第二章-AIGC入门-小白也能看懂的AI图像生成指南:从原理到实战(5/36)
摘要:AI图像生成是基于深度学习的人工智能技术,能依据文本或图像输入生成新图像。其原理主要基于生成对抗网络(GAN)和变分自编码器(VAE),通过生成器和判别器的对抗训练(在 GAN 中),或编码器和解码器的协作(在 VAE 中),实现图像生成。AI图像生成在艺术创作、商业设计、影视游戏、日常生活等方面有广泛应用,但也面临伦理、版权、技术准确性等挑战。
一、AI 图像生成是什么
AI 图像生成,作为人工智能技术在数字创作领域的重要应用,正深刻地改变着我们生成和理解图像的方式。简单来说,AI 图像生成是利用人工智能算法,依据给定的输入(如文本描述、图像示例等),通过对大量数据的学习和分析,自动生成全新图像的技术。

从原理上讲,AI 图像生成技术建立在深度学习模型的基础之上,其中最为常用的是生成对抗网络(GAN)和变分自编码器(VAE) 。以生成对抗网络为例,它由生成器和判别器两个部分组成。生成器负责生成图像,判别器则用于判断生成的图像是否真实。两者相互对抗、不断优化,使得生成器最终能够生成逼真且高质量的图像。就像一场激烈的竞赛,生成器努力创造出足以以假乱真的作品,判别器则火眼金睛,力求找出破绽,在这样的博弈过程中,AI 图像生成的水平不断提升。
在当下数字创作领域,AI 图像生成占据着举足轻重的地位。它极大地拓展了创作的边界,为创作者们提供了前所未有的灵感源泉和创作工具。以往,创作一幅精美的图像可能需要艺术家耗费大量的时间和精力,从构思草图到细致描绘,每一个环节都需要深厚的技巧和经验。而现在,借助 AI 图像生成技术,创作者只需输入简单的文字描述,如 “在繁星闪烁的夜空下,一座古老的城堡矗立在静谧的湖边,城堡的倒影在湖水中摇曳”,短短几分钟,AI 就能生成一幅栩栩如生的图像,为创作者提供了丰富的创意参考,激发他们进一步的创作灵感。

AI 图像生成还广泛应用于各个行业。在游戏开发中,它可以快速生成游戏场景、角色和道具,大大缩短开发周期,降低成本;在影视制作中,能够帮助制作特效镜头、概念设计,提升视觉效果;在广告设计领域,为广告创意提供多样化的视觉呈现,增强广告的吸引力。毫不夸张地说,AI 图像生成技术正逐渐渗透到我们生活的方方面面,成为推动数字创作领域发展的重要力量 。
二、AI 图像生成原理剖析

(一)基于规则的图像生成
在 AI 图像生成的早期探索中,基于规则的图像生成方法曾占据重要地位。这种方法主要通过人为定义一系列详细的规则来指导图像的生成过程。例如,L-system(林登迈耶系统)就是一种典型的基于规则的图像生成技术,它最初由匈牙利生物学家 Aristid Lindenmayer 于 1968 年提出 ,旨在模拟植物的生长形态。
以 L-system 生成植物形态为例,其基本原理是利用字符串替换的方式来构建植物的结构。首先,定义一个初始字符串(也称为公理),它代表植物的初始状态。然后,制定一组产生式规则,这些规则描述了如何将字符串中的每个字符替换为其他字符或字符序列。通过不断地迭代应用这些规则,字符串逐渐演变,最终可以转化为描述植物形态的几何图形。
假设有一个简单的 L-system 用于生成类似树枝的结构。初始字符串为 “F”,代表一个基本的线段,即植物的主干。定义产生式规则为 “F -> F [+F] F [-F] F”,其中 “F” 表示向前绘制一个线段,“+” 表示向右旋转一定角度(例如 45 度),“-” 表示向左旋转相同角度,“[” 和 “]” 用于标记分支的开始和结束。在第一次迭代中,将初始字符串 “F” 按照规则替换为 “F [+F] F [-F] F”,这就生成了一个具有两个分支的简单树枝结构。随着迭代次数的增加,树枝结构会变得越来越复杂,呈现出更加逼真的植物生长形态。
然而,基于规则的图像生成方法存在明显的局限性。一方面,这些规则的制定需要人工手动完成,这要求开发者对目标图像的结构和特征有深入的了解,并且能够将其转化为精确的规则,这是一个非常耗时且具有挑战性的任务。另一方面,由于规则是预先设定的,生成的图像往往缺乏灵活性和多样性,很难生成复杂多变、具有高度创新性的图像。一旦需要生成的图像超出了预设规则的范围,就需要重新设计和调整规则,这极大地限制了基于规则的图像生成方法的应用场景。
(二)基于深度学习的图像生成
随着深度学习技术的迅猛发展,基于深度学习的图像生成方法逐渐成为主流,它们以强大的学习能力和生成能力,为图像生成领域带来了革命性的变化。下面将详细介绍两种重要的基于深度学习的图像生成模型:生成对抗网络(GANs)和变分自编码器(VAEs)。
1. 生成对抗网络(GANs)
生成对抗网络(Generative Adversarial Networks,简称 GANs)由 Ian Goodfellow 等人于 2014 年首次提出,其独特的结构和工作原理使其在图像生成领域取得了巨大的成功 。GANs 主要由两个部分组成:生成器(Generator)和判别器(Discriminator),它们就像两个相互竞争的对手,在不断的博弈中共同提升性能。

