【爬虫】05 - 爬虫攻防
爬虫05 - 爬虫攻防
文章目录
- 爬虫05 - 爬虫攻防
一:随机User-Agent爬虫
1:fake-useragent
当爬虫请求头(User-Agent)暴露规律时,目标网站的反爬系统会在5秒内识别并封锁IP。2023年AlexTop百万网站统计显示,68.7%的反爬策略会检测User-Agent特征。
pip install fake-useragent --upgrade # 添加upgrade是为了防止旧版数据源失效的问题from fake_useragent import UserAgentimport requests# 创建UserAgent对象, 下面将使用ua.random 获取随机的 UserAgentua = UserAgent(browsers=[\'chrome\', \'firefox\', \'edge\'], os=[\'windows\', \'mac\'])header = { \'User-Agent\': ua.random, # 随机获取一个UserAgent \'Accept-Encoding\': \'gzip, deflate, br\', # 告诉服务器,我们接受gzip压缩 \'Accept-Language\': \'zh-CN,zh;q=0.9,en;q=0.8\', # 告诉服务器,我们接受中文 \'Connection\': \'keep-alive\' # 告诉服务器,我们保持连接}requests.get(\'https://www.baidu.com\', headers=header)可以封装设备的一致性
from fake_useragent import UserAgentimport requests# 可以封装设备一致性def generate_user_agent(device_type=\"pc\"): ua = UserAgent() base_headers = { \'Accept-Encoding\': \'gzip, deflate, br\', \'Accept-Language\': \'zh-CN,zh;q=0.9,en;q=0.8\' } if device_type == \'mobile\': return { **base_headers, \'User-Agent\': ua.firefox, # a \'X-Requested-With\': \'com.android.browser\' } else: return { **base_headers, \'User-Agent\': ua.chrome, # b \'Sec-CH-UA-Platform\': \'\"Windows\"\' }for page in range(1, 11): headers = generate_user_agent(\'mobile\' if page % 2 else \'pc\') response = requests.get(f\'https://www.zhipin.com/job_detail/?query=python&city=101010100&industry=&position=\', headers=headers) while True: if response.status_code == 200: print(response.text) break print(\"=\" * 20)2:高级反反爬策略
方案一:动态版本更新(解决版本过时检测)
# 强制使用最新Chrome版本 ua = UserAgent(min_version=120) # Chrome 120+ headers = {\'User-Agent\': ua.chrome} 方案二:混合真实浏览器指纹
# 从真实浏览器捕获指纹注入 real_fingerprint = { \'Sec-CH-UA\': \'\"Chromium\";v=\"118\", \"Google Chrome\";v=\"118\", \"Not=A?Brand\";v=\"8\"\', \'Sec-CH-UA-Mobile\': \'?0\', \'Sec-CH-UA-Platform\': \'\"Windows\"\' } headers = {‌**generate_context_headers(), **‌real_fingerprint} 失败重试熔断机制
from tenacity import retry, stop_after_attempt, wait_exponential @retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1)) def safe_request(url): try: return requests.get(url, headers=generate_context_headers()) except requests.exceptions.RequestException as e: if e.response.status_code == 403: # 触发UA刷新熔断 UserAgent().update() raise safe_request(\'https://target.com/api\') 3:生产环境建议
定时更新UA数据库
