纹理、深度特征)、音频特征(MFCC、频谱等)
4.5 自动化特征工程
-
FeatureTools、AutoML、深度特征自动提取(如AutoEncoder、Transformer)
五、特征工程的实际案例
六、特征工程的价值与挑战
6.1 价值
-
提升模型性能:高质量特征直接决定模型上限,可提升10-100%的准确率。
-
降低模型复杂度:通过特征选择和降维,减少冗余,提高训练效率。
-
增强可解释性:合理特征有助于模型决策透明,便于业务沟通和监管合规。
6.2 挑战
-
高度依赖领域知识:特征设计需结合业务与数据理解,无法完全自动化。
-
特征爆炸与冗余:过多特征可能导致维度灾难、过拟合和计算资源浪费。
-
数据质量与一致性:噪声、缺失、异常值等问题需在特征工程中妥善处理。
七、未来趋势与发展方向
-
自动化特征工程(AutoFE):AutoML、深度学习等工具自动生成和筛选特征,降低人工门槛。
-
生成式特征学习:如自编码器、Transformer等模型自动学习高阶特征表示。
-
多模态特征工程:融合图像、文本、结构化等多源数据,提升模型综合理解力。
-
可解释AI与特征可视化:特征重要性分析、SHAP/LIME等工具助力模型透明化。
-
实时与流式特征工程:支持在线学习和实时预测的特征计算与更新。
八、主流特征工程方法原理与实用实现
1. 数值型特征工程
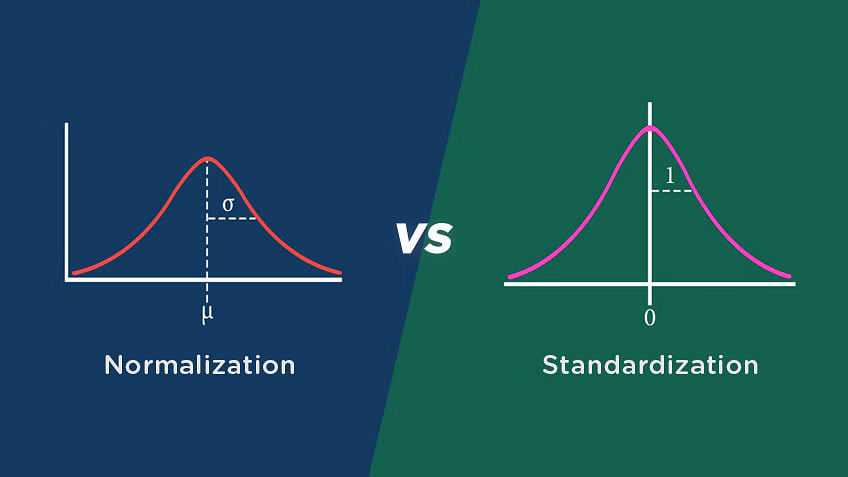
1.1 归一化(Normalization)与标准化(Standardization)
-
原理:
-
归一化将特征缩放到指定区间(如),适合分布无明显异常值的数据。
-
标准化将特征变为均值为0、方差为1的分布,适合有异常值或正态分布假设的数据。
-
-
公式:
-
伪代码实现(Python, sklearn):
from sklearn.preprocessing import MinMaxScaler, StandardScalerscaler = MinMaxScaler()X_norm = scaler.fit_transform(X)scaler = StandardScaler()X_std = scaler.fit_transform(X)
1.2 分箱(Binning)
-
原理:将连续变量离散化为若干区间(bins),提升模型对非线性关系的表达能力。
-
常用方法:等宽分箱、等频分箱、基于聚类的分箱。
-
伪代码实现:
import pandas as pd# 等宽分箱df[\'age_bin\'] = pd.cut(df[\'age\'], bins=5, labels=False)# 等频分箱df[\'income_bin\'] = pd.qcut(df[\'income\'], q=4, labels=False)
1.3 多项式与交互特征(Polynomial & Interaction Features)
-
原理:通过特征组合、幂次扩展,捕捉变量间的高阶关系。
-
公式:
-
伪代码实现:
from sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures(degree=2, interaction_only=True, include_bias=False)X_poly = poly.fit_transform(X)
2. 类别型特征工程
2.1 One-Hot编码(One-Hot Encoding)
-
原理:将每个类别映射为独立的二进制特征,适合无序类别变量。
-
伪代码实现:
import pandas as pddf = pd.get_dummies(df, columns=[\'color\', \'city\'])
2.2 标签编码(Label Encoding)
-
原理:将类别变量映射为整数,适合有序类别。
-
伪代码实现:
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()df[\'grade_encoded\'] = le.fit_transform(df[\'grade\'])