生成器的主要任务是根据输入的随机噪声向量生成图像。它通过一系列的神经网络层,将低维的随机噪声逐步转换为高维的图像数据。例如,在生成手写数字图像的任务中,生成器接收一个随机的 100 维噪声向量,经过多层反卷积神经网络的处理,最终输出一个 28x28 像素的手写数字图像。生成器的目标是生成尽可能逼真的图像,使其能够骗过判别器。
判别器则扮演着 “鉴别者” 的角色,它的任务是判断输入的图像是来自真实数据集还是由生成器生成的。判别器通常采用卷积神经网络,对输入图像进行特征提取和分析,然后输出一个概率值,表示该图像为真实图像的可能性。如果判别器判断一幅图像是真实的,输出的概率值接近 1;如果判断为生成的图像,概率值则接近 0。判别器的目标是尽可能准确地区分真实图像和生成图像。
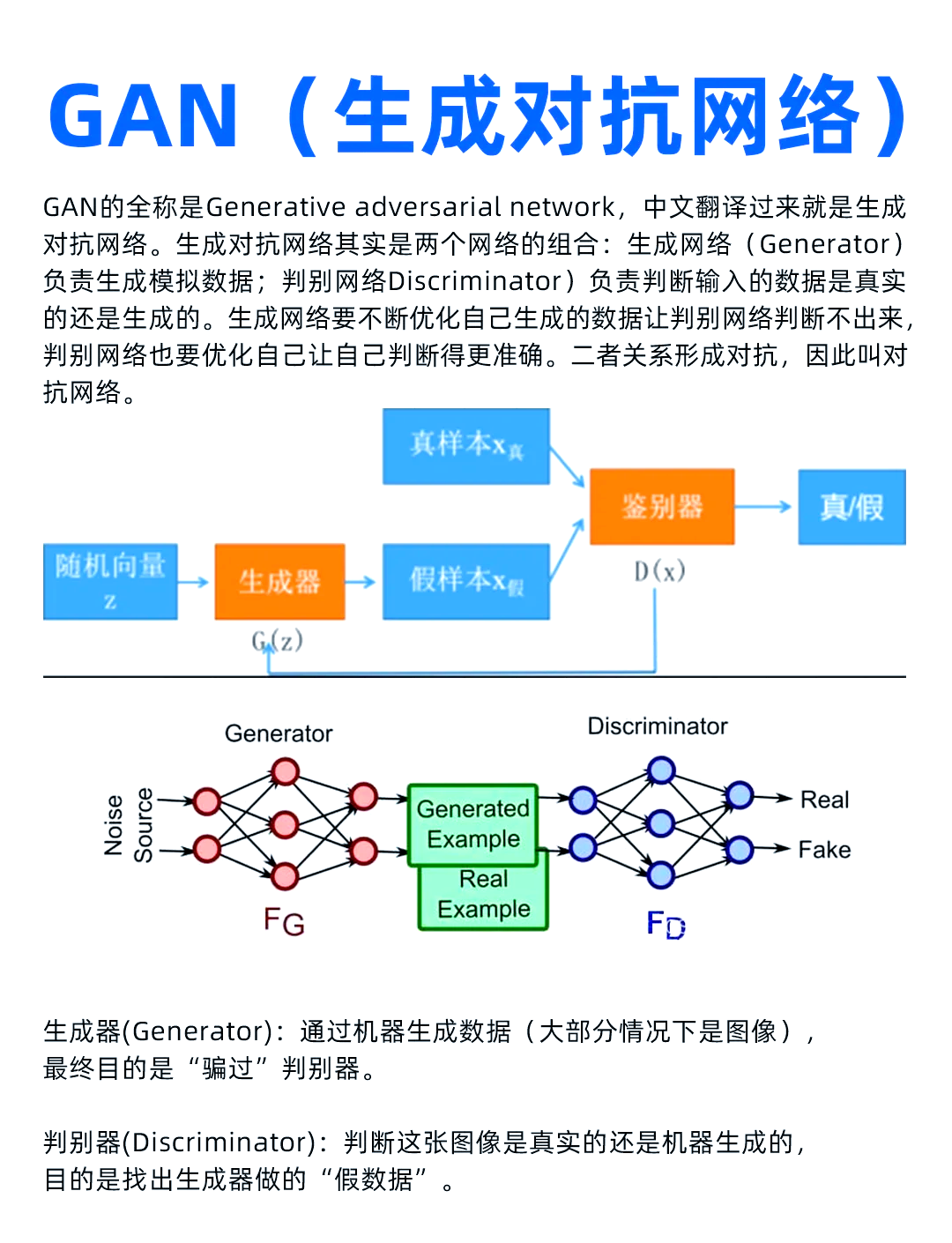
在训练过程中,生成器和判别器进行对抗训练。生成器努力生成更逼真的图像来欺骗判别器,而判别器则不断提高自己的鉴别能力,以准确识别出生成的图像。这个过程可以看作是一场激烈的竞赛,双方在不断的对抗中逐渐优化自己的性能。具体来说,生成器通过调整自身的参数,使得生成的图像能够使判别器的判断产生错误,从而降低生成器的损失函数值;判别器则通过学习真实图像和生成图像的特征差异,调整自身参数,以提高对图像真伪的判断准确率,降低判别器的损失函数值。
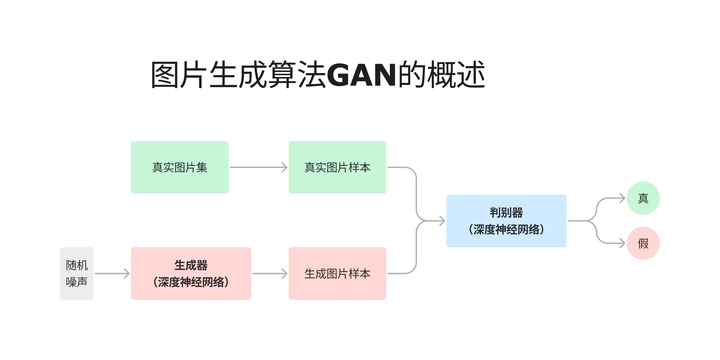
GANs 的训练过程可以用一个极小极大博弈问题来描述。生成器试图最小化判别器正确判断生成图像的概率,而判别器则试图最大化这个概率。通过不断地交替训练生成器和判别器,它们最终可以达到一种动态平衡状态,此时生成器生成的图像已经非常逼真,判别器也难以准确区分真实图像和生成图像。在这种状态下,GANs 就能够生成高质量、逼真的图像,为图像生成领域带来了全新的突破。
2. 变分自编码器(VAEs)
变分自编码器(Variational Autoencoders,简称 VAEs)是另一种重要的基于深度学习的图像生成模型,它在 2013 年被 Diederik P. Kingma 和 Max Welling 提出 。VAEs 的核心思想是将图像编码为低维的潜在向量表示,然后通过解码这个潜在向量来生成新的图像,同时引入了概率分布的概念,使得生成的图像具有一定的可控性和多样性。
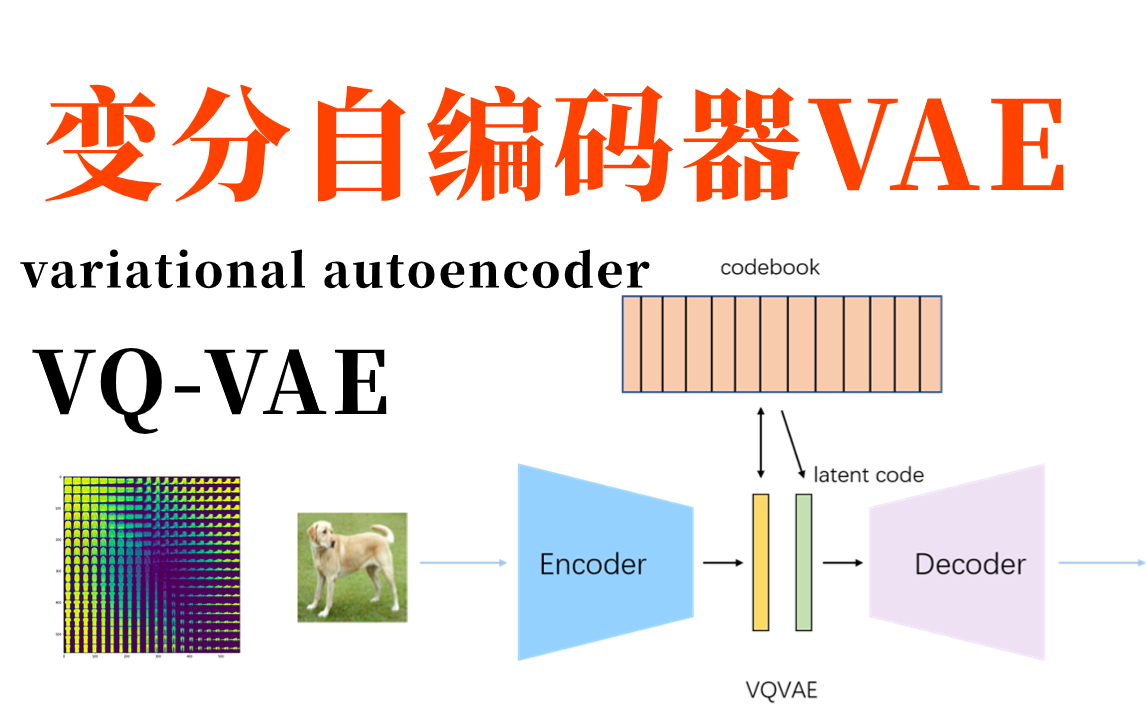
VAEs 主要由编码器(Encoder)和解码器(Decoder)两部分组成。编码器的作用是将输入的图像转换为低维的潜在向量,这个潜在向量可以看作是图像的一种紧凑表示,包含了图像的关键特征信息。例如,对于一张猫的图像,编码器会提取图像中猫的形状、颜色、纹理等特征,并将这些特征压缩成一个低维向量。与传统的自编码器不同,VAEs 中的编码器不仅输出潜在向量,还会计算这个向量的均值和方差,从而定义一个潜在空间中的概率分布。
解码器则负责将潜在向量解码为图像。它从潜在空间中采样一个向量,然后通过一系列的神经网络层,将这个向量逐步转换为高维的图像数据,试图重建出与原始输入图像相似的图像。例如,在生成猫的图像时,解码器会根据采样得到的潜在向量,生成一张具有猫的特征的图像。
VAEs 通过引入变分推断的方法来学习潜在空间中的概率分布。具体来说,它假设潜在空间中的向量服从高斯分布,通过最小化一个包含重构损失和 KL 散度的损失函数来训练模型。重构损失用于衡量解码后的图像与原始输入图像之间的差异,确保生成的图像在视觉上与原始图像相似;KL 散度则用于衡量潜在向量的分布与假设的高斯分布之间的差异,保证潜在空间的连续性和规律性,使得在潜在空间中进行插值等操作时能够生成合理的图像。

