时序数据库选型指南:为什么 Apache IoTDB 正在成为工业大数据的首选?
👨🎓博主简介
🏅CSDN博客专家
🏅云计算领域优质创作者
🏅华为云开发者社区专家博主
🏅阿里云开发者社区专家博主
💊交流社区:运维交流社区 欢迎大家的加入!
🐋 希望大家多多支持,我们一起进步!😄
🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗
文章目录
-
- 一、Apache IoTDB 是什么?
-
- 1.1 官方地址:
- 1.2 产品介绍
- 1.3 产品体系
- 1.4 TimechoDB 整体架构
- 1.5 产品特性
- 二、Apache IoTDB 的“杀手锏”功能
-
- 2.1 写入:单机千万点/秒,集群线性扩展
- 2.2 存储:TsFile 自研文件格式,10:1 压缩比起步
- 2.3 查询:类 SQL + 200+ 内置函数
- 2.4 工业协议“即插即用”
- 三、Linux 单机部署实战
-
- 3.1 环境准备
- 3.2 下载 & 解压
- 3.3 设置hostname
- 3.4 配置 ConfigNode 与 DataNode
- 3.5 启动服务
- 3.6 验证服务
- 3.7 激活(企业版)
- 3.8 常用运维命令
- 3.9 监控面板(可选)
- 3.10 故障速查
- 四、选型决策树:一张图看懂要不要选 IoTDB
- 五、Apache IoTDB 时序数据库总结
一、Apache IoTDB 是什么?

1.1 官方地址:
下载地址:
Apache IoTDB 官方发行版:https://iotdb.apache.org/zh/Download/企业级服务:
Timecho(天谋科技)官网:https://timecho.comGithub仓库链接
Github仓库链接:https://github.com/apache/iotdb官方部署
安装部署与使用文档:快速上手
1.2 产品介绍
Apache IoTDB 是一款低成本、高性能的物联网原生时序数据库。它可以解决企业组建物联网大数据平台管理时序数据时所遇到的应用场景复杂、数据体量大、采样频率高、数据乱序多、数据处理耗时长、分析需求多样、存储与运维成本高等多种问题。
1.3 产品体系
IoTDB 体系由若干个组件构成,帮助用户高效地管理和分析物联网产生的海量时序数据。

其中:
- 时序数据库(Apache IoTDB):时序数据存储的核心组件,其能够为用户提供高压缩存储能力、丰富时序查询能力、实时流处理能力,同时具备数据的高可用和集群的高扩展性,并在安全层面提供全方位保障。同时 TimechoDB 还为用户提供多种应用工具,方便用户配置和管理系统;多语言API和外部系统应用集成能力,方便用户在 TimechoDB 基础上构建业务应用。
- 时序数据标准文件格式(Apache TsFile):该文件格式是一种专为时序数据设计的存储格式,可以高效地存储和查询海量时序数据。目前 IoTDB、AINode 等模块的底层存储文件均由 Apache TsFile 进行支撑。通过 TsFile,用户可以在采集、管理、应用&分析阶段统一使用相同的文件格式进行数据管理,极大简化了数据采集到分析的整个流程,提高时序数据管理的效率和便捷度。
- 时序模型训推一体化引擎(IoTDB AINode):针对智能分析场景,IoTDB 提供 AINode 时序模型训推一体化引擎,它提供了一套完整的时序数据分析工具,底层为模型训练引擎,支持训练任务与数据管理,与包括机器学习、深度学习等。通过这些工具,用户可以对存储在 IoTDB 中的数据进行深入分析,挖掘出其中的价值。
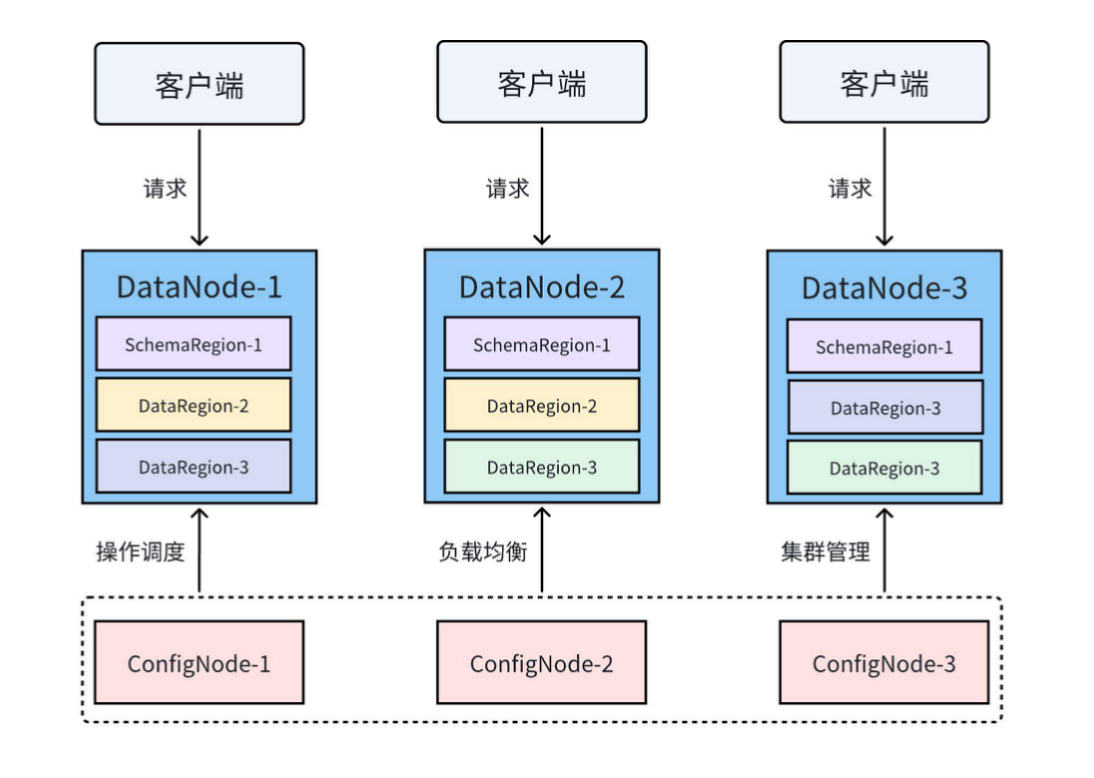
1.4 TimechoDB 整体架构
下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
1.5 产品特性
Apache IoTDB 具备以下优势和特性:
-
灵活的部署方式:支持云端一键部署、终端解压即用、终端-云端无缝连接(数据云端同步工具)
-
低硬件成本的存储解决方案:支持高压缩比的磁盘存储,无需区分历史库与实时库,数据统一管理
-
级化的测点组织管理方式:支持在系统中根据设备实际层级关系进行建模,以实现与工业测点管理结构的对齐,同时支持针对层级结构的目录查看、检索等能力
