PyTorch常用工具
目录
PyTorch可视化工具-Tensorboard教程
summary计算每层参数个数
torch.cuda.synchronize()
Datasets & DataLoaders
模型构建
反向传播
优化
model.train()与model.eval()的作用
PyTorch可视化工具-Tensorboard教程
安装 ubuntu/window 下安装: 在指定的 conda 环境下比如之前教程提到的 mvs 下,在终端输入: 如何调用 模块加载 运行 train.py 后,会在 ./log 文件夹下保存一个文件类似 events.out.tfevents.xxx from torch . utils . tensorboard import SummaryWriter # 实例化 SummaryWriter, 定义 logdir 为 log 即输出路径 writer = SummaryWriter ( \'./log\' ) # 输出图像 writer . add_image # 输出 loss writer . add_scalar # 输出模型结构 writer . add_graph 运行 train.py 后,会在 ./log 文件夹下保存一个文件类似 events.out.tfevents.xxx 如何查看 在终端输入: tensorboard --logdir=./log
summary计算每层参数个数
安装与使用 https://github.com/sksq96/pytorch-summary 输出示例: 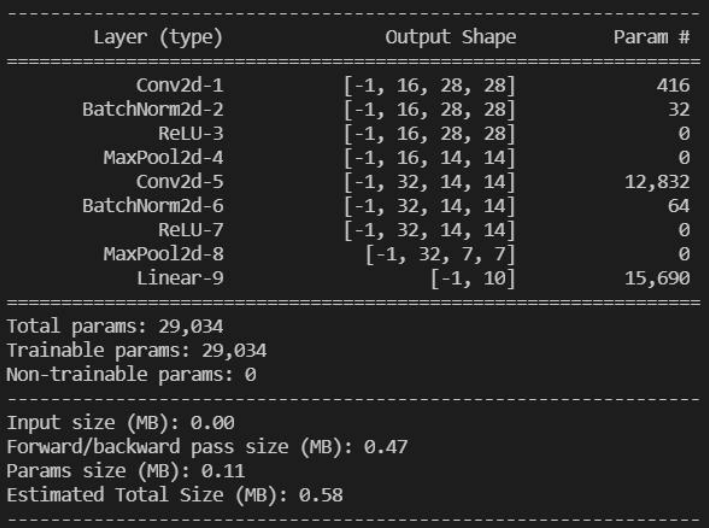 profiler 分析每个操作在 GPU 和 CPU 的时间花销 调用方法: 输出示例
profiler 分析每个操作在 GPU 和 CPU 的时间花销 调用方法: 输出示例
torch.cuda.synchronize()
正确测试代码在 cuda 运行时间,需要加上 torch.cuda.synchronize() ,使用该操作来等待 GPU 全部 执行结束, CPU 才可以读取时间信息。 测试示例
import torchimport torch.nn as nnimport numpy as npimport cv2from model import ConvNetimport timefrom torchsummary import summaryfrom torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter(\'./log1\')device = torch.device(\'cuda:0\' if torch.cuda.is_available() else \'cpu\')#模型加载model=ConvNet(10)state_dict=torch.load(\'model.ckpt\')model.load_state_dict(state_dict)model=model.to(device)model.eval()summary(model, (1, 28, 28))#数据加载with torch.no_grad():image=cv2.imread(\'1.png\',0)image = np.expand_dims(image, 0)writer.add_image(\'image\',image)image = np.expand_dims(image, 0)image=1.0-image.astype(np.float32)/255.0print(image.shape)image_t=torch.from_numpy(image).to(device)with torch.autograd.profiler.profile(enabled=True, use_cuda=True) as prof:torch.cuda.synchronize()start_time = time.perf_counter()outputs = model(image_t)torch.cuda.synchronize()end_time = time.perf_counter()print(\'time=\',end_time - start_time)print(prof)# if prof is not None:# # print(prof)# trace_fn = \'chrome-trace.bin\'# prof.export_chrome_trace(trace_fn)# print(\"chrome trace file is written to: \", trace_fn)#writer.add_image(\'image\',image_t)_, predicted = torch.max(outputs.data, 1)print(predicted.data.cpu().numpy())print(\"test end\")Datasets & DataLoaders
提供两数据加载函数: torch.utils.data.DataLoader 和 torch.utils.data.Dataset 实现数据集代码与模型训练代码分离,以获得更好的可读性和模块化 制作自己的数据集必须要实现三个函数: init 函数在实例化 Dataset 对象时运行一次 len 返回数据集中样本的数量 getitem 函数的作用是 : 从给定索引 idx, 从数据集中加载并返回一个样本并将其转换为张量 __init__ , __len__ , __getitem__
模型构建
神经网络由对数据进行操作的层 / 模块 (layers/modules) 组成。 torch.nn 提供构建网络的所有 blocks, 在 PyTorch 中的每个 modules 都继承了 nn.Module, 可以构建各种复杂的网络结构。 通过 nn.Module 定义神经网络,使用 init 初始化 , 对数据的所有操作都在 forward() 中实现 例:
class NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = nn.Flatten()self.linear_relu_stack = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10),nn.ReLU())def forward(self, x):x = self.flatten(x)logits = self.linear_relu_stack(x)return logits##使用示例#检测是否有GPU可用,若有可以在GPU上训练模型device = \'cuda\' if torch.cuda.is_available() else \'cpu\'print(\'Using {} device\'.format(device))model = NeuralNetwork().to(device)print(model)X = torch.rand(1, 28, 28, device=device)logits = model(X)pred_probab = nn.Softmax(dim=1)(logits)y_pred = pred_probab.argmax(1)print(f\"Predicted class: {y_pred}\")反向传播