2.3 目标编码(Target/Mean Encoding)
-
原理:用类别对应目标变量的均值/中位数等统计量替代类别标签,适合高基数类别变量。
-
伪代码实现(以分类为例):
mean_map = df.groupby(\'category\')[\'target\'].mean()df[\'category_mean_enc\'] = df[\'category\'].map(mean_map)
2.4 频率编码(Frequency Encoding)
-
原理:用类别出现频率替代类别标签,适合类别分布极不均衡的情况。
-
代码实现:
freq_map = df[\'category\'].value_counts(normalize=True)df[\'category_freq_enc\'] = df[\'category\'].map(freq_map)
3. 时间序列与日期特征工程
3.1 时间特征提取
-
原理:将时间戳拆解为年、月、日、时、分、秒、星期、节假日等,捕捉周期性与季节性。
-
代码实现:
df[\'month\'] = df[\'date\'].dt.monthdf[\'dayofweek\'] = df[\'date\'].dt.dayofweekdf[\'is_weekend\'] = df[\'date\'].dt.dayofweek >= 5
3.2 滞后与滑动窗口特征
-
原理:引入历史窗口的统计量(如均值、最大、最小、标准差),帮助模型捕捉时序依赖。
-
代码实现:
df[\'sales_lag_1\'] = df[\'sales\'].shift(1)df[\'sales_rolling_mean_7\'] = df[\'sales\'].rolling(window=7).mean()
4. 文本与非结构化数据特征工程
4.1 文本特征提取
-
Bag-of-Words/TF-IDF:
-
原理:统计词频或加权词频,转为稀疏向量。
-
代码实现:
from sklearn.feature_extraction.text import TfidfVectorizervectorizer = TfidfVectorizer(ngram_range=(1,2), max_features=1000)X_tfidf = vectorizer.fit_transform(df[\'text\'])
-
-
词嵌入(Word Embedding):
-
原理:用Word2Vec、GloVe、BERT等模型将词或句子转为稠密向量,捕捉语义关系。
-
代码实现(以gensim为例):
from gensim.models import Word2Vecw2v_model = Word2Vec(sentences, vector_size=100, window=5, min_count=1)vector = w2v_model.wv[\'word_example\']
-
4.2 图像与音频特征
-
图像:边缘、纹理、颜色直方图、深度神经网络特征(如ResNet、VGG输出)。
-
音频:MFCC、频谱、Chroma等。
5. 特征选择与降维
5.1 过滤法(Filter)
-
原理:用统计指标(如方差、相关系数、卡方检验、互信息)筛选特征。
-
代码实现(以方差筛选为例):
from sklearn.feature_selection import VarianceThresholdselector = VarianceThreshold(threshold=0.01)X_selected = selector.fit_transform(X)
5.2 包裹法(Wrapper)
-
原理:用模型性能作为特征选择依据(如递归特征消除RFE)。
-
代码实现:
from sklearn.feature_selection import RFEfrom sklearn.linear_model import LogisticRegressionrfe = RFE(estimator=LogisticRegression(), n_features_to_select=10)X_rfe = rfe.fit_transform(X, y)
