AI技术解读 | 从GPT到Stable Diffusion,一文搞懂自回归与扩散模型的底层逻辑_自回归和扩散模型
往期文章:
- cursor免费使用方法交流:
cursor免费使用方法交流
欢迎大家关注
自回归模型与扩散模型详解
近年来,人工智能生成内容(AIGC,Artificial Intelligence Generated Content)快速发展,其中“大模型”尤其是语言模型(如GPT-4、Gemini)以及文生图模型(如Stable Diffusion、DALL-E 3)表现尤为突出。大模型主要分为两大类技术路线:
自回归模型(Autoregressive Models):多应用于文本生成,例如GPT系列。
扩散模型(Diffusion Models):多应用于图像生成,例如Stable Diffusion。
本文将详细介绍这两种模型的基本概念、经典方法、数学原理、训练与推理过程,并对比分析二者。内容兼顾科普和专业性。
一、自回归模型
基本概念
科普理解
自回归的核心思想是“根据已有内容一步一步预测后续内容”,类似于我们人类写作文,一字一句逐步写出后面的内容。通俗来说,每个新单词(或者token)都依赖于之前生成的单词。
自回归模型最初用于统计学和时间序列分析,表示当前值取决于之前若干时刻值的线性组合。
AR( p p p)模型定义为:
X t = c + ∑ i = 1 pφ iX t − i+ ε t X_t = c + \\sum_{i=1}^{p} \\varphi_i X_{t-i} + \\varepsilon_t Xt=c+i=1∑pφiXt−i+εt
其中, X t X_t Xt 为时刻 t t t值, c c c为常数项, φ i \\varphi_i φi为系数, ε t \\varepsilon_t εt为随机误差。
