【JS逆向】B站视频评论oid,w_rid签名参数,签名密钥a算法详解_bilibili oid
本篇文章仅用于交流与学习,严禁用于任何商业于非法用途!否则由此产生的一切后果均与作者无关!如有侵权,请联系作者本人进行删除!
感谢关注!!您的关注和点赞就是我的动力❤❤
文章目录
01.逆向目标
02.抓包分析
03.逆向过程
1) md5加密
2) 加密参数
3) 算法逻辑
4) 签名密钥a
5) oid参数
04.最终效果
01.逆向目标
目标网址:atob(\"aHR0cHM6Ly93d3cuYmlsaWJpbGkuY29tL3ZpZGVvL0JWMTVnNDExcjdBdi8=\")
最近许多兄弟也是接了一些关于B站的爬虫单子,但是针对于B站的数据无从下手怎么办。今天我以其中一个B站视频的评论作为案例,给兄弟们做一个请求参数中的w_rid,wts,oid参数逆向详解。
02.抓包分析
老样子,打开我们的好兄弟“开发者工具”,刷新网页并往下翻动,让网页多加载一些承载着评论数据的数据包。在我们的开发者工具中筛选这些评论的数据来源,并观察它们的参数变化。
第一页评论数据: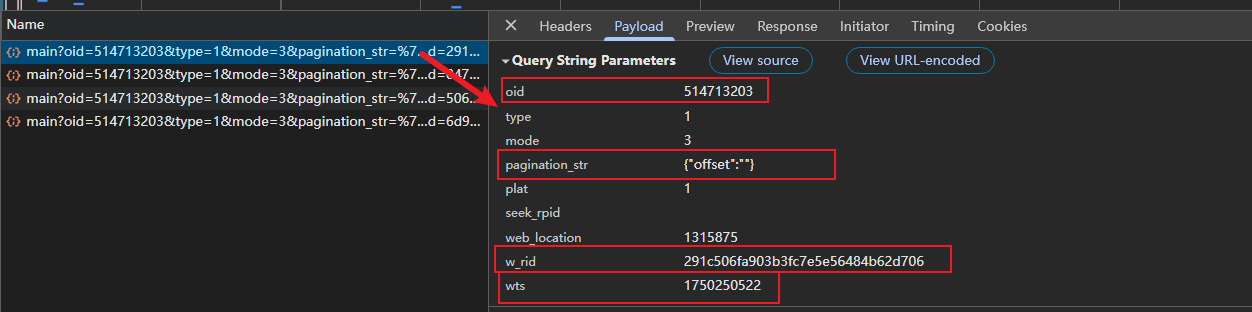
其他页评论数据: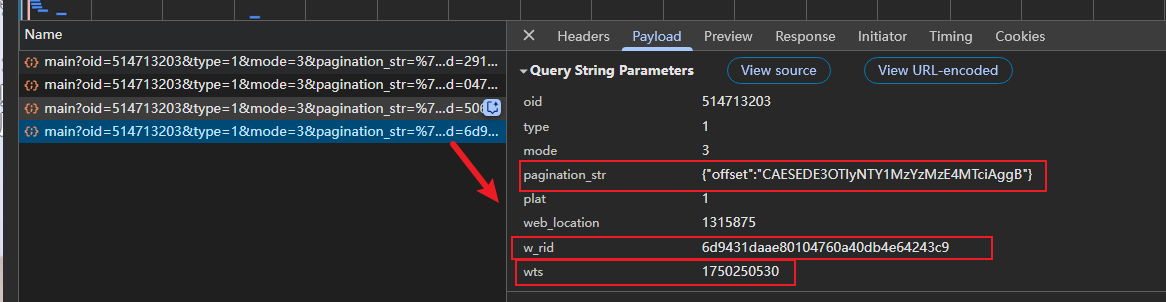
首先,我们可以直观的看到他的参数变化,w_rid以及wts的值都是变化的,并且w_rid很符合MD5加密的格式,wts可能是以秒为单位的时间戳。
我们在python中生成一个以秒为单位的时间戳查看并对比(也可以翻动评论观察wts的变化),确认它的确是以秒为单位的时间戳。
其次,通过字面意思我们可以大致了解到oid可能是当前识别视频的标识符(字符集base58解码),pagination_str应该是评论的页码。而其他的参数都是固定不变的。
