【论文阅读】Fine-structure Preserved Real-world Image Super-resolution via Transfer VAE Training
TVT~
code:Joyies/TVT: [ICCV2025] Official code for Fine-structure Preserved Real-world Image Super-resolution via Transfer VAE Training
introduce
聚焦于真实世界图像超分辨率(Real-ISR)任务中 “精细结构重建” 的核心挑战,提出了一种基于 “迁移 VAE 训练(Transfer VAE Training, TVT)” 的解决方案,旨在解决现有基于稳定扩散(Stable Diffusion, SD)模型的方法在重建小文本、纹理等精细结构时的缺陷。
一、研究背景与核心问题
1. 真实世界图像超分辨率(Real-ISR)的挑战
Real-ISR 的目标是从低分辨率(LR)图像中恢复高分辨率(HR)图像,但真实场景中的图像退化复杂(如传感器噪声、运动模糊、压缩伪影等),传统方法难以处理。
-
早期基于像素损失(L1/L2)的方法仅适用于合成退化(如双三次下采样),对真实复杂退化效果差,易产生过度平滑结果。
-
GAN-based 方法虽能生成逼真纹理,但生成先验有限,且对抗训练易引入视觉伪影,稳定性差。

2. 现有 SD-based 方法的瓶颈
-
精细结构丢失:SD 模型中的变分自编码器(VAE)采用 8 倍空间下采样(VAE-D8),例如将 512×512 图像压缩为 64×64 的 latent 特征,导致小文本、细微纹理等精细结构信息不可逆丢失,扩散过程无法恢复(如图 1 (a) 所示)。
-
适配与效率问题:若直接使用 4 倍下采样 VAE(VAE-D4)以保留更多信息,会面临两个挑战:(1)新 VAE 的 latent 空间与预训练 UNet 不匹配,破坏扩散模型的生成能力;(2)latent 特征分辨率提高(如 128×128)会显著增加计算成本。
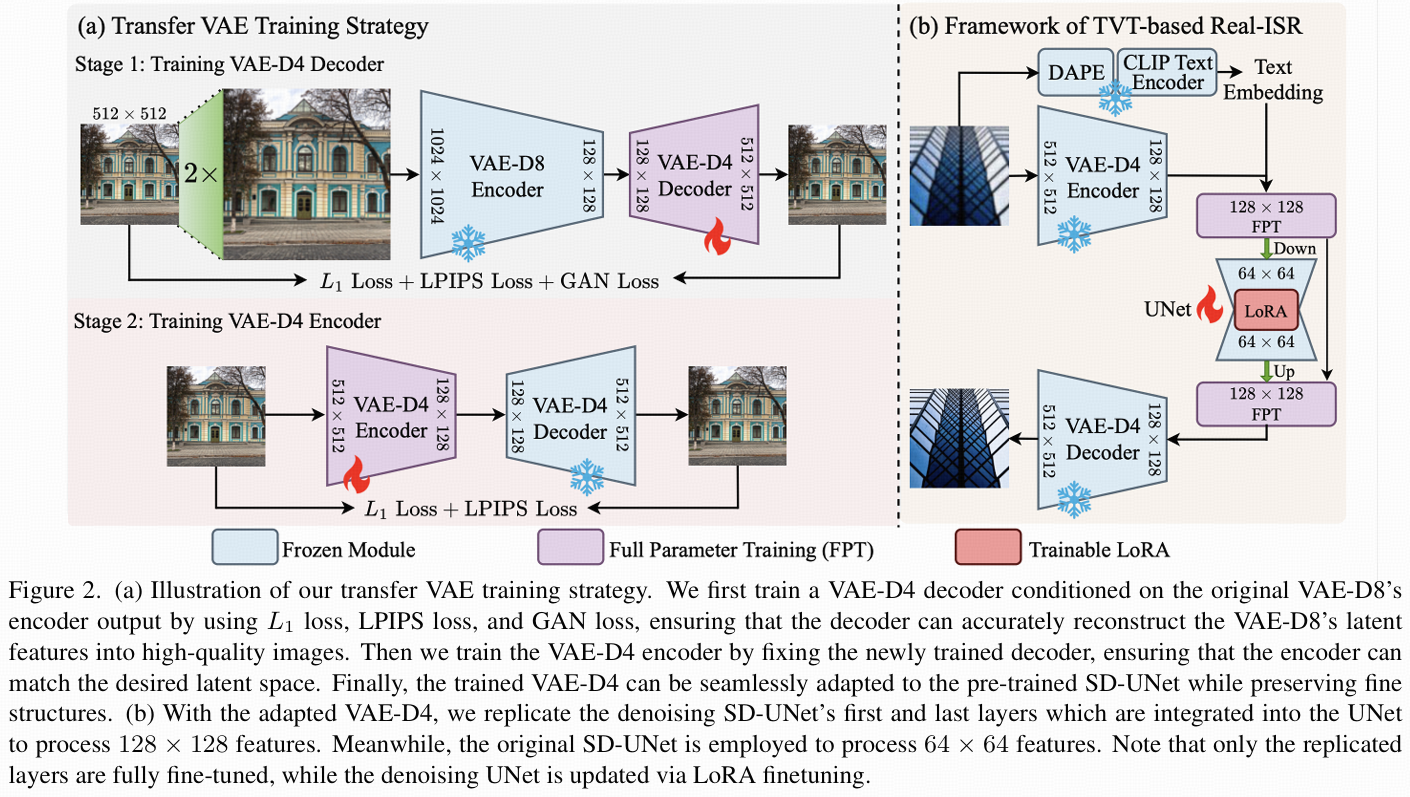
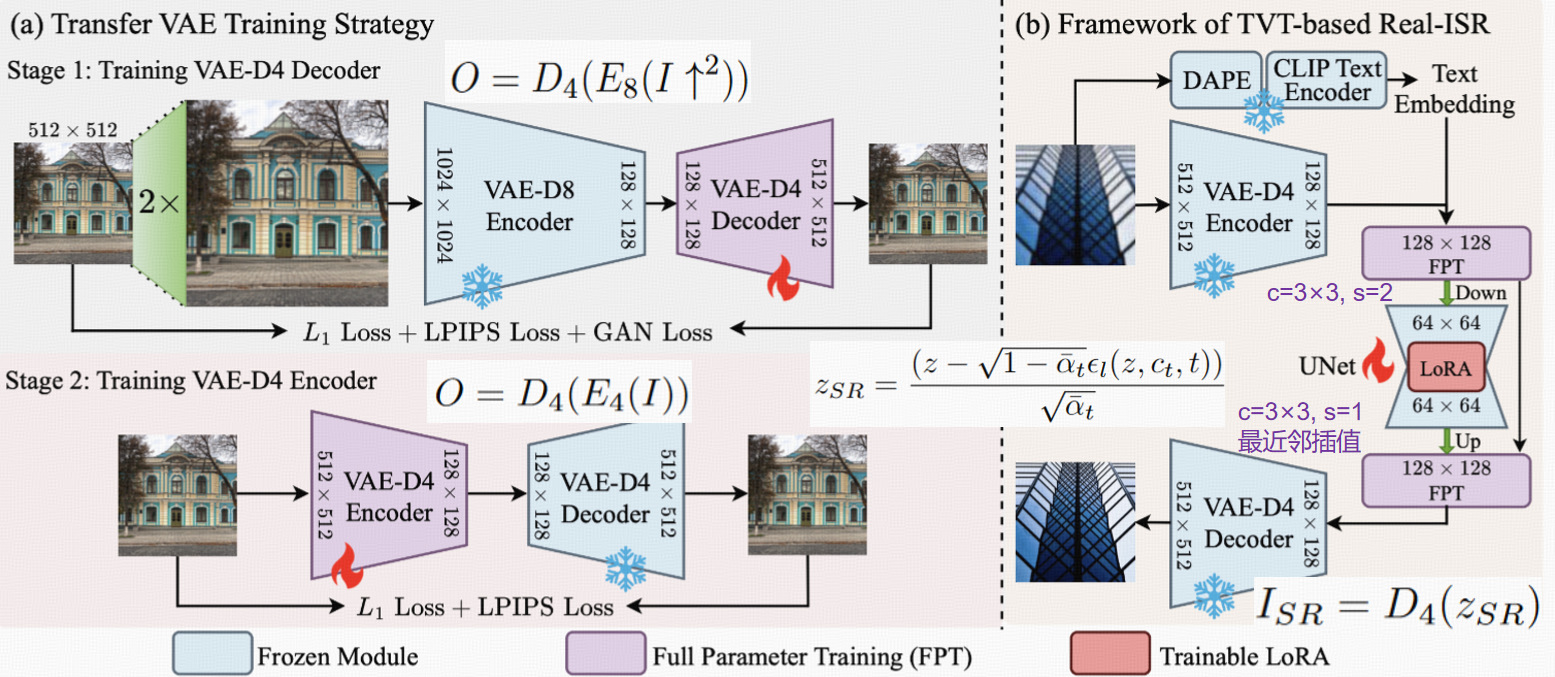
核心方法:迁移 VAE 训练(TVT)与高效网络设计
论文提出 TVT 策略解决 VAE 适配问题,并设计紧凑网络降低计算成本,整体框架围绕 “保留精细结构 + 兼容预训练模型 + 高效计算” 展开。