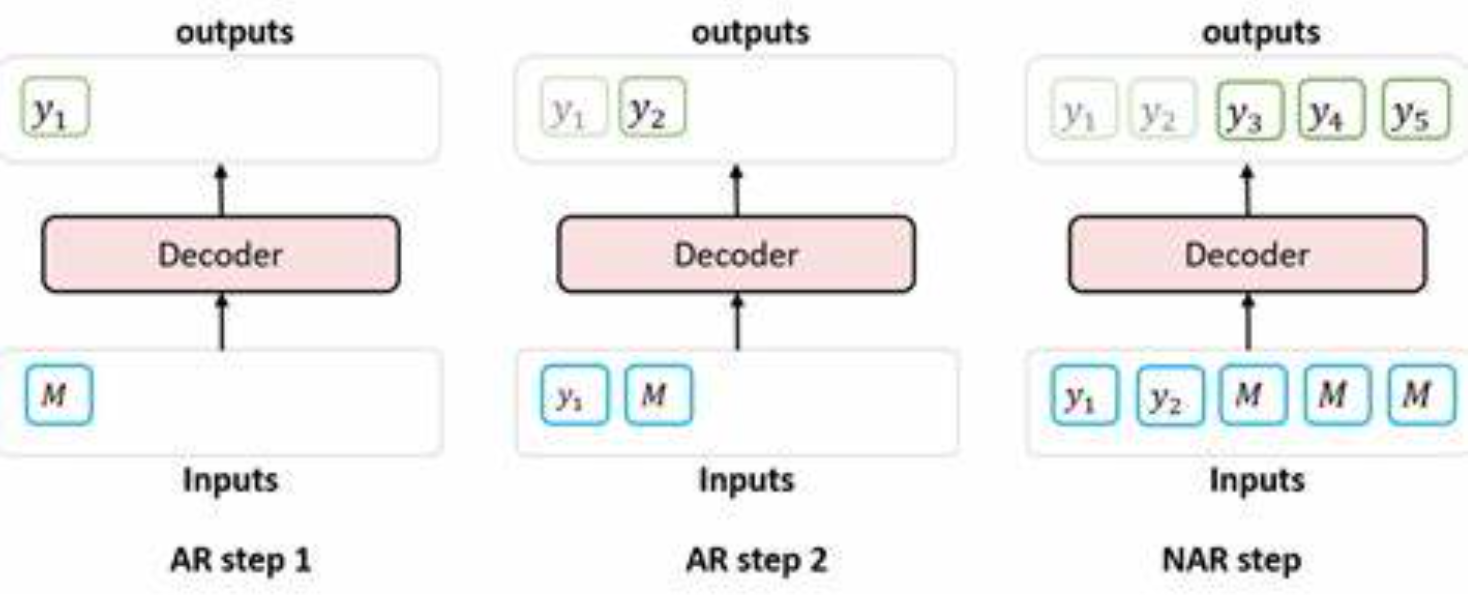
深度学习中的自回归模型
以自然语言处理中的语言模型为例,自回归语言模型定义如下:
p ( x 1 , x 2 , … , x L ) = p ( x 1 ) ⋅ p ( x 2 ∣ x 1 ) ⋯ p ( x L ∣ x 1 , … , x L − 1) p(x_1, x_2, \\dots, x_L) = p(x_1)\\cdot p(x_2 \\mid x_1)\\cdots p(x_L \\mid x_1,\\dots,x_{L-1}) p(x1,x2,…,xL)=p(x1)⋅p(x2∣x1)⋯p(xL∣x1,…,xL−1)
代表模型如 GPT 系列,采用 Transformer 解码器架构。
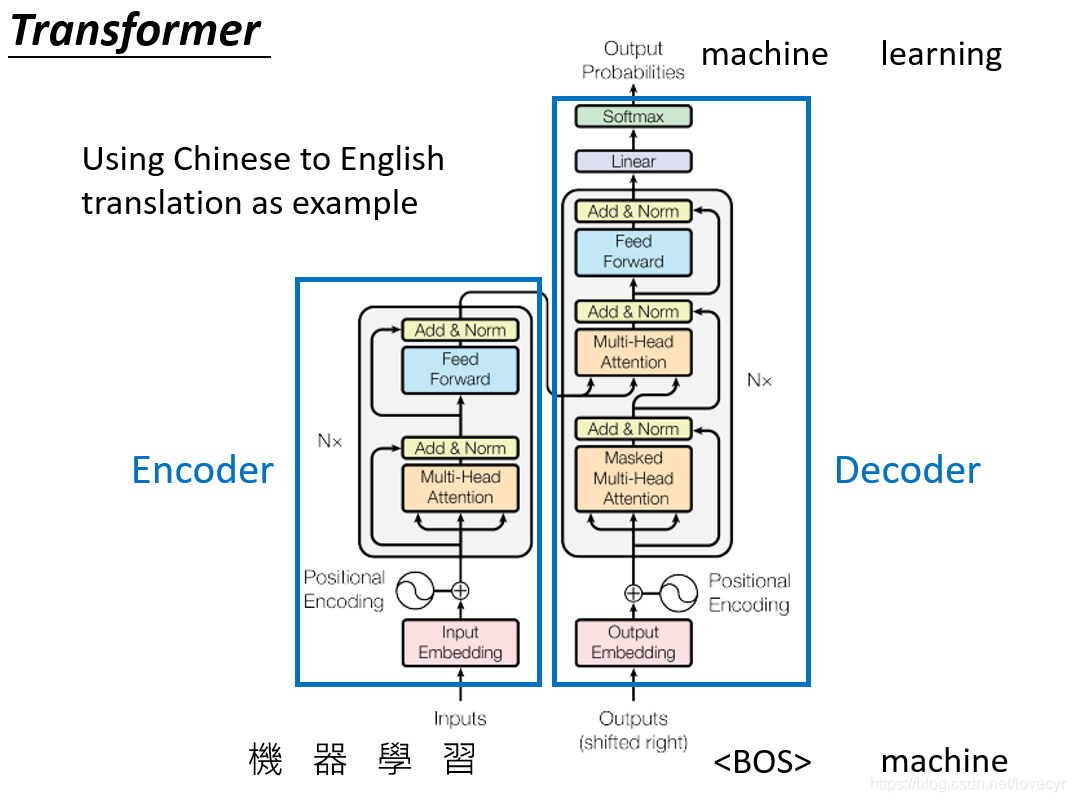
技术原理与结构分析
以 GPT-4 为代表的 Transformer 自回归语言模型核心机制如下:
-
输入预处理:将输入文本转为 token 序列,通过 embedding 映射成向量形式。
-
Transformer 结构:由多层“自注意力机制”构成。
自注意力机制公式定义为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \\text{Attention}(Q,K,V)=\\text{softmax}\\left(\\frac{QK^T}{\\sqrt{d_k}}\\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中:
- Q Q Q(query):当前待处理 token 的查询向量