pagination_str既然是评论的页码,并且它的值也不像是某种加密得来,我们可以尝试拿到它的值在所有的请求数据包中搜索一下。这里我们也是通过观察发现,每个评论数据的pagination_str参数都是来自上一个评论数据的响应。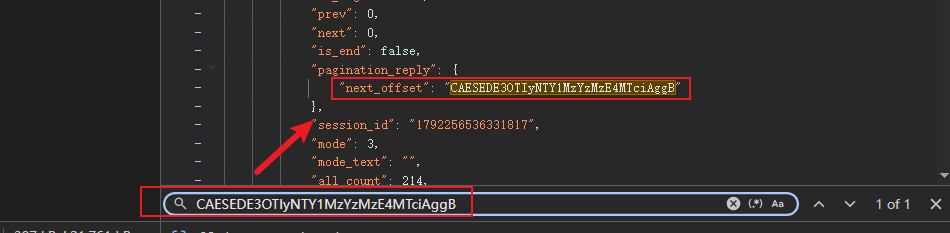
最后,我们观察到第一页数据包的参数和其他页参数的数据包的请求参数是不同的,是不是就可以猜测后续,进行某些加密的时候,加密的逻辑也是不一样的呢?
至此,分析完这几个参数后,我们确定我们当前需要解决的就只剩下w_rid和oid这两个参数。
03.逆向过程
先解决w_rid参数的加密逻辑。可以通过在请求调用堆栈中一步步往回找到加密的入口,也可以在全局搜索\"w_rid:\"的方式去寻找加密的入口。我这里使用的是全局搜索的方式。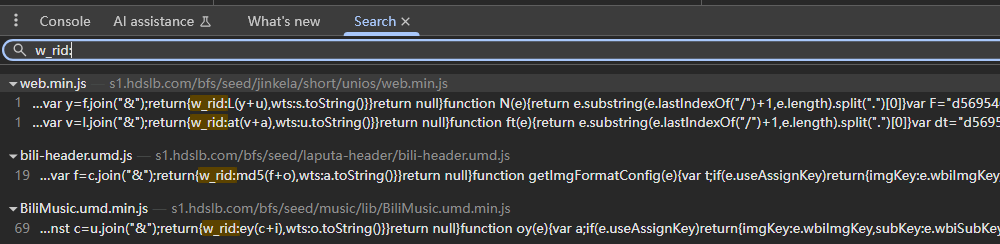
在搜索到的地方分别打上断点,往下翻动评论进行调试。发现它断在了这个地方。输出at(v+a)的值,发现它正式我们需要的请求参数的值。
1) md5加密
最开始我们猜测参数w_rid可能是由MD5加密得来,这里我们把断点设置在这里后,在控制台调用这个at函数,并输出at(\"123\")的值,看看与标准的MD5加密是否有相同的结果。如果结果一致,就说明at()函数正是一个标准的MD5加密。

果然如此!这里我们就可以确定at()函数就是一个标准的MD5加密。那么接下来就只需要找出它加密了什么参数,这些参数是怎么生成的即可。
2) 加密参数
我们观察这段js代码,这里加密的参数是通过v和a字符串拼接得来,在控制台输出v和a的值。
v的值很可能是我们请求参数中的其他字符串参数拼接得来,a的值我们暂且不知道。
3) 算法逻辑
往上阅读它的js代码。发现上述函数的核心功能就是先从localStorage或传进来的参数中获取imgKey和subKey两个密钥,如果localStorage中不存在或无法读取,则使用默认参数中的密钥。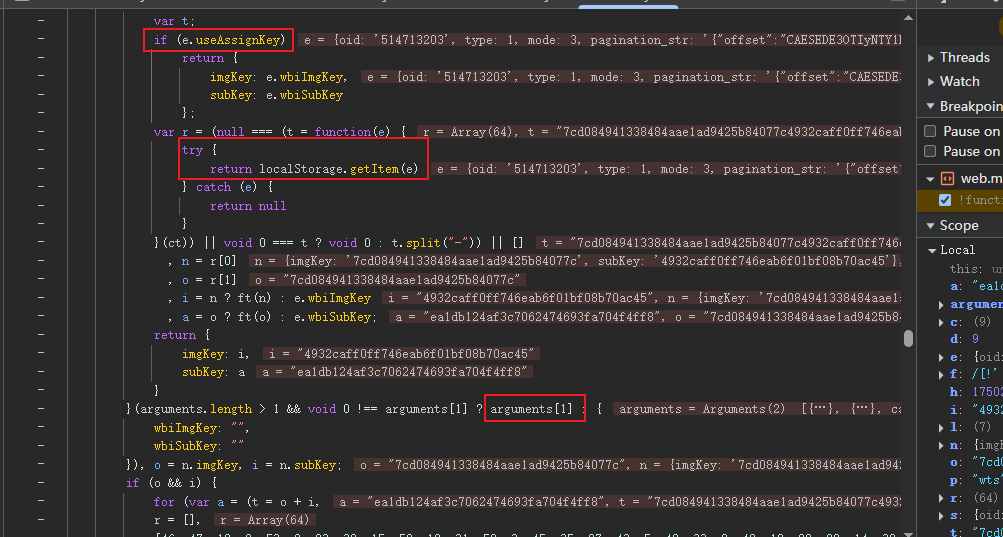
将imgKey和subKey拼接后,按照固定的索引顺序,重新组合字符,截取前32个字符作为最终的签名密钥a。