1. Transfer VAE Training(TVT):将 VAE-D8 迁移为 VAE-D4
目标是将 SD 中原 8 倍下采样 VAE(VAE-D8)转换为 4 倍下采样 VAE(VAE-D4),同时保持与预训练 UNet 的兼容性(即 latent 空间对齐),分两阶段训练:
-
阶段 1:训练 VAE-D4 解码器
以原 VAE-D8 编码器的输出为条件,训练一个 4 倍下采样的解码器。-
目的:让新解码器在学习重建 HR 图像精细结构的同时,对齐原 VAE 的 latent 分布(确保与 UNet 的兼容性)。
-
输入:VAE-D8 编码器输出的 64×64 latent 特征;输出:通过 4 倍解码恢复的 HR 图像,强制解码器学习从原 latent 空间到高分辨率细节的映射。
-
-
阶段 2:训练 VAE-D4 编码器
固定阶段 1 训练好的解码器,单独训练 4 倍下采样的编码器。-
目的:让新编码器生成的 128×128 latent 特征,经过解码器后能准确重建 HR 图像,同时确保新编码器的 latent 空间与原 VAE-D8 的 latent 空间分布一致(避免破坏 UNet 的扩散先验)。
-
2. 紧凑 VAE 与高效 UNet 设计:降低计算成本
4 倍下采样的 VAE 会使 latent 特征分辨率从 64×64 提升至 128×128,若直接使用原 UNet 处理,计算量会显著增加。论文通过以下设计优化:
-
紧凑 VAE:简化 VAE 的网络结构(如减少通道数、优化卷积层),在保留精细结构信息的同时降低参数规模。
-
计算高效 UNet:不直接缩减通道数(避免破坏预训练特征),而是复制预训练 UNet 的第一层和最后一层,新增分支处理 128×128 的 latent 特征;原 UNet 层继续处理 64×64 特征。
优势:微调后新增分支可适配高分辨率 latent 特征,同时保留原 UNet 的扩散先验,显著减少浮点运算次数(FLOPs)。
贡献
-
TVT 策略:首次通过 “先解码器后编码器” 的两阶段训练,实现 VAE 从 8 倍到 4 倍下采样的迁移,同时保持与预训练 UNet 的 latent 空间对齐,解决了精细结构丢失与模型兼容性的矛盾。
-
高效网络设计:通过紧凑 VAE 和分支式 UNet,在提升 latent 特征分辨率的同时降低计算成本,突破了 “高分辨率 = 高计算量” 的瓶颈。
-