5.3 嵌入法(Embedded)
-
原理:用模型自带的特征选择机制(如L1正则、树模型特征重要性)。
-
代码实现(以Lasso为例):
from sklearn.linear_model import Lassolasso = Lasso(alpha=0.01)lasso.fit(X, y)selected_features = X.columns[lasso.coef_ != 0]
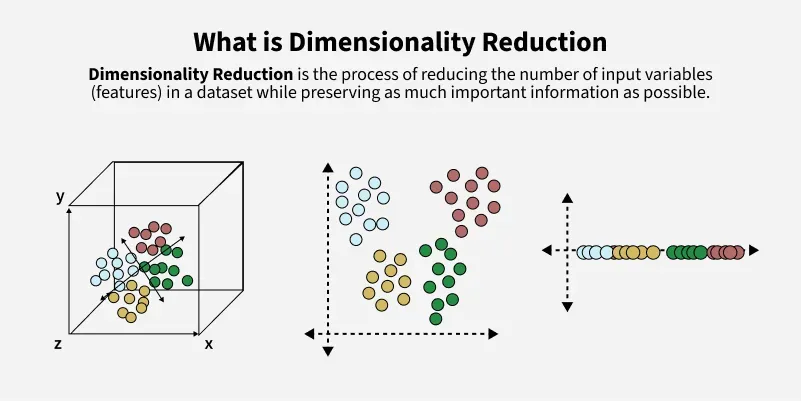
5.4 降维(Dimensionality Reduction)
-
主成分分析(PCA):
-
原理:线性降维,保留最大方差方向。
-
公式:
-
代码实现:
from sklearn.decomposition import PCApca = PCA(n_components=10)X_pca = pca.fit_transform(X)
-
-
t-SNE/UMAP:非线性降维,适合高维数据可视化。
6. 自动化特征工程(AutoFE)
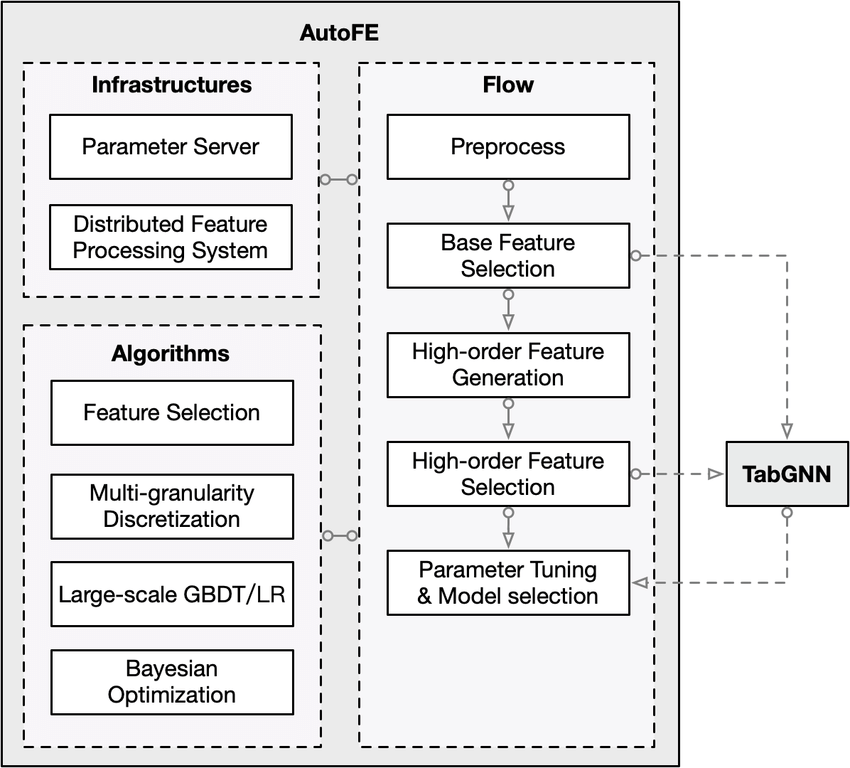
-
原理:用自动化工具(如FeatureTools、AutoML、深度学习)自动生成、筛选和组合特征,降低人工门槛。
-
代码实现(以FeatureTools为例):
import featuretools as ftes = ft.EntitySet(id=\'data\')es = es.entity_from_dataframe(entity_id=\'df\', dataframe=df, index=\'id\')feature_matrix, feature_defs = ft.dfs(entityset=es, target_entity=\'df\')
九、特征工程的未来前沿
-
生成式特征学习:利用自编码器、Transformer等深度模型自动发现高阶特征,减少人工干预。
-
多模态特征融合:将结构化、文本、图像、音频等多源特征融合,提升模型综合理解力。
-
实时与流式特征工程:支持在线学习和实时预测的特征计算与动态更新。
-
特征可解释性与可视化:结合SHAP、LIME等工具,量化特征对模型决策的影响,提升AI系统透明度。
-
AutoML与端到端管道:自动化特征生成、筛选、建模与部署,推动AI工程全流程智能化。
十、总结
特征工程(Feature Engineering)是机器学习和人工智能系统中最具创造性、最能体现工程师价值的环节之一。它不仅决定了模型的“输入上限”,更直接影响着模型的泛化能力、可解释性和工程落地效果。无论是数值型、类别型、时间序列、文本还是图像、音频等非结构化数据,高质量的特征设计和处理都是模型性能提升的关键。
特征工程的核心价值在于:
-
将原始数据转化为信息密度更高、与任务更相关的特征,帮助模型更好地“理解”数据本质;
-
通过特征变换、构造、选择和降维,有效降低冗余、缓解噪声、提升训练效率;
-
结合领域知识与统计方法,提升模型的可解释性和业务适用性。
工程实践中,特征工程既需要理论方法(如归一化、标准化、PCA、特征选择等)的系统掌握,也离不开对数据、业务和模型的深入理解。自动化特征工程(AutoFE)、深度特征学习、多模态特征融合等新技术正在不断降低人工门槛,但领域知识和创造性设计仍然不可替代。
未来趋势方面,特征工程将与AutoML、生成式AI、可解释性工具和实时流式数据处理深度融合,推动AI系统实现更高效、更智能、更透明的数据驱动决策。
掌握特征工程,不仅是成为优秀AI工程师和数据科学家的必修课,更是让模型“聪明起来”、让AI系统真正服务于复杂现实世界的核心能力。无论技术如何演进,特征工程的价值都不会过时——它是AI系统性能跃迁和创新的永恒引擎。
谢谢你看到这里,你们的每个赞、收藏跟转发都是我继续分享的动力。
如需进一步案例、代码实现或与其他聚类算法对比,欢迎留言交流!我是爱酱,我们下次再见,谢谢收看!