接着通过内置方法Object.assign()将秒级时间戳wts添加到对象e当中。然后对请求参数名进行排序,拼接成key=value格式的字符串,并对特殊的字符串进行encodeURIComponent()编码(如pagination_str值)。最后也是将处理后的参数与签名密钥进行拼接,通过at函数生成我们想要的w_rid签名。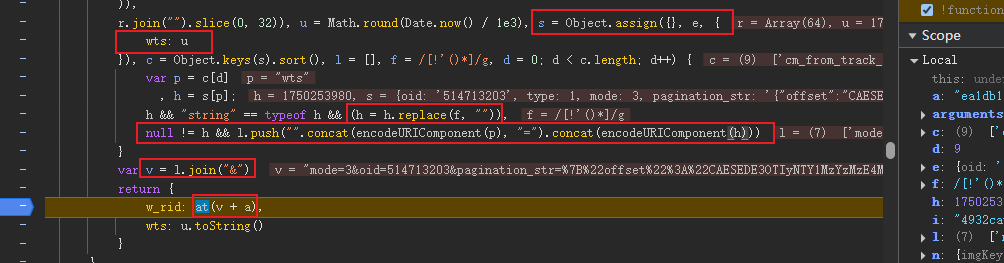
最后也是对秒级时间戳wts进行转字符串处理。
// w_rid签名参数核心算法function lt(e) { var t, r, n = function(e) { var t; if (e.useAssignKey) return { imgKey: e.wbiImgKey, subKey: e.wbiSubKey }; var r = (null === (t = function(e) { try { return localStorage.getItem(e) } catch (e) { return null } }(ct)) || void 0 === t ? void 0 : t.split(\"-\")) || [] , n = r[0] , o = r[1] , i = n ? ft(n) : e.wbiImgKey , a = o ? ft(o) : e.wbiSubKey; return { imgKey: i, subKey: a } }(arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : { wbiImgKey: \"\", wbiSubKey: \"\" }), o = n.imgKey, i = n.subKey; if (o && i) { for (var a = (t = o + i, r = [], [46, 47, 18, 2, 53, 8, 23, 32, 15, 50, 10, 31, 58, 3, 