精细结构重建:如图 1 (a) 所示,VAE-D4 的重建效果显著优于 VAE-D8,能保留更多细节;图 1 (b) 对比显示,相比最先进的单步扩散方法 OSEDiff,TVT 方法在小文本、纹理等精细结构上的恢复更准确。
-
计算效率:相比现有单步扩散模型,TVT 方法的 FLOPs 更低,兼顾性能与效率。
Method
动机(Motivation):为何需要 TVT?
现有 SD 模型使用 8 倍下采样 VAE(VAE-D8)是为了降低文本到图像(T2I)任务的训练成本,但这种强压缩会不可逆地丢失高频细节(如小纹理、文字),严重影响 Real-ISR 的精细结构重建。
-
已有尝试(如增加潜通道维度)需从头训练扩散模型,计算成本极高;
-
直接替换为 4 倍下采样 VAE(VAE-D4)虽能保留更多细节,但会导致:
-
新 VAE 的潜空间与预训练 UNet 不匹配,破坏扩散先验;
-
潜特征分辨率提升(如 128×128)导致计算量激增。
-
因此,论文提出 TVT 策略:在不从头训练 SD 模型的前提下,将 VAE-D8 迁移为 VAE-D4,同时保持与预训练 UNet 的兼容性,并通过高效网络设计控制计算成本。
迁移 VAE 训练(Transfer VAE Training, TVT)
TVT 的核心是通过两阶段训练,让新的 4 倍下采样 VAE(VAE-D4)既保留更多细节,又与原 VAE-D8 的潜空间对齐(确保 UNet 兼容)。具体包括 “紧凑 VAE-D4 设计” 和 “两阶段训练”。
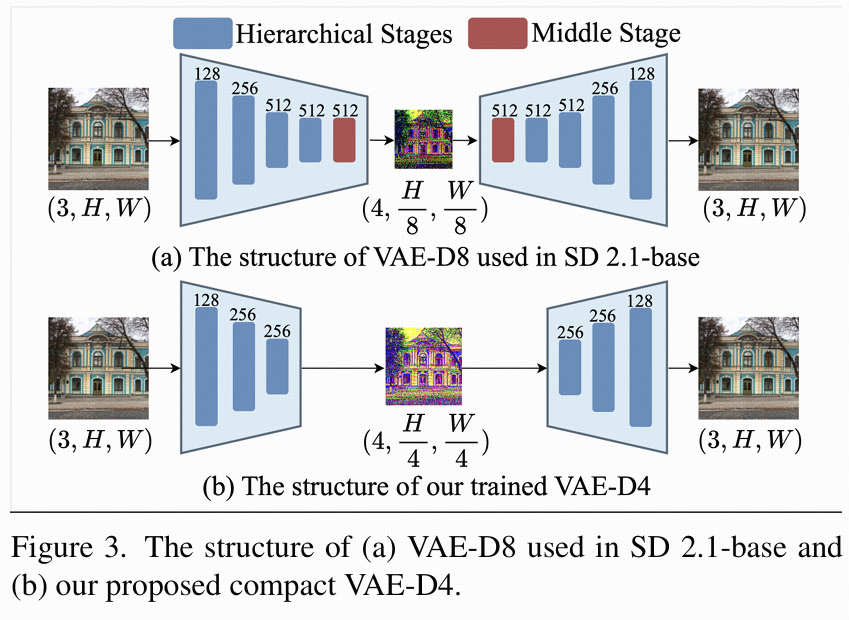
1. VAE-D4 的结构设计
原 VAE-D8 包含 5 个阶段(4 个 ResNet 特征提取阶段 + 1 个带自注意力的中间阶段),通道数为 128→256→512→512,结构复杂且计算量大。 为在提升分辨率的同时降低成本,论文设计了紧凑 VAE-D4(图 3 (b)):
-
减少阶段数:从 5 个阶段缩减为 3 个(移除 1 个层级阶段和中间阶段),降低冗余;
-
压缩通道数:通道数调整为 128→256→256,减少参数和计算量;
-
效果:相比原 VAE-D8,参数减少 81.89%,FLOPs 减少 38.89%,同时保持重建精度。
2. 两阶段训练:对齐潜空间并保留细节
TVT 通过 “先训练解码器,再训练编码器” 的两阶段策略,确保 VAE-D4 的潜空间与 VAE-D8 对齐,同时提升细节重建能力。
阶段 1:训练 VAE-D4 解码器
目标:让 VAE-D4 解码器能从 VAE-D8 的潜特征中重建高质量图像,对齐两者的潜空间。
-