通过这种方式,VAEs 实现了对生成图像特征的一定程度的控制。例如,我们可以在潜在空间中对两个不同图像对应的潜在向量进行插值,然后将插值得到的向量解码为图像,这样就可以生成一系列介于这两个图像之间的过渡图像,展示出图像特征的连续变化。VAEs 在图像生成、图像修复、图像压缩等地方都有广泛的应用,为图像生成技术的发展提供了重要的思路和方法。
三、主流 AI 图像生成工具大盘点
(一)Midjourney
Midjourney 是一款备受瞩目的 AI 图像生成工具,在图像生成领域展现出了强大的实力和独特的魅力 。它基于先进的深度学习算法,能够将用户输入的文本描述转化为令人惊叹的高质量图像,其图像生成能力堪称一绝。
当用户输入 “在梦幻的森林中,一只闪闪发光的独角兽正优雅地漫步,周围是飞舞的精灵和绽放的奇异花朵” 这样复杂的描述时,Midjourney 能够精准捕捉到每个细节,生成的图像中,独角兽的毛发细腻逼真,仿佛能感受到其柔软的质感;精灵的翅膀闪烁着微光,姿态灵动;奇异花朵的色彩鲜艳夺目,造型独特,整个画面充满了奇幻的氛围,将用户脑海中的想象完美地呈现出来 。
Midjourney 生成的图像具有独特的艺术风格,融合了多种艺术元素,既可以呈现出写实主义的细腻质感,让图像中的物体栩栩如生,仿佛触手可及;又能展现出超现实主义的梦幻与荒诞,打破现实的束缚,创造出令人意想不到的视觉效果。在生成一幅以 “未来城市” 为主题的图像时,Midjourney 可能会运用大胆的色彩和独特的构图,构建出一个充满科技感的城市景观,高耸入云的摩天大楼、飞驰在空中的汽车、散发着蓝光的能量塔等元素相互交织,营造出一种既陌生又令人向往的未来氛围 。