# 每天自动更新UA数据库 0 3 * * * /usr/bin/python3 -c \"from fake_useragent import UserAgent; UserAgent().update()\" 可以配置些监控和报警
# 当连续5次403错误时触发警报 if error_count > 5: send_alert(f\"UA策略失效!当前拦截率:{error_count/request_count*100:.2f}%\") switch_to_backup_proxy() 在生产环境中最好使用多库备用
# 当fake_useragent失效时切换至browser_useragent try: from fake_useragent import UserAgent except ImportError: from browswer_useragent import BrowserUserAgent as UserAgent二:代理IP爬虫
当爬虫请求频率超过5次/秒时,目标网站的反爬系统将在10秒内封锁当前IP。据2024年全球反爬技术报告,83%的网站采用IP指纹检测作为核心防御手段
动态代理IP池,结合智能路由与熔断机制实现反爬突围,实测将IP封禁率从72%降至3%
1:获取代理IP
可以使用https://free-proxy-list.net/zh-cn/获取到免费的代理IP
import requestsimport randomfrom bs4 import BeautifulSoup# 获取免费代理 -> https://free-proxy-list.net/zh-cn/def scrape_free_proxies(): url = \"https://free-proxy-list.net/\" # 获取免费的ip代理 response = requests.get(url) soup = BeautifulSoup(response.text, \'html.parser\') proxies = [] # 创建一个空列表, 存储获取到的代理 for row in soup.select(\"table.table tbody tr\"): cols = row.find_all(\'td\') if len(cols) < 7: continue if cols[4].text == \'elite proxy\' and cols[6].text == \'yes\': proxies.append(f\"{cols[0].text}:{cols[1].text}\") return proxies# 请求, 如果失败了就换一个代理IP, 最多尝试5次def do_request(proxy): for i in range(5): print(f\"Trying proxy: {proxy}\") try: response = requests.get(\'http://www.baidu.com\', proxies=proxy) print(response.json()) return except: print(f\"Failed to get IP, trying again...\") proxy = {\'http\': f\'http://{random.choice(proxy_list)}\', \'https\': f\'http://{random.choice(proxy_list)}\'}if __name__ == \'__main__\': proxy_list = scrape_free_proxies() print(proxy_list) # 随机选择代理 current_proxy = {\'http\': f\'http://{random.choice(proxy_list)}\', \'https\': f\'http://{random.choice(proxy_list)}\'} do_request(current_proxy)还可以添加代理IP的智能容错机制
import requestsimport randomfrom bs4 import BeautifulSoupfrom tenacity import retry, stop_after_attempt, wait_fixed# 获取免费代理 -> https://free-proxy-list.net/zh-cn/def scrape_free_proxies(): url = \"https://free-proxy-list.net/\" # 获取免费的ip代理 response = requests.get(url) soup = BeautifulSoup(response.text, \'html.parser\') proxies = [] # 创建一个空列表, 存储获取到的代理 for row in soup.select(\"table.table tbody tr\"): cols = row.find_all(\'td\') if len(cols) < 7: continue if cols[4].text == \'elite proxy\' and cols[6].text == \'yes\': proxies.append(f\"{cols[0].text}:{cols[1].text}\") return proxies# 代理IP的智能容错机制@retry(stop=stop_after_attempt(3), wait=wait_fixed(2))def robust_request(url, proxy_pool): proxy = random.choice(proxy_pool) try: return requests.get(url, proxies={\'http\': f\'http://{proxy}\', \'https\': f\'http://{proxy}\'}, timeout=10) except (requests.ProxyError, requests.ConnectTimeout): proxy_pool.remove(proxy) # 移除失效代理 raiseif __name__ == \'__main__\': proxy_list = scrape_free_proxies() url = \"http://www.baidu.com\" response = robust_request(url, proxy_list) print(response.status_code) print(response.text)2:高阶攻防