分辨率不匹配问题:VAE-D8 的 8 倍下采样与 VAE-D4 的 4 倍下采样会导致解码后图像分辨率差异(如 VAE-D8 编码 512×512 图像得到 64×64 潜特征,VAE-D4 解码后仅为 256×256,是原图的 1/2)。
-
解决方案:先将输入图像 I 上采样 2 倍得到 I(如 512×512→1024×1024),再用 VAE-D8 编码 I 得到潜特征 Z(1024/8=128×128),最后用 VAE-D4 解码器解码 Z 得到 O(128×4=512×512,与原图 I 尺寸一致)。 D4为 VAE-D4 解码器,E8为 VAE-D8 编码器,↑2为 2 倍上采样。

-
损失函数:结合 L1 损失(像素级保真)、LPIPS 损失(感知相似性)和 GAN 损失(生成逼真细节):
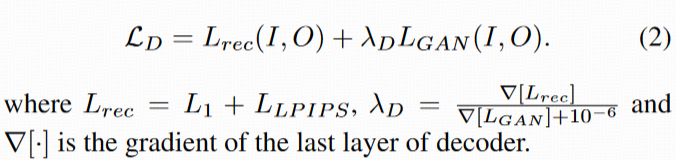
阶段 2:训练 VAE-D4 编码器
目标:让 VAE-D4 编码器生成的潜特征,经过已训练好的解码器后能准确重建原图,确保编码器与解码器匹配。
-
过程:固定阶段 1 训练好的解码器D4,将输入图像 I 通过 VAE-D4 编码器E4得到潜特征z(如 512×512→128×128),再用D4解码z得到 O,优化E4使 O 逼近 I。 公式:O = D4(E4(I))。
-
损失函数:仅用 L1 和 LPIPS 损失(移除 GAN 损失,因实验发现 GAN 会导致训练不稳定):
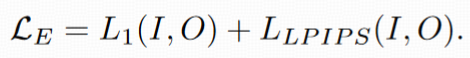 。
。
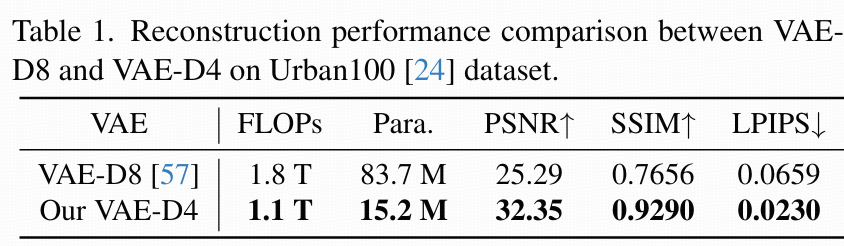
初步验证:VAE-D4 的重建优势
表 1 对比了 VAE-D8 与 VAE-D4 在 Urban100 数据集上的重建指标:
-
VAE-D4 的 PSNR 达 32.35 dB(VAE-D8 仅 25.29 dB),SSIM 达 0.9290(VAE-D8 仅 0.7656),LPIPS 更低(感知相似性更高);
-
视觉上(图 1 (a)),VAE-D4 能清晰保留小文字、纹理,而 VAE-D8 重建结果模糊。
基于 TVT 的 Real-ISR 框架
在 VAE-D4 训练完成后,论文将其与预训练 UNet 结合,构建高效的 Real-ISR 流程,核心包括 “训练框架” 和 “计算高效 UNet 设计”。
1. 训练框架:单步扩散实现超分
流程如图 2 (b) 所示:
-