45, 35, 27, 43, 5, 49, 33, 9, 42, 19, 29, 28, 14, 39, 12, 38, 41, 13, 37, 48, 7, 16, 24, 55, 40, 61, 26, 17, 0, 1, 60, 51, 30, 4, 22, 25, 54, 21, 56, 59, 6, 63, 57, 62, 11, 36, 20, 34, 44, 52].forEach((function(e) { t.charAt(e) && r.push(t.charAt(e)) } )), r.join(\"\").slice(0, 32)), u = Math.round(Date.now() / 1e3), s = Object.assign({}, e, { wts: u }), c = Object.keys(s).sort(), l = [], f = /[!\'()*]/g, d = 0; d < c.length; d++) { var p = c[d] , h = s[p]; h && \"string\" == typeof h && (h = h.replace(f, \"\")), null != h && l.push(\"\".concat(encodeURIComponent(p), \"=\").concat(encodeURIComponent(h))) } var v = l.join(\"&\"); return { w_rid: at(v + a), wts: u.toString() } } return null}4) 签名密钥a
OK,知道了MD5加密参数的生成逻辑后,我们就要解决签名密钥a的问题了。通过不断的调用调试。我们观察到,这里是想自运行函数中传入了\"wbi_img_urls\"进而获取了两个链接,而生成签名密钥a的imgKey和subKey也是来自于这两个链接分割而来。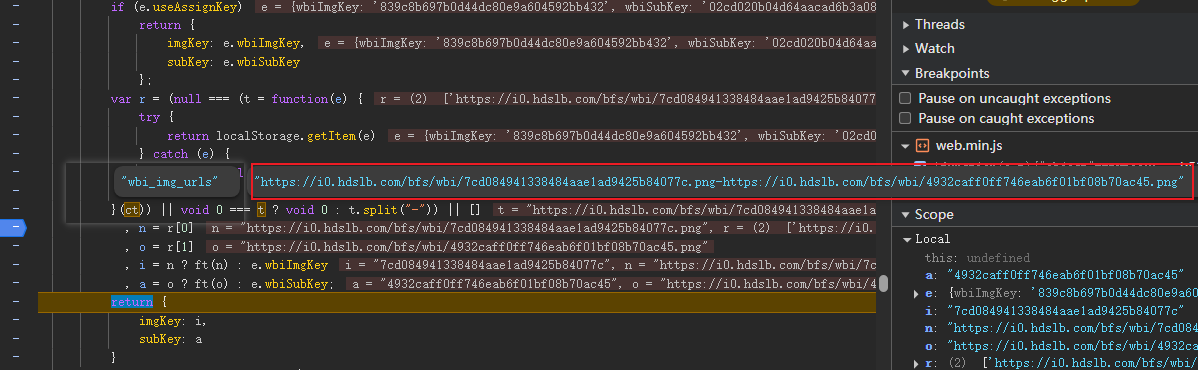