四类代理IP的选型
由此演化出对应IP黑名单的三种策略:
策略一:协议混淆,将HTTP流量伪装成Socks5
import socks import socket # 强制使用Socks5协议 socks.set_default_proxy(socks.SOCKS5, \"proxy_ip\", 1080) socket.socket = socks.socksocket # 发送请求(网站识别为普通Socks流量) requests.get(\"https://target.com\") 策略二:IP冷启动:新代理首次访问仅采集低风险页面
策略三:流量染色:在代理请求中注入真实浏览器指纹(如TLS指纹)
3:企业级的代理实战
redis自建代理池系统
import redisimport jsonimport requestsclass ProxyPool: def __init__(self): self.redis = redis.Redis(host=\'127.0.0.1\', port=6379, db=0) def add_proxy(self, proxy:str, score:float=100): self.redis.zadd(\'proxies\', {proxy: score}) def get_best_proxy(self): return self.redis.zrange(\'proxies\', 0, 0)[0].decode() def refresh_proxy(self, proxy:str, penalty:float=20): self.redis.zincrby(\'proxies\', -penalty, proxy)if __name__ == \'__main__\': # 添加代理 pool = ProxyPool() pool.add_proxy(\'127.0.0.1:8080\') pool.add_proxy(\'127.0.0.1:8081\') pool.add_proxy(\'127.0.0.1:8082\') # 获取代理 best_proxy = pool.get_best_proxy() try: # 请求, 如果失败了就换一个代理IP, 最多尝试5次 requests.get(\"https://target.com\", proxies={\'http\': best_proxy}) except Exception: pool.refresh_proxy(best_proxy) 商业代理集成
import hashlib import time def gen_mogu_proxy(): # 生成动态签名 timestamp = str(int(time.time())) secret = \"your_api_secret\" sign = hashlib.md5(f\"timestamp={timestamp}&secret={secret}\".encode()).hexdigest() # 获取独享代理(按需切换IP) api_url = f\"http://piping.mogumiao.com/proxy/api/get_ip?count=1×tamp={timestamp}&sign={sign}\" result = requests.get(api_url).json() return f\"{result[\'msg\'][0][\'ip\']}:{result[\'msg\'][0][\'port\']}\" # 获取高匿名IP mogu_proxy = gen_mogu_proxy() requests.get(\"https://target.com\", proxies={\'http\': f\'http://{mogu_proxy}\'}) 三:动态数据的抓取
当传统爬虫遭遇React/Vue单页应用时,83%的数据请求通过Ajax/WebSocket动态加载,直接获取HTML源码的成功率不足15%。
而如果结合逆向工程与无头浏览器控制技术,构建覆盖SPA(单页应用)、SSR(服务端渲染)、CSR(客户端渲染)的全场景解决方案,实现动态数据抓取成功率从12%到98%的技术跃迁
1:动态页面技术全景
#mermaid-svg-vm9ikb7O0ylTsMaS {font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-vm9ikb7O0ylTsMaS .error-icon{fill:#552222;}#mermaid-svg-vm9ikb7O0ylTsMaS .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-vm9ikb7O0ylTsMaS .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-vm9ikb7O0ylTsMaS .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-vm9ikb7O0ylTsMaS .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-vm9ikb7O0ylTsMaS .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-vm9ikb7O0ylTsMaS .