编码 LR 图像:低分辨率图像I_LR通过 VAE-D4 编码器E4得到潜特征z_LR(如 256×256→64×64);
-
提取文本嵌入:用 DAPE 和 CLIP 文本编码器从I_LR中提取文本嵌入c_t(引导超分过程的语义信息);
-
单步扩散:将z_LR和c_t输入 UNet,通过单步去噪得到高分辨率潜特征
-
解码得到 SR 图像:z_SR通过 VAE-D4 解码器D4得到高分辨率结果I_SR = D4(z_SR)。
损失函数:结合 L1(像素保真)、LPIPS(感知相似性)和 VSD 损失(扩散模型的分数蒸馏损失):

2. 计算高效 UNet:适配高分辨率潜特征
VAE-D4 的潜特征分辨率为 128×128(是 VAE-D8 的 2 倍),直接用原 UNet 处理会导致计算量激增(原 UNet 处理 64×64 需 1.35T FLOPs,处理 128×128 则更高)。 论文提出高效 UNet 设计:
-
复制原 UNet 的首层和末层(紫色块,图 2 (b)),用于处理 128×128 潜特征;
-
原 UNet 层继续处理 64×64 特征,通过下采样(3×3 卷积,步长 2)和上采样(最近邻插值 + 3×3 卷积)实现分辨率转换;
-
保留跳跃连接:将编码器的 128×128 特征与解码器对应层连接,避免信息丢失;
-
微调策略:仅复制的首尾层进行全参数微调,原 UNet 层用 LoRA 微调(保留预训练扩散先验)。
-
效果:高效 UNet 的 FLOPs 仅 0.73T,相比直接处理 128×128 特征的原 UNet(1.35T)减少 51%,大幅降低计算成本。
Experiment
实验设置为方法的验证提供了基础,包括数据、对比方法、评估指标和实现细节,确保结果的可靠性和可比性。
训练与测试数据集
-
训练数据:
-
VAE 训练:使用 OpenImage 数据集和 LSDIR 数据集中 144 万张 512×512 高质量图像块(确保 VAE 能学习通用图像特征)。
-
Real-ISR 任务:采用 LSDIR 数据集和 FFHQ 前 10K 张人脸图像,通过 Real-ESRGAN 退化管道生成 LR-HR 对(模拟真实世界退化)。
-
文本超分(STISR)任务:使用 RealCE 数据集(含 1935 对训练、261 对测试的文本图像,包含中英文字符,专门用于验证文本细节重建能力)。
-
-
测试数据:
-
Real-ISR:DIV2K-val(通过 Real-ESRGAN 生成的退化对)、RealSR 和 DRealSR(真实世界 LR-HR 对,验证对真实退化的处理能力)。