- K K K(key):上下文 token 的键向量
- V V V(value):上下文 token 的值向量
- d k d_k dk:K的维度,防止内积过大
优化目标为最大化每个位置 token 预测的对数概率:
L = − ∑ t log P ( x t ∣ x < t) L = -\\sum_{t}\\log P(x_t \\mid x_{<t}) L=−t∑logP(xt∣x<t)
- 优点:
- 训练稳定、生成效果连贯、文本逻辑性强。
- 缺点:
- 并行生成速度慢,容易陷入重复生成,难以生成全局连贯的长文本。
训练与推理过程
- 训练阶段:
- 损失函数为所有位置预测的交叉熵之和。
- 推理阶段:
- 给定初始输入逐步预测下一项,直至生成完整输出。
二、扩散模型
基本概念
科普理解
扩散模型灵感源于热力学中的“扩散”过程:初始图像被逐渐加入随机“噪声”,图像逐渐变成纯粹的随机噪声(正向扩散过程)。扩散模型学习的就是如何“反向”去噪,从随机噪声一步步重构出清晰图像。
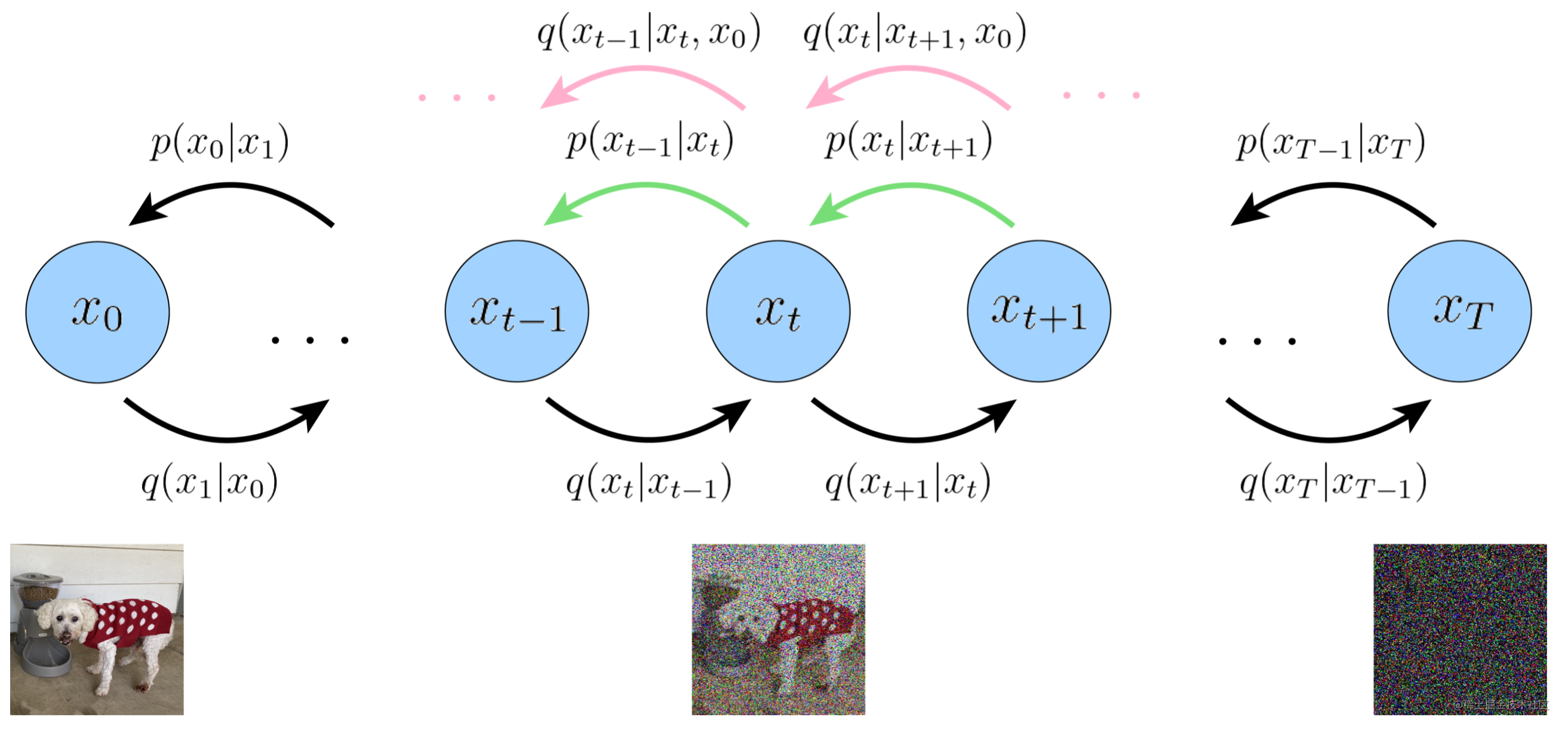
经典扩散模型
DDPM模型前向扩散过程:
q ( x t ∣ x t − 1) = N ( x t ; 1 − β t x t − 1, β t I ) q(x_t|x_{t-1})=\\mathcal{N}(x_t;\\sqrt{1-\\beta_t} x_{t-1},\\beta_t I) q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
一步扩展表示为:
x t = α ˉ t x 0 + 1 − α ˉ t z x_t=\\sqrt{\\bar{\\alpha}_t} x_0 + \\sqrt{1-\\bar{\\alpha}_t} z xt=αˉtx0+1−αˉtz