在使用 Midjourney 时,掌握一些技巧和提示词编写经验能够让生成的图像更加符合预期。在提示词中要尽量使用具体、详细的描述,避免模糊不清的词汇。描述一个人物时,不仅要提及人物的外貌特征,如 “棕色头发、蓝色眼睛、高挺的鼻梁”,还要描述其穿着、姿态以及所处的环境等信息,如 “穿着黑色风衣,双手插兜,站在雨中的街道上”,这样可以为 Midjourney 提供更丰富的信息,生成更具细节和表现力的图像。
合理运用修饰词和限定词也能增强提示词的效果。使用 “柔和的”“强烈的”“朦胧的” 等修饰词来描述光线、色彩或氛围,可以让生成的图像呈现出不同的情感和风格;使用 “在左上角”“位于画面中心”“占据整个背景” 等限定词来指定物体的位置和大小,可以更好地控制图像的构图 。
(二)Stable Diffusion
Stable Diffusion 以其开源特性在 AI 图像生成领域独树一帜,为用户带来了诸多优势和便利。开源意味着其源代码是公开的,这吸引了全球众多开发者参与到项目中,他们可以根据自己的需求对代码进行修改、优化和扩展,从而推动 Stable Diffusion 不断发展和创新。

由于其开源性质,Stable Diffusion 拥有一个庞大而活跃的社区。在这个社区中,开发者们分享自己的经验、技巧和改进方案,用户们也可以交流使用心得、展示生成的作品。社区还会不断发布各种插件和模型,进一步丰富了 Stable Diffusion 的功能和应用场景。用户可以轻松获取到各种风格的模型,如写实、卡通、油画、水彩等,满足不同的创作需求 。

在细节控制和自定义方面,Stable Diffusion 表现出色,尤其适合有一定技术基础的用户。用户可以通过调整各种参数来精确控制图像的生成过程,实现对图像细节的精细调整。在生成人物图像时,用户可以通过调整参数来改变人物的面部表情、发型、服装款式等细节;在生成风景图像时,可以调整天空的颜色、云朵的形状、树木的形态等。这种高度的自定义性使得用户能够根据自己的创意和需求,生成独一无二的图像 。

