字节黑科技:仅凭“音频+1张图”,数字人精细度狂飙20%,真人动画复刻出神入化!
视频之言:
为什么需要这个算法?
尽管人体图像动画生成已经成为当下热门的研究方向,但现有的方法大多只能生成粗粒度的动画。在实现整体精细控制、多尺度输入的泛化能力以及长期时间连贯性方面,现有技术仍然面临重大挑战。
这个算法能做什么?
我们提出了一种基于DiT框架的算法——DreamActor-M1(简称DA-M1)。该算法通过混合引导技术,能够生成整体、富有表现力且鲁棒的人体图像动画。只需提供一张参考图像,DA-M1就能模仿视频中捕捉到的人类行为,生成从肖像到全身动画的多尺度高表现力和逼真的人类视频。
这个算法效果如何?
大量实验结果表明,DA-M1在性能上优于当前最先进的基线方法。它能够为肖像、上身和全身生成富有表现力的结果,生成的视频在时间上保持一致,身份得以保留,并且具有高保真度。
1:M1模块背景概述
沿途风景
随着视频生成技术的快速发展,人体图像动画逐渐成为研究热点,在电影制作、广告传播以及电子游戏等地方展现出广阔的应用前景。然而,当前方法仍主要停留在粗粒度的动作控制层面,在实现精细动作还原(如细微的眨眼、唇部颤动)、适应多尺度输入(如肖像、上半身、全身)以及维持长时间序列中的视觉一致性(如遮挡区域的衣物或肢体连贯性)等方面仍面临显著挑战
2:DA-M1算法简介
22222
为了应对这些复杂场景,作者提出了一个基于DiT框架的算法——DreamActor-M1。该算法通过混合引导技术,实现了整体、富有表现力且鲁棒的人体图像动画。在运动引导方面,混合控制信号融合了隐式面部表示、3D头部球体和3D身体骨架信息,从而实现了对面部表情和身体运动的精准控制,生成了富有表现力且身份一致的动画。
为了适应从肖像到全身视图的各种身体姿势和图像比例,作者采用了一种渐进式训练策略,使用不同分辨率和比例的数据进行训练。在外观引导方面,作者将连续帧的运动模式与互补的视觉参考相结合,确保在复杂运动中不可见区域的长期时间连贯性。
大量实验结果表明,该方法在性能上优于当前最先进的基线方法,能够为肖像、上身和全身生成富有表现力的结果,并具有鲁棒的长期一致性。
3:DA-M1算法应用场景
3.1-基础动作场景
3.1
3.2复杂角色和动作风格场景
3.2
3.3高可控场景
3.3
4:DA-M1算法整体流程
当然,以下是对您提供段落的优化改写版本,使语言更流畅、逻辑更清晰,同时保持技术细节的准确性:
DreamActor-M1 算法在训练阶段的整体流程如下:
首先,从驱动视频的每一帧中提取人体的骨骼姿态和头部球体(head sphere)信息,用于表征身体与头部的运动状态。这些结构化姿态信息随后被送入姿态编码器,转化为紧凑的潜在姿态表示。
接着,该姿态潜在特征与噪声视频的潜空间特征在通道维度上进行融合。其中,视频潜特征通过一个3D变分自编码器(3D VAE)对输入视频片段进行编码获得。与此同时,面部表情动态由独立的面部运动编码器进行建模,生成对应的隐式面部运动表征。
在去噪过程中,以编码后的视频潜特征作为监督信号,指导噪声潜特征的逐步重建。在DiT(Diffusion Transformer)的每一模块中,面部运动信息通过交叉注意力机制融入噪声标记的处理流程;而参考图像的外观特征则通过“自注意力(self-Att)+ 交叉注意力(ref-Att)”的级联结构注入到噪声分支中,从而实现身份一致性与细节纹理的精准还原。
该流程有效融合了姿态控制、面部动态与外观参考,支持高质量、可控的人体图像动画生成。
如需更简洁或更偏工程实现的表达,也可进一步调整。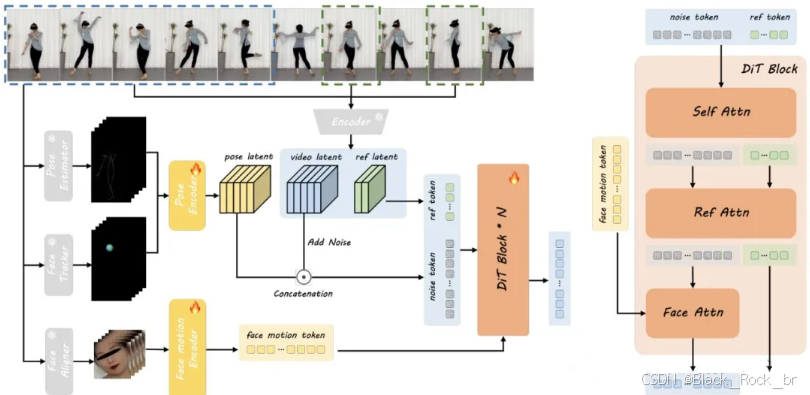
5:DA-M1算法实现细节
5.1算法推理流程

上图展示了该算法的整体推理流程,具体步骤如下:
首先,作者(可选地)生成多个伪引用,以提供互补的外观信息。