我们通过全局搜索这两个链接,发现它们均来自这数据包的响应,并且这个请求的请求方式是GET不需要任何参数。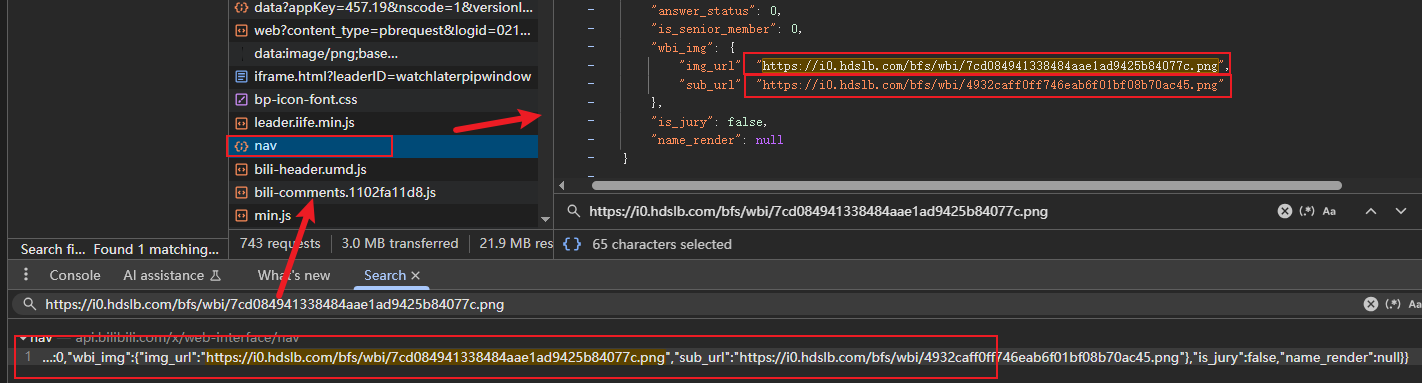
那么我们就可以通过python模拟它的算法,生成相同的签名密钥。
# 签名密钥a算法def get_sign_key(): data = requests.get(\"https://api.bilibili.com/x/web-interface/nav\",headers=headers,cookies=cookies).json() imgKey = data.get(\"data\").get(\"wbi_img\").get(\"img_url\").split(\"/\")[-1].split(\".\")[0] subKey = data.get(\"data\").get(\"wbi_img\").get(\"sub_url\").split(\"/\")[-1].split(\".\")[0] t = imgKey + subKey index_list = [46, 47, 18, 2, 53, 8, 23, 32, 15, 50, 10, 31, 58, 3, 45, 35, 27, 43, 5, 49, 33, 9, 42, 19, 29, 28, 14, 39, 12, 38, 41, 13, 37, 48, 7, 16, 24, 55, 40, 61, 26, 17, 0, 1, 60, 51, 30, 4, 22, 25, 54, 21, 56, 59, 6, 63, 57, 62, 11, 36, 20, 34, 44, 52] r = [] for e in index_list: if e < len(t): r.append(t[e]) a = \'\'.join(r)[:32] return a运行效果:![]()
有了签名密钥a,我们就可以通过python编写代码,获取到签名参数w_rid的值了。但是这里需要注意的是,我们最开是观察到第一页的请求参数,和其他页的是不同的。兄弟们多多调用调试也可以发现其实没有太大变化,签名参数还是那个参数。唯一不同的就是多拼接了一个请求中多余的参数而已。