-
高通量的数据读写:支持百万级设备接入、数据高速读写、乱序/多频采集等复杂工业读写场景
-
丰富的时间序列查询语义:支持时序数据原生计算引擎,支持查询时时间戳对齐,提供近百种内置聚合与时序计算函数,支持面向时序特征分析和AI能力
-
高可用的分布式系统:支持HA分布式架构,系统提供7*24小时不间断的实时数据库服务,一个物理节点宕机或网络故障,不会影响系统的正常运行;支持物理节点的增加、删除或过热,系统会自动进行计算/存储资源的负载均衡处理;支持异构环境,不同类型、不同性能的服务器可以组建集群,系统根据物理机的配置,自动负载均衡
-
极低的使用&运维门槛:支持类 SQL 语言、提供多语言原生二次开发接口、具备控制台等完善的工具体系
-
丰富的生态环境对接:支持Hadoop、Spark等大数据生态系统组件对接,支持Grafana、Thingsboard、DataEase等设备管理和可视化工具
二、Apache IoTDB 的“杀手锏”功能
2.1 写入:单机千万点/秒,集群线性扩展
- 双层 WAL + 内存表 结构,CPU 亲和性调度,单机即可达到 1 500 万点/秒(官方 benchmark,8C32G)。
- Raft 一致性协议,横向扩容只需一条
ADD DATANODESQL,无需重新分片。 - 乱序数据自适应合并:现场时钟漂移、补录历史数据不再“堵管道”。
2.2 存储:TsFile 自研文件格式,10:1 压缩比起步
- 列式+增量编码+二阶差分压缩,浮点数平均压缩率 15:1,文本数据 8:1。
- 时间分区 + 设备分区 双维度索引,冷热数据自动分层,SSD 只放当日热数据。
- 支持 HDFS、S3 作为冷存,打通 Hadoop 生态。
2.3 查询:类 SQL + 200+ 内置函数
SELECT last_value(temperature) FROM root.locomotive.* GROUP BY device一条语句即可完成 万级设备最新值聚合。- 时间对齐插值、异常检测(3-sigma、LOF)函数直接 SQL 调用,无需 Spark 离线作业。
- 毫秒级响应:在中国核电实测,100 TB 数据量,90% 查询 < 300 ms。
2.4 工业协议“即插即用”
- 内置 MQTT、Modbus、OPC-UA、IEC-104 适配器;
- 边缘-中心双活:边缘节点断网本地缓存,恢复后自动同步,带宽占用 < 2%。
三、Linux 单机部署实战
3.1 环境准备
系统调优(root 执行)
# 关闭 swapswapoff -aecho \"vm.swappiness = 0\" >> /etc/sysctl.confsysctl -p# 提升最大文件句柄数echo \"* soft nofile 65535\" >> /etc/security/limits.confecho \"* hard nofile 65535\" >> /etc/security/limits.conf# 临时生效ulimit -n 655353.2 下载 & 解压
# 以 1.3.4 为例,开源版包名:apache-iotdb-1.3.4-all-bin.zipwget -O iotdb.zip https://downloads.apache.org/iotdb/1.3.4/apache-iotdb-1.3.4-all-bin.zipunzip iotdb.zipcd apache-iotdb-1.3.4-all-bin3.3 设置hostname
# 假设本机 IP 为 192.168.1.10echo \"192.168.1.10 iotdb-1\" >> /etc/hosts3.4 配置 ConfigNode 与 DataNode
所有配置文件位于
conf/目录。
编辑 conf/iotdb-system.properties:
# ====== 通用配置 ======cluster_name=standaloneschema_replication_factor=1data_replication_factor=1# ====== ConfigNode ======cn_internal_address=iotdb-1cn_internal_port=10710cn_consensus_port=10720cn_seed_config_node=iotdb-1:10710# ====== DataNode ======dn_rpc_address=0.0.0.0dn_rpc_port=6667dn_internal_address=iotdb-1dn_internal_port=10730dn_mpp_data_exchange_port=10740dn_data_region_consensus_port=10750dn_schema_region_consensus_port=10760dn_seed_config_node=iotdb-1:107103.5 启动服务
# 4.1 启动 ConfigNode./sbin/start-confignode.sh -d# 4.2 启动 DataNode./sbin/start-datanode.sh -d3.6 验证服务
# 进入 CLI./sbin/start-cli.sh -h 127.0.0.1 -p 6667# 执行SHOW CLUSTER;所有节点状态显示 Running 即部署成功。
3.7 激活(企业版)
- 获取机器码
CLI 中执行:SHOW SYSTEM_INFO; - 将返回的机器码发送给 Timecho 商务,获取
license文件。 - 将
license文件放入activation/目录,重启即可。
3.8 常用运维命令
./sbin/stop-standalone.shjps 或 `ps -efrm -rf data/ logs/ (谨慎执行)3.9 监控面板(可选)
- 安装 Prometheus + Grafana
- 导入官方看板 JSON 文件即可查看 150+ 核心指标
- 详细步骤参考官方文档:监控面板部署
3.10 故障速查
cn_internal_address 是否配置为 hostname 且 /etc/hosts 生效lsof -i:6667 / netstat -tunlp至此,单节点 IoTDB 部署完成。
如需要扩容到集群模式,仅需在新增节点重复 3~4 步并修改 dn_seed_config_node 指向已有 ConfigNode 即可。
首次启动后,可通过
conf/iotdb-system.properties调整副本因子、内存等参数,但 cluster_name 等核心参数启动后不可修改。
更多环境部署可参考官网文档: 部署形态
有单机版、集群版、docker版、双活版、kubernetes版、还有监控。
四、选型决策树:一张图看懂要不要选 IoTDB
#mermaid-svg-C9nxcMZZNVDMBhDG {font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-C9nxcMZZNVDMBhDG .error-icon{fill:#552222;}#mermaid-svg-C9nxcMZZNVDMBhDG .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-C9nxcMZZNVDMBhDG .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-C9nxcMZZNVDMBhDG .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-C9nxcMZZNVDMBhDG .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-C9nxcMZZNVDMBhDG .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-C9nxcMZZNVDMBhDG .