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-vm9ikb7O0ylTsMaS .marker{fill:#333333;stroke:#333333;}#mermaid-svg-vm9ikb7O0ylTsMaS .marker.cross{stroke:#333333;}#mermaid-svg-vm9ikb7O0ylTsMaS svg{font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-vm9ikb7O0ylTsMaS .actor{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;}#mermaid-svg-vm9ikb7O0ylTsMaS text.actor>tspan{fill:black;stroke:none;}#mermaid-svg-vm9ikb7O0ylTsMaS .actor-line{stroke:grey;}#mermaid-svg-vm9ikb7O0ylTsMaS .messageLine0{stroke-width:1.5;stroke-dasharray:none;stroke:#333;}#mermaid-svg-vm9ikb7O0ylTsMaS .messageLine1{stroke-width:1.5;stroke-dasharray:2,2;stroke:#333;}#mermaid-svg-vm9ikb7O0ylTsMaS #arrowhead path{fill:#333;stroke:#333;}#mermaid-svg-vm9ikb7O0ylTsMaS .sequenceNumber{fill:white;}#mermaid-svg-vm9ikb7O0ylTsMaS #sequencenumber{fill:#333;}#mermaid-svg-vm9ikb7O0ylTsMaS #crosshead path{fill:#333;stroke:#333;}#mermaid-svg-vm9ikb7O0ylTsMaS .messageText{fill:#333;stroke:#333;}#mermaid-svg-vm9ikb7O0ylTsMaS .labelBox{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;}#mermaid-svg-vm9ikb7O0ylTsMaS .labelText,#mermaid-svg-vm9ikb7O0ylTsMaS .labelText>tspan{fill:black;stroke:none;}#mermaid-svg-vm9ikb7O0ylTsMaS .loopText,#mermaid-svg-vm9ikb7O0ylTsMaS .loopText>tspan{fill:black;stroke:none;}#mermaid-svg-vm9ikb7O0ylTsMaS .loopLine{stroke-width:2px;stroke-dasharray:2,2;stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);}#mermaid-svg-vm9ikb7O0ylTsMaS .note{stroke:#aaaa33;fill:#fff5ad;}#mermaid-svg-vm9ikb7O0ylTsMaS .noteText,#mermaid-svg-vm9ikb7O0ylTsMaS .noteText>tspan{fill:black;stroke:none;}#mermaid-svg-vm9ikb7O0ylTsMaS .activation0{fill:#f4f4f4;stroke:#666;}#mermaid-svg-vm9ikb7O0ylTsMaS .activation1{fill:#f4f4f4;stroke:#666;}#mermaid-svg-vm9ikb7O0ylTsMaS .activation2{fill:#f4f4f4;stroke:#666;}#mermaid-svg-vm9ikb7O0ylTsMaS .actorPopupMenu{position:absolute;}#mermaid-svg-vm9ikb7O0ylTsMaS .actorPopupMenuPanel{position:absolute;fill:#ECECFF;box-shadow:0px 8px 16px 0px rgba(0,0,0,0.2);filter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4));}#mermaid-svg-vm9ikb7O0ylTsMaS .actor-man line{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;}#mermaid-svg-vm9ikb7O0ylTsMaS .actor-man circle,#mermaid-svg-vm9ikb7O0ylTsMaS line{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;stroke-width:2px;}#mermaid-svg-vm9ikb7O0ylTsMaS :root{--mermaid-font-family:\"trebuchet ms\",verdana,arial,sans-serif;} 爬虫 浏览器 CDN API服务器 React 访问https://shop.com 获取基础HTML框架 返回包含React Root的HTML 发送XHR请求GET /api/products 返回JSON数据 执行hydrate渲染DOM 生成完整商品列表DOM 爬虫 浏览器 CDN API服务器 React