-
STISR:RealCE 测试集(验证文本细节重建)。
-
对比方法
-
Real-ISR:对比当前主流 SD-based 方法,包括多步扩散(StableSR、PASD、DiffBIR、SeeSR)和单步扩散(OSEDiff、S3Diff)。
-
STISR:对比文本专用方法(如文本先验网络)、扩散基方法、SD-based 方法(如 OSEDiff、PASD,其中 PASD 和 OSEDiff 在 RealCE 上重新训练以保证公平性)。
评估指标
-
Real-ISR:
-
有参考指标(与 HR 图像对比):PSNR(峰值信噪比,衡量像素保真度)、SSIM(结构相似性,衡量结构一致性)、FSIM(特征相似性)、LPIPS(感知距离,衡量视觉感知差异)、DISTS(深度图像相似度)、AFINE-FR(A-FINE 模型的保真度分数)。
-
无参考指标(无需 HR 图像,衡量视觉自然度):CLIPIQA、MUSIQ、Q-Align、TOPIQ、HyperIQA、AFINE-NR(A-FINE 模型的自然度分数)。
-
-
STISR:除 PSNR、SSIM、LPIPS 外,增加字符识别准确率(ACC) 和归一化编辑距离(NED)(直接衡量文本结构的可识别性)。
实现细节
-
VAE-D4 训练:batch size=256,迭代 2×10⁵次,使用 8 张 A100 GPU。
-
Real-ISR/STISR 训练:基于 SD 2.1-base 预训练模型,学习率 5×10⁻⁵,batch size=16,AdamW 优化器,LoRA 秩 = 4;Real-ISR 迭代 2×10⁴次(4 张 A100),STISR 迭代 1×10⁴次。
4.2 与最先进方法的对比(Comparison with State-of-the-Arts)
通过定量、定性和复杂度分析,验证 TVT 在精细结构保留和效率上的优势。
定量对比
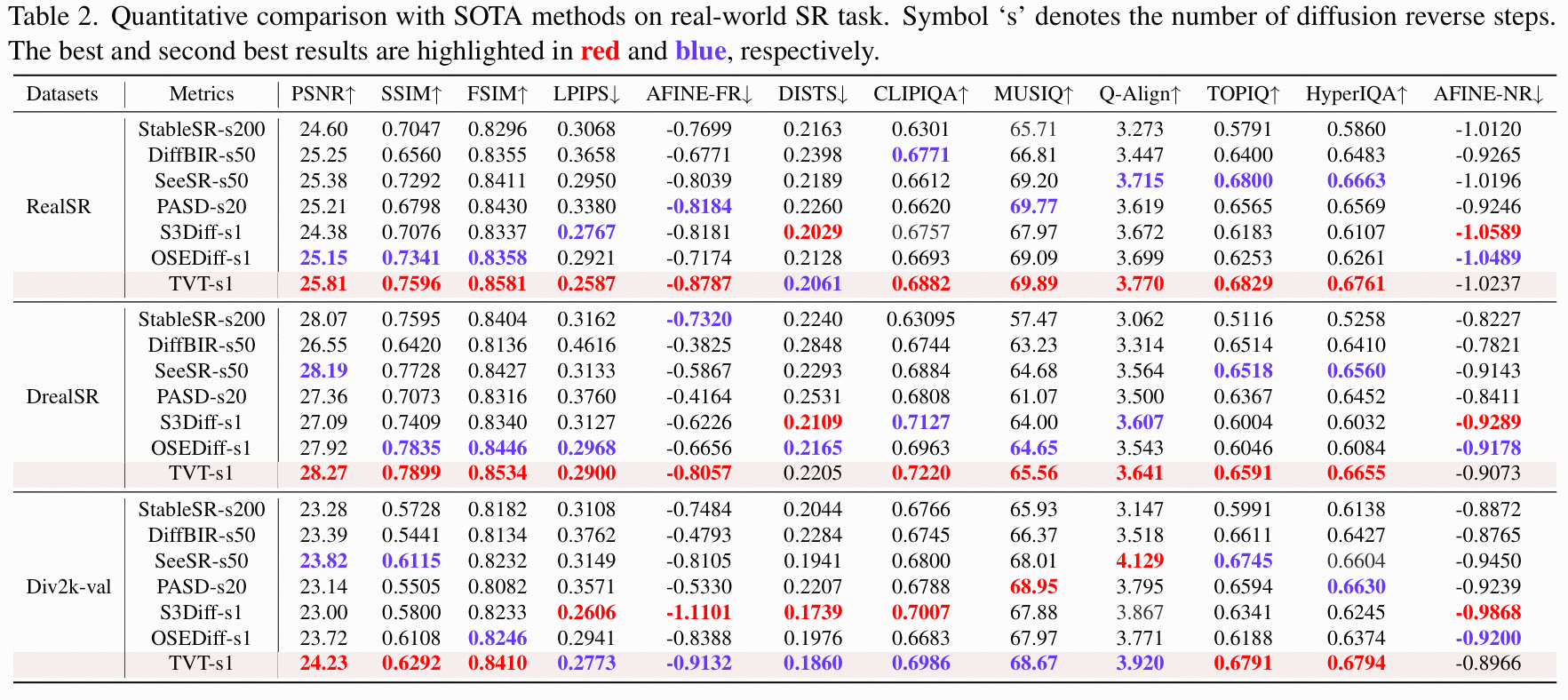
-
Real-ISR(表 2):
TVT 在所有数据集上的指标全面领先:-
有参考指标:PSNR、SSIM、FSIM 均为最高(如 RealSR 上,TVT 的 PSNR=25.81 dB,高于 S3Diff 的 24.38 dB 和 OSEDiff 的 25.15 dB),LPIPS、AFINE-FR 等感知指标也为最优或次优,证明其在精细结构保真上的优势。
-