Stable Diffusion 还支持多种输入方式,除了文本输入外,还可以通过上传图像作为参考,进行图像到图像的生成。用户可以上传一张草图,然后让 Stable Diffusion 根据草图生成更加精细、完整的图像;或者上传一张照片,通过修改提示词和参数,将照片转换为不同风格的艺术作品,如将写实照片转换为印象派风格的绘画 。
(三)DALL・E 2
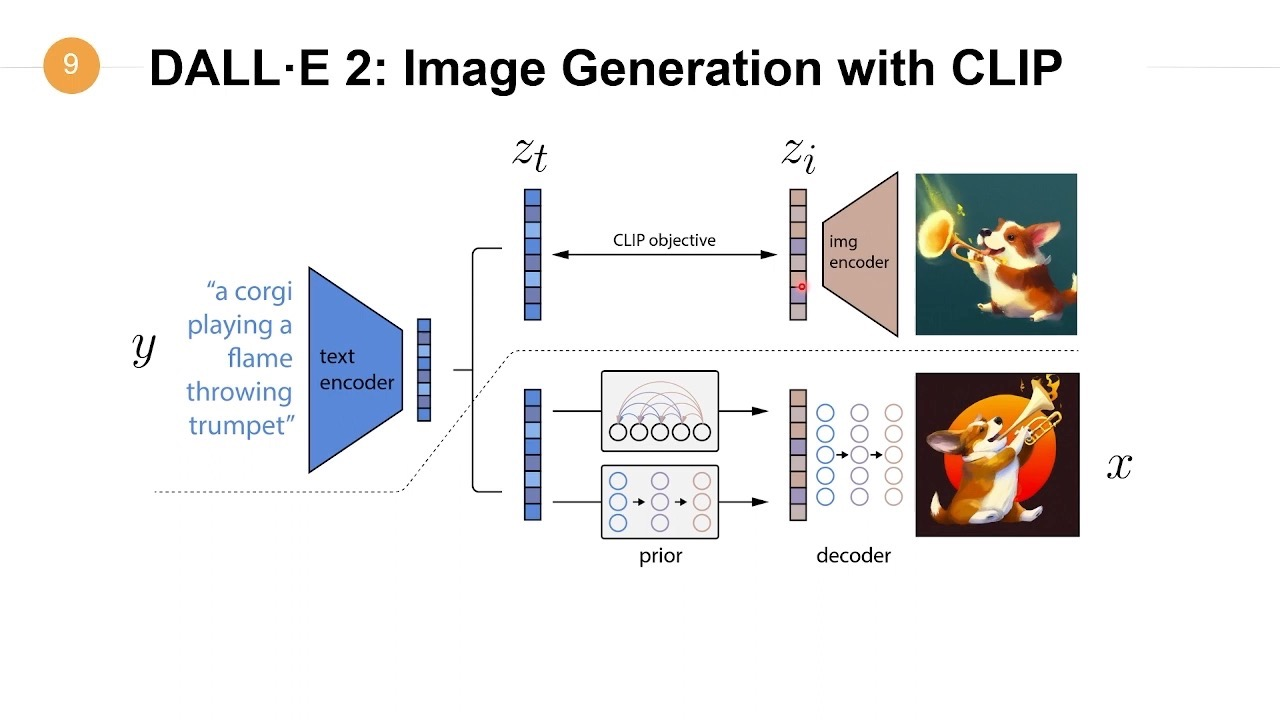
DALL・E 2 是 OpenAI 开发的一款强大的图像生成模型,它在根据文本描述生成高质量图像方面表现卓越,为创意图像生成带来了新的可能性 。DALL・E 2 能够理解文本中的抽象概念,并将其转化为生动、逼真的图像,展现出了惊人的创造力和图像生成能力。
当输入 “一只穿着宇航服的猫咪在月球上弹吉他” 这样充满想象力的文本描述时,DALL・E 2 能够迅速理解其中的关键元素:猫咪、宇航服、月球和吉他,并将这些元素巧妙地组合在一起,生成一幅富有创意的图像。在生成的图像中,猫咪穿着白色的宇航服,头盔上反射出月球表面的光影,它正坐在月球的岩石上,专注地弹奏着一把红色的吉他,身后是浩瀚的宇宙星空,画面充满了奇幻和趣味,让人不禁为 DALL・E 2 的创意生成能力赞叹 。
DALL・E 2 在创意图像生成方面取得了许多令人瞩目的成果,为艺术家、设计师和创作者们提供了丰富的灵感源泉。在艺术创作领域,艺术家可以借助 DALL・E 2 探索新的创意和风格,通过输入各种独特的文本描述,生成前所未有的艺术作品,突破传统创作的局限;在设计领域,设计师可以利用 DALL・E 2 快速生成设计概念图,如产品设计、平面设计、室内设计等,大大提高设计效率,激发更多的设计灵感 。
DALL・E 2 还可以应用于广告、影视、游戏等多个行业。在广告制作中,能够根据广告主题和文案生成具有吸引力的图像,增强广告的视觉效果;在影视和游戏制作中,可以为场景设计、角色设定、特效制作等提供创意参考,帮助制作团队更快地实现创意设想 。
(四)LiblibAI
LiblibAI(哩布哩布AI)是由北京奇点星宇科技有限公司推出的国内领先的AI图像生成平台,以下是对它的具体介绍:
基本简介
-
成立背景与发展历程:LiblibAI于2023年5月正式成立,成立之初即确立“从专业生产端切入”的战略方向,致力于为设计师、画师等创作者提供AI图像生成工具。其核心团队成员主要来自清华大学、北京大学、卡内基梅隆大学等顶尖院校,且曾任职于腾讯、阿里、字节跳动等科技巨头,兼具AI技术、互联网产品与设计产业经验。2024年2-3月,通过国家互联网信息办公室的深度合成服务算法备案,并成为国内首家通过《生成式人工智能服务管理暂行办法》备案的AI社区。2024年7月宣布完成三轮数亿元融资,创下国内AI图像赛道最大融资纪录。2024年末,平台用户突破1000万,汇聚超10万原创AI模型,生成图片超2.3亿张,并推出订阅制会员服务,同步开启国际化布局。
-
核心定位:LiblibAI定位为AI时代的创意生产力工具,是一家专注于AI图像生成与创意内容平台的科技公司,其目标是彻底改变设计师、画师、自媒体创作者的原有创作方式,成为内容创意行业的AI新质生产力。
核心功能
-
AI绘画与图像生成:基于先进的AI技术,LiblibAI能够将用户输入的文本描述快速转化为高质量的图像,用户只需输入简单的文字提示词,如“在繁星闪烁的夜空下,一座古老的城堡矗立在静谧的湖边,城堡的倒影在湖水中摇曳”,LiblibAI就能生成一幅栩栩如生的图像,为创作者提供创意参考和灵感激发。此外,还提供基于图像的图像生成功能,用户可以上传图像进行扩展、风格转换、修复等操作。
-
模型训练与分享:平台构建了国内最大的Lora创作者社区,用户可上传、下载、训练原创AI模型,形成“创作-分享-版权-售卖”的完整生态链。无论是专业设计师还是普通爱好者,都可以在社区中分享自己的模型,交流创作经验,共同探索AI绘画的可能性。
-
在线工作流:LiblibAI提供在线工作流功能,用户无需复杂的部署和安装,即可通过直观的界面进行创作。平台默认安装了许多节点插件,包括多种模型和LoRA等资源,用户可以通过调整工作流节点,如模型、ControlNet、采样器、像素空间等,来实现个性化的创作效果,大大提升了创作的效率和灵活性。
应用场景
-
电商领域:为电商企业提供商品图片生成、设计等服务,帮助商家快速生成高质量的商品主图、海报、详情页等视觉材料,降低运营成本,提高工作效率。
-
设计领域:满足设计师在创意设计、概念探索、设计方案呈现等方面的需求,提供丰富的风格和素材选择,助力设计师实现更加大胆和创新的设计理念,提升设计质量和效率。
-
游戏领域:可用于生成游戏场景、角色、道具等艺术资源,加速游戏开发流程,为游戏创作者提供更多的创意灵感和视觉素材,打造更具吸引力的游戏作品。
-
教育领域:为教育工作者和学习者提供生动形象的教学素材生成服务,如历史场景再现、科学概念可视化、艺术创作教学示范等,使教学过程更加有趣、直观和富有启发性。
优势与特色
-
技术实力强:凭借顶尖团队的技术积累和创新,LiblibAI在图像生成的质量、细节、创意等方面都处于行业领先水平。采用先进的AI算法和架构,能够快速准确地理解和响应用户的创作需求,生成具有高度艺术性和真实感的图像。
-
模型生态丰富:平台拥有海量的原创AI模型资源,涵盖了各种不同的风格和主题,包括摄影、写实、动漫、游戏、科幻、插画、平面设计、建筑、工业设计、时尚服装等不同风格和领域,为用户提供了丰富的创作选择和灵感来源。
-
用户体验好:注重用户体验,提供简洁易用的界面和操作流程,无论是专业创作者还是初学者都能快速上手,轻松进行AI绘画创作。同时,平台还提供了丰富的教程、示例和社区交流功能,帮助用户不断提升创作技能和水平。
(五)其他工具
除了上述三款主流的 AI 图像生成工具外,还有许多其他优秀的工具,它们各自具有独特的特点,在不同的场景中发挥着重要作用。
Copilot 是微软开发的 AI 伴侣,其图像生成功能完全免费。它采用对话式图像生成方法,AI 会根据用户之前的对话自动建议下一个提示,用户可以随时生成和调整图像,这种交互方式对于刚入门或从未使用过 AI 工具的人来说特别友好 。