2:动态页面逆向工程
2.1:XHR请求追踪与解析
- 打开Network面板并筛选XHR/Fetch请求
- 定位目标数据的API端点(如/graphql)
- 解析请求头认证参数(Authorization/X-API-Key)
- 复制为Python代码(Copy as cURL → 转换为requests代码)
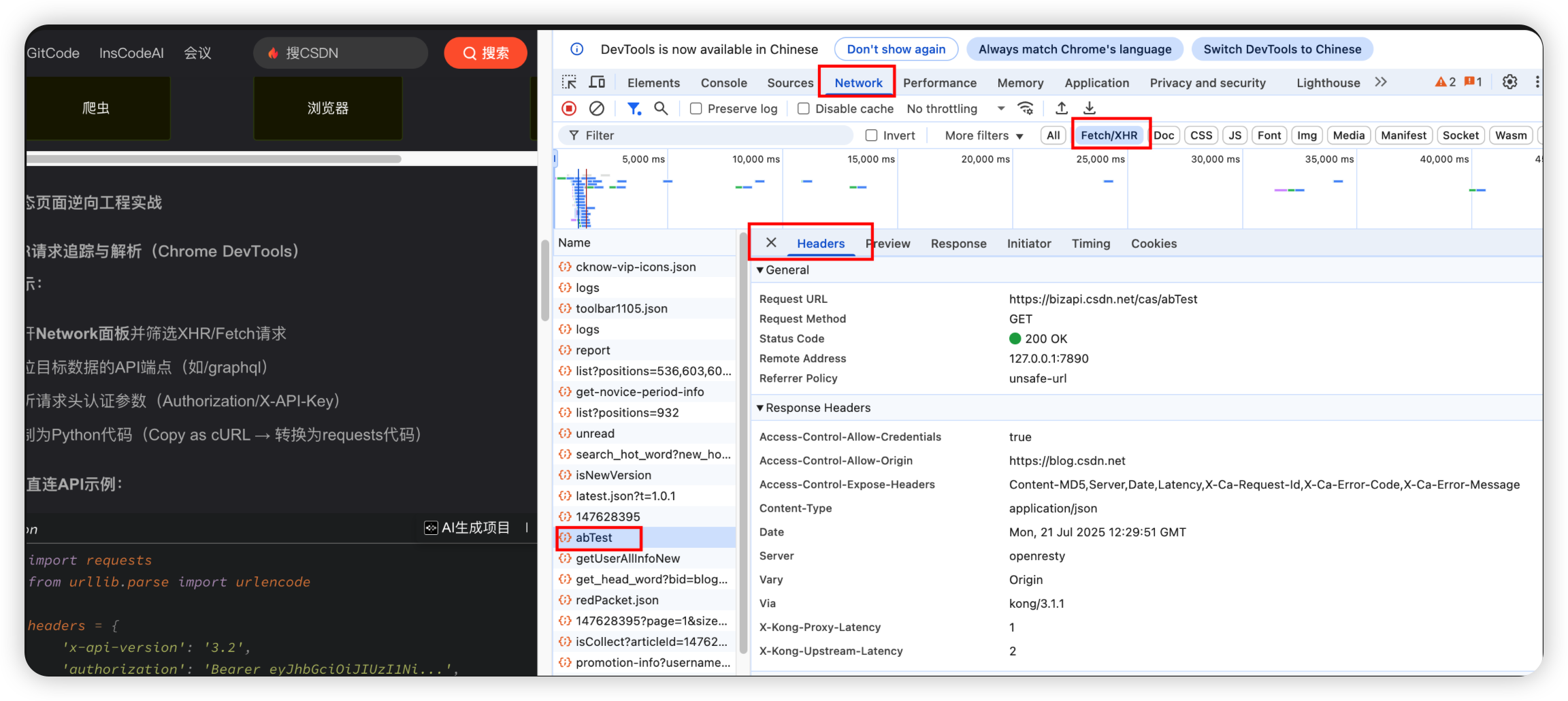
import requestsfrom urllib.parse import urlencode# 设置请求头,包含API版本和授权信息headers = { \'x-api-version\': \'3.2\', \'authorization\': \'Bearer eyJhbGciOiJIUzI1Ni...\',}# 定义请求参数,包括类别ID、排序方式、页码和平台信息params = { \'categoryId\': 305, \'sort\': \'sales_desc\', \'page\': 1, \'platform\': \'web\'}# 直接请求数据接口response = requests.get( \'https://api.shop.com/graphql\', headers=headers, params=urlencode(params, doseq=True))# 解析JSON数据products = response.json()[\'data\'][\'products\']2.2:websocket实时数据捕获
import asyncioimport websocketsimport jsonasync def fetch_danmu(): uri = \"wss://live-api.example.com/ws\" # 替换为实际的 WebSocket 地址 while True: try: async with websockets.connect(uri) as websocket: print(\"成功连接到直播间!\") # 可选:发送认证信息 auth_message = json.dumps({ \"user\": \"test_user\", \"token\": \"your_token\" }) await websocket.send(auth_message) print(\"认证信息已发送\") while True: try: # 接收服务器发送的弹幕消息 message = await websocket.recv() danmu_data = json.loads(message) print(f\"收到弹幕: {danmu_data.get(\'content\', \'未知内容\')}\") except websockets.exceptions.ConnectionClosed: print(\"连接断开,重新连接中...\") break except Exception as e: print(f\"发生错误: {e}\") break# 运行异步任务asyncio.get_event_loop().run_until_complete(fetch_danmu())3:无头浏览器控制技术
无头浏览器(Headless Browser)是指没有图形用户界面的浏览器,可以通过编程方式控制,模拟用户操作,执行JavaScript渲染,是现代爬虫技术中的重要工具。
- Puppeteer - Google开发的Node库,控制Chromium/Chrome
- Playwright - Microsoft开发的多浏览器控制工具
- Selenium - 传统的浏览器自动化框架(后面介绍)
- Pyppeteer - Puppeteer的Python版本
3.1:Playwright详解
Playwright是由Microsoft开发的跨浏览器自动化测试工具,支持Chromium、WebKit和Firefox
Playwright有如下的特性:
- 多浏览器支持:Chromium (Chrome, Edge)、WebKit (Safari)、Firefox
- 跨平台能力:Windows、macOS、Linux全平台支持 & 可本地运行也可CI/CD集成
- 多语言绑定:JavaScript/TypeScript、Python、Java、.NET
- 现代化架构:基于WebSocket的通信协议、自动等待机制、强大的选择器引擎
pip install playwrightplaywright install # 安装浏览器基本页面操作
from playwright.sync_api import sync_playwrightwith sync_playwright() as p: # 启动浏览器(无头模式) browser = p.chromium.launch(headless=False) # 创建新页面 page = browser.new_page() # 导航到URL page.goto(\"https://example.com\") # 获取页面标题 print(page.title()) # 截图 page.screenshot(path=\"example.png\") # 关闭浏览器 browser.close()元素定位与交互 - Playwright提供多种强大的选择器:
# CSS选择器page.click(\"button.submit\")# 文本选择器page.click(\"text=Login\")# XPathpage.click(\"//button[@id=\'submit\']\")# 组合选择器page.click(\"article:has-text(\'Playwright\') >> button\")自动等待机制 -> Playwright内置智能等待,无需手动添加sleep
# 等待元素出现(最多10秒)page.wait_for_selector(\"#dynamic-element\", timeout=10000)# 等待导航完成page.click(\"text=Navigate\")page.wait_for_url(\"**/new-page\")# 等待网络请求完成with page.expect_response(\"**/api/data\") as response_info: page.click(\"button.load-data\")response = response_info.value网络请求拦截
# 路由拦截def handle_route(route): if \"ads\" in route.request.url: route.abort() # 阻止广告请求 else: route.continue_()page.route(\"**/*\", handle_route)文件下载处理
# 等待下载开始with page.expect_download() as download_info: page.click(\"a#download-link\")download = download_info.value# 保存下载文件path = download.path()download.save_as(\"/path/to/save\")iframe处理
# 定位iframeframe = page.frame(name=\"embedded\")# 在iframe内操作frame.fill(\"#username\", \"testuser\")frame.click(\"#submit\")爬虫实战应用:
动态内容抓取
async with async_playwright() as p: browser = await p.chromium.launch() page = await browser.new_page() await page.goto(\"https://dynamic-ecom-site.com\") # 滚动加载所有商品 while await page.locator(\"text=Load More\").is_visible(): await page.click(\"text=Load More\") await page.wait_for_timeout(2000) # 适当延迟 # 提取所有商品数据 products = await page.locator(\".product\").evaluate_all(\"\"\" products => products.map(p => ({ name: p.querySelector(\'.name\').innerText, price: p.querySelector(\'.price\').innerText })) \"\"\") print(products) await browser.close()登录会话保持
# 保存登录状态context = browser.new_context()page = context.new_page()page.goto(\"login_url\")page.fill(\"#username\", \"user\")page.fill(\"#password\", \"pass\")page.click(\"#login\")# 保存cookiescontext.storage_state(path=\"auth.json\")# 后续使用保存的状态context = browser.new_context(storage_state=\"auth.json\")page = context.new_page()性能优化技巧
浏览器上下文复用:
context = browser.new_context()page1 = context.new_page()page2 = context.new_page()请求过滤:
await page.route(\"**/*.{png,jpg,jpeg}\", lambda route: route.abort())并行处理:
async with asyncio.TaskGroup() as tg: tg.create_task(scrape_page(page1, url1)) tg.create_task(scrape_page(page2, url2))常见问题解决方案
检测规避:
# 修改WebGL供应商信息await page.add_init_script(\"\"\" const originalGetParameter = WebGLRenderingContext.prototype.getParameter; WebGLRenderingContext.prototype.getParameter = function(parameter) { if (parameter === 37445) return \"Intel Open Source Technology Center\"; return originalGetParameter.call(this, parameter); };\"\"\")超时处理:
try: await page.wait_for_selector(\".element\", timeout=5000)except TimeoutError: print(\"元素加载超时\")元素点击问题:
await page.locator(\"button\").dispatch_event(\"click\") # 直接触发事件与Puppeteer对比
3.2:反反爬虫策略应对