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-C9nxcMZZNVDMBhDG .marker{fill:#333333;stroke:#333333;}#mermaid-svg-C9nxcMZZNVDMBhDG .marker.cross{stroke:#333333;}#mermaid-svg-C9nxcMZZNVDMBhDG svg{font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-C9nxcMZZNVDMBhDG .label{font-family:\"trebuchet ms\",verdana,arial,sans-serif;color:#333;}#mermaid-svg-C9nxcMZZNVDMBhDG .cluster-label text{fill:#333;}#mermaid-svg-C9nxcMZZNVDMBhDG .cluster-label span{color:#333;}#mermaid-svg-C9nxcMZZNVDMBhDG .label text,#mermaid-svg-C9nxcMZZNVDMBhDG span{fill:#333;color:#333;}#mermaid-svg-C9nxcMZZNVDMBhDG .node rect,#mermaid-svg-C9nxcMZZNVDMBhDG .node circle,#mermaid-svg-C9nxcMZZNVDMBhDG .node ellipse,#mermaid-svg-C9nxcMZZNVDMBhDG .node polygon,#mermaid-svg-C9nxcMZZNVDMBhDG .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-C9nxcMZZNVDMBhDG .node .label{text-align:center;}#mermaid-svg-C9nxcMZZNVDMBhDG .node.clickable{cursor:pointer;}#mermaid-svg-C9nxcMZZNVDMBhDG .arrowheadPath{fill:#333333;}#mermaid-svg-C9nxcMZZNVDMBhDG .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-C9nxcMZZNVDMBhDG .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-C9nxcMZZNVDMBhDG .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-C9nxcMZZNVDMBhDG .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-C9nxcMZZNVDMBhDG .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-C9nxcMZZNVDMBhDG .cluster text{fill:#333;}#mermaid-svg-C9nxcMZZNVDMBhDG .cluster span{color:#333;}#mermaid-svg-C9nxcMZZNVDMBhDG div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-C9nxcMZZNVDMBhDG :root{--mermaid-font-family:\"trebuchet ms\",verdana,arial,sans-serif;} 是 是 是 否 否 否 设备数量 > 1 万? 写入 > 100 万点/秒? 需要国产化合规? 选择 Apache IoTDB 评估海外方案 单机 InfluxDB/TimescaleDB SQLite/MySQL 即可
五、Apache IoTDB 时序数据库总结
Apache IoTDB 是一款专为物联网场景设计的开源时序数据库,以高吞吐写入、高效压缩存储、工业级协议适配为核心优势。其单机写入性能可达千万点/秒,集群支持线性扩展;自研的 TsFile 格式实现 10:1 以上的压缩比,显著降低存储成本。产品提供类 SQL 查询语言与 200+ 内置函数,支持时间对齐、异常检测等时序特征分析,同时内置 MQTT、Modbus 等工业协议适配器,实现边缘-云端无缝协同。
部署上,IoTDB 支持单机、集群及 Kubernetes 等多种模式,并提供企业级服务(TimechoDB)满足国产化需求。典型应用场景包括智能制造、能源监控与车联网等,尤其适合设备规模超1万、高频写入且需国产替代的工业场景。通过开源生态与商业支持的结合,IoTDB 为物联网时序数据管理提供了高性能、低成本的解决方案。