Gemini 是谷歌的产品,拥有 “深度语境感知” 功能,能够理解提示中的关系和语境,而不仅仅是关键词,因此能够更好地处理复杂提示,生成高度逼真且精准匹配提示的图像。Gemini 还具备对话式编辑图像的功能,为用户提供了更便捷的图像创作体验 。
DeepAI 参与 AI 竞赛已近十年,其文本转图像生成器广受欢迎。虽然 DeepAI 模型相对简单、老旧,生成的图像在某些方面可能略逊于一些顶级平台,但在质量和准确性方面依然表现出色,能够满足用户的基本图像生成需求 。
Canva 作为知名的平面设计平台,推出的 AI 图像生成功能也毫不逊色。凭借在平面设计领域的深厚功底,Canva 的 AI 能够生成一些高质量的文本转图像作品,不仅可以帮助用户绘制草图、编辑图像,还能通过简单的文本提示从零开始创作设计 。
Leonardo.ai 在全球创作者中备受追捧,它生成的超逼真图像能够精准匹配用户提供的提示,并且拥有丰富的免费套餐,为用户提供了高性价比的图像生成选择 。
通义千问是阿里巴巴旗下的产品,最初是一款聊天机器人,如今已发展成为功能强大的 AI 工具,能够生成图像、视频和代码,进行深度研究、分析图像等,满足各种专业需求,在图像生成领域也展现出了一定的实力 。
四、AI 图像生成的应用场景

(一)艺术创作领域
在艺术创作领域,AI 图像生成技术正掀起一场变革的浪潮,为艺术家们打开了一扇通往全新创作境界的大门。许多先锋艺术家敏锐地捕捉到了这一技术的潜力,将 AI 融入到自己的创作过程中,创作出了一系列令人瞩目的作品。
以美国艺术家马里奥・克林格曼(Mario Klingemann)为例,他长期致力于探索 AI 在艺术创作中的应用 。他利用生成对抗网络(GAN)等 AI 技术,创作出了风格独特、充满奇幻色彩的图像作品。在他的作品中,常常出现超现实的场景和元素,如融合了不同生物特征的奇异生物、悬浮在梦幻城市上空的神秘物体等。这些作品不仅展现了 AI 强大的图像生成能力,也体现了艺术家独特的创意和对未来艺术的探索 。
AI 图像生成技术对艺术创作的影响是多方面的。它打破了传统艺术创作的边界,让艺术家能够突破自身技能和经验的限制,实现更加自由的创作表达。以往,艺术家可能需要花费大量时间和精力去学习绘画技巧、掌握各种绘画工具,才能将自己的创意转化为具体的作品。而现在,借助 AI 图像生成技术,艺术家只需通过简单的文本描述,就能快速生成图像初稿,为创作提供丰富的灵感和参考。
AI 还为艺术创作带来了新的可能性,推动了艺术风格的多元化发展。通过对大量艺术作品的学习和分析,AI 能够模仿各种现有的艺术风格,如梵高的印象派、毕加索的立体派等,甚至能够融合多种风格,创造出全新的艺术风格。艺术家可以利用这一特性,探索不同风格之间的融合与创新,创作出独具个性的作品 。
(二)商业设计方面
在商业设计的广阔领域中,AI 图像生成技术正发挥着日益重要的作用,成为提升效率与激发创意的强大引擎。在广告设计领域,时间就是金钱,快速响应市场需求至关重要。以往,设计师为了制作一个广告海报,可能需要从构思创意、寻找素材、设计排版到反复修改,耗费大量的时间和精力。而现在,借助 AI 图像生成工具,设计师只需输入简单的文本描述,如 “夏日清爽饮料广告,画面中要有阳光、沙滩和冰镇饮料”,AI 就能在短时间内生成多个创意海报,为设计师提供丰富的灵感和选择 。
在产品包装设计方面,AI 同样大显身手。它能够根据产品的特点、目标受众和品牌定位,快速生成多种包装设计方案。设计师可以在此基础上进行优化和完善,大大缩短了设计周期,提高了产品上市的速度。AI 还能通过分析市场数据和消费者喜好,预测哪种包装设计更具吸引力,为设计决策提供有力支持 。
对于 UI 设计而言,AI 图像生成技术也带来了诸多便利。它可以帮助设计师快速生成界面布局、图标设计和交互元素,提高设计的一致性和规范性。AI 还能根据用户的行为数据和反馈,自动优化界面设计,提升用户体验 。
(三)影视游戏行业
在影视游戏行业,AI 图像生成技术已成为推动行业发展的重要力量,为影视特效制作、游戏场景和角色设计带来了前所未有的变革。在影视特效制作中,AI 技术的应用大大提高了制作效率和视觉效果。以往,制作一个复杂的特效镜头,可能需要特效师花费数周甚至数月的时间,通过手工绘制、建模、渲染等多个环节才能完成。而现在,借助 AI 图像生成技术,特效师可以通过简单的文本描述或草图,快速生成高质量的特效镜头,如逼真的外星生物、宏大的战争场景、震撼的自然灾害等 。
AI 还能实现实时渲染,让导演和特效师在拍摄现场就能实时看到特效效果,及时进行调整和优化,大大缩短了制作周期,提高了制作效率 。在电影《阿丽塔:战斗天使》中,主角阿丽塔的面部表情和动作捕捉就是通过 AI 技术实现的,使得角色形象更加生动逼真,为观众带来了震撼的视觉体验 。
在游戏开发中,AI 图像生成技术同样发挥着重要作用。它可以快速生成游戏场景、角色和道具,为游戏开发节省大量的时间和成本。通过 AI 技术,游戏开发者可以根据游戏的主题和风格,生成各种独特的游戏场景,如神秘的古代遗迹、未来感十足的科幻城市、充满奇幻色彩的魔法森林等,为玩家带来丰富多样的游戏体验 。
AI 还能根据玩家的行为数据和喜好,生成个性化的游戏内容,如定制化的角色形象、独特的游戏关卡等,提升玩家的参与度和沉浸感 。在一些开放世界游戏中,AI 可以实时生成动态的游戏场景和任务,让游戏世界更加真实和丰富 。
(四)日常生活应用
在日常生活中,AI 图像生成技术也为我们带来了诸多便利和乐趣,成为我们记录生活、表达创意的得力助手。在社交媒体配图方面,AI 图像生成技术让我们能够轻松制作出独具个性的配图,为我们的社交分享增添光彩。以往,我们可能需要花费大量时间在网上搜索合适的图片,或者使用专业的图像处理软件进行编辑,但效果往往不尽如人意。而现在,借助 AI 图像生成工具,我们只需输入简单的描述,如 “一张充满活力的运动场景配图,有奔跑的运动员和欢呼的观众”,AI 就能快速生成符合要求的配图,让我们的社交媒体动态更加吸引人 。
在个人照片处理方面,AI 图像生成技术也展现出了强大的功能。它可以帮助我们修复老旧照片,去除照片中的瑕疵和划痕,让珍贵的回忆更加清晰。AI 还能为照片添加各种艺术风格,如复古风、油画风、卡通风等,让我们的照片瞬间变得艺术感十足。我们可以将自己的照片转化为梵高风格的油画,或者制作成可爱的卡通形象,为生活增添更多乐趣 。
AI 图像生成技术还可以应用于个性化壁纸制作、头像设计等方面,满足我们对个性化和创意的追求 。我们可以根据自己的喜好和心情,生成独一无二的手机壁纸或头像,展现自己的个性风采 。