无参考指标:在 CLIPIQA、MUSIQ 等自然度指标上多次取得最优,说明 TVT 在保留细节的同时,生成结果的视觉自然度未受影响(解决了多数方法 “保真与自然度难以兼顾” 的问题)。
-
-
STISR(表 3):
TVT 在 SSIM(0.892)、LPIPS(0.091)上最优,PSNR 次优;更关键的是,字符识别准确率(ACC=89.7%)和 NED(0.042)显著高于其他方法(如 OSEDiff 的 ACC=78.3%),证明其能有效恢复文本结构的可识别性。
定性对比
-
Real-ISR(图 4):
视觉上,TVT 在精细结构(如小文字、纹理)的重建上显著优于对比方法:-
例如,第一幅图像中的 “care” 文字,S3Diff 和 OSEDiff 均无法清晰重建,而 TVT 输出清晰可辨;
-
对比方法(如 SeeSR、PASD)可能生成错误结构(如错误文本、过度增强的伪影),而 TVT 的结果更忠实于原图。
-

-
STISR(图 5):
TVT 恢复的文本(中英文字符)边缘更锐利、结构更完整,而其他方法输出模糊或存在字符变形(如字母缺失、笔画错误)。

复杂度对比(表 4)
尽管 VAE-D4 的潜特征分辨率更高(128×128),但 TVT 通过紧凑 VAE 和高效 UNet 设计,计算成本显著低于对比方法:
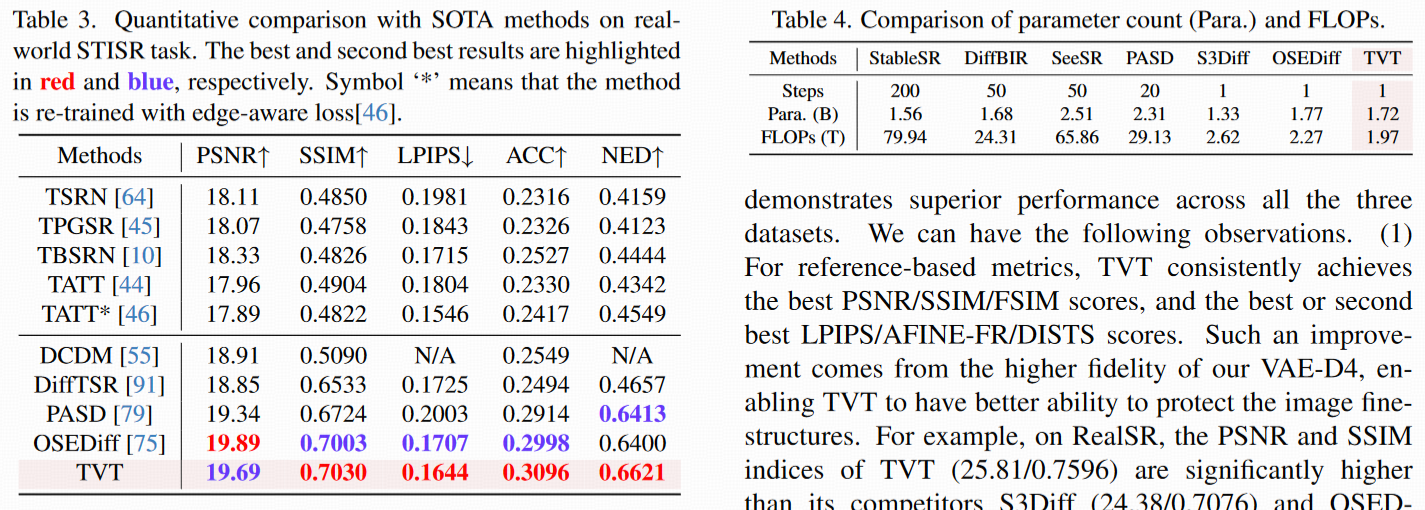
-
FLOPs(1.97T)为所有方法中最低(低于 OSEDiff 的 2.34T、S3Diff 的 3.12T);
-
参数数量(1.72B)少于 OSEDiff,证明其在性能提升的同时兼顾了效率。
4.3 消融实验(Ablation Study)
通过控制变量实验,验证 TVT 核心组件(紧凑 VAE-D4、两阶段训练策略、高效 UNet)的必要性。
紧凑 VAE-D4 的结构设计(表 5)
对比不同 VAE-D4 结构(V1:3 阶段 + 中间块;V2:3 阶段无中间块;TVT 的紧凑设计:3 阶段 + 通道压缩):
-
结果显示,TVT 的紧凑设计(通道 128→256→256)与 V1、V2 性能接近,但 FLOPs 更低(V1:1.23T→TVT:0.73T),证明简化结构的合理性(在不损失性能的前提下降低计算成本)。
TVT 两阶段训练策略的有效性(表 6)
对比三种方案:
-
T1:不使用 TVT,直接从头训练 VAE-D4(潜空间未对齐);
-
T2:用 L1 损失强制 VAE-D4 与 VAE-D8 的潜特征对齐(简单对齐);
-
TVT:两阶段训练(先解码器后编码器,潜空间自适应对齐)。