在训练神经网络时,最常用的算法是反向传播 (back propagation) 。在该算法中,根据损失函数计 算给定参数的梯度来调整参数 ( 模型权重 ) 。 为了计算这些梯度, PyTorch 有一个内置的微分引擎,叫做 torch.autograd 。它支持任何计算图的 梯度自动计算。 假设一个简单的一层神经网络,输入 x, 输出为 z, 参数是 w 和 b. 在这个网络中, w 和 b 是我们需要 优化的参数。因此,我们需要能够计算关于这些变量的损失函数的梯度。 为了做到这一点,我们设置了这些张量的 requires_grad 性质。在 pytorch 中实现如下
import torchx = torch.ones(5) # input tensory = torch.zeros(3) # expected outputw = torch.randn(5, 3, requires_grad=True)b = torch.randn(3, requires_grad=True)z = torch.matmul(x, w)+b #z=wx+b#交叉熵损失函数loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)#反向传播函数的引用存储在一个张量的grad_fn属性中print(\'Gradient function for z =\',z.grad_fn)print(\'Gradient function for loss =\', loss.grad_fn)#优化器optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)梯度计算,为了优化神经网络中参数的权值,我们需要计算损失函数对参数的导数,可以直接 调用 loss.backward() loss . backward () print ( w . grad ) print ( b . grad ) 禁用梯度计算:默认情况下,所有 requires_grad=True 的张量都跟踪它们的计算历史并支持 梯度计算。但是,在某些情况下,我们并不需要这样做,例如,当我们训练了模型,只是想跑 一下前向测试我们的数据。我们可以通过使用 detach() 或者 torch.no_grad() 块包围计算代码来 禁止梯度计算 :
z = torch.matmul(x, w)+bprint(z.requires_grad)#方法1 使用no_gradwith torch.no_grad():z = torch.matmul(x, w)+bprint(z.requires_grad)#方法2 使用detach()z_det = z.detach()print(z_det.requires_grad)优化
优化是指在每个训练步骤中调整模型参数以减少模型误差的过程。优化算法定义如何执行这个过程 ( 在本例中,我们使用随机梯度下降 ) 。所有优化逻辑都封装在优化器对象中。在这里,我们使用 SGD 优化器 ; 此外, PyTorch 中还有许多不同的优化器,如 adam 和 RMSProp ,它们可以更好地处理 不同类型的模型和数据。 随机梯度下降法( SGD ) 一般指的 mini-batch gradient descent 每一次迭代计算 mini-batch 的梯度,然后对参数进行更新,是最常见的优化方法。 缺点 1 : SGD 容易收敛到局部最优,并且在某些情况下可能被困在鞍点。 缺点 2 :选择合适的 learning rate 比较困难 - 对所有的参数更新使用同样的 learning rate 。对 于稀疏数据或者特征,有时我们可能想更新快一些对于不经常出现的特征,对于常出现的特征 更新慢一些,这时候 SGD 就不太能满足要求了 优化器介绍与对比参考链接 https://ruder.io/optimizing-gradient-descent/ https://blog.csdn.net/weixin_40170902/article/details/80092628 使用示例:
#初始化optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)...#循环loop中:#重置模型参数的梯度。默认是累加,为了防止重复计数,在每次迭代时显式地将它们归零。optimizer.zero_grad()#计算梯度loss.backward()#根据上面计算的梯度,调整参数optimizer.step()模型加载与保存 保存: PyTorch 模型将学习到的参数存储在一个内部状态字典中,称为 state_dict 。使用 torch.save() 保存 加载: torch.load()
#加载model = models.vgg16()model.load_state_dict(torch.load(\'model_weights.pth\'))model.eval()#保存torch.save(model.state_dict(), \'model_weights.pth\')model.train()与model.eval()的作用
model.train() 如果模型中有 BN 层 (Batch Normalization )和 Dropout ,需要在训练时添加 model.train() 。 model.train() 是保证 BN 层能够用到每一批数据的均值和方差。对于 Dropout , model.train() 是随机取一部分网络连接来训练更新参数。 启用 Batch Normalization 和 Dropout model.eval() 不启用 Batch Normalization 和 Dropout 如果模型中有 BN 层 (Batch Normalization )和 Dropout ,在测试时添加 model.eval() 。 model.eval() 是保证 BN 层能够用全部训练数据的均值和方差,即测试过程中要保证 BN 层的均 值和方差不变。对于 Dropout , model.eval() 是利用到了所有网络连接,即不进行随机舍弃神 经元。 eval() 时,框架会自动把 BN 和 Dropout 固定住,不会取平均,而是用训练好的值 . 否则的话, 有输入数据,即使不训练,它也会改变权值