五、经典代码案例
案例一:基于 Keras 的简单 GAN 生成手写数字(MNIST)
Python
from keras.models import Sequentialfrom keras.layers import Dense, Reshape, Flatten, Conv2D, Conv2DTransposefrom keras.optimizers import Adam# 生成器定义generator = Sequential()generator.add(Dense(128*7*7, activation=\'relu\', input_dim=100))generator.add(Reshape((7, 7, 128)))generator.add(Conv2DTranspose(64, kernel_size=3, strides=2, padding=\'same\', activation=\'relu\'))generator.add(Conv2DTranspose(1, kernel_size=3, strides=2, padding=\'same\', activation=\'tanh\'))# 判别器定义discriminator = Sequential()discriminator.add(Conv2D(64, kernel_size=3, strides=2, padding=\'same\', input_shape=(28, 28, 1)))discriminator.add(Flatten())discriminator.add(Dense(1, activation=\'sigmoid\'))# 判别器编译discriminator.compile(loss=\'binary_crossentropy\', optimizer=Adam(), metrics=[\'accuracy\'])# 组合模型gan = Sequential([generator, discriminator])gan.compile(loss=\'binary_crossentropy\', optimizer=Adam())# 训练过程需要加载MNIST数据集,然后对生成器和判别器进行交替训练,逐步提升图像生成质量。解释:该案例展示了一个基础的 GAN 架构,用于生成 MNIST 数据集中的手写数字图像。生成器将输入的噪声向量转换为图像,判别器判断图像真伪。通过对抗训练,生成器逐渐学会生成更逼真的数字图像。
案例二:基于 PyTorch 的简单 VAE 生成手写数字(MNIST)
Python
import torchimport torch.nn as nnimport torch.optim as optimclass VAE(nn.Module): def __init__(self): super(VAE, self).__init__() # 编码器 self.encoder = nn.Sequential( nn.Linear(784, 400), nn.ReLU(), nn.Linear(400, 20*2) # 输出均值和方差 ) # 解码器 self.decoder = nn.Sequential( nn.Linear(20, 400), nn.ReLU(), nn.Linear(400, 784), nn.Sigmoid() ) def reparameterize(self, mu, logvar): std = torch.exp(0.5*logvar) eps = torch.randn_like(std) return mu + eps*std def forward(self, x): h = self.encoder(x.view(-1, 784)) mu, logvar = h.chunk(2, dim=1) z = self.reparameterize(mu, logvar) return self.decoder(z), mu, logvar# 初始化和训练model = VAE()optimizer = optim.Adam(model.parameters(), lr=1e-3)# 训练循环中需要计算重构损失和KL散度损失,通过优化器更新参数,使模型学会生成与原始手写数字相似的图像。解释:本案例实现了一个基本的 VAE 模型用于生成手写数字。编码器将图像编码为均值和方差向量,通过重参数化技巧采样潜在向量,解码器再将其解码为图像。训练中通过重构损失和 KL 散度优化模型,使生成图像接近原始图像且潜在空间具有规律性。
案例三:使用 TensorFlow Hub 的预训练模型进行图像到图像生成(将草图转换为彩色图像)
Python
import tensorflow as tfimport tensorflow_hub as hub# 加载预训练的图像到图像生成模型(如 cyclegan)model = hub.load(\'https://tfhub.dev/tensorflow/cyclegan/1\')# 假设 input_sketch 是一张草图图像(预处理后的张量形式,如归一化到 [0,1] 范围)# 将草图转换为彩色图像generated_image = model(input_sketch, training=False)# 可视化生成的图像import matplotlib.pyplot as pltplt.imshow(generated_image[0])plt.show()解释:此案例利用 TensorFlow Hub 上预训练的图像到图像生成模型(如 cyclegan),将草图图像转换为彩色图像。预训练模型学习了草图与彩色图像之间的映射关系,输入草图后能够生成对应的彩色图像,展示了图像到图像生成的应用。
六、AI 图像生成的未来展望