接着,作者从驾驶视频中提取混合控制信号,这些信号包括隐式面部运动和显式姿势(头部球体和身体骨架)。
最后,将这些信号注入DiT模型,以合成动画人类视频。
需要注意的是,该框架将面部运动与身体姿势分离,面部运动信号也可以从语音输入中导出。
5.2算法训练细节

为提升模型的初始化效果,作者采用一个预训练的图像到视频生成模型进行权重初始化,并结合条件训练策略进行阶段性预热。整个训练过程分为三个阶段,训练步数分别为20,000步、20,000步和30,000步。
为了增强模型对不同视频时长和空间分辨率的泛化能力,训练中采用动态采样策略:每个视频片段的帧数在25至121之间随机选取,空间分辨率则统一调整为960×640的区域,同时保持原始视频的宽高比不变,以避免形变。
所有训练阶段均在8张NVIDIA H20 GPU上进行,使用AdamW优化器,学习率设为5×10⁻⁶。在推理阶段,每个生成的视频片段包含73帧。为保证跨片段的时间连续性,作者将前一片段末尾的潜特征作为下一片段的初始状态,从而将后续片段的生成转化为条件化的图像到视频生成任务。参考图像的外观信息与运动控制信号均采用无分类器引导(Classifier-Free Guidance, CFG),引导权重统一设为2.5,以平衡生成质量与控制精度
6:DA-M1算法性能评估
6.1 主观效果性能评估
20250816_190617
上面的视频展示了该方法在位姿迁移任务上与其他多个最先进的方法(DisPose、MimicMotion、Champ、Animate Anyone)的生成效果对比。经过细致的观察与分析,我们发现:相较于其他基线方法,该方法能够生成更加精细的运动效果,同时在身份保持、时间连贯性以及生成图像的高保真度方面表现出色。
20250816_191031
上方视频展示了本算法与多种当前领先方法(如 LivePortrait、X-Portrait、Skyreels-A1 和 Runway ActOne)在肖像动画任务中的生成效果对比。通过细致观察与分析可以发现,该方法在人像驱动的精细度和表现力方面更具优势,能够更准确地还原面部细微动作,实现更自然、生动的高保真肖像动画,展现出更强的细节控制能力。
6.2客观效果性能评估
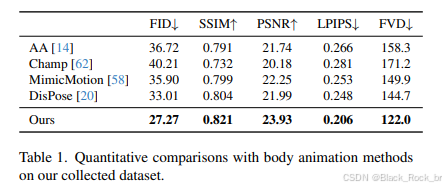
上表展示了本方法与当前先进的身体驱动动画方法(如 AA、Champ、Mimic Motion 和 DisPose)在多个客观评价指标上的定量对比结果。通过分析可知,本方法在绝大多数指标上均取得了最优表现,相较于现有方法实现了显著提升,表明其在生成质量、动作保真度和时序一致性等方面具有更强的综合性能。
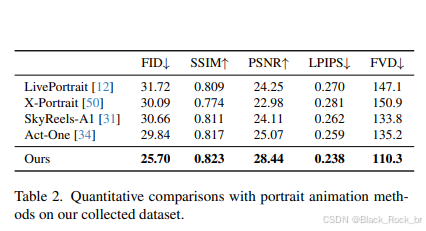
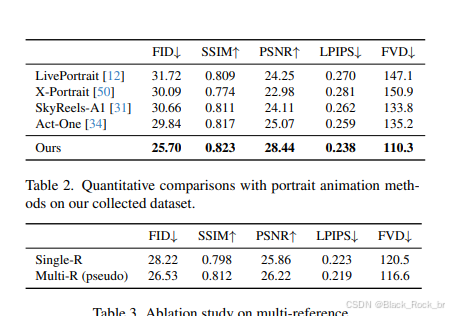
上表呈现了该方法与多个顶尖肖像动画方法(LivePortrait、X-Portrait、Sky Reels-A、Act-One)在客观指标上的评估结果对比。经过细致的观察与分析,我们不难发现:相较于其他基线方法,该方法在多项关键指标上均实现了显著的提升,并且与排名第二的方法之间形成了较为明显的差距。
文章总结:
本文介绍了一项由字节跳动研发的前沿数字人生成技术,仅需输入一段音频和一张静态人像照片,即可生成高度逼真、细节丰富的动态人物视频。该技术通过深度融合音频驱动与图像动画建模,在面部微表情(如眨眼、唇动、肌肉颤动)和头部运动的精细控制上实现突破,相较现有方法,动作自然度与视觉保真度提升约20%。其核心算法在多尺度特征融合、时序一致性建模和跨模态对齐方面进行了创新,显著提升了单图驱动下的动画质量,实现了接近真人级的动态复刻效果。该技术有望广泛应用于虚拟主播、短视频生成、元宇宙交互等场景,标志着AI驱动数字人迈向“以少驭多、以静生动”的新阶段