- 指纹伪装:修改浏览器指纹特征
- 行为模拟:模拟人类操作模式(鼠标移动、随机延迟)
- 代理轮换:结合代理IP池使用
- WebGL/Canvas指纹处理:定制化渲染参数
3.3:高级技术应用
分布式无头浏览器集群
#mermaid-svg-apTJCqsOHBfWC8K7 {font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-apTJCqsOHBfWC8K7 .error-icon{fill:#552222;}#mermaid-svg-apTJCqsOHBfWC8K7 .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-apTJCqsOHBfWC8K7 .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-apTJCqsOHBfWC8K7 .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-apTJCqsOHBfWC8K7 .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-apTJCqsOHBfWC8K7 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-apTJCqsOHBfWC8K7 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-apTJCqsOHBfWC8K7 .marker{fill:#333333;stroke:#333333;}#mermaid-svg-apTJCqsOHBfWC8K7 .marker.cross{stroke:#333333;}#mermaid-svg-apTJCqsOHBfWC8K7 svg{font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-apTJCqsOHBfWC8K7 .label{font-family:\"trebuchet ms\",verdana,arial,sans-serif;color:#333;}#mermaid-svg-apTJCqsOHBfWC8K7 .cluster-label text{fill:#333;}#mermaid-svg-apTJCqsOHBfWC8K7 .cluster-label span{color:#333;}#mermaid-svg-apTJCqsOHBfWC8K7 .label text,#mermaid-svg-apTJCqsOHBfWC8K7 span{fill:#333;color:#333;}#mermaid-svg-apTJCqsOHBfWC8K7 .node rect,#mermaid-svg-apTJCqsOHBfWC8K7 .node circle,#mermaid-svg-apTJCqsOHBfWC8K7 .node ellipse,#mermaid-svg-apTJCqsOHBfWC8K7 .node polygon,#mermaid-svg-apTJCqsOHBfWC8K7 .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-apTJCqsOHBfWC8K7 .node .label{text-align:center;}#mermaid-svg-apTJCqsOHBfWC8K7 .node.clickable{cursor:pointer;}#mermaid-svg-apTJCqsOHBfWC8K7 .arrowheadPath{fill:#333333;}#mermaid-svg-apTJCqsOHBfWC8K7 .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-apTJCqsOHBfWC8K7 .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-apTJCqsOHBfWC8K7 .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-apTJCqsOHBfWC8K7 .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-apTJCqsOHBfWC8K7 .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-apTJCqsOHBfWC8K7 .cluster text{fill:#333;}#mermaid-svg-apTJCqsOHBfWC8K7 .cluster span{color:#333;}#mermaid-svg-apTJCqsOHBfWC8K7 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:\"trebuchet ms\",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-apTJCqsOHBfWC8K7 :root{--mermaid-font-family:\"trebuchet ms\",verdana,arial,sans-serif;} 调度中心 浏览器节点1 浏览器节点2 浏览器节点3 代理IP池
智能渲染策略
- 按需渲染:根据目标网站特点定制渲染策略
- 资源加载控制:选择性加载CSS/JS/图片
- 预渲染缓存:对常见页面进行预渲染
性能优化技术
- 浏览器实例复用:避免频繁启动关闭
- 页面池管理:维护多个页面实例
- 资源拦截:阻止不必要资源加载
- CDN缓存利用:合理设置缓存策略