AI 图像生成技术在未来有望实现与其他前沿技术的深度融合,开辟出更为广阔的应用天地。与虚拟现实(VR)和增强现实(AR)技术的融合,将为用户打造出沉浸式的交互体验。在 VR 游戏中,AI 图像生成技术能够根据玩家的实时动作和场景变化,实时生成逼真的游戏画面,使玩家仿佛身临其境;在 AR 购物应用中,用户可以通过手机摄像头,利用 AI 生成的虚拟商品图像,直观地看到商品在家中的摆放效果,增强购物的趣味性和决策的准确性 。
随着物联网技术的不断发展,AI 图像生成技术还可能与物联网设备相结合,实现智能化的图像感知与生成。智能家居设备可以根据用户的生活习惯和环境数据,生成个性化的图像内容,如根据天气情况生成相应的室内装饰图像,为用户营造出舒适的居住氛围 。
AI 图像生成技术也面临着一系列严峻的挑战和问题。从伦理道德层面来看,AI 生成的虚假图像可能被恶意利用,用于制造假新闻、进行诈骗等不良行为,这将对社会的信息安全和公众信任造成严重威胁。一些别有用心的人可能利用 AI 图像生成技术制造虚假的名人丑闻照片,或者伪造重要事件的现场照片,误导公众舆论,破坏社会稳定 。
从法律角度而言,AI 生成图像的版权归属问题尚存在争议。由于 AI 生成图像是通过算法和数据训练产生的,其版权归属难以简单地按照传统的版权规则来确定。如果 AI 生成的图像侵犯了他人的知识产权,责任该如何界定,也是亟待解决的问题 。
在技术层面,AI 图像生成技术的准确性和可靠性仍有待进一步提高。有时,AI 生成的图像可能会出现细节错误、逻辑不合理等问题,影响其实际应用效果。在生成人物图像时,可能会出现面部特征不自然、肢体比例不协调等情况 。
为了应对这些挑战,我们需要加强伦理道德教育,提高公众对 AI 图像生成技术潜在风险的认识;完善相关法律法规,明确 AI 生成图像的版权归属和责任界定;加大技术研发投入,不断提升 AI 图像生成技术的准确性和可靠性,确保这一技术能够健康、可持续地发展 。
七、总结

AI 图像生成作为 AIGC 领域的重要分支,正以其独特的魅力和强大的功能,深刻地改变着我们的创作方式和生活。从深入剖析其原理,到全面盘点主流工具,再到广泛探索丰富的应用场景,我们不难发现,AI 图像生成不仅为创作者们提供了无限的创意空间,也为各个行业的发展注入了新的活力。
尽管 AI 图像生成技术目前还面临着一些挑战,如伦理道德、法律和技术层面的问题,但我们有理由相信,随着技术的不断进步和完善,这些问题终将得到妥善解决。在未来,AI 图像生成有望与更多前沿技术深度融合,为我们带来更加震撼的视觉体验和前所未有的创新应用。
如果你对数字创作充满热情,渴望探索新的创作方式,不妨勇敢地迈出第一步,尝试使用 AI 图像生成工具。也许,在这个充满无限可能的领域里,你将发现自己的无限潜力,创造出令人惊叹的作品。让我们一起期待 AI 图像生成技术在未来绽放出更加绚烂的光彩!

关键字解释
-
AI图像生成:利用人工智能算法,依据输入生成图像的技术。
-
深度学习:机器学习的分支,通过多层神经网络模型学习数据特征。
-
生成对抗网络(GAN):由生成器和判别器组成的模型,通过对抗训练生成逼真图像。
-
变分自编码器(VAE):包含编码器和解码器,引入概率分布生成图像的模型。
-
编码器:将图像编码为潜在向量的网络部分。
-
解码器:将潜在向量解码为图像的网络部分。
-
生成器:在 GAN 中生成图像的网络部分。
-
判别器:在 GAN 中判断图像真伪的网络部分。
-
重参数化技巧:在 VAE 中用于从潜在分布采样的技巧,使模型可训练。
-
图像到图像生成:依据输入图像生成另一张相关图像(如风格转换)的技术。

最后,AI绘画的未来充满无限可能。它不仅为艺术创作带来了新的机遇,也为我们的生活带来了更多的色彩和创意。愿大家创作顺利,愿大家像超级博主一样,在文字的宇宙中自由穿梭,创造出无数的奇迹!

博主还写了本文相关文章,欢迎大家批评指正:
1、Stable Diffusion 本地部署教程
2、详细AI作画算法原理、使用案例、注意事项
3、六个免费的AI制图网站的介绍
4、AI作图免费网站,看看我画的愤怒的小鸟和小姐姐
5、AI绘画入门:探索数字艺术新世界(1/10)
6、AI绘画工具大对决:谁才是你的创意缪斯?(2/10)
7、AI绘画:从灵感到杰作的奇幻之旅(3/10)
8、AI绘画咒语指南:驯服AI,精准出图(4/10)
9、AI画笔,绘就古今艺术星河(5/10)
10、AI绘画:解锁商业设计新宇宙(6/10)
11、AI绘画破茧成蝶:从新手到高手的进阶秘籍(7/10)
12、AI绘画进阶指南:突破参数与模型的次元壁(8/10)
13、AI绘画社区:解锁艺术共创的无限可能(9/10)
14、AI绘画:开启艺术与科技融合的未来之门(10/10)
AI通识课相关文章:
第一章 人工智能概述【共2篇】
第一章-人工智能概述-机器学习基础与应用(1/36)
第一章-人工智能概述-深度学习与AI发展(2/36)
第二章 AIGC入门 【共6篇】
第二章-AIGC入门:打开人工智能生成内容的新世界大门(3/36)
第二章-AIGC入门-文本生成:开启内容创作新纪元(4/36)
第二章-AIGC入门-小白也能看懂的AI图像生成指南:从原理到实战(5/36)