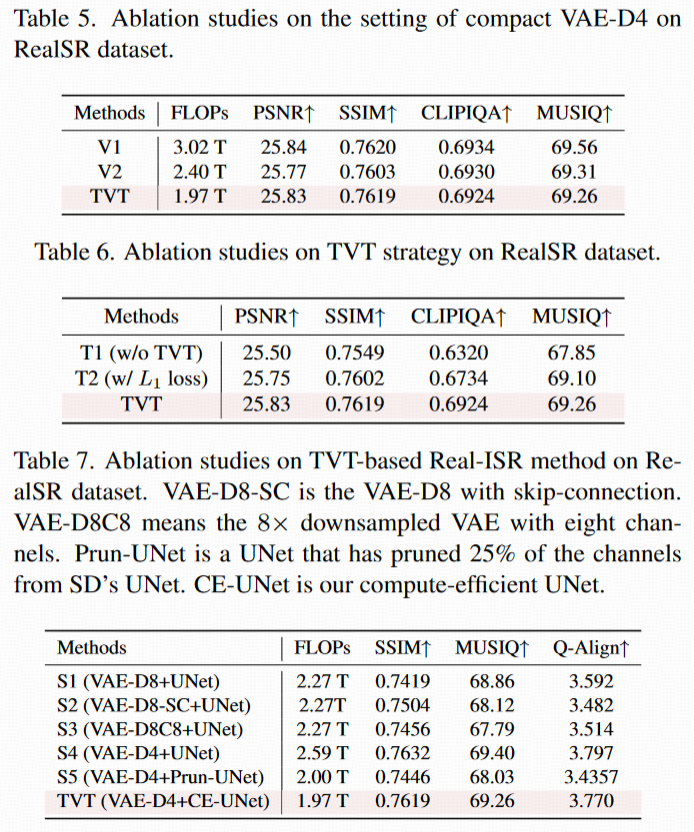
结果:
-
T1 性能最差(PSNR=23.12,SSIM=0.689),证明潜空间未对齐会导致 UNet 的扩散先验无法利用;
-
T2 性能优于 T1 但差于 TVT(PSNR=24.56 vs TVT 的 25.81),说明简单的 L1 损失对齐效果有限,而 TVT 的两阶段策略能更有效对齐潜空间。
TVT-based Real-ISR 框架的组件验证(表 7)
对比六种变体方案,验证 VAE-D4 和高效 UNet(CE-UNet)的作用:
-
S1(VAE-D8 + 原 UNet):基线模型,性能最差(SSIM=0.721);
-
S2(VAE-D8 + 跳跃连接):性能提升微弱(SSIM=0.725),证明仅靠跳跃连接无法弥补 VAE-D8 的信息丢失;
-
S3(VAE-D8+8 通道潜特征):SSIM 提升(0.745)但自然度指标(MUSIQ=67.79)下降,说明增加通道会破坏 UNet 的预训练先验;
-
S4(VAE-D4 + 原 UNet):相比 S1,SSIM(0.741)、MUSIQ(68.28)显著提升,证明 VAE-D4 对性能的关键作用;
-
S5(VAE-D4 + 通道裁剪 UNet):FLOPs 降低但性能下降(SSIM=0.732),而 TVT 的 CE-UNet(S6)在 FLOPs 更低的同时保持 S4 的性能,证明高效 UNet 设计的有效性。
Conclusion & Limitations
结论
TVT 通过两阶段训练策略将 SD 的 VAE-D8 迁移为 VAE-D4,在保持潜空间与预训练 UNet 兼容的同时,显著提升了精细结构保留能力;结合紧凑 VAE 和高效 UNet,实现了性能与效率的双赢,在 Real-ISR 和 STISR 任务上超越现有 SD-based 方法。
局限性
-
资源限制:尽管计算成本已降低,但在资源受限设备(如移动端)上仍需进一步轻量化(更少参数、更低 FLOPs);
-
严重退化场景:当精细结构因退化(如重度模糊、噪声)几乎完全丢失时,TVT 仍难以准确恢复(如图 6 示例,严重模糊的纹理无法重建)。
总结
实验部分通过全面的设置、对比和消融实验,层层验证了 TVT 方法的核心优势:在保留精细结构(尤其是小文本、纹理)的同时,兼顾生成结果的自然度和计算效率,解决了现有 SD-based Real-ISR 方法的关键瓶颈。局限性则为未来研究(如更轻量模型、重度退化恢复)提供了方向。