并且pagination_str的值{\"offset\":\"\"}也是没有东西的(因为是第一页),所以这点也需要注意一下。在最后整体爬取的时候,单独写一个请求函数就可以了。
5) oid参数
兄弟们,这里我也就不卖关子了,这里的oid参数就是当前视频的AV号,对应url中的这一块,也就是BV号。而B站的BV号是用于替代早期AV号(如 AV514713203)的新型视频标识符,它实际上是一个base58编码。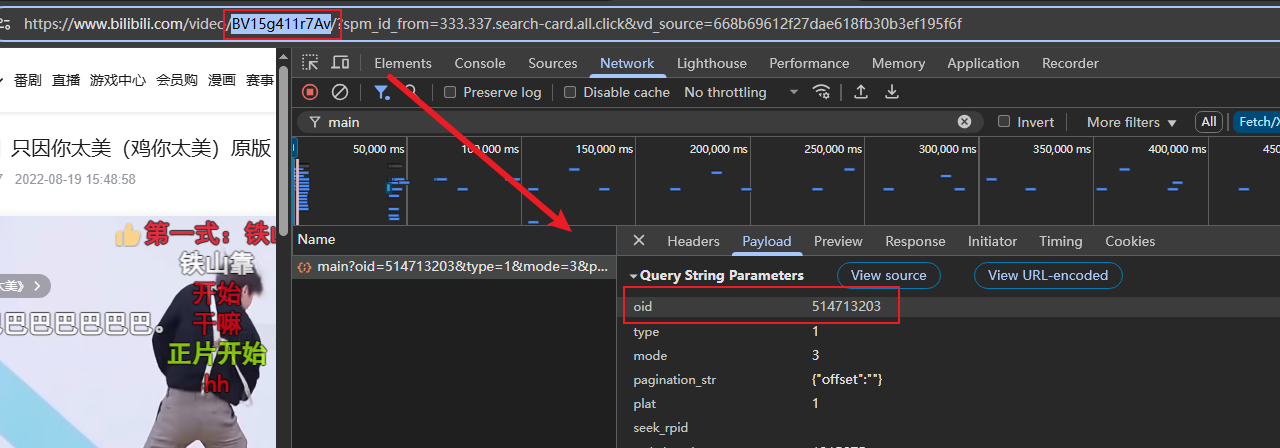
将BV号通过字符集base58进行解码即可得到正确的oid参数(AV号)。后续的设计,兄弟们可以自行操作。
# BV号解码为AV号def bv_to_av(bv): # BV 号使用的字符集(Base58) table = \'fZodR9XQDSUm21yCkr6zBqiveYah8bt4xsWpHnJE7jL5VG3guMTKNPAwcF\' # 位置置换表(用于混淆) s = [11, 10, 3, 8, 4, 6] # 固定偏移量 xor = 177451812 # 固定模数 add = 8728348608 # 提取并还原字符顺序 chars = [bv[s[i]] for i in range(6)] # 将 Base58 字符转换为数值 num = 0 for i, c in enumerate(chars): num += table.index(c) * (58 ** i) # 逆运算:减去偏移量,再异或 av = (num - add) ^ xor return av04.最终效果
代码最终运行效果: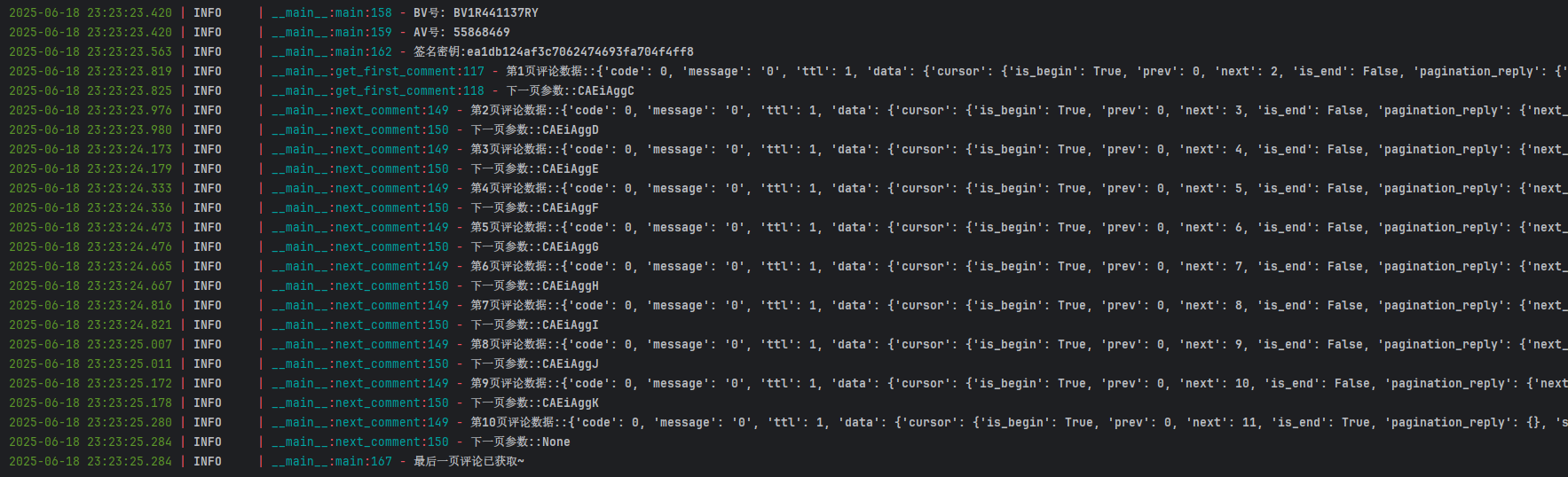
编写不易,兄弟们点点赞!!点点关注!!你们的支持,就是我的动力o(* ̄︶ ̄*)o