损失函数为预测添加的噪声 ε \\varepsilon ε的均方误差。
文生图如何实现?
在文生图任务中,扩散模型通常采用以下方式实现:
- 使用文本编码模型(如 CLIP 模型)将输入文本转化为嵌入(embedding)向量;
- 将文本嵌入向量作为条件(输入)提供给 U-Net 去噪网络;
- U-Net 网络逐步去噪,从随机噪声中生成最终的清晰图像。
代表模型包括 DALL·E 2、Stable Diffusion、Imagen 等。
- 优点:
- 生成图像质量高、细节丰富、条件控制灵活。
- 缺点:
- 生成速度较慢,需要较多的采样步骤,计算成本较高。

训练与推理
- 训练阶段:随机抽取 t t t步添加噪声,模型预测原始图像或噪声。
- 推理阶段:从纯噪声开始,逐步去噪直至生成清晰数据。
三、自回归模型 vs 扩散模型对比
四、未来发展趋势
自回归模型
- 更大规模模型,增强上下文理解和规划能力
- 结合知识库和检索功能,提升内容准确性
- 减少曝光偏差,提升长序列生成一致性
扩散模型
- 提高生成效率,降低计算代价
- 提升图像和视频生成质量,拓展到更多模态
- 强化用户交互控制能力
融合与突破
- 自回归模型与扩散模型协同工作,如先自回归后扩散细化
- 融合强化学习实现更强适配人类需求的生成
- 发展多模态统一模型,实现更加通用智能
- 探索全新生成范式,如能量模型、概率流模型
未来可能出现自回归和扩散模型的结合,甚至与强化学习、检索机制融合,形成更为强大的生成模型,推动生成式AI发展。
通过本文对自回归模型与扩散模型的详解与对比分析,希望能够帮助你更深入理解 AI 生成模型的技术本质与未来发展趋势。

